qwen3-8b微调实战
前言
在完成微调前备知识的学习后,正式开始使用unsloth对Qwen3-8B-unsloth-bnb-4bit模型的lora微调实战
模型加载
1 | from unsloth import FastLanguageModel |
FastLanguageModel是 Unsloth 框架的核心入口类,即“把 Hugging Face 的 transformers 模型‘加速’成支持 QLoRA 微调、显存占用减半、速度提升 2-5 倍的封装器。”
max_seq_length = 8192作用:告诉框架 “后续所有输入序列的最大长度”。内部一次性为位置编码、注意力掩码、KV-Cache 等开辟的张量尺寸,因此显存随它 平方级增长。
dtype = None作用:让 Unsloth 自动选择最合适的浮点精度。
load_in_4bit = True作用:把模型权重量化成 4-bit,显存降到 1/4,QLoRA 微调必备。
查看模型与分词器信息
模型信息
运行
1 | model |
通过阅读模型信息我们可以了解到:
1 | (embed_tokens): Embedding(151936, 4096, padding_idx=151654) |
模型有 15 万个 token 的字典,每个字/词被翻译成 4096 维向量,第 151 654 号 token 被官方指定为填充符。
1 | (layers): ModuleList( |
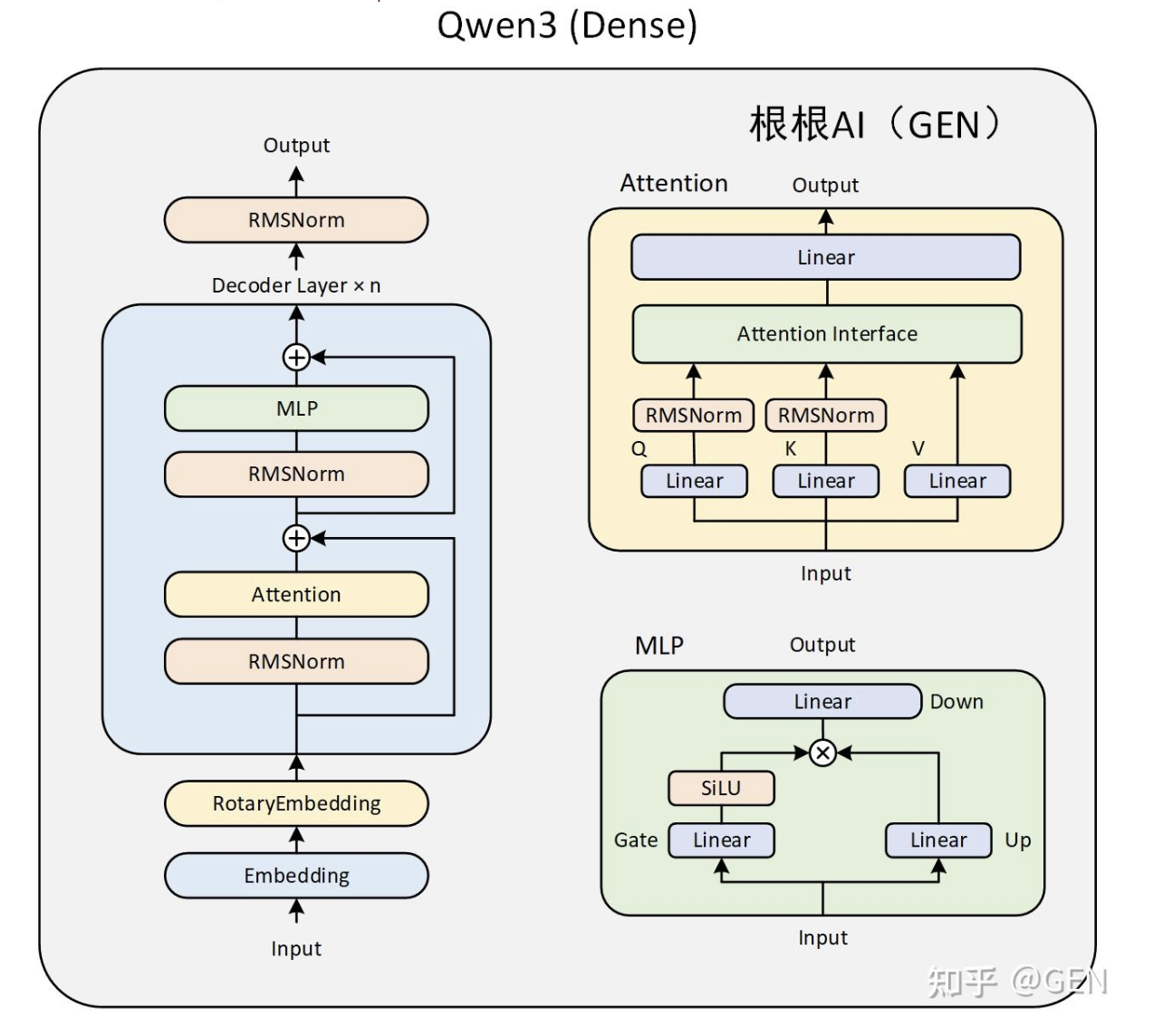
共有36层Qwen3DecoderLayer,每层包含Qwen3Attention,Qwen3MLP(一个 SwiGLU 前馈网络),Qwen3RMSNorm(两个归一化层,对 4096 维的隐藏向量做“均方根归一化”,防止梯度爆炸、稳定训练。)
大模型-qwen3 模型结构解读-66 - jack-chen666 - 博客园
LoRA可以插到哪里呢?
凡是打印里每层 Decoder 中出现的
Linear4bit(q/k/v/o + gate/up/down)就是 LoRA 可插、且默认会被插入的位置。
分词器信息
运行
1 | tokenizer |
查看tokenizer信息
1 | Qwen2TokenizerFast(name_or_path='/workspace/qwen3-8b', vocab_size=151643, model_max_length=40960, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'eos_token': '<|im_end|>', 'pad_token': '<|vision_pad|>', 'additional_special_tokens': ['<|im_start|>', '<|im_end|>', '<|object_ref_start|>', '<|object_ref_end|>', '<|box_start|>', '<|box_end|>', '<|quad_start|>', '<|quad_end|>', '<|vision_start|>', '<|vision_end|>', '<|vision_pad|>', '<|image_pad|>', '<|video_pad|>']}, clean_up_tokenization_spaces=False, added_tokens_decoder={ |
vocab_size=151643:模型真正能理解和生成的子词/符号有这 151643 种,其余位置是预留空白。
model_max_length=40960:理论最大输入长度 40k token(实际受显存限制)
is_fast=True:表示 tokenizer 使用的是 Hugging Face 的「Rust 高速实现」(即 tokenizers 库)
special_tokens:打印的 special_tokens 字典 &
added_tokens_decoder 已经把 151643-151668
全部列出,共 26 个。
模拟一次模型处理流程
将对话内容通过tokenizer进行处理
1 | messages = [ |
apply_chat_template 是把「人类对话格式的 Python
列表」一键翻译成 模型能直接理解的带特殊标记的文本字符串(或
token id 序列) 的“官方模板引擎”。
转化后的格式为:
1 | '<|im_start|>user\n你好,好久不见!<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\n' |
然后将转化后的字符串转成 GPU 上的 PyTorch token 张量,准备直接送进模型推理或训练。
1 | inputs = tokenizer(text, return_tensors="pt").to("cuda") |
以上代码共做了三步:
- tokenizer(text) 把前面
apply_chat_template得到的字符串按词表切成 token id 列表。 - return_tensors=“pt” 把列表包成 PyTorch 张量(shape = [1, seq_len])。
- .to(“cuda”) 把张量搬到 GPU 显存。
输出如下
1 | {'input_ids': tensor([[151644, 872, 198, 108386, 3837, 111920, 101571, 6313, 151645, |
| 键 | 形状 | 每个数字的含义 |
|---|---|---|
| input_ids | [1, 17] |
17 个 token 的 ID 列表,已放到 GPU |
| attention_mask | [1, 17] |
17 个 1,表示“这些位置都是有效 token,无填充” |
1 | outputs = model.generate( |
让模型在 GPU 上 根据已有 token
继续生成文本,直到达到 max_new_tokens
或遇到终止符。
outputs格式和inputs类似,使用nput_ids表示后续字符
1 | response = tokenizer.batch_decode(outputs) |
把模型输出的 token id
序列(outputs)一次性还原成
人类可读的字符串。
输出如下
1 | '<|im_start|>user\n你好,好久不见!<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\n你好!好久不见!最近过得怎么样?有什么新鲜事想和我分享吗?😊<|im_end|>' |
这里展示的是没有思考过程的,最简单对话流程,若设置思考模式,完整代码如下
1 | text = tokenizer.apply_chat_template( |
当然,除了使用上述底层API进行对话外,Unsloth还提供了更加便捷的流式输出模型对话信息的函数,基本对话效果如下:
1 | messages = [ |
准备数据集
下载数据集
选取的两个数据集
- 我们使用 Open Math Reasoning 数据集,该数据集曾被用于赢得 AIMO(AI 数学奥林匹克 - 第二届进步奖)挑战!我们从中抽取了 10% 可验证的推理轨迹,这些轨迹是基于 DeepSeek R1 模型生成的,并且准确率超过 95%。数据集地址:https://huggingface.co/datasets/unsloth/OpenMathReasoning-mini
- 我们还利用了 Maxime Labonne 的 FineTome-100k 数据集,该数据集风格类似 ShareGPT。但我们需要将其转换为 HuggingFace 通用的多轮对话格式。数据集地址:https://huggingface.co/datasets/mlabonne/FineTome-100k
在实际微调过程中,大多都会使用huggingface的datasets库进行数据集下载和管理,实际下载流程如下:
1 | !pip install --upgrade datasets huggingface_hub |
datasets 是 Hugging Face
提供的一个高效数据处理库,专为机器学习和大语言模型(LLM)训练而设计。它支持加载、处理、转换和保存各种格式的数据(如
JSON、CSV、Parquet 等),并能与 transformers
模型无缝集成。通过
datasets,开发者可以快速完成数据清洗、切分、tokenization
等常见任务,大大提升训练效率,特别适合用于指令微调、对话生成、Function
Calling 等任务的数据预处理。
然后分别下载并导入这两个库:
1 | reasoning_dataset = load_dataset("unsloth/OpenMathReasoning-mini", split = "cot") |
cot全称为Chain-of-Thought,思维链,是「一步一步把思考过程写出来」的解题方式,而不是直接给出最终答案。
只下 cot 是因为任务只需要“带推理过程”的那部分数据,其他子集对当前微调目标无用,避免冗余下载。
1 | non_reasoning_dataset = load_dataset("mlabonne/FineTome-100k", split = "train") |
查看数据集
然后输入数据集名称,即可查看数据集基本信息:
1 | reasoning_dataset |
1 | Dataset({ |
一共 19 252 条 CoT(思维链)数学题,每条包含 8 个字段,可直接用来训练/评估模型的逐步推理能力。
generated_solution:模型自己写的 逐步推理 + 最终答案(就是你想要的 CoT)
expected_answer:标准答案(通常是一个简洁数字或表达式)
generation_model:生成这条 CoT 的“教师模型”名字,比如 qwen2-72b
加上索引则可以直接查看对应数据集信息:
1 | reasoning_dataset[0] |
1 | {'expected_answer': '14', |
能够看出这是一个基于DeepSeek
R1回答的数学数据集,其中problem是问题,generated_solution是数学推导过程(即思考过程),而expected_answer则是最终的答案。该数据集总共接近2万条数据
而对话数据集如下:
1 | non_reasoning_dataset |
1 | Dataset({ |
1 | non_reasoning_dataset[0] |
1 | {'conversations': [{'from': 'human', |
其中每一条数据都是一个对话,包含一组或者多组ChatGPT的聊天信息,其中from代表是用户消息还是大模型回复消息,而value则是对应的文本。该对话数据集总共包含10万条数据
能够看出dataset是一种类似json的数据格式,每条数据都以字段格式进行存储,在实际微调过程中,我们需要先将数据集的目标字段进行提取和拼接,然后加载到Qwen3模型的提示词模板中,并最终带入Unsloth进行微调。
数据集清洗
对话数据集的清洗
接下来尝试对上述两个格式各异的数据集进行数据清洗,主要是围绕数据集进行数据格式的调整,便于后续带入Qwen3提示词模板。对于dataset格式的数据对象来说,可以先创建满足格式调整的函数,然后使用map方法对数据集格式进行调整。
1 | def generate_conversation(examples): |
这里先创建generate_conversation函数,用于对reasoning_dataset中的每一条数据进行格式调整,即通过新创建一个新的特征conversations,来以对话形式保存历史问答数据:
1 | reasoning_data = reasoning_dataset.map( |
map:对数据集中的每一批样本调用 generate_conversation
batched=True:一次传入一批(几百到几千条)样本,避免逐行慢速 Python 循环
接下来将其带入Qwen3的提示词模板中进行转化:
1 | reasoning_conversations = tokenizer.apply_chat_template( |
之后即可带入这些数据进行微调。能看出每条数据的格式都和Unsloth底层对话API创建的数据格式类似,之后我们或许可以借助Unsloth底层对话API来创建微调数据集。
推理数据集的推理
然后继续处理non_reasoning_conversations数据集,由于该数据集采用了sharegpt对话格式,因此可以直接借助Unsloth的standardize_sharegpt库进行数据集的格式转化,转化效果如下所示:
1 | from unsloth.chat_templates import standardize_sharegpt |
standardize_sharegpt的作用
把“ShareGPT 格式”的对话数据一键转成 Unsloth / Hugging Face 通用的
role/content列表,后续就能直接用apply_chat_template生成训练文本。1️⃣ ShareGPT 原始长什么样?
2
{"from": "gpt", "value": "2"}2️⃣ 转换后长什么样?
2
{"role": "assistant", "content": "2"}
1 | dataset = standardize_sharegpt(non_reasoning_dataset) |
接下来即可直接带入Qwen3对话模板中进行格式调整:
1 | non_reasoning_conversations = tokenizer.apply_chat_template( |
数据集采样
自此即完成了每个数据集的格式调整工作,不过这两个数据集并不均衡,能看得出非推理类数据集的长度更长。我们假设希望模型保留一定的推理能力,但又特别希望它作为一个聊天模型来使用。
因此,我们需要定义一个 仅聊天数据的比例。目标是从两个数据集中构建一个混合训练集。这里我们可以设定一个 25% 推理数据、75% 聊天数据的比例:也就是说,从推理数据集中抽取 25%(或者说,抽取占比为 100% - 聊天数据占比 的部分),最后将这两个数据集合并起来即可。
1 | chat_percentage = 0.75 |
这里我们需要先将上述list格式的数据转化为pd.Series数据,然后进行采样,并最终将其转化为dataset类型对象。(此外也可以先转化为dataset对象类型,然后再进行采样)
1 | data = pd.concat([ |
pd.concat([…]):纵向拼接 → 一条长 Series,顺序:先推理,后非推理
Dataset.from_pandas(…):把 Pandas Series 转成 Hugging Face Dataset
把“推理对话”和“抽样后的非推理对话”合并成一个
随机打乱 的 Dataset
对象,后面可直接拿去训练。
查看数据集
1 | combined_dataset[0] |
1 | {'text': "<|im_start|>user\nCalculate the pH during a titration when 9.54 mL of a 0.15 M HCl solution has reacted with 22.88 mL of a 0.14 M NaOH solution?<|im_end|>\n<|im_st截取", |
其中text字段就是后续带入微调的字段。
数据集保存
1 | combined_dataset.save_to_disk("/workspace/cleaned_qwen3_dataset") |
后续使用时即可使用如下代码进行读取:
1 | from datasets import load_from_disk |
Qwen3推理能力高效微调流程
准备完数据之后,即可开始进行微调。这里我们先进行少量数据微调测试,程序能够基本跑通后,我们再进行大规模数据集微调。
进行LoRA参数注入
1 | model = FastLanguageModel.get_peft_model( |
这一步“LoRA 参数注入”就是:在不改动原模型权重的前提下,给指定层插入少量 可训练低秩矩阵 (LoRA 适配器),从而只更新 < 1 % 的参数,完成高效微调。
不是“在原有层之外再增加一层”,而是把 LoRA 的“小矩阵”插到 原有线性层内部:
- 原层结构(冻结):
x → Linear4bit(W) → y- 注入后结构(冻结 + 可训练):
x → [Linear4bit(W) + LoRA(A·B)] → y
A和B两个低秩矩阵被 注册为同一层的新参数,不新建网络层,参数在 前向时相加,反向只更新 A 和 B。
设置微调参数
1 | from trl import SFTTrainer, SFTConfig |
TRL (Transformers Reinforcement Learning,用强化学习训练Transformers模型) 是一个领先的Python库,旨在通过监督微调(SFT)、近端策略优化(PPO)和直接偏好优化(DPO)等先进技术,对基础模型进行训练后优化。TRL 建立在 🤗 Transformers 生态系统之上,支持多种模型架构和模态,并且能够在各种硬件配置上进行扩展。
其中SFTTrainer:一个专门为指令微调设计的训练器,封装了
Hugging Face 的
Trainer,而SFTConfig:配置训练参数的专用类,功能类似
TrainingArguments。而SFTConfig核心参数解释如下:
| 参数名 | 含义 |
|---|---|
dataset_text_field="text" |
数据集中用于训练的字段名称,如 text 或
prompt |
per_device_train_batch_size=2 |
每张 GPU 上的 batch size 是 2 |
gradient_accumulation_steps=4 |
梯度累计 4 次后才进行一次反向传播(等效于总 batch size = 2 × 4 = 8) |
warmup_steps=5 |
前 5 步进行 warmup(缓慢提升学习率) |
max_steps=30 |
最多训练 30 步(适合调试或快速实验) |
learning_rate=2e-4 |
初始学习率(短训练可用较高值) |
logging_steps=1 |
每训练 1 步就打印一次日志 |
optim="adamw_8bit" |
使用 8-bit AdamW 优化器(节省内存,Unsloth 支持) |
weight_decay=0.01 |
权重衰减,用于防止过拟合 |
lr_scheduler_type="linear" |
线性学习率调度器(从高到低线性下降) |
seed=3407 |
固定随机种子,确保结果可复现 |
report_to="none" |
不使用 WandB 或 TensorBoard 等日志平台(可改为
"wandb") |
per_device_train_batch_size=2 每次前向只用了 2 条样本 → 显存占用小,单卡就能跑。
batch_size 决定「每一步真正喂给模型的样本数量」,越大训练越稳,但对显存要求越高。
gradient_accumulation_steps=4 把这 2 条样本算出的梯度先攒起来,攒够 4 次再一次性做反向传播 → 等效于一次性看了 2 × 4 = 8 条样本,但显存仍按 2 条算。
此时基本训练过程为: 1. 从 combined_dataset
中取出一批样本(2 条) 2. 重复上面过程 4
次(gradient_accumulation_steps=4) 3.
将累计的梯度用于更新模型一次参数(等效于一次大 batch 更新) 4.
重复上述过程,直到 max_steps=30 停止
设置训练可视化swanlab
🤗HuggingFace Trl | SwanLab官方文档
只需要在你的训练代码中,找到HF的Config部分(比如SFTConfig、GRPOConfig等),添加report_to="swanlab"参数,即可完成集成。
1 | from trl import SFTConfig, SFTTrainer |
默认下,项目名会使用你运行代码的目录名。
如果你想自定义项目名,可以设置SWANLAB_PROJECT环境变量:
1 | import os |
微调执行流程
一切准备就绪后,接下来即可开始进行微调。由于本次微调总共只运行30个step,整个过程并不会很长,实际执行过程如下:
1 | trainer_stats = trainer.train() |
保存模型
1. 保存 LoRA Adapter
1 | # 保存 LoRA adapter(仅几十 MB) |
以后加载:
1 | from unsloth import FastLanguageModel |
2.合并 LoRA → 完整模型
如果你想把 LoRA 权重合并到基座 得到一个独立的大模型(方便推理、上传 Hub):
1 | # 合并权重 |
合并后就是完整的大模型(GB 级),可直接用
AutoModelForCausalLM.from_pretrained("./merged-model")
加载,不依赖 Unsloth。
微调结果
可视化结果
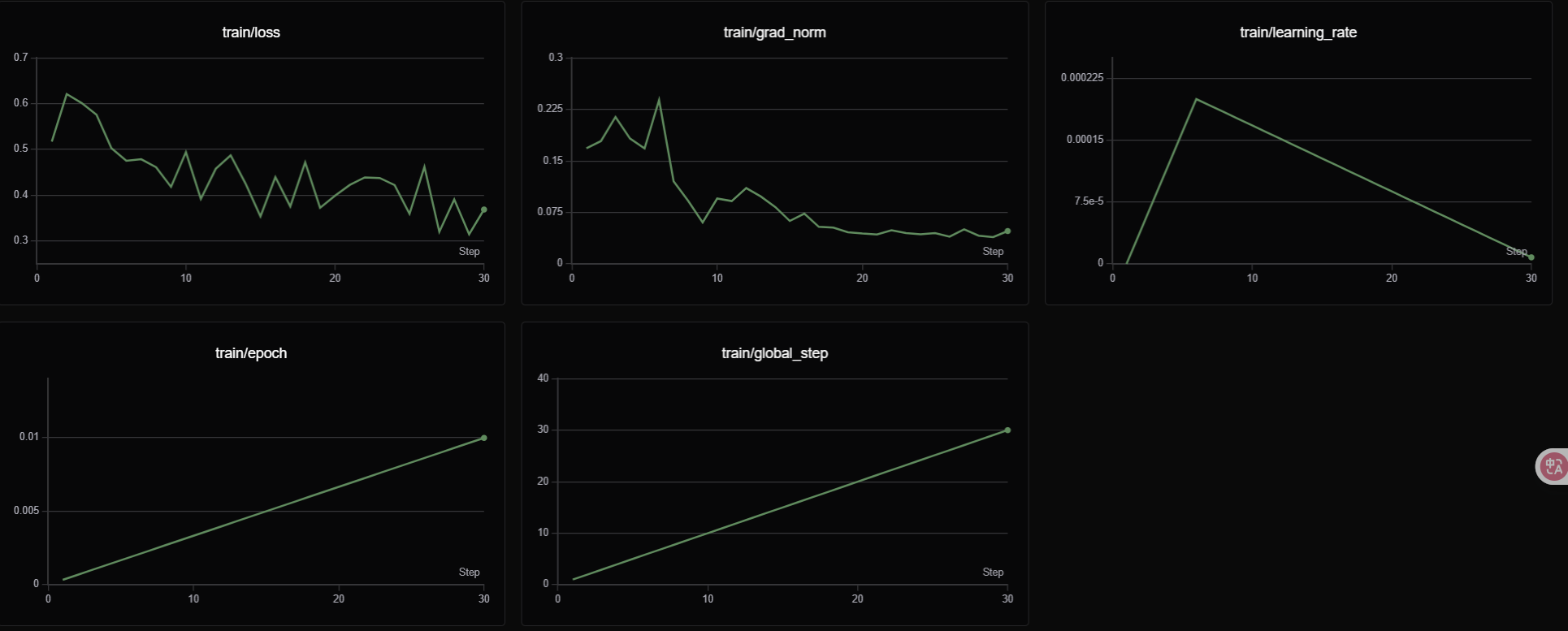
| 指标名称 | 含义 | 单位/范围提示 | 常见关注点 |
|---|---|---|---|
| train/loss | 训练损失(Training Loss) | 标量,越小越好 | 是否持续下降、是否震荡、是否过拟合 |
| train/grad_norm | 梯度范数(Gradient Norm) | 标量,通常 0.01–1.0 为合理区间 | 是否爆炸(>10)或消失(<1e-4) |
| train/learning_rate | 学习率(Learning Rate) | 标量,如 1e-4、5e-4 等 | 是否过大导致震荡、过小导致收敛慢 |
| train/epoch | 已训练的轮次(Epoch) | 标量,1.0 表示完整遍历一次训练集 | 当前已训练多少轮、是否还需继续训练 |
| train/global_step | 全局步数(Global Step) | 整数,每个 batch +1 | 与 epoch 对应,计算已见样本量 |
对话测试
1 | messages = [ |