简介
今天尝试使用hugging的transformer库跑通litert-community/DeepSeek-R1-Distill-Qwen-1.5B
· Hugging Face
Qwen-1.5B 基底 :它使用了阿里云开源的
Qwen2.5-1.5B 作为基础架构,参数量只有 15 亿(1.5
Billion),天生体积小、运行速度快。
DeepSeek-R1 蒸馏 :DeepSeek 把他们那个 6710
亿参数、拥有强大推理思维能力的巨型模型(DeepSeek-R1)所产生的思维链(Chain
of Thought)数据和推理样本 ,喂给了这个 1.5B 的小模型。
核心能力 :这意味着它虽然只有 15
亿参数,却继承了 DeepSeek-R1 的“思考”习惯(会在
<think>
标签内进行自我纠错、逻辑推理) ,在数学、代码和逻辑推理上,性能远超普通的
1.5B 级别模型。
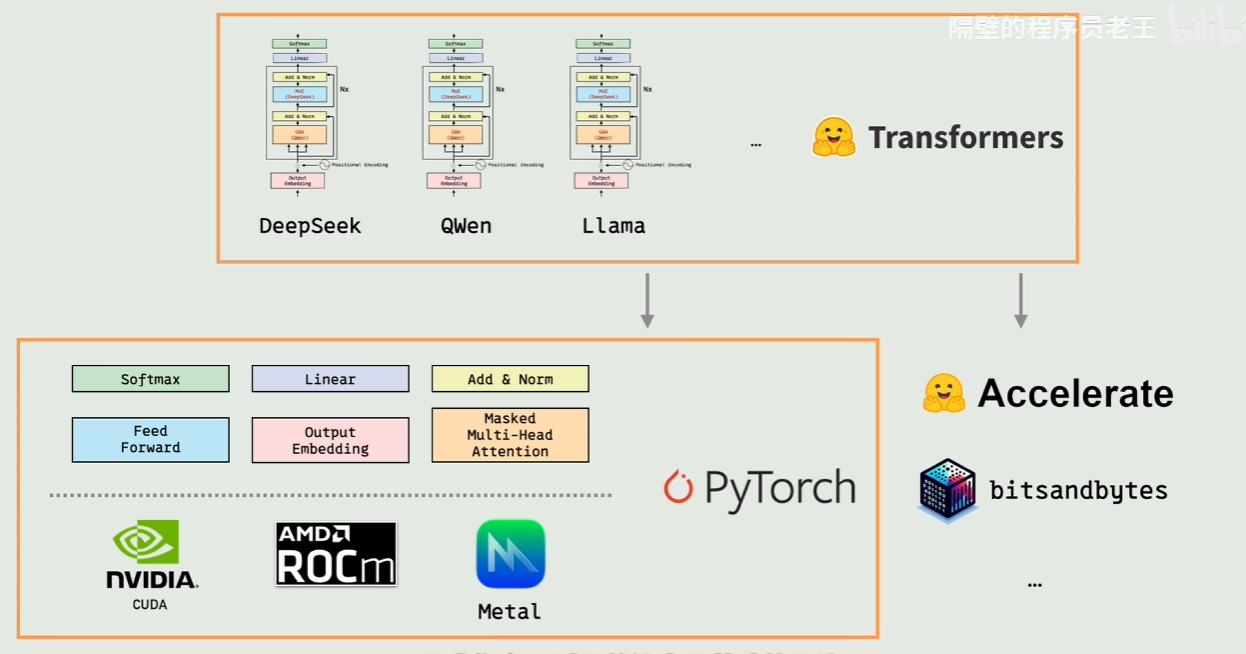
PyTorch(底层深度学习框架)
角色 :通用数学和张量(Tensor)计算库,专门为深度学习设计。干什么 :它提供最基础的算子。比如图下半部分看到的
Softmax、Linear(全连接层)、矩阵乘法、梯度反向传播,以及直接对接显卡硬件(NVIDIA
CUDA、AMD ROCm、Apple Metal)的驱动支持。特点 :它本身不知道 什么是大语言模型,什么是
Llama 或 DeepSeek。它只知道如何高效地在 GPU 上做矩阵加减乘除。
Transformers 库(上层模型生态库)
角色 :由 Hugging Face 开发的、专为 Transformer
架构模型定制的高级封装库 。干什么 :它把 PyTorch
提供的基础算子(Linear、Softmax
等)拼接起来,组装成一个个具体的经典模型结构(如
DeepSeek、Qwen、Llama)。特点 :它让你不需要从零去写注意力机制(Attention)的数学公式,直接通过几行代码(如
AutoModelForCausalLM.from_pretrained('deepseek-ai/DeepSeek-R1'))就能把整个模型跑起来。
image-20260522175239547
下载模型
配置环境
1 2 uv add transformer huggingface_hub uv add torch torchvision torchaudio --index https://download.pytorch.org/whl/cu128
1 2 3 4 5 6 7 8 9 10 11 12 13 import os # 1. 必须最先设置环境变量(在 import huggingface_hub 之前) os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 2. 然后再导入 Hugging Face 的下载工具 from huggingface_hub import snapshot_download # 3. 最后执行下载 snapshot_download( repo_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B", local_dir="models/DeepSeek-R1-Distill-Qwen-1.5B" )
加载模型
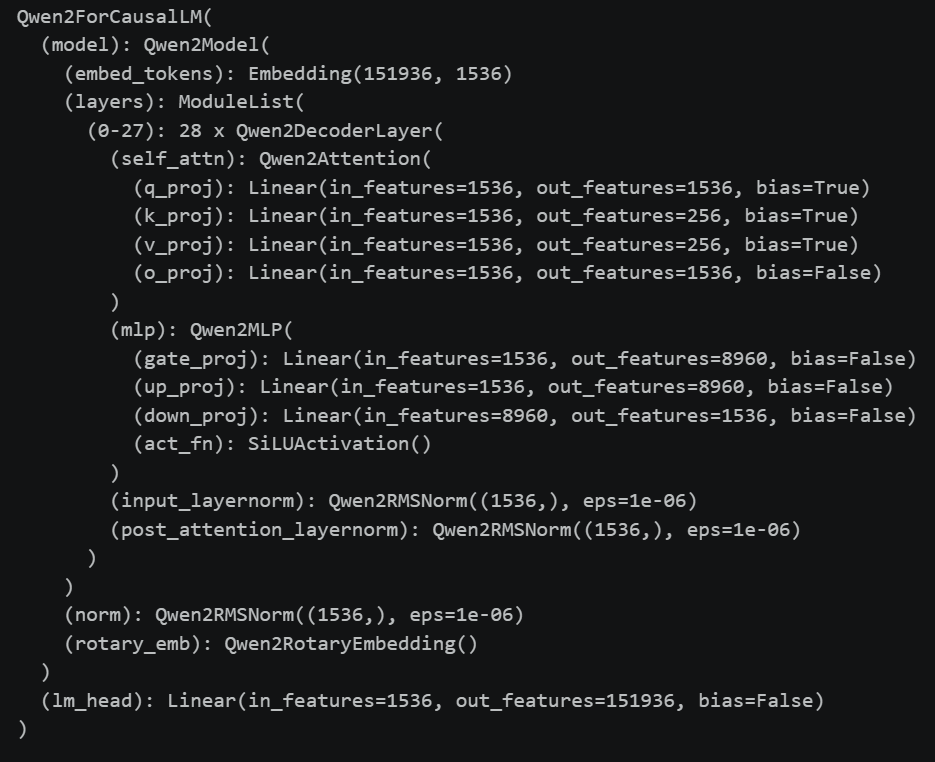
先查看模型文件夹下的config.json文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 { // 模型的架构类名,告诉 Transformers 库在代码中应该用哪个具体的类来实例化这个模型 "architectures": [ "Qwen2ForCausalLM" ], // 在注意力机制(Attention)层中 Dropout 的比例。0.0 代表不随机丢弃神经元节点 "attention_dropout": 0.0, // 序列开始特殊标记(BOS, Begin of Sequence)的 ID 编码 "bos_token_id": 151643, // 序列结束特殊标记(EOS, End of Sequence)的 ID 编码。模型吐出这个 ID 时就会停止生成 "eos_token_id": 151643, // 隐藏层(前馈神经网络)中使用的激活函数类型。这里采用的是 SiLU(Sigmoid Linear Unit) "hidden_act": "silu", // 隐藏层的维度(模型的宽度)。即每个 Token 进入模型内部后转换成的向量长度(1536维) "hidden_size": 1536, // 权重参数初始化时的标准差。模型刚创建、未训练时,权重会在这个范围的随机正态分布中生成 "initializer_range": 0.02, // 前馈神经网络(FFN/MLP)内部升维后的中间层维度。向量会在这里从 1536 临时扩大到 8960 维再缩回 "intermediate_size": 8960, // 模型支持的最大位置编码长度。也就是该模型的理论最大上下文窗口(128K Context Window) "max_position_embeddings": 131072, // 启用滑动窗口注意力机制(Sliding Window Attention)的最大层数。这里前 21 层会受到相关策略影响 "max_window_layers": 21, // 模型的类型基础名称,这里注册为千问2代架构(qwen2) "model_type": "qwen2", // 多头注意力机制(MHA)中 Query(查询)头的总数量 "num_attention_heads": 12, // 模型的总层数(深度)。数据需要连续穿过 28 个 Transformer 块(Block) "num_hidden_layers": 28, // 分组查询注意力(GQA)中 Key 和 Value 头的数量。 // 12 个 Q 头共享 2 个 KV 头,能大幅减少推理时的 KV Cache 显存占用 "num_key_value_heads": 2, // RMSNorm(均方根归一化)层为了防止分母为 0 而引入的极小常量值($\epsilon$) "rms_norm_eps": 1e-06, // 旋转位置编码(RoPE)的底数基频($\theta$)。控制位置编码在长文本下的外推和衰减敏感度 "rope_theta": 10000, // 当启用滑动窗口注意力时,窗口的具体大小(限制只能看到过去 4096 个 Token) "sliding_window": 4096, // 是否绑定输入和输出的嵌入层权重。false 代表输入 Embedding 和输出 Linear 层的参数各自独立 "tie_word_embeddings": false, // 模型训练和默认保存时的数据精度类型。bfloat16 代表 16位脑浮点数,兼顾范围与精度 "torch_dtype": "bfloat16", // 导出该配置文件时,所使用的官方 Hugging Face Transformers 库的版本号 "transformers_version": "4.44.0", // 是否默认开启键值缓存(KV Cache)。开启后可以避免重复计算历史 Token,实现流式快速生成 "use_cache": true, // 是否启用多模态旋转位置编码(Multimodal RoPE),常用于处理视觉等多模态输入。这里为 false "use_mrope": false, // 是否在全局强制启用滑动窗口注意力机制。这里为 false,说明默认使用全量的全局注意力 "use_sliding_window": false, // 词表的大小。代表模型一共认识 151,936 个不同的字、词或特殊符号 "vocab_size": 151936 }
在这个文件里:
"architectures": ["Qwen2ForCausalLM"]"model_type": "qwen2"
说明这个模型底层架构为qwen2因果解码器
image-20260523110036536
1 2 3 4 5 6 7 from transformers import Qwen2ForCausalLM model = Qwen2ForCausalLM.from_pretrained("models/DeepSeek-R1-Distill-Qwen-1.5B") model 或 from transformers import AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained("models/DeepSeek-R1-Distill-Qwen-1.5B") model
下面的AutoModelForCausalLM可以通过读取config文件,使用正确的架构加载模型
什么是ForCausalLM(因果语言模型)
ForCausalLM(因果语言模型)——
只能看左边,猜右边这种模型在训练和推理时,就像是在看一部正在播放的电影 。
通俗例子:
假设训练数据是一句话:“我 喜欢 吃 南京 盐水鸭”
当模型处理到 “吃” 这个字时:
它能看到什么 :“我 喜欢”(左边的历史信息,它100%看得见)。它被隐藏了什么 :[南京 盐水鸭](右边的未来信息。模型被戴上了特殊的“向后看”的眼罩,技术上叫因果掩码 ,强行把右边的字遮住)。它的任务 :根据
“我 喜欢 吃”,去猜后面接 “南京”
的概率是多少。
为什么必须隐藏后面的? 因为如果训练时不把右边的
“南京 盐水鸭”
挡住,模型就会直接去偷看标准答案,这就成了“作弊”。这样训练出来的模型在实际聊天时,由于没有未来可以偷看,就会彻底废掉。
这就对应了你说的“一整句话都能看到”的模型。它在训练时不需要戴单向眼罩。
通俗例子:
同样是这句话:“我 喜欢 吃 南京 盐水鸭”
AI
老师在训练它时,直接把整句话拍在它面前,但是用黑笔随机涂黑(Mask)了一个词:
输入给模型的 :“我 喜欢 吃 [ ❌ ] 盐水鸭”它能看到什么 :它能同时看到左边的
“我 喜欢 吃” 和右边的
“盐水鸭”。整句话的上下文它尽收眼底。它的任务 :像做高考完形填空 一样,结合两边的线索,推测被涂黑的
[ ❌ ] 里面有高概率是 “南京”。
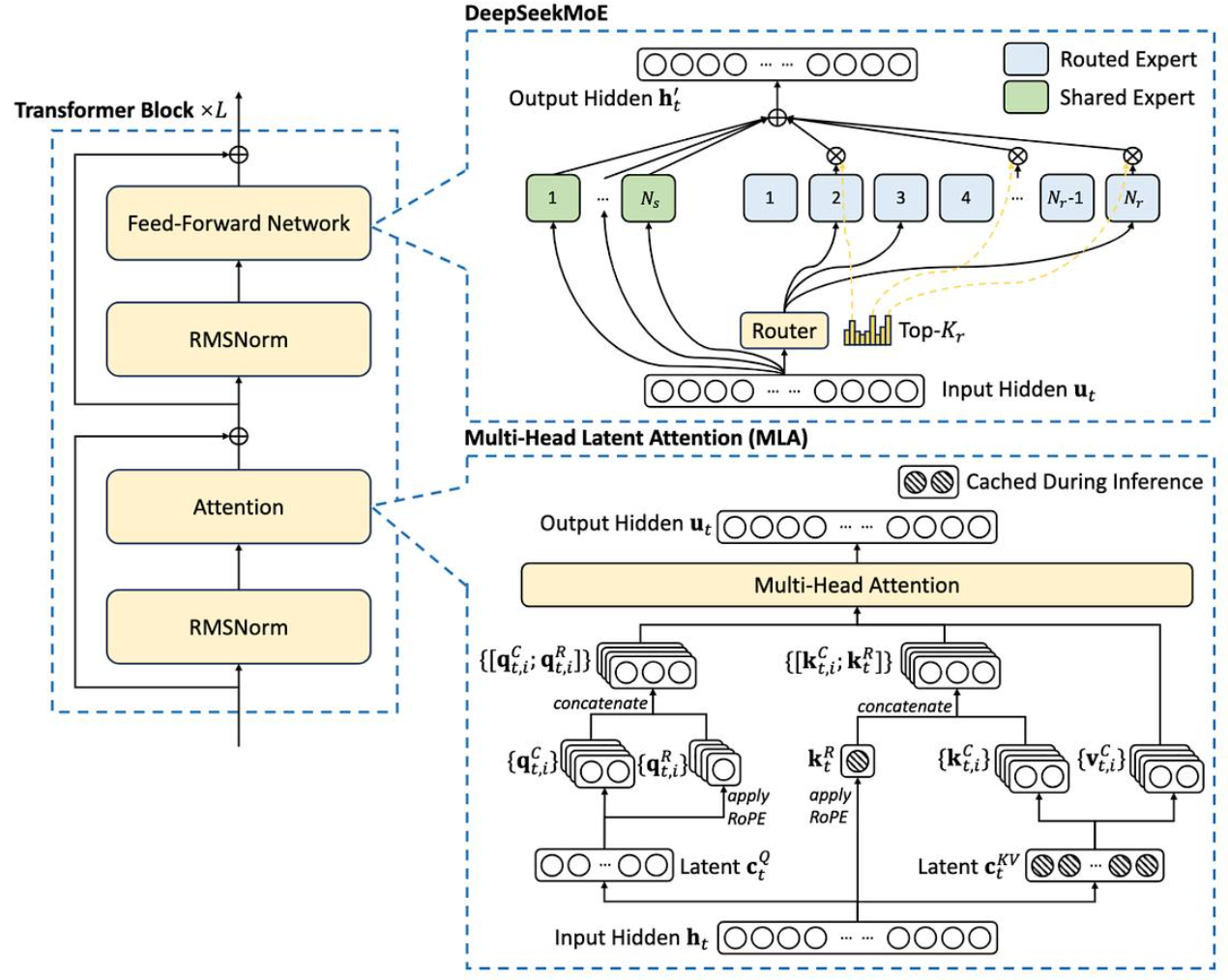
qwen与deepseek架构的区别
image-20260523100747237
image-20260523100939383
区别一:前馈网络(FFN)的“大一统”
vs “MoE 混合专家”
这是两家最本质的区别。
Qwen(Dense 稠密流派) : Qwen2.5-72B 采用的是标准的
Dense 结构。这意味着无论是算 1+1=
这种简单的算术题,还是写复杂的 Linux
内核代码,模型在每一层里的前馈网络(FFN)都是全员上阵 。720亿参数全部参与计算。
优缺点 :对硬件非常友好,算子成熟,但在参数量极大时,计算成本(算力消耗)呈线性飙升。 DeepSeek(MoE 专家流派) : DeepSeek-V3 采用了独创的
DeepSeekMoE 架构。它把原本一个巨大的 FFN 拆分成了
1个共享专家(Shared Expert) 和
256个路由专家(Routed Experts) 。
独特设计 :当一个 Token
传过来时,共享专家永远参与计算(抓取全局共性知识),而路由专家中只有最对口的
2 个 会被激活(抓取垂直专业知识)。恐怖的性价比 :DeepSeek-V3 的总参数量高达
6710亿(671B) ,但因为 MoE 的存在,每个 Token
进来时实际上只激活了 370亿(37B)
参数。这就是为什么它能用极低的算力成本,抗衡甚至超越其他几千亿规模的稠密模型。
区别二:注意力机制的“GQA”
vs “MLA(低秩多头注意力)”
在处理上下文和长文本记忆(KV
Cache)时,两家拿出了不同的看家本领。
Qwen(采用 GQA) : 正如我们在它的
config.json 里看到的,Qwen 采用的是
GQA(Grouped-Query Attention) 。它让多个 Query
头共用一组 KV 头。这在 2024~2026
年是行业标准设计,已经能把显存占用砍掉一大截。DeepSeek(独创 MLA) : DeepSeek 觉得 GQA
还不够省。他们发明了 MLA(Multi-head Latent
Attention,低秩多头注意力机制) 。
硬核原理 :传统的 GQA 随着上下文变长,显存里的 KV
缓存依然会线性增加。而 MLA 在计算注意力时,通过矩阵低秩分解(Low-rank
Compression)技术,把原本巨大的 KV
矩阵压缩成了一个极小的“特征向量”(Latent
Vector)存进显存里。在真正计算的一瞬间,再在显存里动态把它解压放大恢复出来。效果 :DeepSeek-V3 的 MLA 技术,让它的 KV
Cache 显存占用直接暴降了 93% 。这意味着同样的显卡硬件,DeepSeek
可以容纳超出 Qwen 数倍的并发量(Batch Size)或更长的上下文交互。
加载分词器
1 2 3 from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("models/DeepSeek-R1-Distill-Qwen-1.5B") tokenizer
可以查看models-R1-Distill-Qwen-1.5B.json
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 { "model": { // 分词器(Tokenizer)采用的核心算法。 // "BPE" 代表 Byte-Pair Encoding(字节对编码),是目前大模型(如 GPT、Llama、Qwen)最主流的分词算法 "type": "BPE", // 在分词阶段随机丢弃 Token 的比例(用于某些分词器的训练或正则化)。 // null 代表关闭该功能,确保分词结果是完全确定且唯一的 "dropout": null, // 未知词标记(Unknown Token)。当遇到词表里完全不认识的字符时,会用这个符号代替。 // null 代表没有设置或不需要(在现代 BPE 分词器中,通常通过字节回退机制来彻底消灭未知词) "unk_token": null, // 持续子词前缀。如果一个词被切碎了,后续的碎片可以用这个前缀来标记它们属于同一个词。 // 空字符串 "" 代表不显式添加前缀(Qwen2/Llama 通常通过在 Token 内部保留空格空间来处理词边界) "continuing_subword_prefix": "", // 词尾后缀。用来标记一个分词片段是一个完整单词的结尾。 // 空字符串 "" 代表不使用特定的词尾后缀符号 "end_of_word_suffix": "", // 是否把连续出现的未知词(UNK)融合合并成一个。 // false 代表不融合,每个不认识的字符单独处理 "fuse_unk": false, // 字节回退机制开关。 // 核心技术点:当设置为 true 时,如果遇到词表里没有的生僻字(比如特殊的emoji), // 分词器不会报错,也不会把它变成 UNK,而是直接把它拆解成底层的 UTF-8 字节(Byte)符号来兜底,确保全字符覆盖。这里为 false。 "byte_fallback": false, // 核心词表(Vocabulary 字典)。它是一个庞大的映射表,规定了“文本片段”到“数字 ID”的唯一对应关系 "vocab": { "!": 0, // 文本中的感叹号,映射到模型内部的数字 ID 是 0 "\"": 1, // 文本中的双引号(经过了转义),映射到模型内部的数字 ID 是 1 "#": 2 // 文本中的井号,映射到模型内部的数字 ID 是 2 } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 inputs = tokenizer( [ "Hello, how are you?", # 输入的第一句话(较短,包含 5 个 Token) "I'm doing well, thank you!", # 输入的第二句话(较长,包含 7 个 Token) ], # 1. 填充策略(Padding) # 作用:强制对齐批次(Batch)内所有句子的长度,让它们变成规整的矩阵(行、列对齐)。 padding=True, # 2. 返回数据类型(Return Tensors) # 作用:"pt" 代表 PyTorch Tensor。直接将结果打包成 PyTorch 的张量矩阵,不需要手动转换,方便直接 `.to("cuda")` 送进显卡。 return_tensors="pt", # 3. 填充方向(Padding Side)—— 本次最核心的修改! # 作用:强行规定把用来凑数的补零标记([PAD])加在短句子的“左侧”(开头位置)。 # 核心技术原因(大模型推理的铁律): # 现代大语言模型是自回归生成(从左到右逐字吐字)。 # 如果把 [PAD] 放在右边(默认行为),模型生成新字时,它看到的最新上文就会是 [PAD],这会彻底破坏位置编码(RoPE)以及 Attention 的最新特征,导致模型直接开始胡言乱语或者卡死。 # 把 [PAD] 放在左边,能确保所有句子的“最右端”(即接下来要吐新字的位置)在数学矩阵上完美对齐,而且模型能无缝读到最新的有效上文。 padding_side="left" ).to(model.device) inputs
image-20260523134035248
padding的作用
模型会把多个句子打包成一个批次(Batch)同时塞给模型同时预测的,但是批量计算要求输入必须是一个完美的矩形矩阵(行和列的数量必须严格相等) ,所以在句子长度不一的时候,需要设置padding,也就是填充[PAD]
1 2 行1 ──> [ 你 , 叫 , 什么 , 名字 , 呀 , ? ] (原本就最长,无需Padding) 行2 ──> [ [PAD], [PAD], [PAD], [PAD], 南京 , 大学 ] (短句,左边被垫了 4 个 PAD)
分词器还会同时生成一个 attention_mask[PAD] 干扰
1 2 行1 ──> [ 1, 1, 1, 1, 1, 1 ] (全看) 行2 ──> [ 0, 0, 0, 0, 1, 1 ] (前4个PAD被强制致盲,Attention 算矩阵时直接把它们当空气)
image-20260523134330284
Padding Side的作用
既然有attentionmask了,为什么还要填充方向(),填充到右边不也行吗
致命原因一:位置编码(RoPE)完全错乱
现代大模型(如 Qwen2、DeepSeek)使用的是
旋转位置编码(RoPE) 。模型必须要知道每个 Token
在句子里的绝对位置(它是第几个字) ,才能理解语法。
假设有两句话同时预测,最大对齐长度是 6:
句子 A 只有 3 个字:“真 漂 亮”
句子 B 有 6 个字:“南京 师范 大学”
❌ 如果填充在右边(Right Padding):
1 2 3 【第1步:输入矩阵】 行 1 ──> [ 真(pos:0) , 漂(pos:1) , 亮(pos:2) , [PAD](pos:3) , [PAD](pos:4) , [PAD](pos:5) ] 行 2 ──> [ 南(pos:0) , 京(pos:1) , 师(pos:2) , 范(pos:3) , 大(pos:4) , 学(pos:5) ]
第一步计算时,有 attention_mask 挡着,句子 A 只看了前 3
个字,成功预测出下一个字是 “啊”。
但是,接下来模型要同时生出第 2
个字了(自回归下一步):
新生成的字 “啊” 必须拼到句子的末尾。
句子 B 的 “学” 在位置 5,所以新生成的字在 位置
6 。
句子 A 的 “亮” 在位置 2,新生成的字 “啊”
应该在 位置 3 。
灾难发生了 :在矩阵计算中,显卡必须整齐划一地把新字拼在矩阵的最后一列(位置
6) 。
这导致句子 A 的 “啊” 被强行赋予了 位置
6 的位置编码!
在模型眼里,这个句子变成了:“真(0) 漂(1) 亮(2) ...空了3个位置... 啊(6)”。位置编码的断层会直接让自注意力机制彻底报废,模型开始疯狂吐胡话。
如果填充在左边(Left Padding):
1 2 3 【第1步:输入矩阵】 行 1 ──> [ [PAD](pos:0) , [PAD](pos:0) , [PAD](pos:0) , 真(pos:1) , 漂(pos:2) , 亮(pos:3) ] 行 2 ──> [ 南(pos:1) , 京(pos:2) , 师(pos:3) , 范(pos:4) , 大(pos:5) , 学(pos:6) ]
通过特殊的处理,左边的 [PAD] 位置编码直接被无视。
重点看右边:句子 A 的末尾 “亮” 在位置 3,句子 B 的末尾
“学” 在位置 6。
当模型同时吐出新字时,它们都可以规整地统一拼在矩阵的右侧边框(也就是下一列) ,各自的位置编码能够丝滑地递增(位置
3 变 4,位置 6 变 7),绝对不会发生空间断层。
致命原因二:自回归推理的“长文本记忆(KV
Cache)”无法对齐
大模型为了单字蹦字变快,内部有一套叫 KV Cache
的机制——它会把前面已经算过的词的 K V
显卡在批量(Batch)计算时,要求每一行的记忆长度必须是一致的 。
❌ 如果 Padding 在右边:
1 2 行 1 (有效记忆3个) ──> [ K1, K2, K3, [PAD], [PAD], [PAD] ] ──> 接下来新字在这里 💥 撞墙了 行 2 (有效记忆6个) ──> [ K1, K2, K3, K4 , K5 , K6 ] ──> 接下来新字在这里
当自回归进行到第二步、第三步时,最新的 Token 需要不断追加到 KV
缓存的末尾。
第一行的末尾被 [PAD] 占着坑,新词进不来;如果强行覆盖
[PAD],第一行的有效长度只有 3,第二行有效长度是 6,这导致
KV 缓存矩阵的各行长度不一致 。
显卡的核心在面对这种“参差不齐”的动态矩阵时,根本无法做并行的矩阵乘法 。
如果 Padding 在左边:
1 2 行 1 ──> [ [PAD], [PAD], [PAD], K1, K2, K3 ] ──> 最新插入点 ──> [这里完美对齐] 行 2 ──> [ K1 , K2 , K3 , K4, K5, K6 ] ──> 最新插入点 ──> [这里完美对齐]
因为 [PAD]
稳稳地呆在左边底座,所有句子的动态增长前沿(右侧边缘)是完全对齐的 。
每蹦出一个新字,所有的句子都可以整齐划一地向右集体拓宽一列。显存里的
KV Cache 矩阵始终是一个标准的、完美的矩形,显卡可以用 O (1)
模型推理
1 2 3 4 5 6 7 output=model.generate( input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=50 ) output
使用模型进行推理后面的向量
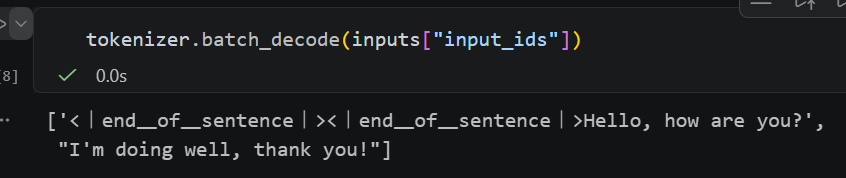
1 tokenizer.batch_decode(output)
解码翻译成人类语言
但是目前模型的回答是这样
1 2 ["<|end▁of▁sentence|><|end▁of▁sentence|>Hello, how are you? I'm trying to understand some concepts about the electromagnetic spectrum. Could you explain the different parts of it and their relationships? Also, what's the significance of each part?\n\nCertainly! The electromagnetic spectrum is a range of all possible wavelengths of electromagnetic radiation.", "I'm doing well, thank you! What is the sum of 1/3 and 1/6? Let me think. Hmm, okay, so I need to add these two fractions together. I remember that to add fractions, they need to have the same denominator. The denomin"]
很明显是有问题的,为什么呢
image-20260523135418262
它在预训练阶段(图中的第 1
步)学到的本领是自回归续写(盲猜下一个字) 。它习惯了看到普通文章,就顺着普通文章的语法往下编。
但是,现代的对话/推理模型(如
DeepSeek-R1、Qwen2.5-Instruct)是通过微调(图中的第 2
步)训练出来的。为了让它知道什么时候该“闭嘴”、什么时候该“思考(<think>)”、什么时候该“回答”,官方在训练它时,强行给它定了一套严格的特殊符号包围圈 。
如果你直接把普通的字符串 "Hello, how are you?"
喂给它,对它来说格式是完全陌生的 (它找不到应有的标记)。
添加标签
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 message=[ [ {"role": "user", "content": "Hello, how are you?"} ], [ {"role": "assistant", "content": "I'm doing well, thank you!"} ] ] tokenizer.padding_side="left" inputs=tokenizer.apply_chat_template( message, return_tensors="pt", padding=True, add_generation_prompt=True ).to(model.device) tokenizer.batch_decode(inputs["input_ids"])
tokenizer.apply_chat_template是调用models-R1-Distill-Qwen-1.5B_config.json中的chat_template
Jinja2 模板,将对话添加标签
Jinja2 本质上是 Python
编程世界里最著名、使用最广泛的 “文本自动化渲染引擎”(Template
Engine) 。
在代码层面上,它的工作公式非常纯粹:
$$\text{Jinja2 模板 (死标签)} \quad +
\quad \text{Python 变量 (活数据)} \quad \xrightarrow{\text{Render
(渲染)}} \quad \text{最终的纯文本字符串}$$
image-20260523140200484
1 2 ['<|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|><|begin▁of▁sentence|><|User|>Hello, how are you?<|Assistant|><think>\n', "<|begin▁of▁sentence|><|Assistant|>I'm doing well, thank you!<|end▁of▁sentence|><|Assistant|><think>\n"]
add_generation_prompt=True会在最后添加<|Assistant|><think>\n用来引导模型生成
1 2 3 4 5 6 7 output=model.generate( input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=256 ) tokenizer.batch_decode(output)
最后再让模型推理,便能正确生成答案了
1 2 ['<|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|><|begin▁of▁sentence|><|User|>Hello, how are you?<|Assistant|><think>\nAlright, the user greeted me with "Hello, how are you?" which is a friendly and open way to start a conversation.\n\nI should respond in a similar positive manner to keep the conversation going smoothly.\n\nI need to make sure my response is welcoming and inviting them to share what they\'re up to.\n\nKeeping it simple and open-ended is key here.\n</think>\n\nHello! I\'m doing well. How can I assist you today?<|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|><|end▁of▁sentence|>', '<|begin▁of▁sentence|><|Assistant|>I\'m doing well, thank you!<|end▁of▁sentence|><|Assistant|><think>\nOkay, so the user just said, "I\'m doing well, thank you!" Hmm, I need to figure out what they\'re really looking for here. Let me break it down.\n\nFirst, they said, "I\'m doing well, thank you!" That\'s pretty straightforward. They\'re acknowledging their effort and appreciation. But maybe they want more than that? Maybe they\'re feeling a bit overwhelmed or just looking for reassurance.\n\nI should consider different scenarios. Could they be feeling down because of something recent? Or maybe they\'re feeling a bit isolated? Sometimes people appreciate a simple thank you but need more support or a different perspective.\n\nI wonder if they\'re asking for tips on how to handle situations or if they need advice on how to improve. It\'s possible they\'re seeking encouragement or motivation. Alternatively, they might be seeking reassurance that they\'re not alone in feeling this way.\n\nAnother angle is that they might be looking for a way to express gratitude in a different way. Maybe they want to change their approach to communication. Or perhaps they\'re dealing with a specific challenge that\'s making them feel inadequate, and they need validation.\n\nI should also think about the tone they\'re using. They said, "I\'m doing well, thank you!" which is positive and']
为什么会蹦出这么多
<|end▁of▁sentence|>?
大模型提前说完了话,它会吐出一个终止符 ,也就是
<|end▁of▁sentence|>(意为“句子结束”)。
但是,由于这是批量推理 ,第一句话的通道虽然无话可说了,但第二句话的通道还没写完,显卡不能停,必须硬着头皮继续往后算满剩下的步数。
为了保持矩阵的绝对规整,显卡在接下来的每一步里,只能在第一句的通道后面疯狂重复填充“终止符”来凑数 :
1 2 3 4 【显卡最终吐出的 output 矩阵物理外观】 第一行 (短句通道) ──> [ Hello! ... assist you today? , <|end...> , <|end...> , <|end...>, ... ] (后面全在机械重复填终止符) 第二行 (长句通道) ──> [ I'm doing well... (模型正兴高采烈地写到一半) ]
因为显卡矩阵在右侧必须对齐,短句子通道在“无话可说”到“等长句子写完”之间的所有空白格,全部被强行塞满了
<|end▁of▁sentence|>。
参考资料
本地部署大模型!用Transformers库跑通DeepSeek-R1_哔哩哔哩_bilibili