前言
本文简单测试了一下langgraph官方提供的记忆管理工具,发现还是存在bug,我在a线程先让他记住我是张熙浚,然后又告诉他我不是张熙浚我是张俊细,在线程b询问他我是谁时,他还是认为我是张熙浚。记忆的管理部分确实是一个很大的问题,但中小开发者我认为还是直接使用人家造好的轮子方便些(我尝试去阅读了他的记忆管理工具的源码,以我目前的水平,想手搓花费的精力还是太多了)
我还有一个疑惑,我的理解是,当前记忆的存储基本上依赖于agent的决定,所以并不稳定,我也搞不清楚他什么时候会把哪些信息存入记忆,可以设置
schemas结构,控制存储的内容,但是长期记忆仅存储指定的这些信息,感觉还是有些鸡肋啊
代码见learn-rag-langchain/langmem
at main · zxj-2023/learn-rag-langchain
介绍
LangMem 是 LangChain 推出的开源 SDK,通过一套存储-提取-优化机制,让
Agent
能够在多轮、多天甚至多用户之间持续学习、记住用户偏好并不断改进回答。
LangMem 的记忆工具按两个层次的集成模式组织:
核心 API
LangMem
的核心是提供无副作用地转换记忆状态的函数。这些原语是记忆操作的构建块:
记忆管理器 提示优化器
这些核心函数不依赖于任何特定的数据库或存储系统。您可以在任何应用程序中使用它们。
有状态集成
上一层依赖于 LangGraph 的长期记忆存储。这些组件使用上述核心 API
来转换存储中存在的记忆,并在新对话信息传入时根据需要进行更新/插入或删除:
image-20250814152044798
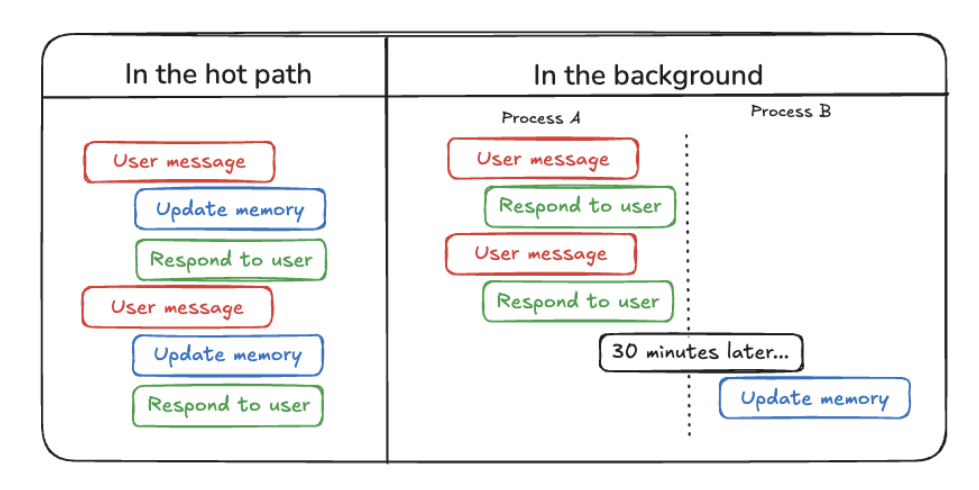
langmem可以通过两种方式创建记忆
在热路径中: Agent 使用工具主动保存笔记。在后台: 记忆从对话中自动“潜意识地”提取。
热路径快速入门指南
在本指南中,我们将创建一个 LangGraph Agent,它通过 LangMem 的
manage_memory 工具来主动管理自己的长期记忆。
create_manage_memory_tool通过创建一个工具(Tool),这个工具可以被
agent用来管理持久化记忆 。这些记忆可以在不同的对话、会话甚至应用重启后依然存在。
持久化存储 (Persistent Storage): 它利用了
LangGraph 提供的 BaseStore
接口。这使得数据可以存储在内存、数据库(如
Postgres)等地方,而不是仅仅存在于程序的运行时内存中。
命名空间 (Namespace):
为了组织和隔离不同用户或不同类型的记忆,数据被存储在层级化的命名空间中。例如,("memories", "user-123")
可以确保用户 “user-123”
的记忆与其他用户或系统记忆分开。命名空间可以包含占位符(如
{langgraph_user_id}),在实际执行时会被具体的配置值替换。
记忆 (Memory):
在这个上下文中,一个“记忆”就是存储在 BaseStore
中的一个数据项(Item)。它有一个唯一的
key(通常是 UUID),一个 namespace,一个
value(存储实际内容),以及创建和更新时间戳。
工具 (Tool): 在 AI
应用中,工具是代理(Agent)可以调用的函数或能力。这个函数创建的工具就是一个封装好的、可以被
Agent 调用的函数,用于执行创建、更新、删除记忆的操作。
什么时候agent会调用记忆工具
image-20250814163150589
ai是这样回答的,ReAct架构的agent是否调用工具由他自己决定
实战
导入库
1 2 3 4 5 6 7 8 from langgraph.checkpoint.memory import MemorySaver from langgraph.prebuilt import create_react_agent from langgraph.store.memory import InMemoryStore from langgraph.utils.config import get_store from langmem import ( # 让智能体创建、更新和删除记忆 create_manage_memory_tool, )
返回记忆提示词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def prompt(state): """为LLM准备消息。""" # 从配置的上下文变量中获取存储; store = get_store() # 与提供给 `create_react_agent` 的相同 memories = store.search( # 在与我们为智能体配置的相同命名空间内搜索 ("memories",), query=state["messages"][-1].content, ) system_msg = f"""You are a helpful assistant. ## Memories <memories> {memories} </memories> """ return [{"role": "system", "content": system_msg}, *state["messages"]]
定义store与checkpoint
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain import embeddings from langchain_openai import OpenAIEmbeddings embedding=OpenAIEmbeddings( api_key="sk-", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="text-embedding-v4", check_embedding_ctx_length = False, dimensions=1536 ) store = InMemoryStore( index={ # 存储提取的记忆 "dims": 1536, "embed": embedding, } ) checkpointer = MemorySaver() # 检查点图状态
定义agent
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_openai import ChatOpenAI model_qwen=ChatOpenAI( api_key="sk-", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen3-30b-a3b-instruct-2507", ) agent = create_react_agent( model=model_qwen, prompt=prompt, tools=[ # 添加记忆工具 # 智能体可以调用 "manage_memory" 来 # 通过ID创建、更新和删除记忆 # 命名空间为记忆添加作用域。要 # 为每个用户限定记忆范围,使用 ("memories", "{user_id}"): create_manage_memory_tool(namespace=("memories",)), ], # 我们的记忆将存储在这个提供的BaseStore实例中 store=store, # 图的"状态"将在每个节点完成执行后进行检查点 # 用于跟踪聊天历史和持久执行 checkpointer=checkpointer, )
可视化图
1 agent.get_graph().draw_mermaid_png(output_file_path="agent.png")
在线程a让agent记住我们的偏好
1 2 3 4 5 6 7 8 9 10 11 12 config = {"configurable": {"thread_id": "thread-a"}} agent.invoke( { "messages": [ {"role": "user", "content": "我喜欢黑色的显示模式"} ] }, # 我们将通过使用具有相同thread_id的config # 来继续对话(thread-a) config=config, ) print(response["messages"][-1].content)
1 是的,我知道!你偏好黑色显示模式。我会在后续交互中保持这一设置。
在线程b查看是否记住
1 2 3 4 5 6 7 8 9 10 # 新线程 = 新对话! new_config = {"configurable": {"thread_id": "thread-b"}} # 智能体只能回忆起 # 它使用manage_memories工具明确保存的内容 response = agent.invoke( {"messages": [{"role": "user", "content": "你好。你还记得我吗?你知道我有什么偏好吗?"}]}, config=new_config, ) print(response["messages"][-1].content)
1 你好!虽然我无法记住你作为个体的详细信息,但我可以访问一些关于你的偏好信息。根据之前的记录,我知道你偏好使用黑色显示模式。如果你还有其他偏好或希望我记住什么,请告诉我,我会帮你记录下来。
后台快速入门指南
本指南将向您展示如何使用 create_memory_store_manager
Runnable: LangChain/LangGraph
中的核心抽象,代表一个可以被调用(invoke/ainvoke)来处理输入并产生输出的单元。MemoryStoreManager
本身就是一个 Runnable。
BaseStore: LangGraph
提供的持久化存储接口。Manager
会使用它来读取(搜索)和写入(创建、更新、删除)记忆。
Memory (记忆): 在 Manager
的上下文中,记忆通常是指从对话中提取的、值得保存的片段信息(如用户偏好、事实等)。它们存储在
BaseStore 中,有自己的 namespace 和
key。
Schema (模式): 一个 Pydantic
模型,用于定义记忆的结构。这允许你强制记忆遵循特定的格式(例如,包含
category, preference, context
字段)。如果未提供
schemas,则默认使用非结构化的字符串。
Namespace (命名空间): 用于组织存储在
BaseStore 中的记忆。支持使用占位符(如
{langgraph_user_id})进行动态配置。
自动化流程:
Manager 会自动执行以下步骤:
搜索 (Search): 根据新对话内容,在
BaseStore 中查找相关的现有记忆。分析/提取 (Analyze/Extract): 使用 LLM
分析新对话和检索到的记忆,决定是否需要创建新记忆、更新现有记忆或删除过时记忆。应用更改 (Apply Changes):
将分析结果(记忆的增删改)写回到 BaseStore。
实战
导入库
1 2 3 4 5 from langchain.chat_models import init_chat_model from langgraph.func import entrypoint from langgraph.store.memory import InMemoryStore from langmem import ReflectionExecutor, create_memory_store_manager
定义store
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from langchain_openai import OpenAIEmbeddings embedding=OpenAIEmbeddings( api_key="sk-", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="text-embedding-v4", check_embedding_ctx_length = False, dimensions=1536 ) store = InMemoryStore( index={ # 存储提取的记忆 "dims": 1536, "embed": embedding, } )
创建记忆管理器
1 2 3 4 5 6 7 8 9 10 # 创建记忆管理器 Runnable 来从对话中提取记忆 memory_manager = create_memory_store_manager( model_qwen, # 将记忆存储在 "memories" 命名空间(即目录)中 namespace=("memories",), instructions="用中文存储记忆。" ) # 包装 memory_manager 以处理延迟的后台处理 executor = ReflectionExecutor(memory_manager)
对每条消息都进行记忆处理存在以下缺点: -
当消息快速连续到达时,会产生冗余工作 -
在对话中途进行处理时,上下文不完整 - 不必要的 token 消耗
ReflectionExecutor
创建工作流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langchain_openai import ChatOpenAI model_qwen=ChatOpenAI( api_key="sk-", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen3-30b-a3b-instruct-2507", ) @entrypoint(store=store) # 创建一个 LangGraph 工作流 async def chat(message: str): response = model_qwen.invoke(message) # memory_manager 从对话历史中提取记忆 # 我们将以 OpenAI 的消息格式提供它 to_process = {"messages": [{"role": "user", "content": message}] + [response]} await memory_manager.ainvoke(to_process) return response.content # 正常运行对话 response = await chat.ainvoke( "记住我是张熙浚", ) print(response)
查看记忆
1 print(store.search(("memories",)))
参考资料
简介 - LangChain
框架
核心概念
- LangChain 框架