计算机组成原理作业
第一章作业
1
假设同一套指令集用不同的方法设计了两种机器 M1 和 M2。机器 M1 的时钟周期为 0.8ns,机器 M2 的时钟周期为 1.2ns。某个程序 P 在机器 M1 上运行时的 CPI 为 4,在 M2 上的 CPI 为 2。对于程序 P 来说,哪台机器的执行速度更快?快多少?
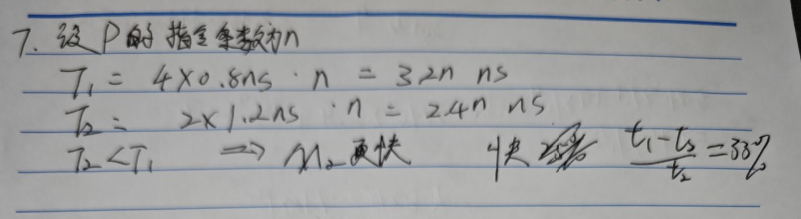
2
假定编译器对某段高级语言程序编译生成两种不同的指令序列 S1 和 S2,在时钟频率为 500MHz 的机器 M 上运行,目标指令序列中用到的指令类型有 A、B、C 和 D 四类。每类指令在 M 上的 CPI 和两个指令序列所用的各类指令条数如下表所示。
| 指令类型 | A | B | C | D |
|---|---|---|---|---|
| 各指令的 CPI | 1 | 2 | 3 | 4 |
| S1 的指令条数 | 5 | 2 | 2 | 1 |
| S2 的指令条数 | 1 | 1 | 1 | 5 |
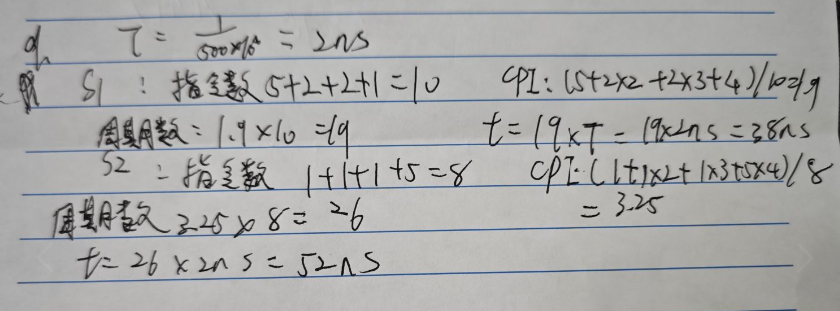
3
假定机器 M 在运行程序 P 的过程中,共执行了 500×10⁶ 条浮点数指令、4000×10⁶ 条整数指令、3000×10⁶ 条访存指令、1000×10⁶ 条分支指令,这 4 种指令的 CPI 分别是 2、1、4、1。若要使程序 P 的执行时间减少一半,浮点指令的 CPI 应如何改进?若要使程序 P 的执行时间减少一半,访存指令和分支指令的 CPI 应如何改进?若浮点指令和整数指令的 CPI 减少 20%,访存指令和分支指令的 CPI 减少 40%,则程序 P 的执行时间会减少多少?


第二章作业
1
假定某计算机的总线采用奇校验,每8位数据有一位校验位,若在32位数据线上传输的信息是
8F 3C AB 96H,则对应的4个校验位应为什么?
若接收方收到的数据信息和校验位分别为87 3C AB 96H 和
0101B,则说明发生了什么情况,并给出验证过程。.0
第一部分:计算原始数据 8F 3C AB 96H 对应的 4
个校验位
前提条件: -
使用奇校验:每个字节(8位)中,1的个数必须是奇数。
- 每8位数据配1位校验位,所以32位数据分成4个字节,对应4个校验位。 -
数据是十六进制:8F 3C AB 96H
我们需要对每一个字节单独计算其奇校验位。
第一步:把每个十六进制字节转换成二进制
8F H=1000 11113C H=0011 1100AB H=1010 101196 H=1001 0110
第二步:数每个字节中“1”的个数,然后确定校验位
奇校验规则: 如果当前字节中“1”的个数是偶数,则校验位设为
1,使总数变为奇数;如果是奇数,则校验位设为0,保持奇数。
我们逐个来看:
- 字节
8F=1000 1111- 数“1”:位置0, 4,5,6,7 → 共 5个1 → 是奇数
- 所以校验位 =
0
- 字节
3C=0011 1100- 数“1”:位置2,3,4,5 → 共 4个1 → 是偶数
- 所以校验位 =
1
- 字节
AB=1010 1011- 数“1”:位置0,2,4,6,7 → 共 5个1 → 是奇数
- 所以校验位 =
0
- 字节
96=1001 0110- 数“1”:位置0,3,5,6 → 共 4个1 → 是偶数
- 所以校验位 =
1
✅ 所以,对应的4个校验位是:0 1 0 1,即
0101B
第二部分:接收方收到的数据是 87 3C AB 96H
和校验位 0101B,发生了什么?验证过程
现在接收方收到: - 数据:87 3C AB 96H -
校验位:0101B
我们怀疑有错误,因为原始发送的是 8F,但收到的是
87 —— 很可能第一个字节出错了!
我们来逐字节验证奇校验是否成立。
第一步:将接收到的数据转为二进制
87 H=1000 01113C H=0011 1100(没变)AB H=1010 1011(没变)96 H=1001 0110(没变)
校验位:0101B → 对应四个字节的校验位分别是:第1字节
0,第2字节 1,第3字节 0,第4字节
1
第二步:验证每个字节 + 校验位 是否满足奇校验
注意:我们验证的是“数据位 + 校验位”一共9位中,1的个数是否为奇数。
- 第一字节
87+ 校验位0- 数据位:
1000 0111→ “1”的个数:位置0, 5,6,7 → 4个1 - 加上校验位
0→ 总共还是 4个1 → 是偶数 ❌ - 不满足奇校验!→ 出错!
- 数据位:
- 第二字节
3C+ 校验位1- 数据位:
0011 1100→ “1”的个数:4个(偶数) - 加上校验位
1→ 总共 4+1=5 → 奇数 ✅ - 正确
- 数据位:
- 第三字节
AB+ 校验位0- 数据位:
1010 1011→ “1”的个数:5个(奇数) - 加上校验位
0→ 总共 5 → 奇数 ✅ - 正确
- 数据位:
- 第四字节
96+ 校验位1- 数据位:
1001 0110→ “1”的个数:4个(偶数) - 加上校验位
1→ 总共 5 → 奇数 ✅ - 正确
- 数据位:
✅ 结论:只有第一个字节校验失败!说明在传输过程中,第一个字节发生了错误。
进一步分析:哪里出错了?
原始发送的是 8F H = 1000 1111
接收的是 87 H = 1000 0111
对比:
1 | 原始: 1 0 0 0 1 1 1 1 |
所以,第5位发生了翻转错误(bit flip)。
🧠 总结
- 原始数据
8F 3C AB 96H的校验位是0101B。 - 接收方收到
87 3C AB 96H和0101B后,发现第一个字节校验失败,说明该字节在传输中发生了错误(具体是第5位由1变0)。 - 奇校验能检测单个比特错误,但不能纠正它,也不能检测偶数个比特错误。

第三章作业
已知 x = 10, y = -6,采用
6位机器数表示。请按如下要求计算并把结果还原成真值。
(1)求 [x + y]补,[x - y]补
(2)用原码一位乘法计算 [x × y]原 (3)用布斯算法计算
[x × y]补 (4)用加减交替法计算 [x / y]原
的商和余数



第七章作业
1

DRAM 的全称是 Dynamic Random Access Memory,中文叫 动态随机存取存储器。
它是计算机中最常用的主存储器(Main Memory / RAM),也就是我们平时常说的“内存条”上的核心芯片。
为什么 DRAM 单元要刷新?(物理原理)
核心原因:漏电。
你可以把 DRAM 的存储单元想象成一个底部有个小针眼的“水桶”(电容),而数据就是“水”(电荷)。
- 存入数据 “1”: 你给桶里倒满水。
- 存入数据 “0”: 你把桶倒空。
- 问题来了:
因为那个小针眼(晶体管的漏电流),满桶的水会慢慢往下漏。
- 如果你不管它,过一会儿(比如 2ms 后),桶里的水漏干了,原本的 “1” 就变成了 “0”,数据就丢了。
这里最容易混淆的是两个时间概念,必须分清楚:
- 最大刷新时间(题目中的 2ms):
- 这是死线 (Deadline)。
- 意思是:对于每一个水桶,管理员最迟必须每隔 2ms 回来检查一次。如果超过 2ms 没管它,水就漏光了。
- 产生刷新信号的间隔(题目要求的答案):
- 这是管理员处理下一行水桶的频率。
- 关键点: 管理员不能一次性同时刷新几百万个水桶(那样电路会过载,电流太大)。他必须一批一批地(一行一行地)轮流刷新。

2

ROM 的全称是 Read-Only Memory,中文叫 只读存储器。
核心特点:
- 字面意思: “Read-Only” 意味着只能读,不能写(或者说在正常工作状态下不能随意写入)。
- 实际特性(最重要):非易失性 (Non-Volatile)。
- RAM (DRAM/SRAM): 一断电,数据立马消失。
- ROM: 断电后,数据依然保存。哪怕你把电脑关机放一年,ROM 里的数据也不会丢。
为什么 ROM 总是放在内存地址的最前面(从 0 开始)?
- 开机第一件事: 当你按下电脑电源键时,RAM(内存条)里是空的(全是乱码或 0),CPU 无法从 RAM 里读取指令。
- 启动引导: CPU 设计为通电后自动去地址
0000H(或其他固定地址)找第一条指令。 - 固化程序:
我们必须在这个位置放一个断电也不丢数据的存储器(ROM),里面存着电脑的启动程序(BIOS/UEFI)。
- 它负责检测硬件、初始化系统,然后把操作系统(Windows/Linux)从硬盘搬到 RAM 里。
当 $\overline{\text{MREQ}} = 0$(即处于低电平/有效状态)时,它的主要作用是通知系统,CPU 当前正打算对内存(RAM 或 ROM)进行访问。
$R/\overline{W}$ (Read / Write Control)
- 角色:这是 CPU 发出的控制信号(总线信号)。
- 含义:它告诉整个系统,CPU 当前想要控制数据流向的方向。
- 状态逻辑:
- 高电平 (1) = Read (读):CPU 准备从总线上接收数据(数据流向:内存 → CPU)。
- 低电平 (0) = Write (写):CPU 准备向总线上发送数据(数据流向:CPU → 内存)。
通俗理解:这是 CPU 在喊话:“大家都听好了,我现在是要‘收东西’(Read)还是要‘发东西’(Write)。”
$\overline{WE}$ (Write Enable)
- 角色:这是 RAM 芯片上的输入引脚(控制端)。
- 含义:允许写入信号。它决定了内存芯片是否允许将数据总线上的电平记录到存储单元中。
- 符号含义:顶部的横线表示低电平有效 (Active Low)。
- 状态逻辑:
- 低电平 (0) = 允许写入:内存芯片打开“大门”,将数据总线上的数据存入当前地址指向的单元。
- 高电平 (1) = 禁止写入:内存芯片处于读取模式(配合其他信号)或待机模式,不会修改内部存储的数据。
通俗理解:这是内存芯片身上的一个开关。只有把这个开关拉下来(变低),内存才会乖乖地把数据“记下来”。
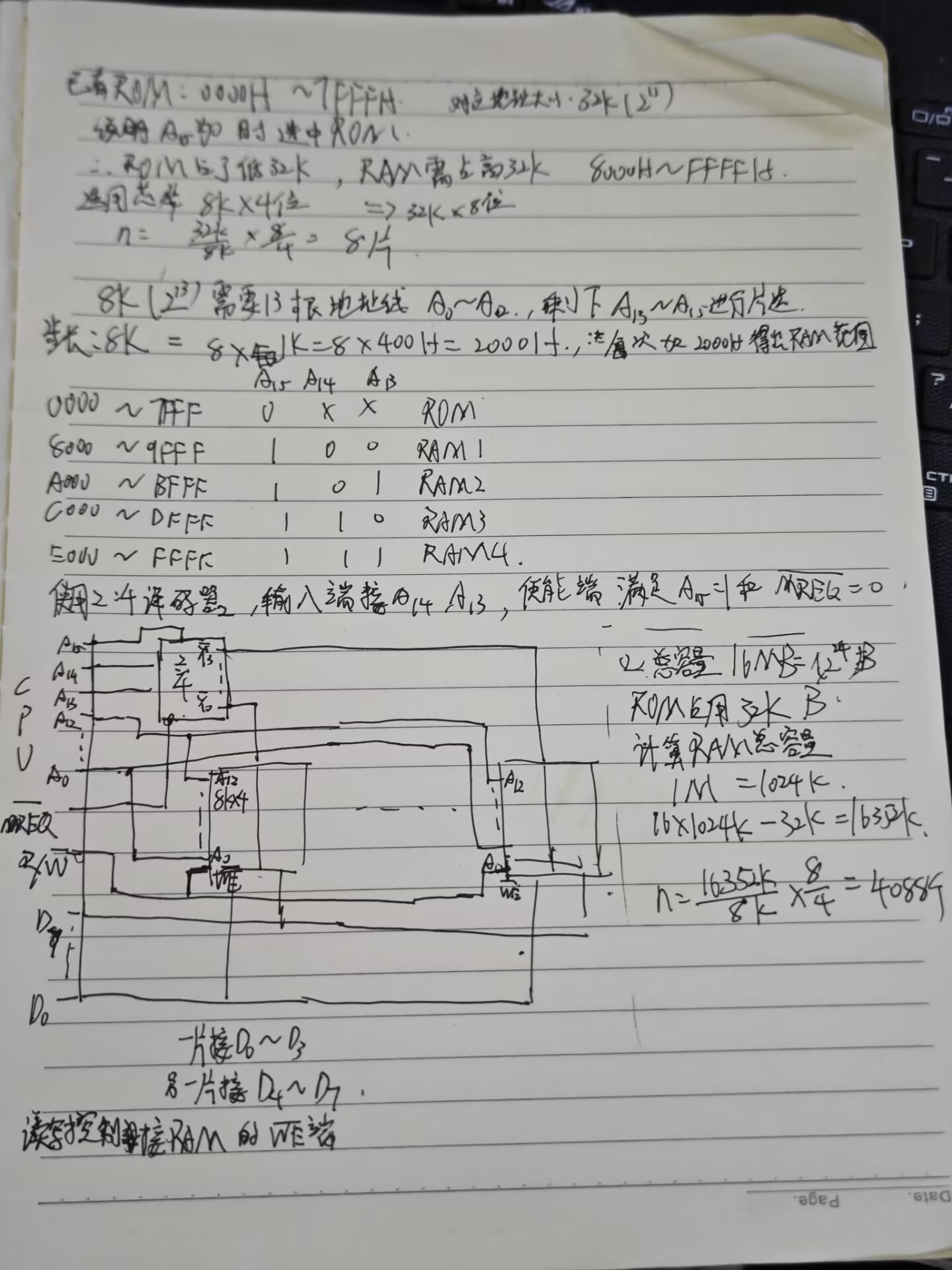
3


4


5



6

第四章作业
1
哪些寻址方式下的操作数在寄存器中?哪些在存储器中?
- 操作数(Operand):指令执行时要处理的数据。
- 寻址方式(Addressing Mode):指明操作数在哪里(寄存器?内存?立即数?)以及如何找到它。
- 寄存器(Register):CPU内部的高速存储单元。
- 存储器(Memory):主存(RAM),速度比寄存器慢,但容量大。
| 寻址方式 | 操作数位置 | 举例 |
|---|---|---|
| 寄存器寻址 | ✅ 寄存器 | MOV AX, BX |
| 立即寻址 | ❌ 不在寄存器/存储器(在指令中) | MOV AX, 5 |
| 直接寻址 | ✅ 存储器 | MOV AX, [2000H] |
| 寄存器间接寻址 | ✅ 存储器 | MOV AX, [BX] |
| 寄存器相对寻址 | ✅ 存储器 | MOV AX, [BX + 10] |
| 基址变址寻址 | ✅ 存储器 | MOV AX, [BX + SI] |
| 相对基址变址寻址 | ✅ 存储器 | MOV AX, [BX + SI + 5] |
⚠️ 注意:立即数(Immediate) 不是寄存器也不是存储器,它直接嵌入在指令中。
2
什么是 RISC?
RISC = Reduced Instruction Set Computer(精简指令集计算机)
与之相对的是 CISC(Complex Instruction Set Computer,复杂指令集计算机),比如 Intel x86。
1️⃣ 指令集精简(Reduced Instruction Set)
- 指令数量少(通常几十到几百条),每条指令功能单一。
- 指令长度固定(如 32 位),便于流水线处理。
💡 类比:就像厨房里只有几把多功能刀具,每把刀只做一件事,但做得又快又好。
例子:
- RISC:
ADD R1, R2, R3→ 把 R2 和 R3 相加,结果存入 R1 - CISC:
MOV [BX+SI+10], AX→ 一条指令完成地址计算+内存写入
2️⃣ 指令执行周期短(Single-Cycle Execution)
- 大多数指令在一个时钟周期内完成。
- 通过简化指令和硬件设计实现。
3️⃣ 大量通用寄存器(Large Register File)
- 寄存器数量多(如 ARM 有 16 个通用寄存器,RISC-V 有 32 个)。
- 减少对内存的访问,提高速度。
4️⃣ 采用流水线技术(Pipelining)
- 指令执行分为多个阶段(取指、译码、执行、访存、写回),并行处理。
- RISC 指令简单统一,非常适合流水线。
5️⃣ 加载/存储架构(Load/Store Architecture)
- 只有
LOAD和STORE指令可以访问内存。 - 其他运算指令只能在寄存器之间进行。
3
假定某计算机中有一条转移指令,采用相对寻址方式,共占两字节,第一字节是操作码,第二字节是 相对位移量(用补码表示),CPU每次从内存只能取一字节。假设执行到某转移指令时 PC的内容为200, 执行该转移指令后要求转移到100开始的一段程序执行,则该转移指令第二字节的内容应该是多少?

4
4.假设地址为1200H的内存单元中的内容为12FCH,地址为12FCH的内存单元的内容为38B8H,而 38B8H单元的内容为88F9H。说明以下各情况下操作数的有效地址是多少? (1)操作数采用变址寻址,变址寄存器的内容为252,指令中给出的形式地址为1200H。 (2)操作数采用一次间接寻址,指令中给出的地址码为1200H。 (3)操作数采用寄存器间接寻址,指令中给出的寄存器编号为8,8号寄存器的内容为1200H。

5
6.某计算机指令系统采用定长指令字格式,指令字长16位,每个操作数的地址码长6位。指令分二 地址、单地址和零地址3类。若二地址指令有k2条,零地址指令有k0条,则单地址指令最多有多少条?

第五章作业
1.
CPU的基本组成和基本功能各是什么?
1. CPU 的基本组成 (Basic Composition)
CPU 在硬件上主要由 数据通路 (Datapath) 和 控制器 (Control Unit) 两大部分组成。
- 数据通路 (Datapath):
- 定义:它是 CPU 中负责数据处理和信号传递的路径,“干活的肌肉”。
- 包含的核心部件:
- 运算部件 (ALU):负责算术运算(加减)和逻辑运算(与或)。
- 寄存器堆 (Register File):CPU 内部的高速存储单元,用于暂存操作数和运算结果(如 rs, rt, rd)。
- 程序计数器 (PC):存着当前或下一条指令的地址,是指令流动的“指针”。
- 其他连接部件:包括多路选择器 (MUX)、加法器 (Adder)、符号扩展单元 (SignExt) 等,用于连通电路和辅助计算。
- 控制器 (Control Unit):
- 定义:它是 CPU 的“大脑”,指挥数据通路工作。
- 功能:根据指令的操作码 (Opcode) 和功能码
(Func),生成各种控制信号(如
RegDst,ALUSrc,MemWr等),控制 MUX 的选通和寄存器的读写。
2. CPU 的基本功能 (Basic Functions)
CPU 的功能就是执行指令,这一过程通常被称为 “指令周期”。结合 PPT 中的流程,基本功能可以概括为以下四点:
- 指令控制 (Instruction Control):
- 取指令:控制程序按照顺序执行 (
PC + 4) 或进行跳转 (beq/j)。确保 CPU 能自动地、连续地从存储器中取出指令。
- 取指令:控制程序按照顺序执行 (
- 操作控制 (Operation Control):
- 译码与指挥:对取出的指令进行译码(分析
Opcode),产生相应的控制信号,指挥各个部件按规定的动作工作(例如:看到
lw就打开内存读开关,看到add就指挥 ALU 做加法)。
- 译码与指挥:对取出的指令进行译码(分析
Opcode),产生相应的控制信号,指挥各个部件按规定的动作工作(例如:看到
- 时间控制 (Time Control):
- 时序同步:对各种操作实施时间上的定时。通过 时钟信号 (Clk) 来同步所有部件的动作(例如:规定在时钟上升沿更新 PC,在下降沿写入寄存器),保证计算机有条不紊地工作。
- 数据加工 (Data Processing):
- 运算:利用 ALU 对数据进行算术运算(如
add)和逻辑运算(如ori),这是 CPU 最根本的功能。
- 运算:利用 ALU 对数据进行算术运算(如
2. 取指令部件的功能是什么?
根据 PPT image_373184.png,取指令部件 (Instruction Fetch
Unit) 主要有两个核心功能:
- 取指令:根据程序计数器 (PC) 中的地址,从指令存储器
(Instruction Memory) 中读取出当前的指令字 (
M[PC])。 - 更新 PC:计算下一条指令的地址。通常情况下是顺序执行
(
PC <- PC + 4);如果是跳转或分支指令,则更新为目标跳转地址。
3. 控制器的功能是什么?
根据 PPT image_2f0f80.png 和 image_2f0cd7.png 中展示的真值表逻辑:
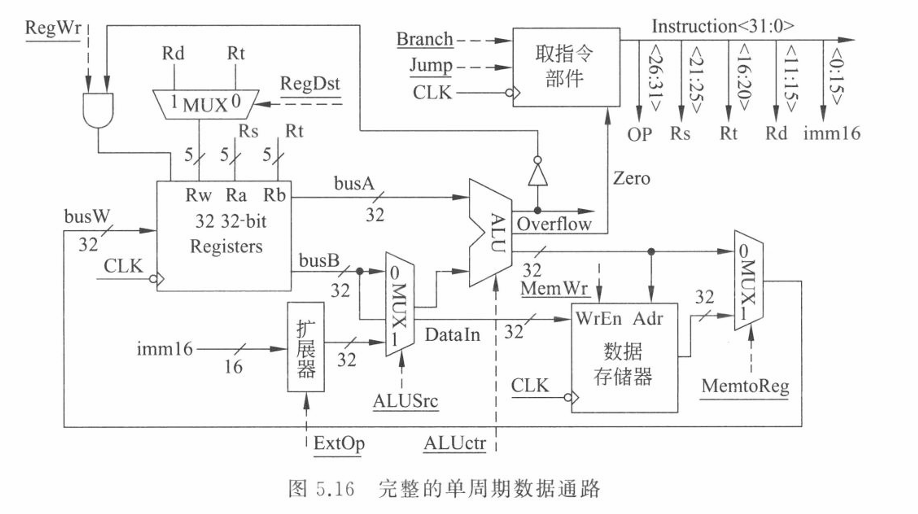
控制器的功能是“翻译”和“指挥”。它接收指令中的 操作码 (op) 和 功能码 (func),通过译码逻辑,产生一系列的 控制信号 (如 RegDst, ALUSrc, RegWr, MemtoReg 等)。这些信号控制着数据通路中各个多路选择器 (MUX)、ALU 和寄存器的动作,确保指令按预定逻辑执行。
4. 单周期处理器相关问题
- 单周期处理器的 CPI 是多少?
- CPI = 1。
- 原因:顾名思义,单周期处理器每条指令都在一个时钟周期内完成。
- 时钟周期如何确定?
- 时钟周期取决于 最复杂指令(通常是
lw)的执行时间,也就是数据通路中的 关键路径 (Critical Path)。 - 计算公式:Tcycle≥ 取指时间 + 译码/读寄存器时间 + ALU运算时间 + 读数据存储器时间 + 写回时间。必须保证最慢的指令也能在一个周期内跑完。
- 时钟周期取决于 最复杂指令(通常是
- 为什么单周期处理器的性能差?
- 因为 时钟周期被“最慢的指令”拖累了。
- 解释:虽然像
add或beq这样的简单指令本来可以跑得很快(比如只要 400ps),但因为时钟周期必须迁就最慢的lw指令(比如 600ps),所以简单指令执行完后必须 空转等待,直到周期结束。这就造成了巨大的时间浪费,导致整体效率低下。
5. 单周期方式下,在一个指令周期内某个部件能否被重复使用多次?为什么?
- 回答:不能。
- 为什么:
- 在单周期设计中,指令的执行像水流一样流过数据通路,每个部件在每个周期内只能处理这一个指令流过的数据。
- 如果需要重复使用某个功能(例如需要做两次加法:一次算 PC+4,一次算
ALU 运算),硬件上必须
设置多份独立的部件(例如设置专门的加法器用于 PC
更新,见
image_2dc282.png中的 Adder),而不能复用同一个 ALU。 - 原因总结:如果复用,会产生 资源冲突 (Structural Hazard),因为在一个时钟周期内,一个部件无法同时处理两个不同的任务。
6

| 指令 | 含义 | 格式 | 核心动作 | 关键区分点 |
|---|---|---|---|---|
| add | 加法 | op rs rt rd shamt func |
Reg + Reg -> Reg | 写 rd |
| sub | 减法 | op rs rt rd shamt func |
Reg - Reg -> Reg | 写 rd |
| ori | 逻辑或 | op rs rt imm |
Reg OR ZeroExt(Imm) | 零扩展 |
| lw | 取数 | op rs rt imm |
Mem[Base+Off] -> Reg | 读内存, 写 rt |
| sw | 存数 | op rs rt imm |
Reg -> Mem[Base+Off] | 写内存 |
| beq | 分支 | op rs rt imm |
if (Reg==Reg) Jump | 比较, 条件跳 |
| j | 跳转 | op target |
Goto Target | 无条件, 拼接地址 |
1. RegWr
(寄存器写使能)
- 正常功能:
1:允许将数据写入寄存器堆(用于R-type,ori,lw)。0:禁止写入(用于sw,beq,j)。
- 若恒为 0:寄存器堆的大门永远关上了,任何数据都写不进去。
- 受影响指令:所有需要写回结果的指令,包括
R型指令 (
add,sub等)、ori和lw。它们虽然能算出结果,但存不下来,相当于白忙活。
2. RegDst
(写入目标寄存器选择)
- 正常功能:
1:写入目标是rd(指令 11-15 位),用于 R型指令。0:写入目标是rt(指令 16-20 位),用于lw,ori。
- 若恒为 0:写入数据的目的地永远被锁定在
rt。 - 受影响指令:R型指令 (
add,sub等)。这些指令本该把结果存入rd,现在却错误地覆盖了rt寄存器里的内容。- 注:
lw和ori本来就要选 0,所以它们不受影响。
- 注:
3. ALUSrc (ALU
源操作数选择)
- 正常功能:
1:ALU 的第二个输入选 立即数 (用于lw,sw,ori)。0:ALU 的第二个输入选 寄存器 B (用于R-type,beq)。
- 若恒为 0:ALU 永远看不见立即数,只能看见寄存器 B。
- 受影响指令:
lw,sw,ori。这些指令需要用到立即数(算地址或做逻辑运算),信号错误会导致 ALU 使用错误的操作数进行计算。
4. Branch
(分支信号)
- 正常功能:
1:表示当前是分支指令,如果Zero=1则更新 PC 为跳转目标。0:表示顺序执行 PC+4。
- 若恒为 0:与门永远输出 0,PC 永远无法加载分支目标地址。
- 受影响指令:
beq。即使比较结果相等(应跳转),CPU 也会无视,继续执行下一条指令,导致分支失效。
5. MemWr
(存储器写使能)
- 正常功能:
1:允许向数据存储器写入数据 (用于sw)。0:只读不写。
- 若恒为 0:数据存储器变成了“只读”模式。
- 受影响指令:
sw。该指令的功能就是存数,写不进去就完全失效了。
6. ExtOp
(扩展模式选择)
- 正常功能:
1:进行 符号扩展 (Sign Extension),用于lw,sw(处理负偏移量)。0:进行 零扩展 (Zero Extension),用于ori。
- 若恒为 0:所有立即数都按“零扩展”处理。
- 受影响指令:
lw和sw。- 如果偏移量是正数,运气好还能对;但如果偏移量是 负数,零扩展会把它变成一个巨大的正数,导致计算出的内存地址完全错误。
7. R-type
(R型指令标识)
- 正常功能:这通常是一个译码信号。当它为
1时,ALU 控制器会去查看func字段来决定具体做什么运算(加、减、与、或等)。当它为0时,ALU 控制器通常执行默认操作(如加法,服务于lw/sw)。 - 若恒为 0:ALU 控制器认为当前“不是
R型指令”,因此忽略
func字段,直接执行默认操作(通常是ADD)。 - 受影响指令:除了
add以外的所有 R型指令 (sub,and,or,slt等)。它们会被错误地执行成加法。
8. MemtoReg
(写回数据来源选择)
- 正常功能:
1:写回寄存器的数据来自 存储器 (用于lw)。0:写回寄存器的数据来自 ALU (用于R-type,ori)。
- 若恒为 0:写回通路永远连着 ALU,断开了存储器。
- 受影响指令:
lw。该指令本想把从内存读出的数据存进寄存器,结果却错误地把内存地址(ALU 计算结果)存进去了。
| 信号 (恒为1) | 不能正确执行的指令 | 简要原因 |
|---|---|---|
| RegWr | sw, beq, j | 意外修改寄存器内容 |
| RegDst | lw, ori | 结果存错寄存器 (rd 而非 rt) |
| ALUSrc | R-type, beq | 误用立即数代替寄存器运算 |
| Branch | 运算结果为0的指令 | 意外发生跳转 |
| MemWr | 除 sw 外所有指令 | 意外修改内存数据 |
| ExtOp | ori | 逻辑运算的高位扩展错误 |
| R-type | lw, sw, beq, ori | ALU 执行了错误的操作 |
| MemtoReg | R-type, ori | 写入了内存值而非计算结果 |
第六章作业
2(1)
1. 为什么“一条指令”的执行时间没有缩短?
流水线技术并不是让“单条指令跑得更快”,而是将一条指令拆分成多个步骤(如 IF, ID, EX, MEM, WB)。
- 寄存器延迟(Overhead):在流水线的每个阶段之间,都需要加入流水线寄存器来保存中间结果。这些寄存器本身有读写延迟(建立时间、保持时间)。
- 木桶效应:流水线的时钟周期取决于最慢的那一个阶段。
- 假设非流水线执行一条指令需要 800ps。
- 将其切分为 5 段流水线,每段 160ps。但因为要加上寄存器延迟(假设 10ps),周期可能变成了 170ps。
- 那么一条指令走完 5 个阶段总共需要 170 × 5 = 850ps。
- 结论:单条指令从进入流水线到流出,所花费的总时间(潜伏期,Latency)反而因为寄存器的开销而略微增加了。
2. 为什么“程序”的执行时间缩短了?
流水线的核心优势在于并行(Parallelism)*和*吞吐率(Throughput)。
并行处理:虽然一条指令要 5 个周期才做完,但当第一条指令在做“第二步”时,第二条指令已经开始做“第一步”了。
吞吐率提升:
- 非流水线:每 800ps 才能完成一条指令。
- 流水线:一旦流水线填满,每 170ps 就能有一条指令完成(理想情况下)。
数据证明:
参考你之前的 PPT image_edf843.png:
- 单周期方式执行 N 条指令:时间 = 600N ps。
- 流水线方式执行 N 条指令:时间 = 234N ps。
- 结论:234N < 600N,程序的总执行时间被显著缩短了。
2(5)
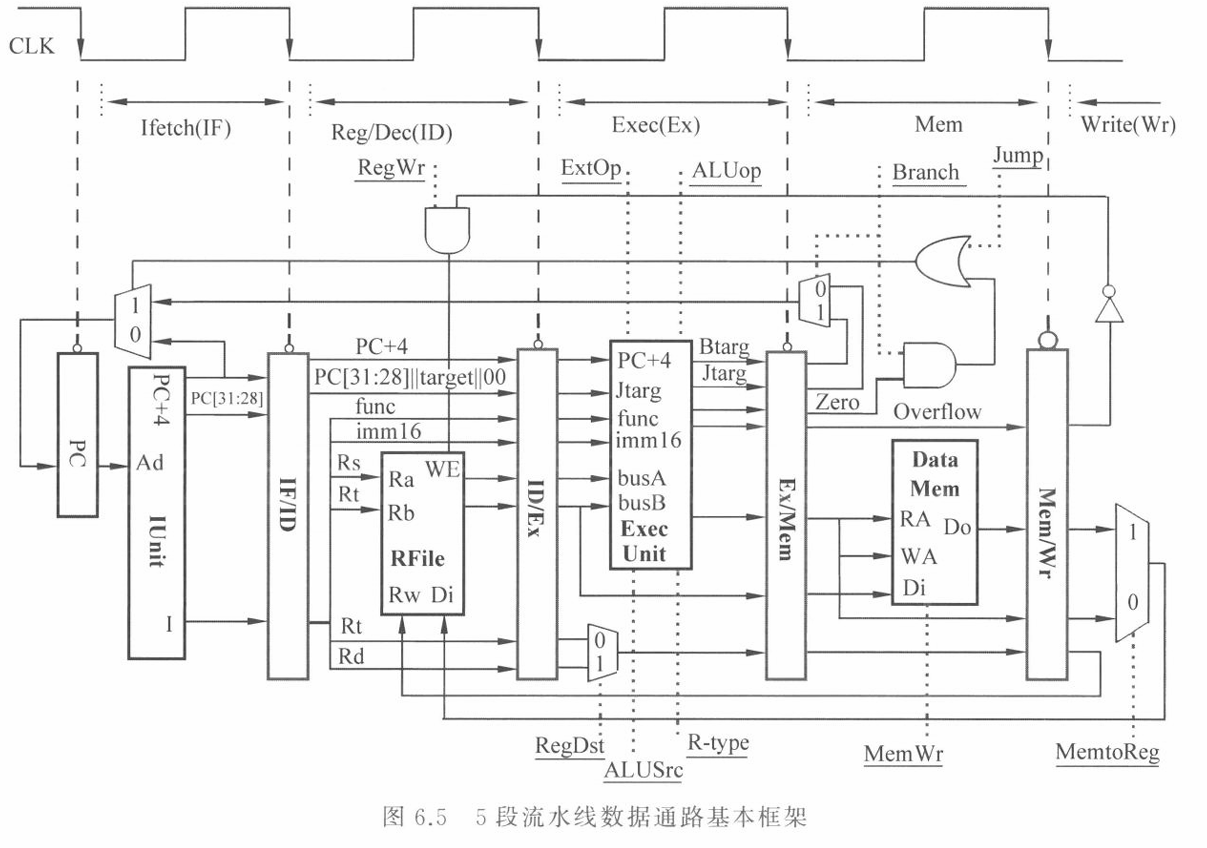
(1) 为什么要各流水段之间加寄存器?
简单来说,流水线寄存器(Pipeline Registers)是实现“流水线”功能的物理基础。
- 保存中间结果(记忆功能):每个时钟周期结束时,当前阶段完成的工作(比如计算出的地址、读出的寄存器值)必须被保存下来,才能在下一个时钟周期传给下一阶段使用。如果没有寄存器,信号会瞬间流过整个电路,变成单周期处理器,无法并行。
- 隔离各个阶段(解耦):寄存器像一堵墙,把复杂的组合逻辑电路切成了 5 小段。这样,第 1 段在取指时,第 2 段可以同时在译码,互不干扰。
- 同步时钟:所有的流水线寄存器由同一个时钟信号控制,确保所有指令像排队一样,整齐划一地每过一个周期向前挪一步。
(2) 各流水段寄存器的宽度是否都一样?
不一样。
(3) 为什么?
因为每个阶段需要传递给后续阶段的信息量是不同的。
流水线寄存器的宽度取决于后面所有的阶段需要用到哪些信息。所有的信息(包括数据信号和控制信号)都必须像接力棒一样,一层一层往下传。
我们可以具体拆解一下(以标准的 MIPS 32位 5级流水线为例):
- IF/ID 寄存器(通常最窄):
- 只需要保存:指令本身(32位) + 下一条指令地址 PC+4(32位)。
- 总宽约 64位。
- ID/EX 寄存器(通常最宽):
- 这一步刚把指令翻译完,需要把所有原材料都带上:读出的两个寄存器数据(32+32位)、扩展后的立即数(32位)、PC+4(32位)、写回的目标寄存器号(5位),再加上一大堆控制信号(WB, MEM, EX 段的信号)。
- 总宽往往超过 100位。
- EX/MEM 寄存器:
- ALU用完的数据不需要传了,但算出的结果要传:ALU计算结果(32位)、准备写入内存的数据(32位)、写回目标寄存器号(5位)以及剩下的控制信号。
- 宽度变小。
- MEM/WB 寄存器:
- 内存操作完,只需要传:读取的内存数据(32位)、ALU结果(32位)、写回目标寄存器号(5位)以及最后的 WB 控制信号。
- 宽度进一步变化。
3

首先,我们根据题目给出的数据,列出当前各个阶段的耗时:
- IF (取指):使用存储单元 → 200ps
- ID (译码):寄存器堆读 → 50ps
- EX (执行):ALU 和加法器 → 150ps
- MEM (访存):使用存储单元 → 200ps
- WB (写回):寄存器堆写 → 50ps
当前基准时钟周期:
Tclk = max (200, 50, 150, 200, 50) = 200ps。
目前的瓶颈是 IF 和 MEM 阶段。
(1) 若 EX 阶段的 ALU 时间缩短 20%
- 计算:新的 ALU 时间 = 150ps × (1 − 20%) = 120ps。
- 分析:此时流水线各段最长时间依然是 IF 和 MEM 的 200ps。EX 阶段本来就不是瓶颈(150ps < 200ps),缩短它只会让它等待的时间更长(气泡更多)。
- 结论:不能加快流水线执行速度。时钟周期仍然维持在 200ps。
(2) 若 ALU 操作时间增加 20%
- 计算:新的 ALU 时间 = 150ps × (1 + 20%) = 180ps。
- 分析:虽然 ALU 变慢了,但 180ps 仍然小于最慢的存储器访问时间(200ps)。流水线的“短板”依然是存储器。
- 结论:对流水线性能没有影响。时钟周期仍然维持在 200ps。
(3) 若 ALU 操作时间增加 40%
- 计算:新的 ALU 时间 = 150ps × (1 + 40%) = 210ps。
- 分析:此时 EX
阶段的时间(210ps)超过了原本的瓶颈(200ps)。
- 旧瓶颈:200ps
- 新瓶颈:210ps
- 根据木桶效应,时钟周期必须迁就最慢的阶段。
- 结论:流水线性能会下降。时钟周期必须调整为 210ps,导致整体运行速度变慢。
4

(1) 在非流水线处理器上执行该程序需要花多长时间?
非流水线处理器采用串行执行方式,上一条指令完全做完,下一条才开始。
计算公式:总时间 = 指令条数 × 单条指令执行时间
计算过程:
Tnon-pipe = 106 × 100ps = 108ps
单位换算:
108ps = 100, 000ns = 100μs
答案: 需要花 100μs(或者写 108ps)。
(2) 若新 CPU 采用 20 级流水线,理想情况下,它比非流水线处理器快多少?
这道题可以从两个角度回答,一个是计算加速比,一个是计算具体时间。题目问的是“快多少”(倍数),通常指加速比。
理想流水线假设:
- 流水线各段 perfectly balanced(完全平衡),每段耗时相等。
- 没有流水线填充时间的损耗(当 N 很大时,k − 1 个填充周期可忽略)。
流水线时钟周期:
$$T_{\text{clk}} = \frac{\text{非流水线指令时间}}{\text{流水线级数}} = \frac{100\text{ps}}{20} = 5\text{ps}$$
流水线总执行时间:
Tpipe ≈ N × Tclk = 106 × 5ps = 5 × 106ps
(注:精确公式为 (N + k − 1) × Tclk,但 106 ≫ 19,故忽略不计)
计算加速比 (Speedup):
$$\text{Speedup} = \frac{T_{\text{non-pipe}}}{T_{\text{pipe}}} = \frac{100 \times 10^6\text{ps}}{5 \times 10^6\text{ps}} = 20$$
答案: 理想情况下,它比非流水线处理器快 20 倍。
(一句话结论:理想情况下,多少级流水线,就获得多少倍的加速比)
(3) 实际流水线并是不是理想的,流水段之间的数据传送会有额外开销。这些开销是否会影响指令执行时间和指令吞吐率?
这是一个考察对流水线“潜伏期(Latency)”和“吞吐率(Throughput)”概念理解的问题。
回答:是的,会有影响。 具体分析如下:
- 对“指令执行时间”(Latency)的影响:
会变长。
- 定义:指一条指令从进入流水线第一段到最后一段完成所需要的总时间。
- 分析:在非流水线中,时间纯粹是逻辑电路的操作时间(100ps)。在流水线中,为了保存中间结果,每一级之间都要加入流水线寄存器。这些寄存器有建立时间、保持时间等物理延迟(Overhead)。
- 结果:一条指令在流水线中走完 20 级,总耗时 = 20 × (理想每级时间 + 寄存器延迟)。这个总和一定大于原来的 100ps。
- 对“指令吞吐率”(Throughput)的影响:
会降低(相比理想流水线)。
- 定义:指单位时间内完成的指令数量($\text{TP} = \frac{1}{T_{\text{clk}}}$)。
- 分析:流水线的时钟周期 Tclk 必须足够长,以容纳最慢的一段逻辑操作加上寄存器的延迟开销。
- 结果:实际时钟周期 Tactual = 5ps + Overhead。因为分母变大了,所以吞吐率 $\frac{1}{T_{\text{actual}}}$ 会比理想吞吐率 $\frac{1}{5\text{ps}}$ 要低。
总结答案:
会影响。
- 指令执行时间(单条延迟):会增加(因为加入了流水线寄存器的延迟开销)。
- 指令吞吐率:会降低(相比于没有开销的理想流水线,因为时钟周期被迫变长了)。
6

1. 哪些指令对之间发生数据相关(Data Dependency)?
我们要找出“写后读”(RAW, Read After Write)的依赖关系。
- 第一组相关:
$s3- 产生者:第 1 条指令
addu $s3, $s1, $s0(写入$s3) - 消费者:第 2 条指令
addu $t2, $s3, $s3(读取$s3) - 描述:第 2 条指令依赖第 1 条指令的结果。
- 产生者:第 1 条指令
- 第二组相关:
$t2- 产生者:第 2 条指令
addu $t2, $s3, $s3(写入$t2) - 消费者:第 3 条指令
lw $t1, 0($t2)(读取$t2作为基地址) - 以及:第 4 条指令
add $t3, $t1, $t2(读取$t2) - 描述:第 3 条和第 4 条指令都依赖第 2 条指令的结果。
- 产生者:第 2 条指令
- 第三组相关:
$t1- 产生者:第 3 条指令
lw $t1, 0($t2)(写入$t1) - 消费者:第 4 条指令
add $t3, $t1, $t2(读取$t1) - 描述:第 4 条指令依赖第 3 条指令的结果。
- 产生者:第 3 条指令
2. 如果不用“转发”技术,需要加几条 NOP?
规则分析: 在没有转发机制的标准 5 段流水线中,数据必须在 WB(写回) 阶段写入寄存器堆后,才能在 ID(译码) 阶段被后续指令读取。
- 写操作发生在第 5 个时钟周期(WB)。
- 读操作发生在第 2 个时钟周期(ID)。
- 这意味着,产生数据的指令必须先完成 WB 阶段,使用数据的指令才能进入 ID 阶段。对于相邻的两条相关指令,中间通常需要间隔 2 个时钟周期(即插入 2 条 NOP)。
具体插入情况:
在第 1 条和第 2 条之间(解决
$s3相关): 需要插入 2 条 NOP。Plaintext
1
2
3
4addu $s3, $s1, $s0
nop
nop
addu $t2, $s3, $s3在第 2 条和第 3 条之间(解决
$t2相关): 需要插入 2 条 NOP。Plaintext
1
2
3
4addu $t2, $s3, $s3
nop
nop
lw $t1, 0($t2)在第 3 条和第 4 条之间(解决
$t1相关): 需要插入 2 条 NOP。Plaintext
1
2
3
4lw $t1, 0($t2)
nop
nop
add $t3, $t1, $t2(注:虽然第 4 条也依赖第 2 条的
$t2,但因为中间已经隔了第 3 条指令和它的 NOP,所以$t2的数据早就准备好了,不需要额外处理)
结论(无转发): 需要在每组发生数据相关的相邻指令前加入 2 条 NOP 指令。
3. 如果采用“转发”,是否可以完全解决数据冒险?
回答:不可以。
原因分析(Load-Use 冒险):
- ALU 到 ALU 的冒险(如第 1、2 条之间,第 2、3 条之间)可以通过转发完全解决。数据在 EX 阶段算出后,可以直接从流水线寄存器转发给下一条指令的 EX 阶段输入。
- Load 到 ALU 的冒险(即第 3 条
lw和第 4 条add之间)无法完全解决。lw指令的数据是在 MEM(访存) 阶段结束时才从内存读出的(时钟周期 4)。add指令需要在 EX(执行) 阶段开始时使用数据进行计算(时钟周期 3)。- 时间悖论:数据在未来(第 4 周期)才产生,但现在(第 3 周期)就要用。这是物理上做不到的,这被称为 Load-Use Hazard。
4. 如果不行,需要加入几条 NOP?
针对上述的 Load-Use 冒险,必须让流水线暂停一个周期,等待数据从内存读出。
- 位置:在第 3 条
lw和第 4 条add之间。 - 数量:1 条 NOP。
- 加了 1 条 NOP 后,
add指令晚一个周期进入 EX 阶段,此时lw刚好走完 MEM 阶段,数据可以通过 MEM/WB 寄存器转发给add。
- 加了 1 条 NOP 后,
最终代码序列(采用转发):
MIPS Assembler
1 | addu $s3, $s1, $s0 |
结论(有转发): 需要在发生数据相关的第 4
条指令(add)之前加入 1 条 NOP 指令。