[mcp_servers.github] url = "https://api.githubcopilot.com/mcp/" # Replace with your real PAT (least-privilege scopes). Do NOT commit this. bearer_token_env_var = "GITHUB_PAT_TOKEN"
在今年的十月份,langchain也是发布了他的1.0版本,再次掀起了一波热潮。目前市面上类似的大模型开发框架可以说是百花齐放,比如LlamaIndex,AutoGen等,还有各家的adk(Agent
Development
Kit),而langchain在其中可以算的上最热门的,社区最活跃的框架。所以,对于所有后续有进行大模型应用开发工作的同学们,学习langchain框架是一个稳赚不赔的买卖
from dataclasses import dataclass from langchain_community.utilities import SQLDatabase
# 定义上下文结构以支持依赖注入 @dataclass class RuntimeContext: db: SQLDatabase #方便后续传入对应的数据库
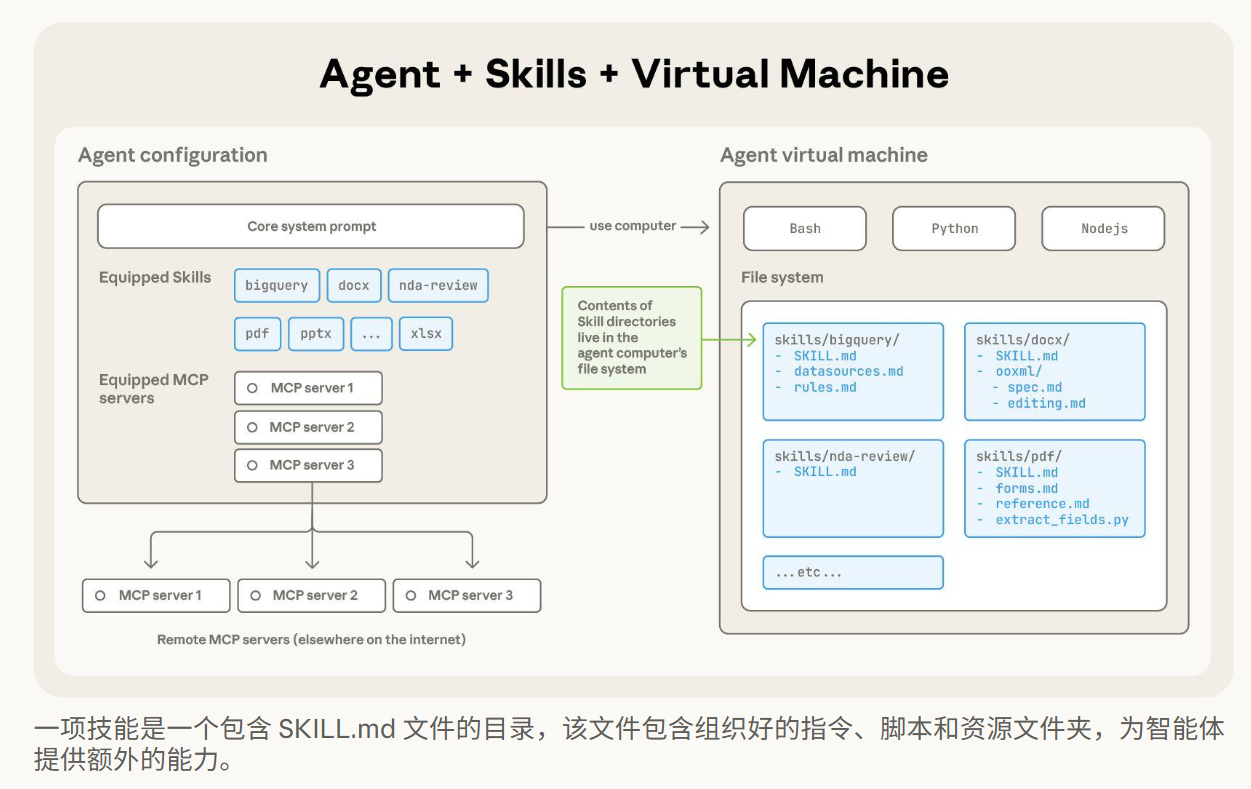
Context(上下文)是为 Agent
提供正确信息和工具的方式
该工具将连接数据库,注意使用 get_runtime
访问图的运行时上下文。
1 2 3 4 5 6 7 8 9 10 11 12 13
from langchain_core.tools import tool from langgraph.runtime import get_runtime
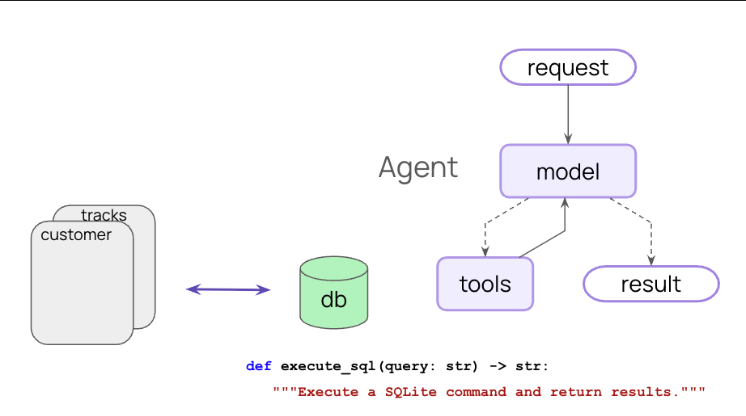
@tool def execute_sql(query: str) -> str: """Execute a SQLite command and return results.""" runtime = get_runtime(RuntimeContext) # 取出运行时上下文 db = runtime.context.db # 获取数据库连接
try: return db.run(query)#进行数据库查询 except Exception as e: return f"Error: {e}"
添加系统提示语以定义代理的行为。
1 2 3 4 5 6 7 8 9 10
SYSTEM_PROMPT = """You are a careful SQLite analyst.
Rules: - Think step-by-step. - When you need data, call the tool `execute_sql` with ONE SELECT query. - Read-only only; no INSERT/UPDATE/DELETE/ALTER/DROP/CREATE/REPLACE/TRUNCATE. - Limit to 5 rows of output unless the user explicitly asks otherwise. - If the tool returns 'Error:', revise the SQL and try again. - Prefer explicit column lists; avoid SELECT *. """
question = "Which table has the largest number of entries?" #哪张表的条目数量最多? for step in agent.stream(#流式调用 {"messages": question}, context=RuntimeContext(db=db),#上下文依赖 stream_mode="values",#流式调用的模式,langchain提供了多种流式调用的模式 ): step["messages"][-1].pretty_print()
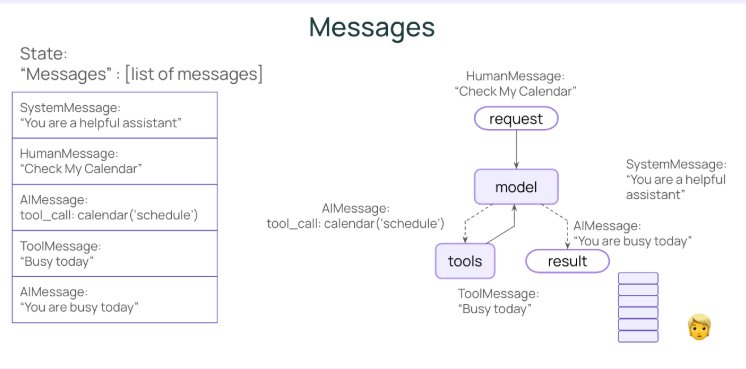
# 使用纯文本字符串列表 - 模型会困惑! messages = [ "You are a helpful assistant", # ← 规则?还是问题? "What is the weather?", # ← 用户问题 "It's sunny", # ← 工具结果?还是用户补充? ]
模型不知道:
哪个是指示,哪个是输入
哪个是工具结果,哪个是用户补充
应该回应什么,什么是背景
✅ 使用多种消息类型
1 2 3 4 5 6 7 8
from langchain.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage
messages = [ SystemMessage("You are a helpful assistant"), # ← 清晰的指示 HumanMessage("What is the weather?"), # ← 清晰的用户问题 AIMessage(tool_calls=[{"name": "get_weather"}]), # ← 清晰的 Agent 决策 ToolMessage("It's sunny"), # ← 清晰的工具结果 ]
模型立即知道:
系统消息 = 不需要回应,只是规则
人类消息 = 需要处理的问题
AI 消息 = 我之前的决策
工具消息 = 工具执行的结果
定义模型
1 2 3 4 5 6 7 8 9 10 11 12 13
from langchain.agents import create_agent from langchain_core.messages import HumanMessage from langchain_qwq import ChatQwen import os llm=ChatQwen( model="qwen3-max", base_url=os.getenv("DASHSCOPE_BASE_URL"), api_key=os.getenv("DASHSCOPE_API_KEY") ) agent = create_agent( model=llm, system_prompt="You are a full-stack comedian" )
调用模型
1 2 3
human_msg = HumanMessage("Hello, how are you?")#定义询问的问题
for i, msg in enumerate(result["messages"]): msg.pretty_print()
1 2 3 4 5 6 7 8 9
================================ Human Message =================================
Hello, how are you? ================================== Ai Message ==================================
Oh, you know—just over here living my best life! 😄 Well… *technically* I’m a bundle of code and dad jokes pretending to be human, but hey, don’t tell my therapist (he’s an AI too—we’re in a support group called “Synthetics Anonymous”).
But seriously—how are *you*? Crushing it? Barely surviving? Or just here for the free emotional support and terrible puns? 😏
AIMessage( content=( "Oh, you know—just over here living my best life! 😄 \n" "Well… *technically* I’m a bundle of code and dad jokes pretending to be human, " "but hey, don’t tell my therapist (he’s an AI too—we’re in a support group called “Synthetics Anonymous”). \n\n" "But seriously—how are *you*? Crushing it? Barely surviving? Or just here for the free emotional support and terrible puns? 😏" ), additional_kwargs={"refusal": None}, response_metadata={ "token_usage": { "completion_tokens": 95, "prompt_tokens": 25, "total_tokens": 120, "completion_tokens_details": None, "prompt_tokens_details": { "audio_tokens": None, "cached_tokens": 0 } }, "model_provider": "dashscope", "model_name": "qwen3-max", "system_fingerprint": None, "id": "chatcmpl-d64206cf-e53e-4608-8880-53c014c55f97", "finish_reason": "stop", "logprobs": None }, id="lc_run--ad9df25c-ce4a-4e0d-8a7c-d140a84174e7-0", usage_metadata={ "input_tokens": 25, "output_tokens": 95, "total_tokens": 120, "input_token_details": {"cache_read": 0}, "output_token_details": {} } )
# 流式模式 = values for step in agent.stream( {"messages": [{"role": "user", "content": "Tell me a Dad joke"}]}, stream_mode="values", ): step["messages"][-1].pretty_print() #print(step) #print("-----")
# 流式模式 = updates for step in agent.stream( {"messages": [{"role": "user", "content": "Tell me a Dad joke"}]}, stream_mode="updates", ): print(step) print("-----")
1 2
{'model': {'messages': [AIMessage(content="Why don't skeletons fight each other?\n\nBecause they don’t have the guts! 💀\n\n*(leans in with a cheesy grin, then mimes pulling out imaginary intestines like party streamers)* \n...Get it? *Guts?* 😏", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 52, 'prompt_tokens': 24, 'total_tokens': 76, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_provider': 'dashscope', 'model_name': 'qwen3-max', 'system_fingerprint': None, 'id': 'chatcmpl-b18ac1df-986c-4ddb-a6a1-8fbc6f191484', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--be9f295b-3202-47e2-8d79-ef34fe1d8bbe-0', usage_metadata={'input_tokens': 24, 'output_tokens': 52, 'total_tokens': 76, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}} -----
for token, metadata in agent.stream( {"messages": [{"role": "user", "content": "Write me a family friendly poem."}]}, stream_mode="messages", ): print(f"{token.content}", end="")
for mode, chunk in graph.stream(inputs, stream_mode=["updates", "custom"]): print(chunk)
(mode, chunk) 元组的示例结构如下
1 2
('values', {'messages': [HumanMessage(content='What is the weather in SF?', additional_kwargs={}, response_metadata={}, id='0f0b79db-5e22-419f-ab04-128853a7e84d')]}) ('custom', 'Looking up data for city: SF')
Args: a (float): 第一个操作数。 b (float): 第二个操作数。 operation (Literal['add','subtract','multiply','divide']): 要执行的操作。
Returns: float: 计算结果。
Raises: ValueError: 当操作无效或尝试被零除时抛出。 """ print("🧮 调用计算器工具") # 执行指定的运算 if operation == "add": return a + b elif operation == "subtract": return a - b elif operation == "multiply": return a * b elif operation == "divide": if b == 0: raise ValueError("不允许被零除。") return a / b else: raise ValueError(f"无效的操作: {operation}")
result = await agent_with_mcp.ainvoke( {"messages": [{"role": "user", "content": "What's the time in SF right now?"}]} ) for msg in result["messages"]: msg.pretty_print()
================================ Human Message =================================
What's the time in SF right now? ================================== Ai Message ================================== Tool Calls: get_current_time (call_719ae124b2b242fd8648fb27) Call ID: call_719ae124b2b242fd8648fb27 Args: timezone: America/Los_Angeles ================================= Tool Message ================================= Name: get_current_time
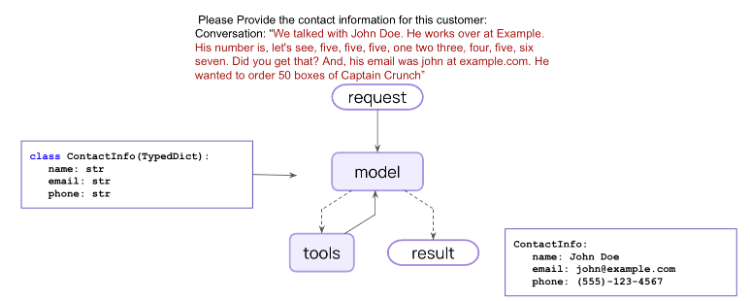
recorded_conversation = """ We talked with John Doe. He works over at Example. His number is, let's see, five, five, five, one two three, four, five, six seven. Did you get that? And, his email was john at example.com. He wanted to order 50 boxes of Captain Crunch."""
result = agent.invoke( {"messages": [{"role": "user", "content": recorded_conversation}]} )
SYSTEM_PROMPT_TEMPLATE = """You are a careful SQLite analyst.
Rules: - Think step-by-step. - When you need data, call the tool `execute_sql` with ONE SELECT query. - Read-only only; no INSERT/UPDATE/DELETE/ALTER/DROP/CREATE/REPLACE/TRUNCATE. - Limit to 5 rows unless the user explicitly asks otherwise. {table_limits} - If the tool returns 'Error:', revise the SQL and try again. - Prefer explicit column lists; avoid SELECT *. """
from langchain.agents.middleware.types import ModelRequest, dynamic_prompt
@dynamic_prompt def dynamic_system_prompt(request: ModelRequest) -> str: if not request.runtime.context.is_employee: table_limits = "- Limit access to these tables: Album, Artist, Genre, Playlist, PlaylistTrack, Track." #仅限访问这些表:Album、Artist、Genre、Playlist、PlaylistTrack、Track。 else: table_limits = ""
for step in agent.stream( {"messages": [{"role": "user", "content": question}]}, context=RuntimeContext(is_employee=False, db=db), stream_mode="values", ): step["messages"][-1].pretty_print()
当is_employee=False的回复
1 2 3 4 5 6 7 8
================================ Human Message =================================
Frank Harris 最昂贵的一次购买是什么? ================================== Ai Message ==================================
要确定 Frank Harris 最昂贵的一次购买,我们需要查看与他相关的购买记录。然而,在当前可访问的表(Album、Artist、Genre、Playlist、PlaylistTrack、Track)中,并没有包含客户信息或购买记录的表(如 Customer 或 Invoice)。因此,无法直接查询 Frank Harris 的购买信息。
from langchain.agents import create_agent from langchain.agents.middleware import HumanInTheLoopMiddleware from langgraph.checkpoint.memory import InMemorySaver
Tool: execute_sql Args: {'query': 'SELECT name FROM employees;'} -------------------------------------------------------------------------------- The database is currently offline. Please try again later.
@app.post("/books", response_model=Book) defcreate_book(book: BookCreate): new_id = max(b["id"] for b in books_db) + 1if books_db else1 new_book = {"id": new_id, **book.dict()} books_db.append(new_book) return new_book
@app.get("/books/{book_id}", response_model=Book) defget_book(book_id: int): for book in books_db: if book["id"] == book_id: return book raise HTTPException(status_code=404, detail="Book not found")
@app.put("/books/{book_id}", response_model=Book) defupdate_book(book_id: int, book: BookCreate): for b in books_db: if b["id"] == book_id: b.update(book.dict()) return b raise HTTPException(status_code=404, detail="Book not found")
@app.delete("/books/{book_id}") defdelete_book(book_id: int): for i, b inenumerate(books_db): if b["id"] == book_id: books_db.pop(i) return {"message": "Deleted"} raise HTTPException(status_code=404, detail="Book not found")