大模型训练流程
什么是大模型
随着2022年底 ChatGPT 再一次刷新 NLP 的能力上限,大语言模型(Large Language Model,LLM)开始接替传统的预训练语言模型(Pre-trained Language Model,PLM) 成为 NLP 的主流方向,基于 LLM 的全新研究范式也正在刷新被 BERT 发扬光大的预训练-微调范式,NLP 由此迎来又一次翻天覆地的变化。
LLM,即 Large Language Model,中文名为大语言模型或大型语言模型,是一种相较传统语言模型参数量更多、在更大规模语料上进行预训练的语言模型。
一般来说,LLM 指包含数百亿(或更多)参数的语言模型,它们往往在数 T token 语料上通过多卡分布式集群进行预训练,具备远超出传统预训练模型的文本理解与生成能力。不过,随着 LLM 研究的不断深入,多种参数尺寸的 LLM 逐渐丰富,广义的 LLM 一般覆盖了从十亿参数(如 Qwen-1.5B)到千亿参数(如 Grok-314B)的所有大型语言模型。只要模型展现出涌现能力,即在一系列复杂任务上表现出远超传统预训练模型(如 BERT、T5)的能力与潜力,都可以称之为 LLM。
一般认为,GPT-3(1750亿参数)是 LLM 的开端,基于 GPT-3 通过 预训练(Pretraining)、监督微调(Supervised Fine-Tuning,SFT)、强化学习与人类反馈(Reinforcement Learning with Human Feedback,RLHF)三阶段训练得到的 ChatGPT 更是主导了 LLM 时代的到来。
区分 LLM 与传统 PLM 最显著的特征即是 LLM 具备
涌现能力。涌现能力是指同样的模型架构与预训练任务下,某些能力在小型模型中不明显,但在大型模型中特别突出。
训练流程
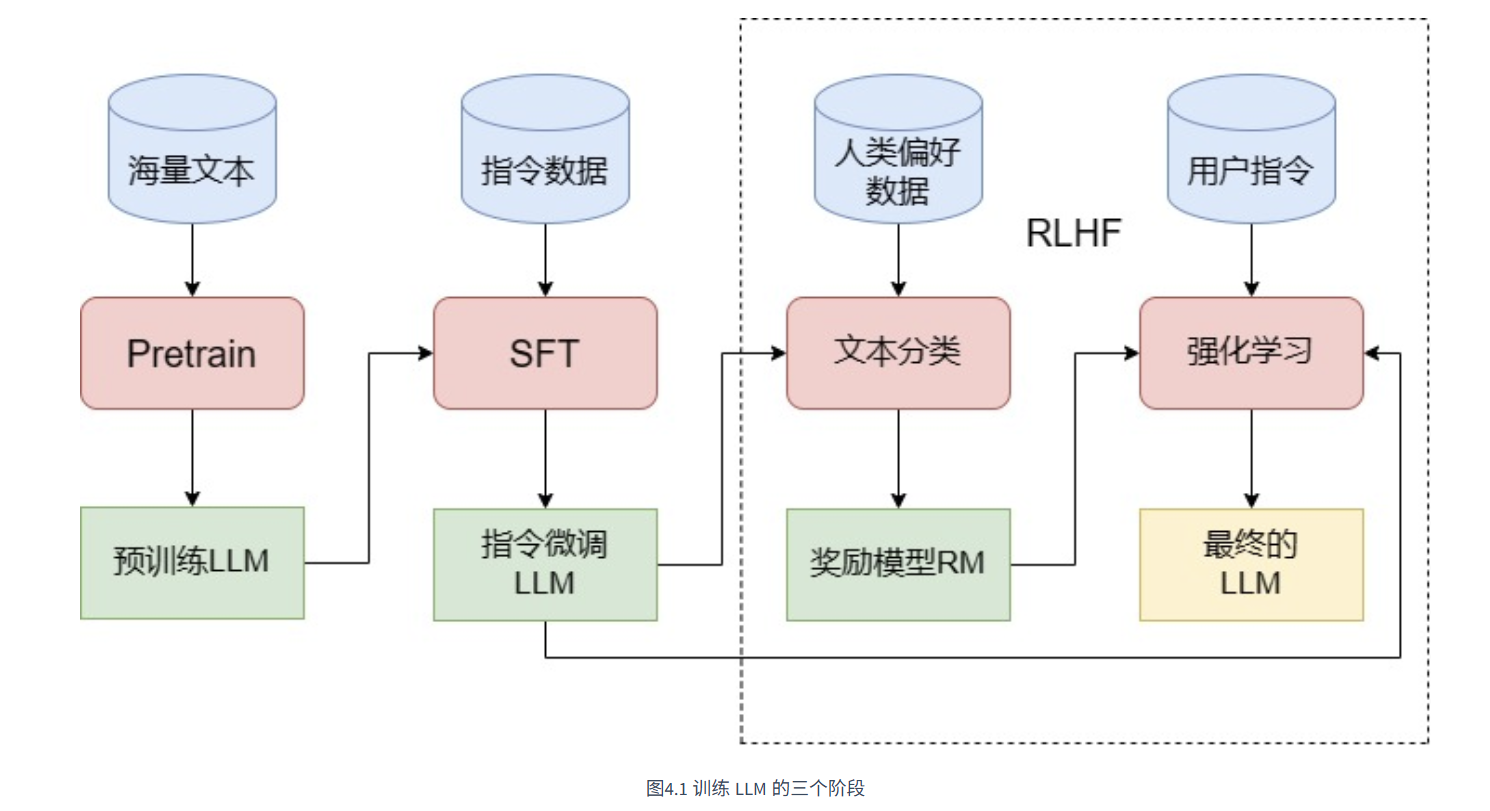
一般而言,训练一个完整的 LLM 需要经过图1中的三个阶段——Pretrain、SFT 和 RLHF。
Pretrain
Pretrain,即预训练,是训练 LLM 最核心也是工程量最大的第一步。
参数
| 模型 | hidden_layers | hidden_size | heads | 整体参数量 | 预训练数据量 |
|---|---|---|---|---|---|
| BERT-base | 12 | 768 | 12 | 0.1B | 3B |
| BERT-large | 24 | 1024 | 16 | 0.3B | 3B |
| Qwen-1.8B | 24 | 2048 | 16 | 1.8B | 2.2T |
| LLaMA-7B | 32 | 4096 | 32 | 7B | 1T |
| GPT-3 | 96 | 12288 | 96 | 175B | 300B |
根据定义,LLM 的核心特点即在于其具有远超传统预训练模型的参数量,同时在更海量的语料上进行预训练。传统预训练模型如 BERT,有 base 和 large 两个版本。BERT-base 模型由 12个 Encoder 层组成,其 hidden_size 为 768,使用 12个头作为多头注意力层,整体参数量为 1亿(110M);而 BERT-large 模型由 24个 Encoder 层组成,hidden_size 为 1024,有 16个头,整体参数量为 3亿(340M)。同时,BERT 预训练使用了 33亿(3B)token 的语料,在 64块 TPU 上训练了 4天。事实上,相对于传统的深度学习模型,3亿参数量、33亿训练数据的 BERT 已经是一个能力超群、资源消耗巨大的庞然大物。
但是,前面我们提到,一般而言的 LLM 通常具有数百亿甚至上千亿参数,即使是广义上最小的 LLM,一般也有十亿(1B)以上的参数量。例如以开山之作 GPT-3 为例,其有 96个 Decoder 层,12288 的 hidden_size 和 96个头,共有 1750亿(175B)参数,比 BERT 大出快 3个数量级。即使是目前流行的小型 LLM 如 Qwen-1.8B,其也有 24个 Decoder 层、2048的 hidden_size 和 16个注意力头,整体参数量达到 18亿(1.8B)。
分布式训练
也正因如此,分布式训练框架也成为 LLM 训练必不可少的组成部分。分布式训练框架的核心思路是数据并行和模型并行。所谓数据并行,是指训练模型的尺寸可以被单个 GPU 内存容纳,但是由于增大训练的 batch_size 会增大显存开销,无法使用较大的 batch_size 进行训练;同时,训练数据量非常大,使用单张 GPU 训练时长难以接受。
数据集
训练数据本身也是预训练 LLM 的一个重大挑战。训练一个 LLM,至少需要数百 B 甚至上 T 的预训练语料。根据研究,LLM 所掌握的知识绝大部分都是在预训练过程中学会的,因此,为了使训练出的 LLM 能够覆盖尽可能广的知识面,预训练语料需要组织多种来源的数据,并以一定比例进行混合。目前,主要的开源预训练语料包括 CommonCrawl、C4、Github、Wikipedia 等。不同的 LLM 往往会在开源预训练语料基础上,加入部分私有高质量语料,再基于自己实验得到的最佳配比来构造预训练数据集。事实上,数据配比向来是预训练 LLM 的“核心秘籍”,不同的配比往往会相当大程度影响最终模型训练出来的性能。
训练一个中文 LLM,训练数据的难度会更大。目前,高质量语料还是大部分集中在英文范畴,例如上表的 Wikipedia、Arxiv 等,均是英文数据集;而 C4 等多语言数据集中,英文语料也占据主要地位。目前开源的中文 LLM 如 ChatGLM、Baichuan 等模型均未开放其预训练数据集,开源的中文预训练数据集目前仅有昆仑天工开源的SkyPile(150B)、中科闻歌开源的yayi2(100B)等,相较于英文开源数据集有明显差距。
数据清洗
预训练数据的处理与清洗也是 LLM 预训练的一个重要环节。诸多研究证明,预训练数据的质量往往比体量更加重要。预训练数据处理一般包括以下流程:
- 文档准备。由于海量预训练语料往往是从互联网上获得,一般需要从爬取的网站来获得自然语言文档。文档准备主要包括 URL 过滤(根据网页 URL 过滤掉有害内容)、文档提取(从 HTML 中提取纯文本)、语言选择(确定提取的文本的语种)等。
- 语料过滤。语料过滤的核心目的是去除低质量、无意义、有毒有害的内容,例如乱码、广告等。语料过滤一般有两种方法:基于模型的方法,即通过高质量语料库训练一个文本分类器进行过滤;基于启发式的方法,一般通过人工定义 web 内容的质量指标,计算语料的指标值来进行过滤。
- 语料去重。实验表示,大量重复文本会显著影响模型的泛化能力,因此,语料去重即删除训练语料中相似度非常高的文档,也是必不可少的一个步骤。去重一般基于 hash 算法计算数据集内部或跨数据集的文档相似性,将相似性大于指定阈值的文档去除;也可以基于子串在序列级进行精确匹配去重。
SFT 指令微调
预训练赋予了 LLM 能力,却还需要第二步将其激发出来。经过预训练的 LLM 好像一个博览群书但又不求甚解的书生,对什么样的偏怪问题,都可以流畅地接出下文,但他偏偏又不知道问题本身的含义,只会“死板背书”。这一现象的本质是因为,LLM 的预训练任务就是经典的 CLM,也就是训练其预测下一个 token 的能力,在没有进一步微调之前,其无法与其他下游任务或是用户指令适配。
因此,我们还需要第二步来教这个博览群书的学生如何去使用它的知识,也就是 SFT(Supervised Fine-Tuning,有监督微调)。
面对能力强大的
LLM,我们往往不再是在指定下游任务上构造有监督数据进行微调,而是选择训练模型的“通用指令遵循能力”,也就是一般通过指令微调的方式来进行
SFT。
所谓指令微调,即我们训练的输入是各种类型的用户指令,而需要模型拟合的输出则是我们希望模型在收到该指令后做出的回复。例如,我们的一条训练样本可以是:
1 | input:告诉我今天的天气预报? |
也就是说,SFT 的主要目标是让模型从多种类型、多种风格的指令中获得泛化的指令遵循能力,也就是能够理解并回复用户的指令。
RLHF
RLHF,全称是 Reinforcement Learning from Human Feedback,即人类反馈强化学习,是利用强化学习来训练 LLM 的关键步骤。相较于在 GPT-3 就已经初见雏形的 SFT,RLHF 往往被认为是 ChatGPT 相较于 GPT-3 的最核心突破。事实上,从功能上出发,我们可以将 LLM 的训练过程分成预训练与对齐(alignment)两个阶段。预训练的核心作用是赋予模型海量的知识,而所谓对齐,其实就是让模型与人类价值观一致,从而输出人类希望其输出的内容。在这个过程中,SFT 是让 LLM 和人类的指令对齐,从而具有指令遵循能力;而 RLHF 则是从更深层次令 LLM 和人类价值观对齐,令其达到安全、有用、无害的核心标准。
RLHF 分为两个步骤:训练 RM 和 PPO 训练。
RM,Reward Model,即奖励模型。RM 是用于拟合人类偏好,来给 LLM 做出反馈的。在强化学习的训练中,对于 LLM 的每一个回复,RM 会进行打分,这个打分反映了生成回复符合人类偏好的程度。然后 LLM 会根据强化学习的原理,基于 RM 的打分来进行优化训练。
在完成 RM 训练之后,就可以使用 PPO 算法来进行强化学习训练。PPO,Proximal Policy Optimization,近端策略优化算法,是一种经典的 RL 算法。事实上,强化学习训练时也可以使用其他的强化学习算法,但目前 PPO 算法因为成熟、成本较低,还是最适合 RLHF 的算法。