深度学习大作业
MMGraphRAG
流程说明:
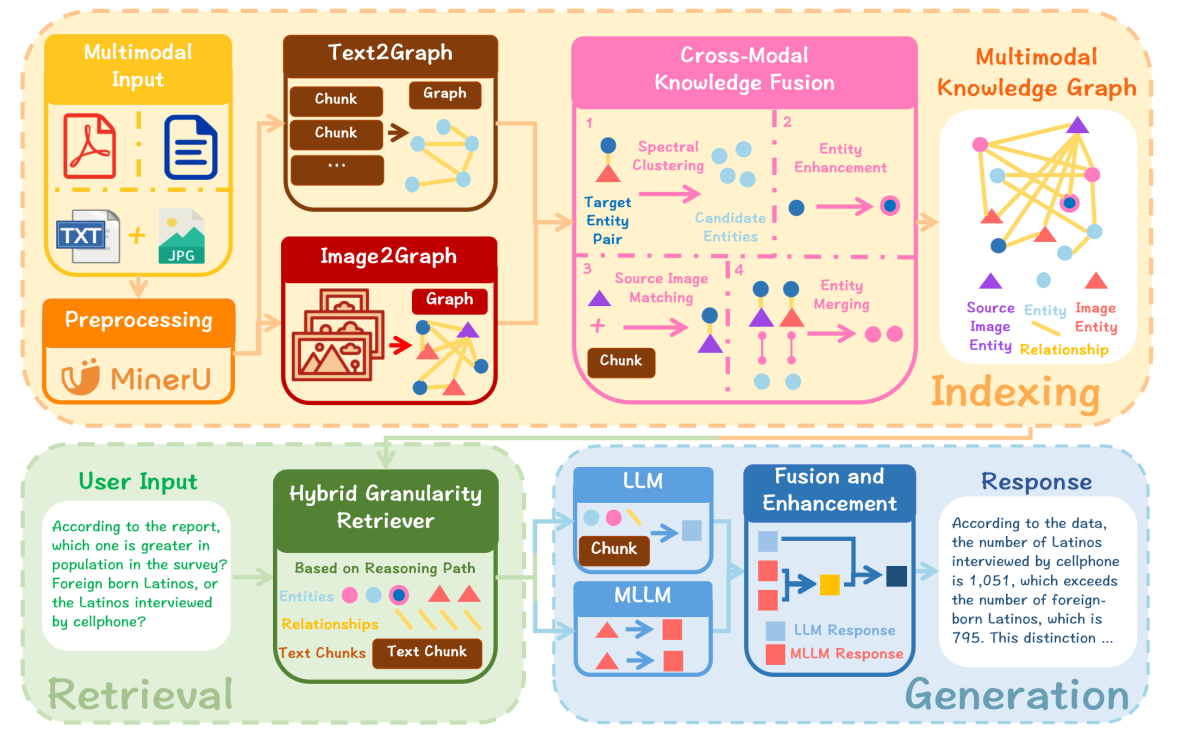
索引阶段 (Indexing)
◦ 目标: 将原始的多模态数据(文本和图像)转化为结构化的多模态知识图谱(MMKG)。
◦ Text2Graph: 对文本输入进行分块并提取实体,构建文本知识图谱 (Text-based KG)。
◦ Image2Graph: 图像通过场景图 (scene graphs) 精炼视觉内容。这包括使用 YOLOv8 进行语义分割、使用多模态大语言模型(MLLM)生成特征块描述、提取实体和关系(包括显式和隐式关系),并构建描述整个图像的全局实体。从而构建图像知识图谱 (Image-based KG)。
◦ 跨模态知识融合 (Cross-Modal Knowledge Fusion): 这是核心步骤,通过跨模态实体链接 (CMEL) 将文本 KG 和图像 KG 融合。
▪ 论文采用了基于谱聚类 (Spectral Clustering) 的优化策略来高效地生成候选实体对,该方法结合了实体间的语义和结构信息,从而增强了 CMEL 任务的准确性。
▪ 融合步骤还包括:对未对齐的图像实体进行描述增强,以及对全局图像实体进行对齐。
◦ 输出: 多模态知识图谱 (MMKG)。该框架采用基于节点的 MMKG (N-MMKG) 范式,将图像视为独立的节点,以保留更丰富的语义信息和可扩展性。
检索阶段 (Retrieval)
◦ 目标: 根据用户查询,在 MMKG 中提取相关知识线索。
◦ 混合粒度检索 (Hybrid Granularity Retriever): 检索模块沿着 MMKG 中的多模态推理路径,提取相关的实体、关系和上下文信息。
生成阶段 (Generation)
◦ 目标: 整合检索到的多模态线索,生成最终答案。
◦ 混合生成策略 (Hybrid Generation Strategy):
▪ 首先,大型语言模型 (LLM) 生成初步的文本响应。
▪ 随后,多模态大语言模型 (MLLM) 基于视觉和文本信息生成多个多模态响应。
▪ 最后,LLM 将这些响应整合并增强,输出一个统一且连贯的最终答案。
概念解析
场景图(Scene Graphs)
场景图是 MMGraphRAG 框架在索引阶段用于处理视觉信息的核心工具,d。
• 定义和作用: 场景图用于精炼视觉内容,将图像信息转化为实体和关系。通过构建场景图,MMGraphRAG 能够将原始视觉输入转换为结构化的图像知识图谱(Image-based KG),。
• 结构和信息捕获: 传统的场景图方法通常会忽略细粒度的语义细节和物体之间隐藏的信息,导致在下游推理任务中产生偏差。相比之下,MMGraphRAG 采用基于多模态大语言模型(MLLM)的方法来生成场景图。这种方法能够:
◦ 通过语义分割和 MLLM 的推理能力提取实体并推断出显式关系(例如:“女孩”——“拿着相机”——“相机”)和隐式关系(例如:“男孩”——“男孩和女孩看起来很亲密,可能是朋友或情侣”——“女孩”),。
◦ 为视觉实体提供更丰富的语义描述,例如将基本的标签“男孩”细化为更详细的表达,如“眼睛疲惫的大学生”。
• 构建过程: 在 MMGraphRAG 的 Img2Graph
模块中,场景图的构建流程包括图像语义分割、为每个特征块生成文本描述、提取实体和关系,以及构建描述整个图像的全局实体,。
跨模态实体链接(Cross-Modal Entity Linking, CMEL)
CMEL 是实现跨模态融合和构建统一 MMKG 的关键组成部分。
• 定义: CMEL 的目标是对齐从图像和文本中提取的实体,即识别指代同一现实世界概念的图像实体和文本实体对,。
• 在 MMGraphRAG 中的作用: 它是跨模态融合模块的第一步,也是最关键的一步。它负责在文本知识图谱(Text-based KG)和图像知识图谱(Image-based KG)之间建立连接。
• 与传统方法的区别:
◦ 传统实体链接(EL):仅将文本实体与知识库中的对应条目关联,忽略非文本信息。
◦ 多模态实体链接(MEL):将视觉信息作为辅助属性来增强实体与知识库条目之间的对齐,但无法建立超出这些辅助关联的跨模态关系,。
◦ CMEL:更进一步,它将视觉内容视为独立的实体,并将这些视觉实体与其文本对应物对齐,从而构建 MMKG 并促进显式的跨模态推理。
基于谱聚类(Spectral Clustering-Based)的方法
基于谱聚类的方法是 MMGraphRAG 针对 CMEL 任务中候选实体生成这一挑战提出的优化策略,。
• 目标: 在 CMEL 任务中,由于文本实体数量通常大于视觉实体,需要高效且鲁棒地为每个视觉实体生成一组候选文本实体,。
• 优势: 现有的聚类方法(如 KMeans、DBSCAN)依赖语义相似性,但忽略图结构;而图聚类方法(如 PageRank、Leiden)关注结构关系,但在稀疏图上表现不佳。基于谱聚类的方法解决了这两个方面的问题,它同时捕获实体间的语义信息和结构信息,。
• 具体实现:
◦ 该方法通过重新设计加权邻接矩阵 A 和度矩阵 D 来实现语义和结构的整合。
◦ 邻接矩阵 A 的构建同时反映了节点间的余弦相似性(语义信息)和它们之间关系的重要性(结构信息),其中关系的重要性由 LLM 评估。
◦ 度矩阵 D 的对角线值表示节点与其所有其他节点之间的总加权相似度。
◦ 随后,遵循标准的谱聚类步骤,构建拉普拉斯矩阵并进行特征分解,然后利用 DBSCAN 在特征向量空间(矩阵 Q 的行空间)上进行聚类,从而获得簇划分,。
• 效果: 实验结果显示,该方法在 CMEL 任务上的表现显著优于其他聚类和嵌入方法,将微观准确率提高了约 15%,宏观准确率提高了约 30%。
混合粒度检索(Hybrid Granularity Retrieval)
混合粒度检索是 MMGraphRAG 检索阶段的核心功能,。
• 定义: 在接收到用户查询后,检索模块在构建好的多模态知识图谱(MMKG)内部执行检索。
• 检索内容: 这种检索方式会提取不同粒度的相关信息,包括实体(Entities)、关系(Relationships) 上下文信息/文本块(Contextual Information/Text Chunks),。
• 机制: 检索是沿着 MMKG 内的多模态推理路径进行的,。由于 MMKG 将图像建模为独立的节点,并明确地链接了视觉和文本实体,这种结构化的检索(基于推理路径)能够比传统的基于嵌入相似度的检索(如 NaiveRAG)更精确地检索出与问题相关的视觉内容,并支持复杂的跨模态推理,,。检索结果随后用于指导生成过程,。
核心贡献
论文的三个主要核心贡献如下:
提出首个基于知识图谱的多模态 RAG 框架 (MMGraphRAG)
MMGraphRAG 是第一个基于知识图谱(KG)的多模态 RAG 框架。它旨在实现深度跨模态融合和推理,其设计具有强大的可扩展性和适应性。
A. 创新性的索引阶段(构建 MMKG)
MMGraphRAG 的核心在于其索引阶段,它将原始的多模态数据(文本和图像)转化为统一的多模态知识图谱 (MMKG)。
• 视觉内容精炼: 图像信息首先通过场景图(Scene Graphs) 显式和隐式关系,从而生成高精度和细粒度的场景图,将原始视觉输入转化为图像知识图谱。
• MMKG 范式: 论文采用了基于节点的 MMKG(Node-based MMKG, N-MMKG)范式。在这种范式中,图像被视为独立的节点,而非仅仅是文本实体的属性(Attribute-MMKG, A-MMKG)。这种设计避免了将视觉数据存储为属性时带来的信息损失,保留了更丰富的语义信息,并显着增强了跨模态推理能力和图的灵活性与可扩展性。
B. 结构化检索与生成
• 检索: 检索模块在 MMKG 内部沿着多模态推理路径执行混合粒度检索,从而提取相关的实体、关系和上下文信息,以指导生成过程。
• 混合生成策略: 生成阶段采用混合策略,首先由 LLM 生成初步的文本响应,然后由 MLLM 根据视觉和文本信息生成多模态响应。最后,LLM 将两者整合为一个统一且连贯的最终答案。这种方法有效缓解了当前 MLLM 在推理上的限制,确保了高质量、上下文适当的响应。
跨模态实体链接(CMEL)的创新方法和基准数据集
为解决构建 MMKG 中跨模态实体对齐的关键挑战,论文在 CMEL 任务上做出了重要贡献。
A. 提出基于谱聚类的 CMEL 优化策略
• 挑战: 准确地为每个视觉实体从文本实体池中生成一组候选实体对,是一个高效且鲁棒性的挑战。
• 解决方案: 论文设计了基于谱聚类的优化策略,用于高效生成候选实体。这种方法通过重新设计邻接矩阵 A 和度矩阵 D,同时捕获实体间的语义信息和结构信息。这极大地增强了 CMEL 任务的准确性,实验结果表明其在微观准确率上提升了约 15%,在宏观准确率上提升了约 30%,显著优于其他聚类和嵌入方法。
B. 构建并发布 CMEL 数据集
• 目的: 为了解决该领域缺乏统一基准评估的问题。
• 内容: 构建并发布了 CMEL 数据集,这是一个专门针对细粒度多实体对齐设计的新型基准,其在实体多样性和关系复杂性上都高于现有基准。该数据集包含来自新闻、学术和小说三个不同领域的文档,总共提供了 1,114 个对齐实例。
实验验证:实现最先进性能和高鲁棒性
MMGraphRAG 框架在多模态文档问答(DocQA)任务上进行了全面的评估,验证了其优势:
• 达到 SOTA 性能: MMGraphRAG 在 DocBench 和 MMLongBench 这两个多模态 DocQA 基准数据集上均取得了最先进的性能,显着优于现有的 RAG 基线方法(包括 LLM、MLLM、NaiveRAG 和 GraphRAG)。
• 跨域适应性: MMGraphRAG 表现出强大的跨领域适应性,尤其在具有高视觉结构复杂性的领域(如学术和金融)中,相比于纯文本的 RAG 方法有实质性提升。
• 处理“不可回答”问题的优势: 该框架在处理不可回答(Unanswerable, Una.)的问题时显示出明显的优势。由于其通过 MMKG 进行结构化推理,MMGraphRAG 能够更可靠地评估问题是否可答,从而减少生成误导性答案,增强了在真实世界场景中的鲁棒性。
• 提供可解释性: 该框架通过可追溯的推理路径来指导多模态推理
相关工作 (Related Work)
GraphRAG
多模态 GraphRAG 的尝试: 针对多模态数据,HM-RAG 提出了一个分层多智能体多模态 RAG 框架。该框架通过协调分解智能体、多源检索智能体和决策智能体,从结构化、非结构化和基于图的数据中动态地合成知识。
• HM-RAG 的不足: 尽管 HM-RAG 在多模态处理方面有所进步,但它仍然依赖于通过多模态大语言模型(MLLMs)将多模态内容转换为文本,未能充分捕获跨模态关系,从而导致逻辑链不完整
实体链接 (Entity Linking
• 传统实体链接(EL): 传统 EL 方法将文本实体与其在知识库中的对应条目关联起来,但忽略了非文本信息。
• 多模态实体链接(MEL): MEL 扩展了 EL,它将视觉信息作为辅助属性纳入进来,以增强实体与知识库条目之间的对齐。
• MEL 的局限性: 然而,MEL 并未在这些辅助关联之外建立跨模态关系,从而限制了真正的跨模态交互。
• 跨模态实体链接(CMEL): CMEL 更进一步,它将视觉内容视为实体,并将这些视觉实体与其文本对应物进行对齐,从而构建多模态知识图谱(MMKGs),并促进显式的跨模态推理。
• CMEL 研究现状与挑战: 当前,CMEL 领域的研究仍处于早期阶段,缺乏统一的理论框架和可靠的评估协议。例如,MATE 基准用于评估 CMEL 性能,但其合成的 3D 场景未能捕捉现实世界图像的复杂性和多样性。
MMGraphRAG 对 CMEL 的贡献:
• 为了弥补这一差距,MMGraphRAG 构建了一个具有更高现实世界复杂性的 CMEL 数据集。
• 同时,MMGraphRAG 提出了基于谱聚类的方法用于候选实体生成,旨在推动 CMEL 研究的进一步发展。
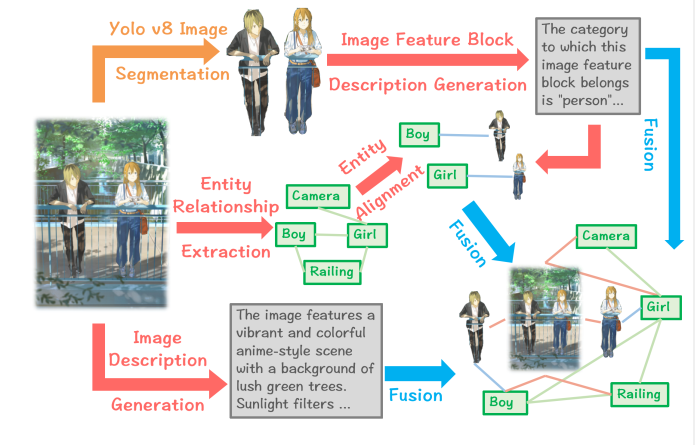
Image2Graph 模块
Img2Graph 模块通过一个五步流程将图像映射为知识图谱:
图像分割 (Image Segmentation):
◦ 这是第一步,使用 YOLOv8 等工具执行语义分割,将图像划分为具有独立语义意义的区域,这些区域被称为图像特征块(image feature blocks),。
◦ 分割的粒度会显著影响知识图谱中边缘描绘的精度。
图像特征块描述 (Image Feature Block Description):
◦ 接下来,使用 MLLM 为每个分割后的特征块生成文本描述。
◦ 这些描述不仅为图像模态构建了独立的实体,也为后续与文本模态的对齐提供了桥梁。模型会根据特征块的类别(物体、生物或人物)来生成详细描述,例如描述人物的性别、发型、衣着和姿势等,。
实体和关系提取 (Entity and Relation Extraction):
◦ 此步骤利用 MLLM 识别图像中的显式关系和隐式关系,并提取实体。
◦ 这些提取出的实体和关系为知识图谱的多模态扩展提供了结构化信息。
图像特征块与实体的对齐 (Alignment of Image Feature Blocks with Entities):
◦ 通过 MLLM 的识别和推理能力,将分割生成的特征块与它们对应的视觉实体进行对齐,。
◦ 例如,将“特征块 2”识别为“男孩”的图像,并在知识图谱中建立关系,这加强了模态间的关联。
全局实体构建 (Global Entity Construction):
◦ 最后,为整个图像构建一个全局实体,作为知识图谱中的全局节点。
◦ 该全局节点提供对图像整体信息的补充描述(例如:“在桥上相遇”),并通过与局部实体的连接,增强了知识图谱的完整性。
基于谱聚类的候选实体生成(Spectral Clustering-Based Candidate Generation)
CMEL 的目标是识别指代同一现实世界概念的图像实体和文本实体对。由于文本实体的数量通常大于视觉实体,CMEL 任务被分解为两个阶段:
- 为每个视觉实体生成一组候选文本实体,以及 (2) 从该集合中选择最佳对齐的文本实体。
阶段一:候选实体的生成
基于谱聚类的方法主要解决了第一个阶段,即候选实体的生成。
方法创新
现有的候选实体生成方法存在局限性:
- 基于距离的聚类方法(如 KMeans 和 DBSCAN)依赖语义相似性,但忽略了图结构。
- 基于图的聚类方法(如 PageRank 和 Leiden)捕获结构关系,但在稀疏图上效果不佳。
为了解决这些问题,MMGraphRAG 提出了一种专门为 CMEL 定制的谱聚类算法,该算法能够同时捕获实体之间的语义信息和结构信息。
核心机制
该方法重新设计了加权邻接矩阵 A 和 度矩阵 D,以融合语义和结构信息:
- 邻接矩阵 A 的构建: 矩阵 A
反映了节点之间的相似性以及它们之间关系的重要性。
- 其定义为 Apq = sim(vp, vq) ⋅ weight(rpq)。
- 其中,vp 是实体 ep 的嵌入向量,sim(⋅) 表示余弦相似度。
- weight(rpq) 是由大型语言模型(LLM)评估的关系 rpq 的重要性标量(如果两个实体之间没有关系,则权重设置为 1)。
- 度矩阵 D 的构建: D 是一个对角矩阵,对角线上的每个值 Dpp 表示节点 p 的总加权连接强度,即节点 p 与所有其他节点之间总的加权相似度。
随后,按照标准的谱聚类步骤,构建拉普拉斯矩阵并执行特征分解。利用最小的 m 个特征向量形成矩阵 Q。
候选实体生成
最后,在矩阵 Q 的行空间上使用 DBSCAN 进行聚类,得到簇划分 C1, C2, …, Cn。对于每个视觉实体 ek(Ii),算法会根据其嵌入向量 vk(Ii) 与簇成员之间的余弦相似度来选择最相关的簇。该簇中的所有实体构成了最终的候选实体集 C(ek(Ii))。
0. 场景设定
- 输入(视觉实体):一张红富士苹果的照片 eimg。
- 数据库(文本实体池):我们有 5 个文本实体(节点),它们都包含“Apple”或相关概念,导致传统方法容易混淆。
- T1: “Fresh Fuji Apple”(新鲜红富士苹果 - 水果)
- T2: “Red Delicious Apple”(红蛇果 - 水果)
- T3: “Apple iPhone 15”(苹果手机 - 科技)
- T4: “Apple MacBook Pro”(苹果电脑 - 科技)
- T5: “Banana and Fruit Salad”(香蕉水果沙拉 - 水果,但没有 Apple 这个词)
第一步:构建邻接矩阵 A (融合语义与 LLM)
我们需要计算每两个文本实体之间的“亲密度”。公式是 Apq = sim(vp, vq) ⋅ weight(rpq)。
- 语义相似度 (Sim)
假设我们计算出 T1 (“Fresh Fuji Apple”) 与其他词的向量相似度:
- 与 T2 (“Red Delicious”): 0.9 (都很像)
- 与 T3 (“Apple iPhone”): 0.7 (因为都有单词 “Apple”,向量空间里靠得较近,这是传统方法的陷阱)
- 与 T5 (“Banana…”): 0.5 (属于水果,但词不一样)
- LLM 权重 (Weight)
这里 MMGraphRAG 的核心创新来了。我们问 LLM:“‘新鲜红富士’和‘iPhone 15’在现实世界中关系紧密吗?”
- LLM 答:关系很弱,它们属于不同领域。 → Weight = 0.1
- LLM 答:‘新鲜红富士’和‘红蛇果’都是水果。 → Weight = 1.0
- 计算最终矩阵 A
让我们看看 T1 和 T3 的连接发生了什么变化:
- T1 vs T2 (水果 vs 水果): 0.9(Sim) × 1.0(LLM) = 0.9 (强连接)
- T1 vs T3 (水果 vs 科技): 0.7(Sim) × 0.1(LLM) = 0.07 (连接被切断!)
关键点:LLM 成功把“水果苹果”和“科技苹果”原本虚高的相似度打压下去了。
第二步:构建度矩阵 D
计算每个节点与其他所有节点的总连接强度。
- T1 (Fuji Apple): 连接 T2 (0.9) + 连接 T5 (0.4) + 连接 T3 (0.07)… ≈ 1.4
- T3 (iPhone): 连接 T4 (MacBook, 强连接 0.9) + 连接 T1 (0.07)… ≈ 1.0
这反映了节点在各自簇内的“人缘”。
第三步:谱变换与特征分解 (生成矩阵 Q)
构建拉普拉斯矩阵并分解后,我们将这 5 个文本实体映射到一个新的坐标系(比如 2D 平面)。
在这个新空间里,因为我们在第一步切断了“水果”和“科技”的强联系:
- T1, T2, T5 会紧紧聚在坐标系左下角。
- T3, T4 会紧紧聚在坐标系右上角。
- 它们之间的距离被拉得非常大,不再是原来混在一起的状态。
第四步:DBSCAN 聚类
在矩阵 Q 的坐标系上运行 DBSCAN。
- 输入:上述分散的坐标点。
- 过程:
- DBSCAN 发现 T1, T2, T5 密度很高,划分为 簇 C1 (水果簇)。
- DBSCAN 发现 T3, T4 密度很高,划分为 簇 C2 (科技簇)。
- 如果有一个 T6 “SpaceX Rocket”,它离谁都远,DBSCAN 可能会把它标记为噪声并扔掉(优于 K-Means 的点)。
第五步:候选实体生成 (匹配图片)
现在我们有了两个干净的候选池:
- C1: {Fuji Apple, Red Delicious, Banana Salad}
- C2: {iPhone 15, MacBook Pro}
最终匹配:
- 输入图片的向量 vimg (红富士照片)。
- 计算 vimg 与 C1 中成员的平均相似度 → 0.85 (很高)。
- 计算 vimg 与 C2 中成员的平均相似度 → 0.15 (很低)。
输出结果:
算法选择 簇 C1 作为最终的候选集合。
阶段二:从筛选出的候选集中确定最佳对齐结果
- 背景: 在 CMEL 任务中,第二阶段是从为每个视觉实体(visual entity)生成的候选实体集中选出最匹配的文本实体。这个过程通过基于 LLM 的推理来实现,因为 LLM 在复杂的对齐场景中展示了高准确性和适应性。
- 提示(Prompt)内容: 为了指导 LLM
完成实体对齐,向其提供的提示中包含以下关键信息:
- 视觉实体的名称和描述(the name and description of the visual entity)。
- 来自所选簇的候选实体的描述(descriptions of candidate entities from the selected cluster)。这些候选实体是通过前一步骤的基于谱聚类的候选生成方法(Spec)得到的。
- 一套固定的对齐示例(a fixed set of alignment examples),用于指导 LLM。
- 最终输出: LLM 基于上述提示内容进行推理判断后,其输出被采纳为最终的对齐结果(The output is adopted as the final alignment result)。
简而言之,这段文字是 MMGraphRAG 框架中跨模态知识融合模块(Cross-Modal Fusion Module)*执行 CMEL 任务时,利用 **LLM 进行最终实体对齐**的*输入信息(Prompt)构成和结果决定的说明。
CMEL (Cross-Modal Entity Linking) 数据集
您提供的这段文字是对 CMEL (Cross-Modal Entity Linking) 数据集 的详细介绍,该数据集是为了解决跨模态实体链接任务中缺乏评估基准而专门构建和发布的。
以下是对这段内容的详细解释:
1. CMEL 数据集的构成和领域多样性
CMEL 数据集是一个新颖的基准,专门用于评估复杂多模态场景下的细粒度跨实体对齐(cross-entity alignment)任务。
- 数据来源和领域: CMEL
数据集包含来自三个不同领域的文件,确保了广泛的领域多样性和实际适用性:
- 新闻(news)
- 学术(academia)
- 小说(novels)
- 每个样本的内容:
数据集中的每个样本都包含三个核心组件:
- (i) 基于文本块构建的文本知识图谱(text-based KG built from text chunks)。
- (ii) 源自每张图像的场景图的基于图像的知识图谱(image-based KG derived from per-image scene graphs)。
- (iii) 原始 PDF 格式文档(the original PDF-format document)。
- 对齐实例总数和分布: CMEL 数据集总共提供了
1,114 个对齐实例(alignment
instances)。这些实例按领域分布如下:
- 来自新闻文章的实例:87 个。
- 来自学术论文的实例:475 个。
- 来自小说的实例:552 个。
CMEL 数据集相比现有基准(如 MATE)具有更强的实体多样性和关系复杂性,并且支持通过半自动化流程进行扩展。
2. 评估指标(Evaluation Metrics)
为了全面评估跨模态实体链接(CMEL)的性能,该研究采用了两种不同的准确率指标:微观准确率(micro-accuracy)*和*宏观准确率(macro-accuracy)。
| 指标 | 计算方式 | 目的/反映的性能 |
|---|---|---|
| 微观准确率 (Micro-accuracy) | 按实体(per-entity)计算。即所有正确预测的实体数占总实体数的比例。 | 反映了整体预测的正确性,是全局性能的指标。 |
| 宏观准确率 (Macro-accuracy) | 按文档(per document)计算平均准确率。即每个文档的准确率的平均值。 | 旨在减轻评估偏差,这种偏差由不同文档中实体分布不平衡引起。更好地突出了不同方法在不同领域的性能。 |
实验设置与结果(Experimental Setup and Results)
“实验设置与结果”(Experimental Setup and Results)部分详细介绍了 MMGraphRAG 框架的评估方法,主要分为两部分:针对 CMEL 任务的评估,以及针对多模态文档问答(DocQA)任务的整体框架性能评估。
1. 跨模态实体链接(CMEL)实验设置与结果
CMEL 实验的目的是验证 MMGraphRAG 提出的基于谱聚类的候选实体生成方法(Spec)在复杂多模态场景下的有效性。
实验设置
数据集: 实验基于新构建和发布的 CMEL 数据集,该数据集专为细粒度多实体对齐设计,包含来自新闻、学术和小说三个不同领域的 1,114 个对齐实例。
评估指标: 采用微观准确率 (micro-accuracy) 和宏观准确率 (macro-accuracy)。
- 微观准确率按实体计算,反映了整体预测的正确性(全局性能)。
- 宏观准确率按文档计算平均准确率,旨在减轻实体分布不平衡导致的评估偏差,并更好地突出方法在不同领域中的性能。
对比方法: 实验涵盖三类方法,并与主流聚类算法进行了全面比较:
- 基于嵌入的方法 (Emb): 使用预训练嵌入模型(如 stella-en-1.5B-v5),通过计算余弦相似度来确定候选实体。
- 基于 LLM 的方法 (LLM): 利用 LLM(如 Qwen2.5-72B-Instruct)直接基于上下文理解能力生成候选实体集。
- 聚类基线: 包括 DBSCAN (DB)、KMeans (KM)、PageRank (PR) 和 Leiden (Lei)。
- 统一处理: 所有聚类方法和基线,其候选集内的最终实体对齐都是通过统一的基于 LLM 的推理完成的。
关键实验结果(CMEL)
- 聚类方法的优势: 总体而言,基于聚类的方法在 CMEL 任务中的表现显著优于基于嵌入和基于 LLM 的方法。
- Spec 性能最佳: MMGraphRAG 的基于谱聚类的 Spec 方法表现最佳。与其他聚类方法相比,Spec 将微观准确率提高了约 15%,宏观准确率提高了约 30%。
- 具体结果(Table 1 所示最佳配置): Spec 在整体微观/宏观准确率上达到了 65.5%/56.9%,明显优于排名第二的 Leiden (54.8%/44.7%)。
2. 多模态文档问答(DocQA)实验设置与结果
DocQA 实验用于评估 MMGraphRAG 框架在多模态信息集成、复杂推理和领域适应性方面的整体性能。
实验设置
- 评估任务: 选择 DocQA 作为主要评估任务,因为它能全面评估方法在处理长文档、集成多样格式以及跨领域适应性的能力。
- 基准数据集:
- DocBench: 包含 229 份 PDF 文档,涵盖学术、金融、政府、法律和新闻五个领域,问题类型包括纯文本 (Txt.)、多模态 (Mm.) 和不可回答 (Una.)。
- MMLongBench: 包含 135 份长 PDF 文档,证据格式包括文本 (Txt.)、图表/表格 (C.T.)、布局 (Lay.) 和图 (Fig.)。
- 评估基线:
- LLM: 通过 MLLM 将图像转换为文本后,输入 LLM(例如 Qwen2.5-72B-Instruct)。
- MLLM: 直接输入图像块和问题,评估其多模态推理能力(例如 InternVL2.5-38B-MPO)。
- NaiveRAG (NRAG): 基于嵌入相似度的文本块检索。
- GraphRAG (GRAG): 基于知识图谱的 RAG,使用局部模式查询。
关键实验结果(DocQA)
- MMGraphRAG (MMGR) 表现: MMGraphRAG 在 DocBench 和
MMLongBench 数据集上都显著优于所有现有的 RAG 基线方法。
- 在 DocBench 上的总体准确率达到 60.5%(对比 NRAG 的 43.6% 和 GRAG 的 39.6%)。
- 在 MMLongBench 上的总体准确率达到 39.6%,F1 分数达到 34.1%(对比 NRAG 的 22.3%/20.9% 和 GRAG 的 18.2%/19.3%)。
- 多模态融合优势: MMGraphRAG 在多模态问题上的准确率(DocBench 上 MMGR 88.7%)显著高于 GraphRAG(26.0%),证明了跨模态融合对于复杂推理至关重要。
- 跨领域适应性: 相比纯文本 RAG 方法,MMGraphRAG 在学术和金融等具有高视觉结构复杂性的领域获得了显著提升,表明其在专业领域中具有出色的适应性和泛化能力。
- 不可回答问题处理: MMGraphRAG 在处理不可回答问题(Una.)时表现出明显优势。这归因于其通过 CMEL 实现完整和细粒度的跨模态信息交互,并在 MMKG 上进行结构化推理,从而更可靠地评估问题是否可回答,减少了误导性答案的生成。
DocBench 数据集
DocBench 数据集是 MMGraphRAG 框架在多模态文档问答(DocQA)任务中用于评估其整体性能的主要基准之一
以下是关于 DocBench 数据集的详细介绍:
1. 目的与作用
DocBench 的主要作用是作为一个综合性基准,用于评估基于大型语言模型的文档阅读系统(LLM-based document reading systems)的性能,。
在 MMGraphRAG 的实验中,选择 DocQA(文档问答)作为主要评估任务,因为 DocBench 这类基准能够全面评估方法在以下方面的能力:
- 多模态信息集成。
- 复杂推理。
- 领域适应性。
- 处理长文档和集成多种格式的能力。
2. 数据构成与领域覆盖
DocBench 数据集包含来自公开在线资源的 229 份 PDF 文档。
它涵盖了五个不同的领域(Domains),确保了评估的广泛性:
- 学术 (academia/Aca.),。
- 金融 (finance/Fin.),。
- 政府 (government/Gov.),。
- 法律 (laws/Law.),。
- 新闻 (news/News),。
3. 问题类型 (Question Types)
DocBench 数据集的问题涵盖了多种类型,以测试模型的不同能力。它包括四种类型的问题,但在 MMGraphRAG 的实验中,排除了其中一类:
- Txt. (Pure Text Questions):纯文本问题。
- Mm. (Multimodal Questions):多模态问题,需要整合文本和视觉信息才能回答。
- Una. (Unanswerable Questions):不可回答问题,文档中缺乏答案证据。
- Metadata Questions:元数据问题。
注意: 在 MMGraphRAG 的实验中,由于信息被转换成了知识图谱(KG),因此元数据问题被排除在统计之外。
4. 评估机制
在实验中,DocBench 依靠大型语言模型(LLM)来确定答案的正确性。具体来说,在 MMGraphRAG 的实验中,Llama3.1-70B-Instruct 被用于评估 DocBench 上的答案正确性。
MMGraphRAG 在 DocBench 数据集上取得了显著的优势,其总体准确率达到了 60.5%,明显优于 NaiveRAG 和 GraphRAG 等现有 RAG 基线方法,,。特别是在处理多模态问题(Mm.)上,MMGraphRAG 的准确率高达 88.7%,。
DeepSeek-OCR
2D 光学映射(Optical 2D Mapping)
2D 光学映射(Optical 2D Mapping)*是 DeepSeek-OCR 提出的一种创新技术,旨在*利用视觉模态作为高效的压缩介质,将长文本上下文压缩为少量的视觉 Token。
以下是基于来源对 2D 光学映射的详细解析:
1. 核心概念与动机
大语言模型(LLM)在处理长文本时面临巨大的计算挑战,因为其计算量随序列长度呈平方级增长。2D 光学映射的思路在于:一张包含文档文字的图片(视觉模态)所代表的信息量,通常远超同等数量的数字文本 Token。因此,通过将文本“映射”为视觉表示,可以实现极高的光学压缩(Optical Compression)率。
2. 技术实现方案:DeepSeek-OCR
DeepSeek-OCR 是实现 2D 光学映射的实验性模型,它建立了一套完整的“压缩-解压”映射机制:
- 压缩(视觉编码器 - DeepEncoder): 这是核心引擎,它将高分辨率的输入图像(包含文字内容)通过 16 倍卷积压缩器进行处理。它能在保持极少视觉 Token 数量的同时,捕捉到图像中的关键文本信息。
- 解压(解码器 - MoE Decoder): 采用 DeepSeek3B-MoE 架构,学习如何从 DeepEncoder 产生的压缩隐空间 Token 中重新构建原始文本表示。
2D 光学映射就像是将一叠厚厚的文字资料(长文本)拍摄成一张高像素的照片(视觉 Token)。虽然照片本身只占用了极小的存储空间(Token 数量少),但只要有一个视力极佳的观察者(解码器),依然能从照片中清晰地还原出原本所有的文字内容。
压缩率(Compression Ratio)
根据提供的来源,在 DeepSeek-OCR 的研究语境下,压缩率(Compression Ratio)*是指*视觉-文本 Token 压缩率(Vision-Text Token Compression Ratio)。
以下是详细定义及其在技术中的重要性:
1. 核心定义与公式
压缩率用于衡量视觉 Token(Vision Tokens)作为压缩介质存储文本信息的效率。根据来源,其具体的计算方式为: 压缩率 = 原始文本的 Token 数量(Ground Truth Text Tokens) / 模型使用的视觉 Token 数量(Vision Tokens Used)。
例如,如果一段包含 1000 个文字 Token 的文本被压缩成 100 个视觉 Token,其压缩率就是 10×。
2. 性能表现与阈值
来源提供了 DeepSeek-OCR 在不同压缩率下的识别精度(Decoding Precision)指标:
- 10倍以内(< 10×): 解码精度可达 97% 左右,被视为近乎无损的压缩。
- 10-12倍(10-12×): 识别准确率仍能保持在 90% 左右。
- 20倍(20×): 这是该技术的极限测试点,此时准确率下降至约 60%。
3. 为什么需要这个指标?
- 解决计算瓶颈: 大语言模型(LLM)处理长文本时,计算量随序列长度呈平方级增长。通过高压缩率,可以用极少的 Token 代表极其丰富的信息,从而大幅降低计算开销。
- 探索记忆机制: 压缩率的调整可以模拟人类的遗忘机制。通过降低分辨率(即增加压缩率),可以让陈旧的信息变得模糊(消耗更少 Token),而让近期信息保持清晰(消耗更多 Token),从而实现理论上无限长的上下文处理。
- 衡量模型效率: 相比其他模型(如使用近 7000 个 Token 的 MinerU2.0),DeepSeek-OCR 追求在更少的视觉 Token 下(如少于 800 个)实现同等或更优的解析效果,这直接体现在更高的压缩率上。
压缩率就像是行李箱的分层收纳效率。原本需要 10 个大箱子才能装下的散装衣服(长文本 Token),通过某种神奇的折叠技术(2D 光学映射),现在只需要 1 个箱子(视觉 Token)就能装走。压缩率越高,意味着这个箱子折叠衣服的技术越厉害,装下的东西越多。