MinerU
docker部署
使用dockerfile构建镜像:
1 | wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/docker/china/Dockerfile |
使用wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU @master/docker/china/Dockerfile -O Dockerfile将指定的
Dockerfile 下载到本地
Dockerfile:
1 | # 使用官方的 sglang 镜像作为基础镜像 |
SGLang(全称可能为 Serving Large Language Models with Golang )是由斯坦福大学研究团队开发的一个高效的大语言模型(LLM)推理服务框架 ,旨在通过优化模型推理过程,显著提升生成式AI服务的吞吐量和响应速度。
- SGlang 版本 :
v0.4.8.post1(SGlang 是一个用于大语言模型(LLM)推理和服务的高性能框架)。- CUDA 版本 :
cu126表示使用 CUDA 12.6 ,适用于 Turing/Ampere/Ada Lovelace/Hopper 架构的 GPU (如 RTX 30/40 系列、A100、H100)。
报错排查
之前由于默认dockerfile内容为FROM lmsysorg/sglang:v0.4.8.post1-cu126报错
1 | lmsysorg/sglang:v0.4.8.post1-cu126: failed to resolve source metadata for docker.io/lmsysorg/sglang:v0.4.8.post1-cu126: unexpected status from HEAD request to https://yaj2teeh.mirror.aliyuncs.com/v2/lmsysorg/sglang/manifests/v0.4.8.post1-cu126?ns=docker.io: 403 Forbidden |
之前以为是sglang版本问题,然后去dockerhub上查找,并通过docker pull sglang:v0.4.8.post1-cu126测试,是可以拉取的,最后认为原因还是网络问题
解决方法,更换了镜像源
镜像源配置
1 | "registry-mirrors": [ |
保姆级Docker安装+镜像加速 计算机系必备技能_哔哩哔哩_bilibili
为什么要指定基础镜像
- 提供操作系统和依赖 基础镜像包含操作系统(如
Ubuntu、Alpine)、运行时环境(如 Python、Node.js)或框架(如
TensorFlow、PyTorch)等核心组件,后续所有操作(如安装依赖、拷贝文件)都基于此环境。
- 例如:
FROM python:3.9提供了 Python 3.9 的运行环境,后续可以直接用pip install安装 Python 包。
- 例如:
- 避免重复造轮子
如果直接从空镜像(
scratch)开始,需要手动安装所有依赖,效率低下且容易出错。使用现有基础镜像可以复用已验证的环境配置。
确认支持的cuda版本
命令nvidia-smi
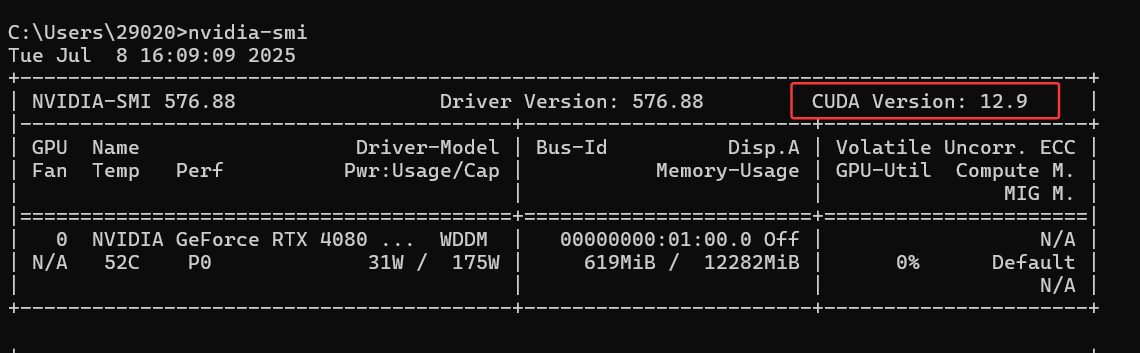
CUDA Version 显示当前驱动支持的最高 CUDA 版本
问题:使用dockerfile直接部署,始终出现网络问题
解决方案
先修改了一下docker储存镜像的位置,太大了
先拉取基础镜像docker pull lmsysorg/sglang:v0.4.8.post1-cu126
再使用docker build -t mineru-sglang:latest -f Dockerfile .,可以直接跳过基础镜像的拉取
启动
官方启动命令
1 | docker run -d \ |
1 | docker run -d --name sglang-server --gpus all --shm-size 32g -p 30000:30000 --ipc=host mineru-sglang:latest mineru-sglang-server --host 0.0.0.0 --port 30000 |
将mineru-sglang-server暴露到30000端口的作用
为了支持 vlm-sglang-client 后端模式,使得MinerU客户端可以通过网络连接到这个服务器,实现多个客户端可以同时连接到同一个服务器
使用docker exec -it sglang-server bash命令进入容器
或
使用docker desk
1 | docker run -d --name mineru-server --gpus all --shm-size 32g -p 30000:30000 -p 7860:7860 -p 8000:8000 --ipc=host \ |
使用挂载卷启动
- 将本地的PDF文件目录挂载到容器内的 /pdfs 目录
- 将本地的输出目录挂载到容器内的 /output 目录
- 把8000,和7860端口暴露,方便调用fastapi与gradio webui 可视化


调用
命令行调用sglang-server/client 模式
docker exec mineru-server mineru -p /pdfs/demo1.pdf -o /output -b vlm-sglang-client -u http://localhost:30000
这条命令在名为 mineru-server 的容器内执行 mineru 工具,处理 /pdfs 目录下的 demo1.pdf 文件,输出结果到 /output 目录,使用 vlm-sglang-client 后端,并连接到 http://localhost:30000 的SGLang服务器。
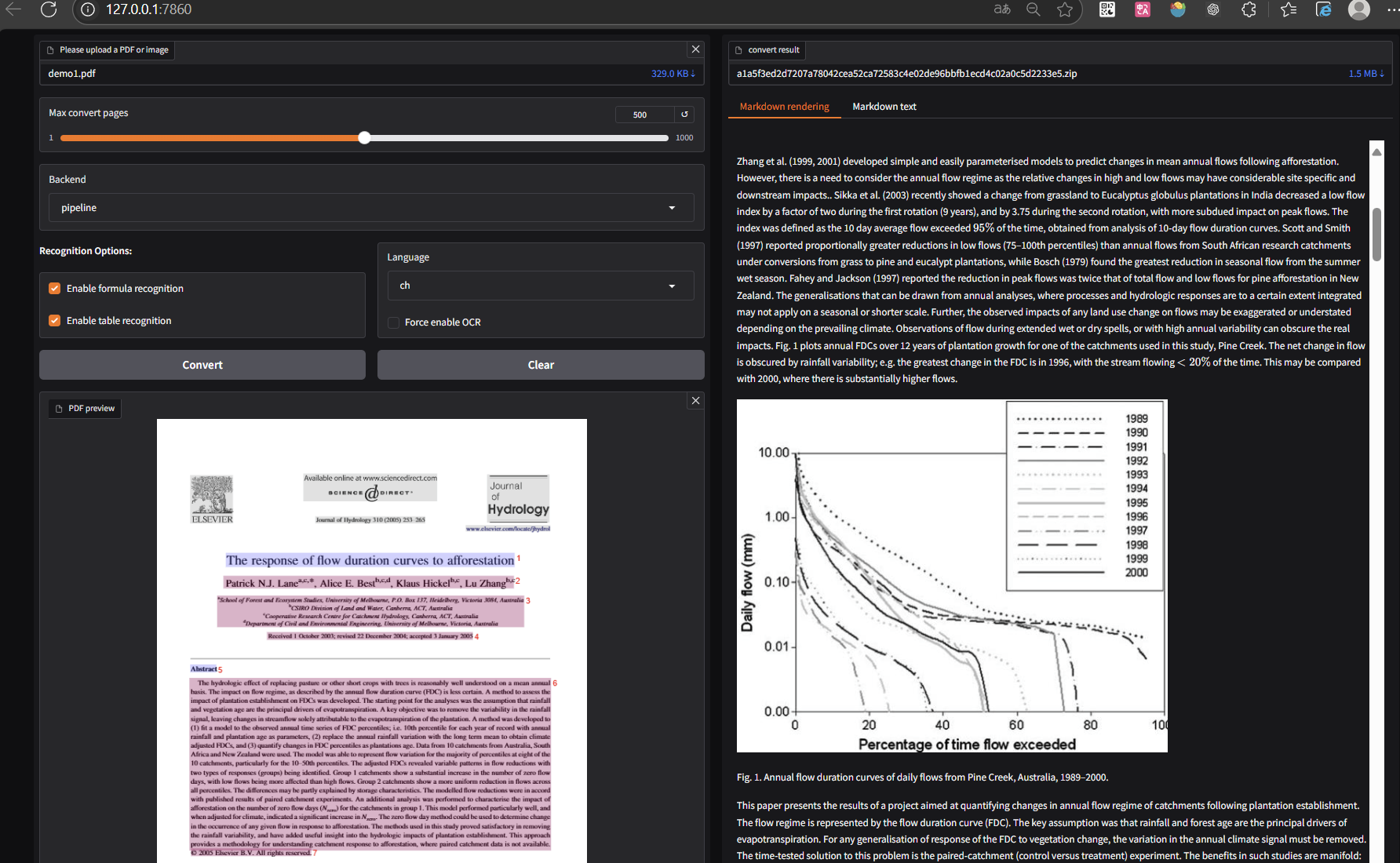
fastapi调用与gradio webui 可视化
在完成docker的端口映射之后,运行mineru-api --host 0.0.0.0 --port 8080启动fastapi服务,
FastAPI服务的使用场景
FastAPI服务提供了一个
/file_parse端点,用于处理PDF和图像文件的解析请求微服务架构部署,FastAPI服务可以独立部署
服务提供了标准的HTTP API接口,允许客户端通过网络请求进行文档解析
运行mineru-gradio --server-name 0.0.0.0 --server-port 7860启动gradio
webui服务
或mineru-gradio --server-name 0.0.0.0 --server-port 7860 --enable-sglang-engine true
注意,模型下载需要配置环境变量
2
3
4
export MINERU_MODEL_SOURCE=local
# 验证环境变量是否设置成功
echo $MINERU_MODEL_SOURCE
在调用过程中关于端口的问题与思考
调用过程中发现,在容器中使用mineru-api --host 127.0.0.1 --port 8000,宿主机无法访问http://127.0.0.1:8000/docs/,经过查询ai,命令改为mineru-api --host 0.0.0.0 --port 8000就可以正常访问,那么关键在于对这两个地址的理解
查看端口
netstat -ano | findstr LISTENING
127.0.0.1与0.0.0.0
- 127.0.0.1 (localhost) :仅表示本机回环地址,只能在 同一设备内 访问
- 0.0.0.0 :表示监听所有可用的网络接口,允许 来自任何地址 的连接
当您在Docker容器内运行服务时:
使用127.0.0.1作为绑定地址 :
- 服务只接受来自容器内部的连接
- 即使您映射了端口,宿主机也无法访问该服务
- 只有容器内的应用程序可以通过 127.0.0.1:端口 访问
使用0.0.0.0作为绑定地址 :
- 服务接受来自任何网络接口的连接请求
- 允许从容器外部(包括宿主机)访问该服务
- 当您映射端口时(如 -p 8000:8000 ),宿主机可以通过 localhost:8000 或 127.0.0.1:8000 访问
为什么需要在容器内使用0.0.0.0
在Docker环境中,容器有自己独立的网络命名空间,这意味着容器内的 127.0.0.1 与宿主机的 127.0.0.1 是完全不同的两个环境。因此:
- 当您在容器内使用 –host 0.0.0.0 启动服务时,该服务会监听容器的所有网络接口
- 当您在宿主机上访问 127.0.0.1:映射端口 时,Docker会将请求转发到容器内监听在 0.0.0.0:容器端口 的服务
mineru相关知识
参数
1 | Usage: mineru [OPTIONS] |
后端的区别
pipeline (默认后端) :
- 含义 : 这是 MinerU 的默认后端,它使用本地安装的 mineru 库来执行文档解析任务。它通常不依赖于外部的 VLM(视觉语言模型)服务,而是直接在本地处理 PDF 文件。

vlm-transformers :
- 含义 : 这个后端利用 Hugging Face transformers 库中提供的 VLM 模型进行文档分析。它会在本地加载并运行一个基于 transformers 的 VLM 模型来处理 PDF 中的视觉信息和文本内容。
VLM(Vision-Language Model,视觉语言模型)是一种结合计算机视觉和自然语言处理能力的多模态人工智能模型。
OCR 是 Optical Character Recognition(光学字符识别)的缩写。它是一种技术,用于将图像中的手写、打印或打字文本转换为机器编码的文本,使其可以被计算机编辑、搜索、存储和处理。
vlm-sglang-engine :
- 含义 : 这个后端表示 MinerU 将直接集成并使用 SGLang 引擎进行 VLM 推理。SGLang 是一个高性能的推理引擎,旨在优化大型语言模型(LLM)和 VLM 的推理速度和效率。在这种模式下,SGLang 引擎作为 MinerU 进程的一部分运行。
vlm-sglang-client :
- 含义 : 这个后端表示 MinerU 作为 SGLang 服务器的客户端。在这种模式下,MinerU 不会直接运行 VLM 模型,而是将 PDF 处理请求发送到一个独立的 SGLang 服务器(通过 -u 参数指定的 URL,例如 http://localhost:30000 )。SGLang 服务器负责执行实际的 VLM 推理,并将结果返回给 MinerU 客户端。
用场景 : 这是我们之前讨论的 Docker 容器部署场景中推荐的模式。它非常适合以下情况: - 资源隔离 : 将 VLM 推理的计算密集型任务从 MinerU 主进程中分离出来,允许独立扩展和管理 SGLang 服务器。 - 集中管理 : 可以在一个或多个 SGLang 服务器上集中管理 VLM 模型,供多个 MinerU 客户端共享使用。 - 性能优化 : SGLang 服务器可以针对 VLM 推理进行专门优化,提供更好的吞吐量和延迟。 - 灵活部署 : SGLang 服务器可以部署在不同的机器上,甚至作为微服务运行,提供更大的部署灵活性。
关于吞吐量的相关知识
“吞吐量”(throughput)*指的是系统在单位时间内能处理的 **Token 数量**,单位通常是 **tokens/秒**。这个指标衡量的是整体系统*处理并发请求的能力,而不仅仅是单个请求的速度。
SGLang 支持两种主要并行方式来提升吞吐量:
| 并行类型 | 作用 | 对吞吐量的影响 |
|---|---|---|
| 张量并行(TP) | 把模型权重切分到多张卡上,减少单卡负载 | 提升单请求处理能力,但通信开销大 |
| 数据并行(DP) | 把不同请求分发到不同卡上,并行处理多个请求 | 直接提升并发吞吐量,尤其适合高并发场景 |
mineru的并发测试和吞吐量测试
并发能力是测试mineru同时处理多个请求的能力,吞吐量是测试mineru处理文件时的tokens
明确要的是哪个吞吐量:一个是MinerU 内部推理引擎(如
vLLM/SGLang)的 token/s 输出,即
生成阶段(decode)的吞吐量,一个是你压测
/file_parse 接口时的 端到端 tokens/s。
是否有缓存(kvcache)
测试场景:10页的pdf,50用户并发
工具:locust
1 | locust \ |
1 | locust -f locustfile.py --headless -u 100 -r 5 --host=http://mineru-server:30000 --html=report.html --csv=result |
测试结果

对于推理模型的吞吐量,在3个gpu开启数据并行的情况下,平均每秒单个gpu处理tokens为1500左右
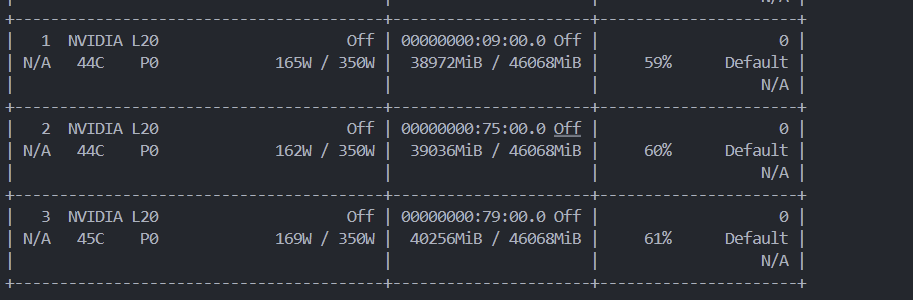
gpu状态如上:显存几乎打满 85–87 %,GPU 利用率 59–63 %,功耗 170–188 W / 350 W

完整压测结果如上
重要指标:
| 指标 | 数值 | 通俗解释 |
|---|---|---|
| 平均响应时间 | 241 秒 ≈ 4 分钟 | 上传一个 PDF → 拿到解析结果,平均要等 4 分钟。 |
| 中位数 | 215 秒 ≈ 3.6 分钟 | 一半请求在 3.6 分钟内完成。 |
| 95% 用户 | 361 秒 ≈ 6 分钟 | 最慢的 5% 要等 6 分钟以上。 |
| 吞吐量 | 0.18 req/s | 这台 MinerU 每分钟只能处理约11 个 PDF。 |
参考资料
部署服务器并运行
load镜像
1 | docker load -i mineru-sglang-latest.tar |
1 | free -h |
每秒刷新watch -n1 nvidia-smi # 每秒刷新
查看Linux路径
1 | pwd |
启动容器
1 | docker run -d --name mineru-server --gpus all --shm-size 32g -p 30000:30000 -p 7860:7860 -p 8000:8000 --ipc=host \ |
1 | docker run -d --name mineru-server --gpus all --shm-size 32g -p 30000:30000 --ipc=host -v "/aisys/repo_dev/xizhang/pdfs:/pdfs" -v "/aisys/repo_dev/xizhang/outputs:/output" mineru-sglang:latest mineru-sglang-server --host 0.0.0.0 --port 30000 |
调用
1 | docker exec mineru-server mineru -p /pdfs/demo1.pdf -o /output -b vlm-sglang-client -u http://localhost:30000` |
进入容器
1 | docker exec -it mineru-server /bin/bash |
使用pipline解析后端模式
1 | mineru -p /pdfs/demo1.pdf -o /output --source local |
使用sglang加速推理
1 | CUDA_VISIBLE_DEVICES=1,2,3 mineru -p /pdfs/small_ocr.pdf -o /output -b vlm-sglang-engine --source local |
vlm模式同样可以处理扫描件
使用ocr解析扫描件
1 | mineru -p /pdfs/small_ocr.pdf -o /output --source local -m ocr |
增加推理设备
1 | mineru -p /pdfs/small_ocr.pdf -o /output --source local -m ocr -d cuda |
通过在命令行的开头添加CUDA_VISIBLE_DEVICES
环境变量来指定可见的 GPU 设备。
1 | CUDA_VISIBLE_DEVICES=1,2,3 mineru -p /pdfs/small_ocr.pdf -o /output --source local -m ocr |
使用sglang加速模式的多GPU并行
数据并行(dp-size)和张量并行(tp-size)
MinerU支持通过sglang的多GPU并行模式来提升推理速度。您可以使用以下参数:
--dp-size: 数据并行,通过多卡同时处理多个输入来增加吞吐量--tp-size: 张量并行,将模型分布到多张GPU上以扩展可用显存
如果您已经可以正常使用sglang对vlm模型进行加速推理,但仍然希望进一步提升推理速度,可以尝试以下参数:
- 如果您有超过多张显卡,可以使用sglang的多卡并行模式来增加吞吐量:
--dp-size 2- 同时您可以启用
torch.compile来将推理速度加速约15%:--enable-torch-compile
1 | CUDA_VISIBLE_DEVICES=1,2,3 mineru -p /pdfs -o /output -b vlm-sglang-engine --source local --dp-size 3 --enable-torch-compile |
将python文件上传docker并运行
1 | docker cp demo.py mineru-server:/demo.py |
添加自定义网络,修改挂载卷
1 | docker run -d --name mineru-server --gpus all --shm-size 32g -p 30000:30000 --ipc=host -v /aisys/:/aisys/ --network network_test mineru-sglang:latest mineru-sglang-server --host 0.0.0.0 --port 30000 |
后面才知道,上面这个命令会自动启动sglang-server服务
1 | docker run -d --name mineru-server --gpus all --shm-size 32g -p 30000:30000 --ipc=host -v /aisys/:/aisys/ --network network_test mineru-sglang:latest tail -f /dev/null |
使用上面这个命令启动容器,但不启动sglang-server服务,使用下面指令手动启动
1 | docker exec -it mineru-server /bin/bash |
启动服务后在另一个容器尝试访问
1 | curl http://mineru-server:30000/get_model_info |
在另一个容器使用服务
1 | mineru -p /test -o / -b vlm-sglang-client -u http://mineru-server:30000 |
启动fastapi服务
1 | MINERU_MODEL_SOURCE=local CUDA_VISIBLE_DEVICES=1,2,3 mineru-api --host 0.0.0.0 --port 30000 --dp-size 3 --enable-torch-compile |
在另一个容器验证
1 | curl http://mineru-server:30000/openapi.json |
1 | # 在容器内设置环境变量 |
资料
https://github.com/opendatalab/MinerU?tab=readme-ov-file#local-deployment
https://deepwiki.com/opendatalab/MinerU