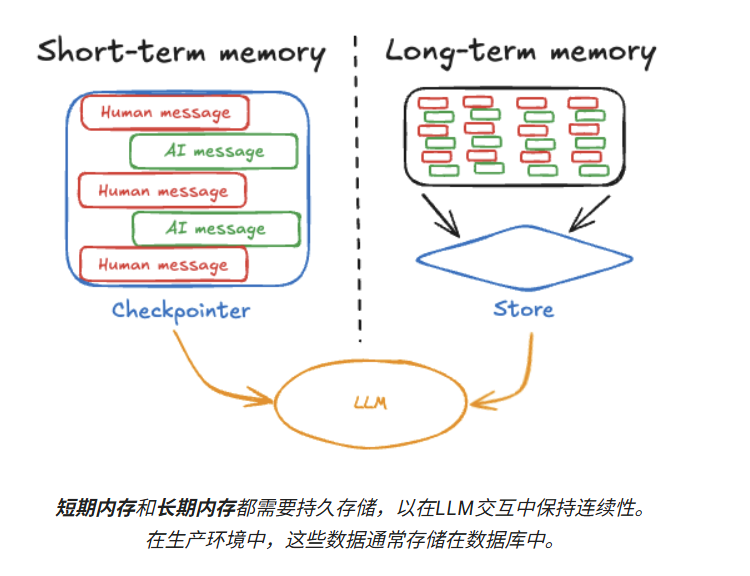
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
@app.post("/v1/chat/completions")
async def chat_completions(request: ChatCompletionRequest):
if not graph:
logger.error("服务未初始化")
raise HTTPException(status_code=500, detail="服务未初始化")
try:
logger.info(f"收到聊天完成请求: {request}")
query_prompt = request.messages[-1].content
logger.info(f"用户问题是: {query_prompt}")
config = {"configurable": {"thread_id": request.userId+"@@"+request.conversationId}}
logger.info(f"用户当前会话信息: {config}")
prompt_template_system = PromptTemplate.from_file(PROMPT_TEMPLATE_TXT_SYS)
prompt_template_user = PromptTemplate.from_file(PROMPT_TEMPLATE_TXT_USER)
prompt = [
{"role": "system", "content": prompt_template_system.template},
{"role": "user", "content": prompt_template_user.template.format(query=query_prompt)}
]
if request.stream:
async def generate_stream():
chunk_id = f"chatcmpl-{uuid.uuid4().hex}"
async for message_chunk, metadata in graph.astream({"messages": prompt}, config, stream_mode="messages"):
chunk = message_chunk.content
logger.info(f"chunk: {chunk}")
yield f"data: {json.dumps({'id': chunk_id,'object': 'chat.completion.chunk','created': int(time.time()),'choices': [{'index': 0,'delta': {'content': chunk},'finish_reason': None}]})}\n\n"
yield f"data: {json.dumps({'id': chunk_id,'object': 'chat.completion.chunk','created': int(time.time()),'choices': [{'index': 0,'delta': {},'finish_reason': 'stop'}]})}\n\n"
return StreamingResponse(generate_stream(), media_type="text/event-stream")
else:
try:
events = graph.stream({"messages": prompt}, config)
for event in events:
for value in event.values():
result = value["messages"][-1].content
except Exception as e:
logger.info(f"Error processing response: {str(e)}")
formatted_response = str(format_response(result))
logger.info(f"格式化的搜索结果: {formatted_response}")
response = ChatCompletionResponse(
choices=[
ChatCompletionResponseChoice(
index=0,
message=Message(role="assistant", content=formatted_response),
finish_reason="stop"
)
]
)
logger.info(f"发送响应内容: \n{response}")
return JSONResponse(content=response.model_dump())
except Exception as e:
logger.error(f"处理聊天完成时出错:\n\n {str(e)}")
raise HTTPException(status_code=500, detail=str(e))
|