数据结构——课设
题目
- 编程实现希尔、快速、堆排序、归并排序算法。要求随机产生10000个数据存入磁盘文件,然后读入数据文件,分别采用不同的排序方法进行排序,并将结果存入文件中。
- N(N>10)个居民区之间需要铺设煤气管道。假设任意两个居民区之间都可以铺设煤气管道,但代价不同。要求事先将任意两个居民区之间铺设煤气管道的代价存入磁盘文件中。设计一个最佳方案使得这N个居民区之间铺设煤气管道所需代价最小,并将结果以图形方式在屏幕上输出。
题目一
算法思想
希尔排序:希尔排序是一种基于插入排序的排序算法,通过按一定步长将待排序的元素分组,对每组内的元素进行插入排序,不断缩小步长,最终实现整体排序。希尔排序的时间复杂度依赖于步长的选择,最坏情况下时间复杂度为O(n^2),最好的情况下接近O(nlogn)。
快速排序:快速排序是一种分治法思想的排序算法,选择一个基准元素,将待排序的数组分为左右两部分,左侧部分的元素都小于基准元素,右侧部分的元素都大于基准元素,然后分别对左右两部分进行递归排序。时间复杂度为O(nlogn),最坏情况下为O(n^2)。
堆排序:堆排序是一种选择排序的改进算法,利用堆数据结构(通常是大顶堆或小顶堆)来找到最大值或最小值,并将其移到数组的末尾,然后调整堆。时间复杂度为O(nlogn),适合大数据量排序。
归并排序:归并排序是一种分治法的排序算法,它将待排序的数组分为两部分,分别排序后再合并。时间复杂度为O(nlogn),且具有稳定性。
程序结构
数据生成:程序首先生成10000个随机数并将其存储到文件
data.txt中。排序算法实现:实现了四种排序算法:希尔排序、快速排序、堆排序和归并排序。
文件操作:程序从文件中读取数据,然后使用不同的排序算法对数据进行排序,并将排序结果保存到文件中。
测试结果
程序组成
生成数据
排序结果
收获与体会
- 实践了不同排序算法的实现,加深了对算法效率和适用场景的理解。
- 学会了如何操作文件进行数据存储和读取,增强了文件输入输出的处理能力。
题目二
算法思想描述
本题使用了Kruskal算法来求解最小生成树。Kruskal算法是一种典型的贪心算法,步骤如下:
- 先将所有的边按照权重排序。
- 从最小的边开始,逐步加入到生成树中,若加入该边不会形成环,就加入生成树,否则跳过该边。
- 使用并查集(Union-Find)数据结构来判定是否会形成环。
该算法通过选择最小权重的边逐步构建最小生成树,保证了铺设煤气管道的总代价最小。
程序结构
- 文件读取:程序读取包含代价矩阵和节点坐标的文件
costs.txt,并根据这些信息构建图。 - 并查集实现:实现了一个并查集数据结构来判断是否形成环。
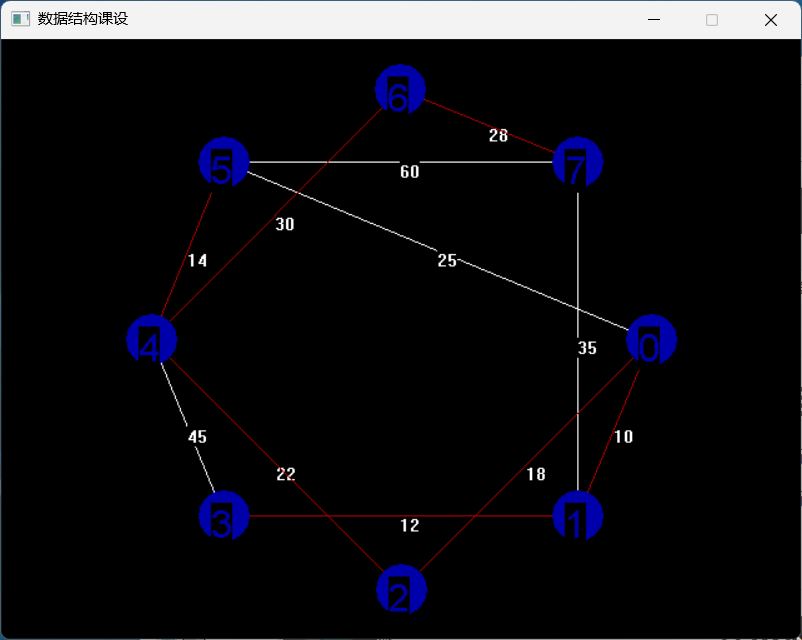
- 图形显示:利用图形库绘制了居民区的分布、各居民区之间的煤气管道代价以及最终的最小生成树。
测试结果
通过程序实现,成功展示了根据最小生成树算法铺设的煤气管道图形,并显示了连接每个居民区的最小代价路径。图形显示了所有居民区和最小生成树路径的直观效果,确保了程序的正确性和可视化。
收获与体会
- 通过实现Kruskal算法,深入理解了最小生成树问题以及并查集的使用。
- 掌握了如何通过图形库展示算法结果,增加了对图论问题的兴趣。
- 通过实践提高了编程技巧,特别是在图形和图论方面的应用。