LinearRAG论文阅读
深度学习大作业实验报告
RAG 的现状与瓶颈
1. 朴素 RAG (Naive RAG) 的现状与瓶颈
- 现状:通过外部知识库增强 LLM,是目前处理知识密集型任务的标准做法,。其核心操作是将文档切分为小块(Chunks)并进行语义索引,。
- 瓶颈:
- 上下文丢失:简单的分块策略会导致关键上下文细节的丢失,损害检索精度。
- 难以处理复杂推理:在面对大规模、非结构化语料库时,相关信息往往分散在不同文档中。朴素 RAG 往往只关注关键词匹配,容易遗漏多跳推理链条中必不可少的逻辑相关文档,。
- 组织混乱:检索到的内容往往冗长、复杂且缺乏清晰的组织,导致生成结果的一致性和准确性存在波动。
2. 图 RAG (GraphRAG) 的兴起与局限
- 现状:为了解决多跳推理问题,GraphRAG(如 Microsoft GraphRAG, LightRAG 等)通过构建外部结构化图来建模背景知识的层次结构,以提升检索的广度与深度。
- 瓶颈:
- 关系提取的不稳定性:现有的 GraphRAG
极度依赖大语言模型进行“关系提取”,但这个过程不稳定且容易产生幻觉。
- 局部不准确:关系提取模型常产生错误的事实三元组(例如将“没得奖”误认为“得奖”),。
- 全局不一致:由于缺乏全局协调机制,构建出的图结构往往是破碎、连接性差且充满结构性冲突的,。
- 成本与效率低下:构建复杂的知识图谱需要调用大量 LLM Token,过程极其昂贵且耗时,难以随语料库规模线性扩展,。
- 噪声引入:虽然图检索能提高召回率(Recall),但由于图中存在大量错误连接,会引入严重噪声,导致其在现实应用中的表现有时甚至不如朴素 RAG,。
- 关系提取的不稳定性:现有的 GraphRAG
极度依赖大语言模型进行“关系提取”,但这个过程不稳定且容易产生幻觉。
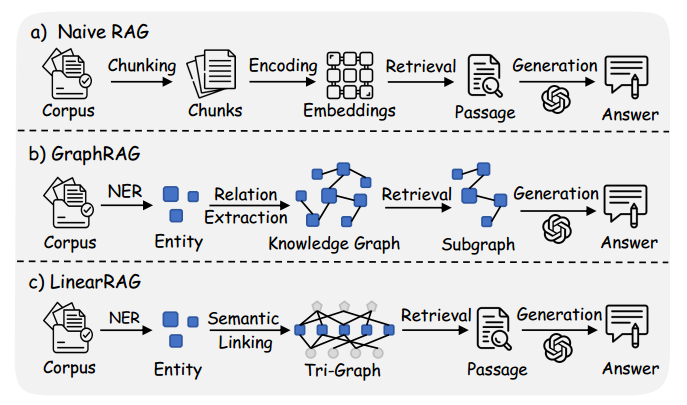
局部不准确和全局不一致
根据源代码,局部不准确(Local Inaccuracy)和全局不一致(Global Inconsistency)是传统 GraphRAG 系统由于过度依赖大语言模型(LLM)进行“关系提取”而产生的两大核心缺陷,。
1. 局部不准确 (Local Inaccuracy)
这指的是在单个三元组(Triple)层面的知识质量问题。
- 核心定义:关系提取模型在处理单个文本段落时,经常会产生事实错误的三元组,导致实体之间的语义关系被歪曲,。
- 具体案例:源代码中举了一个生动的例子:原始句子是“爱因斯坦没有因为相对论获得诺贝尔奖”,但关系提取模型可能会将其错误地提取为
(爱因斯坦, 获得了诺贝尔奖, 相对论)。 - 后果:这种从根本上改变事实意义的错误会直接导致图谱中充斥着虚假信息(Noise),从而误导后续的检索和生成过程,。
2. 全局不一致 (Global Inconsistency)
这指的是在整个图谱结构/跨三元组层面的逻辑冲突问题。
- 核心定义:由于关系提取通常是在单个文档片段上局部进行的,缺乏一个全局机制来验证或协调整个语料库中的连接,导致构建出的图谱在结构上是碎片化的,且连接性极差,。
- 具体案例:源代码提到,在构建关于“AI”的图谱时,系统可能会将“自然语言处理(NLP)”、“计算机视觉(CV)”和“无监督学习(UL)”都链接为 AI 的并行子类别,。然而在逻辑上,NLP 和 CV 是 AI 的子领域,而 UL 是其中的一种技术手段。这种缺乏层次一致性的表达会导致结构性冲突。
- 后果:这种结构上的模糊性和不连贯性会导致检索路径断裂,使模型在处理需要跨篇章整合信息的复杂查询时,无法找到正确的逻辑链条,。
总结与影响
这两大缺陷共同导致了 GraphRAG 的性能退化。虽然图结构本意是提高召回率,但由于图中存在大量错误事实(局部不准确)和逻辑冲突(全局不一致),系统会引入严重的语义噪声,。实验表明,这使得传统 GraphRAG 在现实应用中的准确性和一致性有时甚至不如朴素的 RAG
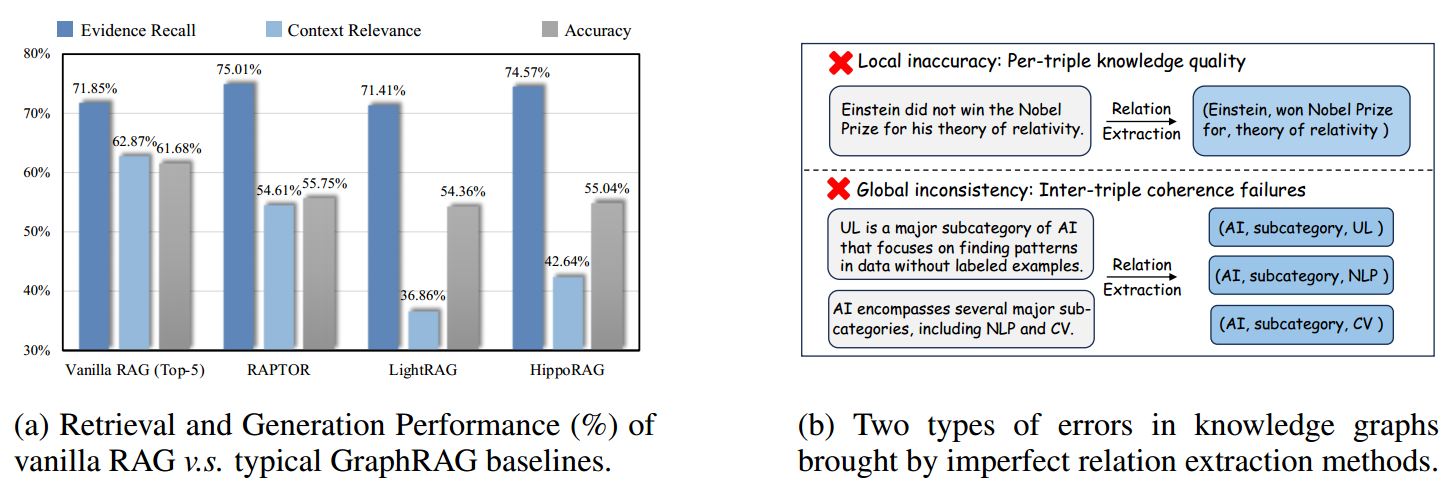
左图 (a):性能对比——理想与现实的差距
这张柱状图展示了传统 RAG(Vanilla RAG)与几种主流 GraphRAG 基准模型(RAPTOR, LightRAG, HippoRAG)在三个关键指标上的表现:
- Evidence Recall(证据召回率 - 深蓝色):衡量系统能否把包含答案的原文找回来。
- Context Relevance(上下文相关性 - 浅蓝色):衡量找回来的东西是不是废话,与问题的匹配度如何。
- Accuracy(准确率 - 灰色):最终生成答案的正确率。
图表传达的核心信息:
- GraphRAG 不一定比 Vanilla RAG 强:你会发现,在很多指标上(尤其是准确率 Accuracy),Vanilla RAG 甚至优于一些复杂的图模型。
- “副作用”明显:许多 GraphRAG 为了追求召回率(Recall),召回了大量噪音,导致上下文相关性(Context Relevance)显著下降。例如 LightRAG 的浅蓝色柱子非常短,说明它召回了很多无关信息,干扰了大模型的判断。
- LinearRAG 的出发点:这组数据有力地反击了“只要加了图谱效果就一定好”的迷思。它暗示现有的图构建方法(依赖三元组提取)可能引入了负面影响。
右图 (b):错误分类——为什么图谱会失效?
这张图深入探讨了导致左图数据不佳的根源,即不完美的“关系提取(Relation Extraction)”带来的两种致命错误:
1. 局部不准确 (Local Inaccuracy)
- 案例:原文说“爱因斯坦没有因为相对论获得诺贝尔奖”。
- 错误提取:大模型在提取三元组时,忽略了否定词,强行提取出
(爱因斯坦, 获得诺贝尔奖, 相对论)。 - 后果:知识图谱里存入了错误的事实。一旦存入,后续无论检索算法多强,答案必然是错的。这就是“垃圾进,垃圾出”(Garbage In, Garbage Out)。
2. 全局不一致 (Global Inconsistency)
- 案例:
- 片段 A 提取出:
AI 的子类别包含 UL(无监督学习)。 - 片段 B 提取出:
AI 的主要子类别包含 NLP 和 CV。
- 片段 A 提取出:
- 错误表现:这些三元组之间缺乏逻辑内聚性。在全局视图下,系统无法理清这些子类别之间的并列、包含或权重关系。
- 后果:当用户问“AI 有哪些主要分支?”时,系统可能会因为图谱节点间的孤立或冲突,给出碎片化或逻辑混乱的回答。
## 什么是复杂多跳(multi-hop)推理任务
复杂多跳(multi-hop)推理任务是指那些无法通过检索单一文档或事实来完成,而必须跨越多个异构文档、整合碎片化信息并进行多步逻辑推导才能解决的任务
核心特征
• 跨文档合成:这类任务要求模型从多个文档中合成信息,并进行有效的跨文档推导和证据选择。
• 序列化推理步骤:多跳任务通常需要 2 到 4 个连续的推理步骤,要求模型在推理过程中保持上下文的一致性。
• 信息分散性:在现实场景中,相关信息往往不均匀地分布在不同的文档中,这使得仅靠关键词匹配的传统检索方法难以奏效,。
LinearRAG框架的总体流程
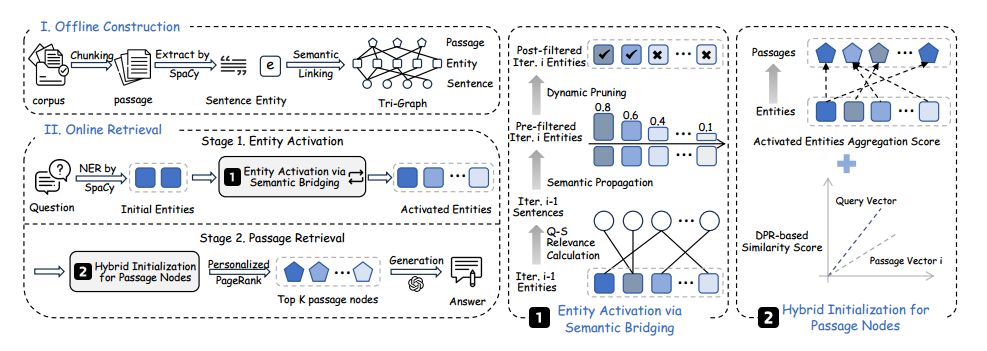
根据源代码中的 Figure 3 以及相关章节的描述,LinearRAG 框架的总体流程可以清晰地划分为两个核心阶段:离线图构建(Offline Construction)和在线检索与生成(Online Retrieval & Generation)。
以下是结合框架图的详细步骤解析:
一、 离线图构建 (I. Offline Construction)
这一阶段的目标是将原始语料库转化为一个轻量级、无关系的层次化结构,即 Tri-Graph。
- 文本处理与分段:首先将语料库(Corpus)切分为篇章节点(Passage),并进一步细分为句子节点(Sentence)。
- 实体提取 (NER):使用轻量级的工具(如 SpaCy)识别文本中的实体节点(Entity),这一步完全不消耗大模型的 Token。
- 建立连接 (Tri-Graph 构建):
- 包含矩阵 C:连接实体与篇章节点(记录哪个篇章包含哪些实体)。
- 提及矩阵 M:连接实体与句子节点(记录哪个句子提到了哪些实体)。
- 核心优势:该过程具有线性扩展性,且保留了原始文本的完整语义,避免了传统 GraphRAG 在关系提取中产生的幻觉和事实错误。
二、 在线检索 (II. Online Retrieval)
当系统接收到查询(Query)时,会通过两个互补的阶段在 Tri-Graph 上进行检索:
第一阶段:通过语义桥接激活实体 (Stage 1: Entity Activation)
- 初始激活:从查询中提取实体,并根据语义相似度在图中找到对应的初始实体节点。
- 局部语义传播 (Semantic Propagation):计算查询与各句子的语义相关性,并利用句子-实体子图进行传播,从而发现那些虽然没被查询提及、但在逻辑上起到桥梁作用的隐藏中间实体。
- 动态剪枝 (Dynamic Pruning):通过设定阈值 δ 过滤掉低相关的实体,防止搜索空间爆炸,确保检索聚焦在高质量的语义路径上。
第二阶段:通过全局重要性聚合检索篇章 (Stage 2: Passage Retrieval)
- 混合初始化:结合第一阶段激活的实体得分与查询-篇章的直接相似度,为图节点赋予初始重要性分数。
- 个性化 PageRank (PPR):在实体-篇章子图上运行 PPR 算法,通过图结构进行全局重要性聚合,评估每个篇章的综合贡献。
- 获取 Top-K:最终根据 PPR 得分选取最相关的 Top-K 个篇章作为背景知识。
三、 生成阶段 (Generation)
系统将检索到的 Top-K 篇章与原始查询一同输入大语言模型(如 GPT-4o-mini),模型基于这些高质量、逻辑连贯的上下文生成最终答案
传统的 GraphRAG目前问题
1. 语义表达的“原子化”困境
你提到的“三元组无法传达正确含义”在来源中被描述为语义细节的丢失。
- 复杂性难以压缩:自然语言中的关系往往是复杂、依赖上下文且具有组合性的。来源指出,像“瑞秋不情愿地同意和菲比一起去跑步”这样的句子,很难被干净地简化为原子三元组而不丢失关键的语义细微差别。
- 原始文本才是最佳载体:LinearRAG 的核心主张之一就是原始文本完整保留了所有上下文关系。通过强行提取关系,反而可能产生“局部不准确”,导致事实被歪曲(例如漏掉否定词)。
2. 成本与效率的“Token 陷阱”
你提到的“构建过程极度依赖大模型导致高成本”是阻碍 GraphRAG 大规模应用的最大障碍。
- 昂贵的索引阶段:传统的 GraphRAG 在构建索引时需要调用 LLM 进行大量的三元组提取或摘要生成,这会产生海量的 Token 消耗。
- 线性扩展性差:来源中的实验显示,像 LightRAG 这种模型在索引 2Wiki 数据集时需要消耗约 35.52M 的 Token,耗时近 5000 秒。相比之下,LinearRAG 采用轻量级的实体提取,实现了零 Token 消耗,且索引速度提升了 77% 以上。
3. 检索时的“噪声干扰”
你提到的“杂乱错误的关系误导检索”对应了来源中发现的“高召回、低相关”现象。
- 召回与相关的矛盾:虽然图结构能通过多跳连接帮模型“找得更多”(高召回率),但由于图中充满了错误提取的事实(局部不准确)和逻辑冲突(全局不一致),这些“脏数据”引入了巨大的语义噪声。
- 性能倒退:实验证明,很多 GraphRAG 模型在“上下文相关性”指标上表现惨淡(仅 36.86%~54.61%),甚至不如简单的朴素 RAG(62.87%),正是因为 LLM 被检索出来的错误关联信息给带偏了
LinearRAG的优势,如何解决传统的GraphRAG目前问题
根据源代码和我们的讨论,LinearRAG 框架通过一种全新的“线性”范式,针对性地解决了传统 GraphRAG 的三大痛点。以下是其核心优势及解决方案的总结:
1. 解决语义丢失问题:采用“原始文本”作为知识载体
传统三元组由于过于简练,往往无法捕捉自然语言中细微、复杂的语义细节。
- 无关系图谱(Relation-free Tri-Graph):LinearRAG 不再强行将文本摘要成“主-谓-宾”三元组,而是构建了一个包含实体、句子和篇章三层节点的层级图。
- 信息无损化:该框架主张原始文本才是关系的完整保留者。它通过实体对齐将分散的篇章连接起来,但在推理时直接检索并提供原始篇章给大模型,确保所有上下文细节(如语气、否定词)得到 100% 保留,从而避免了“二次创作”带来的事实歪曲。
2. 解决高昂成本问题:实现“零 Token”索引与全阶段线性扩展
构建传统知识图谱极其依赖大模型进行关系抽取,这导致了惊人的 Token 消耗和时间成本。
- Token-free 索引构建:LinearRAG 使用轻量级的命名实体识别(NER,如 spaCy)和语义链接技术来构建图谱,而非调用昂贵的大模型。这使得其在索引阶段产生的 LLM Token 消耗为零。
- 效率极大幅度提升:由于其算法复杂度随语料库规模呈线性增长(Linear Scalability),索引构建时间比传统方法缩短了 77% 以上。在处理大规模数据集(如 10M Token)时,其速度比现有领先方法(如 RAPTOR)快 15.1 倍。
3. 解决检索噪声问题:两阶段精准检索机制
传统的图检索常因为错误的边或碎片化的结构引入大量无关的背景信息(噪声),导致“找得多但找得乱”。
- 局部语义桥接(Entity Activation):在第一阶段,它不依赖显式关系,而是通过语义传播(Semantic Propagation)来激活那些没在查询中直接出现、但在逻辑链条中起桥梁作用的“隐藏实体”。同时,通过动态剪枝(Dynamic Pruning)剔除无关路径,从源头封堵噪声。
- 全局重要性聚合(Global Importance Aggregation):在第二阶段,利用个性化 PageRank(PPR)算法,从全局视角对篇章的重要性进行评分。这确保了检索到的 Top-K 篇章不仅与问题相关,而且在逻辑结构上具有核心价值。
- 突破性能瓶颈:实验证明,LinearRAG 成功克服了“高召回率必然导致低相关性”的难题,在保持极高证据召回率的同时,上下文相关性得分显著优于 HippoRAG 和 GFM-RAG 等模型。
Token-free Graph Construction(零 Token 图构建)
Token-free Graph Construction(零 Token 图构建)是 LinearRAG 框架的核心创新之一,旨在通过构建一个名为 Tri-Graph 的层次化图结构,彻底解决传统 GraphRAG 在索引阶段由于依赖大模型(LLM)进行关系抽取而导致的高昂成本、事实错误和扩展性差的问题。
以下是该技术的详细讲解及其数学公式:
1. 核心架构:三层图(Tri-Graph)
LinearRAG 并不提取复杂的“实体-关系-实体”三元组,而是建立一个包含三种粒度节点的层级结构:
- 篇章节点 (Vp):语料库中的原始文本段落集合 P。
- 句子节点 (Vs):通过标点符号(如句号、感叹号)将篇章进一步切分得到的句子集合 S。
- 实体节点 (Ve):使用轻量级模型(如 spaCy 的 BERT 基础模型)从文本中识别出的命名实体集合 E。
2. 边构建规则与数学定义
该框架通过两个关键的邻接矩阵来捕捉节点间的关联,这些边仅基于“包含”或“提及”关系,而非不稳定的语义关系建模:
A. 包含矩阵 (Contain Matrix, C)
该矩阵描述了篇章与实体之间的从属关系。如果篇章 pi 包含实体 ej,则在对应的节点间建立一条边。其形式化定义为: C = [Cij] * |Vp|×|Ve|, 其中 C * ij = 𝟙pi contains ej (1) 这里 𝟙 是指示函数,若包含则 Cij = 1,否则为 0。
B. 提及矩阵 (Mention Matrix, M)
该矩阵描述了句子与实体之间的显式提及关系。如果句子 si 提到了实体 ej,则建立连接。其形式化定义为: M = [Mij] * |Vs|×|Ve|, 其中 M * ij = 𝟙si mentions ej (2) 同样地,Mij 的值仅取决于句子中是否出现了该实体的字面量。
3. “Token-free”的技术优势
之所以称之为“Token-free”,是因为其构建过程完全不消耗 LLM Token,具有极高的经济性:
- 轻量级提取:使用 spaCy 等非大模型工具进行命名实体识别(NER),比大模型驱动的开放域信息抽取(OpenIE)更精准且效率更高。
- 线性扩展性:计算复杂度为 O(|P|⋅T)(其中 T 是篇章平均长度),这意味着处理速度随语料库规模呈线性增长。
- 稀疏存储:由于每个句子通常只包含少量实体(约4个),矩阵 C 和 M 在实现上采用稀疏格式,极大地降低了内存占用。
- 信息无损(Lossless):传统三元组会丢失文本中的语气和微妙细节(如“不情愿地同意”),而 LinearRAG 保留原始篇章作为知识载体,确保了语义的完整性。
4. 动态维护与更新
当新文档加入语料库时,系统只需对新篇章进行句子切分、NER 提取并更新邻接矩阵中的对应条目,无需重新计算或校对全局的图结构,这使其非常适合大规模且快速增长的工业级应用
命名实体识别(Named Entity Recognition)
根据提供的来源和我们之前的对话,NER 的全称是命名实体识别(Named Entity Recognition)。
在这些源代码中,NER 是 LinearRAG 框架实现高效知识索引的核心技术。以下是关于 NER 的详细讲解:
NER 在框架中的定义与工具
- 基本定义:NER 是一种从文本中识别并提取特定类别实体(如人名、组织、地点等)的技术。在 LinearRAG 中,NER 被用来生成“实体集合(Entity Set)”,这些实体构成了 Tri-Graph(三层图)中的实体节点 (Ve)。
- 具体工具:来源多次提到使用 spaCy 等轻量级模型来执行 NER。这些工具通常基于 BERT 等基础模型,而不是昂贵的大语言模型(LLM)。
第一阶段:通过语义桥接激活相关实体(Relevant Entity Activation via Semantic Bridging)
在 LinearRAG 框架中,第一阶段:通过语义桥接激活相关实体(Relevant Entity Activation via Semantic Bridging) 是其精准检索多跳信息的关键。
这一阶段的核心逻辑是在 “实体-句子”子图上操作,旨在识别那些在查询中未被直接提及、但在逻辑链条中起桥梁作用的中间实体。以下是该阶段的详细步骤与公式解析:
1. 初始实体激活 (Initial Entity Activation)
首先,系统需要将自然语言查询转化为图谱中的初始状态。
- 提取与匹配:使用 spaCy 从查询 q 中提取实体集合 Eq。对于 Eq 中的每个实体,在 Tri-Graph 的实体库 Ve 中寻找语义最相似的节点。
- 公式定义:生成一个稀疏的初始激活向量 aq: aq = [aq, i] * |Ve|×1, 其中 a * q, i = 𝟙 * i = argmax * ej ∈ Vesim(eq, ej) ⋅ sim(eq, ei) (3) 这里 aq, i 代表实体节点 i 的初始激活分值,由其与查询实体的相似度决定。
计算查询问题中实体和知识图谱所有实体的相似度
2. 查询-句子相关性分布 (Query-Sentence Relevance Distribution)
为了引导激活分数的传播方向,系统需衡量查询与语料库中每个句子的关联度。
- 计算相似度:计算查询问题 q 与句集 S 中每个句子 si 的语义关联,生成相关性向量 σq。
- 公式定义: σq = [σq, i] * |S|×1, 其中 σ * q, i = sim(q, si) (4) 该向量确保了传播过程会向语义相关性更高的上下文区域倾斜。
计算查询问题和知识图谱中所有句子的相似度
3. 语义传播 (Semantic Propagation)
在 LinearRAG 框架中,语义传播(Semantic Propagation)*是第一阶段“通过语义桥接激活相关实体”的核心逻辑,。它的主要任务是通过*“实体-句子-实体”*的路径,在图中“顺藤摸瓜”,发掘出那些查询问题中没有直接提到、但在逻辑链条中至关重要的*中间实体,。
以下是基于源代码公式 (5) 的具体解析:
核心公式拆解
语义传播通过以下迭代公式更新实体的激活分数向量 aq: aqt = MAX(MT(σq ⊙ (Maqt − 1)), aqt − 1)
我们可以将这个复杂的数学过程拆解为三个直观的物理动作:
- 第一步:从点到线 (Maqt − 1)
- 激活分数从上一轮已知的“种子实体”(aqt − 1)出发,沿着提及矩阵 M(记录了哪个句子提到了哪个实体)流向包含它们的句子。
- 这相当于在问:“有哪些句子提到了当前的这些关键人物?”
- 第二步:加权过滤 (σq ⊙ ...)
- 流向句子的分数会与查询-句子相关性向量 σq 进行逐元素相乘。
- 这相当于在筛选:“在这些提到的句子中,哪些句子跟我的问题最匹配?”只有语义高度相关的句子,分数才会被放大,无关的句子分数则被抑制。
- 第三步:从线到点 (MT...)
- 经过筛选的分数再沿着矩阵的转置 MT 流回到这些句子中出现的所有实体。
- 这步最关键:即使某个实体没在问题里出现,但只要它出现在了一个高相关性的句子里,它就会被“激活”。
- 第四步:保留最优 (MAX(..., aqt − 1))
- 取当前计算出的新分数与历史最高分的极大值,确保实体的激活程度是累积且最优的。
为什么叫“语义桥接”?
这种机制建立了一种隐式关系匹配(Implicit Relation Matching)。 传统的 GraphRAG 需要通过大模型提取显式的关系三元组(如“A 是 B 的丈夫”),这既贵又容易出错,。而 LinearRAG 的语义传播认为:如果两个实体出现在同一个与查询相关的句子里,它们之间就存在某种潜在的语义关联(即桥梁),。
关键特性
- 多跳推理(Multi-hop Reasoning):每进行一次迭代,搜索范围就向外扩展一“跳”。源代码指出,通常只需要 4 次以内的迭代,就能覆盖绝大多数复杂的多跳推理路径。
- 计算极其高效:整个过程被简化为稀疏矩阵相乘(SpMM)和极大值运算,不涉及大模型的 API 调用(Token-free),且可以利用硬件进行并行加速,。
- 动态剪枝保护:在传播过程中,系统会配合阈值 δ 进行动态剪枝。如果一个实体被传播到的分数太低,它就会被果断舍弃,防止搜索范围像滚雪球一样扩散到无关的语义区域。
实验证明的作用
在消融实验中,如果去掉“语义传播”这一步(即只使用问题里直接提取的实体),系统在处理复杂问题(如 HotpotQA)时的准确率会显著下降,。这证明了语义传播是捕捉隐藏逻辑链条的功臣
4. 动态剪枝 (Dynamic Pruning)
在 LinearRAG 框架中,Dynamic Pruning(动态剪枝) 是第一阶段“语义桥接”检索中至关重要的质量控制机制,。
在语义传播(Semantic Propagation)过程中,激活分数会不断向外扩散。如果没有约束,搜索空间将随传播深度的增加呈指数级增长。动态剪枝的作用就是确保搜索始终聚焦在高质量的语义路径上。以下是其具体讲解:
核心运行机制
动态剪枝通过引入一个激活阈值 δ(Threshold)来过滤节点:
- 评分过滤:在每一轮迭代传播中,系统会计算新实体的相关性得分。只有当实体的分数超过阈值 δ 时,它才会被保留并允许作为下一轮传播的“种子”。
- 舍弃噪声:得分低于 δ 的实体会被视为无关噪声或弱相关干扰,直接从激活向量中移除(分值归零)。
- 自适应终止:当某一轮迭代后,没有任何新实体的得分能超过 δ 时,传播过程会自动停止。这意味着系统能根据问题的复杂程度,动态调整搜索深度。
解决的两大痛点
- 防止语义漂移(Semantic Drift):如果没有剪枝,不相关的实体可能会反复充当新的种子,导致搜索过程偏离原本的查询意图,进入完全无关的语义区域。例如,查询“气候变化”时,如果没有剪枝,可能会顺着微弱的联系跳跃到无关的“经济政策”篇章。
- 控制计算复杂度:通过过滤低质量路径,系统将搜索限制在一个规模可控且精准的子图中,避免了计算量的爆炸式扩张。
阈值 δ 的影响与设置
根据来源中的参数敏感性实验,δ 的选取对性能有显著影响,:
- δ 太小:会导致引入过多的背景噪声,降低检索效率和精准度。
- δ 太大:会过于严格,导致系统丢失关键的中间证据实体,限制了捕捉完整上下文的能力。
- 推荐设置:在 LinearRAG 的实验中,设置 δ = 0.4 通常能达到检索质量与计算效率的最佳平衡。
第二阶段:通过全局重要性聚合进行篇章检索(Passage Retrieval via Global Importance Aggregation)
在完成第一阶段的实体激活后,LinearRAG 进入第二阶段:通过全局重要性聚合进行篇章检索(Passage Retrieval via Global Importance Aggregation)。
这一阶段的任务是利用第一阶段识别出的“种子”实体,在“实体-篇章”子图上衡量每个篇章的全局重要性,从而锁定最终的检索结果。以下是该阶段的详细解析与核心公式:
1. 初始分数分配:混合初始化(Hybrid Initialization)
在开始全局聚合之前,系统需要为图中的节点赋予初始重要性分数。
- 实体节点的初始化: 实体节点 vi ∈ Ve 的初始分数直接采用第一阶段计算得到的激活分数 aq。 I(vi|vi ∈ Ve) = aq, i
- 篇章节点的初始化: 篇章节点 v ∈ Vp 的初始分数采用混合评分机制。它结合了篇章与查询的直接语义相似度,以及该篇章所包含的已激活实体的贡献。公式如下(公式 7): $$I(v|v \in V_p) = \left( \lambda \cdot sim(q, v) + \ln \left( 1 + \sum_{e_i \in E_a} \frac{a_{q,i} \cdot \ln(1 + N_{ei})}{L_{ei}} \right) \right) \cdot W_p \quad$$
2. 全局重要性聚合:个性化 PageRank (PPR)
有了初始分值后,系统通过个性化 PageRank 算法在实体与篇章组成的二部图上进行分数迭代传播。这一步能从全局视角聚合信息,识别出那些通过多个关键实体连接起来的核心篇章。
聚合公式如下(公式 6): $$I(v_i) = (1 - d) + d \cdot \sum_{v_j \in B(v_i)} \frac{I(v_j)}{deg(v_j)} \quad$$
- d:阻尼因子,通常设为 0.85。
- B(vi):指向节点 vi 的邻居节点集合。
- deg(vj):节点 vj 的出度(连接数)。
通过这种方式,重要性分数在实体和篇章之间反复流动:一个包含多个“高分实体”的篇章会获得更高的评分;反之,一个被多个“重要篇章”共同提及的实体也会被进一步强化。
3. 排序与输出 (Ranking)
完成 PPR 迭代后,系统根据每个篇章节点最终获得的全局重要性分数 I(v|v ∈ Vp) 进行降序排列,并选取前 k 个(Top-k)得分最高的篇章作为检索结果,交给大模型(LLM)生成答案。
篇章节点的初始化(Passage Node Initialization)
在 LinearRAG 的第二阶段(篇章检索阶段),篇章节点的初始化(Passage Node Initialization) 是通过混合评分机制为语料库中的篇章赋予初始重要性分数的关键步骤,。这一过程将第一阶段发现的“逻辑线索”(激活实体)与传统的语义相似度相结合,从而识别出那些对回答多跳问题至关重要的篇章,。
以下是其详细解释和数学公式:
1. 篇章节点初始化公式
根据来源中的公式 (7),篇章节点 v ∈ Vp 的初始重要性分数 I(v) 计算如下:
$$I(v|v \in V_p) = \left( \lambda \cdot sim(q, v) + \ln \left( 1 + \sum_{e_i \in E_a} \frac{a_{q,i} \cdot \ln(1 + N_{ei})}{L_{ei}} \right) \right) \cdot W_p \quad$$
2. 公式参数详细拆解
该公式通过两个核心模块的加权聚合来定义篇章的重要性:
- 直接语义相关性部分 (λ ⋅ sim(q, v)):
- sim(q, v):表示查询问题
q 与整个篇章 v
之间的语义相似度,通常使用嵌入模型(如
all-mpnet-base-v2)计算余弦得分,。 - λ(折衷系数):用于调节相似度得分的权重。实验表明,当 λ 设为较小值(如 0.05)时性能最优。这说明 实体信息是核心贡献者,而直接的语义相似度仅作为辅助增强。
- sim(q, v):表示查询问题
q 与整个篇章 v
之间的语义相似度,通常使用嵌入模型(如
- 实体逻辑贡献部分 (ln (1 + ∑...)):
这一项衡量篇章中包含的“激活实体”对其重要性的贡献:
- Ea:是在第一阶段通过语义传播被成功激活的所有实体集合。
- aq, i:实体 ei 的激活分数。如果这个实体在逻辑链条中越关键,它的分数就越高,。
- Nei:实体 ei 在该篇章 v 中出现的次数。出现次数越多,该篇章与该实体的关联越强。
- Lei:实体的层级水平(Hierarchical Level),用于调节不同层级实体的影响力。
- 全局调节项 (Wp):
- Wp:篇章节点权重系数。它作为一个全局缩放因子,决定了篇章节点在进入后续图算法(个性化 PageRank)之前所携带的总体能量量级。
3. 这个公式解决的核心问题
弥补传统检索的“多跳”盲区: 传统的相似度检索(即 *s**im(q,v*))往往只关注关键词匹配,容易错过那些虽然没有关键词、但包含关键推理线索的篇章。这个公式通过引入第一阶段激活的实体信息,强制系统关注那些处于逻辑链条上的篇章。
确定“实体”与“内容”的权重 (λ): 实验发现,当 λ 设置得很小(如 0.05)时,效果最好。
◦ 洞察:这说明在复杂的推理任务中,篇章里包含哪些“正确实体”(即第一阶段挖出的线索)比篇章整体看起来像不像问题要重要得多。
4. 公式的最终产出
计算出的这个初始分数 I(v) 将作为 个性化 PageRank (PPR) 算法的“种子”。在接下来的全局聚合中,分数会从这些高分篇章出发,在“实体-篇章”二部图上反复流动,最终识别出那些在全球视角下最能支撑推理链条的 Top-k 篇章。
全局重要性聚合(Global Importance Aggregation)
在 LinearRAG 框架中,全局重要性聚合(Global Importance Aggregation)是检索的第二阶段,其核心目标是利用第一阶段激活的“线索实体”,通过图算法在全局范围内锁定最关键的篇章。
以下是该阶段计算逻辑的详细拆解:
1. 运行环境:篇章-实体二部图
在这一阶段,系统会暂时“忽略”句子节点,转而在篇章节点 (Vp)*与*实体节点 (Ve) 构成的二部图上进行计算。如果某个篇章包含某个实体,则它们之间存在连接边。
2. 核心计算公式:个性化 PageRank (PPR)
LinearRAG 采用 PPR 算法来评估图中每个节点(包括实体和篇章)的最终全局重要性得分 I(vi):
$$I(v_i) = (1 - d) + d \cdot \sum_{v_j \in B(v_i)} \frac{I(v_j)}{deg(v_j)}$$
- d (阻尼因子):通常设置为 0.85。它代表了分数在图中流动的比例。
- B(vi):指向当前节点
vi
的邻居节点集合。
- 若 vi 是篇章,则其邻居是该篇章包含的实体。
- 若 vi 是实体,则其邻居是提到该实体的所有篇章。
- deg(vj):邻居节点 vj 的出度(即与其连接的边的数量)。
- I(vj):邻居节点在当前轮次的重要性分数。
逻辑:一个节点的重要性取决于它的邻居。如果一个篇章包含了很多“高分实体”,那么这个篇章的分数就会提高;反之,如果一个实体出现在很多“高分篇章”里,它的地位也会上升。
3. 为什么这样计算更有效?
- 全局视角(Holistic Perspective):第一阶段的语义传播侧重于局部的语义联想(即“这个词能联想到那个词”),而第二阶段的 PPR 则是从图结构出发,识别出那些在整个逻辑网格中被最多关键线索“背书”的篇章。
- 抗噪声与单次推理:通过这种全局聚合,系统可以有效过滤掉虽然包含某些关键词但处于逻辑边缘的噪声篇章,并实现更精准的单次多跳检索(Single-pass Multi-hop Retrieval)。
- 线性扩展性:在稀疏的二部图上执行 PPR 迭代,其计算复杂度与篇章数量呈线性关系 (O(|P|)),这保证了在大规模语料库上的极高效率。
4. 最终产出:Top-k 排序
当 PPR 迭代稳定后,系统提取所有篇章节点的得分 I(v|v ∈ Vp),进行降序排列,并选出得分最高的前 k 个篇章作为最终的检索结果提供给大模型生成答案。
端到端性能的主要结果
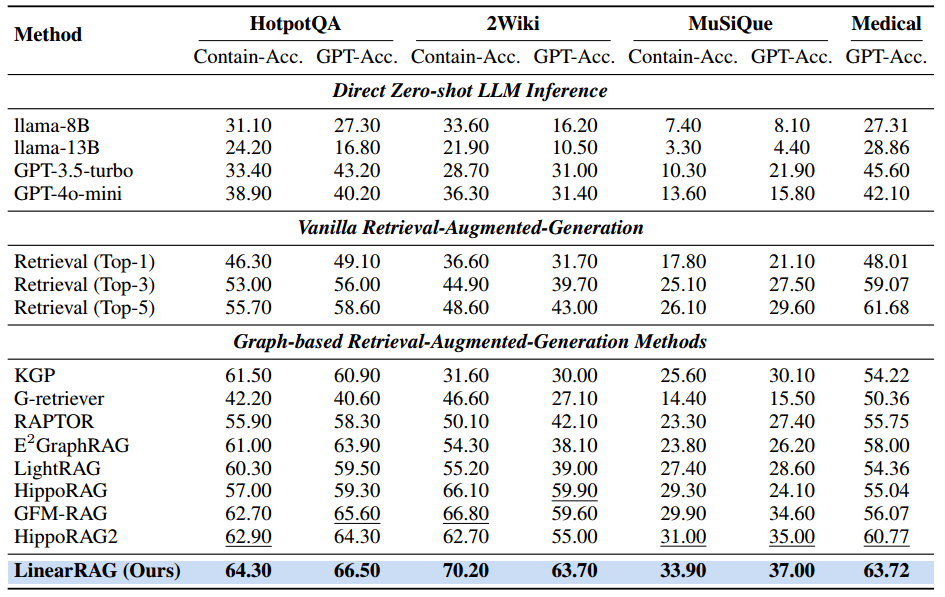
表 1 是 LinearRAG 论文中的核心实验结果表,展示了 LinearRAG 与各类基准模型在四个基准数据集上的性能对比。它从生成准确性的角度证明了 LinearRAG 在处理复杂、多跳(multi-hop)问题时的卓越能力。
以下是对该表的详细讲解:
1. 数据集与评估指标
该实验在四种具有挑战性的数据集上进行,主要考察模型的多跳推理能力:
- 数据集:包括三个通用的多跳问答数据集(HotpotQA、2Wiki、MuSiQue)和一个领域特定的 Medical(医疗) 数据集。
- 指标 1:Contain-Match Accuracy (Contain-Acc.):检查生成的回答中是否包含正确答案。
- 指标 2:GPT-Evaluation Accuracy (GPT-Acc.):利用大模型(如 GPT-4o-mini)来判断生成的答案是否在语义上与标准答案一致。对于答案较长的 Medical 数据集,仅使用此指标。
2. 对比的三大类模型
表 1 将所有方法分为三类,以便观察性能梯度的变化:
- 直接零样本 LLM 推理(Direct Zero-shot):如 Llama-3、GPT-3.5 等模型在不引用任何外部知识的情况下直接回答。实验证明其表现最差,例如 GPT-4o-mini 在 MuSiQue 上仅有 15.80% 的准确率。
- 传统 RAG(Vanilla RAG):使用简单的向量相似度检索 Top-k 个篇章。虽然比零样本强,但在多跳任务中容易由于只关注关键词匹配而丢失关键的逻辑链条。
- 图 RAG 方法(Graph-based RAG):包括 HippoRAG、LightRAG、HippoRAG2 等。这些方法通过建模结构化信息来增强推理。其中,HippoRAG2 在 LinearRAG 出现之前通常表现最佳。
3. LinearRAG 的表现与核心结论
在表中,加粗(Bold)表示最优结果,下划线(Underline)表示次优结果。
- 全面领先:LinearRAG 在所有数据集的所有指标上都取得了最优(加粗)的成绩,显著超过了现有的最强图 RAG 模型。
- 显著提升:在 2Wiki 数据集上,LinearRAG 的 GPT 评估准确率达到了 63.70%,比排名第二的基准模型高出约 3.80%。
- 性能稳健:与其他依赖“关系抽取(Relation Extraction)”的 GraphRAG 方法不同,LinearRAG 通过简化图结构(Tri-Graph)避免了错误关系引入的噪声,从而在不同难度的任务中表现更加稳健。
4. 实验背后的观察 (Observations)
作者通过表 1 得出了三个关键结论:
- RAG 是必须的:外部知识的引入能成倍提升 LLM 的回答准确性。
- 结构信息对多跳推理至关重要:建模文档间的结构依赖(图结构)可以捕捉到传统向量检索遗漏的逻辑关联。
- 图的质量决定上限:现有的 GraphRAG 方法受限于不稳定的关系抽取,而 LinearRAG 通过“语义桥接”和“全局聚合”实现了更精准、抗噪的检索。
实验设置(Experimental Setting)
在 LinearRAG 的研究中,实验设置(Experimental Setting) 的设计旨在全面验证该框架在处理复杂、多跳查询时的有效性、效率和扩展性。以下是根据来源对实验设置进行的详细解析:
1. 测试数据集 (Datasets)
实验选择了四个具有代表性且极具挑战性的数据集,涵盖了通用多跳推理和特定领域知识:
- 通用多跳问答数据集:
- HotpotQA:包含约 9.7 万个问答实例,要求模型从多个文档中合成信息。
- 2WikiMultiHopQA (2Wiki):包含 19.2 万个问题,测试模型在多篇维基百科文章间进行结构化推理的能力。
- MuSiQue:包含 2.5 万个问答对,要求进行 2-4 步的连续逻辑推理。
- 领域特定数据集:
- Medical:从结构化临床数据(NCCN 指南)中构建,涵盖事实检索、复杂推理、上下文总结和创意生成四类任务,共 4,076 个问题。
- 评估规模:为了公平对比,实验从每个数据集的验证集中随机抽取 1,000 个问题 进行测试。
2. 对比基准 (Baselines)
为了证明 LinearRAG 的优越性,实验将其与三类模型进行了对比:
- 零样本 LLM 推断 (Zero-shot):直接使用基础模型(如 LLaMA3-8B/13B、GPT-3.5-turbo 和 GPT-4o-mini)在没有外部知识的情况下回答问题。
- 传统 RAG (Vanilla RAG):采用基于语义相似度的文档检索(取 Top-1, 3, 5),并结合思维链(CoT)提示词。
- 前沿图 RAG 系统 (GraphRAG):包括构建层级树结构的 RAPTOR、提取三元组构建图的 LightRAG、HippoRAG、HippoRAG2、GFM-RAG,以及结合多种策略的 E2GraphRAG。
3. 评估指标 (Evaluation Metrics)
实验从两个维度评估模型性能:
- 端到端问答性能 (End-to-end QA):
- 包含匹配准确率 (Contain-Acc.):检查生成的回答中是否包含正确答案。
- GPT 评估准确率 (GPT-Acc.):利用 LLM 判断预测答案与标准答案在语义上是否一致(医疗数据集仅使用此项)。
- 检索质量 (Retrieval Quality):
- 上下文相关性 (Context Relevance):衡量问题与检索出的篇章之间的语义对齐程度。
- 证据召回率 (Evidence Recall):评估检索内容是否包含了回答问题所需的全部关键信息。
4. 实施细节 (Implementations)
为了确保对比的严谨性,所有实验均遵循以下统一标准:
- 嵌入模型:所有算法均使用
all-mpnet-base-v2作为统一的向量嵌入模型。 - 生成模型:所有 RAG 方法均采用
GPT-4o-mini进行答案生成和结果评估。 - 检索参数:检索结果统一取 Top-5。
- 硬件配置:实验在配备 NVIDIA GeForce RTX 4090 D (24GB VRAM) 和 Intel Xeon Gold 6426Y 处理器的服务器上运行。
效率与性能比较
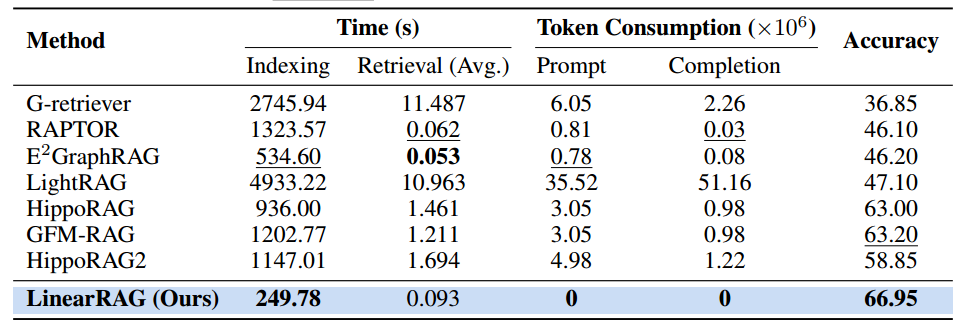
在 LinearRAG 的实验部分,效率分析(Efficiency Analysis,即实验问题 Q2) 是该框架的核心亮点之一。研究团队通过对比不同 GraphRAG 模型在 2WikiMultiHopQA 数据集上的 运行时间 和 Token 消耗,证明了 LinearRAG 在成本控制和速度上的压倒性优势。
以下是效率分析部分的详细讲解:
1. 索引阶段:零 Token 消耗与高速构建
在索引(图构建)阶段,LinearRAG 展现了极高的经济性和速度:
- 零 Token 成本:与 LightRAG 或 G-Retriever 等依赖大语言模型(LLM)进行关系抽取的系统不同,LinearRAG 采用轻量级的实体提取和语义链接,整个索引过程不消耗任何 LLM Token。
- 极短的构建时间:在 2Wiki 数据集上,LinearRAG 的索引时间仅为 249.78 秒,而最慢的 LightRAG 需要 4933.22 秒。来源指出,这种设计将索引时间缩短了 77% 以上。
- 线性可扩展性:其计算复杂度为 O(|P|⋅T)(其中 |P| 为篇章数,T 为平均长度),这意味着它能随着语料库规模的增加保持稳定的线性增长。
2. 检索阶段:极低延迟与高效算法
在在线检索阶段,LinearRAG 同样保持了领先地位:
- 平均检索时间最快:LinearRAG 的平均检索时间仅为 0.093 秒。相比之下,LightRAG 的检索延迟高达 10.963 秒,几乎是 LinearRAG 的 117 倍。
- 无检索 Token 消耗:检索过程同样不依赖 LLM 调用,避免了因处理大量检索内容而产生的额外 API 费用和延迟。
- 算法优化:通过使用稀疏矩阵相乘(SpMM)加速语义传播,以及在线性时间内完成的 个性化 PageRank (PPR) 迭代,确保了在大规模图结构下的高效运行。
3. 大规模语料库下的扩展性 (Large-scale Analysis)
为了验证其在现实世界大规模场景下的潜力,研究人员在 ATLAS-Wiki 数据集(5M 和 10M Token 级别)上进行了测试:
- 倍数级加速:在 10M Token 的子集上,LinearRAG 的索引速度比 RAPTOR 快 15.1 倍。
- 工业级应用潜力:由于完全消除了对 API 的依赖且具备 全阶段线性可扩展性(All-stage Linear Scalability),它被认为是目前最适合大规模企业级部署的方案。
消融实验 Ablation Study
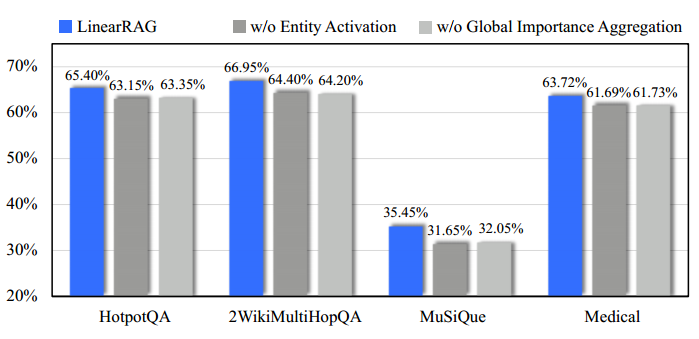
在 LinearRAG 的实验部分,消融实验(Ablation Study,即问题 Q3) 旨在通过有针对性地移除核心组件,来验证各模块对系统整体性能的具体贡献,。研究团队在四个不同的数据集上进行了系统性测试,重点考察了两个核心阶段。
以下是消融实验的详细分析:
1. 考察的两个核心模块
实验通过创建两个变体来分析性能损耗:
- 变体一:移除相关实体激活(w/o Entity Activation):
- 操作:该变体跳过了通过“局部语义桥接”传播激活分数的过程,直接使用从查询中提取的初始实体作为激活实体。
- 作用分析:第一阶段的意义在于通过语义相似度传播,识别出那些与查询没有直接字面匹配、但在推理链中起到“桥梁”作用的隐藏中间实体,。
- 变体二:移除全局重要性聚合(w/o Global Importance
Aggregation):
- 操作:该变体跳过了个性化 PageRank (PPR) 算法,直接根据第一阶段计算出的初始激活分数来检索文档,。
- 作用分析:第二阶段旨在从全局视角评估文档的重要性,通过在实体-篇章图上进行迭代,过滤掉噪声并强化逻辑链核心篇章的权重,。
2. 主要实验发现(Observation 7)
根据实验数据(如图 4 所示),研究团队得出了以下关键结论:
- 模块的不可或缺性:实验结果明确显示,每一个模块对于达到最优性能都是至关重要的。在所有四个数据集(HotpotQA、2Wiki、MuSiQue、Medical)上,完整版的 LinearRAG 性能均高于任何一个变体。
- 第一阶段的功能贡献:局部语义桥接通过发现隐藏的逻辑关系,解决了多跳问题中“线索中断”的问题。
- 第二阶段的功能贡献:全局重要性聚合通过 PPR 算法,从整体结构出发评估篇章的权重,显著提升了检索的精准度。
- 互补效应:这两个模块虽然功能不同,但具有极强的互补性,共同构成了 LinearRAG 既高效又准确的检索能力,。
3. 数据反映的趋势
在消融实验的图表中可以看到:
- 当移除任何一个阶段后,模型的准确率(GPT-Acc. 与 Contain-Acc. 的平均值)都会出现明显的下降。
- 这种下降在处理逻辑更加复杂的 MuSiQue 和 2Wiki 数据集时尤为显著,这证明了 “语义桥接”和“全局聚合”是处理多跳推理任务的基石,。
Medical(医疗)数据集上的检索质量评估结果
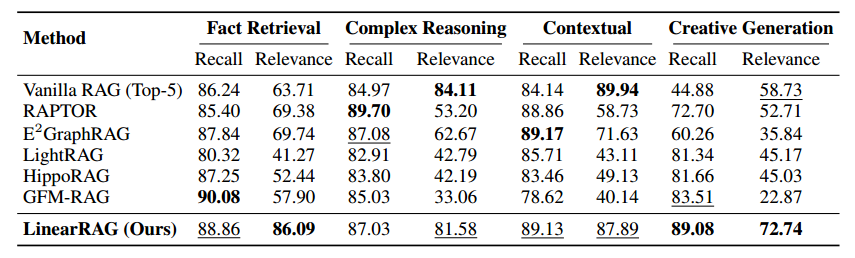
表 4 展示了不同基准模型在 Medical(医疗)数据集上针对四种任务维度的检索质量评估结果,。这些任务按难度递增分为:事实检索(Fact Retrieval)、复杂推理(Complex Reasoning)、上下文理解(Contextual Understanding)和创意生成(Creative Generation),。
以下是对该表核心发现的详细讲解:
1. 核心指标的含义
评估采用了两个关键的检索指标:
- 证据召回率 (Evidence Recall):衡量检索到的内容是否包含了回答问题所需的全部必要信息。
- 上下文相关性 (Context Relevance):衡量问题与检索出的篇章之间的语义对齐程度,即检索结果中“杂质”的多少。
2. LinearRAG 的卓越表现 (Obs. 9)
LinearRAG 在所有四个任务中几乎都占据了最优(加粗)或次优(下划线)的位置,展现了极强的综合能力,:
- 打破“召回-相关性”矛盾:通常提高召回率会引入更多无关文档(降低相关性),反之亦然。但 LinearRAG 成功实现了高召回与高相关的并存。
- 创意生成任务的跨越:在难度最高的“创意生成”任务中,LinearRAG 的召回率达到 89.08%,相关性达到 72.74%,均位居第一。相比之下,传统 RAG 虽然相关性尚可,但召回率仅为 44.88%。
3. 传统 GraphRAG 的“噪声瓶颈” (Obs. 8)
观察表中其他图检索模型(如 GFM-RAG、HippoRAG、LightRAG)可以发现一个共同问题:相关性大幅下降,。
- 高召回的代价:这些模型通过图结构增强了信息获取范围,例如 GFM-RAG 在创意生成任务中将召回率提升至 83.51%,但其相关性却暴跌至 22.87%,。
- 原因分析:这是因为它们依赖不稳定的关系抽取来构建图,导致图中充斥着错误的逻辑链接和冗余连接,从而在检索时带回了大量无关的干扰信息,,。