数据挖掘作业
数据的规范化
- Min-Max 归一化(Normalization)
1 | from sklearn.preprocessing import MinMaxScaler |
- 结果范围:[0, 1](或可指定其他范围)
- 保留原始分布形状
- 对异常值敏感(因为依赖最大/最小值)
- Z-score 标准化(Standardization)
1 | from sklearn.preprocessing import StandardScaler |
- 结果:均值 ≈ 0,标准差 ≈ 1
- 不保证固定范围(可能有 -3 到 +3 甚至更大)
- 对异常值相对稳健
RobustScaler (鲁棒标准化)与Z-score 标准化(Standardization)对比
StandardScaler (Z-score标准化) 1
2
3
4
5
6
7
8
9公式: (x - 均值) / 标准差
问题: 均值和标准差都会被异常值严重影响!
例如:
正常值: [100, 150, 200, 180, 220] → 均值 = 170
加入异常值: [100, 150, 200, 180, 220, 6445] → 均值 = 1216 ❌
结果: 所有正常值都变成负数,异常值主导了整个标准化过程
1 | 公式: (x - 中位数) / IQR |
Apriori算法
Apriori 算法 是一种用于 频繁项集挖掘(Frequent Itemset Mining) 和 关联规则学习(Association Rule Learning) 的经典算法。
Apriori 基于一个非常重要的性质,叫 先验性质(Apriori Property):
如果一个项集是频繁的,那么它的所有子集也一定是频繁的。 反过来:如果一个项集是非频繁的,那么它的所有超集也一定是非频繁的。
这个性质可以用来 剪枝(prune),避免穷举所有可能的组合。
Apriori 的 候选生成规则:
当且仅当它们的前 (k-1) 个项相同,两个频繁 k项集才可以连接生成 (k+1)项集。
剪枝规则只有一句话:
对候选 k-项集 c,只要存在任何一个 (k−1)-子集 不在 Lₖₖ₋₁ 里, 就把 c 整集扔掉,不再给它计数。
为什么这样做合法?
基于 Apriori 向下封闭性(频繁项集的所有子集必频繁)。 若 c 哪怕只有一个 (k−1)-子集是非频繁的,c 自己绝对不可能频繁, 所以没必要浪费一次数据库扫描去数它的支持度。
例子
1 | transactions = [ |
我们的目标是找出 频繁项集(比如哪些商品经常一起出现)。
步骤 1:设定最小支持度(min_support)
假设我们设 min_support = 2,意思是:至少出现在 2
个购物篮中才算“频繁”。
支持度(Support) = 包含该项集的交易数 / 总交易数
这里我们直接用“出现次数 ≥ 2”来简化。
步骤 2:生成 1-项集(单个商品)
统计每个商品出现次数:
| 项集 | 出现次数 |
|---|---|
| {‘牛奶’} | 4 |
| {‘面包’} | 4 |
| {‘黄油’} | 2 |
| {‘可乐’} | 2 |
全部 ≥2 → 都是频繁 1-项集。
步骤 3:生成 2-项集(两两组合)
从频繁 1-项集中两两组合(注意:只组合那些“所有子集都频繁”的):
可能的组合: - {‘牛奶’, ‘面包’} - {‘牛奶’, ‘黄油’} - {‘牛奶’, ‘可乐’} - {‘面包’, ‘黄油’} - {‘面包’, ‘可乐’} - {‘黄油’, ‘可乐’}
现在统计它们在交易中出现的次数:
| 项集 | 出现次数 |
|---|---|
| {‘牛奶’, ‘面包’} | 3 ✅ |
| {‘牛奶’, ‘黄油’} | 1 ❌ |
| {‘牛奶’, ‘可乐’} | 2 ✅ |
| {‘面包’, ‘黄油’} | 2 ✅ |
| {‘面包’, ‘可乐’} | 1 ❌ |
| {‘黄油’, ‘可乐’} | 0 ❌ |
保留 ≥2 的 → 频繁 2-项集: - {‘牛奶’, ‘面包’} - {‘牛奶’, ‘可乐’} - {‘面包’, ‘黄油’}
步骤 4:生成 3-项集
从频繁 2-项集中尝试组合。
比如:{‘牛奶’,‘面包’} 和 {‘牛奶’,‘可乐’} → 可以组合成
{‘牛奶’,‘面包’,‘可乐’}
但必须检查它的所有 2-项子集是否都在频繁 2-项集中:
- 子集:{‘牛奶’,‘面包’} ✅
- 子集:{‘牛奶’,‘可乐’} ✅
- 子集:{‘面包’,‘可乐’} ❌(之前被剪掉了!)
→ 所以 {‘牛奶’,‘面包’,‘可乐’} 不合法,不能生成。
再试:{‘牛奶’,‘面包’} + {‘面包’,‘黄油’} →
{‘牛奶’,‘面包’,‘黄油’}
检查子集: - {‘牛奶’,‘面包’} ✅ - {‘牛奶’,‘黄油’} ❌(之前只有1次) -
{‘面包’,‘黄油’} ✅
→ 有一个子集不频繁 → 整个 3-项集被剪枝!
结论:没有频繁 3-项集。
算法结束。
FP-growth
FP-growth(Frequent Pattern Growth)算法,它是一种用于频繁项集挖掘的高效算法
- Apriori 算法:通过逐层生成候选项集(先1项,再2项…),每次都要扫描整个数据库,效率低。
- FP-growth:不生成候选项集,而是构建一种压缩数据结构——FP树(Frequent Pattern Tree),只需扫描数据库 2 次,效率更高!
FP-growth 的核心思想(分两步)
第一步:构建 FP 树(FP-Tree)
- 第一次扫描:统计每个单项的支持度,过滤掉低于 min_support 的项。
- 对每条事务:
- 只保留频繁项
- 按支持度从高到低排序
- 第二次扫描:将排序后的事务插入 FP 树。
第二步:从 FP 树中挖掘频繁项集
- 从支持度最低的频繁项开始(称为“后缀模式”)
- 对每个项,找出它的条件模式基(Conditional Pattern Base)
- 构建条件 FP 树(Conditional FP-Tree)
- 递归挖掘,直到树为空
模型评价指标
课后第一,二次作业
考虑表1中的候选3-项集,假设hash函数为h(x)=x mod 4,叶节点最大尺寸为2,构造hash树。
表1. 候选3-项集
| 编号 | 项集 |
|---|---|
| 1 | {1, 4, 5} |
| 2 | {1, 5, 9} |
| 3 | {3, 5, 6} |
| 4 | {1, 2, 4} |
| 5 | {1, 3, 6} |
| 6 | {3, 5, 7} |
| 7 | {4, 5, 7} |
| 8 | {2, 3, 4} |
| 9 | {6, 8, 9} |
| 10 | {1, 2, 5} |
| 11 | {5, 6, 7} |
| 12 | {3, 6, 7} |
| 13 | {4, 5, 8} |
| 14 | {3, 4, 5} |
| 15 | {3, 6, 8} |
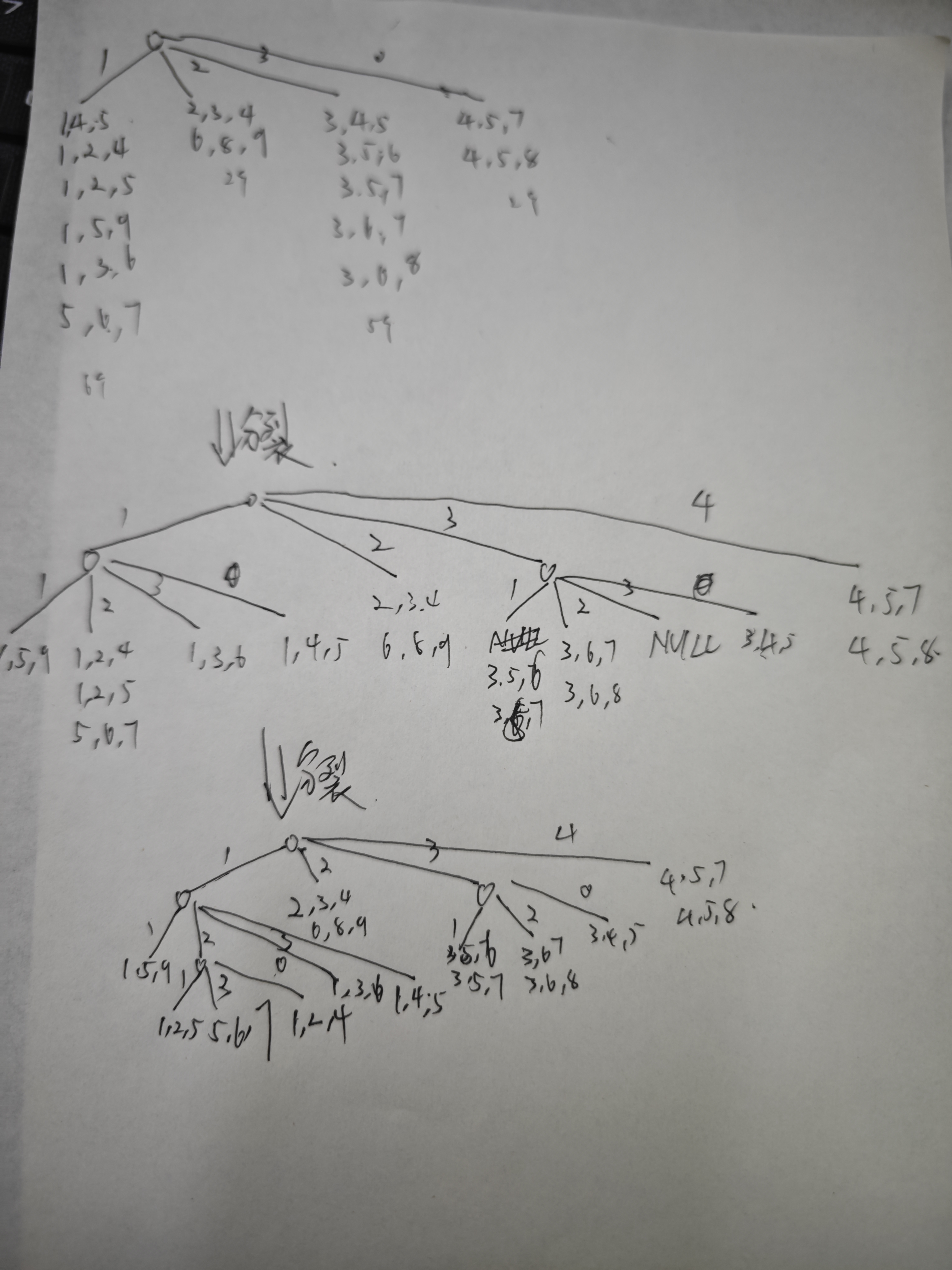
事务集如表2所示,最小支持度阈值是30%。
根据表2的事务集,在格结构上对每个结点添加所有符合条件的字母标记:
N:如果该项集被Apriori算法认为不是候选项集。(一个项集不是候选项集有两种可能的原因,一个是它们没有在候选项集产生步骤产生,另一个是它虽然在候选项集产生步骤产生,但是在剪枝步骤被丢掉)
I:如果计算支持度计数后,该候选项集被认为是非频繁的。
表2. 事务集:
| TID | 项集 |
|---|---|
| 1 | {a, b, d, e} |
| 2 | {b, c, d} |
| 3 | {a, b, d, e} |
| 4 | {a, c, d, e} |
| 5 | {b, c, d, e} |
| 6 | {b, d, e} |
| 7 | {c, d} |
| 8 | {a, b, c} |
| 9 | {a, d, e} |
| 10 | {b, d} |
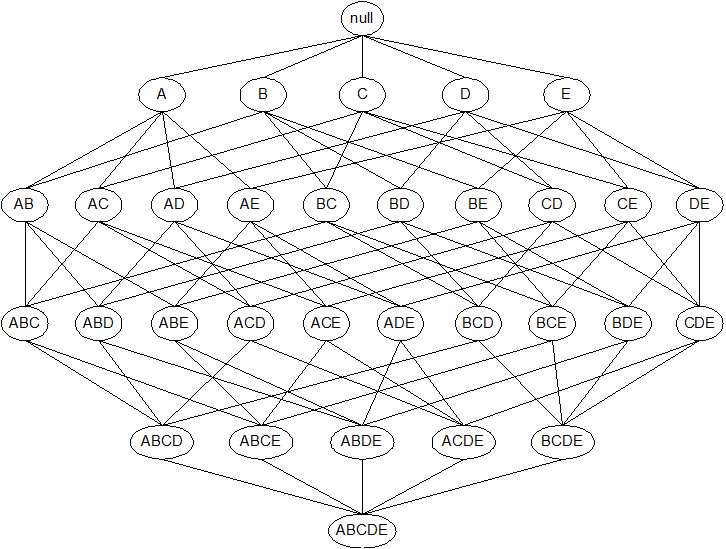

判断极大频繁项集(M)
极大频繁项集:是频繁的,且没有频繁的真超集。
定义:极大频繁项集(Maximal Frequent Itemset)是一个频繁项集,其所有超集都不是频繁的。
检查每个频繁项集:
- ade:超集有 abde, acde, adde(无效), bcde 等,但所有 4-项集都不频繁 → 所以 ade 是极大
- bde:同理,超集如 abde, bcde 都不频繁 → bde 是极大
- 其他频繁项集(如 ad):有超集 ade(频繁)→ 所以 ad 不是极大
- ab:超集 abd(非频繁),abe(非频繁)→ 但 ab 本身频繁,但有没有频繁超集?没有 → 等等!极大要求:没有频繁的超集。abd 支持度=2(非频繁),abe=2(非频繁)→ 所以 ab 没有频繁超集 → 那 ab 是极大?
判断闭频繁项集(C)
闭项集:一个项集 X 是闭的,如果不存在超集 Y ⊃ X 使得 support(Y) = support(X)。
即:它的支持度严格大于所有超集的支持度(或者没有超集具有相同支持度)。
以单项集为例:
单项集:
- a (5):超集 ad(4), ae(4), ab(3), ade(4) → 所有支持度 <5 → 没有超集支持度=5 → a 是闭
- b (7):超集 bd(6), be(4), ab(3), bde(4) → 都 <7 → b 是闭
- c (5):超集 bc(3), cd(4) → 都 <5 → c 是闭
- d (9):超集 ad(4), bd(6), cd(4), de(6), ade(4), bde(4) → 都 <9 → d 是闭
- e (6):超集 ae(4), be(4), de(6) → 注意:de 支持度=6,等于 e
的支持度!
- e ⊂ de,且 support(e)=support(de)=6 → 所以 e 不是闭
课后第三次作业
假设最小支持度阈值为40%,基于以下事务集写出使用FP-growth挖掘频繁项集的过程。
表1. 事务集
| TID | 项集 |
|---|---|
| 1 | {a,b,d,e} |
| 2 | {b,c,d} |
| 3 | {a,b,d,e} |
| 4 | {a,c,d,e} |
| 5 | {b,c,d,e} |


条件 FP 树(Conditional FP-tree)是 FP-growth 算法在“递归”阶段用来压缩“条件模式基”的一棵小 FP 树。 它的构建过程与初始 FP 树几乎一样,只是输入数据换成了“条件模式基”,并且再扫一遍、删低计数、排序、插入即可。下面用 “以 e 为后缀” 的例子把每一步都写出来,你就能完全复现。
一、准备:条件模式基(Conditional Pattern Base)
从主 FP 树里提取所有以 e 结尾的路径,并记录该路径的出现次数:
| 路径(删去 e 本身) | 该路径计数 |
|---|---|
| d b a | 2 |
| d a c | 1 |
| d b c | 1 |
这就是“e 的条件模式基”。
二、第一次扫描:算单项计数
把上面 3 条记录拆成单项累加:
- d: 2+1+1 = 4
- b: 2+0+1 = 3
- a: 2+1+0 = 3
- c: 0+1+1 = 2
最小支持度计数仍是 2,因此全部保留(若某项 <2 则直接丢弃)。
三、第二次扫描:排序 + 插入
- 排序规则:按全局频繁 1-项集的降序排(即 d≻b≻a≻c≻e)。 因此每条记录内部重新排序:
| 原路径 | 排序后路径 | 计数 |
|---|---|---|
| d b a | d b a | 2 |
| d a c | d a c | 1 |
| d b c | d b c | 1 |
- 逐条插入,构建“e 的条件 FP 树”:
- 插入
d b a(计数 2) 根 → d(2) → b(2) → a(2) - 插入
d a c(计数 1) 根 → d(3) → a(1) → c(1) - 插入
d b c(计数 1) 根 → d(4) → b(3) → c(1)
最终得到的条件 FP 树文字表示:
1 | null |