消息队列Message Queue
什么是消息队列
用一个最简单的生活类比:去餐厅吃饭。
- 没有 MQ (同步通信):你(客户端)点完菜,必须站在厨房门口盯着厨师(服务端)把菜做好,端走后才能去干别的事。如果厨师动作慢,你就被“卡”住了。
- 有 MQ (异步通信):你把点菜单交给服务员(MQ)。服务员把单子贴在后厨的墙上(队列)。你就可以回座位玩手机了。厨师做完一道菜,就从墙上撕下一个单子继续做。
技术上的定义: 消息队列是一个存放消息的容器。
- 生产者 (Producer):发送消息的程序(比如:点餐系统)。
- 消费者 (Consumer):从队列中读取并处理消息的程序(比如:后厨系统)。
- Broker:消息队列的服务端本身,负责接收、存储和转发消息。
消息队列(Message Queue, MQ) 是一种进程间通信(IPC)*或*服务间通信的中间件机制。它通过提供异步通信协议,允许发送者(Producer)和接收者(Consumer)在不同的时间、不同的进程甚至不同的网络环境下进行数据交换。
为什么要用 MQ?
MQ 主要是为了解决三个问题:
1. 解耦 (Decoupling)
- 场景:系统 A 下单后,需要通知系统 B(库存)、系统 C(积分)、系统 D(短信)。
- 问题:如果不用 MQ,A 必须调用 B、C、D 的接口。如果 D 挂了,A 也会报错;如果后面加个系统 E,A 又要改代码。
- MQ 方案:A 下单后,往 MQ 扔一条消息“有人下单了”,然后就不管了。B、C、D 自己去 MQ 里监听这条消息。哪怕 D 挂了,A 也不受影响。

2. 异步 (Asynchronous)
- 场景:用户注册,需要写数据库(50ms) + 发邮件(50ms) + 发短信(50ms)。总共耗时 150ms。
- MQ 方案:写完数据库(50ms)后,往 MQ 发个消息(5ms)就直接告诉用户“注册成功”。邮件和短信服务自己在后台慢慢消费消息去发送。响应时间从 150ms 降到了 55ms。
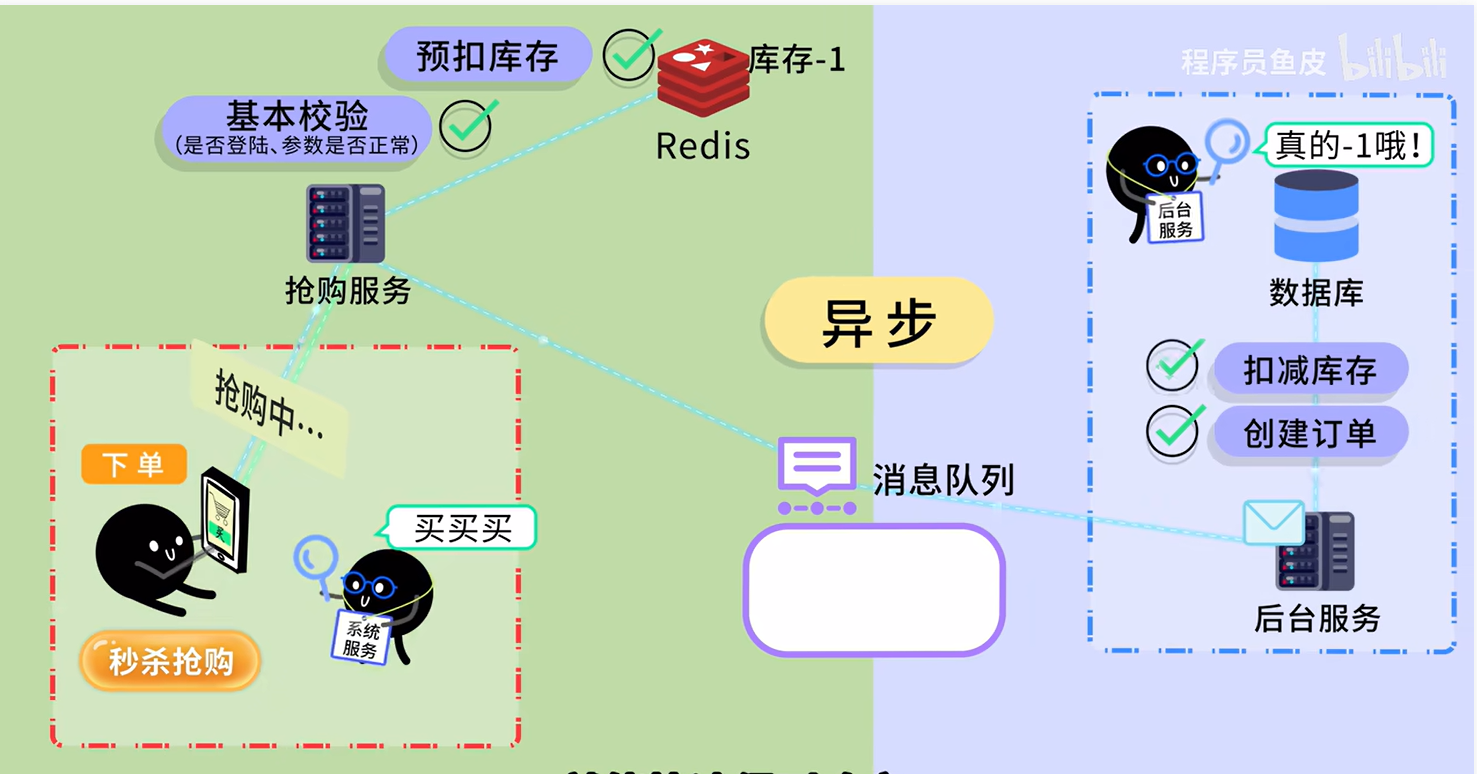
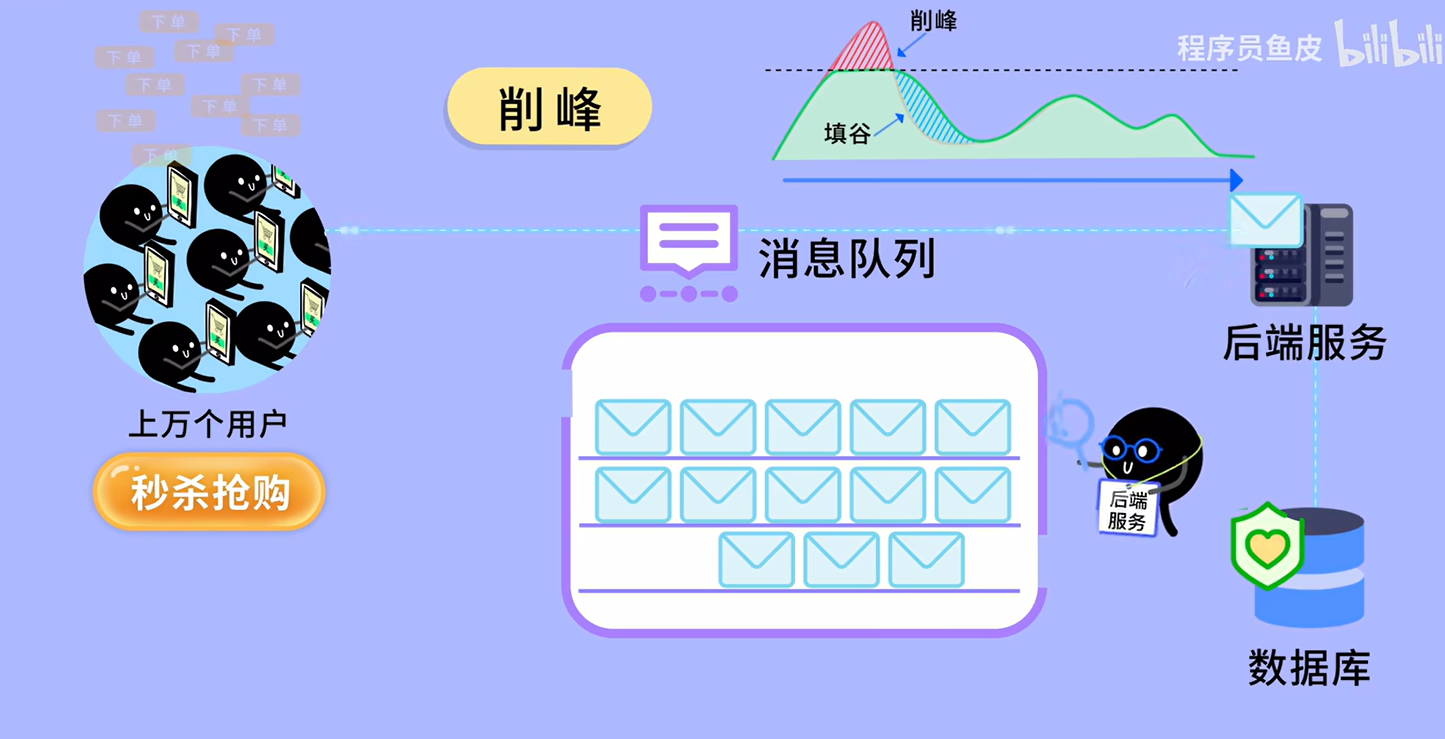
3. 削峰 (Peak Shaving / Load Leveling)
- 场景:秒杀活动,平时每秒 10 个请求,秒杀时每秒 5000 个请求。数据库只能抗 2000 个,直接崩了。
- MQ 方案:把 5000 个请求全部打入 MQ(MQ 的写入性能通常极高)。后台系统按照自己的能力(比如每秒处理 2000 个)慢慢从 MQ 里拉取处理。就像水库蓄水一样,保护下游系统不被冲垮。
市面上主流的 MQ 选型
| 特性 | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|
| 主要特点 | 稳定、功能全 | 金融级可靠、高吞吐 | 极高吞吐、大数据 |
| 开发语言 | Erlang | Java | Scala/Java |
| 单机吞吐量 | 万级 | 十万级 | 百万级 |
| 消息延迟 | 微秒级 (极快) | 毫秒级 | 毫秒级 |
| 适用场景 | 中小型公司,对实时性要求高,数据量没那么大。 | 阿里出品,适合复杂的业务系统(如电商交易),高可靠。 | 日志收集、大数据实时计算、用户行为追踪。 |
| 缺点 | Erlang 语言难维护,吞吐量相对低。 | 社区主要在国内。 | 某些配置下可能丢数据,不适合极其严苛的金融交易。 |
Exchange(交换器)
在消息队列(特别是基于 AMQP 协议 的实现,如 RabbitMQ)中,交换器 (Exchange) 是核心组件之一。
如果说 Queue(队列)是存储消息的“仓库”,那么 Exchange(交换器)就是负责分拣和投递的“路由器”。
在专业的 AMQP 架构中,生产者 (Producer) 绝不会直接把消息发送到队列中,而是发送给交换器。交换器根据既定的路由规则 (Routing Key),将消息分发到一个或多个队列中。
核心机制:Binding 与 Routing Key
理解交换器,必须先理解两个概念:
- Binding (绑定):这是连接 Exchange 和 Queue 的纽带。它告诉交换器:“如果你收到了消息,请把它按这条路径转给这个队列。”
- Routing Key (路由键):生产者发送消息时带的一个“标签”。交换器会拿着这个标签,去和 Binding 规则做匹配。
数据流向:
Producer –>
Message + RoutingKey–> Exchange –> (匹配逻辑) –> Queue –> Consumer
RabbitMQ 的工作模式
第一类:基础队列模式 (点对点)
这两种模式主要利用队列“存储转发”的特性,通常不需要显式配置复杂的 Exchange(交换机)。
1. 简单模式 (Simple / Hello World)
- 架构:
P(生产者) ->Queue(队列) ->C(消费者) - 机制:最原始的模式。一个生产者对应一个消费者。
- 场景:简单的“短信发送”任务。程序 A 产生内容,程序 B 发送,两者不需要同时在线。
2. 工作队列模式 (Work Queues)
- 架构:
P->Queue->C1,C2… - 机制:竞争消费。一个队列对应多个消费者,但一条消息只能被一个消费者抢到。
- 核心逻辑:
- 轮询 (Round-robin):默认情况下,RabbitMQ 会依次把消息分给每个消费者(你一条,我一条)。
- 公平分发 (Fair Dispatch):通过设置
prefetch=1,让“忙碌”的消费者不接新单,把消息给“空闲”的消费者(即:谁处理得快谁多干活)。
- 场景:集群削峰。比如大促期间的订单处理,启动 100 个订单处理服务(Worker)去消费同一个订单队列,加快处理速度。
第二类:高级发布订阅模式 (Publish/Subscribe)
这类模式引入了 Exchange (交换机) 的概念,实现了“一次发送,多处接收”。区别在于路由规则的不同。
3. 发布/订阅模式 (Publish/Subscribe - Fanout)
- 架构:
P->Exchange (Fanout)->Queue A,Queue B->C1,C2 - 机制:广播。生产者把消息发给交换机,交换机把它复制给所有绑定到它身上的队列。
- 特点:速度最快,因为它完全忽略 Routing Key,闭着眼转发。
- 场景:数据同步或日志广播。比如“修改密码”事件,既要发给“短信队列”通知用户,又要发给“审计队列”记录日志。
4. 路由模式 (Routing - Direct)
- 架构:
P->Exchange (Direct)->Queue A (error),Queue B (info) - 机制:精准匹配。发送消息时携带
Routing Key(比如 “error”),交换机只把消息投递给绑定了 “error” Key 的队列。 - 场景:日志分级存储。
- 消费者 A 只想接收
error级别的日志写磁盘(绑定 key=“error”)。 - 消费者 B 想接收所有级别的日志打印控制台(绑定 key=“info”, “warning”, “error”)
- 消费者 A 只想接收

5. 主题模式 (Topics - Topic)
- 架构:
P->Exchange (Topic)->Queue - 机制:通配符匹配。这是最灵活的模式。
#:匹配 0 个或多个单词。*:匹配 1 个单词。
- 例子:
- 发送 Key:
usa.news - 队列 A 绑定:
usa.#(接收美国的所有消息) - 队列 B 绑定:
#.news(接收全世界的新闻)
- 发送 Key:
- 场景:复杂业务路由。比如外卖系统,按区域(北京.海淀)、按品类(食品.奶茶)进行多维度的消息分发。

Quorum 队列
1. 为什么要发明 Quorum 队列?(历史背景)
在 Quorum 队列出现之前,RabbitMQ 想要实现“一台机器挂了数据不丢”,用的是 镜像队列 (Mirrored Queues)。
老镜像队列的致命痛点:
- 同步风暴:当一个新节点加入集群时,它需要从老节点把所有数据复制过来。这个过程会导致整个集群卡顿(Stop-the-world),甚至导致集群崩溃。
- 效率低下:它采用的是“链式复制”或者简单的广播,一条消息要在所有节点间转圈圈,性能随着节点数增加而剧烈下降。
- 即将被废弃:RabbitMQ 官方已经宣布,在未来的版本(4.0)中将彻底删除镜像队列。
所以,Quorum 队列就是为了“接班”而来的。
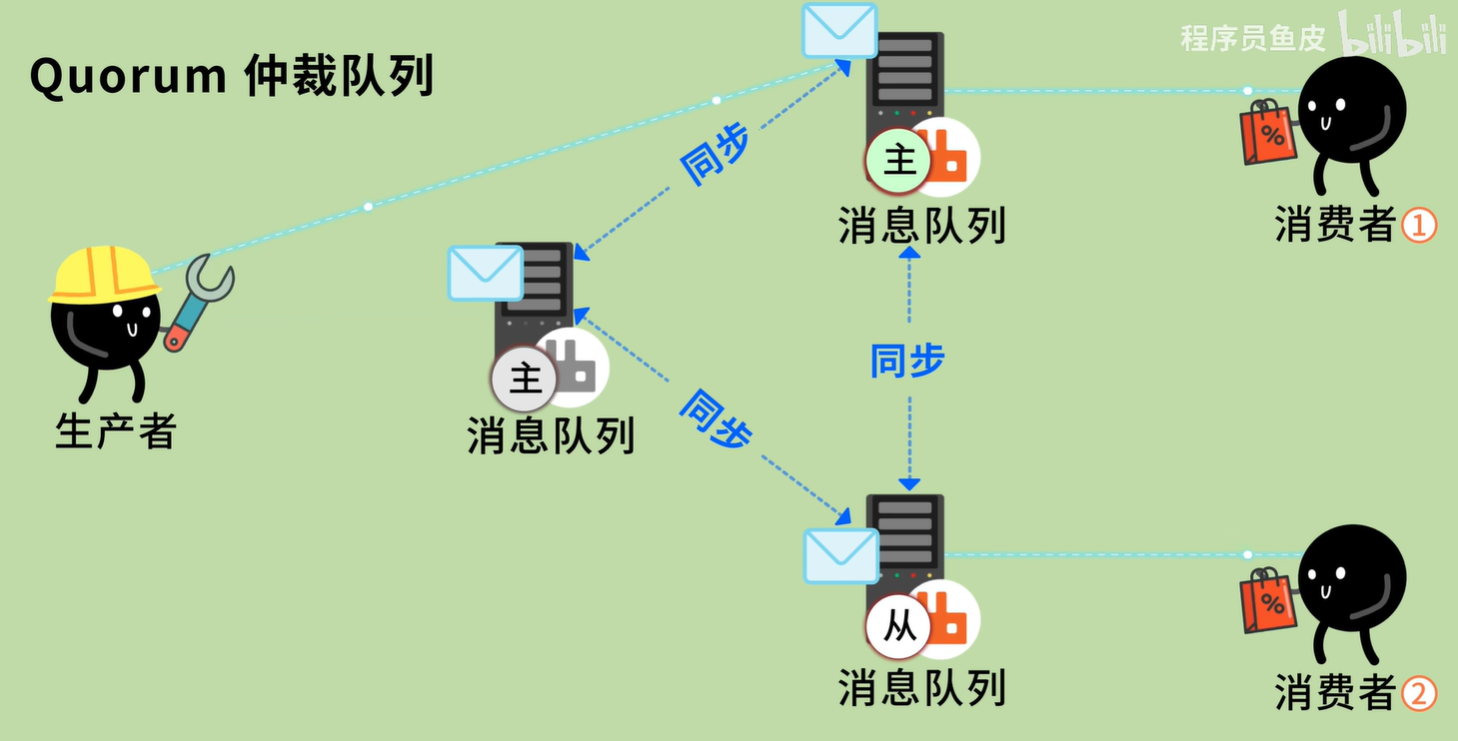
2. Quorum 队列的核心原理:Raft 算法
“Quorum”这个词的本意是“法定人数”(也就是多数派)。
它的核心逻辑不再是“所有人都必须收到消息”,而是“只要大多数人收到消息,这事儿就成了”。它基于著名的分布式一致性算法 Raft。
工作机制图解:
假设你的集群有 3 个节点(Node A, Node B, Node C)。
- Leader 选举:三个节点通过投票,选出 Node A 作为 Leader,B 和 C 是 Follower。
- 写消息:
- 生产者把消息发给 Leader (A)。
- A 把消息写入自己的日志,并同时发给 B 和 C。
- 关键点:只要 B 或者 C 其中有一个 回复“我收到了”(加上 A 自己,就是 2 票,满足 3 票中的多数派),A 就认为这条消息写入成功。
- A 返回 ACK 给生产者。
- 故障切换:
- 如果 Leader (A) 挂了。
- B 和 C 发现老大不在了,迅速发起新一轮投票。
- 因为 B 和 C 都是活着的(2 > 3/2),它们能立刻选出新的 Leader,继续工作。
常见问题
如果重启rabbitmq,出现消息丢失问题如何解决
核心原因是默认情况下 RabbitMQ 是将数据存储在内存中的。一旦进程关闭或服务器重启,内存数据就会被清空。
要解决这个问题,必须配置 “持久化” (Persistence)。
但这不仅仅是改一个配置那么简单。要保证消息绝对不丢,你需要同时满足 三个层面的持久化(缺一不可):
1. 交换器的持久化 (Exchange Durability)
如果你只持久化了队列和消息,但交换器没持久化。重启后,交换器没了,生产者发消息时找不到交换器,消息就会直接报错或丢弃。
如何设置:在声明交换器时,将
durable参数设为True。代码示例 (Python):
1
2
3
4
5
6import pika
# durable=True 是关键
channel.exchange_declare(exchange='my_exchange',
exchange_type='direct',
durable=True)
2. 队列的持久化 (Queue Durability)
如果队列不持久化,重启后队列元数据会消失,依附于该队列的消息(无论消息本身是否持久化)都会一起消失。
如何设置:在声明队列时,将
durable参数设为True。代码示例 (Python):
1
2# durable=True 告诉 RabbitMQ 重启后恢复该队列
channel.queue_declare(queue='my_queue', durable=True)
3. 消息的持久化 (Message Persistence)
这是最容易被遗忘的一步。即便队列还在,如果消息本身是“瞬态”的,重启后队列是空的。
如何设置:在发送消息(Publish)时,设置
delivery_mode = 2(1 是非持久化,2 是持久化)。代码示例 (Python):
1
2
3
4
5
6
7
8channel.basic_publish(
exchange='my_exchange',
routing_key='my_queue',
body='Hello World',
properties=pika.BasicProperties(
delivery_mode=2, # 关键点:2 代表消息持久化
)
)
进阶:这样就 100% 安全了吗?
不是的。 即便你做到了以上三点,依然存在两个极端情况会导致丢失:
- 漏洞 1:消息刚到内存,还没来得及刷盘 RabbitMQ
为了性能,不会每收到一条消息就立马写硬盘(fsync),而是先存缓存区。如果这时候断电了,缓存区里的几条消息就丢了。
- 解决方案:发布确认机制 (Publisher Confirms)。 生产者开启 Confirm 模式。只有当 RabbitMQ 明确告诉你“我已经把这条消息存入硬盘了”(Handle Ack),你才算发送成功。如果超时未收到 Ack,生产者需要重发。
- 漏洞 2:磁盘坏了 / 物理机报废
如果单台机器硬盘物理损坏,持久化也没用。
- 解决方案:镜像队列 (Mirrored Queues) 或 仲裁队列 (Quorum Queues)。 这是集群层面的高可用。将消息复制到 3 台不同的机器上。挂掉一台,另外两台还有数据。
如何解决同一个消息被消费多次的问题
这是一个非常经典且必须解决的分布式系统问题。在专业术语中,解决这个问题的方法叫做实现接口的“幂等性” (Idempotency)。
简单来说,幂等性意味着:无论我对同一个消息处理多少次,最终的结果都和处理一次是一样的。
在 RabbitMQ(以及大多数 MQ)的设计中,为了保证消息不丢,默认采用的是 “至少投递一次” (At-Least-Once) 策略。
- 场景还原:消费者把钱扣了,正准备告诉 MQ “我办完了(ACK)”,结果网线断了或进程崩了。
- 后果:MQ 没收到 ACK,以为你没办完,于是把消息重新发给另一个消费者。结果:扣了两次钱。
要解决这个问题,不能依赖 MQ,必须由消费者(Consumer)在业务逻辑层面来保证。以下是三种最主流的工程实现方案:
方案一:利用数据库的唯一约束 (最强硬方案)
这是最简单、最可靠的方法,适用于新增数据(Insert)的场景。
- 原理:利用数据库(MySQL/Oracle)的主键(Primary Key)或唯一索引(Unique Key)约束。
- 做法:
- 每条消息必须携带一个全局唯一的 ID(比如
message_id或者业务上的order_id)。 - 消费者尝试向数据库插入数据。
- 如果插入成功 -> 处理结束,发送 ACK。
- 如果插入失败(报
DuplicateKeyException) -> 说明已经处理过了,直接忽略,发送 ACK。
- 每条消息必须携带一个全局唯一的 ID(比如
方案二:利用 SQL 的条件更新 (状态机方案)
适用于更新数据(Update)的场景,比如更新订单状态。
原理:利用 SQL 的
WHERE条件作为乐观锁,防止回退。错误做法:
1
UPDATE orders SET status = 'PAID' WHERE id = 1001;
风险:如果你执行两次,它就更新两次,虽然状态看起来一样,但如果有触发器或日志,就会重复。
正确做法 (带前置条件):
1
2UPDATE orders SET status = 'PAID'
WHERE id = 1001 AND status = 'UNPAID'; -- 关键在这里- 第一次执行:找到 ID=1001 且状态是 UNPAID 的记录,更新成功,影响行数 = 1。
- 第二次执行:虽然 ID=1001 还在,但这时的状态已经是
PAID 了,不满足
status = 'UNPAID',所以影响行数 = 0。业务逻辑判断影响行数为 0,即视为重复消费,直接 ACK。
方案三:Redis 去重表 (最高性能方案)
如果你的业务不涉及数据库,或者并发量极高,可以用 Redis 做“去重记录表”。
做法:
- 消息到达,先拿着
message_id去 Redis 查一下:EXISTS message_id? - 如果有:说明处理过了,直接丢弃,ACK。
- 如果无:开始处理业务。
- 业务处理完,把
message_id写入 Redis(通常设置一个过期时间,比如 24 小时)。
注意:这里存在原子性问题(先查后写中间可能并发),通常使用
SETNX(Set if Not Exists) 命令或者 Lua 脚本来保证原子性。- 消息到达,先拿着
如何处理消息乱序的问题
在 RabbitMQ 中,单个队列由单个消费者消费时,是严格保证先进先出(FIFO)的。
但是,为了提升性能,我们通常会开启多个消费者(Competing Consumers Pattern)同时消费同一个队列,或者发生消息重试(Nack/Requeue)。这时候,顺序就乱了。
场景举例: 生产者依次发了三条关于“订单 A”的消息:
INSERT(创建订单)UPDATE(支付订单)DELETE(删除订单)如果有两个消费者 C1 和 C2。 C1 拿到了
INSERT,C2 拿到了UPDATE。 C2 的网速很快,先处理完UPDATE。结果数据库报错“找不到订单”,操作失败。然后 C1 才把INSERT做完。 结果:数据不一致,业务崩盘。
解决这个问题的核心思路是:我们不需要“全局有序”,只需要“局部有序”(即:保证同一个 ID 的消息是有序的即可,不同 ID 之间的顺序无所谓)。
对于 Python 开发者以及大多数分布式系统来说,解决消息乱序最稳健、最通用的方案就是:拆分 Queue + 一致性 Hash (Queue Sharding)。
核心方案:拆分 Queue + 一致性 Hash
这个方案的核心逻辑是:我们不需要“全局有序”,只需要保证“同一业务 ID 的消息有序”。
只要保证同一个订单(例如
Order_1001)的所有操作(下单、支付、发货)都严格进入同一个队列,并且被同一个消费者处理,那么顺序就绝对不会乱。
1. 架构设计图解
我们要把原来的“一个大队列”拆分成 N 个“小队列”。
- 原来的模型(会乱序):
Producer->Queue->Consumer A,Consumer B(并发抢单,顺序错乱) - 现在的模型(保证有序):
Producer->Exchange->Queue_1->Consumer A(只负责 Queue_1)Producer->Exchange->Queue_2->Consumer B(只负责 Queue_2)Producer->Exchange->Queue_3->Consumer C(只负责 Queue_3)
2. 具体实现步骤
这个方案分为三个关键环节:
第一步:生产者负责“路由分发”
在发送消息时,生产者必须根据业务 ID(如
order_id)决定这条消息发往哪个队列。通常使用 Hash
取模 算法。
- 逻辑:
index = hash(order_id) % N(N 是队列的总数量)。 - 例子:假设有 3 个队列。
Order_1001的 Hash 模 3 结果是 0 -> 发往 Queue_0Order_1002的 Hash 模 3 结果是 1 -> 发往 Queue_1Order_1001的后续状态(如支付)Hash 结果肯定还是 0 -> 依然发往 Queue_0
第二步:RabbitMQ 队列配置 你需要创建 N 个队列(如
order_sub_queue_0, order_sub_queue_1…)。
- 进阶技巧:RabbitMQ 有一个官方插件叫
rabbitmq_consistent_hash_exchange。你只需要把消息发给这个交换机,带上 routing_key(设为 order_id),交换机会自动帮你根据 Hash 值均匀分发到绑定的队列中,连生产者的代码都不用改太复杂。
第三步:消费者“独占”队列 (关键) 这是最重要的一点:每个小队列,同一时刻只能有一个消费者在监听。
- Consumer A 专门监听
Queue_0。 - Consumer B 专门监听
Queue_1。
因为 RabbitMQ 的单个队列是先进先出 (FIFO) 的,而 Consumer A
是单线程顺序处理 Queue_0 的,所以 Order_1001
的“下单”一定比“支付”先被处理。
如何处理消息处理失败的情况
在分布式系统中,消息处理失败是常态(比如数据库挂了、网络抖动、代码 bug)。
如果处理失败,绝不能简单地忽略,否则会导致数据丢失;也不能死板地无限重试,否则会死循环拖垮系统。
处理失败通常有三道防线,层层递进:
第一步:判断异常类型(是“病”还是“命”?)
当 try...except
捕获到异常时,不能盲目重试,先看是什么错:
- 致命错误(Fatal Error):
- 例如:
JsonDecodeError(格式不对)、KeyError(缺字段)、NullPointerException(空指针)。 - 决策:这种错误重试一万次也没用。跳过重试,直接进死信队列。
- 例如:
- 临时错误(Transient Error):
- 例如:
Timeout(连接超时)、Deadlock(数据库死锁)、503 Service Unavailable。 - 决策:这种病能治。进入重试流程。
- 例如:
第二步:带策略的重试(Retry)—— 关键缓冲
既然决定要救,也不能瞎救(比如立即原地无限重试,那是“毒药”)。我们需要“有节制、有延迟”的重试。
- 检查重试次数: 从消息 Header 中读取
retry_count。 - 逻辑:
- 如果 count < 3(假设最大重试3次):
count + 1。- 等待一会儿(Backoff):不要立即重试,而是把消息发到一个
“延迟队列”(或者用代码
sleep一会儿,但 Python 中不建议阻塞主线程,推荐用延迟插件rabbitmq_delayed_message_exchange)。 - 重新发布这条消息(Publish)。
- 对当前失败的这条消息进行
ACK(因为它已经生成了新的替身去排队了)。
- 如果 count >= 3:
- 说明救不活了,放弃治疗。
- 进入第三步。
- 如果 count < 3(假设最大重试3次):
第三步:死信队列(DLQ)—— 最终兜底
这是最后一道防线。当重试次数耗尽,或者遇到致命错误时,才轮到它出场。
- 操作:调用
basic_nack(delivery_tag, requeue=False)。 - 结果:
- RabbitMQ 会根据配置,自动把这条消息“踢”到死信交换机。
- 死信交换机把它路由到 死信队列。
- 后续:
- 开发/运维人员配置报警脚本,监听死信队列。
- 一旦有消息进来,发钉钉/邮件报警。
- 人工排查原因(比如发现是数据库挂了),修复后,手动把死信队列里的消息取出来再发回业务队列(或者写脚本批量重发)。
Kafka
消息队列Kafka是什么?架构是怎么样的?5分钟快速入门_哔哩哔哩_bilibili
1. 核心思维转变:从“队列”到“日志”
这是理解 Kafka 最重要的一步。
- RabbitMQ (队列模型):就像“收件箱”。你把信拿出来,信就没了(Delete)。它的目标是让消息越快被处理完越好,堆积消息是异常状态。
- Kafka
(日志模型):就像“船长的航海日志”。
- 消息是追加写入 (Append-only) 的。
- 消费者读消息,不会删除消息,只是在自己的笔记本上记一下:“我读到了第 100 行”。
- 这意味着:消息可以被多个不同的消费者重复读取,甚至可以“倒带”回去重读历史数据。
2. 为什么 Kafka 快得离谱?(架构设计)
Kafka 单机可以轻松抗住 每秒几十万甚至上百万 的写入,它是怎么做到的?
A. 顺序写磁盘 (Sequential Write)
RabbitMQ 尽量用内存,而 Kafka 直接写磁盘。 你可能会问:“写磁盘不是慢吗?” 随机写确实慢,但顺序写极快。Kafka 强制所有数据只能追加到文件末尾。在现代操作系统中,顺序写磁盘的速度(600MB/s+)甚至可以超过随机写内存的速度。
B. 零拷贝 (Zero-Copy)
还记得你之前感兴趣的底层原理吗?Kafka 是利用 OS sendfile
系统调用的教科书级案例。
- 传统方式:磁盘 -> 内核 Buffer -> 用户态 Buffer (Application) -> 内核 Socket Buffer -> 网卡。
- Kafka 方式:磁盘 -> 内核 Buffer ->
直接传给网卡。
- 数据完全不经过应用程序(Kafka JVM),CPU 也就不用瞎忙活。
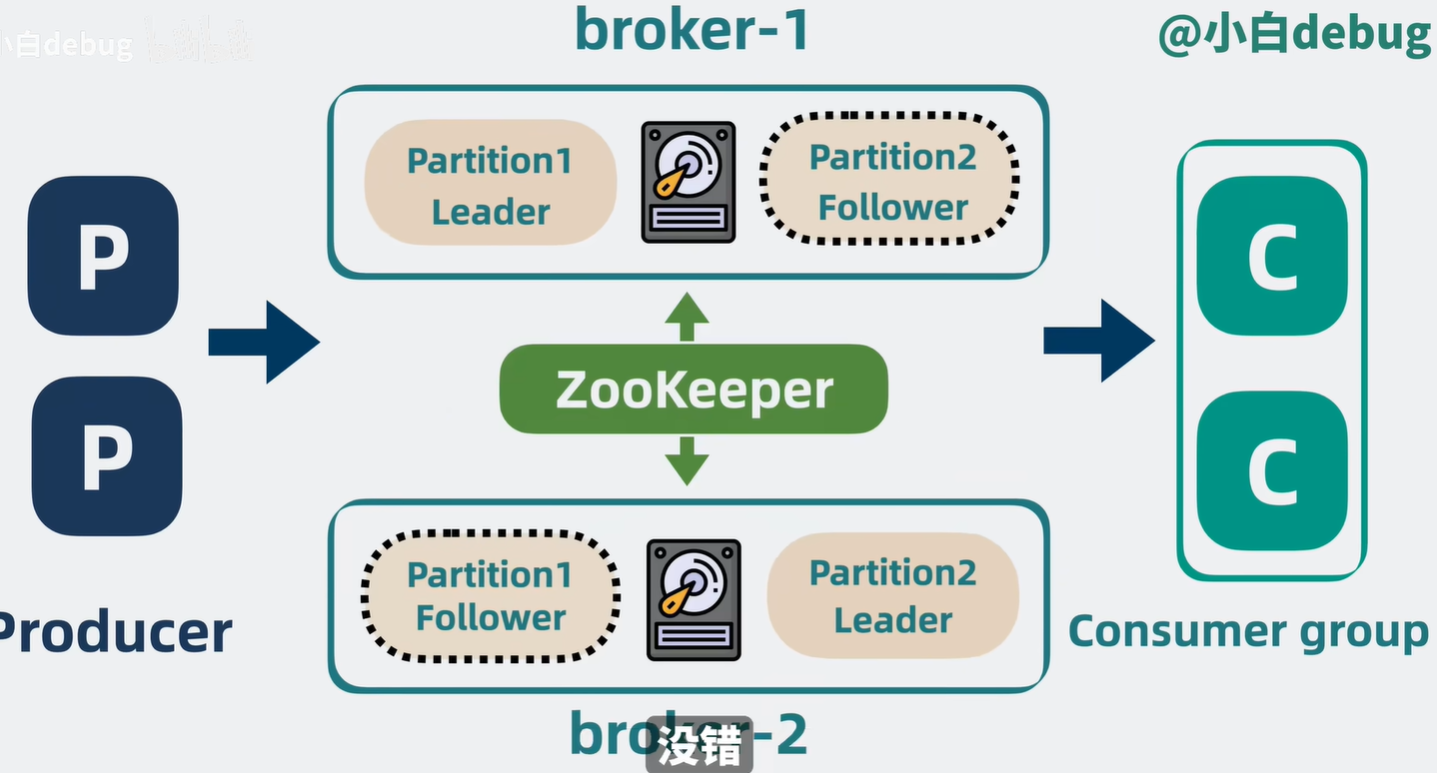
C. 分区 (Partitioning) —— 扩展性的核心
Kafka 将一个 Topic (主题) 拆分成了多个 Partition (分区)。
- 每个 Partition 是一个独立的物理日志文件。
- 不同的 Partition 可以分布在不同的服务器上。
- 结果:并发读写能力随着机器数量线性扩展。
3. Kafka 的核心组件
1. Broker
Kafka 的服务器节点。
2. Topic & Partition
- Topic 是逻辑分类(比如
logs)。 - Partition 是物理存储。Topic A 可以分为 Partition 0, 1, 2。
- 注意:Kafka 只保证 Partition 内部的消息有序,不保证整个 Topic 全局有序。
3. Producer (生产者)
生产者决定把消息发给哪个 Partition(通常轮询或 Hash)。
4. Consumer Group (消费者组) —— Kafka 的神来之笔
这是 Kafka 区别于 RabbitMQ 的最大特色。
- 机制:一个 Topic 可以被多个 Group 消费。
- 组内 (Queue 模式):同一个 Group 里的消费者,互相竞争。Partition 0 给消费者 A,Partition 1 给消费者 B。一个 Partition 只能被组内的一个消费者消费(防止乱序)。
- 组间 (Pub/Sub 模式):Group A 消费了一遍数据,Group B 可以再消费一遍同样的数据,互不干扰。
5. Offset (偏移量)
消费者读到哪了?RabbitMQ 是 Server 记,Kafka 是
消费者自己记(或者提交给 Kafka 的内部 Topic
__consumer_offsets)。
- 你可以随时修改 Offset,让消费者从昨天的数据开始重新跑一遍(用于修复 Bug 后重算数据)。
RocketMQ
消息队列RocketMQ是什么?和Kafka有什么区别?架构是怎么样的?7分钟快速入门_哔哩哔哩_bilibili