前言
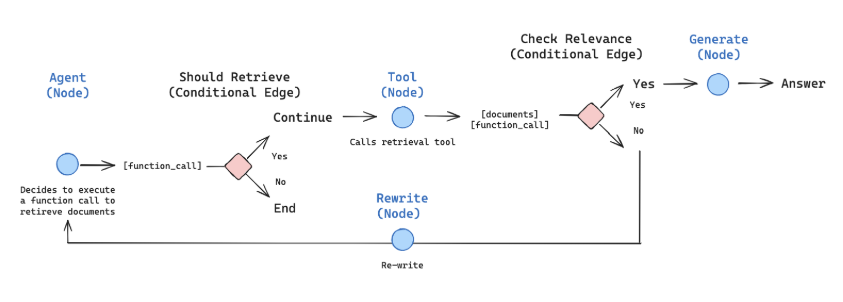
这个agentic
rag主要是作用于检索部分,由是否需要调用检索工具判定是否进入检索阶段,当检索到相关的文章,则进行回答,否则对问题进行改写,再次检索
代码见learn-rag-langchain/agentic-rag
at main · zxj-2023/learn-rag-langchain
在这个教程中,我们将构建一个检索代理。当您希望 LLM
决定是否从向量存储中检索上下文或直接响应用户时,检索代理非常有用。
完成教程后,我们将完成以下工作:
获取并预处理用于检索的文档。
为这些文档建立语义索引,并为代理创建一个检索工具。
构建一个能够决定何时使用检索工具的代理式 RAG 系统。
image-20250819165309335
1. 预处理文档
获取用于我们 RAG 系统的文档。我们将使用 Lilian Weng
优秀博客中最新的三页。我们将从使用 WebBaseLoader
工具获取页面内容开始:
1 2 3 4 5 6 7 8 9 from langchain_community.document_loaders import WebBaseLoader urls = [ "https://lilianweng.github.io/posts/2024-11-28-reward-hacking/", "https://lilianweng.github.io/posts/2024-07-07-hallucination/", "https://lilianweng.github.io/posts/2024-04-12-diffusion-video/", ] docs = [WebBaseLoader(url).load() for url in urls]
1 docs[0][0].page_content.strip()[:1000]
将获取的文档分割成更小的块,以便索引到我们的向量存储中:
1 2 3 4 5 6 7 8 from langchain_text_splitters import RecursiveCharacterTextSplitter docs_list = [item for sublist in docs for item in sublist] text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=100, chunk_overlap=50 ) doc_splits = text_splitter.split_documents(docs_list)
1 doc_splits[0].page_content.strip()
2. 创建检索工具
现在我们已经有了分割的文档,我们可以将它们索引到一个向量存储中,我们将使用这个向量存储进行语义搜索。
使用内存向量存储和 OpenAI 嵌入:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langchain_chroma import Chroma # 导入 Chroma from langchain_openai import OpenAIEmbeddings import os # 确保安装了 langchain-chroma # pip install langchain-chroma embedding = OpenAIEmbeddings( api_key="sk-", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="text-embedding-v4", check_embedding_ctx_length=False, dimensions=1536, chunk_size=5 # 设置较小的批次大小 ) # 使用 Chroma 替代 InMemoryVectorStore vectorstore = Chroma.from_documents( documents=doc_splits, embedding=embedding, persist_directory="./chroma_db" # 指定持久化目录 )
1 2 3 4 5 6 7 # 重新加载已存在的 Chroma 数据库 vectorstore = Chroma( persist_directory="./chroma_db", embedding_function=embedding ) retriever = vectorstore.as_retriever()
使用 LangChain 的预构建 create_retriever_tool
创建检索工具
1 2 3 4 5 6 7 from langchain.tools.retriever import create_retriever_tool retriever_tool = create_retriever_tool( retriever, # 【输入】一个已经配置好的检索器(例如:向量数据库的检索器) "retrieve_blog_posts", # 【工具名称】这个工具的唯一标识名(供模型内部调用) "Search and return information about Lilian Weng blog posts." # 【工具描述】模型看到的说明,用于决定是否调用它 )
1 retriever_tool.invoke({"query": "types of reward hacking"})
3. 生成查询
现在我们将开始构建我们智能体 RAG 图中的组件(节点和边)。
构建一个 generate_query_or_respond 节点。它将调用 LLM
来根据当前图状态(消息列表)生成响应。根据输入消息,它将决定使用检索工具进行检索,或直接响应用户。请注意,我们通过
.bind_tools 向聊天模型提供了先前创建的
retriever_tool 访问权限:
1 2 3 4 5 6 7 from langchain_community.chat_models import ChatTongyi llm = ChatTongyi( model="qwen3-235b-a22b", api_key="sk-", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model_kwargs={"enable_thinking": False} # 关键在这里 )
1 2 3 4 5 6 7 8 9 10 from langgraph.graph import MessagesState def generate_query_or_respond(state: MessagesState): """调用模型,根据当前状态生成响应。根据问题,模型将决定是使用检索工具进行检索,还是直接回复用户。 """ response = ( llm .bind_tools([retriever_tool]).invoke(state["messages"]) ) return {"messages": [response]}
提出一个需要语义搜索的问题:
1 2 3 4 5 6 7 8 9 input = { "messages": [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", } ] } generate_query_or_respond(input)["messages"][-1].pretty_print()
4.评定文件
添加一个条件边 — grade_documents —
来判断检索到的文档是否与问题相关。
我们将使用一个具有结构化输出模式 GradeDocuments
的模型来对文档进行评分。 grade_documents
函数将根据评分决策( generate_answer 或
rewrite_question )返回要前往的节点的名称:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from pydantic import BaseModel, Field from typing import Literal # 定义评分提示模板 GRADE_PROMPT = ( "你是一个评分员,负责评估检索到的文档与用户问题的相关性。\n " "以下是检索到的文档内容:\n\n {context} \n\n" "以下是用户的问题:{question} \n" "如果文档包含与用户问题相关的关键词或语义含义,则将其评为相关。\n" "请给出一个二元评分:'yes'(是)表示相关,'no'(否)表示不相关。" ) # 定义用于评估文档相关性的 Pydantic 模型 class GradeDocuments(BaseModel): """使用二元评分对文档进行相关性评估。""" binary_score: str = Field( description="相关性评分:'yes' 表示相关,'no' 表示不相关" ) # 初始化用于评分的聊天模型 grader_model = llm def grade_documents( state: MessagesState, ) -> Literal["generate_answer", "rewrite_question"]: """ 判断检索到的文档是否与用户问题相关。 参数: state: 包含消息历史的状态对象,其中第一条消息是用户问题, 最后一条消息是检索到的文档内容。 返回: 如果文档相关,返回 "generate_answer"; 如果不相关,返回 "rewrite_question",表示需要重写问题并重新检索。 """ question = state["messages"][0].content # 获取用户问题 context = state["messages"][-1].content # 获取检索到的文档内容 # 将问题和文档内容填入提示模板 prompt = GRADE_PROMPT.format(question=question, context=context) # 调用模型,并以结构化输出(Pydantic 模型)的形式获取评分结果 response = ( grader_model .with_structured_output(GradeDocuments) .invoke([{"role": "user", "content": prompt}]) ) #print(response) score = response.binary_score # 获取二元评分结果 # 根据评分决定下一步操作 if score == "yes": return "generate_answer" # 文档相关,生成答案 else: return "rewrite_question" # 文档不相关,重写问题后重新检索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from langchain_core.messages import convert_to_messages input = { "messages": convert_to_messages(#将一系列消息转换为 BaseMessage 类型的消息列表。 [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "1", "name": "retrieve_blog_posts", "args": {"query": "types of reward hacking"}, } ], }, {"role": "tool", "content": "meow", "tool_call_id": "1"}, ] ) } grade_documents(input)
5. 重写问题
构建 rewrite_question 节点。
检索工具可能会返回潜在的不相关文档,这表明需要改进原始用户问题。为此,我们将调用
rewrite_question 节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 REWRITE_PROMPT = ( "Look at the input and try to reason about the underlying semantic intent / meaning.\n" "Here is the initial question:" "\n ------- \n" "{question}" "\n ------- \n" "Formulate an improved question:" ) def rewrite_question(state: MessagesState): """ 重写用户最初的提问,以更好地表达其语义意图。 参数: state: 包含消息历史的状态对象,其中第一条消息是用户原始问题。 返回: 一个字典,包含一条新的用户消息,内容为改写后的问题。 该消息将用于后续的检索步骤,以提高检索结果的相关性。 """ messages = state["messages"] question = messages[0].content # 获取用户最初的提问 prompt = REWRITE_PROMPT.format(question=question) # 将问题填入提示模板 response = llm.invoke([{"role": "user", "content": prompt}]) # 调用模型生成改写后的问题 # 返回新的消息结构,内容为改写后的问题 return {"messages": [{"role": "user", "content": response.content}]}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 input = { "messages": convert_to_messages( [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "1", "name": "retrieve_blog_posts", "args": {"query": "types of reward hacking"}, } ], }, {"role": "tool", "content": "meow", "tool_call_id": "1"}, ] ) } response = rewrite_question(input) print(response["messages"][-1]["content"])
6. 生成答案
构建 generate_answer
节点:如果我们通过了评分器的检查,我们可以根据原始问题和检索到的上下文生成最终答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GENERATE_PROMPT = ( "You are an assistant for question-answering tasks. " "Use the following pieces of retrieved context to answer the question. " "If you don't know the answer, just say that you don't know. " "Use three sentences maximum and keep the answer concise.\n" "Question: {question} \n" "Context: {context}" ) def generate_answer(state: MessagesState): """Generate an answer.""" question = state["messages"][0].content context = state["messages"][-1].content prompt = GENERATE_PROMPT.format(question=question, context=context) response = llm.invoke([{"role": "user", "content": prompt}]) return {"messages": [response]}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 input = { "messages": convert_to_messages( [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "1", "name": "retrieve_blog_posts", "args": {"query": "types of reward hacking"}, } ], }, { "role": "tool", "content": "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering", "tool_call_id": "1", }, ] ) } response = generate_answer(input) response["messages"][-1].pretty_print()
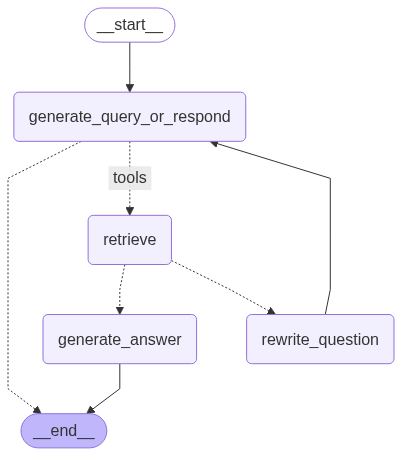
7. 组装图表
以 generate_query_or_respond 开头,并确定是否需要调用
retriever_tool
使用 tools_condition 跳转到下一步:
如果 generate_query_or_respond 返回
tool_calls ,调用 retriever_tool
获取上下文
否则,直接回复用户
对检索到的文档内容按与问题的相关性( grade_documents
)进行评分,并路由到下一步:
如果不相关,使用 rewrite_question
重写问题,然后再次调用 generate_query_or_respond
如果相关,请继续到 generate_answer
并使用检索到的文档上下文生成最终响应 ToolMessage
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from langgraph.graph import StateGraph, START, END from langgraph.prebuilt import ToolNode from langgraph.prebuilt import tools_condition # 创建一个基于状态图(StateGraph)的流程,用于管理对话或任务的执行流程 workflow = StateGraph(MessagesState) # 定义流程中将循环执行的各个节点 workflow.add_node(generate_query_or_respond) # 判断是生成检索查询还是直接回复用户 workflow.add_node("retrieve", ToolNode([retriever_tool])) # 检索节点:使用检索工具(retriever_tool)从知识库中查找相关文档 workflow.add_node(rewrite_question) # 重写问题节点:当检索结果不相关时,优化并重写用户的问题 workflow.add_node(generate_answer) # 生成答案节点:基于检索到的信息生成最终回答 # 设置流程的起始点:从 `generate_query_or_respond` 节点开始 workflow.add_edge(START, "generate_query_or_respond") # 添加条件边:决定是否进行文档检索 workflow.add_conditional_edges( "generate_query_or_respond", # 使用 `tools_condition` 函数判断 LLM 的输出意图: # 如果 LLM 决定调用 `retriever_tool` 工具,则进入检索;如果选择直接回复,则结束流程 tools_condition, { # 将条件判断结果映射到图中的具体节点 "tools": "retrieve", # 若需调用工具,则跳转到检索节点 END: END # 若无需调用工具(即可以直接回答),则结束流程 }, ) # 在 `retrieve` 节点执行后,根据文档相关性判断下一步操作 workflow.add_conditional_edges( "retrieve", # 调用 `grade_documents` 函数评估检索到的文档是否与问题相关 grade_documents, # 根据评分结果决定流向: # - 如果相关,进入 `generate_answer` # - 如果不相关,进入 `rewrite_question` # (该逻辑在 `grade_documents` 函数中返回 "generate_answer" 或 "rewrite_question") ) # 添加固定边:生成答案后流程结束 workflow.add_edge("generate_answer", END) # 重写问题后,回到初始节点重新判断是否需要检索 workflow.add_edge("rewrite_question", "generate_query_or_respond") # 编译整个工作流,生成可执行的图结构 graph = workflow.compile()
image-20250826170834571
参考资料
《Agentic
RAG》 — Agentic RAG