机设——初识RAG
前言
基于 LLM (Large Language Model)最火热的应用技术是什么,检索增强生成(RAG,Retrieval Augmented Generation)技术必占据重要的一席。RAG 最初是为了解决 LLM 的各类问题的产生的,但后面大家发现在现阶段的很多企业痛点上,使用RAG好像是更好的解决方案。
LLM的问题
尽管LLM拥有令人印象深刻的能力,但是它们还面临着一些问题和挑战:
幻觉问题:大模型的底层原理是基于概率,在没有答案的情况下经常会胡说八道,提供虚假信息。
时效性问题:规模越大(参数越多、tokens 越多),大模型训练的成本越高。类似 ChatGPT3.5,起初训练数据是截止到 2021 年的,对于之后的事情就不知道了。而且对于一些高时效性的事情,大模型更加无能为力,比如帮我看看今天晚上有什么电影值得去看?这种任务是需要去淘票票、猫眼等网站先去获取最新电影信息的,大模型本身无法完成这个任务。
数据安全:OpenAI 已经遭到过几次隐私数据的投诉,而对于企业来说,如果把自己的经营数据、合同文件等机密文件和数据上传到互联网上的大模型,那想想都可怕。既要保证安全,又要借助 AI 能力,那么最好的方式就是把数据全部放在本地,企业数据的业务计算全部在本地完成。而在线的大模型仅仅完成一个归纳的功能,甚至,LLM 都可以完全本地化部署。
解决这些挑战对于 LLMs 在各个领域的有效利用至关重要。一个有效的解决方案是集成检索增强生成(RAG)技术,该技术通过获取外部数据来响应查询来补充模型,从而确保更准确和最新的输出。主要表现方面如下:
有效避免幻觉问题:虽然无法 100% 解决大模型的幻觉问题,但通过 RAG 技术能够有效的降低幻觉,在软件系统中结合大模型提供幂等的API接口就可以发挥大模型的重要作用。
经济高效的处理知识&开箱即用:只需要借助信息检索和向量技术,将用户的问题和知识库进行相关性搜索结合,就能高效的提供大模型不知道的知识,同时具有权威性。
数据安全:企业的数据可以得到有效的保护,通过私有化部署基于 RAG 系统开发的AI产品,能够在体验AI带来的便利性的同时,又能避免企业隐私数据的泄漏。
什么是RAG
RAG 是检索增强生成(Retrieval Augmented Generation
)的简称,它为大语言模型 (LLMs)
提供了从数据源检索信息的能力,并以此为基础生成回答。简而言之,RAG
结合了信息检索技术和大语言模型的提示功能,即模型根据搜索算法找到的信息作为上下文来查询回答问题。无论是查询还是检索的上下文,都会被整合到发给大语言模型的提示中。
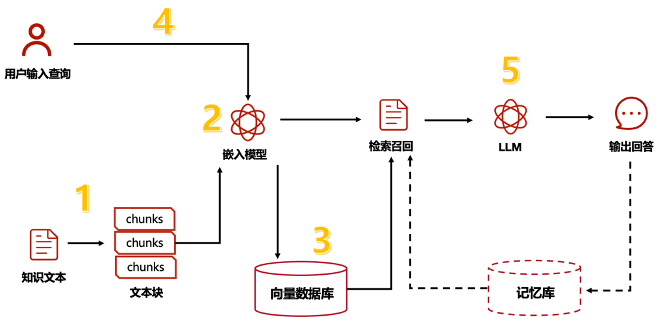
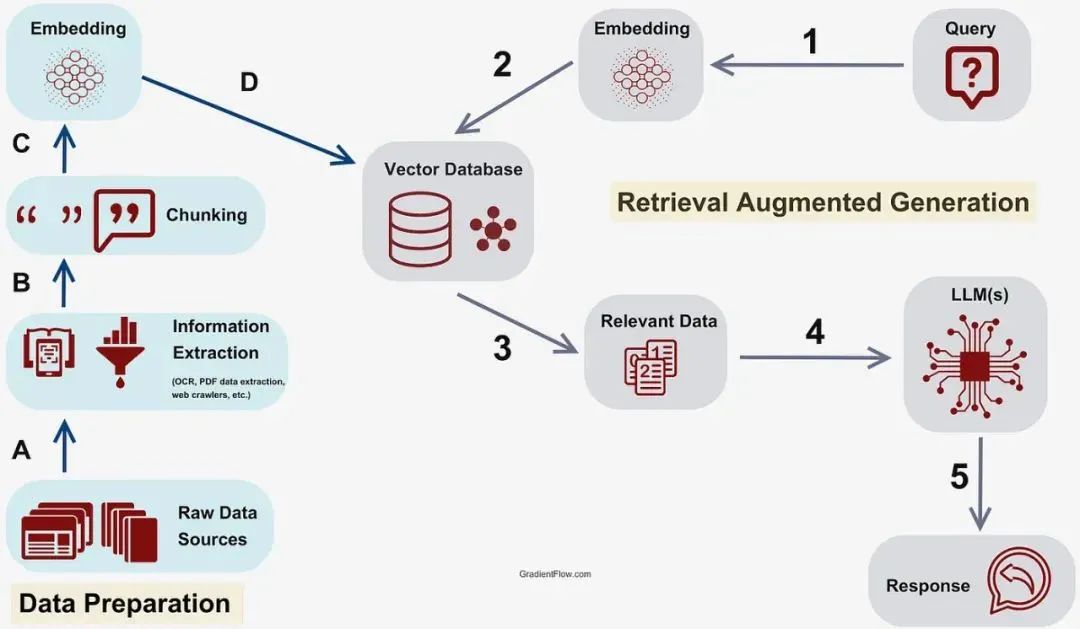
RAG 的架构如图中所示。它既不是一个特定的开源代码库,也不是某个特定的应用,是一个开发框架。
完整的 RAG 应用流程主要包含两个阶段:
数据准备阶段:(A)数据提取–> (B)分块(Chunking)–> (C)向量化(embedding)–> (D)数据入库
检索生成阶段:(1)问题向量化–> (2)根据问题查询匹配数据–> (3)获取索引数据 –> (4)将数据注入Prompt–> (5)LLM生成答案
向量数据库
GPT 的缺陷
GPT-3.5/4 带给我们无限震撼的同时,其天然的缺陷和诸多的限制也让开发者头痛不已,例如其输入端上下文(tokens)大小的限制困扰着很多的开发者和消费者,像 gpt-3.5-turbo 模型它的限制是 4K tokens(~3000字),这意味着使用者最多只能输入 3000 字给 GPT 来理解和推理答案。
向量数据库的崛起
在 GPT 模型的限制下,开发者们不得不寻找其他的解决方案,而向量数据库就是其中之一。向量数据库的核心思想是将文本转换成向量,然后将向量存储在数据库中,当用户输入问题时,将问题转换成向量,然后在数据库中搜索最相似的向量和上下文,最后将文本返回给用户。
当我们有一份文档需要 GPT 处理时,例如这份文档是客服培训资料或者操作手册,我们可以先将这份文档的所有内容转化成向量(这个过程称之为 Vector Embedding),然后当用户提出相关问题时,我们将用户的搜索内容转换成向量,然后在数据库中搜索最相似的向量,匹配最相似的几个上下文,最后将上下文返回给 GPT。这样不仅可以大大减少 GPT 的计算量,从而提高响应速度,更重要的是降低成本,并绕过 GPT 的 tokens 限制。
RAG的挑战
一个基本的 RAG 通常集成了一个向量数据库和一个 LLM,其中向量数据库存储并检索与用户查询相关的上下文信息,LLM 根据检索到的上下文生成答案。虽然这种方法在大部分情况下效果都很好,但在处理复杂任务时却面临一些挑战,如多跳推理(multi-hop reasoning)或联系不同信息片段全面回答问题。
以这个问题为例:“What name was given to the son of the man who defeated the usurper Allectus?”
一个基本的 RAG 通常会遵循以下步骤来回答这个问题:
- 识别那个人:确定谁打败了 Allectus。
- 研究那个人的儿子:查找有关这个人家庭的信息,特别是他的儿子。
- 找到名字:确定儿子的名字。
通常第一步就会面临挑战,因为基本的 RAG 根据语义相似性检索文本,而不是基于在数据集中没有明确提及具体细节来回答复杂的查询问题。这种局限性让我们很难找到所需的确切信息。解决方案通常是为常见查询手动创建问答对。但这种解决方案通常十分昂贵甚至不切实际。
为了应对这些挑战,微软研究院引入了 GraphRAG,这是一种全新方法,它通过知识图谱增强 RAG 的检索和生成。
GraphRAG的诞生
与使用向量数据库检索语义相似文本的基本 RAG 不同,GraphRAG 通过结合知识图谱(KGs)来增强 RAG。知识图谱是一种数据结构,它根据数据间的关系来存储和联系相关或不相关的数据。
GraphRAG 流程通常包括两个基本过程:索引和查询。
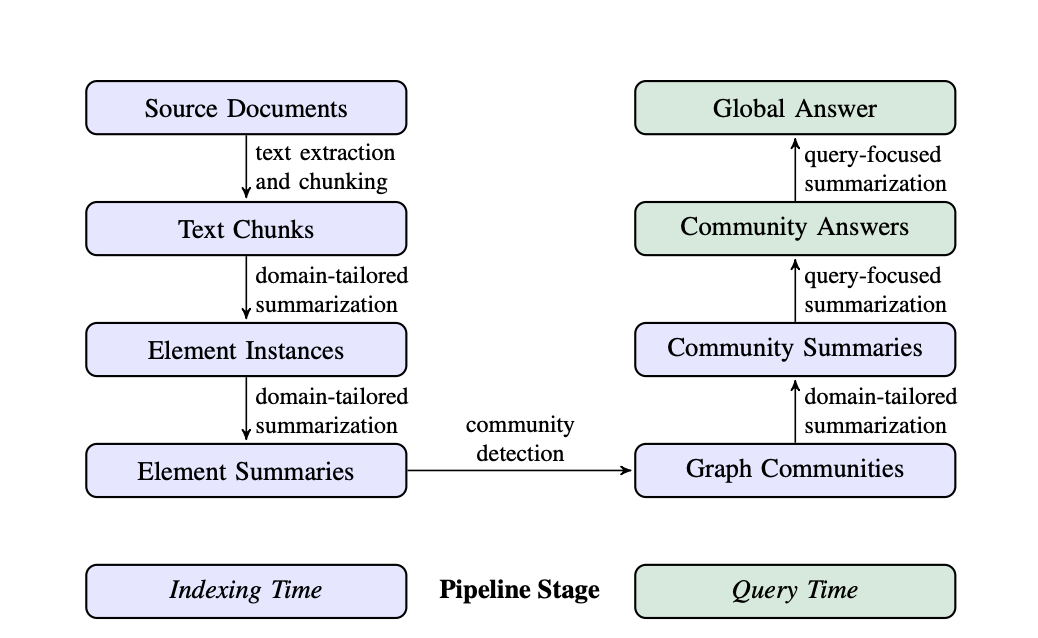
GraphRAG的优势
基础 RAG 和 GraphRAG 都被问到了同样的问题,这需要汇总整个数据集中的信息来构成答案。
问:What are the top 5 themes in the dataset?
下图为答案。基础 RAG 提供的结果与战争主题无关,因为向量搜索检索到了无关的文本,导致了答案的不准确。相比之下,GraphRAG 提供了一个清晰且高度相关的答案,识别了主要的主题和相关细节。结果与数据集一致,并引用了源材料。
上述例子展示了 GraphRAG 如何通过结合知识图谱和向量数据库,更有效地处理需要跨数据集整合信息的复杂查询,从而提高答案的相关性和准确性。

GraphRAG 在多跳推理和复杂信息总结方面性能明显更佳。研究表明GraphRAG 在全面性和多样性方面都超过了基础 RAG:
- 全面性:答案覆盖问题的所有方面。
- 多样性:答案提供的观点和见解具有多样性和丰富性。
参考文献
大模型RAG入门及实践(非常详细)零基础入门到精通,收藏这一篇就够了-CSDN博客
向量数据库|一文全面了解向量数据库的基本概念、原理、算法、选型-腾讯云开发者社区-腾讯云
GraphRAG 详解: 通过知识图谱提升 RAG 系统 - Zilliz 向量数据库
论文: https://arxiv.org/pdf/2404.16130
GraphRAG:知识图谱+RAG、更高质量的检索_哔哩哔哩_bilibili
微软开源的GraphRAG代码: https://github.com/microsoft/graphrag