分布式训练qwen3-32b
训练框架-LLaMA-Factor
docker部署镜像,以便后续传入内网
1 | git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git |
1 | docker pull docker.1ms.run/hiyouga/llamafactory |
LLaMA Board 可视化微调(由 Gradio 驱动)
1 | llamafactory-cli webui |
- Web UI 访问:
http://localhost:7860 - API 服务访问:
http://localhost:8001
数据集-easy-dataset
docker部署镜像,以便后续传入内网
1 | git clone https://github.com/ConardLi/easy-dataset.git |
注意: 请将
{YOUR_LOCAL_DB_PATH}、{LOCAL_PRISMA_PATH}替换为你希望存储本地数据库的实际路径,建议直接使用当前代码仓库目录下的local-db和prisma文件夹,这样可以和 NPM 启动时的数据库路径保持一致。
注意: 如果需要挂载数据库文件(PRISMA),需要提前执行
npm run db:push初始化数据库文件。
使用开源项目制作数据集
打开浏览器,访问 http://localhost:1717
上传内网
使用scp
1 | scp -r "F:\project python\实习\微调\universal-llm_latest.tar" root@10.117.128.50:/aisys/repo_dev/xizhang/images |
SCP 全称是 Secure Copy Protocol(安全复制协议),是一种用于在计算机之间安全地复制文件的网络协议。
它基于 SSH(Secure Shell)协议工作,因此所有传输的数据都是加密的,可以防止被窃听或篡改,非常适合在不安全的网络(如互联网)中使用。
模型部署与调用
制作模型运行镜像
qwen3部署版本要求如下
使用 Python 3.10 或以上版本, PyTorch 2.6 或以上版本
transformers>=4.51.0 版本
使用 sglang>=0.4.6.post1 或
vllm>=0.8.5 来创建一个与 OpenAI 兼容的 API 端点
镜像信息
| 类别 | 组件 | 版本 / 来源 | 说明 |
|---|---|---|---|
| OS | Ubuntu | 22.04 LTS (Jammy) | 上游镜像继承 |
| Python | CPython | 3.11 | 镜像自带 |
| PyTorch | PyTorch | 2.6.0+cu126 | 官方 wheel,CUDA 12.6 |
| CUDA | Runtime | 12.6.3 | 与宿主机 535 驱动兼容 |
| cuDNN | cuDNN | 9 | 包含在镜像 |
| 核心库 | transformers | ≥4.51.0 | 官方最新 |
| tokenizers | ≥0.21 | transformers 依赖 | |
| accelerate | ≥1.0.0 | 训练 / 推理加速 | |
| sentencepiece | ≥0.2.0 | Qwen3 分词器必需 | |
| protobuf | ≥5.28.0 | 序列化 / 模型加载 | |
| tiktoken | ≥0.8.0 | OpenAI 格式分词 | |
| 推理框架 | vLLM | ≥0.8.5 | 支持 tensor-parallel、PagedAttention |
| SGLang | ≥0.4.6.post1 | 支持 outline 解码、MoE 优化 | |
| 可选加速 | flash-attn | ≥2.7 | 长上下文 / 大 batch 推理 |
| 权重下载 | modelscope | 最新 | 国内镜像加速 |
| 工具链 | git / git-lfs | 最新 | 拉取 HuggingFace 权重 |
| curl / jq / vim | 最新 | 调试 & 健康检查 |
基础镜像pytorch/pytorch:2.6.0-cuda12.6-cudnn9-devel
是 PyTorch 官方在 Docker Hub
上提供的“全家桶”开发镜像,发布日期 2025-01-29,镜像大小约 13
GB,定位是 “开箱即用”的 GPU 训练 / 推理 / 调试环境
dockerfile
1 | # ---------- 1. 基础镜像 ---------- |
运行容器
1 | docker run -it \ |
vllm部署qwen3
1 | vllm serve /app/models/qwen3-32b-lora-new \ |
| 参数 | 含义 | 推荐/注意 |
|---|---|---|
--port 8000 |
服务监听端口 | 与 -p 8000:8000 保持一致;如需多实例,可改 8001/8002
… |
--tensor-parallel-size 4 |
把模型权重切成 4 份,跨 4 张 GPU 并行计算 | 必须 ≤ 实际 GPU 数量;Qwen3-32B 在 4×L20 上显存刚好够,不可再大 |
--max-model-len 1024 |
单次推理最大 token 数(含 prompt + 生成) | 若场景需要 4k/8k/32k,可调到 4096/8192;显存占用 ∝ 长度² |
--reasoning-parser qwen3 |
vLLM ≥0.8.5 新增开关,解析 Qwen3 的
<think>…</think> 标签,把推理过程单独返回 |
仅在 Qwen3 系列模型有效,其他模型请去掉 |
--gpu-memory-utilization 0.8 |
显存使用上限 80 %;剩余 20 % 留给 CUDA kernel、KV cache 膨胀 | 若出现 OOM,可降到 0.7;若想多并发,可尝试 0.85(风险 OOM) |
--max-num-seqs 8 |
同一时刻最多并发处理的 请求条数 | 与 --max-model-len 和显存同时决定;若长度 ↑,此值需
↓ |
--host 0.0.0.0 |
监听所有网卡,使容器外可访问 | 生产环境可改为内网 IP 或 127.0.0.1 提高安全性 |
测试
1 | curl http://localhost:4001/v1/chat/completions \ |
调用
1 | import os |
快速入门 - Qwen — Quickstart - Qwen
微调数据集
alpaca和sharegpt的区别
▶ Alpaca 典型字段
1 | { |
- 一条数据 = 一次独立任务
- 字段固定:
instruction / input / output三板斧
▶ ShareGPT 典型字段
1 | { |
- 一条数据 = 一段完整的多轮对话
- 角色交替:
human / gpt / function / observation等
| 维度 | Alpaca | ShareGPT |
|---|---|---|
| 来源 | 斯坦福 Alpaca 项目,为了低成本做指令微调 | ShareGPT 网站爬取的真实 ChatGPT 对话 |
| 目标 | 让模型学会“看到指令+输入→给出答案” | 让模型学会“像 ChatGPT 一样多轮对话” |
详解
1 | { |
instruction为问题;input为上下文;output包含思维链与答案;system为系统提示词
微调参数设置
DeepSpeed stage(DeepSpeed 阶段)
deepSpeed 的 ZeRO 分布式优化阶段,用于在多 GPU 上高效训练大模型。
| Stage | 功能 | 说明 |
|---|---|---|
| Stage 0 | 不做任何优化 | 基础分布式训练(DDP),显存占用高 |
| Stage 1 | 梯度分片(Gradient Sharding) | 将梯度切分到不同 GPU,减少显存 |
| Stage 2 | 参数 + 梯度分片 | 进一步降低显存,但需通信同步 |
| Stage 3 | ✅ 参数 + 梯度 + 优化器状态分片 | 最强显存优化,支持超大模型 |
使用 DeepSpeed offload(使用 offload)
将 部分或全部模型参数、优化器状态卸载到 CPU 内存,进一步释放 GPU 显存。
1 | llamafactory-cli train \ |
训练结果
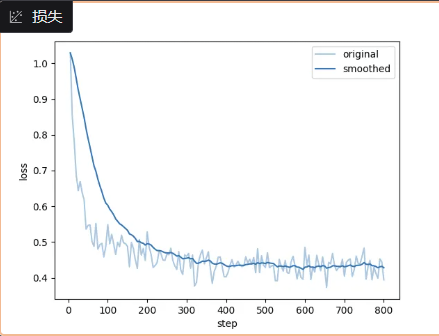
评估
不知道为什么使用llamafactory的评估会爆显存,我怀疑是因为那个webui评估可能不支持多卡,就进行一下人工评估吧
输入
微调模型

初始模型

在内网计算节点访问SwanLab Cloud
在内网计算节点访问SwanLab Cloud | SwanLab官方文档
如何计算训练步数
1. 训练集样本量
公式 训练集样本量 = 总数据量 × (1 − 验证集比例)
示例 总数据 2876 条,验证集占 15% 2876 × (1 − 0.15) = 2876 × 0.85 = 2446 条
2. 每次参数更新处理的样本数(effective batch size)
公式 每次更新样本数 = 单设备批次大小 × GPU 数 × 梯度累积步数
示例
- per_device_train_batch_size = 1
- GPU 数 = 2
- gradient_accumulation_steps = 8
1 × 2 × 8 = 16 条
通俗理解: GPU 一次只能看 1 条 → 2 卡并行就是 2 条 → 累积 8 次才更新一次参数,所以一次更新真正看了 16 条数据。
3. 每轮(epoch)的训练步数
公式 每轮步数 = ⌊ 训练集样本量 ÷ 每次更新样本数 ⌋ (⌊ ⌋ 表示向下取整)
示例 2446 ÷ 16 = 152.875 → 152 步
4. 总训练步数
公式 总步数 = 每轮步数 × 训练轮数 (epochs)
示例 152 × 3 = 456 步
如何计算一个模型占用的显存
基础模型的权重
- 定义:预训练模型的参数矩阵,即选择的预训练模型所占用显存的大小。
- 计算公式: 显存占用 = 模型参数数量 × 单个参数的字节数
常见模型精度下的单个参数显存占用:
表格
复制
| 精度类型 | 二进制位数 | 字节数 |
|---|---|---|
| FP32 | 32位 | 4字节 |
| FP16 | 16位 | 2字节 |
| BF16 | 16位 | 2字节(指数位同FP32) |
| INT8 | 8位 | 1字节 |
| INT4 | 4位 | 0.5字节 |
| INT2 | 2位 | 0.25字节 |
例如
- 模型选择:Qwen2.5-7B-Instruct
- 参数规模:70亿(7B)
- 计算精度:BF16(2字节/参数)
- 预估显存占用: 70亿 × 2字节 = 140亿字节 = 14GB
框架开销(Framework Overhead)
- 定义:LLaMAFactory 底层使用的深度学习框架(如 PyTorch)本身的显存占用。
- 包含内容:
- 张量缓存
- 线程资源
- 内核调度开销
- 自动微分图结构等
- 计算方法:难以精确计算
- 估算方法:通常占用不大,默认估算为 1 GB
LoRA 适配器(LoRA Adapters)
定义:在 LoRA 微调中,不直接修改原始模型的庞大权重,而是插入轻量级的“LoRA适配器模块”来学习微调所需的变化。
计算方法:
显存占用=LoRA层数×秩(Rank)×(输入维度+输出维度)×2B
估算方法:
- 与 LoRA 的秩(Rank)大小相关
- 一般占用不大,常规配置下通常不超过 0.5 GB,保守估计为 0.5 GB
激活值(Activations)
定义:前向传播过程中各层的输出张量(如隐藏层状态、注意力矩阵等),即模型“处理数据时产生的所有中间结果”。
计算方法:
显存占用=批量大小×序列长度×隐藏层维度×模型层数×单个元素字节数
估算方法:
- 单次处理的 Token 量每增加 1K,显存约增加 2.5 GB
- 与单 GPU 的批量大小和数据集的截断长度(序列长度)正相关
- 在固定其他配置(基础模型权重、框架开销、LoRA适配器)后,剩余显存即为激活值占用
加速方式
| 加速方式 | 全称 / 来源 | 核心原理与特点 | 适用场景与注意事项 |
|---|---|---|---|
| auto | 自动选择 | 由框架(如 transformers、LLaMA-Factory、DeepSpeed 等)根据当前硬件、驱动、CUDA 版本自动挑选最快的可用算子或路径。 优点:零配置、开箱即用;缺点:不一定能启用最新、最快的内核。 | 初次实验、不想手动调参时首选。 |
| flashattn2 | FlashAttention-2 | 通过 IO-Aware 的算法和 GPU Tensor Core 优化,将标准 Multi-Head
Attention 的显存访问次数大幅降低,从而显著加快训练/推理速度(通常
2-4×),并减少显存占用。 需要 A100、H100、RTX 30/40 系列等
Ampere/Lovelace 架构;依赖 CUDA≥11.8、PyTorch≥2.0 且需安装
flash-attn wheel。 |
训练/微调 LLM 时首选;序列越长收益越大。若编译失败可退回 xformers 或原生实现。 |
| unsloth | Unsloth 开源库 | 针对 Llama、Mistral、Qwen 等架构,使用动态量化、手工 fused-kernel
和梯度检查点优化,使 LoRA 微调在消费级 GPU 上也能跑更大
batch/更长序列。官方宣称速度提升 2-5×,显存节省 50-70%。
安装简单:pip install unsloth(会自动替换部分 PyTorch
层)。 |
单卡 4090/3090 上 LoRA 微调 7B-13B 模型效果最佳;目前仅支持有限模型。 |
| liger_kernel | Liger-Kernel(微软开源) | 以 Triton 编写的高性能 fused-kernel 合集(SwiGLU、RMSNorm、CrossEntropy、RoPE 等),在保持数值精度的同时减少 kernel launch 和显存写回,训练吞吐量可提升 10-20%。 纯 Python/Triton 实现,无需额外 CUDA 编译。 | 对训练框架侵入性小,可与 FlashAttention 并存;适合想“无痛”提速 10-20% 的场景。 |