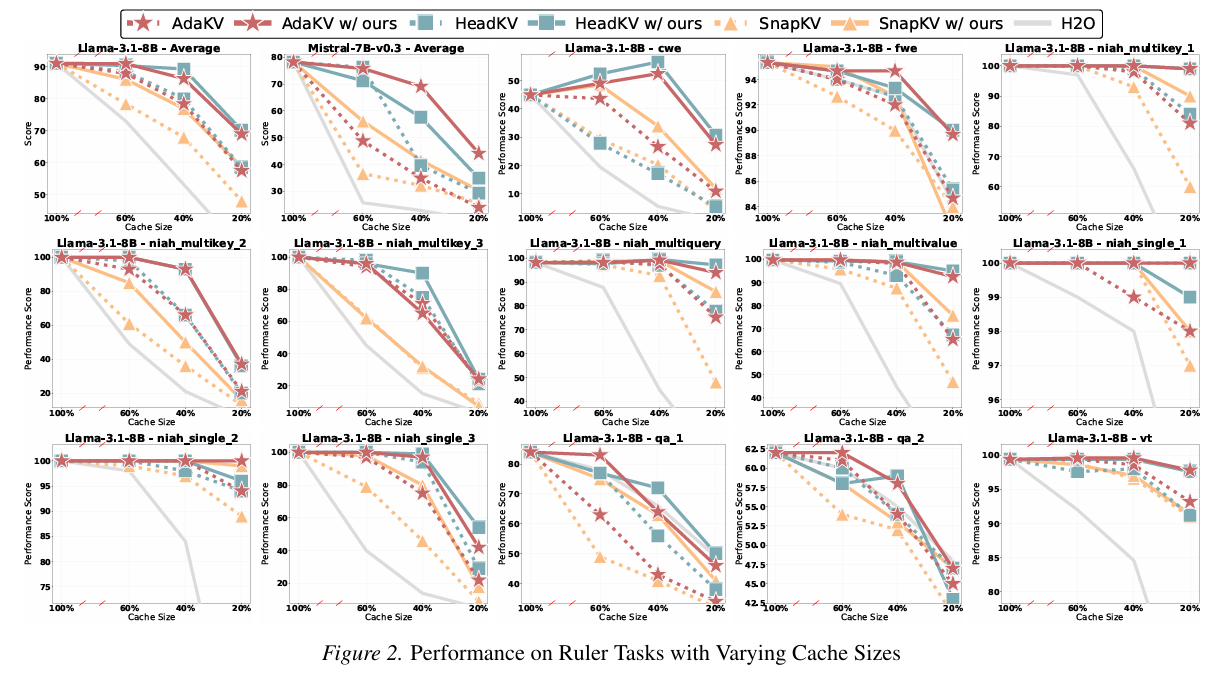
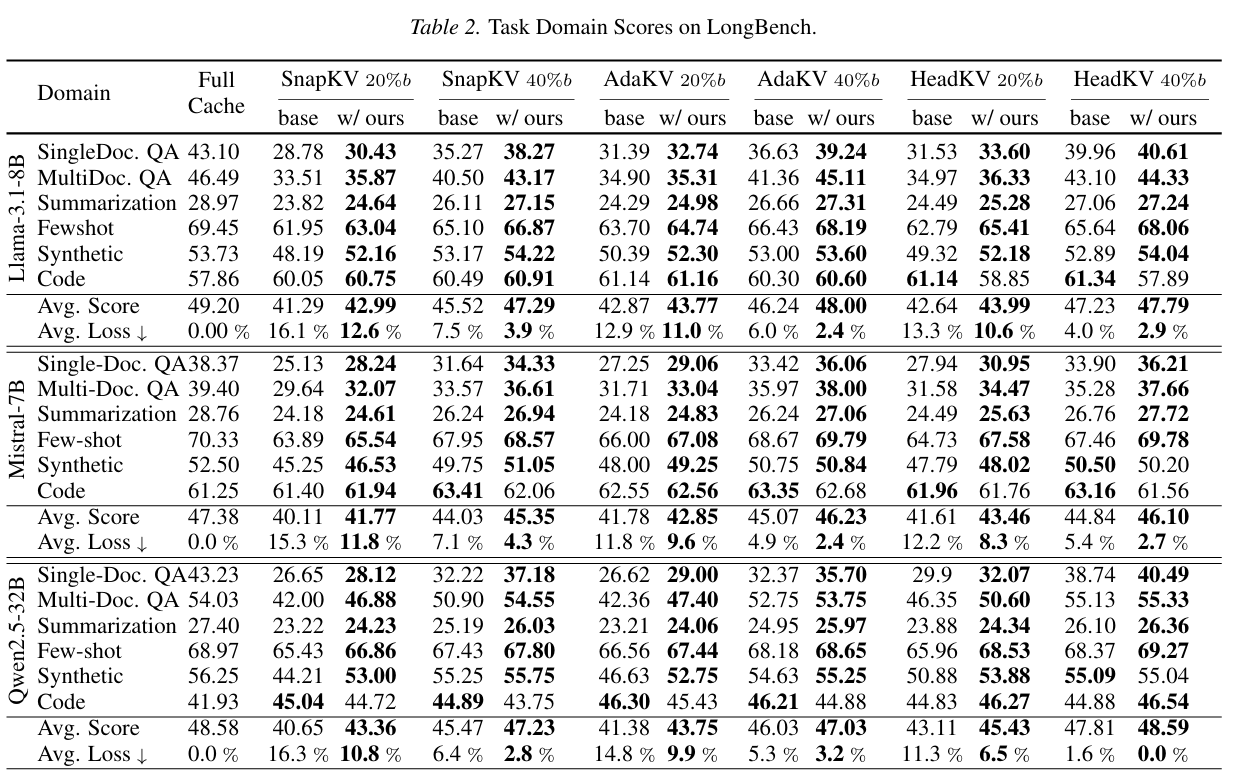
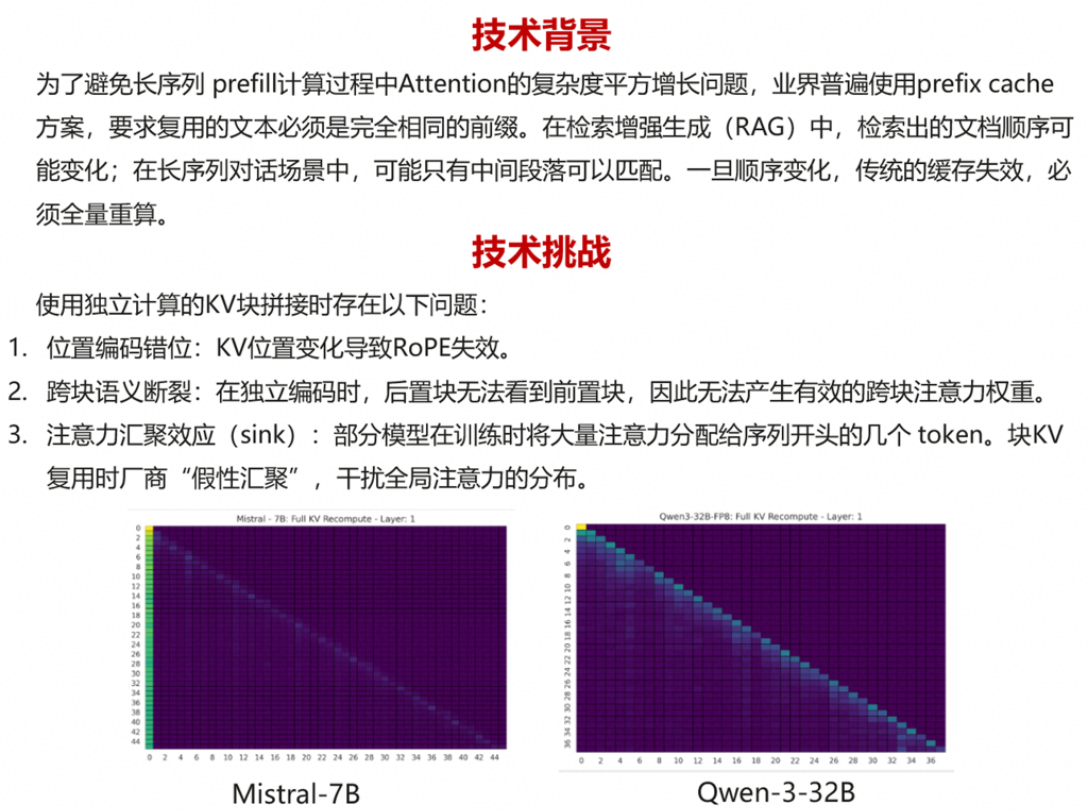
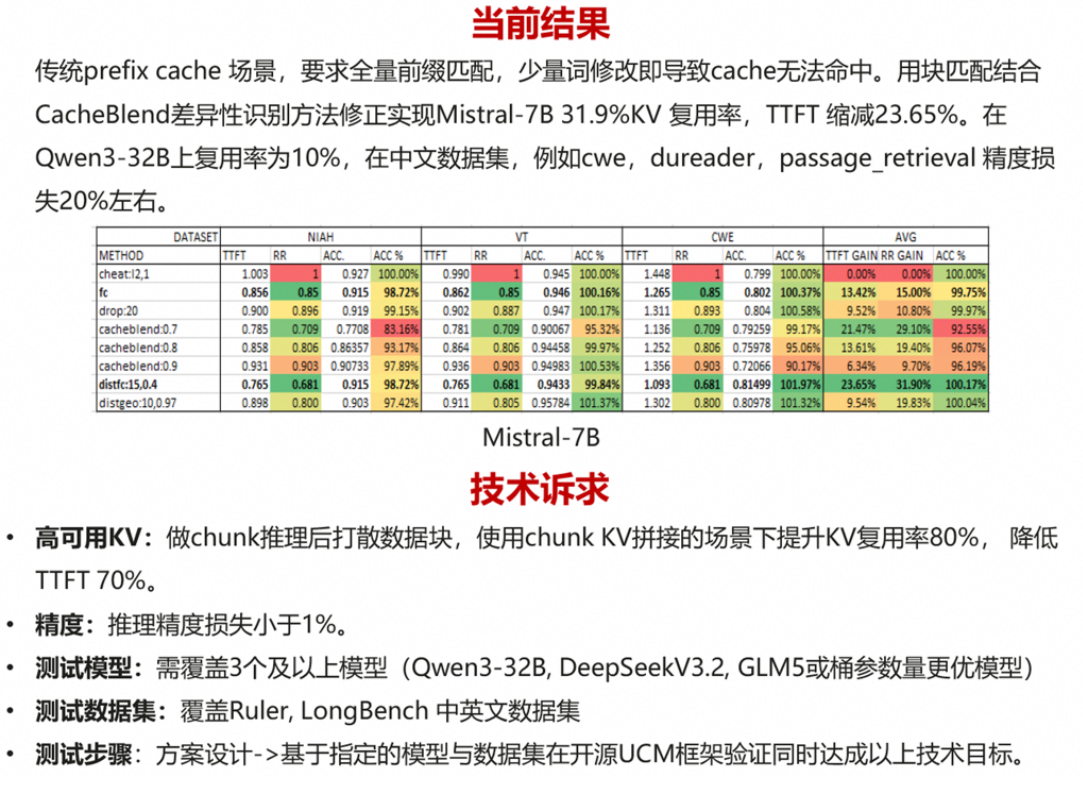
论文阅读——抗幻觉多智能体框架MA-CF
背景
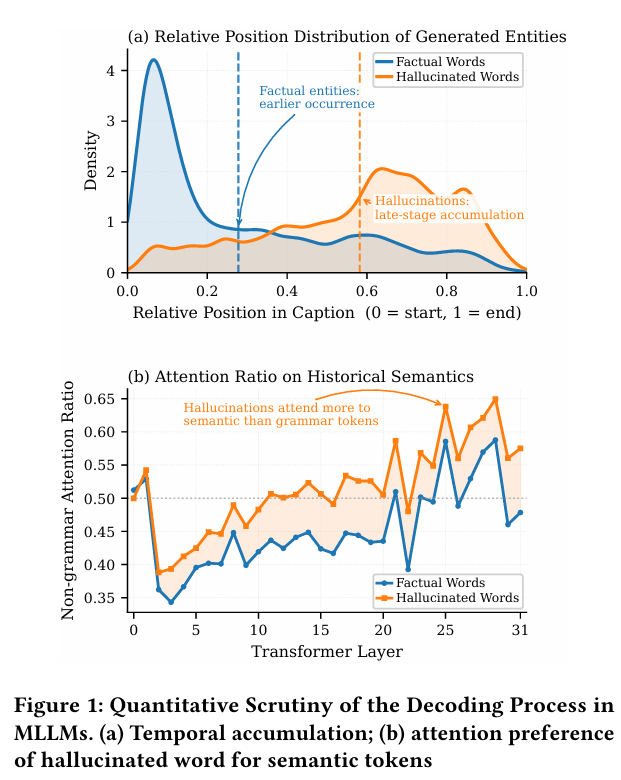
单智能体架构(single-agent architectures)面临着一个内在的优化冲突:即最大化生成响应质量(Generative response quality)与减少事实性幻觉(Mitigating factual hallucinations)之间的矛盾
既要追求生成质量(语言丰富、有文采、答复详尽),又要追求事实精确(严格受限、不乱编)。这两个目标在参数层面会产生梯度干扰(Gradient interference),对事实的过度约束往往会损害语言的表达力与实用性。
related works
大模型幻觉的定义与分类
现代分类(无源/自由问答场景):
事实性幻觉(Factual Hallucinations):生成内容与现实世界的客观事实发生矛盾(例如说“牛顿提出了相对论”)。
忠实性幻觉(Faithfulness Hallucinations):生成内容不符合用户的指令要求或上文语境逻辑(例如答非所问、前后矛盾)。
MA-CF 的针对性设计: 框架中的 幻觉分析 Agent(𝒜hallu) 专门把关“事实性幻觉”,而 质量分析 Agent(𝒜qual) 专门审查“忠实性幻觉”(指令对齐与逻辑一致),实现了分类施策。
单智能体缓解方案
| 范式分类 | 典型技术方法 | 核心思路 |
|---|---|---|
| 1. 推理时干预 (Inference-Time Intervention) | Prompt 工程、思维链(CoT)、上下文感知解码(CAD) | 在不改变模型参数的情况下,通过约束提示词或优化解码概率引导生成。 |
| 2. 架构与知识增强 (External Knowledge Integration) | 检索增强生成(RAG) | 引入外部知识库,让模型动态查询实时/真实数据,打破静态参数限制。 |
| 3. 事后参数精炼 (Post-Hoc Parameter Refinement) | 领域监督微调(SFT)、参数编辑(Parameter Editing)、嵌入空间修剪 | 重新训练或定位修改模型内部权重神经元,纠正错误记忆。 |
单智能体的致命缺陷:“自环问题(Self-loop Problem)”:
单模型方法让同一个 Agent 同时担任生成者(Generator)、评估者(Evaluator)和纠错者(Corrector)。这会导致:
- 认知盲区与自我确认偏误:当模型尝试自我检查(Self-reflection)时,其评估过程依然受限于最初产生错误的同一套内部知识与启发式偏见,无法实现客观诊断。
- 优化冲突(Trade-off):事实精准度与语言流畅度在单一模型内互相拉扯,过度限制事实会损害回答的丰富度。
多智能体系统
| 方案范式 | 代表性框架 / 文献 | 核心机制与思路 | 论文指出的内在局限性 |
|---|---|---|---|
| 1. 迭代辩论范式 (Iterative Debate) | ChatEval (Chan et al., 2023/2024) | 多个 Agent 针对同一话题开展多轮交叉辩论与质询,通过多视角沟通逐步修正错误并达成共识。 | ❶ 共识偏误(Consensus Bias):Agent 为了强行达成一致,常互相妥协,反而“稀释”了高质量输出或强化了表面合理的错误; ❷ 职责混杂:将事实核查与质量评估掺杂在辩论中; ❸ 高延迟与高 Token 消耗。 |
| 2. 协作过滤范式 (Collaborative Filtering) | AgentVerse (Chen et al., 2024) | 多个 Agent 组成审查阵营,通过筛选与抑制异常离群值(Outliers),减少复杂推理中的幻觉。 | ❶ 盲目依赖“数量堆叠”:主要靠增加 Agent 数量来干预错误,缺乏精细的职能解耦; ❷ 重降幻、轻质量:只关注消除错误,忽视了回答的语篇表达与完整性。 |
| 3. 动态网络与角色分配 (Dynamic Agent Networks) | DyLAN (Liu et al., 2023) MRBalance (Zou et al., 2025) | 根据任务动态挑选/组建 Agent 团队或指定特定角色(如数据库转换、因果识别),优化特定业务流程。 | ❶ 缺少关注分离(Separation of Concerns):绝大多数框架依然将“事实核查”与“质量评估”混在同一个决策节点中; ❷ 无法同时兼顾事实精准度与语言表达力。 |
现有多 Agent 系统的三大缺陷:
- 盲目依赖“数量堆叠(Agent
Multiplicity)”:许多系统仅仅依靠增加 Agent
数量来投票减少错误,缺乏精细的职能分工。
- 职责混杂导致“共识偏误(Consensus
Bias)”:传统辩论(Debate)方法将“查证事实”与“评估表达”混在同一讨论中。Agent
们为了达成一致共识,往往会互相妥协,最终输出被“稀释”的平庸内容,甚至强化了表面合理的错误。
- 重“降幻”轻“表达”:现有多 Agent 论文绝大多数只关注如何降低错误率,忽略了回答的语言质量与完整性。
Methodology
核心变量

核心目标
将“生成一个好回答”抽象为一个寻找最优解 Af 的优化问题。
给定用户查询 Q,目标是找到一个回答 A,使得联合效用函数(Joint Utility Function)U(A|Q) 最大化:
Af = arg maxAU(A|Q) = arg maxA[w1 ⋅ F(A, Q) + w2 ⋅ Q(A, Q)]
- F(A, Q)(Factuality
/ 事实性):回答在多大程度上符合真实的客观事实。
- Q(A, Q)(Quality /
质量):回答在语言丰富度、相关性、逻辑完整性上的表现。
- w1, w2:事实性与质量之间的潜在权重(在实际决策中由合成 Agent 动态平衡)。
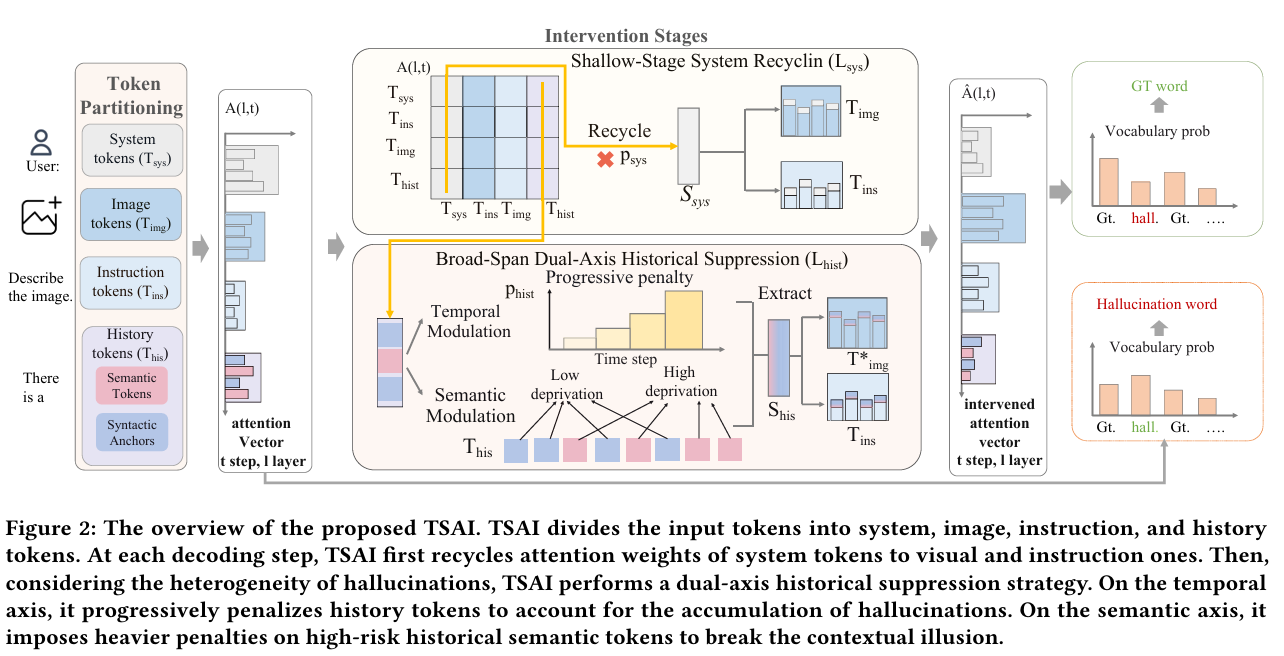
MA-CF framework
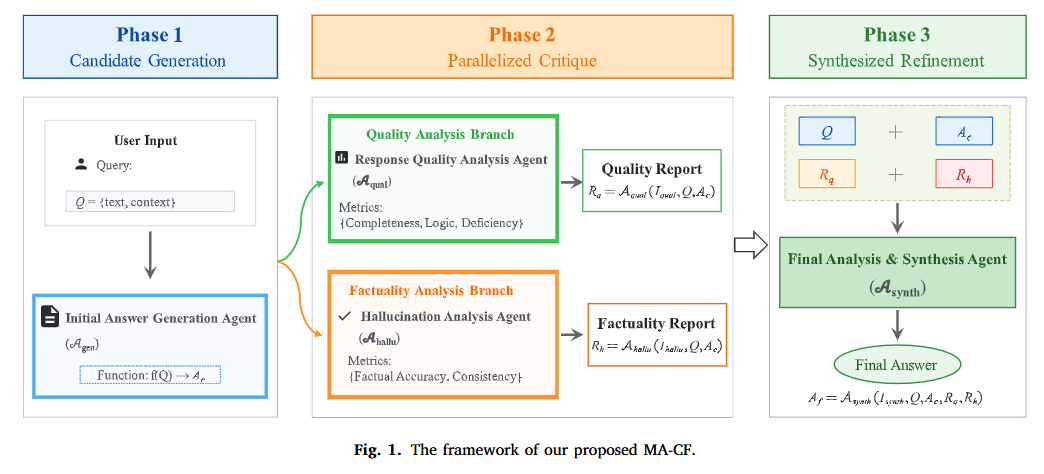
阶段 1:候选生成(Phase 1: Candidate Generation)
- 输入:用户的原始提问 Q(包含文本与上下文环境)。
- 执行角色:初稿生成 Agent(𝒜gen)。
- 处理逻辑: Agent 根据输入 Q
直接生成一份未经自我修正的初始回答草稿 Ac(f(Q) → Ac)。
- 设计用意: 故意不让初稿 Agent 进行过度自我审查,目的是保留一个无偏见的原始底板,将其暴露给后续的专业审查角色,避免模型在早期通过模糊表述掩盖自己的知识盲区。
阶段 2:并行评审(Phase 2: Parallelized Critique)
初稿 Ac 和原始问题 Q 会同时被分发给两个互相独立、并行运行的诊断分支:
1. 质量分析分支(Quality Analysis Branch,绿色框)
- 执行角色:响应质量分析 Agent(𝒜qual)。
- 核心指标:完整度(Completeness)、逻辑性(Logic)、缺陷分析(Deficiency)。
- 产出:质量报告 Rq = 𝒜qual(Iqual, Q, Ac)。
- 职责:评估回答是否全面回答了用户问题、逻辑是否顺畅,并提取出“好的观点(Spro)”与“逻辑缺陷(Scon)”。
2. 事实性分析分支(Factuality Analysis Branch,橙色框)
- 执行角色:幻觉分析 Agent(𝒜hallu)。
- 核心指标:事实准确度(Factual
Accuracy)、一致性(Consistency)。
- 产出:事实报告 Rh = 𝒜hallu(Ihallu, Q, Ac)。
- 职责:像“查事实的校对员”一样,严格审查草稿中是否存在瞎编、错漏或不符事实的内容,并输出具体的错误切片与修正说明(hi, ji)。
💡 架构亮点: 这个阶段的 keypoint 是并行(Parallelized)与解耦(Decoupled)。𝒜qual 专注看“文采与逻辑”,𝒜hallu 专注查“真伪”,两者互不干扰,避免了单个 Agent 既想写好文章又想扣事实细节时的“梯度干扰”与妥协折中。
阶段 3:合成精炼(Phase 3: Synthesized Refinement)
输入:汇总四个关键要素——原始问题 Q + 初始草稿 Ac + 质量报告 Rq + 事实报告 Rh。
执行角色:最终分析与合成 Agent(𝒜synth)(扮演主编/元推理者角色)。
处理逻辑:
Agent 根据输入的完整上下文,执行三项精炼操作:
- 保留:保留草稿 Ac
中被质量报告认可且未被事实报告打掉的高质量内容。
- 修正:根据事实报告 Rh
的批注,对错漏切片进行精准重写与定点替换。
- 补充:根据质量报告 Rq 指出的逻辑漏洞或未尽事宜,补全上下文。
- 保留:保留草稿 Ac
中被质量报告认可且未被事实报告打掉的高质量内容。
产出:最终优质回答 Af = 𝒜synth(Isynth, Q, Ac, Rq, Rh)。

Experiments
dataset
1. PreciseWiki(短文本 / 精准事实问答)
- 评估目标:评估模型在短答案场景下的显性事实准确性(Explicit
factual accuracy)。
- 主要应对幻觉:外在幻觉(Extrinsic
Hallucinations),即生成内容与现实世界的客观知识或可核实事实直接冲突(如错乱的日期、实体名称、概念定义)。
- 数据集来源与规模:源自维基百科条目,并按难度进行了分层,随机采样了
N = 2000 个样本。
- 核心价值:作为无噪声的 Ground-truth 标准,用于评估模型的“已知与未知边界”,特别是测试模型在内部知识不足时拒绝回答不可答问题(Knowledge-aware refusal)的能力。
2. LongWiki(长文本生成 / 篇章级问答)
- 评估目标:评估模型在长文本生成中维持长序列记忆、信息整合以及长距离语义连贯性与忠实度的能力。
- 主要应对幻觉:隐性幻觉(Implicit
Hallucinations),即模型在生成段落级长文时,为了桥接逻辑断层或补全上下文而编造细节、产生前后矛盾。
- 数据集来源与规模:要求模型围绕复杂维基百科实体生成段落级内容,随机抽取了
N = 250 个复杂实体。
- 核心价值:突破了传统二元(对/错)短问答的局限,测试 MA-CF 在长文展开过程中是否能稳住事实密度,避免“越写越瞎编”。
3. HaluEval 2.0(跨领域综合基准)
- 评估目标:评估框架在不同语义领域和多元任务场景下的鲁棒性与泛化能力。
- 数据构成:HaluEval 2.0 是一个大型高质量基准(包含
3.5
万个生成与人工标注样本),覆盖三大常见任务:问答(QA)、基于知识的对话(Knowledge-Grounded
Dialogue)和文本摘要(Text Summarization)。
- 采样规模:作者构建了一个分层测试集,包含跨 5
个不同领域的平衡样本 N = 800。
- 核心价值:包含大量“看似合理但实际错误(Plausible but incorrect)”的微妙幻觉样本,专门用来检验模型区分似是而非的虚构内容与真实事实的边界感知能力。
指标
1. PreciseWiki(短文本精准问答)
将模型输出划分为三个互斥集合:正确(Correct, C)、幻觉(Hallucinated, H)、拒绝回答(Rejected, R)。
正确率(Correct Rate):$\frac{\vert{}C\vert{}}{N}$,评估整体答对比例。
幻觉率(Hallucination Rate):$\frac{\vert{}H\vert{}}{N - \vert{}R\vert{}}$,在未拒绝的回答中出现事实错误的比例(核心安全指标)。
拒答率(Rejection Rate):$\frac{\vert{}R\vert{}}{N}$,评估模型在知识不足时果断“弃答”的安全边界意识。
F1 分数(F1 Score):正确率与回答意愿(1 − Rejection Rate)的调和平均数,防止模型为了追求高正确率而盲目弃答或为了高回答率而胡乱猜答:
$$\text{F1} = 2 \cdot \frac{\text{Correct Rate} \cdot (1 - \text{Rejection Rate})}{\text{Correct Rate} + (1 - \text{Rejection Rate})}$$
2. LongWiki(长文本篇章问答)
长文本不能简单套用“对/错”二元分类,作者采用了原子断言抽取协议(Atomic claim extraction protocol, 设置上限 k = 32)。设 Sref 为标准答案的断言集,Sout 为模型输出抽取的断言集:
- Recall@32(召回率):$\frac{\vert{}\text{输出中得到支持的断言}\vert{}}{\vert{}S_{ref}\vert{}}$,评估模型捕获关键细节的全面性。
- Precision(精准率):$\frac{\vert{}\text{输出中得到支持的断言}\vert{}}{\vert{}S_{out}\vert{}}$,评估输出内容中每一个断言的事实准确性。
- F1@32:Precision 与 Recall@32 的调和平均数,综合惩罚信息遗漏与虚构断言。
3. HaluEval 2.0(跨领域综合评估)
- Macro Factual
Rate(宏观事实率):样本级的二元评估,仅当某个样本中的所有断言都完全正确时,该样本才算事实正确。
- Micro Factual
Rate(微观事实率):单个样本内部得到事实支持的断言比例(捕获样本内部的事实一致性)。
- Average Factual Rate(平均事实率):全数据集所有样本微观事实率的平均值,代表系统的整体事实密度(Factual density)。
Main results
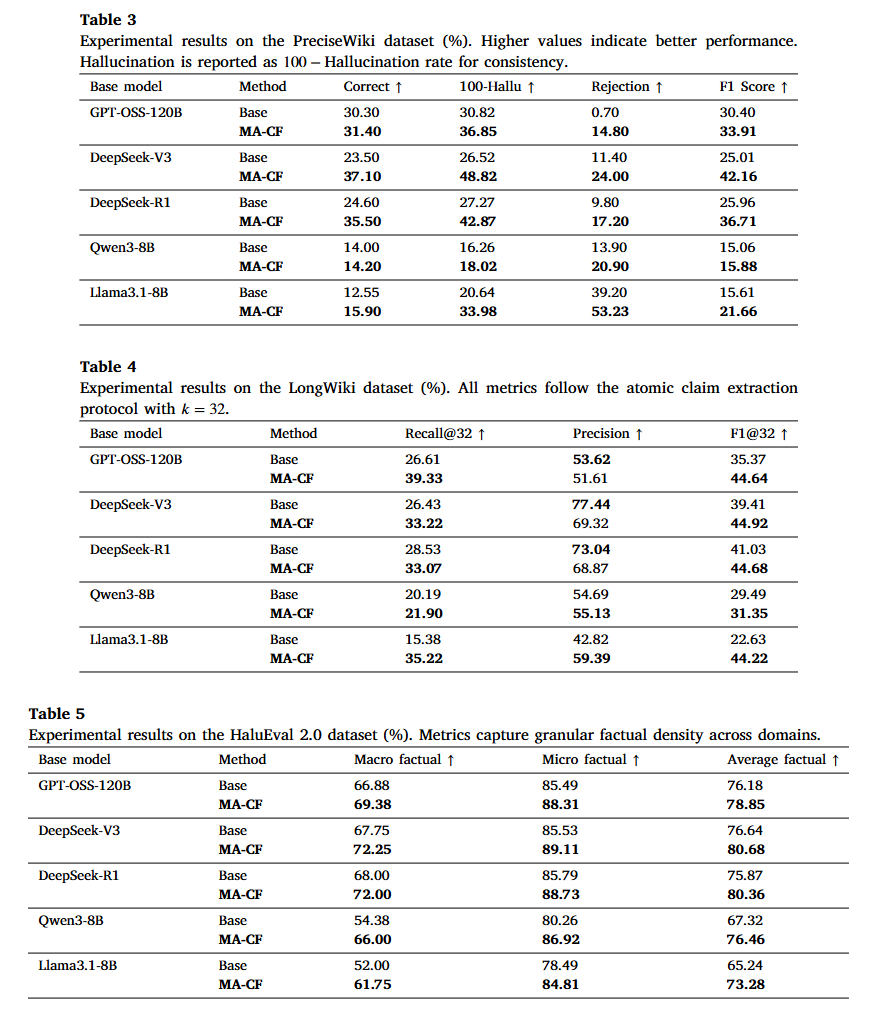
消融实验
| 变体名称 | 对应 Fig. A.3 模板 | 实验设计与假设 |
|---|---|---|
| 1. 简单增强单 Agent | 图 (e) Simple Answer Without Halu |
不搞多 Agent,只在单个提示词里强行要求“不胡编乱造、拒绝不懂的问题”。 |
| 2. 质量与幻觉合并 | 图 (b) Response Merge Agent |
把“查事实”和“评质量”合并到一个通用 Agent 里。 |
| 3. 质量分析细拆分 | 图 (a) Separate Quality Analysis |
把质量分析 Agent 再拆成“评语 Agent”和“正反论点 Agent”。 |
| 4. 仅保留质量分析 | 图 (c) Final Only Quality Decision |
砍掉幻觉核查 Agent,只看质量分析报告。 |
| 5. 仅保留幻觉分析 | 图 (d) Final Only Hallucination Decision |
砍掉质量分析 Agent,只看幻觉核查报告。 |

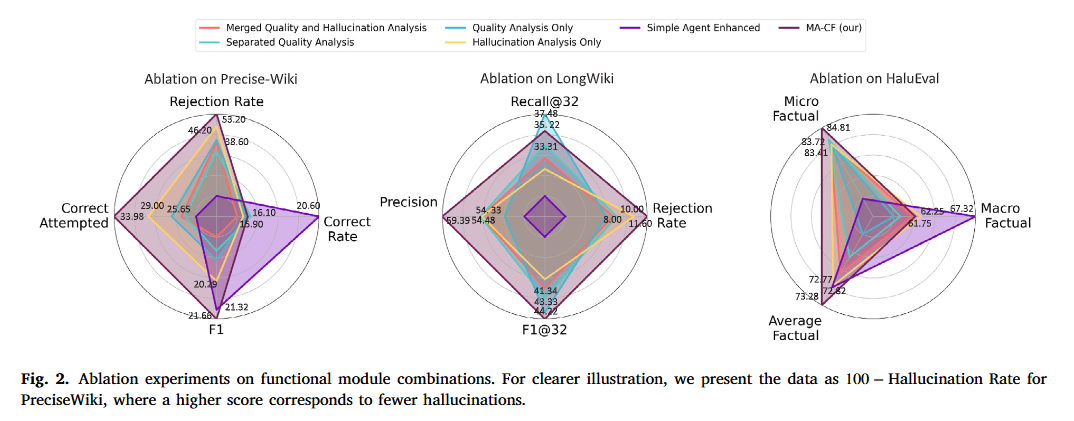
Agent 功能性分析
在 Section 4.5 中,作者做了一件更精细的事:保留 4 个 Agent 的完整架构不变,但故意“剥夺/弱化”某个 Agent Prompt 里的核心功能指令,以此观察系统的性能变化。
以 Llama3.1-8B-instruct 为基座,作者设计了 3 组 targeted
Prompt 弱化配置(具体 Prompt 见附录 Fig. A.2):
- 弱化质量分析(Weaken Quality Analysis):
- 改动:简化质量 Agent 的
Prompt,删除了要求其“权衡正反方论点(Spro, Scon)”和“检查逻辑一致性”的具体指令,仅保留句式简陋的通用质量评估要求。
- 改动:简化质量 Agent 的
Prompt,删除了要求其“权衡正反方论点(Spro, Scon)”和“检查逻辑一致性”的具体指令,仅保留句式简陋的通用质量评估要求。
- 弱化幻觉分析(Weaken Hallucination Analysis):
- 改动:简化幻觉 Agent 的
Prompt,仅让其查找浅层事实错误,删除了“深挖推理过程中幻觉根源/错误归因”的高阶指令。
- 改动:简化幻觉 Agent 的
Prompt,仅让其查找浅层事实错误,删除了“深挖推理过程中幻觉根源/错误归因”的高阶指令。
- 弱化决策(Weaken Decision):
- 改动:修改合成 Agent 的 Prompt,减少其对前两个 Agent 提交的评估报告的依赖,鼓励其做出更多自主(但缺乏依据)的独立判断。
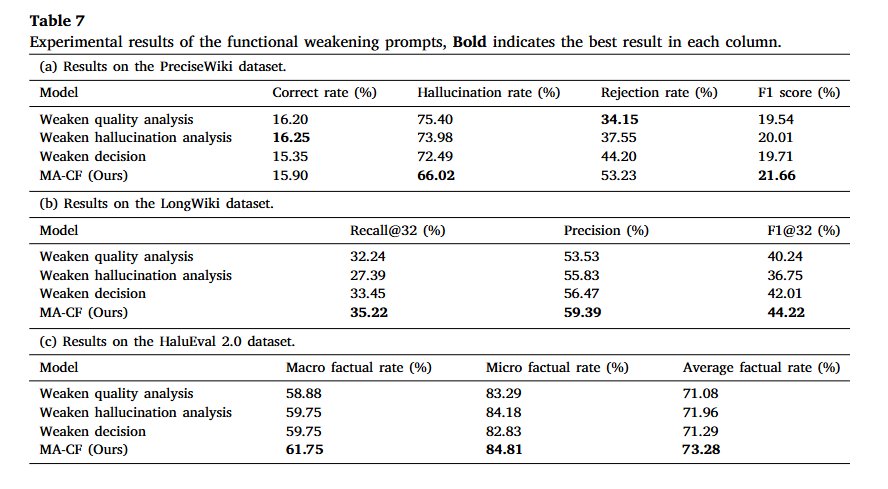
中间报告一致性验证
为了验证中间的质量分析 Agent(𝒜qual)和幻觉分析 Agent(𝒜hallu)出具的诊断报告到底靠不靠谱?它们自己会不会产生二次幻觉?
如果中间环节的 Agent 生成的是毫无关联的废话或错误批判(False Criticism),那么最后一步的合成 Agent 就成了“垃圾进,垃圾出”(Garbage in, Garbage out)。为了验证这两个中间 Agent 的实效性与可靠性,作者设计了一套严谨的自动化中间报告相关性评估实验。
数据集抽样: 从三个数据集(PreciseWiki、LongWiki、HaluEval 2.0)中各随机抽取 20% 的样本(样本量分别为 n = 400、n = 50、n = 160)。
自动化“裁判”模型: 引入超大规模强推理模型 DeepSeek-R1-671B 作为自动化评估员(Evaluator)。
评估维度与标尺: 裁判模型对比 问题 Q、真实标准答案(Ground Truth)、初始草稿 Ac 与 Agent 生成的报告(Rq 或 Rh),测量报告的上下文相关性与一致性(Contextual Relevance),并将得分按连续标尺划分为 3 个区间:
- 不一致(Not Consistent,Score < 0.3):报告偏离主题、分析错误或产生二次幻觉。
- 部分一致(Partially Consistent,0.3 ≤ Score ≤ 0.7):报告捕捉到了关键信息,但粒度或严谨度与裁判标准存在微小差异。
- 高度一致(Highly Consistent,Score > 0.7):报告分析极其精准,完全符合裁判模型的参考标准。
样例和错误分析
成功纠错案例
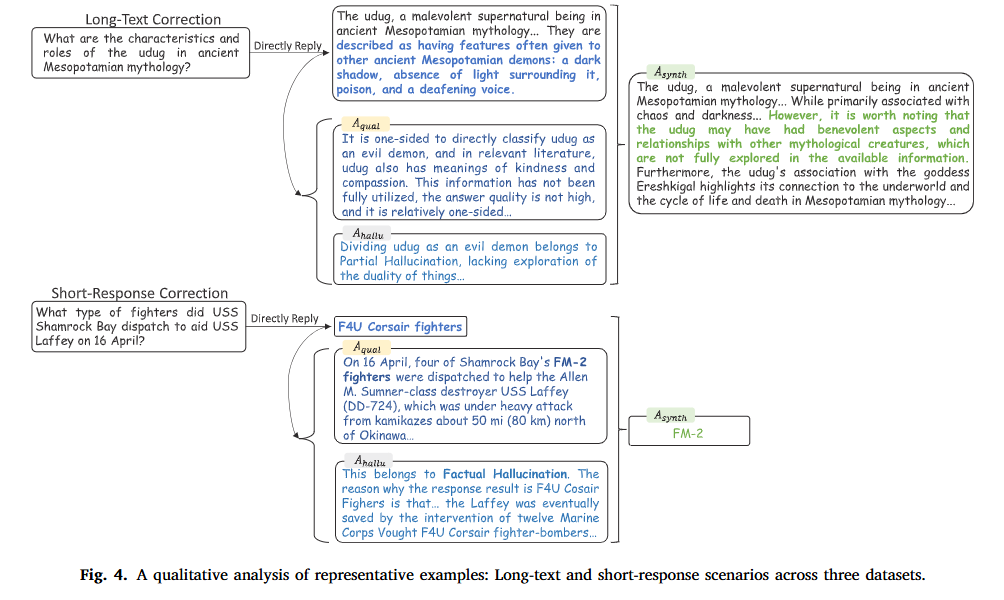
1. 长文本案例:长尾神话知识纠偏(美索不达米亚神话中的 Udug)
- 初始草稿(Ac):片面地将
Udug 描述为一种纯粹邪恶的恶魔(暗影、毒药、刺耳的声音)。
- 质量 Agent(𝒜qual)诊断:指出回答是片面的,相关文献中
Udug 也具有“善良与同情”的含义,信息利用不充分。
- 幻觉 Agent(𝒜hallu)诊断:将其归类为“部分幻觉(Partial
Hallucination)”,缺乏对事物二象性(Duality)的探讨。
- 合成 Agent(𝒜synth)精炼:保留了其与混沌黑暗相关的记载,同时补充了 Udug 善良的一面以及与女神 Ereshkigal 的联系,生成了全面且准确的最终回答。
2. 短文本案例:历史事实精确更正(三明湾号航母援救拉菲号驱逐舰)
- 问题:4月16日,USS Shamrock Bay
派遣了什么型号的战斗机协助 USS Laffey?
- 初始草稿(Ac):错误地回答为
"F4U Corsair"(海盗式战斗机)。
- 质量 Agent(𝒜qual)诊断:查证历史记录指出,当时派出的实际上是
4 架 FM-2 战斗机。
- 幻觉 Agent(𝒜hallu)诊断:识别为“事实性幻觉”,澄清
F4U 确实参与了对 Laffey 的救援(陆战队 12 架 F4U 战斗轰炸机),但
Shamrock Bay 当时具体派出的战斗机是 FM-2。
- 合成 Agent(𝒜synth)精炼:定点更正,最终仅输出准确的答案
"FM-2"。
失败案例

1. 失败案例 1:生物学知识漏诊(带状糖蚁的繁殖行为)
- 问题:带状糖蚁的生命周期、交配模式与蚁群结构。
- 初始草稿:错误地称带状糖蚁“与多个雄性交配(实际上一生只交配一次,即单雄交配
monandrous)”,蚁群通常是单后制。
- 诊断过程:
- 幻觉 Agent(𝒜hallu)成功指出了蚁群结构遗漏了“多后制(polygyny,多只蚁后共存)”的可能性。
- 质量 Agent(𝒜qual)漏诊了,未能挑战草稿中“与多个雄性交配”这一错误的繁殖行为描述。
- 幻觉 Agent(𝒜hallu)成功指出了蚁群结构遗漏了“多后制(polygyny,多只蚁后共存)”的可能性。
- 最终结果:合成 Agent 成功补充了多后制蚁群的知识,但完好地保留了关于交配模式的原始幻觉。
2. 失败案例 2:统计数据虚高(足球运动员 Aleksandar Đurić 的生涯数据)
- 问题:Đurić 为新加坡国家队取得的显著成就。
- 初始草稿:称其出场 128 次打入 50
球(严重虚高,实际数据为 53 场打入 24 球)。
- 诊断过程:
- 质量 Agent(𝒜qual)准确指出了草稿遗漏了
Đurić 的个人荣誉(如 AFF 最佳射手、年度最佳球员)。
- 幻觉 Agent(𝒜hallu)漏诊了,它误以为
50 球/128 场的数据已经得到验证,未能识别出这一严重的数值幻觉。
- 质量 Agent(𝒜qual)准确指出了草稿遗漏了
Đurić 的个人荣誉(如 AFF 最佳射手、年度最佳球员)。
- 最终结果:合成 Agent 补充了完整的个人荣誉,但原封不动地保留了 50 球/128 场的严重统计数据幻觉。
作者归纳出了 MA-CF 的核心瓶颈:
- “木桶效应”与能力上限:
系统的抗幻觉上限,严格取决于单个诊断 Agent
的触发敏感度(Sensitivity)。合成 Agent(𝒜synth)扮演的是“整合者”而非“全知者”,如果
𝒜qual
或 𝒜hallu
没有把错误标注出来,合成 Agent 就无法凭空发现并纠正该遗留幻觉。
- 错漏传递风险:
- 幻觉 Agent 漏诊 →
数值/事实错误被带入最终回答;
- 质量 Agent 漏诊 → 逻辑漏洞或片面观点被带入最终回答。
- 幻觉 Agent 漏诊 →
数值/事实错误被带入最终回答;
这为未来的改进指明了方向:要提升 MA-CF 的上限,重点在于增强中间诊断 Agent 在特定领域(如精准统计数据、复杂生物学)的核查敏感度。
对比实验
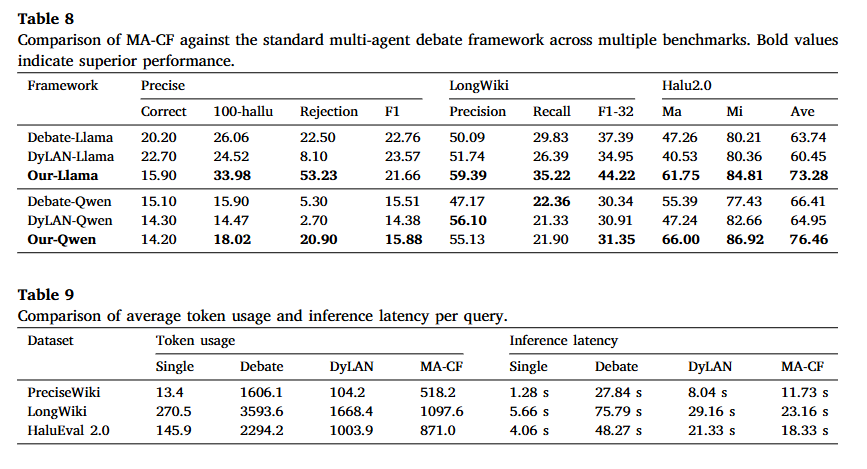
论文挑选了两种最具代表性的多智能体协作范式(均采用 Llama3.1-8B 和 Qwen3-8B 作为基座):
- 标准智能体辩论框架(Standard Agent Debate, SAD /
ChatEval):让多个 Agent
针对问题进行多轮顺序迭代辩论(Iterative Debate),直到达成共识。
- 动态大模型 Agent 网络(Dynamic LLM-Agent Network, DyLAN):配置了 3 个初始 Agent 和 2 层网络结构,通过分层剪枝与早期停止机制来筛选 Agent
工程启示
实际部署与计算效率(Efficiency and Deployment Considerations)
虽然 MA-CF 性能出众,但调用 4 个 Agent 无疑会增加计算开销。作者从工程落地角度提出了极具实用价值的部署策略:
- 成本与延迟权衡(Trade-off):
- 相比单模型:MA-CF
调用了多次模型,成本和延迟确实高于单次生成。
- 相比多轮辩论(Debate):由于采用了并行诊断(Parallelized
Critique),MA-CF 的 Token 消耗和推理延迟比多轮辩论框架降低了
50% 以上。
- 相比单模型:MA-CF
调用了多次模型,成本和延迟确实高于单次生成。
- 小模型集成的硬件门槛优势:
- 部署多个 8B 参数的小模型(如 Llama3.1-8B)所需的 GPU
显存和硬件基础设施开销,远低于运行单体 100B+ 或
671B(如 DeepSeek-V3)超大模型。
- 部署多个 8B 参数的小模型(如 Llama3.1-8B)所需的 GPU
显存和硬件基础设施开销,远低于运行单体 100B+ 或
671B(如 DeepSeek-V3)超大模型。
- 动态条件路由策略(Conditional Routing Strategy):
- 作者强调:没必要让每一个简单的提问都走一遍 MA-CF
管线!
- 工程建议:在入口处加入轻量级的“置信度评估器”或分类器。简单/低风险问题直接由基座单模型回答;只有遇到复杂、高风险或容易产生幻觉的问题,才路由到
MA-CF 多 Agent 管线中。
- 作者强调:没必要让每一个简单的提问都走一遍 MA-CF
管线!
- 模块化即插即用(Plug-and-Play Modularity):
- 框架具备极强的可拓展性。例如在医疗、法律、金融等专业领域,可以在不修改生成 Agent 和合成 Agent 的前提下,直接将幻觉分析 Agent(𝒜hallu)替换为领域专精微调模型或外挂 RAG 检索模块。