Transformer学习
前言
本文基于AI-Guide-and-Demos-zh_CN/PaperNotes/Transformer 论文精读.md at master · Hoper-J/AI-Guide-and-Demos-zh_CN与Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili阅读学习
transformer贡献
实际在这一阶段的工作中,注意力机制就已经在编码器-解码器架构中被广泛应用(与 RNN 一起使用),但 Transformer 彻底颠覆了默认采取的逻辑:直接放弃 RNN 的递归结构,只使用注意力机制来编码和解码序列信息。
Transformer 的主要贡献如下:
取消递归结构,实现并行计算
通过采用自注意力机制(Self-Attention),Transformer 可以同时处理多个输入序列,极大提高了计算的并行度和训练速度。
引入位置编码(Positional Encoding)并结合 Attention 机制巧妙地捕捉位置信息
在不依赖 RNN 结构的情况下,通过位置编码为序列中的每个元素嵌入位置信息,从而使模型能够感知输入的顺序。
transformer架构
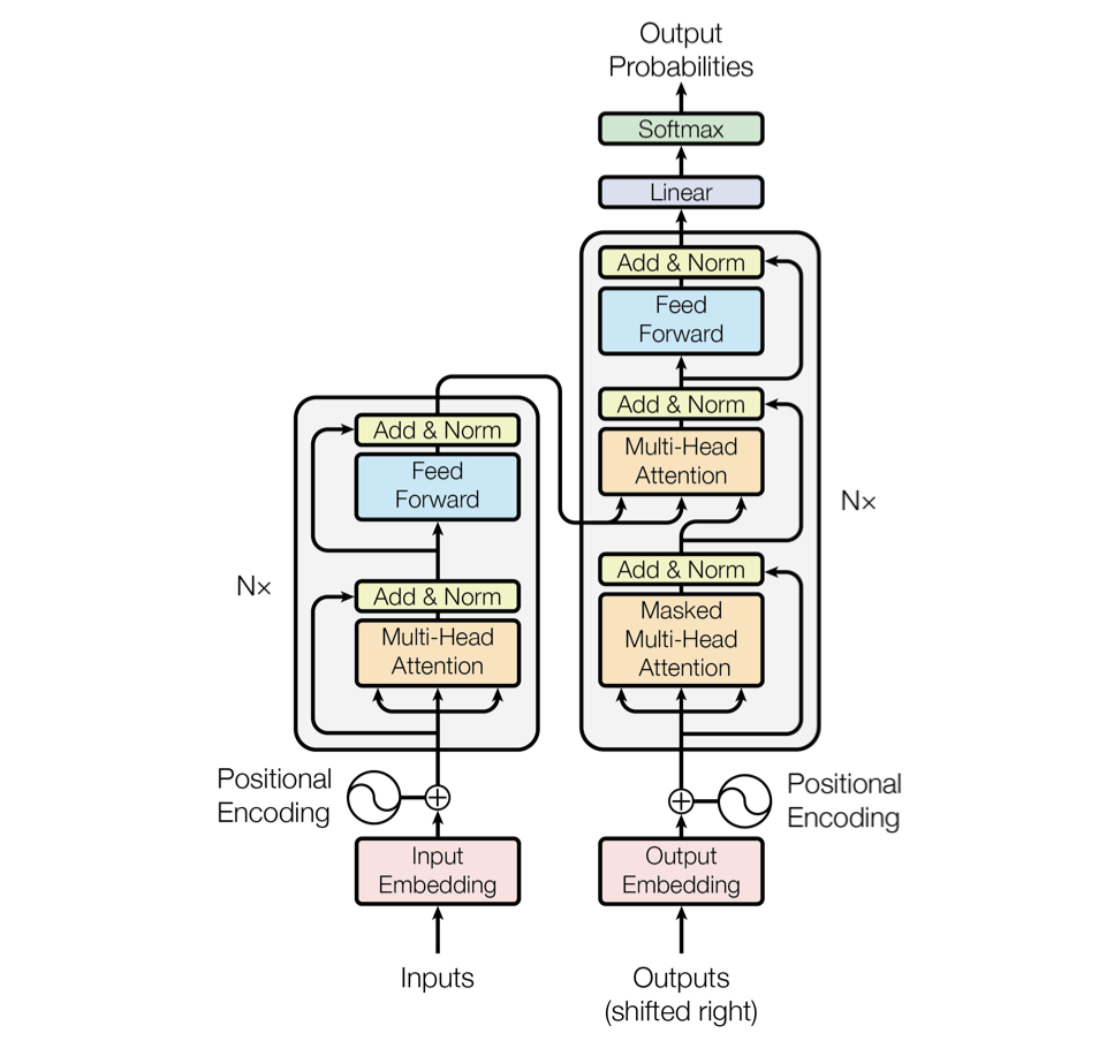
【Transformer模型】曼妙动画轻松学,形象比喻贼好记_哔哩哔哩_bilibili
Transformer 模型基于编码器(左)- 解码器(右)架构
Transformer编码器同样由 N 个完全相同的层(原始论文中 N=6)堆叠而成,每层只有两个子层,而解码器有三个。
- 多头自注意力(Multi-Head Self-Attention) 让输入序列中的每个位置都能关注序列内所有位置,直接建模全局依赖。
- 前馈全连接网络(Position-wise Feed-Forward Network) 对每个位置独立地做一次两层的全连接变换(通常先升维再降维)。
同样,每个子层后都有
- 残差连接(Residual Connection)
- 层归一化(Layer Normalization)
另外,编码器在输入端还会用到
- 位置编码(Positional Encoding)——给模型提供序列位置信息,因为注意力本身不包含顺序信息。
Transformer解码器由多个相同的层堆叠而成,每一层包含三个核心子层:
- 掩蔽多头自注意力机制(Masked Multi-Head Attention) 用于处理目标序列,通过掩码防止当前位置关注未来位置,确保生成过程的自回归特性。
- 编码器-解码器注意力机制(Encoder-Decoder Attention) 使解码器能够关注编码器输出的上下文信息,建立输入与输出序列之间的关联。
- 前馈神经网络(Feed-Forward Neural Network) 对注意力机制的输出进行非线性变换,增强模型的表达能力。
此外,每个子层后均包含残差连接(Residual Connection)和层归一化(Layer Normalization),以稳定训练过程并加速收敛。最终,解码器的输出通过线性层和Softmax层映射为词汇表上的概率分布。
嵌入(Embeddings)
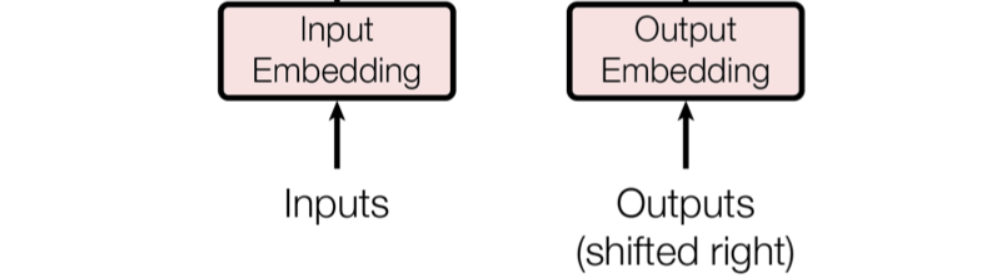
在 Transformer 模型中,嵌入层(Embedding Layer)
是处理输入和输出数据的关键步骤,因为模型实际操作的是张量(tensor),而非字符串(string)。在将输入文本传递给模型之前,首先需要进行分词(tokenization),即将文本拆解为多个
token,随后这些 token 会被映射为对应的 token
ID,从而转换为模型可理解的数值形式。此时,数据的形状为
(seq_len,),其中 seq_len
表示输入序列的长度。
目的:为了让模型捕捉到 token 背后复杂的语义(Semantic meaning)关系,我们需要将离散的 token ID 映射到一个高维的连续向量空间(Continuous, dense)。这意味着每个 token ID 会被转换为一个嵌入向量(embedding vector),期望通过这种方式让语义相近的词汇在向量空间中距离更近,使模型能更好地捕捉词汇之间的关系。
流程:(前面要进行分词,后面要进行位置编码)
初始化一个可学习的矩阵 E ∈ ℝ^(|V| × d_model)
|V| = 词表大小(比如 32 k、50 k),d_model =
512/768/1024…
把 token id 作为行号,直接取对应行: x_i = E[token_id_i]
得到 [batch, seq_len, d_model] 的浮点张量。
位置编码(Positional Encoding)
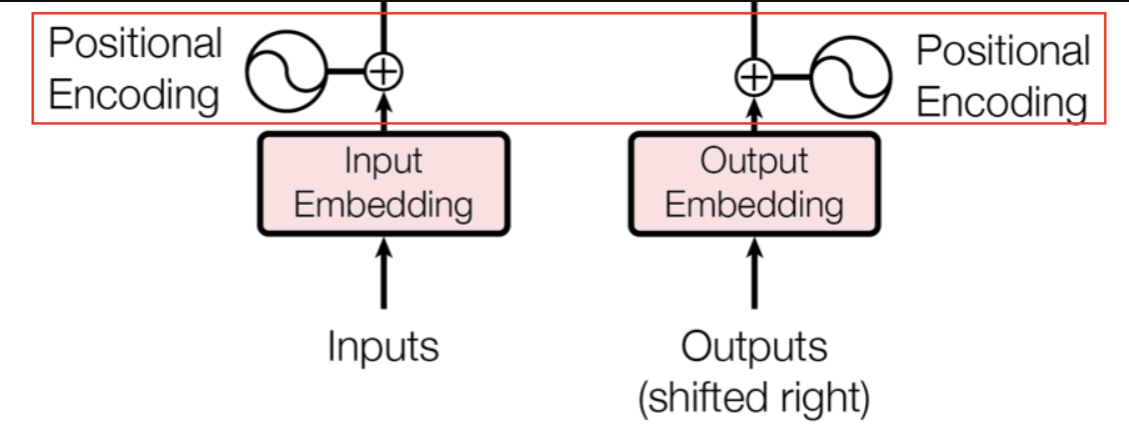
Transformer 的自注意力机制(Self-Attention)是位置无关(position-agnostic)的。也就是说,如果不做任何处理,模型无法区分“我爱你”和“你爱我”这两个句子的差异,因为自注意力机制只关注 token 之间的相关性,而不考虑它们在序列中的顺序。
为了让模型感知到 token 的位置信息,Transformer 引入了位置编码。
在原始论文中,Transformer 使用的是固定位置编码(Positional Encoding),其公式如下:
$$ \begin{aligned} PE_{(pos, 2i)} &= \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right), \\ PE_{(pos, 2i+1)} &= \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right). \end{aligned} $$
其中:
- pos 表示位置索引(Position)。
- i 表示维度索引。
- dmodel 是嵌入向量的维度。
流程:输入的是一个整数索引(位置序号 0,1,2,…)。位置编码模块先把这些整数映射成与词向量同维度的向量(例如 512 维),再把结果加到词向量上。
linear与Softmax
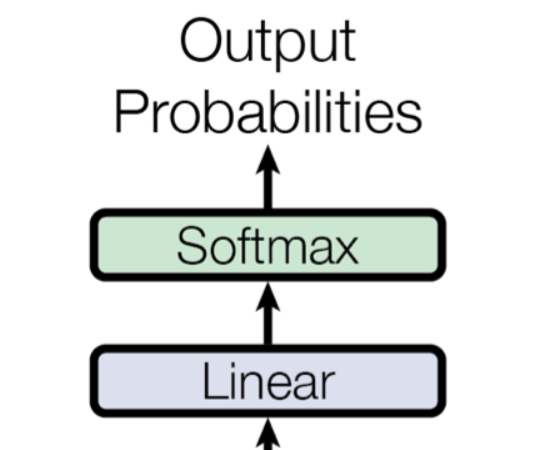
从Linear到MLP AI模型的数学本质【Transformer结构拆解】_哔哩哔哩_bilibili
在 Transformer 模型中,Softmax 函数不仅在计算注意力权重时用到,在预测阶段的输出处理环节也会用到,因为预测 token 的过程可以看成是多分类问题。
Softmax 函数是一种常用的激活函数,能够将任意实数向量转换为概率分布,确保每个元素的取值范围在 [0, 1] 之间,并且所有元素的和为 1。其数学定义如下:
$$ \text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}} $$
其中:
- xi 表示输入向量中的第 i 个元素。
- Softmax(xi) 表示输入 xi 转换后的概率。
我们可以把 Softmax 看作一种归一化的指数变换。相比于简单的比例归一化 $\frac{x_i}{\sum_j x_j}$, Softmax 通过指数变换放大数值间的差异,让较大的值对应更高的概率,同时避免了负值和数值过小的问题,让模型聚焦于权重最高的位置,同时保留全局信息(低权重仍非零)。
注意力机制
【Attention 注意力机制】激情告白transformer、Bert、GNN的精髓_哔哩哔哩_bilibili
缩放点积注意力机制(Scaled Dot-Product Attention)
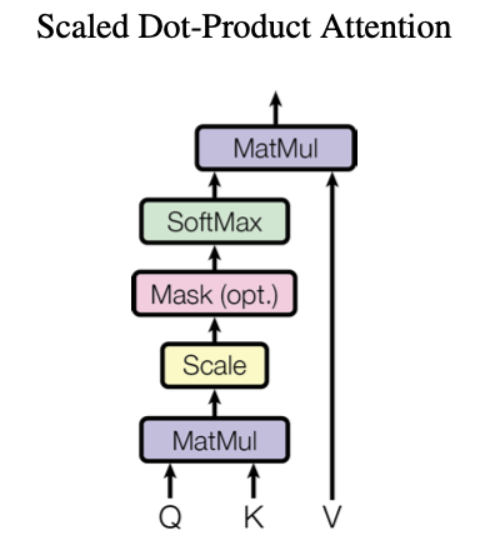
Transformer 的核心是多头注意力机制(Multi-Head Attention),它能够捕捉输入序列中不同位置之间的依赖关系,并从多个角度对信息进行建模。模块将自底向上的进行讲解:在深入理解注意力机制前,首先需要理解论文使用的缩放点积注意力机制(Scaled Dot-Product Attention)。
给定查询矩阵 Q、键矩阵 K 和值矩阵 V, 其注意力输出的数学表达式如下:
$$ \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{Q K^\top}{\sqrt{d_k}}\right) V $$
- Q(Query): 用于查询的向量矩阵。
- K(Key): 表示键的向量矩阵,用于与查询匹配。
- V(Value): 值矩阵,注意力权重最终会作用在该矩阵上。
- dk: 键或查询向量的维度。
理解 Q、K、V 的关键在于代码,它们实际上是通过线性变换从输入序列生成的
公式解释
点积计算(Dot Produce)
将查询矩阵 Q 与键矩阵的转置 K⊤ 做点积,计算每个查询向量与所有键向量之间的相似度:
$`\text{Scores} = Q K^\top`$
- 每一行表示某个查询与所有键之间的相似度(匹配分数)。
- 每一列表示某个键与所有查询之间的相似度(匹配分数)。
缩放(Scaling)
当 dk 较大时,点积的数值可能会过大,导致 Softmax 过后的梯度变得极小,因此除以 $\sqrt{d_k}$ 缩放点积结果的数值范围:
$`\text{Scaled Scores} = \frac{Q K^\top}{\sqrt{d_k}}`$
缩放后(Scaled Dot-Product)也称为注意力分数(attention scores)。
Softmax 归一化
使用 Softmax 函数将缩放后的分数转换为概率分布:
$`\text{Attention Weights} = \text{Softmax}\left(\frac{Q K^\top}{\sqrt{d_k}}\right)`$
注意:Softmax 是在每一行上进行的,这意味着每个查询的匹配分数将归一化为概率,总和为 1。
加权求和(Weighted Sum)
最后,使用归一化后的注意力权重对值矩阵 V 进行加权求和,得到每个查询位置的最终输出: $`\text{Output} = \text{Attention Weights} \times V`$
单头注意力机制(Single-Head Attention)
将输入序列(Inputs)通过线性变换生成查询矩阵(Query, Q)、键矩阵(Key, K)和值矩阵(Value, V),随后执行缩放点积注意力(Scaled Dot-Product Attention)。
掩码注意力机制(Masked Attention)
如果使用 mask 掩盖将要预测的词汇,那么 Attention 就延伸为 Masked Attention
在这段代码中,mask
矩阵用于指定哪些位置应该被遮蔽(即填充为
-∞),从而保证这些位置的注意力权重在 softmax
输出中接近于零。注意,掩码机制并不是直接在截断输入序列,也不是在算分数的时候就排除不应该看到的位置,因为看到也没有关系,不会影响与其他位置的分数,所以在传入
Softmax(计算注意力权重)之前排除就可以了。
另外,根据输入数据的来源,还可以将注意力分为自注意力(Self-Attention)和交叉注意力(Cross-Attention)。
自注意力机制(Self-attention)
1 | 【输入向量 X】(来自上一层或Embedding) |
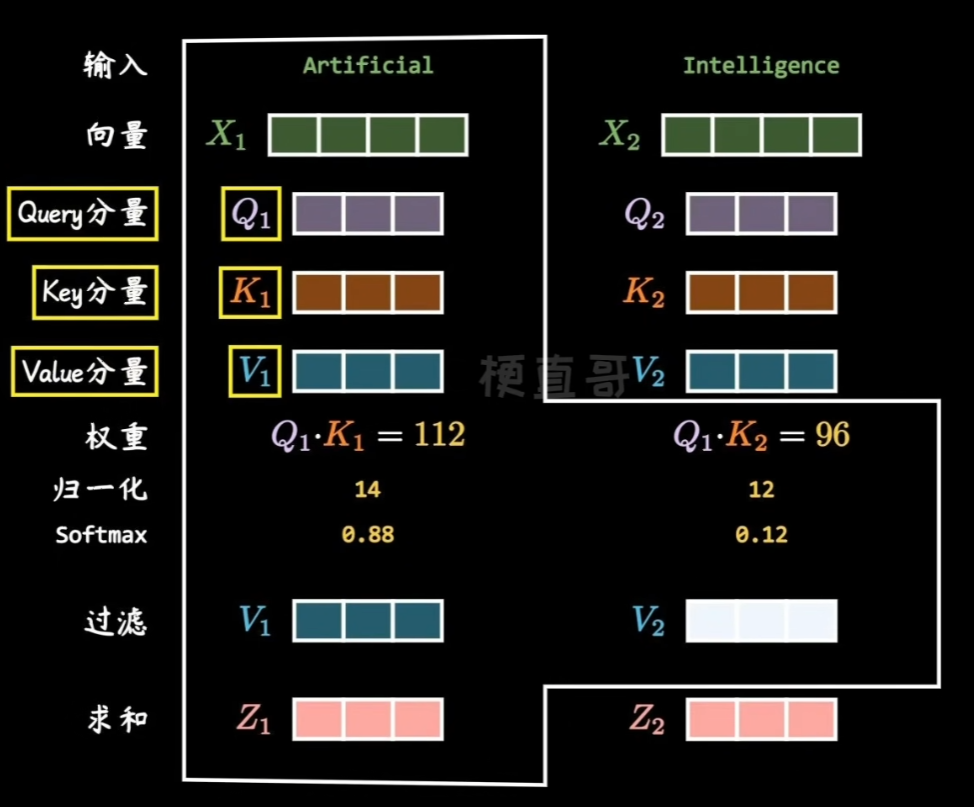
Transformer 模型架构使用到了三个看起来不同的注意力机制,我们继续忽视共有的 Multi-Head。观察输入,线条一分为三传入 Attention 模块,这意味着查询(query)、键(key)和值(value)实际上都来自同一输入序列 X,数学表达如下:
Q = XWQ, K = XWK, V = XWV
- WQ, WK, WV:可训练的线性变换权重,实际上就是简单的线性层
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$

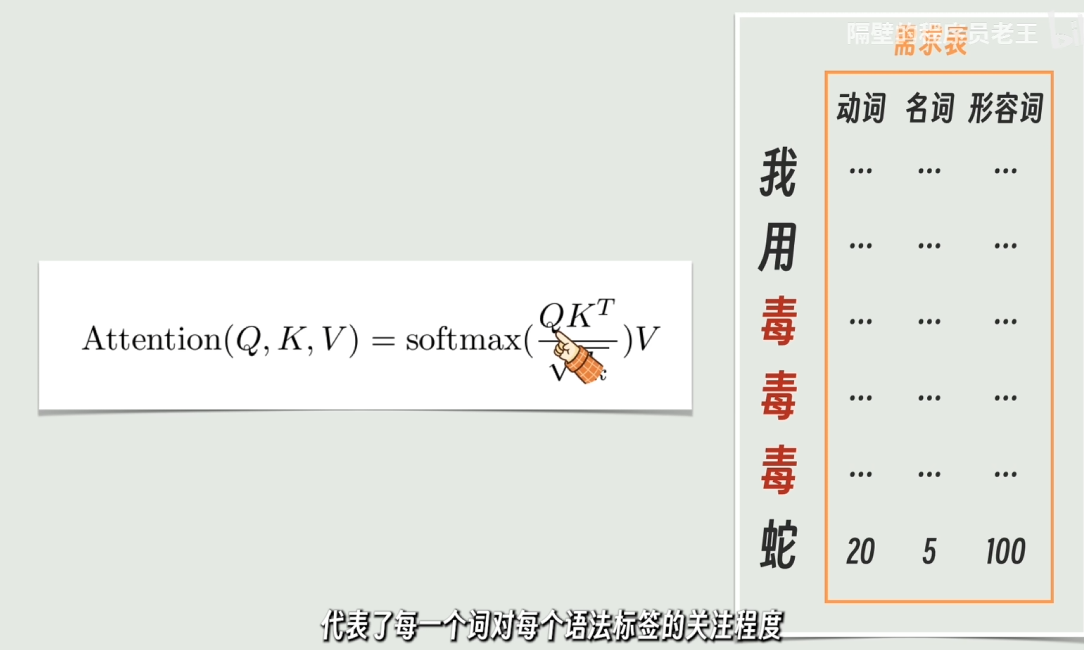
- K 矩阵:单词的“自我介绍表”(图一)
看你的第一张图,标题写着“语法表”,字幕说:“这里的 K 矩阵就是语法表矩阵”。
- 通俗含义:K(Key)是每个词躺在字典里时,向外界展现出的静态特征标签。
- 结合图一理解:
“我”这个词,它的 K 向量是[动词: 1, 名词: 95, 形容词: 40]。这代表它的静态属性高度偏向名词(代词)。“蛇”这个词,它的 K 向量是[动词: 10, 名词: 100, 形容词: 40]。也是一个纯纯的大名词。
- 一句话总结:K 矩阵就是一份“花名册”,记录了全句子每个词在各个语义/语法维度上的静态得分。
- Q 矩阵:单词的“求偶/检索意向表”(图二)
看你的第二张图,标题变成了“需求表”,字幕说:“代表了每一个词对每个语法标签的关注程度”。
- 通俗含义:Q(Query)是每个词在具体的句子里,为了理清自己的意思,主动发出的“我想找谁”的检索申请。
- 结合图二理解:
- 我们看最后那个
“蛇”字。“蛇”作为名词,它自己已经很完整了,但它此时急需一个修饰它的词(什么样的蛇?)。 - 所以
“蛇”发出的 Q 申请表是:[动词: 20, 名词: 5, 形容词: 100]。 - 核心亮点:你看!
“蛇”的 Q 向量里,形容词这一项拿到了 100 分!这说明“蛇”此时强烈的渴望在句子里抓到一个“形容词”来修饰自己。
- 我们看最后那个
- 一句话总结:Q 矩阵就是一份“相亲需求表”,写满了每个词当前最想跟什么属性的词发生关联。
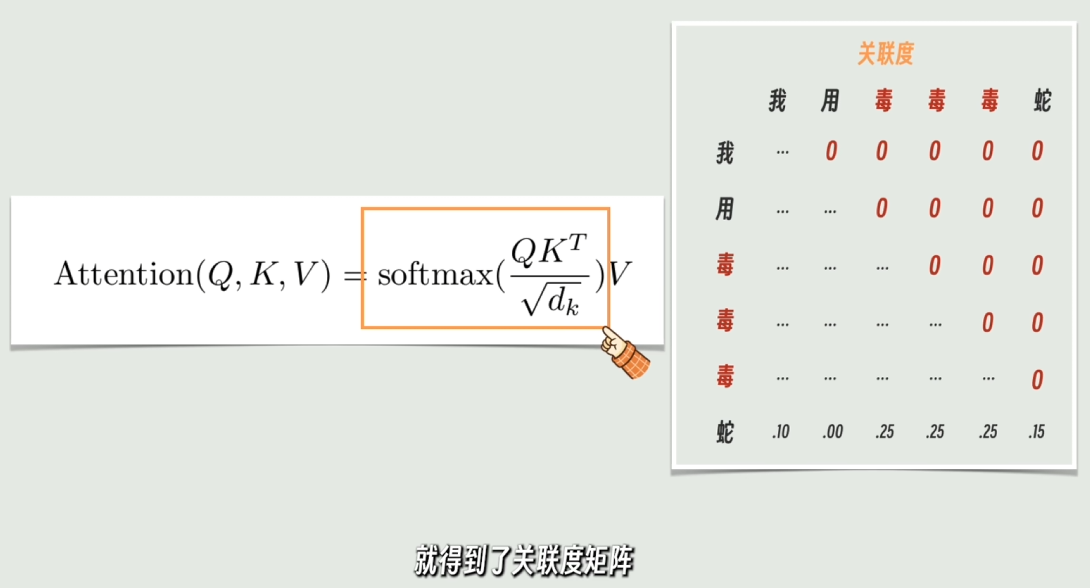
- Q × KT:需求与标签的碰撞,算出“关联度矩阵”(图三)
看你的第三张图,这就是大模型里最著名的核心计算。当
“蛇” 带着它的需求(Q),去挨个查全句子所有词的静态标签(K)时:
- 碰壁:
“蛇”的Q乘以“我”的K→“我”是名词,不是“蛇”想要的形容词,打分很低。 - 看对眼:
“蛇”的Q乘以 第一个“毒”的K→ 刚好第一个“毒”的形容词属性极其强烈!两者的矩阵点积(Dot Product)算出来分数极高。 - 看图三的最后一行(蛇):经过
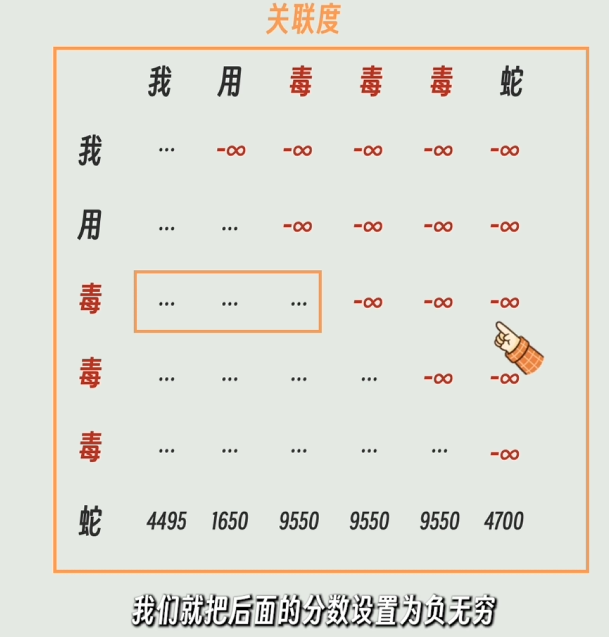
Softmax归一化后,“蛇”对三个“毒”分别给出了0.25, 0.25, 0.25的超高关联度(因为模型在这一层可能还在分辨哪一个是形容词),而对其他不相关的词给出了.00的关联度。 - 注意图三里的右上角(因果掩码):你注意到有很多红色的
0 了吗?这就是我们前面反复提到的
ForCausalLM(因果模型)
的铁证!因为是自回归,前面的词(如“我”)绝对不能看到后面的词(如“蛇”),所以右上角全部被强行抹成
0。只有最后一行
“蛇”才能看完前面所有的词。
- 那么,一直没出场的 V 矩阵是干嘛的?
在这个例子里,通过 Q × KT,“蛇”
终于以 25% 的高分,死死锁定了第一个 “毒” 字。
但是,“蛇”
真正想要的是什么?它不仅想知道“我和你有关系”,它还想把“毒”这个字的【真实毒性、危险含义】给吸收到自己的向量里来,让自己变成一条真正的“毒蛇”。
这时候,V(Value)矩阵 就登场了:
- K 和 Q
只是为了算分数(对暗号)而生。第一个
“毒”的 K 只是它的“形容词标签”。 - 第一个
“毒”真正的内核含义、画面感、语义财富,全存在 V 矩阵 里。 - 最后一步:模型拿着算出来的
0.25的权重,乘以第一个“毒”的 V 向量。
0.25 × V毒
通过这一步,第一个 “毒”
字所代表的“危险、有毒、绿色液体”等深层语义(V),就被 25%
地注入到了 “蛇”
的体内。经过这一层计算,“蛇”
就不再是一条普通的蛇了,它在这一层升华成了“毒蛇”。
交叉注意力机制(Cross-Attention)
在 Transformer 解码器中,除了自注意力外,还使用了 交叉注意力(Cross-Attention)。
如下图所示,解码器(右)在自底向上的处理过程中,先执行自注意力机制,然后通过交叉注意力从编码器的输出中获取上下文信息。
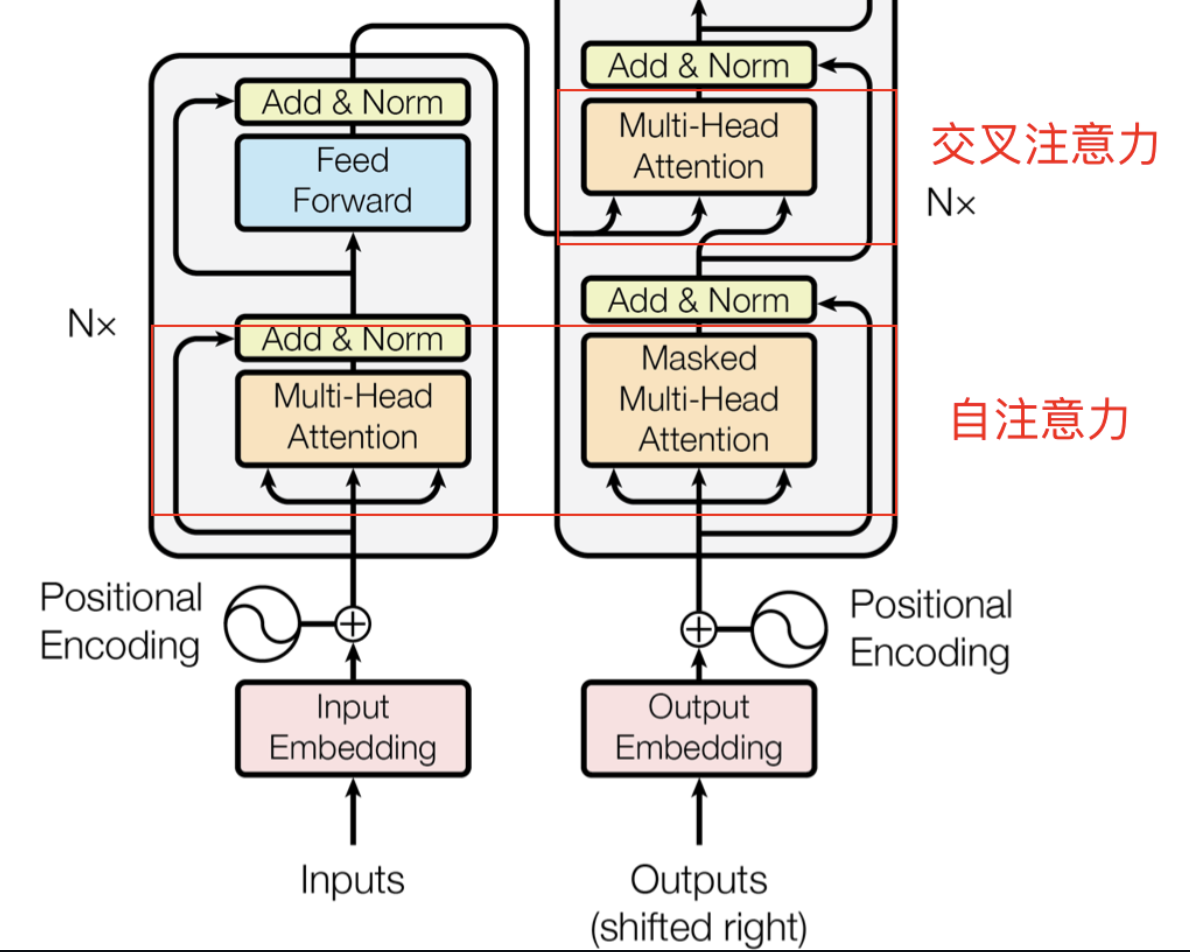
数学表达如下:
Q = XdecoderWQ, K = XencoderWK, V = XencoderWV
对比学习
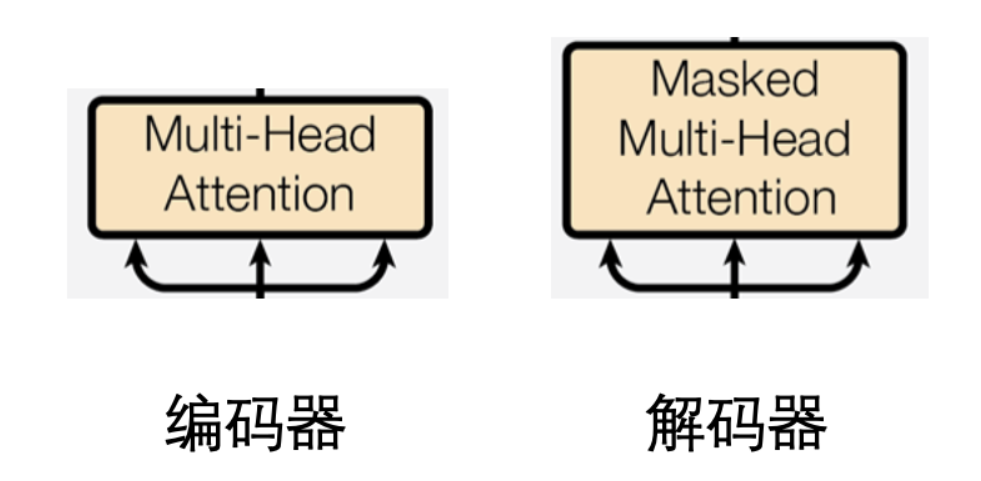
Masked Attention、Self-Attention 和 Cross-Attention 的本质是一致的,这一点从代码调用可以看出来,三者的区别在于未来掩码的使用和输入数据的来源:
Masked Attention:用于解码过程,通过掩码屏蔽未来的时间步,确保模型只能基于已生成的部分进行预测,论文中解码器部分的第一个 Attention 使用的是 Masked Self-Attention。
Self-Attention:查询、键和值矩阵来自同一输入序列,模型通过自注意力机制学习输入序列的全局依赖关系。
Cross-Attention:查询矩阵来自解码器的输入,而键和值矩阵来自编码器的输出,解码器的第二个 Attention 模块就是 Cross-Attention,用于从编码器输出中获取相关的上下文信息。
以机器翻译中的中译英任务为例:对于中文句子“中国的首都是北京”,假设模型已经生成了部分译文“The capital of China is”,此时需要预测下一个单词。
在这一阶段,解码器中的交叉注意力机制会使用当前已生成的译文“The capital of China is”的编码表示作为查询,并将编码器对输入句子“中国的首都是北京”编码表示作为键和值,通过计算查询与键之间的匹配程度,生成相应的注意力权重,以此从值中提取上下文信息,基于这些信息生成下一个可能的单词(token),比如:“Beijing”。
多头注意力机制(Multi-Head Attention)
多头注意力 MultiHeadAttention 是什么_哔哩哔哩_bilibili
因果语言模型
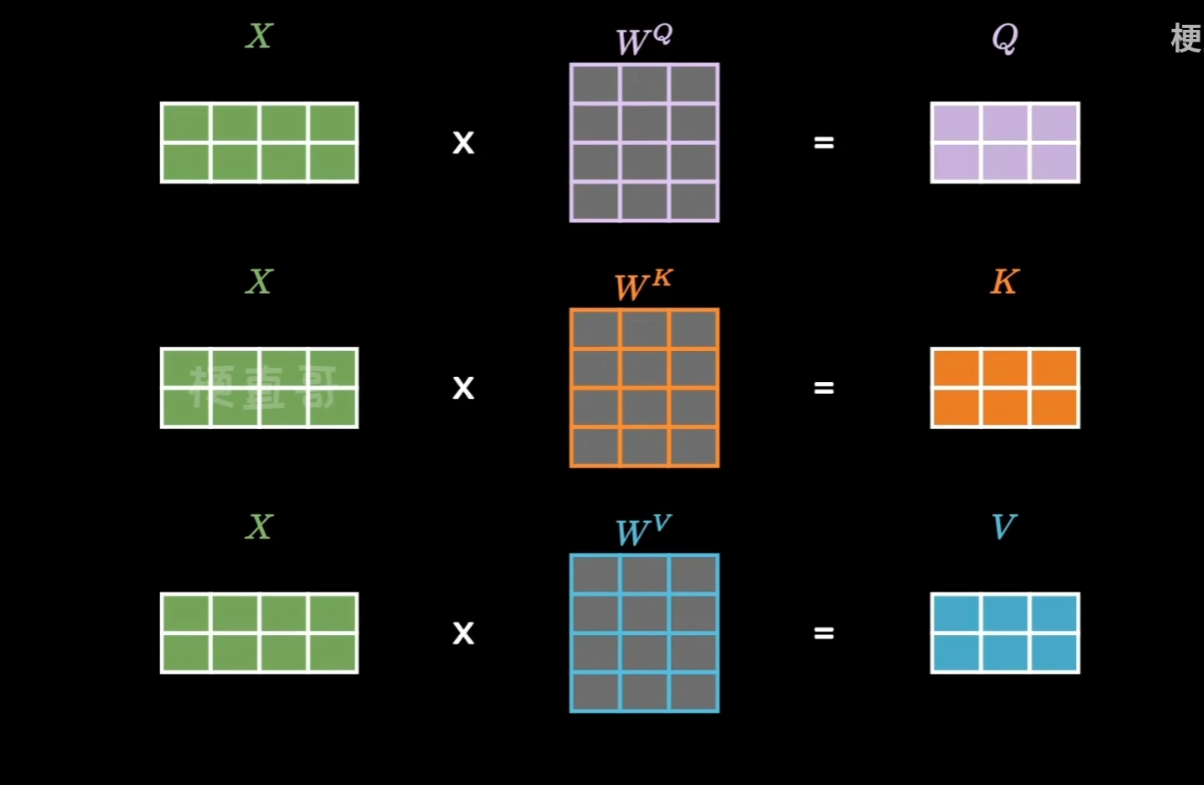
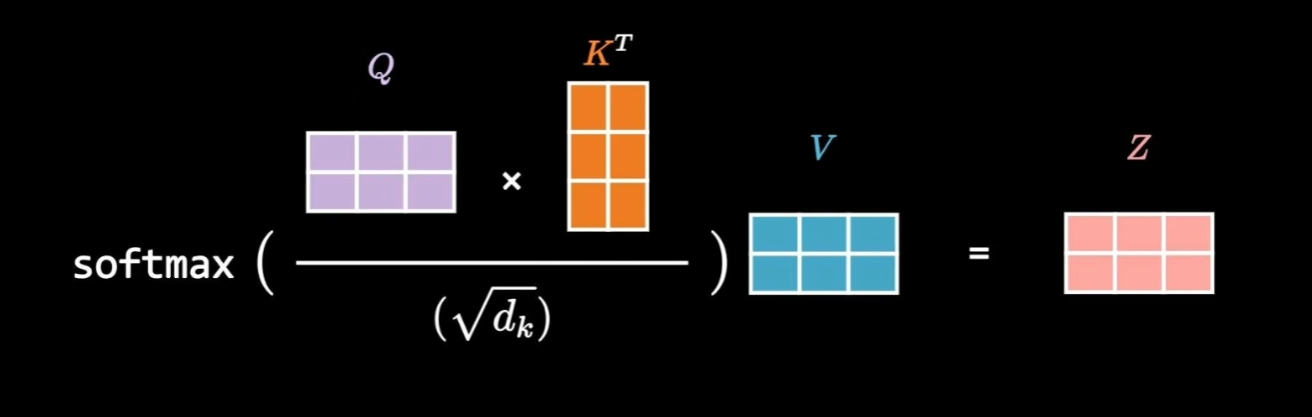
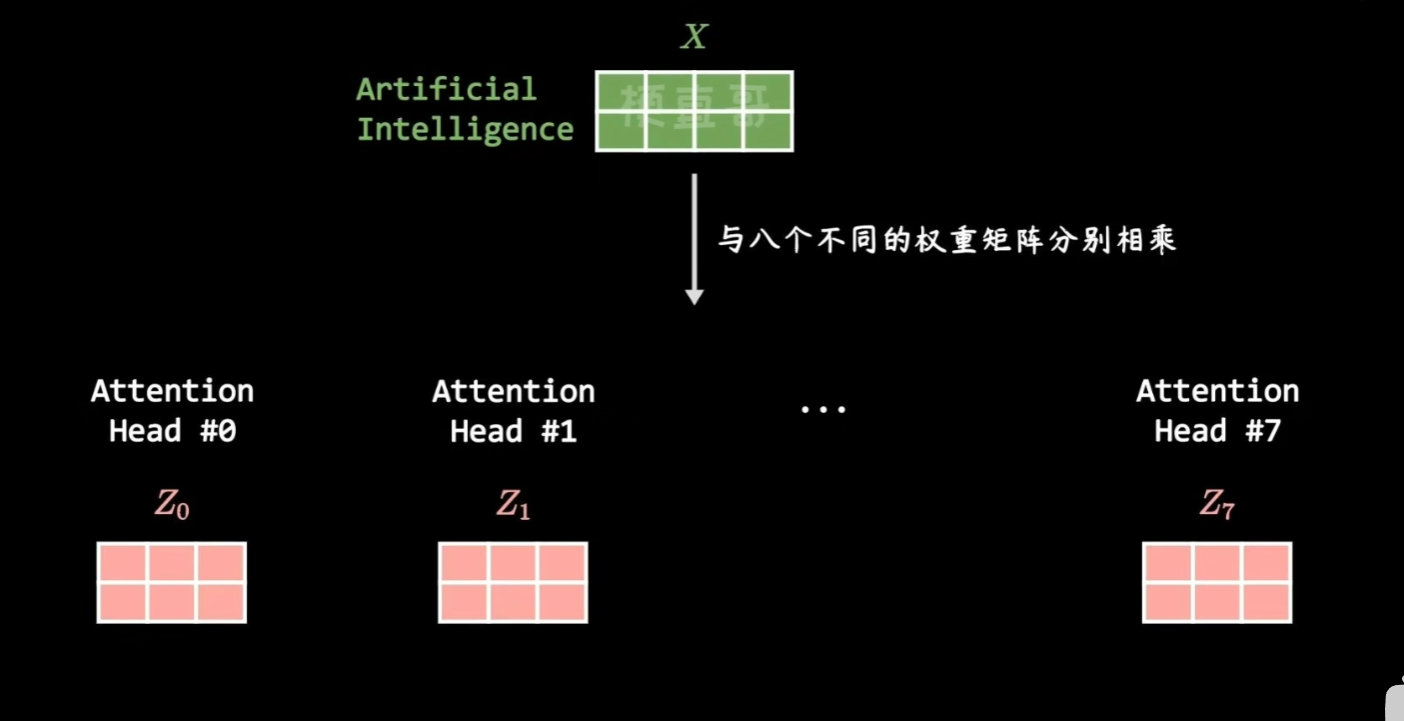
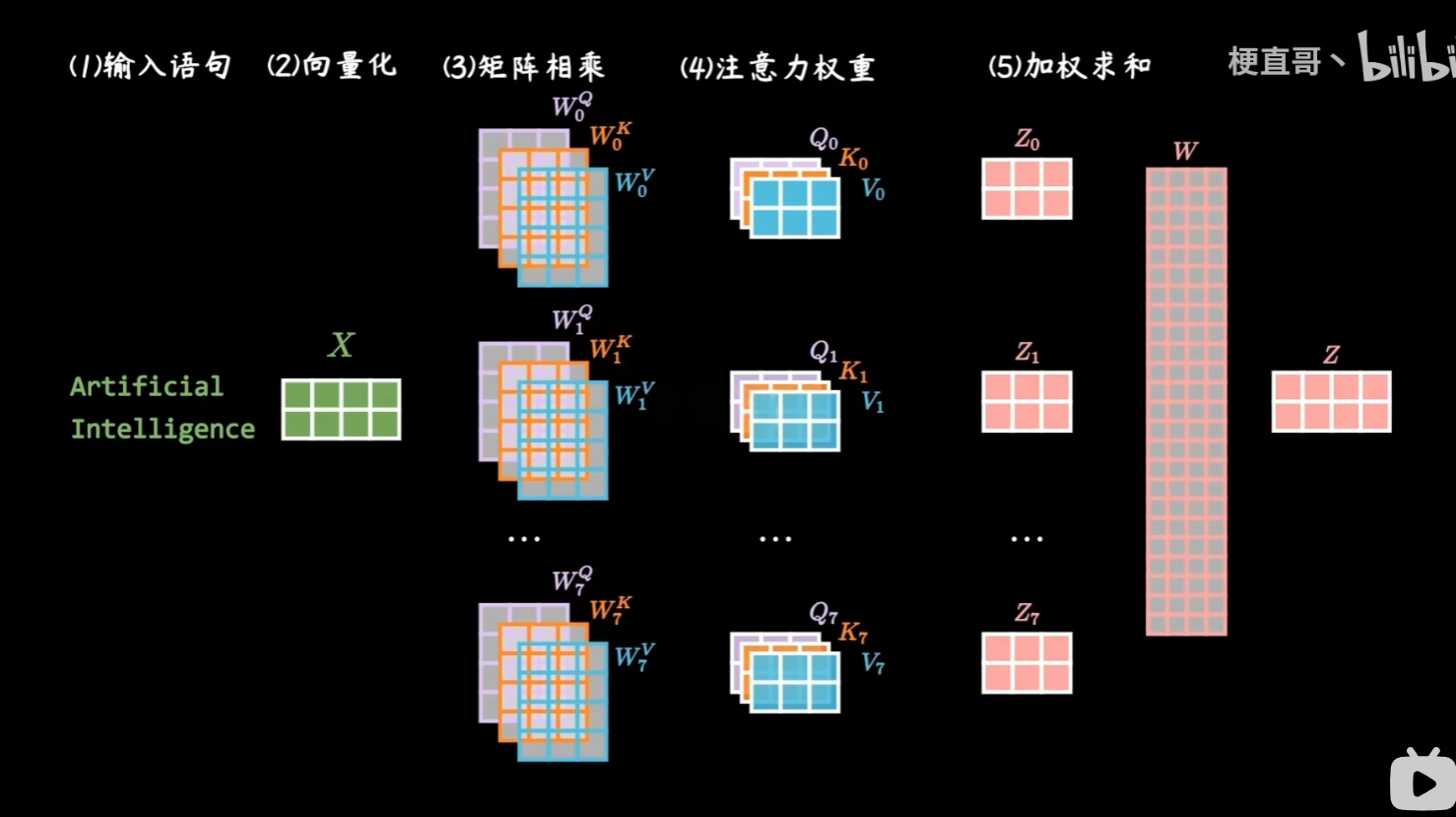
多头注意力机制就是存在多个不同的权重矩阵,形成多个矩阵Z,再把它们 按最后一维(hidden)拼接(concat)→ 做一次线性变换 得到最终输出。
线性bian’h把拼接后的多头结果
Z_concat(形状 batch×seq×d_model)重新线性映射回与输入相同的维度,同时让网络可以学习如何融合不同头的信息。
【Transformer模型】曼妙动画轻松学,形象比喻贼好记_哔哩哔哩_bilibili
Transformer原理及架构:多头自注意力机制_哔哩哔哩_bilibili
残差连接(Residual Connection)和层归一化(Layer Normalization, LayerNorm)
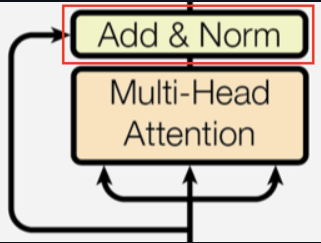
在 Transformer 架构中,残差连接(Residual Connection)与层归一化(LayerNorm)结合使用,统称为 Add & Norm 操作。
Add(残差连接,Residual Connection)
残差连接是一种跳跃连接(Skip Connection),它将层的输入直接加到输出上(观察架构图中的箭头),对应的公式如下:
Output = SubLayer(x) + x
这种连接方式有效缓解了深层神经网络的梯度消失问题。
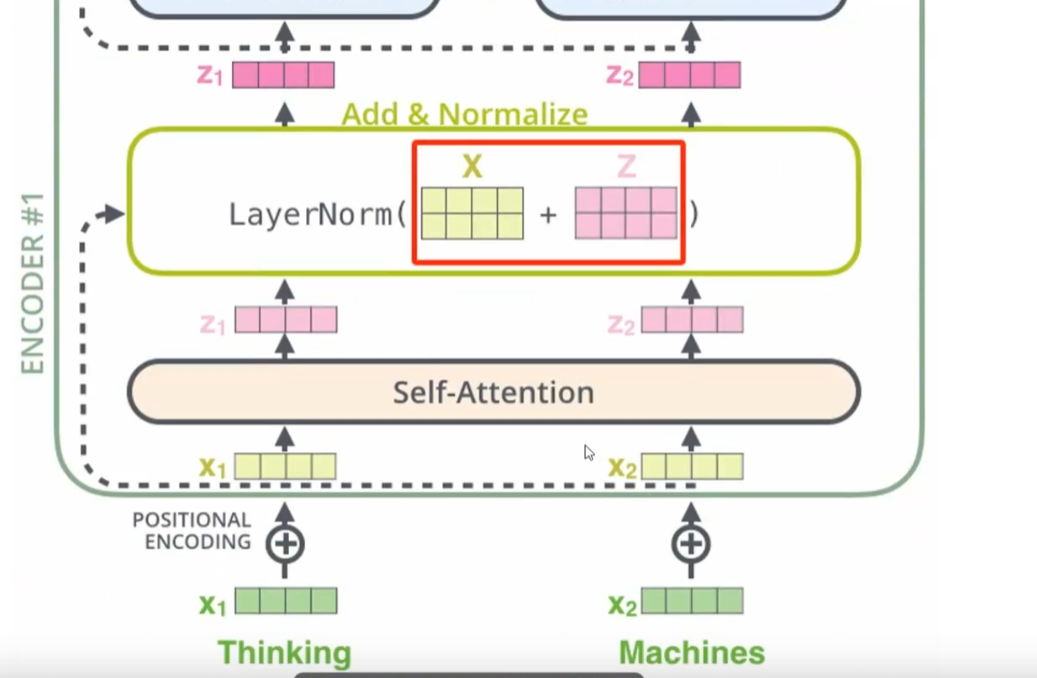
在transform中,就是输入的矩阵x加上经过注意力机制计算出来的z矩阵
Norm(层归一化,Layer Normalization)
层归一化(LayerNorm)是一种归一化技术,用于提升训练的稳定性和模型的泛化能力。
假设输入向量为 x = (x1, x2, …, xd), LayerNorm 的计算步骤如下:
计算均值和方差: 对输入的所有特征求均值 μ 和方差 σ2:
$` \mu = \frac{1}{d} \sum_{j=1}^{d} x_j, \quad \sigma^2 = \frac{1}{d} \sum_{j=1}^{d} (x_j - \mu)^2 `$
归一化公式: 将输入特征 x̂i 进行归一化:
$` \hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} `$
其中, ϵ 是一个很小的常数(比如 1e-9),用于防止除以零的情况。
引入可学习参数: 归一化后的输出乘以 γ 并加上 β, 公式如下:
$` \text{Output} = \gamma \hat{x} + \beta `$
其中 γ 和 β 是可学习的参数,用于进一步调整归一化后的输出。
前馈神经网络 Position-wise Feed-Forward Networks(FFN)
attention输出是词和词之间的关联度,但是因为attention后,很多维度是没用的,所以需要ffn再做进一步映射,提取有用的特征或维度,传给下面
1 | [ Attention 输出: 1536维 ] (充满冗余、噪声和断层) |
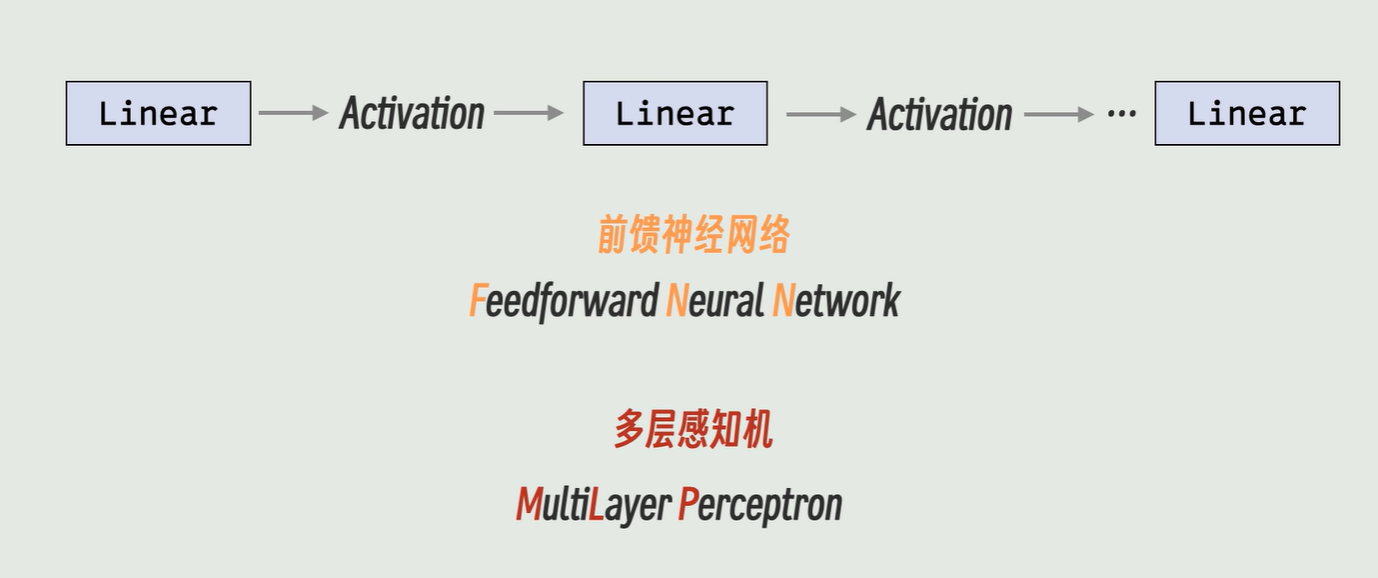
在 Transformer 中,前馈网络层(Feed-Forward Network,FFN)的作用可以概括为一句话: “对每个位置的向量进行非线性变换,增加模型的表达能力。”
在编码器-解码器架构中,另一个看起来“大一点”的模块就是 Feed Forward,它在每个位置 i 上的计算可以表示为:
FFN(xi) = max(0, xiW1 + b1)W2 + b2
其中:
- xi ∈ ℝdmodel 表示第 i 个位置的输入向量。
- W1 ∈ ℝdmodel × dff 和 W2 ∈ ℝdff × dmodel 是两个线性变换的权重矩阵。
- b1 ∈ ℝdff 和 b2 ∈ ℝdmodel 是对应的偏置向量。
- max(0, ⋅) 是 ReLU 激活函数,用于引入非线性。
大模型发展树
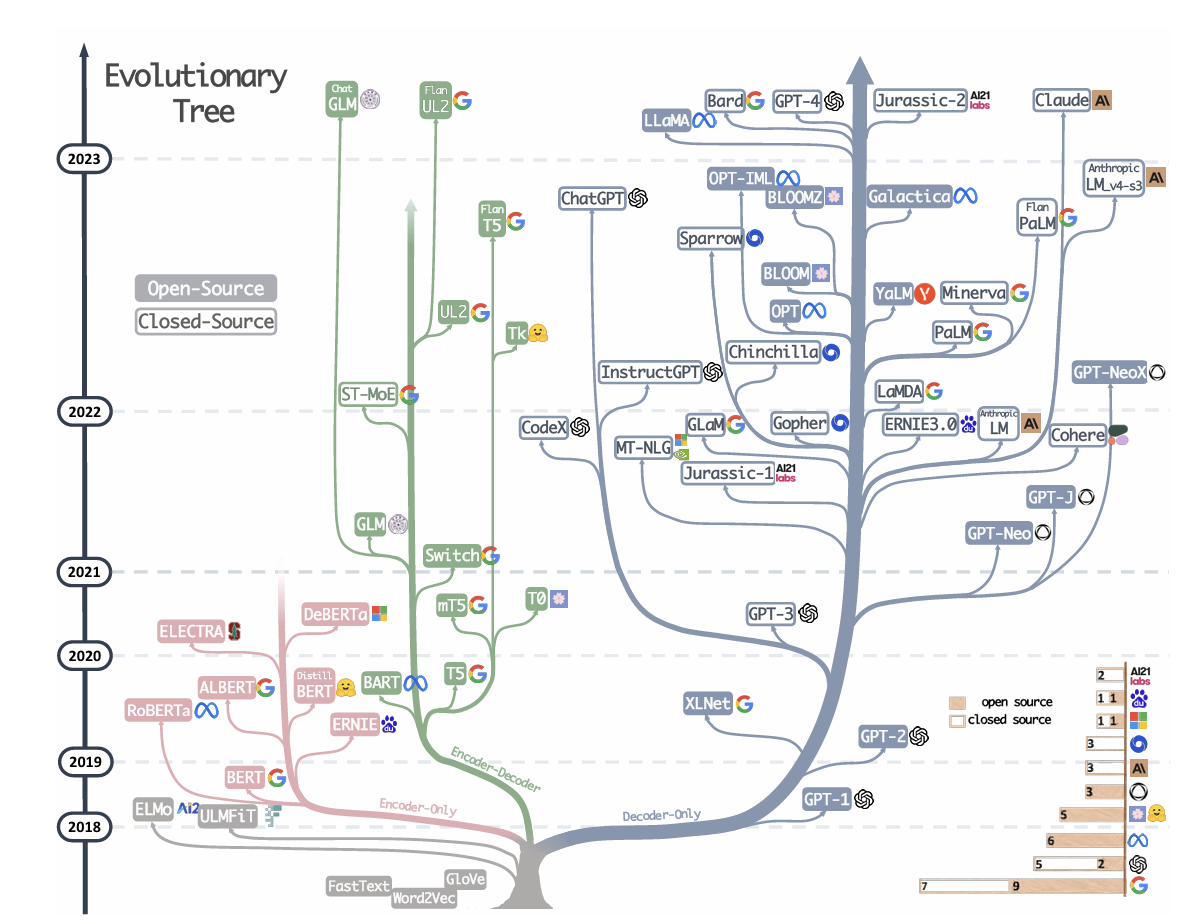
预训练语言模型
预训练语言模型(PLM)是一种通过大量文本数据进行无监督或弱监督训练的语言模型,目的是学习语言的通用表示(即语言的模式、语法、语义等)。这些模型通常在大规模文本数据上进行预训练,然后可以被微调(Fine - tuning)以适应各种下游任务,如文本分类、问答、命名实体识别等。
预训练语言模型的核心思想是利用大量的无标注文本数据来学习语言的通用特征,从而为各种自然语言处理任务提供强大的语言理解能力。预训练模型可以显著提高任务的性能,减少对标注数据的依赖,并且能够快速适应新的任务。
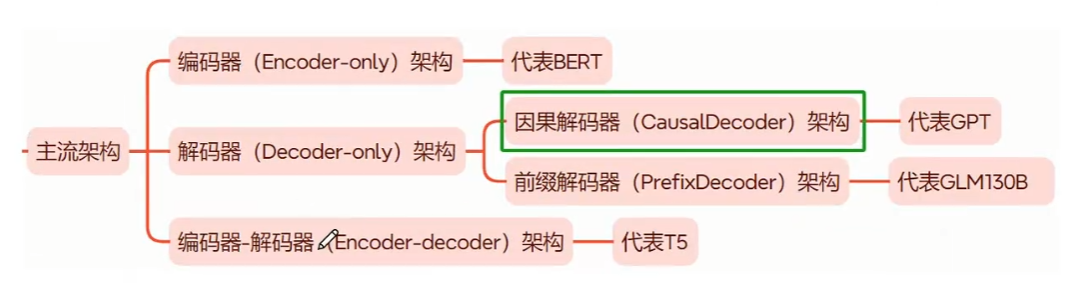
BERT模型(Encoder-only PLM)
针对 Encoder、Decoder 的特点,引入 ELMo 的预训练思路,开始出现不同的、对 Transformer 进行优化的思路。例如,Google 仅选择了 Encoder 层,通过将 Encoder 层进行堆叠,再提出不同的预训练任务-掩码语言模型(Masked Language Model,MLM),打造了一统自然语言理解(Natural Language Understanding,NLU)任务的代表模型——BERT。
BERT,全名为 Bidirectional Encoder Representations from Transformers,是由 Google 团队在 2018年发布的预训练语言模型。该模型发布于论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,实现了包括 GLUE、MultiNLI 等七个自然语言处理评测任务的最优性能(State Of The Art,SOTA),堪称里程碑式的成果。
T5(Encoder-Decoder PLM)
BERT 也存在一些问题,例如 MLM 任务和下游任务微调的不一致性,以及无法处理超过模型训练长度的输入等问题。为了解决这些问题,研究者们提出了 Encoder-Decoder 模型,通过引入 Decoder 部分来解决这些问题,同时也为 NLP 领域带来了新的思路和方法。
T5(Text-To-Text Transfer Transformer)是由 Google 提出的一种预训练语言模型,通过将所有 NLP 任务统一表示为文本到文本的转换问题,大大简化了模型设计和任务处理。T5 基于 Transformer 架构,包含编码器和解码器两个部分,使用自注意力机制和多头注意力捕捉全局依赖关系,利用相对位置编码处理长序列中的位置信息,并在每层中包含前馈神经网络进一步处理特征。
LLama模型(Decoder-Only PLM)
LLaMA模型是由Meta(前Facebook)开发的一系列大型预训练语言模型。从LLaMA-1到LLaMA-3,LLaMA系列模型展示了大规模预训练语言模型的演进及其在实际应用中的显著潜力。
GPT模型(Decoder-Only PLM)
GPT,即 Generative Pre-Training Language Model,是由 OpenAI 团队于 2018年发布的预训练语言模型。虽然学界普遍认可 BERT 作为预训练语言模型时代的代表,但首先明确提出预训练-微调思想的模型其实是 GPT。
GPT 提出了通用预训练的概念,也就是在海量无监督语料上预训练,进而在每个特定任务上进行微调,从而实现这些任务的巨大收益。虽然在发布之初,由于性能略输于不久后发布的 BERT,没能取得轰动性成果,也没能让 GPT 所使用的 Decoder-Only 架构成为学界研究的主流,但 OpenAI 团队坚定地选择了不断扩大预训练数据、增加模型参数,在 GPT 架构上不断优化,最终在 2020年发布的 GPT-3 成就了 LLM 时代的基础,并以 GPT-3 为基座模型的 ChatGPT 成功打开新时代的大门,成为 LLM 时代的最强竞争者也是目前的最大赢家。
MOE
15分钟带你彻底搞懂MoE架构! 从原理解析到路由策略全程干货~大模型|LLM_哔哩哔哩_bilibili
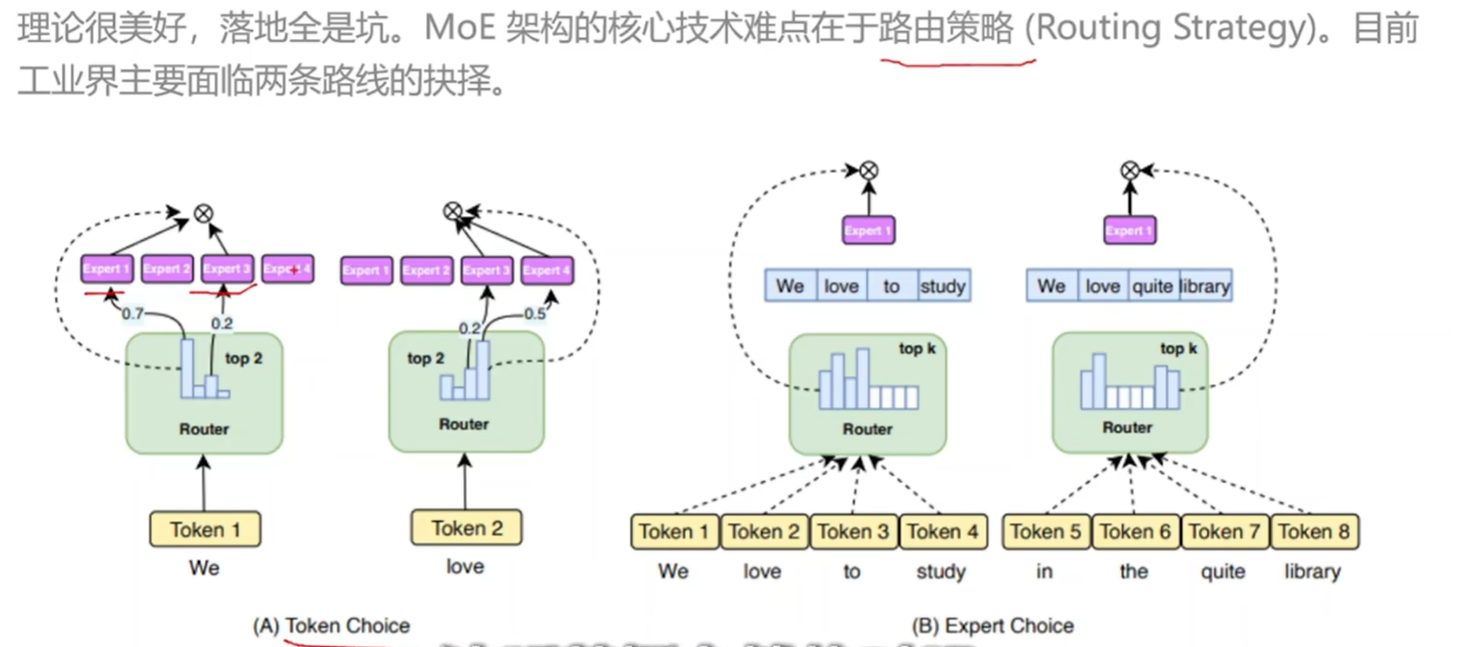

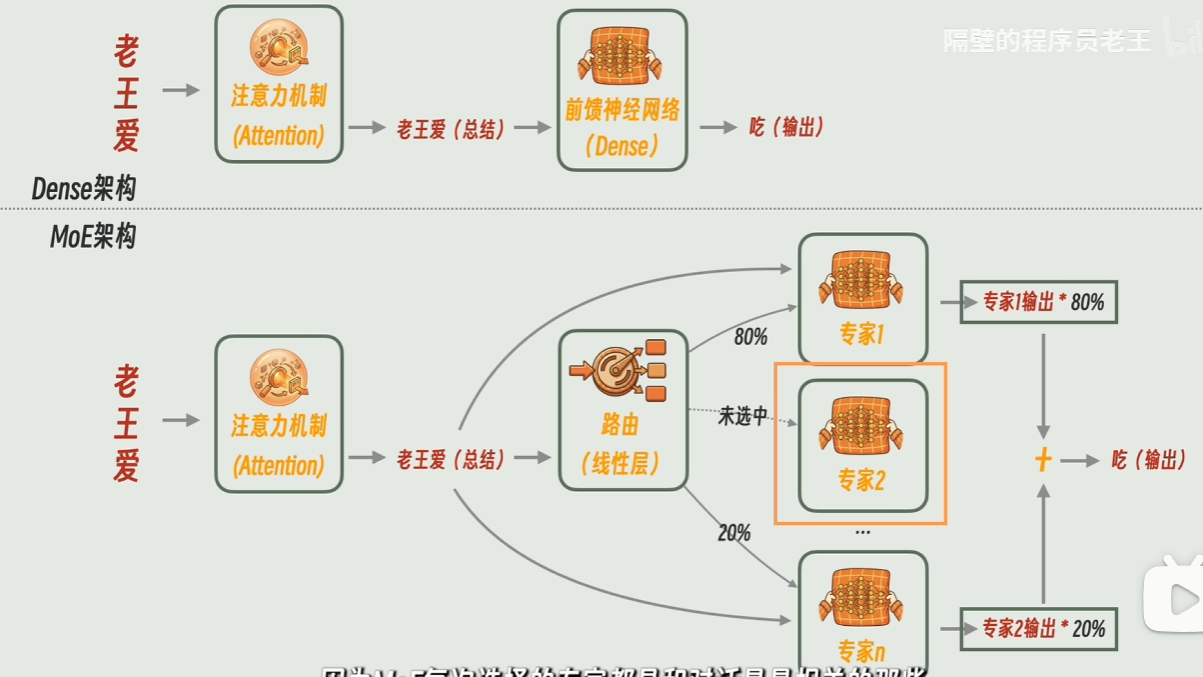
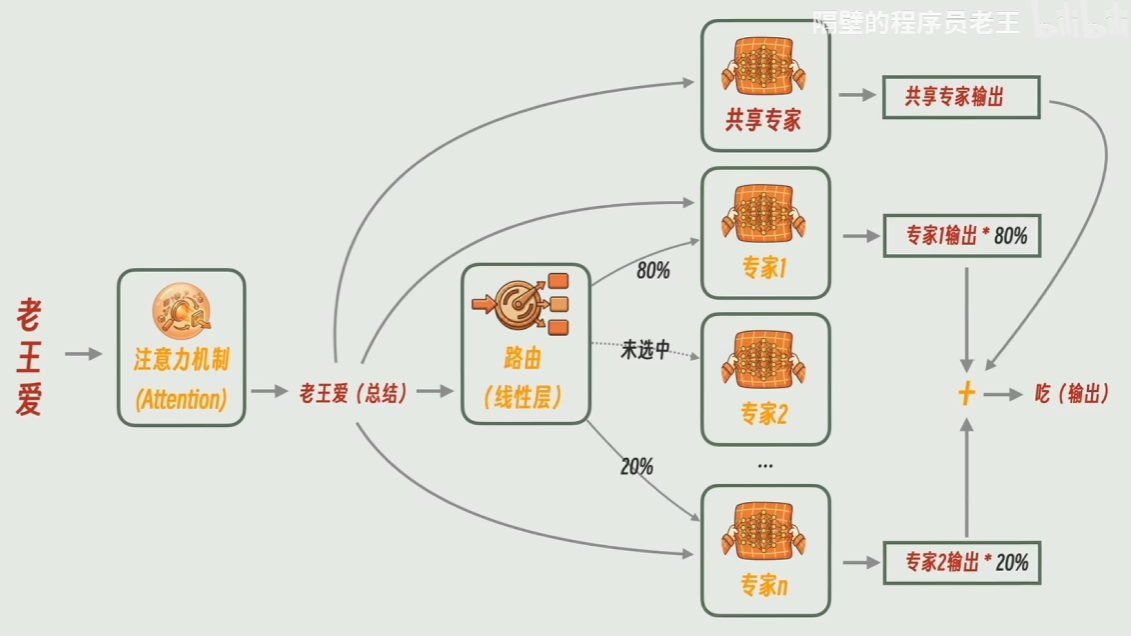
deepseek架构发展
【闪客】深入解读 DeepSeek V1~V4!男女老少都听得懂~_哔哩哔哩_bilibili
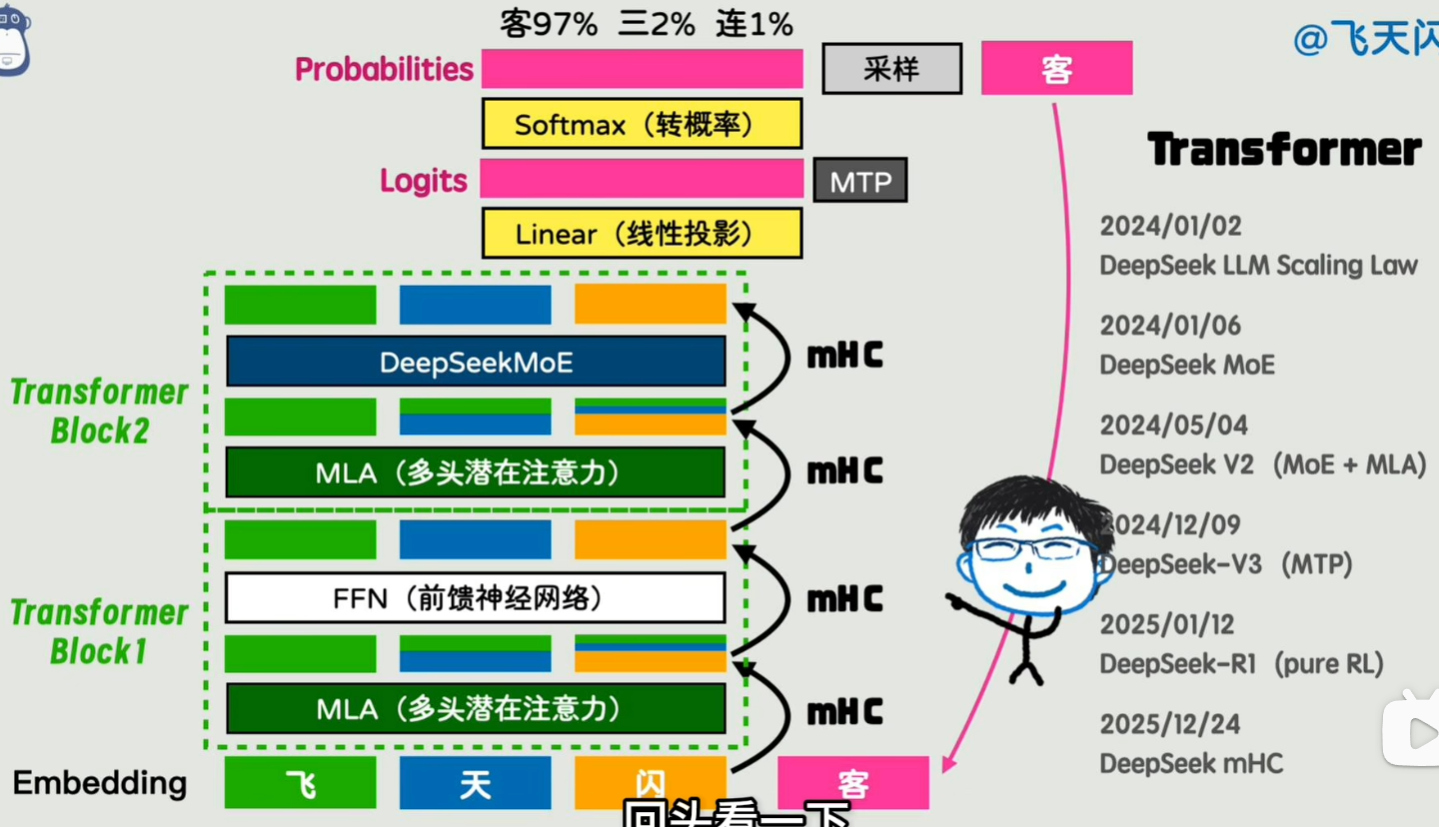
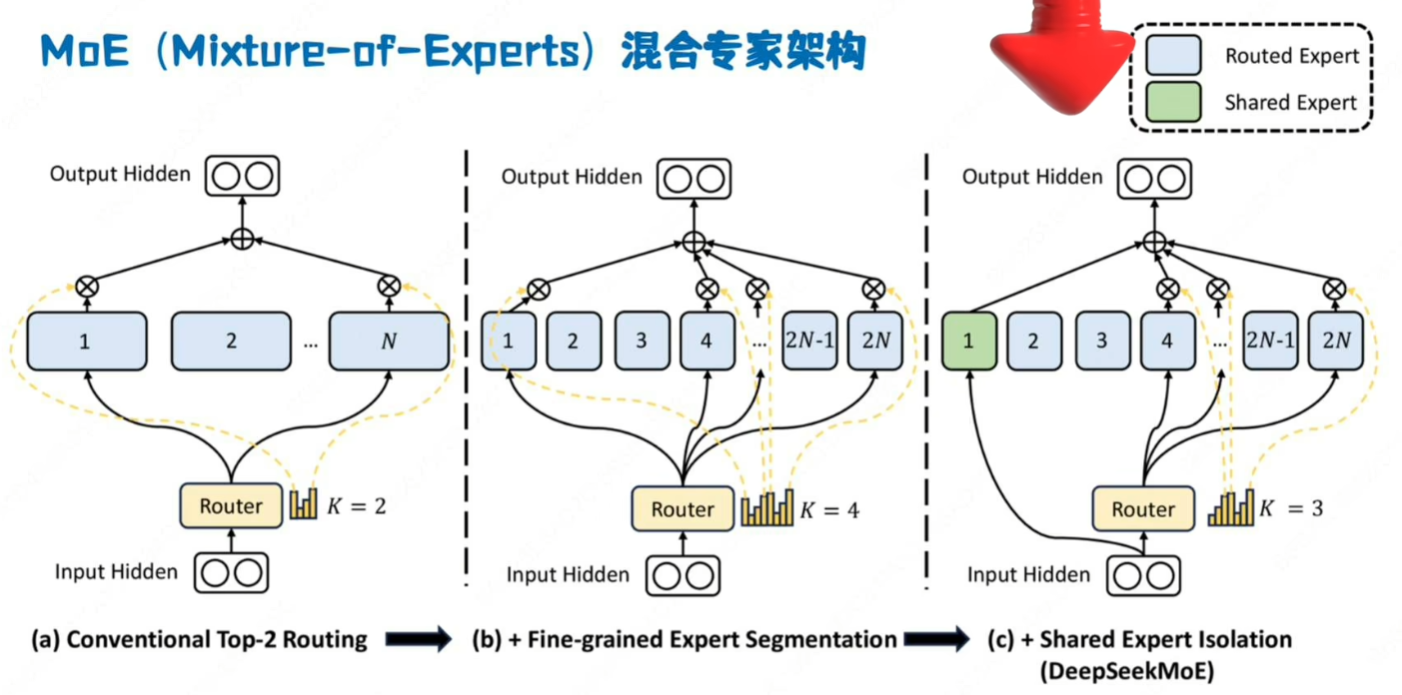
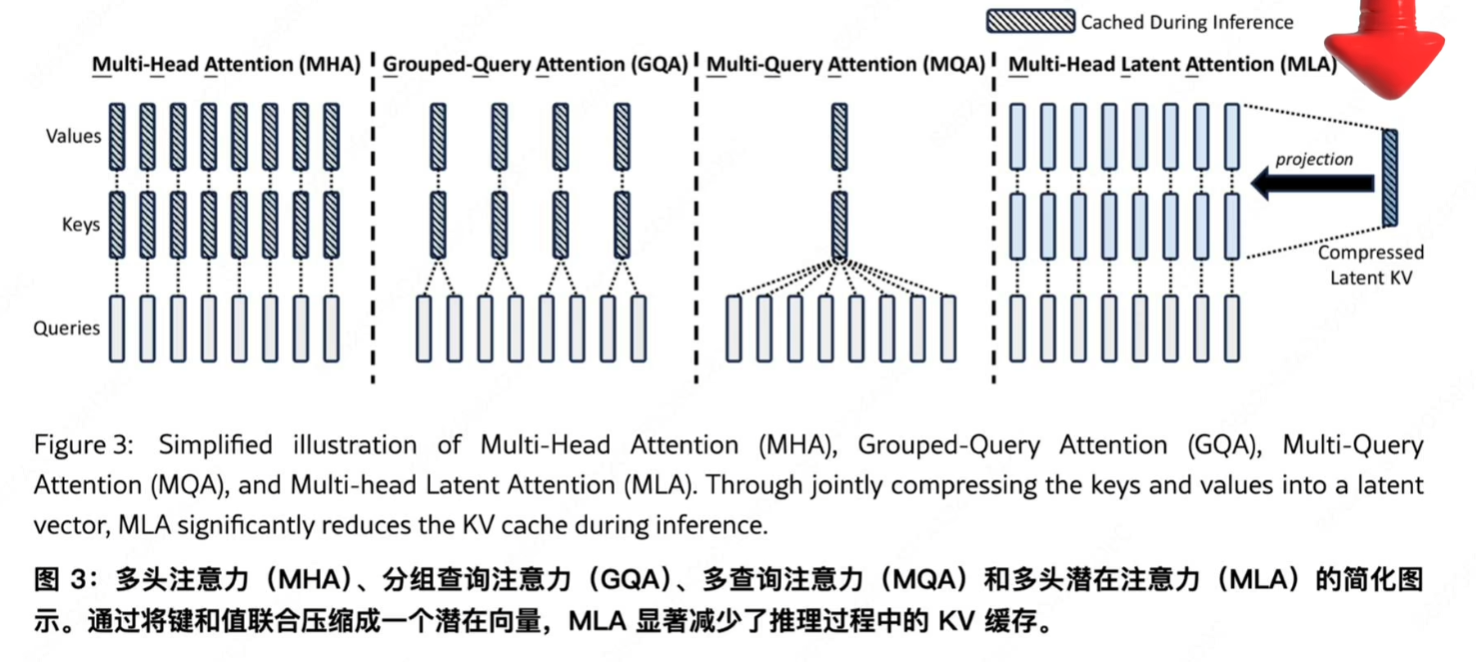
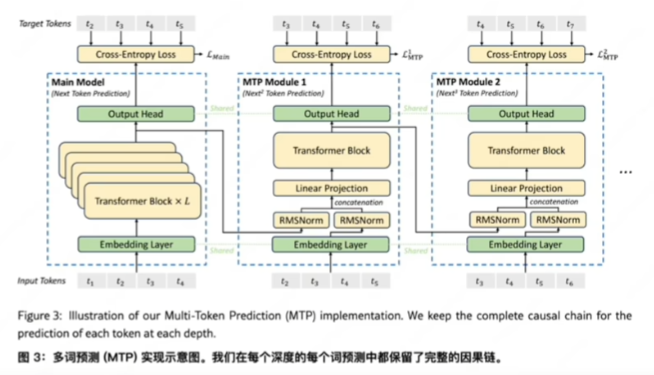
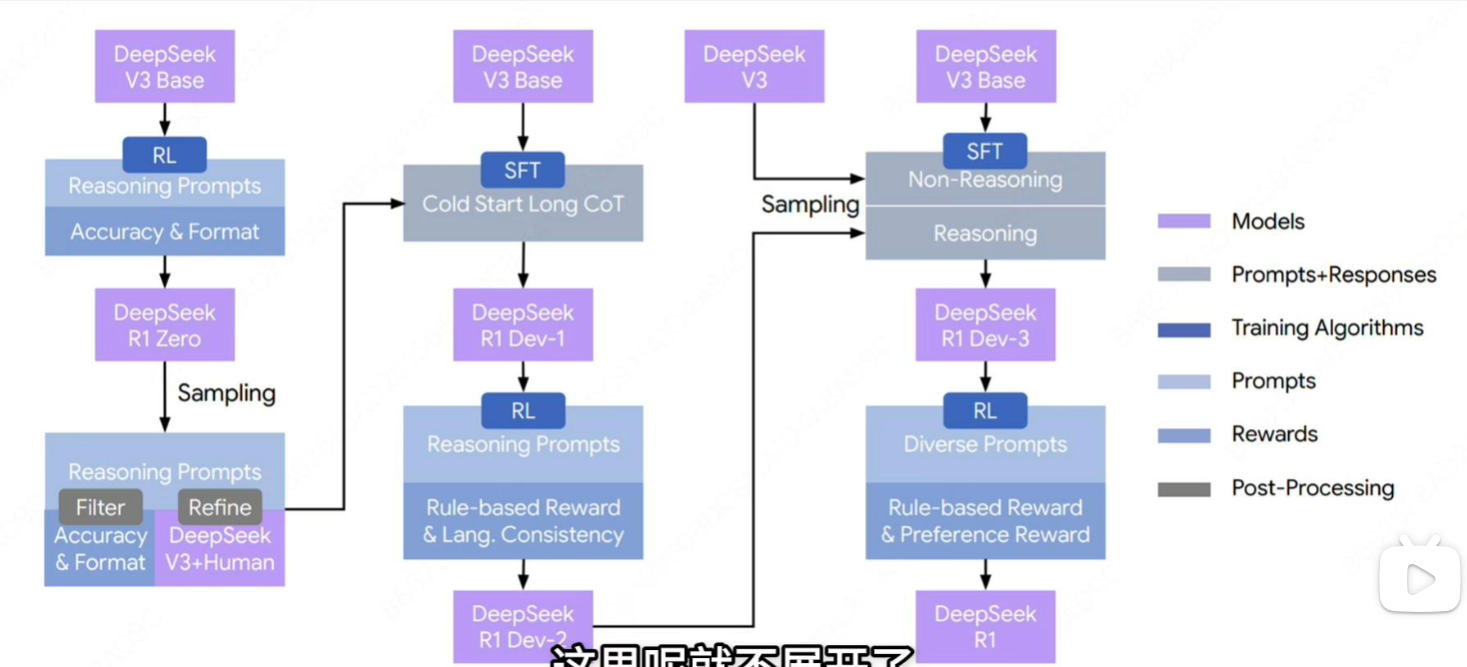
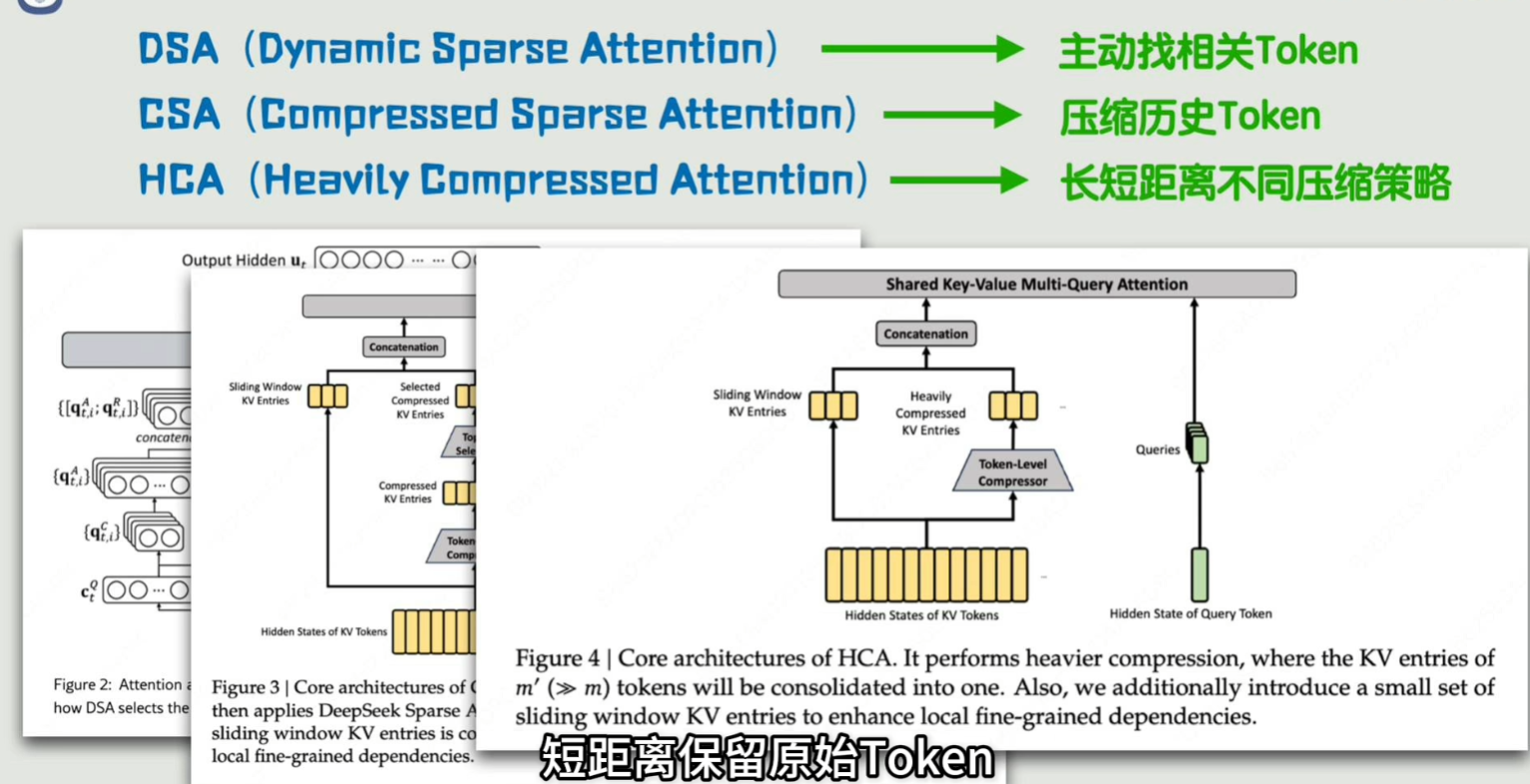
moe,mla,mhc,purerl
参考资料
jsksxs360/How-to-use-Transformers: Transformers 库快速入门教程