learn_pytorch
安装
PyTorch 在 PyPI 上的包名是
torch,而不是 pytorch
1 | # 仅安装 CPU 版本 |
安装 GPU 版本的 PyTorch 需要指定 CUDA 版本的索引。
1 | # CUDA 12.1 版本(推荐,适用于较新的显卡) |
检查你的 NVIDIA 驱动支持的 CUDA 版本:
1 | nvidia-smi |
如何知道对应的cuda版本索引
访问 PyTorch 官网: https://pytorch.org/get-started/locally/
torchvision 和 torchaudio 是 PyTorch 生态系统中的两个官方扩展库:
torchvision - 计算机视觉工具包:
- 预训练模型(ResNet、VGG、YOLO 等)
- 图像数据集(CIFAR-10、ImageNet、COCO 等)
- 图像转换和增强功能
- 图像读取和处理工具
torchaudio - 音频处理工具包:
- 音频数据集
- 音频转换和预处理
- 音频特征提取(MFCC、梅尔频谱等)
- 音频读取和保存
张量与向量
维度的区别 (最本质的区别)
这是区分它们的“金标准”。在数学和编程(如 NumPy,
PyTorch)中,我们看有多少层“方括号” []。
向量 (Vector):是一维的。
- 它只有 1 个轴 (Axis)。
- 对于向量而言,维度通常指:它里面包含了几个数字(元素的个数)。
- 代码形状:
[x, y, z]-> Shape:(3,)
张量 (Tensor):是多维的统称。
- 它可以是 0 维、1 维、2 维、3 维…甚至 N 维。
- 0阶张量 = 标量 (Scalar)
- 1阶张量 = 向量 (Vector) —— 看!向量在这里。
- 2阶张量 = 矩阵 (Matrix)
- 3阶+张量 = 通常直接叫张量。
Linear
1 | from torch import nn |
1 | OrderedDict([('weight', |
linear = nn.Linear(5, 3)
创建了一个线性层(全连接层):
参数含义:
- 5 - 输入特征数(in_features)
- 3 - 输出特征数(out_features)
内部结构: 这个层包含两个可学习的参数:
- 权重矩阵 W:形状为 (3, 5)
- 偏置向量 b:形状为 (3,)
数学运算: y = xWT + b
1 | from torch import tensor |
linear层的权重是torch.float32(Float)- PyTorch 不允许不同数据类型的张量进行矩阵运算
1 | input=tensor( |
1 | torch.Size([2, 2, 5]) |
1 | linear(input) |
1 | tensor([[[ 0.4754, -2.3285, 0.7223], |
输入:(2, 2, 5) ↓ nn.Linear(5, 3) ← 把最后一维从 5 变成 3 ↓ 输出:(2, 2, 3)
激活函数ReLU
1. 什么是激活函数?
激活函数简单来说就是,线性层之间的非线性变换
2. 核心作用:为什么要用它?
你可能会问:“大家都是算数学,为什么非要插在这个 Linear 层中间?不能直接 Linear 接 Linear 吗?”
答案是:绝对不行。 如果没有激活函数,神经网络就是个“草包”。
引入非线性 (Non-linearity) —— 让网络学会“弯曲”
这是激活函数存在的最大意义。
- 线性层只能画直线: y = wx + b 是直线的方程。不管你叠多少层线性层,直线叠加直线,最后还是一条直线(或者平面)。
- 现实世界是弯曲的: 比如要把“猫”和“狗”的图片分开,分界线绝不是一条直线,而是一条极其复杂的曲线。
- 激活函数的作用: 它就像一把钳子,把线性层画出的直线“掰弯”。有了它,神经网络才能拟合各种复杂的形状。
3. 常见的激活函数有哪些?
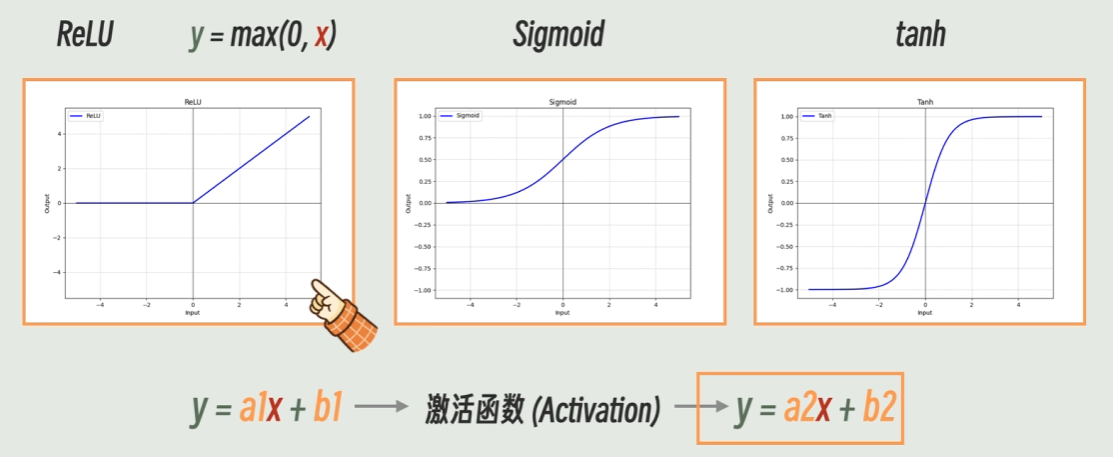
尽管ReLU形式简单,但在实际的工程实践上,效果却相比其他激活函数更好,并且由于形式简单,计算效率也更高,因此,ReLU是目前最流行的激活函数
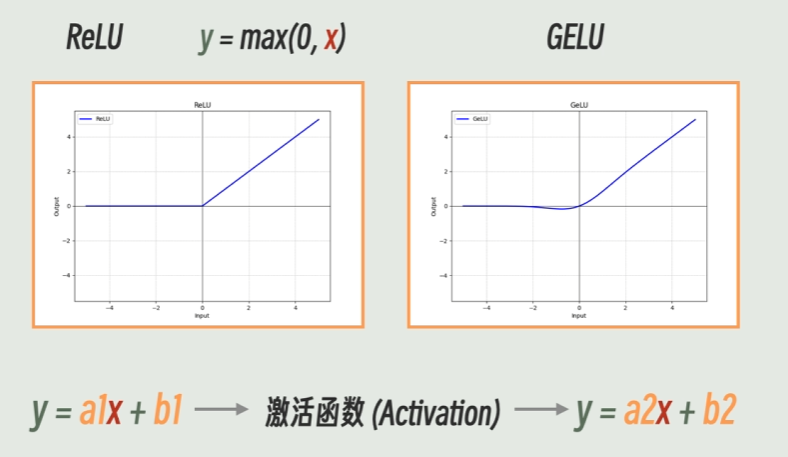
既然 ReLU 这么好,它有缺点吗?
为了客观,必须提一下它的一个著名缺陷:“Dead ReLU” (神经元死亡问题)。
- 现象: 因为负数区域梯度完全是 0。如果运气不好,某个神经元的参数被更新成了一个很大的负数,不管输入什么数据,它算出来都是负的。
- 结果: 经过 ReLU 后全是 0,梯度也是 0。这个神经元从此“死掉了”,再也不会更新,对网络没有任何贡献。
- 解决方案: 出现了一种变体叫 Leaky ReLU,给负数区域一点点斜率(比如 0.01x),让它别死透,还能有一点点梯度传回来。
前馈神经网络FFN
前馈神经网络(Feedforward Neural Network, FNN)是深度学习中最基础、最经典的架构,也被称为多层感知机 (MLP)。
可以用一句话来概括它:一条“绝不回头”的数据流水线。
1. 核心定义:为什么叫“前馈”?
“前馈” (Feedforward) 描述的是数据的流向。
- 单向通行: 信号从输入层进入,经过一层层的隐藏层处理,最后从输出层出来。
- 无回路: 信号永远不会在这个网络里转圈圈,也不会从后一层传回前一层(那是循环神经网络 RNN 做的事)。
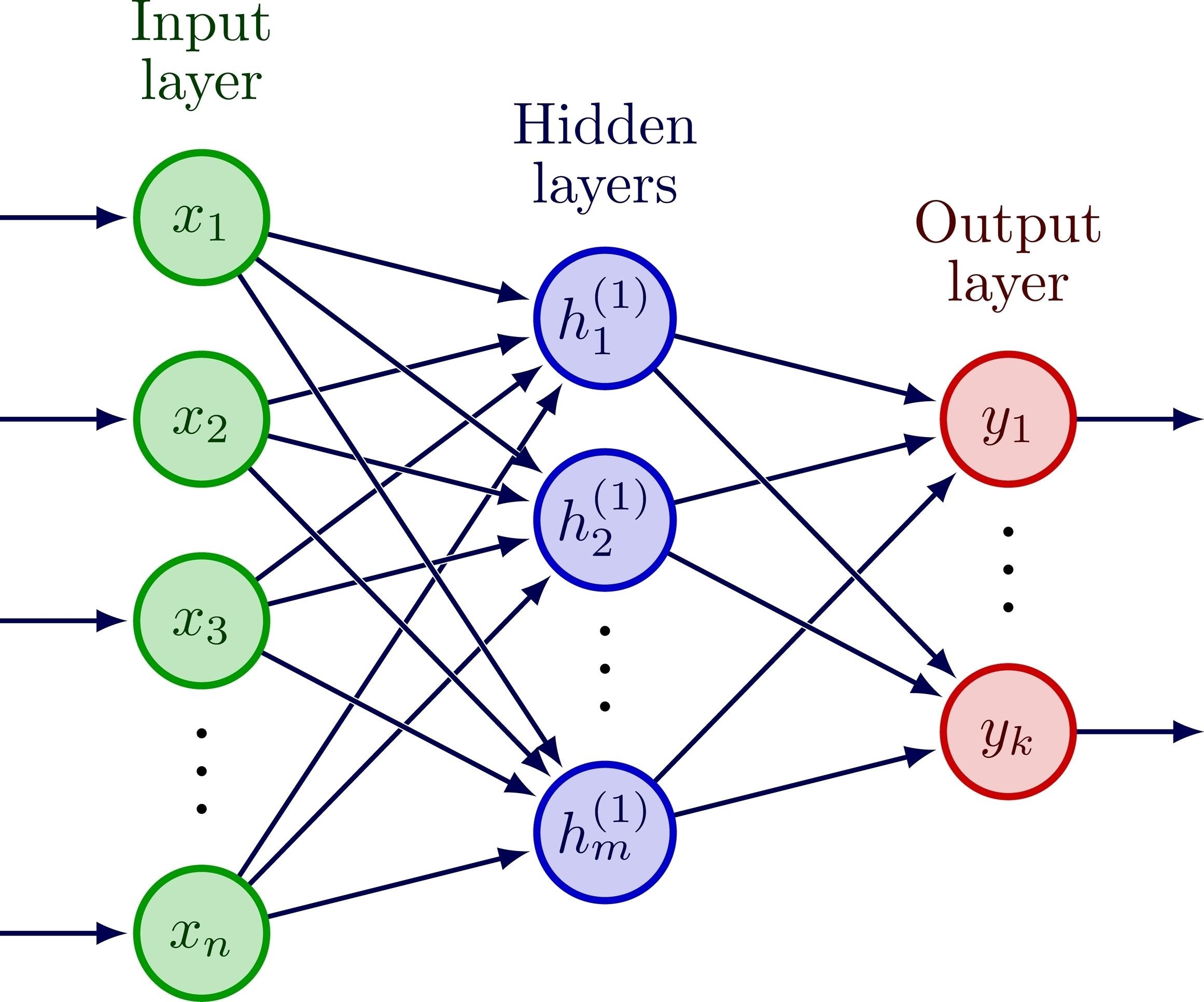
2. 它的解剖结构
一个典型的前馈神经网络由三部分组成“三明治”结构:
A. 输入层 (Input Layer)
- 作用: 负责接收原始数据(向量)。
- 特点: 这一层不进行任何计算,它只是数据的入口。
B. 隐藏层 (Hidden Layers)
- 作用: “提取特征”的主力军。这是网络“深”的地方。
- 组成: 就是我们刚才讲的
Linear(线性变换) +ReLU(非线性激活) 的组合。 - 为什么叫隐藏? 因为你看不到它们。输入和输出是你可以直接观察的,但中间这些层处理出的特征(比如“圆弧”、“边缘”)是机器内部理解的“黑盒”数据。
C. 输出层 (Output Layer)
- 作用: 给出最终结果。
- 特点: 通常不需要激活函数(直接出 Logits),或者接 Softmax 出概率。
3. 数学本质:函数的嵌套
如果你把这个网络拆解成数学公式,它其实就是一个巨大的复合函数。
假设你有两层网络:
- 第一层:h = ReLU(W1x + b1)
- 第二层:y = W2h + b2
把它们套在一起,整个神经网络就是:
$$y = W_2 \cdot \underbrace{ReLU(W_1 \cdot x + b_1)}_{\text{第一层的输出}} + b_2$$
前馈神经网络就是在做这件事:通过层层嵌套,把简单的 Wx + b 变成一个能拟合万物的超级函数。
识别手写数字
下载数据集
1 | import torchvision |
查看数据集
1 | print(train_data.data.shape) # torch.Size([60000, 28, 28]) |
1 | train_data.targets[0] # 获取第1张图片的标签(0-9的数字),表示这张图片是哪个数字 |
1 | tensor(5)#说明代表数字五 |
1 | train_data.data[0]# # 获取第1张图片的像素数据 |
1 | tensor([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, |
展平数据
1 | flat_test_data = test_data.data.view(10000, 784)# 将每张28x28的图片展平成784维的向量 |
把图片拉直是为了输入到全连接层(Linear层)!
原因:
- 图片的原始形状:
(28, 28)- 2维矩阵- 这是图片的”空间结构”
- 全连接层的需求: 每个样本必须是1维特征向量
归一化数据
1 | float_flat_test_data = flat_test_data.float() / 255.0 # 归一化到0-1之间 |
防止大数值可能导致梯度爆炸或消失
定义模型
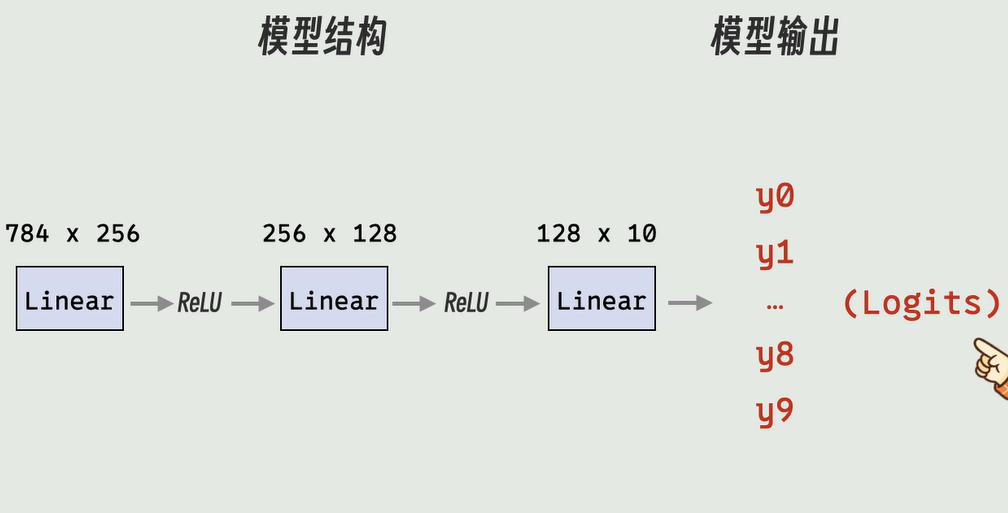
1 | import torch.nn as nn |
定义损失函数
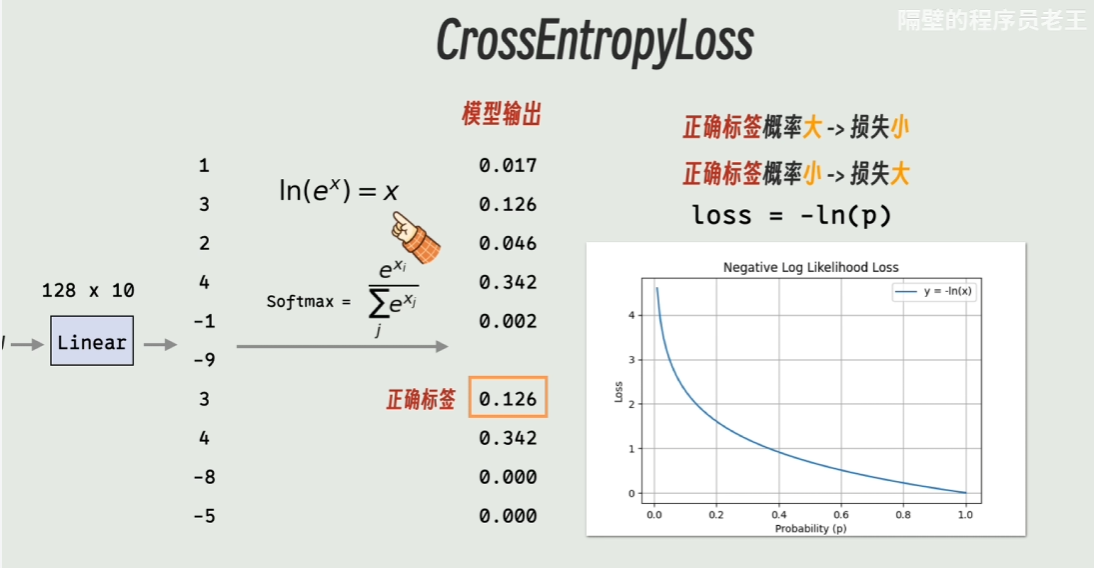
这里使用CrossEntropyLoss
1 | import torch.nn as nn |
模型训练
1 | import torch |
1 | Epoch 1/5, loss=0.2660 |
保存训练参数
1 | # 保存 |
加载模型与预测
1 | import torch |