大创——基础知识储备
学习计划
视频异常检测与视频动作识别的概念明晰与区分
我们后续做的主要是暴力行为的识别,我个人原本概念并没有清楚,以为是属于视频异常检测领域,但这里更关注的是人的动作,应该与视频动作识别更贴合,以下是我结合网上文章理解的二者区别,用词不严谨处还请指正
视频异常检测系统能够检测明显偏离正常的异常行为或实体,例如在视频监控的先验知识有限的情况下识别多个移动物体,或检测特定事件,例如打架、踩踏、交通事故和流浪。视频异常通常是上下文的,并根据真实场景定义。具体来说,检测过程集中于识别所有视频中包含异常的视频片段,而定位致力于确定哪一帧是异常的,并解释该帧的哪一部分是异常的。
视频动作识别是通过已标记的数据集训练模型实现视频理解视频分类的功能。动作识别的目标是识别出视频中出现的动作,通常是视频中人的动作。视频可以看作是由一组图像帧按时间顺序排列而成的数据结构,比图像多了一个时间维度。动作识别不仅要分析视频中每帧图像的内容,还需要从视频帧之间的时序信息中挖掘线索。动作识别是视频理解的核心领域,虽然动作识别主要是识别视频中人的动作,但是该领域发展出来的算法大多数不特定针对人,也可以用于其他视频分类场景。
二维卷积 2D CNN
卷积神经网络(convolutional neural network)是含有卷积层(convolutional layer)的神经网络。它有高和宽两个空间维度,常用来处理图像数据。
卷积神经网络的结构
层级网络,数据包括输入层,卷积层,激活层,池化层,全连接层等
输入层:就是原始图像,非提取的信息,因此卷积神经网络是一个无监督的特征学习网络,数据输入层主要对原始图像数据进行预处理,基础的操作包括去均值、灰度归一化,数据增强等;
卷积层:就是特征提取层,一般卷积神经网络包含多个卷积层,一个卷积层可以有多个不同的卷积核。通过不同的多个卷积核对图像进行预处理,提取特征,每个卷积核会映射出新的特征平面。再通过非线性激活函数对卷积结果进行处理;
激活层:卷积神经网络需要激活层进行特征的选择和抑制;
池化层:用于降低特征平面分辨率及抽象特征,可以有效的压缩网络参数和数据,减少过拟合。池化层最主要的作用就是压缩图像同时保存图像的特征不变;
全连接层:是卷积神经网络的最后,具有卷积核和偏移量两个参数。(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽

卷积核的运算
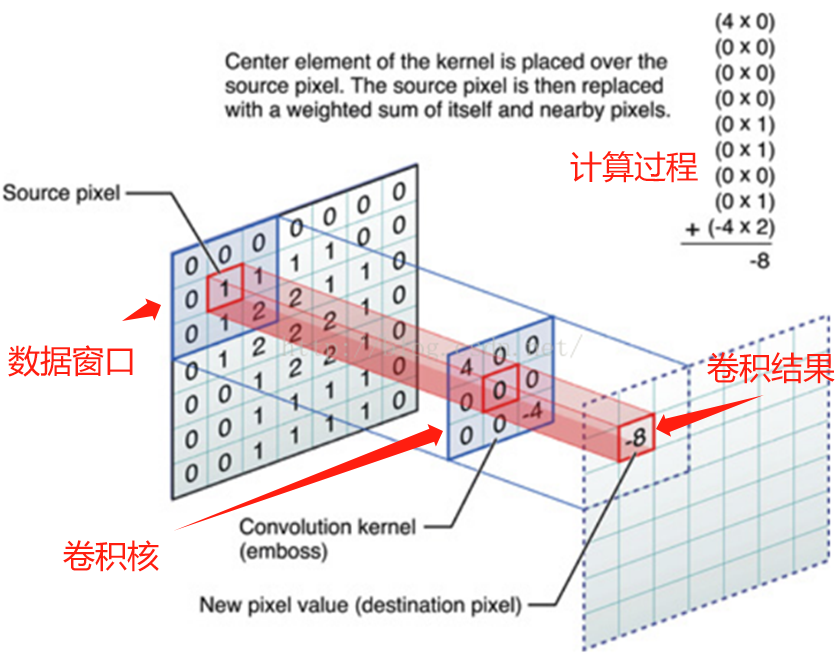
应用
2D卷积神经网络(2D CNN)则主要用于处理二维图像数据,如人脸识别、物体检测和自动驾驶等任务。2D CNN通过将图像划分为多个小的矩形区域(也称为滤波器或卷积核),可以对每个区域进行独立的特征提取。这种网络结构可以有效地减少计算量,同时提高特征提取的精度。在计算机视觉领域,2D CNN已经成为许多重要应用的基石,如人脸识别和目标检测等。
三维卷积 3D CNN
三维卷积输入多了深度C这个维度,输入是高度H宽度W深度C的三维矩阵。
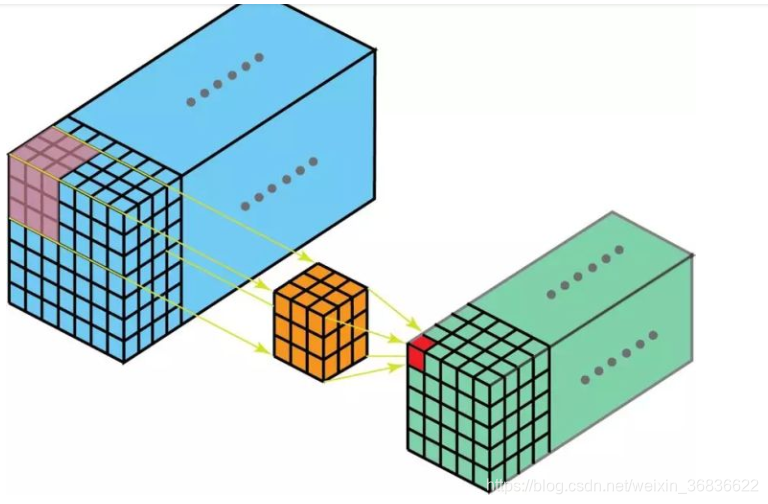
3D
CNN是如何对时间维度进行操作的,如下图所示,我们将时间维度看成是第三维,这里是对连续的四帧图像进行卷积操作,3D卷积是通过堆叠多个连续的帧组成一个立方体,然后在立方体中运用3D卷积核。在这个结构中,卷积层中每一个特征map都会与上一层中多个邻近的连续帧相连,因此捕捉运动信息。
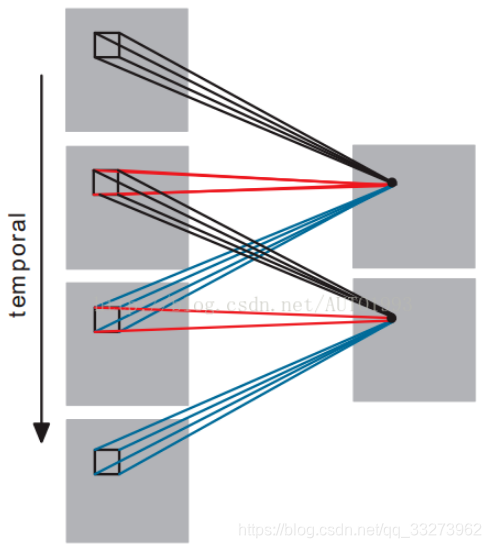
三维卷积和多通道卷积的区别
多通道卷积

具体的实现过程为:
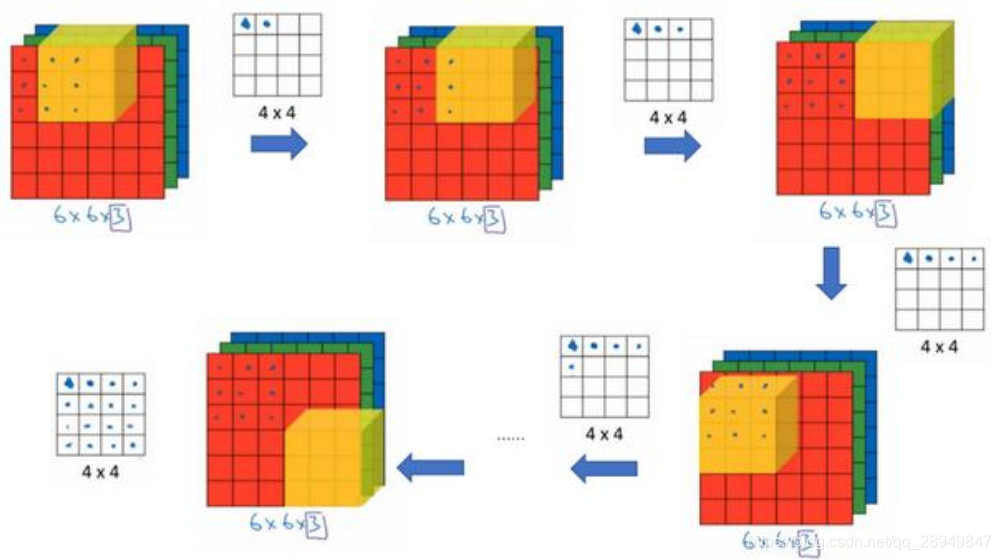
3D CNN主要运用在视频分类、动作识别等领域,它是在2D CNN的基础上改变而来。由于2D CNN不能很好的捕获时序上的信息,因此我们采用3D CNN,这样就能将视频中时序信息进行很好的利用。
循环神经网络 RNN 与 长短期记忆 LSTM
史上最详细循环神经网络讲解(RNN/LSTM/GRU) - 知乎
【循环神经网络】5分钟搞懂RNN,3D动画深入浅出_哔哩哔哩_bilibili
【LSTM长短期记忆网络】3D模型一目了然,带你领略算法背后的逻辑_哔哩哔哩_bilibili
立项书框架构建
工作清单
- 每个人写一份自我介绍,包括自身具备的知识条件、自己的特长、兴趣、已有的实践创新成果
- 每个人查找8篇关于人体动作识别或者暴力事件识别的相关论文,要求:1.国内外论文都要有 2.每个人找好后打成一个压缩包发群里,并把论文名发群里,后面发的就不要跟上面重复了 3.压缩包中除了包含论文,再有一个word文档,简单说明收集每个论文的主要内容
- 简单看一下我发群里的两份去年的立项书,结合立项书框架想一想,后续会进行分工
立项书框架
- 项目研究背景
- 研究意义
- 国内外研究现状
- 人类动作识别现状
- 暴力行为识别现状
- 项目研究目标及主要内容
- 项目创新特色概述
- 项目研究技术路线
- 项目方案设计
PPT思路初步构建
背景与意义
- 人体行为事件的含义与应用
- 视频暴力行为识别的意义
- 暴力行为的定义,早期与后续方法的比较,数据集的比较,暴力行为识别任务和应用
研究现状
单模态与多模态的优点和挑战
行为识别和暴力行为的识别和挑战
数据集的对比
解决方法的比较:3D CNN, 2D CNN+ RNN, 骨架
研究方法:抓住识别暴力的要素
一方面:抓住重要因素进行特征提取
另一方面:尽可能去除冗余信息(裁剪 / 去背景)
算法框架
注意力融合模块
总结
提出了一种基于多模态特征融合的视频暴力行为识别算法。通过融合RGB模态提供的外观信息、RGB帧差提供的运动信息以及Depth模态提供的相对位置信息,丰富、完善了暴力行为的特征,使其能够准确、鲁棒地在复杂的真实环境下进行暴力行为识别。
提出了一种自适应的注意力算法用于多模态融合。让模型自适应地学习不同模态特征之间的权重关系,允许模型根据具体任务动态调整每个模态的重要性,从而更灵活地应对不同的场景。
参考文献
【视频异常检测综述-论文阅读】Deep Video Anomaly Detection: Opportunities and Challenges-CSDN博客