tokenizer
什么是 Tokenizer?
Tokenizer(分词器)可以将原始文本(raw text)转换为模型能够理解的数字序列,在模型输入和输出的两个主要阶段中发挥重要作用:
模型输入(编码 Encode)阶段
分词(Tokenize)
将文本拆分为词元(Token),常见的分词方式包括字级、词级、子词级(如 BPE、WordPiece)、空格分词等。
1
2输入: "你好"
分词: ["你", "好"]映射(Mapping)
将每个词元映射为词汇表中的唯一 ID,生成的数字序列即为模型的输入。
1
2分词: ["你", "好"]
映射: [1001, 1002]
模型输出(解码 Decode)阶段
反映射(De-mapping)
模型输出的数字序列通过词汇表映射回对应的词元,二者是一一对应的关系。
1
2输出: [1001, 1002]
反映射: ["你", "好"]文本重组
将解码后的词元以某种规则重新拼接为完整文本。
1
2反映射: ["你", "好"]
重组: "你好"
直观感受
访问 Tiktokenizer,通过右上角选取不同的 Tokenizer 进行尝试
词汇表
两种常见的构建词汇表的方法:
- BPE(Byte-Pair Encoding):用于 GPT、GPT-2、RoBERTa、BART 和 DeBERTa 等模型。
- WordPiece:用于 DistilBERT、MobileBERT、Funnel Transformers 和 MPNET 等模型。
BPE
BPE(Byte Pair Encoding,字节对编码)在 NLP 里是一种贪心式的子词(subword)分词算法。 理解:从“字符”开始,反复把出现次数最多的相邻字符对合并成新的符号,并加入词汇表,直到达到预设的词汇表大小。
为什么可以处理 OOV(Out-Of-Vocabulary)情况
因为所有词汇都是由字符或词根组成的,通过对单个字符的学习,可以组成oov的词汇
为什么需要词汇表
编码时,从文本到模型:需要将文本分词为 Tokens,再通过词汇表将 Tokens 转换为 Token IDs,再传给transformer
解码时,从模型到文本:需要通过词汇表Token IDs 转换为 Tokens,再把Tokens 拼接为文本
步骤
- 初始化词汇表 V:
- V 包含语料库中的所有唯一字符,即单词字符的集合。
- 统计字符对的频次:
- 对于每个单词的字符序列,统计相邻字符对的出现频次。
- 找到频次(Score)最高的字符对并合并:
- 选择出现频率最高的字符对 (x, y),将其合并为新符号 xy。
- 更新词汇表并重复步骤 2 到 4:
- 将新符号添加到词汇表 V = V ∪ {xy}。
- 更新语料库中的单词表示,重复统计和合并过程,直到满足停止条件(例如,词汇表达到预定大小)。
示例
我们需要将语料库(corpus)的文本拆分为单词,假设当前语料库包含的单词和对应频次如下:
1 | ("low", 5), ("lower", 2), ("newest", 6), ("widest", 3) |
步骤 1:初始化词汇表
将单词拆分为字符序列:
1 | ("l", "o", "w"), 5 |
词汇表 V:
1 | {'l', 'o', 'w', 'e', 'r', 'n', 's', 't', 'i', 'd'} |
步骤 2:统计字符对的频次
1 | 字符对频次统计结果: |
步骤 3:找到频次最高的字符对并合并
选择频次最高的字符对:
("e", "s")和("s", "t"),频次均为 9。可以任选其一进行合并,假设选择排序第一的:("e", "s")。
合并 ("e", "s") 为新符号
es。
记录合并操作:
1 | Merge 1: ("e", "s") -> "es" |
步骤 4:更新词汇表并重复
更新单词序列:
1 | ("l", "o", "w"), 5 |
更新词汇表 V:
1 | {'l', 'o', 'w', 'e', 'r', 'n', 's', 't', 'i', 'd', 'es'} |
重复步骤 2 到 4,直到达到预定的词汇表大小。
WordPiece
WordPiece 是 Google 在 2016 年为语音识别与 BERT 提出的子词(subword)分词算法,可看作 BPE 的“似然改进版”。理解:“用概率贪心而不是频次贪心,从字符开始逐步合并子词。”
与 BPE 不同,WordPiece 的 Score 由字符对频次与其组成部分频次的比值决定,定义 Score:
$$ \text{Score}_{\text{WordPiece}}(x, y) = \frac{\text{freq}(xy)}{\text{freq}(x) \times \text{freq}(y)} $$
其中, freq(x), freq(y) 和 freq(xy) 分别表示符号 x, y 和它们合并后的符号 xy 的频次。
步骤
- 初始化词汇表 V:
- 与 BPE 相同, V
包含语料库中的所有唯一字符,但处理方式略有不同:对于每个单词,除了首个字符外,其他字符前都加上
##前缀。
- 与 BPE 相同, V
包含语料库中的所有唯一字符,但处理方式略有不同:对于每个单词,除了首个字符外,其他字符前都加上
- 统计字符对的频次及 Score:
- 对于每个可能的字符对 (x, y),计算 freq(x), freq(y), freq(xy),并计算 Score。
- 找到 Score 最高的字符对并合并:
- 选择 Score 最高的字符对 (x, y),将其合并为新符号
xy,注意:
- 如果第二个符号以
##开头,合并时去掉##前缀再进行连接。 - 新符号是否以
##开头,取决于第一个符号是否以##开头。
- 如果第二个符号以
- 选择 Score 最高的字符对 (x, y),将其合并为新符号
xy,注意:
- 更新词汇表并重复步骤 2 到 4:
- 将新符号添加到词汇表 V = V ∪ {xy}。
- 更新语料库中的单词表示,重复统计和合并过程,直到满足停止条件。
映射(Mapping)
以 BPE 为例,最终词汇表 V 中的 Token 和对应的频次分别为:
1 | vocab = { |
输出:
1 | Token to ID: {'lo': 0, 'w': 1, 'e': 2, 'r': 3, 'n': 4, 'est': 5, 'i': 6, 'd': 7} |
当然,也可以根据频次或者其他规则进行特殊处理。
以上是编码部分的概述,实际上在文本预处理的时候还会增加特殊标记,但这些以及后续的解码部分大多是一些文本处理的规则,这里就不过多赘述了,Tokenizer 之间的核心差异在于使用的分割方法和词汇表的构建策略。
transformer中的分词
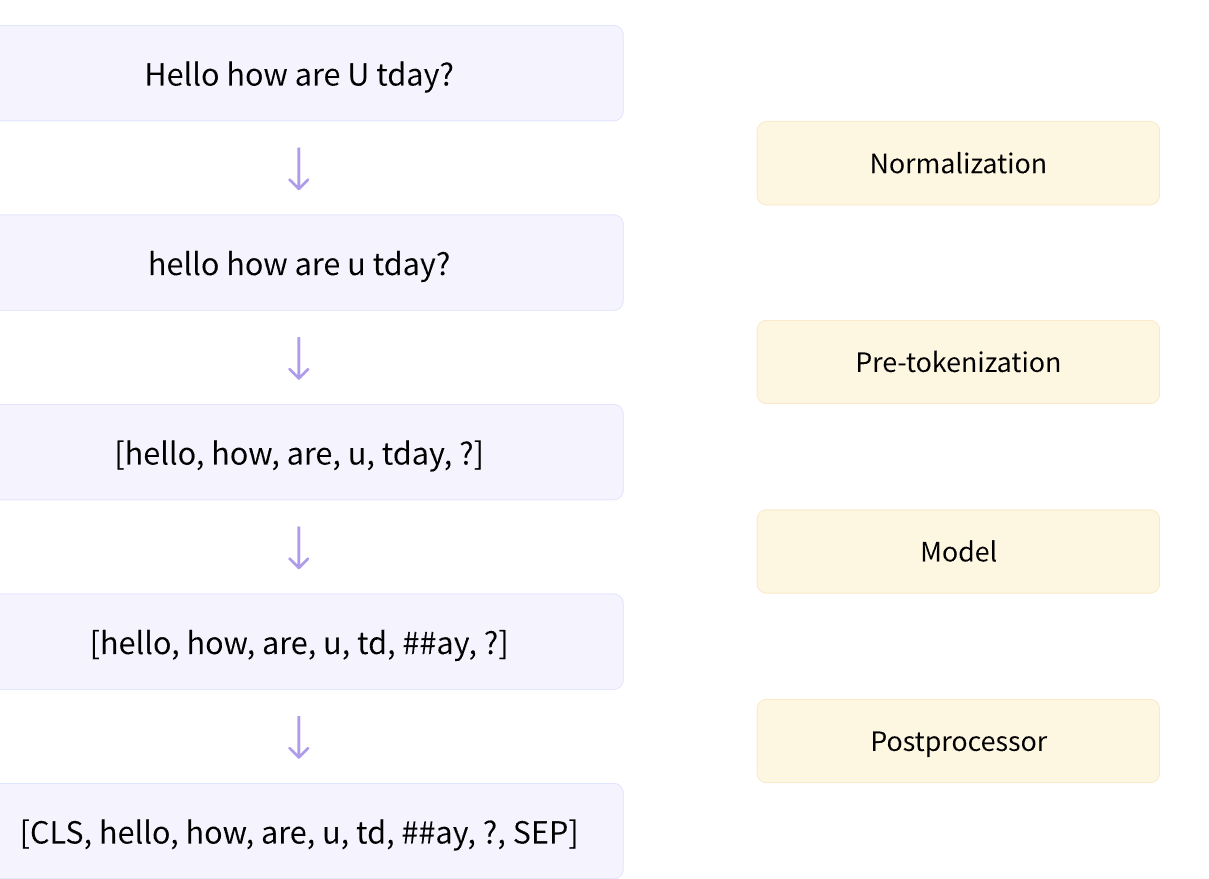
在 Transformers 中,分词(tokenization) 实际上包含以下几个步骤:
- 标准化(Normalization):对文本进行必要的清理操作,例如删除多余空格或重音符号、进行 Unicode 标准化等。
- 预分词(Pre-tokenization):将输入拆分为单词。
- 通过模型处理输入(Running the input through the model):使用预分词后的单词生成一系列词元(tokens)。
- 后处理(Post-processing):添加分词器的特殊标记,生成注意力掩码(attention mask)和词元类型 ID(token type IDs)。
流程图如下
注意力掩码(Attention Mask)和词元类型 ID (Token Type IDs)是什么?
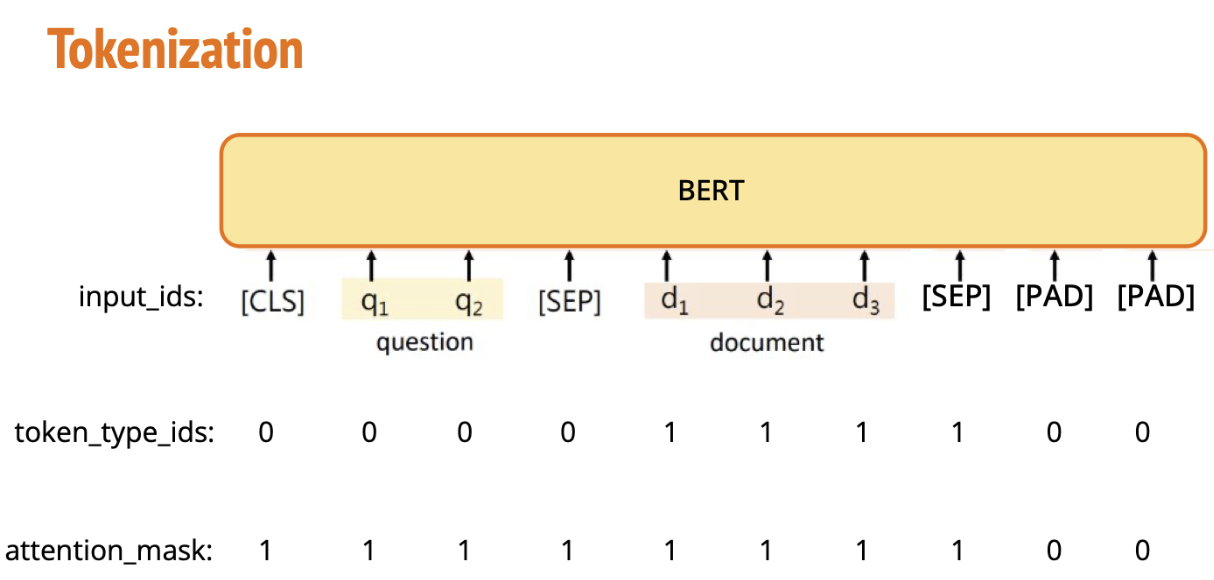
1️⃣ 注意力掩码(Attention Mask) •
目的:告诉模型“哪些位置可以被看到”,其余位置直接屏蔽。 • 典型场景: –
自注意力里做 padding 掩码:把 <pad>
对应的位置设为 −∞,softmax 后权重=0。 –
解码器自回归掩码:生成任务用下三角掩码,避免第 i 个
token 看到未来 token。
2️⃣ 词元类型 ID(Token Type IDs,也叫 Segment IDs) •
目的:区分同一次输入里不同句子或段落,让模型知道“这段属于
A,那段属于 B”。 • 典型场景: – BERT
做句子对分类(NSP):[CLS] 句子A [SEP] 句子B [SEP] → TypeID
= 0 0 0 0 1 1 1。 – RoBERTa、GPT 等单句模型则不需要
Token Type IDs。
注意力掩码确保模型只关注实际的词元,忽略填充部分,从而避免无效的计算:
- 1:表示模型应关注的词元(Tokens)
- 0:表示模型应忽略的词元(通常是填充
padding的部分)。
词元类型 ID 用于区分输入中的不同句子或段落:
- 0:表示第一个句子的词元。
- 1:表示第二个句子的词元。
CLS,SEP,PAD都是什么意思
[CLS](Classification),作用:对应位置的隐藏状态被当作整句/句对的“整体表示”,用来接分类头做句子级任务(情感分类、NLI 等)。
[SEP](Separator),作用:让模型知道分段 / 句子边界,配合 Token Type IDs 区分句子 A 和句子 B。
[PAD](padding token)的作用是 批量训练时把不同长度的序列补齐到同一长度,让张量可以堆叠成规整的矩阵;模型在计算注意力时通过 Attention Mask 把[PAD]对应的位置屏蔽掉,不让它们影响有效 token 的表示。
rag embedding与llm embedding
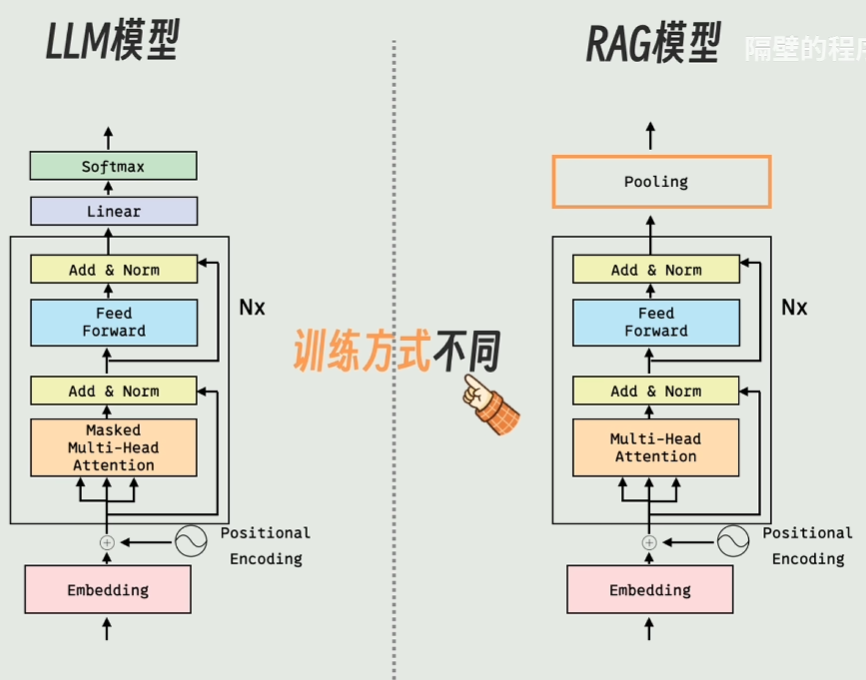
这个问题非常切中本质。虽然 RAG 的 Embedding 模型和 LLM(大语言模型)底层通常都基于 Transformer 架构,但它们在设计目的、输出形态以及训练范式上有着根本的分歧。
可以将 LLM 的 Embedding 视作“字词级的基础翻译官”,而 RAG 的 Embedding 则是“篇章级的语义指纹提取器”。
以下是它们核心不同点的深度剖析:
1. 核心目的与作用的不同
| 维度 | LLM Embedding (如 Llama/GPT 的输入层) | RAG Embedding (如 BGE, OpenAI text-embedding) |
|---|---|---|
| 核心目的 | 将离散的 Token(字/词汇)转换为连续向量,为模型后续的自注意力机制计算做准备。 | 将一整段文本(句子/段落/文档)压缩成一个固定维度的向量,用于计算文本间的相似度。 |
| 表示层级 | Token 级别(词元级)。 | Chunk/Sentence 级别(段落/句子级)。 |
| 输出形态 | 输入 N 个 Token,输出
N 个向量。形状通常为
[Sequence_Length, Hidden_Dim]。 |
输入 N 个 Token
的段落,通过池化(Pooling)输出 1 个综合向量。形状为
[1, Hidden_Dim]。 |
| 工程角色 | 是 LLM 内部的一个组件(权重矩阵 V × d),不可独立拆解使用。 | 是一个独立的模型服务,专为检索系统(如向量数据库)提供特征提取。 |
2. 训练方式的区别 (The “How”)
它们之所以有上述的差异,根本原因在于训练目标(Loss Function)完全不同。
LLM Embedding 的训练:自监督预测 (Self-Supervised Learning)
LLM 的 Embedding 是在训练整个大模型时“顺带”训练出来的。
- 训练目标: 典型的生成式模型(如 GPT 系列)使用的是下一个词预测(Next-Token Prediction)。
- 训练过程: 模型读取一段上文,尝试预测下一个 Token 是什么。系统计算预测概率分布与真实下一个 Token 之间的交叉熵损失(Cross-Entropy Loss),然后通过反向传播更新网络中所有的参数,包括最底层的 Embedding 矩阵。
- 结果特性: 这种训练使得 LLM 的 Embedding 极度擅长捕捉语法结构、词性关联以及上下文搭配。它知道“苹果”和“手机”在某些语境下经常一起出现。
RAG Embedding 的训练:对比学习 (Contrastive Learning)
RAG 使用的 Embedding 模型(通常是类似 BERT 的编码器架构)需要经历专门的对比学习训练,这是它具备强大检索能力的关键。
训练目标: 并非预测下一个词,而是拉近相似文本的距离,推远不相关文本的距离。
训练过程: 通常采用 InfoNCE Loss 等对比损失函数。训练数据需要组织成三元组:
(Query, Positive_Document, Negative_Document)。Query (锚点): 用户的查询语句。
Positive (正样本): 真正能回答该查询的文档段落。
Negative (负样本): 干扰项,特别是“困难负样本(Hard Negatives)”——那些字面上有重合但语义不相关的文档。
数学直觉: 优化目标是最大化正样本对的余弦相似度,同时最小化负样本对的相似度:
$$ L = -\log \frac{e^{\text{sim}(q, p)/\tau}}{e^{\text{sim}(q, p)/\tau} + \sum_{i=1}^{K} e^{\text{sim}(q, n_i)/\tau}} $$
结果特性: 这种训练强制模型放弃局部的语法细节,去提取宏观的中心思想和语义匹配度。
总结来说:
LLM Embedding 的使命是“理解字词的组合规律以生成文本”,因此采用自监督的序列预测训练;而 RAG Embedding 的使命是“判断段落之间的语义等价性以实现精准检索”,因此必须依赖高质量正负样本的对比学习训练。