机设——LightRAG与GraphRAG
GraphRAG
最新消息是11.26凌晨,微软宣布将推出 GraphRAG 的全新迭代版本LazyGraphRAG 核心亮点是极低的使用成本,其数据索引成本仅为现有GraphRAG 的 0.1%。此外,LazyGraphRAG 引入了全新的混合数据检索方法,大幅提升了生成结果的准确性和效率。该版本将很快开源,并纳入到 GitHub GraphRAG 库中 原文链接如下:https://www.microsoft.com/en-us/research/blog/lazygraphrag-setting-a-new-standard-for-quality-and-cost/
支持的检索方式
Naive Search Naive 模式是最简单的检索策略,它直接基于输入查询计算向量相似度,返回最接近的结果,不进行任何额外的优化或复杂处理 Local Search Local 模式只在本地上下文范围内进行检索。它聚焦于用户当前输入的特定领域或某部分数据,不会考虑全局数据 Global Search Global 模式会在整个知识库范围内进行检索,试图找到与查询最相关的信息,而不局限于当前上下文或局部区域 Hybrid Search Hybrid 模式结合了 Local 和 Global 的优势,同时考虑局部上下文和全局信息,综合结果以提高答案的相关性和覆盖范围
Anaconda
Anaconda,中文大蟒蛇,是一个开源的Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等190多个科学包及其依赖项。
Anaconda就是可以便捷获取包且对包能够进行管理,包括了python和很多常见的软件库和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易,同时对环境可以统一管理的发行版本
为什么要安装Anaconda?
Anaconda对于python初学者而言及其友好,相比单独安装python主程序,选择Anaconda可以帮助省去很多麻烦,Anaconda里添加了许多常用的功能包,如果单独安装python,这些功能包则需要一条一条自行安装,在Anaconda中则不需要考虑这些,同时Anaconda还附带捆绑了两个非常好用的交互式代码编辑器(Spyder、Jupyter notebook)。
简单来说,Anconda,可以理解成运输车,每当下载Anconda的时候,里面不仅包含了python,还有180多个库(武器)一同被打包下载下来。
下载完Anconda之后,再也不用一个个下载那些库了。
集成开发环境搭建Anaconda+PyCharm
【大模型应用开发基础】集成开发环境搭建Anaconda+PyCharm_哔哩哔哩_bilibili
LightRAG与GraphRAG运行对比
NanGePlus/LightRAGTest: LightRAG与GraphRAG在索引构建、检索测试中的耗时、模型请求次数、Token消耗金额、检索质量等方面进行对比
命令行终端中执行如下命令安装依赖包 cd LightRAG pip install -e . cd GraphRAG pip install graphrag==0.5.0
测试文本 测试文本均为使用西游记白话文前九回内容,文件名为book.txt 模型配置 大模型使用OpenAI(代理方案),Chat模型均使用gpt-4o-mini,Embedding模型均使用text-embedding-3-small 其他配置 笔记本均为MacBook Pro2017,网速、python环境均相同
LightRAG测试
(1)构建索引
打开命令行终端,执行如下指令 cd LightRAG/nangeAGICode python test.py 注意 在运行脚本之前,需要调整相关代码将如下代码块打开,检索相关的代码块注释
(2)逐一测试
执行如下指令 cd LightRAG/nangeAGICode python test.py 注意 在运行脚本之前,需要注释如下构建索引代码,取消检索相关的代码块注释
GraphRAG测试
(1)构建索引
打开命令行终端,执行如下指令 cd GraphRAG graphrag index –root ./
(2)逐一测试
graphrag query –root ./ –method local –query “这个故事的核心主题是什么?” graphrag query –root ./ –method global –query “这个故事的核心主题是什么?” graphrag query –root ./ –method drift –query “这个故事的核心主题是什么?”

利用neo4j可视化
测试文本 测试文本均为使用西游记白话文前九回内容 模型配置 大模型均使用OpenAI(代理方案),Chat模型均使用gpt-4o,Embedding模型均使用text-embedding-3-small 其他配置 笔记本均为MacBook Pro2017,网速、python环境均相同
1 | # gpt大模型相关配置根据自己的实际情况进行调整 |
LightRAG构建索引测试
(1)安装textract依赖包
通过指令 pip install textract 安装时会报错,报错的原因是 其元数据文件中使用了不再被支持的版本约束符号(<=0.29.*),而当前 pip 和 setuptools 不再接受这种格式 解决方案:下载依赖包源码,修改相应参数后本地进行安装 https://pypi.org/project/textract/1.6.5/#description cd textract-1.6.5 pip install .
(2) 创建neo4j数据库实例
推荐使用云服务进行测试,链接地址如下: https://console-preview.neo4j.io/tools/query 注册登录成功,直接新建实例即可
也可以用本地neo4j
1 | # 数据库连接相关参数配置 |
(3)增量索引构建及知识图谱可视化测试
运行如下指令进行索引构建 cd LightRAG/nangeAGICode1201 python insertTest.py python queryTest.py 每一次构建完成,先清除数据库中的数据再运行如下指令进行可视化 在运行之前需要根据自己的实际情况进行参数的调整 python graph_visual_with_html.py
python graph_visual_with_neo4j.py
在数据库中进行查询测试 MATCH (n:PERSON)
WHERE n.displayName CONTAINS ‘唐僧’ RETURN n LIMIT 25;
MATCH (n:PERSON) WHERE n.displayName CONTAINS ‘八戒’
RETURN n LIMIT 25;
MATCH (n:PERSON) WHERE n.displayName CONTAINS ‘沙和尚’
RETURN n LIMIT 25;
清除数据 MATCH (n) CALL { WITH n DETACH DELETE n } IN TRANSACTIONS OF 25000 ROWS;
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r
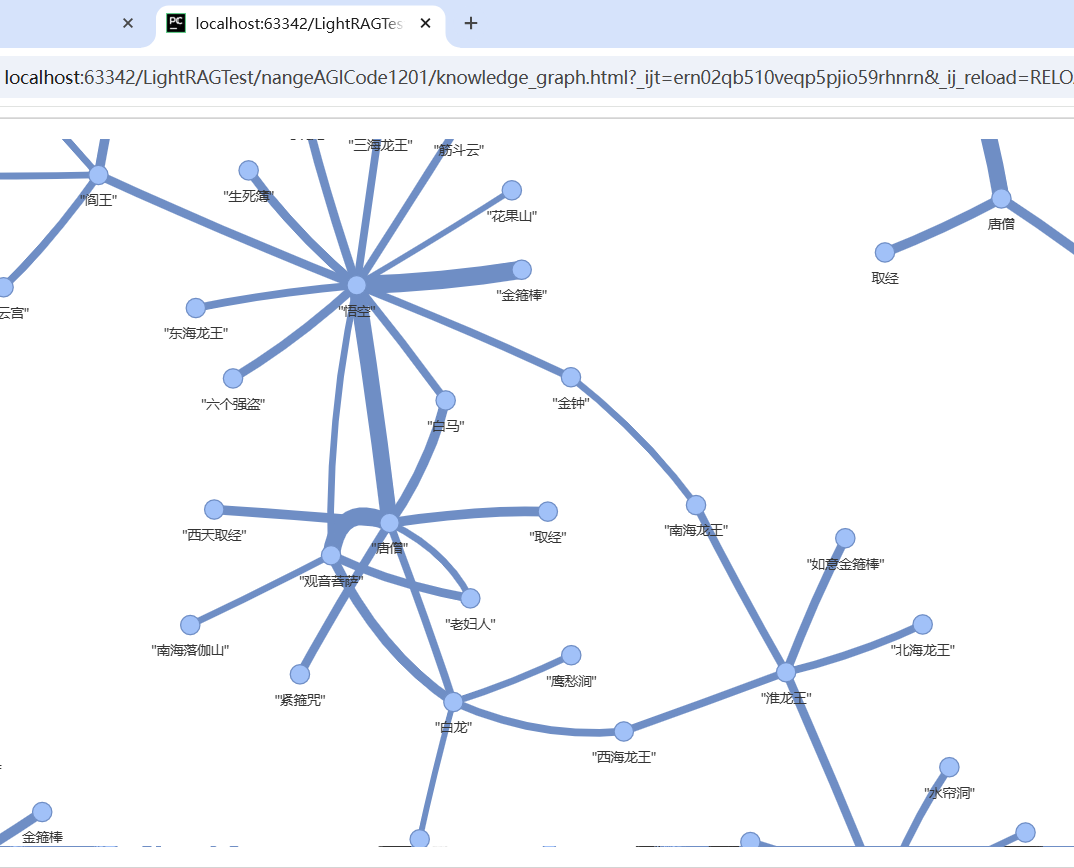
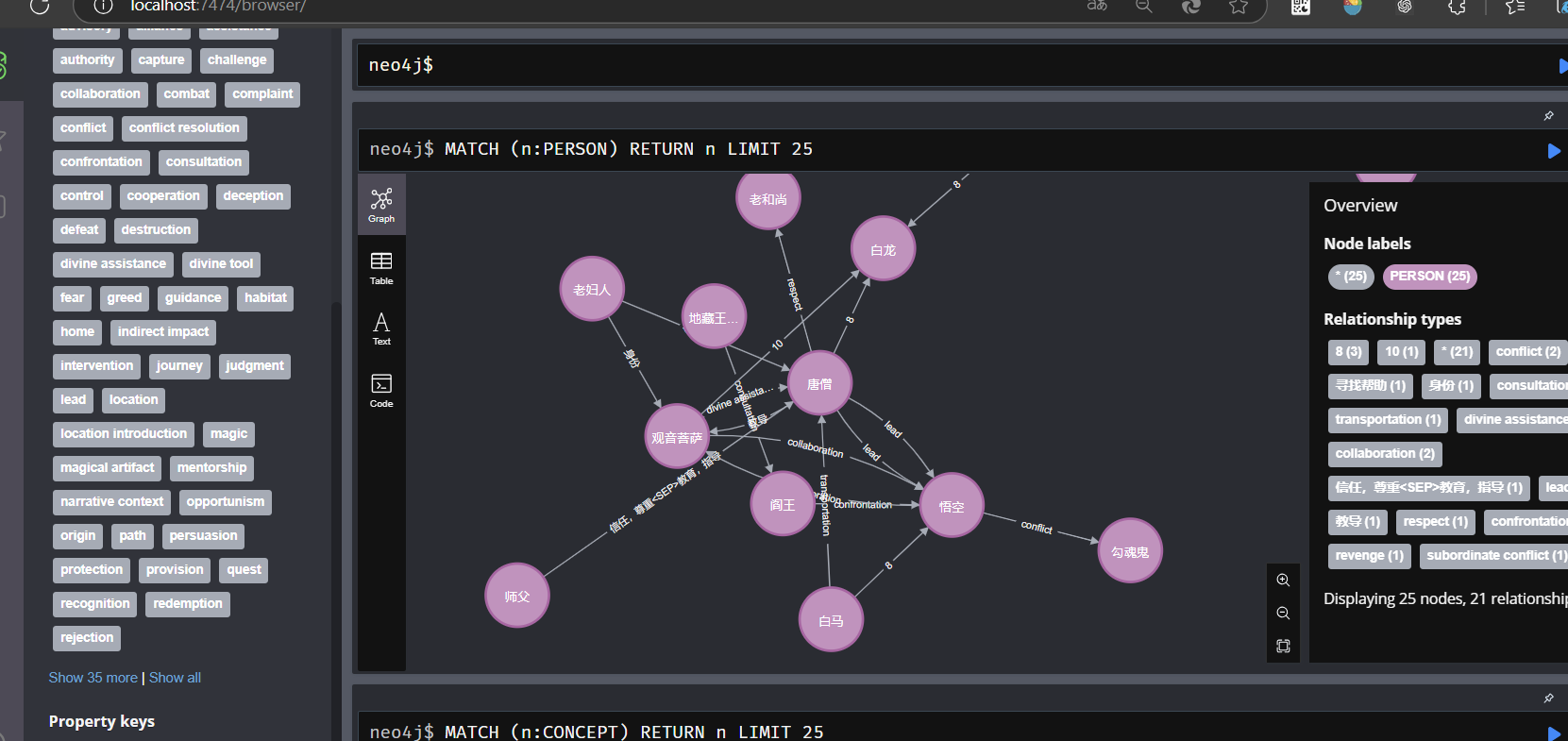
LightRAG和GraphRAG生成的知识图谱对比
运行如下指令将GraphRAG生成的知识图谱进行可视化展示 cd GraphRAG/utils
python graph_visual_with_neo4j.py
在运行脚本前根据自己的实际情况进行调整,修改文件所在路径为存储增量数据的文件路径
GRAPHRAG_FOLDER=“/Users/janetjiang/Desktop/agi_code/LightRAGTest/GraphRAG/output”
在数据库中进行查询测试 MATCH
(n:__Entity__) WHERE n.name CONTAINS ‘唐僧’ RETURN n LIMIT
25;
MATCH (n:__Entity__) WHERE n.name CONTAINS ‘八戒’ RETURN
n LIMIT 25;
MATCH (n:__Entity__) WHERE n.name CONTAINS ‘沙和尚’
RETURN n LIMIT 25;
清除数据 MATCH (n) CALL { WITH n DETACH DELETE n } IN TRANSACTIONS OF 25000 ROWS;
参考文献
LightRAG与GraphRAG对比评测,从索引构建、本地检索、全局检索、混合检索等维度对请求大模型次数、Token消耗、金额消耗、检索质量等方面进行全面对比_哔哩哔哩_bilibili