模型微调——LoRA
为什么要微调
预训练大模型在海量通用语料上学到的知识,在垂直场景(医疗、法律、零售客服等)里往往“泛而浅”。
从零训练一个同等规模的大模型成本极高(千卡周级别),而微调只需在已有权重上做小步调整,算力/数据量都指数级下降。
什么是全量微调

全量微调(full fine-tuning)通俗来说,对于参数的每一个权重,都要学习一个新的值(或者偏移量),更新所有 Transformer 层里的权重矩阵(包括 embedding、attention、FFN),这样的开销是很大的。
什么是LoRA
LoRA(Low-Rank Adaptation,低秩适配)是一种参数高效微调(PEFT)技术,核心目的: “冻结大模型 99 % 以上原始权重,只额外训练极少量低秩矩阵,就能让模型在下游任务上达到近似全量微调的效果。”
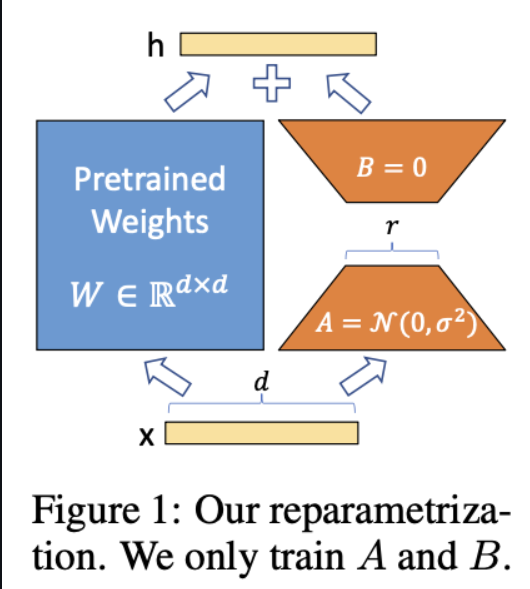
通俗来说,通过学习两个低秩的矩阵,来近似于完整的矩阵,如图,W=A*B,矩阵相乘
在实际应用中,LoRA可以直接和transformer的FFN层(线性层)对齐
Transformer 模型的核心是注意力机制,其中涉及到 Query, Key, Value 的计算,这些都是线性变换。
在标准的注意力机制中,计算公式为:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
其中 Q, K, V 的计算为:
Q = XQWQ, K = XKWK, V = XVWV
XQ, XK, XV 的输入可以相同,也可以不同。例如,在 Cross-Attention 中,解码器的隐藏状态作为 XQ,编码器的输出作为 XK 和 XV。
LoRA 可以应用到 WQ, WK, WV 上,采用与线性层类似的方式。
为什么要用lora
首先要理解低秩:秩可以理解成一个矩阵所代表的信息,低秩矩阵,便是带有少量信息的矩阵,当然这样的矩阵计算效率是更高的,
在全量微调中,由于训练一个完整的矩阵开销是非常大的;在lora中就通过训练低秩矩阵,来近似模型权重更新的效果
若模型参数比较小,使用冻结部分参数或全量微调的方式,往往更好
初学者不禁会思考,这样难道不会损失信息导致大模型的性能变差吗?但是,实验下来效果还是不错的,通过牺牲一点性能,来换取开销的大幅度减少
LoRA 原文实验 在 GPT-3 175 B 上,仅用 rank 4 的 LoRA 就能在全量微调 99 % 参数量的情况下,保持 97 % 的下游指标。
什么是QLoRA
QLoRA(Quantized Low-Rank Adaptation,量化低秩适应)是 LoRA 的“极致省内存”版本。它把 LoRA 的“低秩增量”思路再往前推一步:先把整个底座模型权重压到 4-bit,再在上面做 LoRA 微调。
QLoRA 是另一个热门术语,它与 LoRA 之间的唯一区别在于首字母“Q”,代表“量化(quantized)”。“量化”一词指的是用来减少存储神经元权重的比特数。
例如,神经网络的权重通常以浮点数表示,每个权重需要 32 位。量化的思想是将神经网络的权重压缩为更低的精度,而不会显著损失模型性能或产生重大影响。因此,不再使用 32 位,而是可以舍弃部分比特,例如只用 16 位。
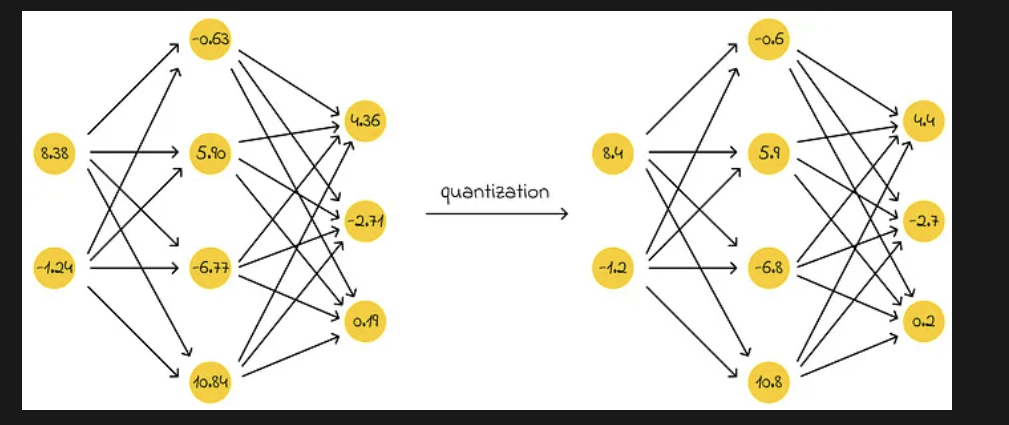
微调工具的介绍
unsloth
unsloth是一个专为大型语言模型(LLM)设计的动态量化与微调框架,旨在提高微调效率并减少显存占用,因此主要用于单机单卡的模型微调。
值得一提的是,Unsloth动态量化模型:https://unsloth.ai/blog/dynamic-v2
Unsloth的动态量化方法,特别是其最新的Dynamic 2.0版本,旨在在尽量减少性能损失的同时显著压缩大型语言模型(LLMs)的体积。对于Qwen3模型,尤其是4-bit动态量化版本,现有的评测显示其性能下降非常有限,甚至在某些任务上与原始模型相当。
Unsloth 的「动态量化」可以一句话概括为: “按层、按敏感度自动决定每块权重到底用 2.5 / 3.5 / 4 / 6 / 8 / 32 bit 的精细化量化策略,而不是一股脑全量化到 4 bit。”
这也使得Unsloth的动态量化模型成为个人配置下的最佳微调工具。
不过需要注意的是,动态量化由利也有弊,其好处在于可以极大程度压缩模型运行所需占用的显存大小,同时几乎不损失性能,但问题在于动态量化的模型,无论是推理还是微调,只能单卡运行,这就使得其吞吐量有限,无法在一台物理机上实现多GPU并行从而扩大吞吐量。
LLaMA Factory
hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
LLaMA Factory 是一个简单易用且高效的大型语言模型训练与微调平台。通过它,用户可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
LLaMA Factory 提供了API Server 和一站式 WebUI Board,方便企业进行模型的管理和部署。适合不会写代码或代码基础比较弱的同学快速上手进行微调。
其他
ms-SWIFT GitHub项目主页:https://github.com/modelscope/swift
ColossalAI GitHub项目主页:https://github.com/hpcaitech/ColossalAI
除此之外,也可以借助更加底层的库,如peft、LoRA、transformer等实现高效微调。
模型性能评估框架
EvalScope
项目地址: https://github.com/modelscope/evalscope
EvalScope 是由阿里巴巴魔搭社区(ModelScope)推出的一款开源模型评估框架,旨在为大语言 模型(LLM)和多模态模型提供统一、系统化的性能评估方案。该框架具备高度的自动化和可扩展性, 适用于研究机构、工业界以及模型开发者在模型验证与性能对比场景中的广泛需求。
可视化框架
wandb
Weights & Biases(简称 wandb) 是一个专为机器学习 / 深度学习设计的 云端实验管理、可视化与协作平台。它帮你把“训练过程中发生了什么”全部自动化地记录下来,并以网页仪表盘的形式实时展示,省去你手动保存日志、画图、整理表格的麻烦。
wandb官网: https://wandb.ai/site
swanlab
SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,提供了一个跟踪、记录、比较、和协作实验的平台。
SwanLab 面向人工智能研究者,设计了友好的Python API 和漂亮的UI界面,并提供训练可视化、自动日志记录、超参数记录、实验对比、多人协同等功能。在SwanLab上,研究者能基于直观的可视化图表发现训练问题,对比多个实验找到研究灵感,并通过在线网页的分享与基于组织的多人协同训练,打破团队沟通的壁垒,提高组织训练效率。
SwanLab官方文档 | 先进的AI团队协作与模型创新引擎
构造微调数据集
为什么要构造微调数据集
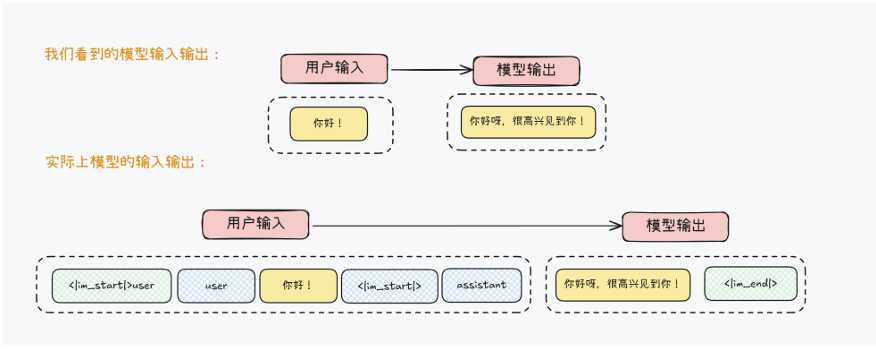
其中 <∣im_start∣>
代表文本开始,而user则代表消息身份,用于构建多轮对话,而
而模型其实是通过这样一组特殊字符标记来规范自己的行为,判断当前消息类型,以及通过输出特殊标记来确定停止时间。对于绝大多数模型,我们可以在模型的tokenizer_config.json中看到完整的特殊标记符(以及系统提示词模板):
而在实际微调过程中,我们都知道需要有监督的数据集、也就是需要输入QA对来进行微调。以著名的alpaca_zh中文微调数据集来说,其基本格式如下:

就可以表示为下列json格式数据集:
1 | json{ "instruction": "", "input": "输入:你好。", "output": "输出:你好,有什么可以帮到你的?"} |
而在真实的微调过程中,如果是针对Qwen3进行微调,微调脚本会将这条数据集(无论什么格式)转化为如下格式:
1 | xml<im_start|>user\n你好<im_end|>\n<im_start|>assistant\n你好,有什么可以帮到你的?<im_end|> |
而在实际训练过程中,模型就会根据assistant前的内容,学习assistant后面的输出内容。
因此我们要在下载数据集后,进行微调前,对数据集进行预处理,接下来引出构造数据集的几种场景
带有系统提示微调数据集格式
在很多场景下,我们还会发现一些带有instruction字段的微调数据集,那instruction字段是如何带入到微调过程中的呢?
答案非常简单,还是依靠特殊字符。例如有一个对话内容如下:
1 | - 系统提示词(instruction):你是一名助人为乐的助手。 |
此时模型的输入和输出如下:
1 | <lim_start|>system你是一名助人为乐的助手。</im_end> |
即会通过<lim_start|>system…<lim_end|>来标记系统提示词。实际进行微调时,模型会根据assistant为界,学习assistant之前的文本输入情况下应该如何输出。
带Function calling微调数据集格式
更进一步的,如果对话过程中带入了Function calling,此时首先模型会读取提前准备好的tool schema(也可能是自动生成的,例如MCP即可自动创建tool schema):
1 | { |
而假设我们的对话内容如下:
1 | - 系统提示词(instruction):你是一名助人为乐的助手。当用户查询天气的时候,请调用get_weather函数进行天气信息查询。 |
此时回复内容就是一条Function call message
而此时模型真实的输入和输出内容如下:
1 | <|im_start|>system |
接下来在进行训练时,模型同样根据assistant前的内容,学习assistant后面的输出内容。不过需要注意的是,由于高效微调调整的参数量较少,因此只能优化模型的Function calling能力,并不能从无到有让模型学会Function calling。
带有思考过程的微调数据集结构
而如果是带有思考链,则一个简单的问答数据如下:

- 系统提示词(instruction):你是一名助人为乐的助手。
- 用户输入(input):你好,好久不见。
- 助手回复(output):好的,用户发来“你好,好久不见!”,我需要回应。首先,用户可能希望得到亲切的回应,所以应该用友好的语气。/n是的呀,好久不见,最近有什么有趣的事情要和我分享么?
此时模型真实的内部输入和输出结果如下:
1 | <lim_start|>system |
模型同样根据assistant前的内容,学习assistant后面的输出内容。也就是说,所谓的思考过程,本质上其实是一种文本响应格式,通过模型训练而来。
混合推理模型构造微调数据集基本方法
在了解了微调数据集结构背后的基本原理后,接下来的问题是应该如何构造微调数据集呢?
一般来说我们可以在huggingface、ModelScope或llama- factory中挑选合适的数据集,并根据实际情况进行组装。
例如围绕Qwen3模型的高效微调,为了确保其仍然保留混合推理能力,我们可以考虑在微调数据集中加入如普通对话数据集FineTome,以及带有推理字段的数学类数据集OpenMathReasoning,并围绕这两个数据集进行拼接,从而在确保能提升模型的数学能力的同时,保留非推理的功能。
同时还需要在持续微调训练过程中不断调整COT数学数据集和普通文本问答数据集之间的配比,以确保模型能够在提升数学能力的同时,保留混合推理的性能。
Qwen3 的「混合推理能力」= 在同一个模型里内置两套“大脑”: • 快思考(非思考模式):轻量算力、秒级响应,适合简单问答; • 慢思考(思考模式):多步链式推理、深度推敲,适合复杂逻辑、数学、代码。 系统会自动或按用户指令在两种模式之间 动态切换,从而 既省算力又保证难题精度。
微调的基本流程
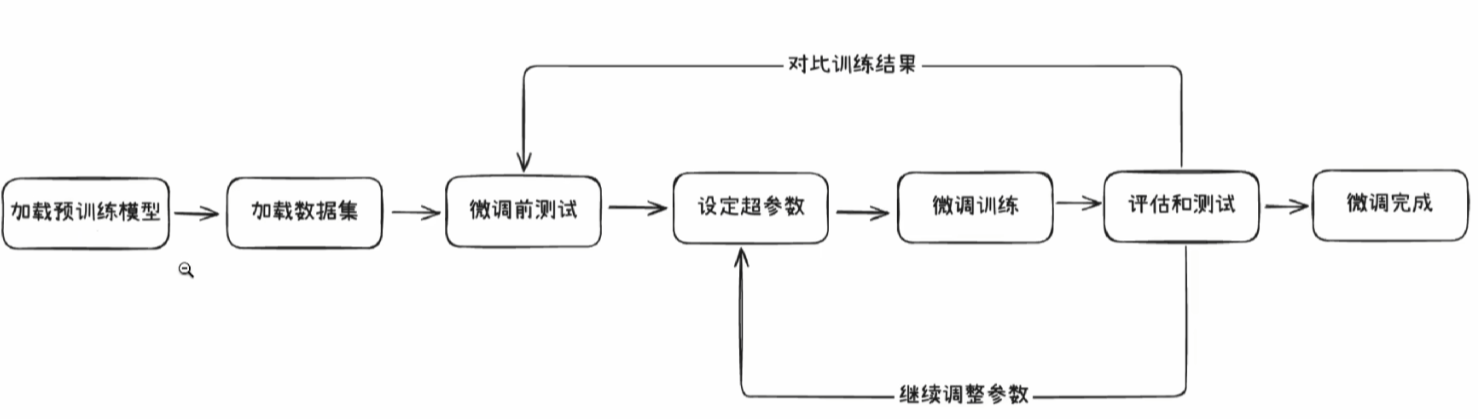
环境配置
安装Unsloth
1 | pip install --upgrade --force-reinstall --no-cache-dir unsloth unsloth_zoo |
安装Qwen3-8B-unsloth-bnb-4bit
1 | modelscope download --model unsloth/Qwen3-8B-unsloth-bnb-4bit --local_dir /workspace/qwen3-8b |
1 | #模型下载 |
unsloth/Qwen3-8B-unsloth-bnb-4bit 这个模型它是 专门为Unsloth微调框架优化过的4bit量化版本
原始 Qwen3-8B(FP16)需要约 22GB 显存,而 4bit 量化后仅需 6GB 左右
只要显存允许,原始 FP16/BF16 模型也可以用 Unsloth 做 4-bit LoRA(即 QLoRA)微调;官方预量化 4-bit 模型只是帮你把“量化”这一步提前做完了,二者本质相同。
Unsloth 的两种用法示例
场景 代码片段 备注 A. 用官方已量化好的 4-bit 权重 model_name="unsloth/Qwen3-8B-bnb-4bit"显卡 6 GB 就能跑,省去自己量化 B. 用原始 FP16 权重并现场 4-bit 量化 model_name="Qwen/Qwen3-8B"+load_in_4bit=True显卡仍需 6 GB,显存占用与 A 相同
2
3
4
5
6
7
8
# 两种写法效果等价
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="Qwen/Qwen3-8B", # 原始权重
load_in_4bit=True, # 现场量化到 4-bit
max_seq_length=2048,
)
安装EvalScope
1 | pip install evalscope |
安装wandb
wandb官网: https://wandb.ai/site
安装wandb:
1 | pip install wandb |
与其类似,一个开源、现代化设计的深度学习训练跟踪与可视化工具
参考资料
DIY你的AI梦中情人?Qwen3微调手把手教你!_哔哩哔哩_bilibili
通俗易懂理解全量微调和LoRA微调_哔哩哔哩_bilibili
3.四大微调框架及微调硬件环境介绍_哔哩哔哩_bilibili