算法流程
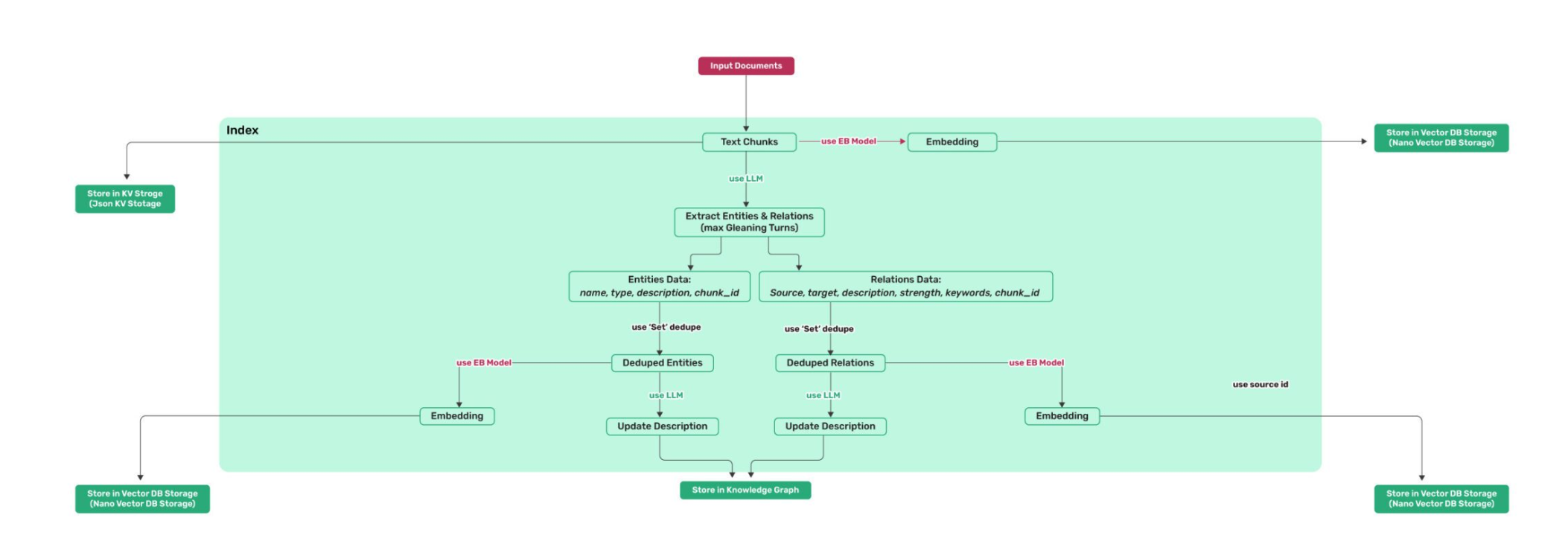 image-20250924135355928
image-20250924135355928
对文本进行分块后,分别存储在kvstorage与
VectorDB Storage
然后调用大模型进行实体与关系抽取(Extract
Entities & Relations)
然后进行实体与关系的存储(Entities Data
/ Relations
Data),去重后(Deduplication),再次调用embedding模型存储于VectorDB
Storage
再次调用大模型,对关系与实体的描述进行精炼或合并(Update
Description),并存储到Knowledge
Graph
 image
image
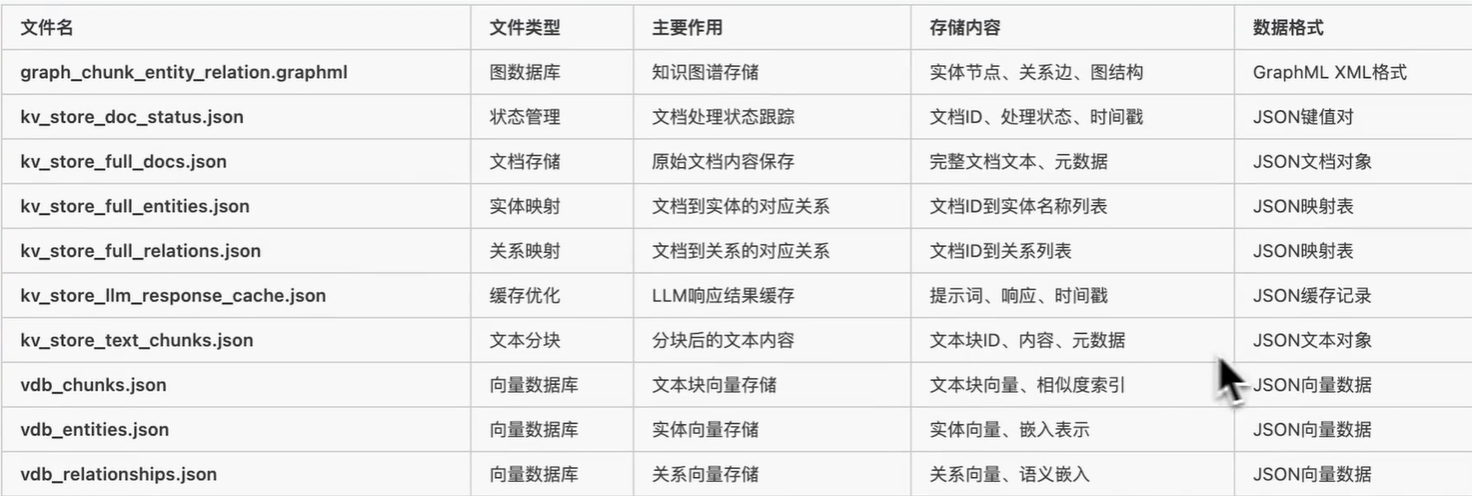
LightRAG 使用 4 种类型的存储用于不同目的:
- KV_STORAGE:llm 响应缓存、文本块、文档信息
- VECTOR_STORAGE:实体向量、关系向量、块向量
- GRAPH_STORAGE:实体关系图
- DOC_STATUS_STORAGE:文档索引状态
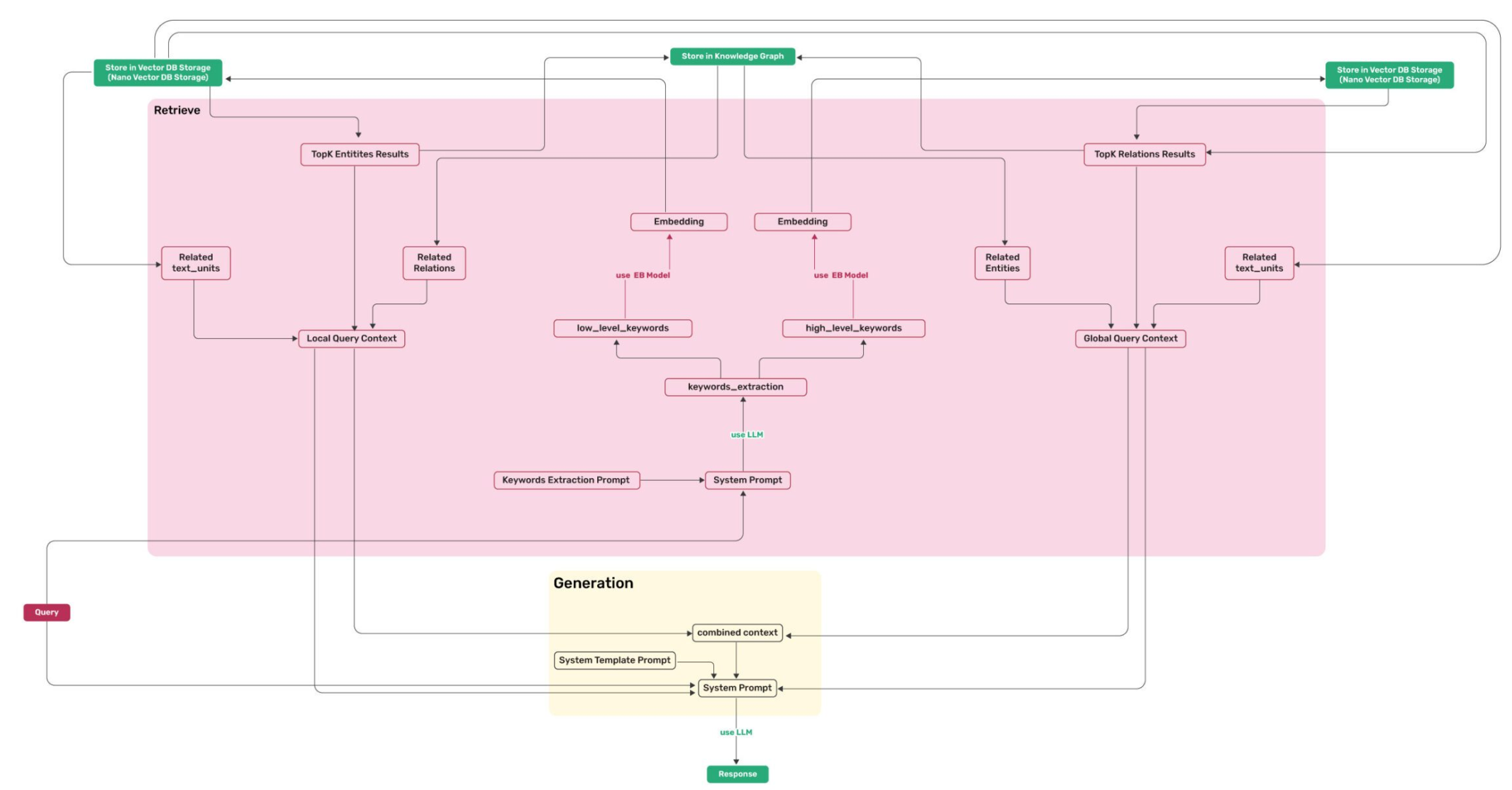 image-20250924142554264
image-20250924142554264
值得注意的是,local检索模式仅使用low_level_keywords,而global检索模式仅支持high_level_keywords,从算法流程图可以看出来,前者更侧重于检索实体,后者则侧重于关系
高关键词(High-level
Keywords)用于捕获查询的核心意图和主题概念;低关键词(Low-level
Keywords)用于识别具体的实体和细节信息
text_units的作用是:
- 每条实体/关系记录在 KV 里都挂着
chunk_ids 列表。
- 把 Top-K 结果里的
chunk_ids 做 合并 +
去重,得到原始文本块序号。
- 用序号去 Nano VectorDB 里把对应
text_units(原始句子/段落) 拉回,作为
上下文原始语料。
 image-20250924135917313
image-20250924135917313
安装
安装LightRAG服务器
LightRAG服务器旨在提供Web UI和API支持。Web
UI便于文档索引、知识图谱探索和简单的RAG查询界面。LightRAG服务器还提供兼容Ollama的接口,旨在将LightRAG模拟为Ollama聊天模型。这使得AI聊天机器人(如Open
WebUI)可以轻松访问LightRAG。
1
2
3
| pip install "lightrag-hku[api]"
cp env.example .env
lightrag-server
|
在此获取LightRAG docker镜像历史版本: LightRAG
Docker Images
安装 LightRAG Core
1
| pip install lightrag-hku
|
LightRAG 服务器和 WebUI
LightRAG/lightrag/api/README-zh.md
at main · HKUDS/LightRAG
LightRAG 服务器旨在提供 Web 界面和 API 支持。Web
界面便于文档索引、知识图谱探索和简单的 RAG 查询界面。
使用环境变量来配置 LightRAG
服务器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| LLM_BINDING=openai
LLM_MODEL=qwen3-max-preview
LLM_BINDING_HOST=https://dashscope.aliyuncs.com/compatible-mode/v1
LLM_BINDING_API_KEY=sk-
EMBEDDING_BINDING=openai
EMBEDDING_MODEL=text-embedding-v4
EMBEDDING_DIM=1024
EMBEDDING_BINDING_API_KEY=sk-
EMBEDDING_BINDING_HOST=https://dashscope.aliyuncs.com/compatible-mode/v1
############################
### 数据存储选择
############################
### 默认存储(推荐用于小规模部署)
LIGHTRAG_KV_STORAGE=JsonKVStorage
LIGHTRAG_DOC_STATUS_STORAGE=JsonDocStatusStorage
LIGHTRAG_GRAPH_STORAGE=NetworkXStorage
LIGHTRAG_VECTOR_STORAGE=NanoVectorDBStorage
### 图存储(推荐用于生产部署)
# LIGHTRAG_GRAPH_STORAGE=Neo4JStorage
# LIGHTRAG_GRAPH_STORAGE=MemgraphStorage
### PostgreSQL
# LIGHTRAG_KV_STORAGE=PGKVStorage
# LIGHTRAG_DOC_STATUS_STORAGE=PGDocStatusStorage
# LIGHTRAG_GRAPH_STORAGE=PGGraphStorage
# LIGHTRAG_VECTOR_STORAGE=PGVectorStorage
### PostgreSQL 配置
# POSTGRES_HOST=localhost
# POSTGRES_PORT=5432
# POSTGRES_USER=您的用户名
# POSTGRES_PASSWORD='您的密码'
# POSTGRES_DATABASE=您的数据库
### Neo4j 配置
# NEO4J_URI=neo4j+s://xxxxxxxx.databases.neo4j.io
# NEO4J_USERNAME=neo4j
# NEO4J_PASSWORD='您的密码'
# NEO4J_DATABASE=noe4j
### Milvus 配置
# MILVUS_URI=http://localhost:19530
# MILVUS_DB_NAME=lightrag
# MILVUS_USER=root
# MILVUS_PASSWORD=您的密码
|
启动
这是因为每次启动时,LightRAG
Server会将.env文件中的环境变量加载至系统环境变量,且系统环境变量的设置具有更高优先级。
启动时可以通过命令行参数覆盖.env文件中的配置。常用的命令行参数包括:
--host:服务器监听地址(默认:0.0.0.0)--port:服务器监听端口(默认:9621)--working-dir:数据库持久化目录(默认:./rag_storage)--input-dir:上传文件存放目录(默认:./inputs)--workspace:
工作空间名称,用于逻辑上隔离多个LightRAG实例之间的数据(默认:空)
启动多个LightRAG实例
所有实例共享一套相同的.env配置文件,然后通过命令行参数来为每个实例指定不同的服务器监听端口和工作空间。你可以在同一个工作目录中通过不同的命令行参数启动多个LightRAG实例。例如:
1
2
3
4
5
| # 启动实例1
lightrag-server --port 9621 --workspace space1
# 启动实例2
lightrag-server --port 9622 --workspace space2
|
运行
 image-20250926162648415
image-20250926162648415
 image-20250926162703167
image-20250926162703167
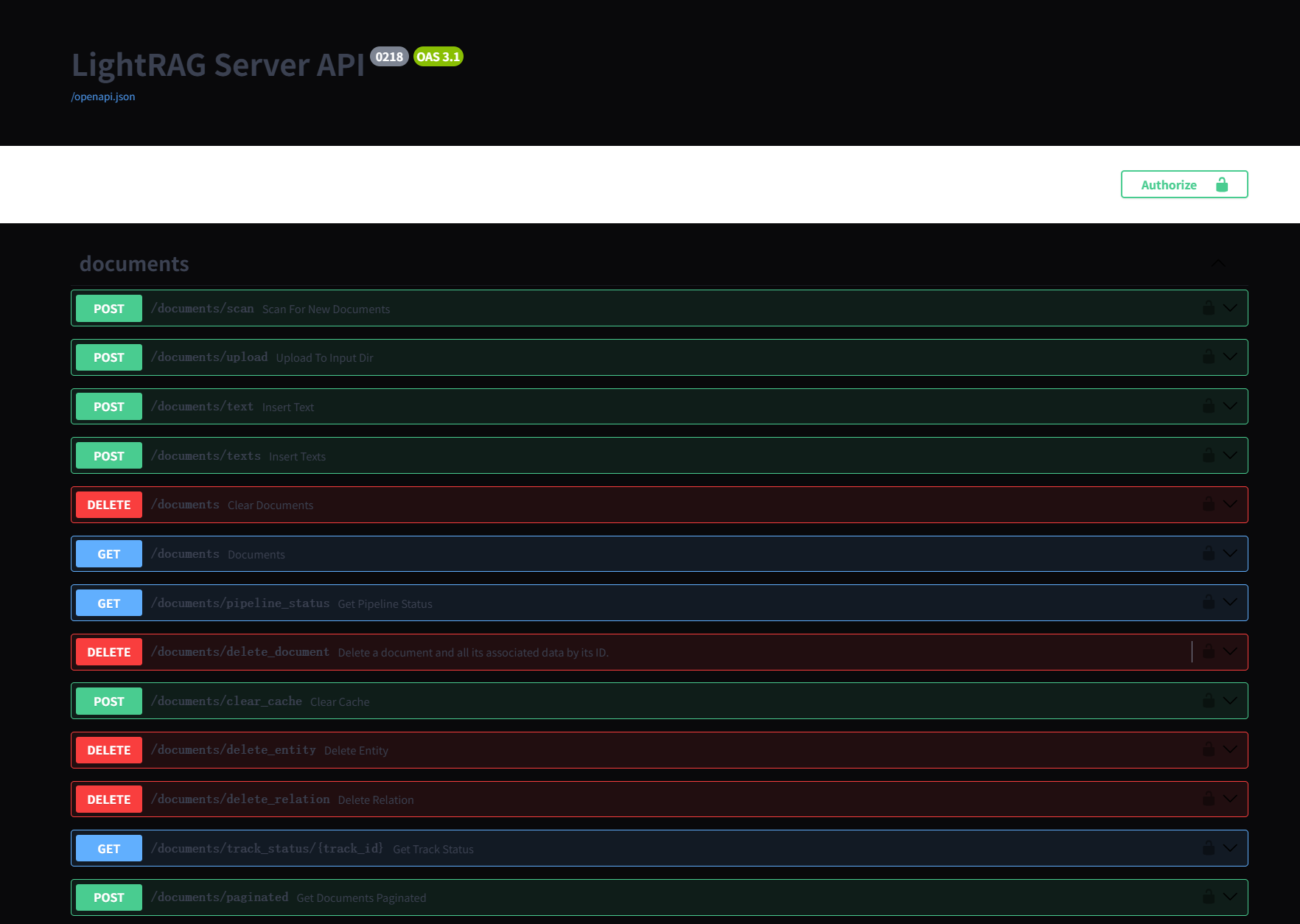 image-20250926162714883
image-20250926162714883
LightRAG的数据隔离
需要通过配置工作空间来实现数据隔离,否则不同实例的数据将会出现冲突并被破坏。
LightRAG 使用 4 种类型的存储用于不同目的:
- KV_STORAGE:llm 响应缓存、文本块、文档信息
- VECTOR_STORAGE:实体向量、关系向量、块向量
- GRAPH_STORAGE:实体关系图
- DOC_STATUS_STORAGE:文档索引状态
每种存储类型都有多种存储实现方式。LightRAG
Server默认的存储实现为内存数据库,数据通过文件持久化保存到WORKING_DIR目录。LightRAG还支持PostgreSQL、MongoDB、FAISS、Milvus、Qdrant、Neo4j、Memgraph和Redis等存储实现方式。
您可以通过环境变量选择存储实现。例如,在首次启动 API
服务器之前,您可以将以下环境变量设置为特定的存储实现名称:
1
2
3
4
| LIGHTRAG_KV_STORAGE=PGKVStorage
LIGHTRAG_VECTOR_STORAGE=PGVectorStorage
LIGHTRAG_GRAPH_STORAGE=PGGraphStorage
LIGHTRAG_DOC_STATUS_STORAGE=PGDocStatusStorage
|
文档和块处理逻辑说明
LightRAG
中的文档处理流程有些复杂,分为两个主要阶段:提取阶段(实体和关系提取)和合并阶段(实体和关系合并)。有两个关键参数控制流程并发性:并行处理的最大文件数(MAX_PARALLEL_INSERT)和最大并发
LLM 请求数(MAX_ASYNC)。工作流程描述如下:
MAX_ASYNC 限制系统中并发 LLM
请求的总数,包括查询、提取和合并的请求。LLM
请求具有不同的优先级:查询操作优先级最高,其次是合并,然后是提取。MAX_PARALLEL_INSERT
控制提取阶段并行处理的文件数量。MAX_PARALLEL_INSERT建议设置为2~10之间,通常设置为
MAX_ASYNC/3,设置太大会导致合并阶段不同文档之间实体和关系重名的机会增大,降低合并阶段的效率。- 在单个文件中,来自不同文本块的实体和关系提取是并发处理的,并发度由
MAX_ASYNC 设置。只有在处理完 MAX_ASYNC
个文本块后,系统才会继续处理同一文件中的下一批文本块。
- 当一个文件完成实体和关系提后,将进入实体和关系合并阶段。这一阶段也会并发处理多个实体和关系,其并发度同样是由
MAX_ASYNC 控制。
- 合并阶段的 LLM
请求的优先级别高于提取阶段,目的是让进入合并阶段的文件尽快完成处理,并让处理结果尽快更新到向量数据库中。
- 为防止竞争条件,合并阶段会避免并发处理同一个实体或关系,当多个文件中都涉及同一个实体或关系需要合并的时候他们会串行执行。
- 每个文件在流程中被视为一个原子处理单元。只有当其所有文本块都完成提取和合并后,文件才会被标记为成功处理。如果在处理过程中发生任何错误,整个文件将被标记为失败,并且必须重新处理。
- 当由于错误而重新处理文件时,由于 LLM
缓存,先前处理的文本块可以快速跳过。尽管 LLM
缓存在合并阶段也会被利用,但合并顺序的不一致可能会限制其在此阶段的有效性。
- 如果在提取过程中发生错误,系统不会保留任何中间结果。如果在合并过程中发生错误,已合并的实体和关系可能会被保留;当重新处理同一文件时,重新提取的实体和关系将与现有实体和关系合并,而不会影响查询结果。
- 在合并阶段结束时,所有实体和关系数据都会在向量数据库中更新。如果此时发生错误,某些更新可能会被保留。但是,下一次处理尝试将覆盖先前结果,确保成功重新处理的文件不会影响未来查询结果的完整性。
大家好,我想请教一下如何更好的使用这个项目,我现在处理的好慢,昨天从晚上十点跑到今天早上7点,只处理好33份文件[苦涩]我看日志,一份47页的pdf花了一个小时(mineru处理了十分钟)。
我自己总结下是有以下几个
1.我应该使用milvus和neo4j存储,而不是图方便存本地
2.设置一下并发,而不是每次只处理一个文件
3.不对图片进行处理了(感觉对我当前的场景没有必要)
针对第一点,我想问一下,存储到数据库是影响检索速率还是存储(我个人感觉是不是只影响检索啊)
Embedding模型应该本地部署,这样速度才比较快。一个文本块的Embedding速度在本地是毫秒级别的。调用云端API通常是秒级别的。
没有必要都用RagAnything来处理,先试一下用LightRAG来处理看一把速度如何。日后LightRAG会进程RagAnything,到时候可以灵活地指定每个文件的处理方式。
LightRAG的处理速度组要受到LLM的影响,与使用什么存储关系不是十分大。
LLM每秒能够输出的Tokens数量和支持的最大并发数决定了文档处理的速度。
例如一个LLM在8个并发的时候能够达到 400Tokens/秒
的峰值,预计处理速度达到15~20秒处理一个文本块。文本块的处理速度与识别出来的实体数量和实体关系需要合并的数量是有关的,因此不同文档是有所不同的。
可以用以上经验值来评估一下自己的系统处理速度是否合理。
实现代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
| class LightRAGStorage:
"""LightRAG存储和检索类
支持多种存储后端:
- KV存储: PostgreSQL
- 文档状态存储: PostgreSQL
- 图存储: Neo4j
- 向量存储: Milvus
使用workspace实现数据隔离
"""
def __init__(self, workspace: str = "default"):
"""初始化LightRAG存储
Args:
workspace: 工作空间名称,用于数据隔离
"""
self.workspace = workspace
# 加载环境变量
load_dotenv()
# 使用文件同级的 lightrag_storage 目录
self.working_dir = os.path.join(os.path.dirname(__file__), "lightrag_storage")
self.rag: Optional[LightRAG] = None
# 确保工作目录存在
os.makedirs(self.working_dir, exist_ok=True)
async def _get_llm_model_func(self):
"""LLM模型函数"""
async def llm_model_func(
prompt,
system_prompt=None,
history_messages=[],
keyword_extraction=False,
**kwargs
) -> str:
return await openai_complete_if_cache(
model=os.getenv("DASHSCOPE_MODEL", "qwen-max"),
prompt=prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("DASHSCOPE_API_BASE", "https://dashscope.aliyuncs.com/compatible-mode/v1"),
**kwargs
)
return llm_model_func
async def _get_embedding_func(self):
"""嵌入模型函数"""
async def embedding_func(texts: List[str]) -> np.ndarray:
return await openai_embed(
texts,
model=os.getenv("DASHSCOPE_EMBEDDING_MODEL", "text-embedding-v4"),
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("DASHSCOPE_API_BASE", "https://dashscope.aliyuncs.com/compatible-mode/v1")
)
return embedding_func
async def initialize(self) -> None:
"""初始化LightRAG实例"""
if self.rag is not None:
return
# 获取模型函数
llm_model_func = await self._get_llm_model_func()
embedding_func = await self._get_embedding_func()
# 存储配置 - 统一使用字符串方式,让LightRAG自动处理
# 图存储配置
graph_storage = os.getenv("LIGHTRAG_GRAPH_STORAGE", "Neo4JStorage")
# KV存储配置
kv_storage = os.getenv("LIGHTRAG_KV_STORAGE", "PGKVStorage")
# 文档状态存储配置
doc_status_storage = os.getenv("LIGHTRAG_DOC_STATUS_STORAGE", "PGDocStatusStorage")
# 向量存储配置
vector_storage = os.getenv("LIGHTRAG_VECTOR_STORAGE", "MilvusVectorDBStorage")
# 创建LightRAG实例
self.rag = LightRAG(
working_dir=self.working_dir,
embedding_func=EmbeddingFunc(
func=embedding_func,
embedding_dim=int(os.getenv("EMBEDDING_DIM", 1024))
),
llm_model_func=llm_model_func,
workspace=self.workspace,
graph_storage=graph_storage,
kv_storage=kv_storage,
doc_status_storage=doc_status_storage,
vector_storage=vector_storage
)
# 初始化存储
await self.rag.initialize_storages()
await initialize_pipeline_status()
async def insert_text(self, text: str) -> None:
"""插入文本到LightRAG
Args:
text: 要插入的文本内容
"""
if self.rag is None:
await self.initialize()
await self.rag.ainsert(text)
async def insert_texts(self, texts: List[str]) -> None:
"""批量插入文本
Args:
texts: 文本列表
"""
for text in texts:
await self.insert_text(text)
async def query(
self,
query: str,
mode: str = "hybrid",
**kwargs
) -> str:
"""执行查询
Args:
query: 查询文本
mode: 查询模式 ("naive", "local", "global", "hybrid")
**kwargs: 其他查询参数
Returns:
查询结果
"""
if self.rag is None:
await self.initialize()
return await self.rag.aquery(
query,
param=QueryParam(mode=mode, **kwargs)
)
|
参考资料
通过实际案例拆解Light
RAG,构建可视化知识图谱,解析Graph
RAG的运行原理和关键概念(一)_哔哩哔哩_bilibili
AI知识图谱
GraphRAG 是怎么回事?_哔哩哔哩_bilibili
LightRAG/README-zh.md
在主 ·香港科技大学/LightRAG — LightRAG/README-zh.md at main ·
HKUDS/LightRAG