计算机组成原理查漏补缺
三种指令类型 (R, I, J)
MIPS 指令集的设计非常整齐,所有的指令都是 32位(bits) 长。但是,这 32 个格子怎么分配,取决于指令的类型。
(1) R-type (Register type, 寄存器型)
- 用途:纯粹的数学运算。
- 特点:所有的操作数都在寄存器里。
- 例子:
add $t0, $t1, $t2(把 t1 和 t2 里的数拿出来相加,结果存到 t0)。 - 格局:因为它需要 3
个寄存器(2个源,1个目标),所以它的空间被切得很细,最后剩下了 6 位给
func。
(2) I-type (Immediate type, 立即数型)
- 用途:涉及常数运算,或者读写内存。
- 特点:操作数里包含一个具体的数字(立即数)。
- 例子:
ori $t0, $t1, 100(把 t1 和数字 100 做或运算)。lw $t0, 4($t1)(去内存取数,地址是 t1 + 4)。
- 格局:为了放那个数字(比如 100),它牺牲了
rd和func的位置,腾出了 16位 的空间来存这个数。
(3) J-type (Jump type, 跳转型)
- 用途:程序跳转(就像代码里的
goto)。 - 特点:跳得很远。
- 例子:
j 1000(直接跳到地址 1000 去执行)。 - 格局:除了开头的 op,剩下的 26位 全用来存目标地址,保证能跳得足够远。
| 指令类型 | 全称 (中文名) | 包含的常见指令 (加粗为你课件中的) | 核心特征 | 指令格式结构 (32位) |
|---|---|---|---|---|
| R-Type | Register Type (寄存器型) | add (加法) sub (减法) and, or, slt, nor | 纯运算。 操作数全在寄存器里,不做数据传输,不涉及立即数。 | op(6) rs(5) rt(5)
rd(5) shamt(5) func(6)
(特点:op全为0,靠 func 区分) |
| I-Type | Immediate Type (立即数型) | ori (或立即数) lw (加载字) sw (存储字) beq (相等分支) addi, andi, bne | 带常数/地址偏移。 计算或访存时,需要用到一个具体的数字(16位)。 | op(6) rs(5) rt(5)
immediate(16) (特点:最后16位是常数/地址) |
| J-Type | Jump Type (跳转型) | jump (无条件跳转) jal (跳转并链接) | 长距离跑路。 不需要计算,直接跳到程序代码的另一个位置。 | op(6) address(26)
(特点:后面26位全是目标地址) |
op 和 func
是什么?
这两个是指令的身份证。
op(Opcode, 操作码):指令的高 6 位 (31-26 bit)。- 作用:它决定了这到底是一条什么指令(大类)。
- 比喻:就像身份证上的“省份”。控制器一看
op,就知道你是lw还是sw还是beq。 - 特殊情况:对于所有的 R-type
指令,它们的
op都是000000。这就尴尬了,控制器光看op分不清你是加法还是减法。
func(Function code, 功能码):指令的低 6 位 (5-0 bit)。- 作用:专门用来区分 R-type 指令的具体操作。
- 比喻:就像身份证上的“名字”。
- 逻辑:当
op是000000时,控制器就会去查func。func = 100000-> 做加法 (add)func = 100010-> 做减法 (sub)
- 注意:只有 R-type 有
func。I-type 和 J-type 的这最后 6 位已经被那个常数或者地址占用了,所以它们没有 func 字段。

为什么对于所有的 R-type 指令,它们的 op 都是 000000
设计者回头看了一眼 R-type 指令的格式。他们发现了一个惊喜:
R-type 指令只需要存 3 个寄存器编号(rs, rt,
rd)和 1 个移位量(shamt)。
op: 6位rs: 5位rt: 5位rd: 5位shamt: 5位- 总共使用:6 + 5 + 5 + 5 + 5 = 26 位。
32 - 26 = 6 位!
R-type 指令的末尾,正好空出了 6位 没地方用。
天才的设计思路来了:
既然 R-type 指令末尾空着 6 位,那为什么不把 Opcode 统一设为 000000(意思是:这是一条运算指令),然后利用末尾这空闲的 6 位(也就是 func 字段)来具体区分是加法还是减法呢?
- 这样一来,
add,sub,and,or,slt等几十条运算指令,在 Opcode 表里只占用 1 个位置(就是 000000)。 - 这就把剩下的 63 个 Opcode 宝贵名额,留给了那些没有空闲位置的 I-type
和 J-type 指令(因为它们后面被立即数填满了,没有
func字段可用)。
控制信号的含义都有哪些
这些信号就是控制器发出的“命令”,控制数据通路里的多路选择器 (Mux) 和 使能开关 (Enable)。
我们把它们分为三类来记:
第一类:选路信号(Mux Selectors)
这些信号决定数据走哪条路。你可以理解为火车轨道的道岔。如果是
0 走左边,1 走右边。
RegDst(Register Destination)- 含义:运算结果存到哪个寄存器编号里?
- 背景:
- R-type 的目标寄存器编号在指令的第 15-11 位 (
rd字段)。 - I-type (如 lw) 的目标寄存器编号在指令的第 20-16 位 (
rt字段)。
- R-type 的目标寄存器编号在指令的第 15-11 位 (
- 值:
1: 选rd(R-type)。0: 选rt(I-type)。
ALUSrc(ALU Source)- 含义:ALU 的第二个操作数来自哪里?
- 值:
0: 来自寄存器堆的读出数据(两个寄存器做运算,如 R-type)。1: 来自指令里的立即数(寄存器和数字做运算,如ori,lw,sw)。
MemtoReg(Memory to Register)- 含义:写回寄存器的数据来源是谁?
- 值:
1: 来自内存的数据(只有lw指令是这样,把数据从仓库搬回寄存器)。0: 来自 ALU 的计算结果(绝大多数指令,如add,ori)。
第二类:开关信号(Enables)
这些信号是安全锁。只有设为
1,才允许动作。
RegWr(Register Write)- 含义:允不允许修改寄存器的值?
- 值:
1: 允许写。像add,lw,ori这种需要保存结果的指令。0: 禁止写。像sw(只是往内存存数),beq(只是比较),j(只是跳转),绝对不能改写寄存器里的数据。
MemWr(Memory Write)- 含义:允不允许修改内存的值?
- 值:
1: 允许写。只有sw(Store Word) 指令是 1。0: 禁止写。其他所有指令。
第三类:功能控制信号
ExtOp(Extension Operation)- 含义:16位的立即数怎么变成32位?
- 背景:指令里的数字只有16位,但计算器是32位的。
- 值:
1(Signed): 符号扩展。保持正负号不变(比如 -2 扩展后还是 -2)。用于lw,sw,beq(算地址偏移量)。0(Unsigned): 零扩展。高位直接补0。用于逻辑运算如ori。
Branch- 含义:这是一个条件分支指令吗?
- 值:如果是
beq指令,这个信号是1。它会结合 ALU 的“零标志位”来决定要不要跳。
Jump- 含义:这是一个无条件跳转指令吗?
- 值:如果是
j指令,这个信号是1。直接强行修改 PC 指针。
ALUctr(ALU Control)- 含义:ALU 到底做什么数学题?
- 值:这是个多位信号(通常3位或4位)。
Add: 加法 (用于add,lw,sw)Sub: 减法 (用于sub,beq比较是否相等)Or: 逻辑或 (用于ori)
什么是控制器 (Controller)?
在 CPU 这个“大工厂”里,主要分两部分:
- 数据通路 (Datapath):这是干活的工人和机器。包括寄存器(用来记账的小本子)、ALU(算盘/计算器)、内存(大仓库)。它们负责搬运数据、做加减法。
- 控制器 (Controller):这是工厂的指挥官。
控制器的作用: 它不直接干活(不存数、不算数),它的任务是看懂指令,然后对着数据通路里的各种开关“发号施令”。
- 输入:它看的是指令(Instruction)。比如指令说“把 A 和 B 加起来”,这串 0101 的机器码传给控制器。
- 输出:控制器根据指令,把相应的控制信号线拉高(置1)或拉低(置0)。
一句话总结:控制器就是 CPU 的大脑,它通过查表(真值表)来告诉身体的各个部位(ALU、寄存器、内存)在当前这一刻该干什么。
什么是数据通路 (Datapath)?
它的任务:根据指挥官(控制器)的命令,把数据从仓库(寄存器/内存)里搬出来,送到加工车间(ALU)算一下,再搬回去。
核心组成:
- 仓库:寄存器堆 (Registers)、数据存储器 (Data Memory)。
- 车间:算术逻辑单元 (ALU)、加法器 (Adder)。
- 交通枢纽:多路选择器 (Mux)、扩展器 (Ext)。
什么是单周期处理器 (Single-Cycle Processor)?
核心定义:CPI (Cycles Per Instruction) = 1。
通俗解释:
- 时钟信号“哒”(上升沿)一下,CPU 开始取指令。
- 在时钟“哒”下一响之前,CPU 必须把这条指令的所有工作(取指、翻译、运算、读写内存、写回结果)全部做完。
单周期处理器包含哪些功能?
为了让程序能跑起来,处理器通常需要支持三大类功能(指令):
A. 算术逻辑运算 (R-Type)
- 功能:做数学题。
- 指令例子:
add(加),sub(减),and(与),or(或),slt(比较大小)。 - 流程:读寄存器 -> ALU 算 -> 写回寄存器。
B. 数据传输/访存 (I-Type)
- 功能:搬运数据。CPU 的寄存器太小,数据多了要放内存里。
- 指令例子:
lw(Load Word):从内存搬到寄存器。sw(Store Word):从寄存器搬到内存。
- 流程:算地址 -> 读/写内存 -> (如果是读)写回寄存器。
C. 条件分支与跳转 (Branch & Jump)
- 功能:改变程序执行顺序(也就是改变 PC 的值)。
- 指令例子:
beq(Branch if Equal):如果两个数相等,就跳到某处去。j(Jump):无条件直接飞到某处。
- 流程:比较 -> 计算新地址 -> 修改 PC。
单周期处理器包含哪些组成部分?
我们可以把它分为“肉体”(数据通路)和“灵魂”(控制单元)两大部分。
第一部分:数据通路 (Datapath) —— “干活的”
这部分你之前的实验已经做了一大半了,现在需要补全:
- 取指单元 (Instruction Fetch) ——
这是新面孔
- PC (Program Counter):一个 32 位的寄存器,存着“现在执行到哪一行代码了”。
- 指令存储器 (Instruction Memory):存放你写的机器码的大仓库。
- 加法器 (+4):让 PC 自动加 4,指向下一条指令。
- 寄存器堆 (Register File)
- CPU 的“口袋”,这里有 32 个格子 ($0 - $31),用来存放临时数据。
- 算术逻辑单元 (ALU)
- CPU 的“计算器”,负责算加减法、逻辑运算。
- 数据存储器 (Data Memory)
- CPU 的“大仓库”,用来做
lw和sw。
- CPU 的“大仓库”,用来做
- 扩展单元 (Extender)
- 把 16 位的立即数变成 32 位。
- 多路选择器 (Mux) —— 交通警察
- 关键组件!比如
ALUSrc这个 Mux,决定了 ALU 的输入是来自寄存器还是立即数。
- 关键组件!比如
第二部分:控制单元 (Control Unit) —— “发号施令的”
在你上一个实验里,“你”就是控制器(手动在波形里设 0 或 1)。现在要写一个模块来替代你。
- 主控制器 (Main Control)
- 输入:指令的高 6 位 (Opcode)。
- 输出:所有的控制信号 (
RegDst,ALUSrc,MemWr等)。 - 作用:看到
lw指令,它就自动把MemtoReg拉高,把RegWr拉高。
- ALU 控制器 (ALU Control)
- 输入:主控制器的信号 + 指令的低 6 位 (Funct)。
- 输出:给 ALU 的
ALUctr(3位或4位)。 - 作用:专门告诉 ALU 该做加法还是减法。
MIPS是什么
1. 一种经典的 CPU 架构 (MIPS Architecture)
全称是 Microprocessor without Interlocked Pipeline Stages(无互锁流水线阶段微处理器)。
- 这是什么: 它是一种基于 RISC(精简指令集计算机)原则设计的 CPU 架构。
- 地位与影响: MIPS 是计算机体系结构教科书中的“标准模版”(著名的《计算机组成与设计》一书就主要使用 MIPS 教学)。它的设计非常简洁、优雅,对后来的 CPU 设计(包括 ARM 和 RISC-V)产生了深远影响。
- 应用场景:
- 曾经的辉煌: 索尼 PlayStation (PS1, PS2)、任天堂 N64 等游戏机都使用 MIPS 处理器。
- 现在的应用: 依然广泛用于路由器(如部分 TP-Link, Ubiquiti 设备)、嵌入式设备和部分龙芯处理器(早期的龙芯基于 MIPS 指令集)。
- 现状: 虽然曾经辉煌,但在移动端被 ARM 击败,在开源领域受到 RISC-V 的强烈冲击。MIPS 公司后来宣布将架构开源,随后又经历了多次收购和转型,目前已不再开发新的 MIPS 架构,转投 RISC-V 阵营。
2. 一种性能指标 (Million Instructions Per Second)
全称是 Million Instructions Per Second(每秒百万条指令)。
这是什么: 它是衡量计算机 CPU 运算速度的一个老式指标。
计算公式:
$$\text{MIPS} = \frac{\text{指令总数}}{\text{执行时间} \times 10^6}$$
缺点: 这个指标在现代对比中往往被认为不准确,因此有时候被戏称为 “Meaningless Indication of Processor Speed”(处理器速度的无意义指标)。
- 原因: 不同的 CPU 执行一条指令所做的事情不同。例如,CISC(如 Intel x86)的一条复杂指令可能相当于 RISC(如 ARM)的 5 条简单指令。仅仅比较“每秒执行多少条指令”并不能真实反映两台不同架构电脑的快慢。
ISA是什么
ISA 是 Instruction Set Architecture(指令集架构)的缩写。
它是计算机体系结构中最重要的抽象层,可以理解为软件(程序员/编译器)和硬件(CPU)之间的“合同”或“接口”。
1. 核心概念:它是什么?
想象一下驾驶汽车:
- ISA 就像是驾驶舱的设计标准: 它规定了“方向盘是用来转弯的”、“右边的踏板是油门”、“仪表盘显示速度”。只要懂这个标准,你就能开福特,也能开丰田。
- 硬件(微架构)就像是引擎的设计: 它是 V6 还是 V8 引擎,是燃油还是电动,这属于内部实现。
在计算机中:
- 软件(操作系统、编译器)只看 ISA,它只需知道“发送
ADD指令能做加法”,不需要知道 CPU 内部是有几亿个晶体管怎么连线的。 - 硬件(CPU 设计师)必须实现 ISA 规定的所有功能,至于怎么实现(用多少级流水线、多大的缓存),那是硬件的事。
2. ISA 规定了什么? (CPU 的“词汇表”)
ISA 定义了程序员在汇编层面能看到的所有东西:
- 指令集 (Instructions): CPU 能干什么?(如:加法、减法、从内存读取数据、跳转)。
- 数据类型 (Data Types): 它是怎么理解 0 和 1 的?(如:这是个 32 位整数,还是个 64 位浮点数?)。
- 寄存器 (Registers):
程序员能直接控制哪些“临时存储格”?(比如 MIPS 里的
$t0-$t9,x86 里的RAX,RBX)。 - 寻址模式 (Addressing Modes): 怎么找到内存里的数据?(是直接给地址,还是通过寄存器加偏移量?)。
- 内存管理与异常处理: 程序崩溃了怎么办?如何和操作系统配合?
MIPS 指令集架构 (ISA)
MIPS 指令集架构 (ISA) 是计算机体系结构中最经典的“教科书级”设计。它基于 RISC(精简指令集计算机)理念,主打简洁、高效和规整。
以下是 MIPS 指令集的核心要素拆解:
核心设计理念
- 固定长度: 所有的指令都是 32位(4字节)长。这使得 CPU 解码非常容易。
- Load/Store 架构: 只有
load(读取)和store(写入)指令可以访问内存。其他的算术逻辑运算(如加法、减法)必须在寄存器之间进行。 - 三操作数格式:
大多数运算指令需要三个操作数(例如:
add a, b, c意思是a = b + c),非常直观。
Register Transfer Language(寄存器传输语言)
Register Transfer Language (RTL),有时在教科书中也称为 RTN (Register Transfer Notation),是一种用于描述计算机内部微操作 (Micro-operations) 的符号系统。
如果说汇编语言是给程序员看的,那么 RTL 就是给计算机架构师用来推导和设计电路逻辑的“数学公式”。它比汇编更底层,因为它描述的是数据在硬件连线上的具体流动。
以下是关于它的详细介绍:
核心符号 (The Vocabulary)
RTL 使用一套简洁的数学符号来表示硬件动作。掌握这些符号就能读懂各种架构图:
| 符号 | 含义 | 例子 | 解释 |
|---|---|---|---|
| ← | 传输 / 赋值 | R1 ← R2 | 把寄存器 R2 的内容复制给 R1 |
| [ ] | 寻址 / 内容 | M[100] | 内存地址为 100 的存储单元里的数据 |
| M | 内存 (Memory) | M[PC] | PC 指向的内存地址里的内容 |
| , | 并行执行 | R1 ← R2, R2 ← R1 | 这两个操作在同一个时钟周期内同时发生 |
| () | 部分位 | R1(0 − 7) | 仅操作 R1 寄存器的低 8 位 |
记录开发过程中遇到的问题
浏览器的跨域预检
INFO: 127.0.0.1:54365 - “OPTIONS /usersrole=admin HTTP/1.1” 200 OK INFO: 127.0.0.1:54365 - “GET /usersrole=admin HTTP/1.1” 200 OK 为什么每次调用这个接口会有两个
• 这是浏览器的跨域预检 + 实际请求各一次:
- 前端带 Authorization 头、跨域调用 /users?role=admin 时,浏览器会先发 OPTIONS 预检,看服务器是否允许该方法 头。你启用了 CORS,所以预检返回 200。
- 预检通过后才发真正的 GET /users?role=admin,所以日志里看到两条。
这是正常行为;非浏览器(如 curl/postman)或同源、无自定义头的请求则不会有预检。
如何解决跨源的问题
我们推导出了两套针对不同环境的最佳实践方案,核心逻辑都是“利用中间人(代理)实现同源”。
💻 开发环境 (Development)
- 工具: Vite (
server.proxy) - 原理: 利用 Vite 启动的 Node.js 服务转发请求。
- 效果: 浏览器只跟 Vite 打交道(同源),Vite 跟后端打交道(服务器间无 CORS 限制)。完美消除预检和跨域报错。
🚀 生产环境 (Production)
- 工具: Nginx (反向代理)
- 原理: 浏览器所有请求(页面 + 接口)统一发给
Nginx(比如 80 端口)。
/-> Nginx 返回静态 HTML/JS 文件。/api-> Nginx 转发给后端服务(8000 端口)。
- 效果: 在浏览器看来,它始终只访问了一个域名(同源),因此不需要 CORS 配置,也没有预检请求,性能最高。
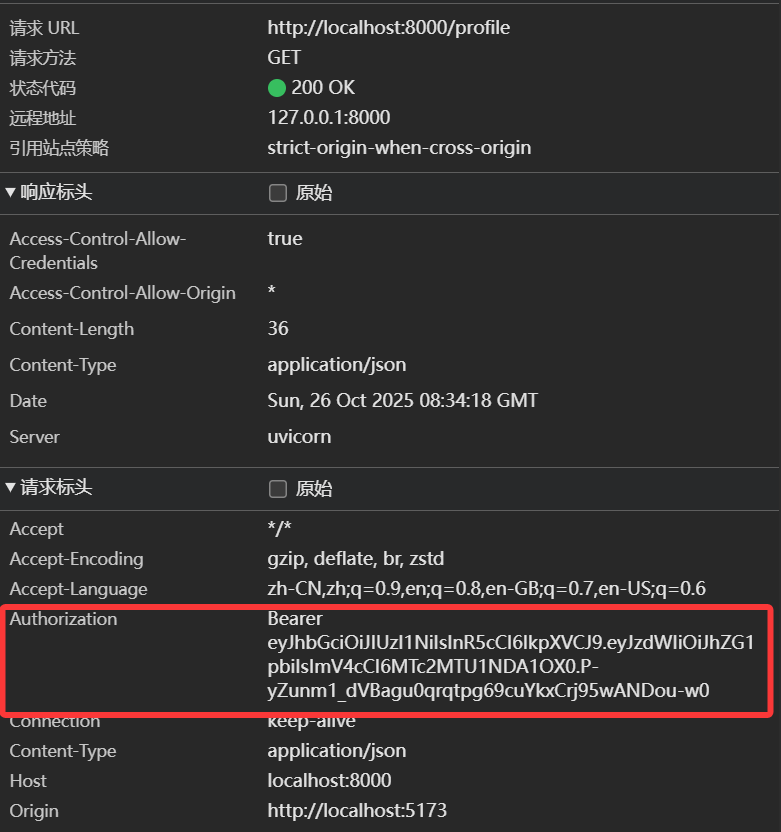
Authorization 头是什么
Authorization 头(Header)是 HTTP
协议中用来验证用户身份的一个标准字段。
1. 标准格式
Authorization
头的值并不是随便填写的,它遵循一个严格的语法结构:
1 | Authorization: <认证类型> <凭证数据> |
- 认证类型 (Schema):
说明后面跟的是哪种类型的凭证(比如是“密码”还是“令牌”)。常见的有
Bearer和Basic。 - 空格: 中间必须有一个空格分隔。
- 凭证数据 (Credentials): 具体的加密字符串或 Token。
2. 最常用的两种类型
A. Bearer (最常见,用于 JWT)
这是目前现代 Web 应用和 API 最主流的方式,通常配合 JWT (JSON Web Token) 使用。
含义: “Bearer” 的意思是“持有者”。意思是:“谁持有这个令牌,谁就有权限。”
场景: 用户登录后,服务器发给用户一个 JWT。用户下次请求时,把这个 JWT 放在这里。
HTTP 请求示例:
HTTP
1
2
3GET /api/user/profile HTTP/1.1
Host: example.com
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...注意: 这里的乱码字符串
eyJ...就是上一条回答中提到的 JWT。
B. Basic (最基础,用于用户名密码)
这是 HTTP 协议内置的最古老的认证方式。
含义: 直接把“用户名:密码”拼接,然后进行 Base64 编码传给服务器。
场景: 内部系统、简单的测试环境、或者某些传统的网关认证。
原理:
- 用户名
admin,密码123456。 - 拼接:
admin:123456。 - Base64 编码:
YWRtaW46MTIzNDU2。
- 用户名
HTTP 请求示例:
1
2POST /api/login HTTP/1.1
Authorization: Basic YWRtaW46MTIzNDU2
常用mcp与skills
常用mcp
supabase
模型上下文协议 (MCP) | Supabase 文档 — Model context protocol (MCP) | Supabase Docs
codex mcp login supabase
context7
context7/i18n/README.zh-CN.md at master · upstash/context7
claude mcp add –transport http context7 https://mcp.context7.com/mcp –header “CONTEXT7_API_KEY: ctx7sk-7f2ea2a0-d309-4ba7-97d0-af20a783540f”
[mcp_servers.context7] url = “https://mcp.context7.com/mcp” http_headers = { “CONTEXT7_API_KEY” = “ctx7sk-7f2ea2a0-d309-4ba7-97d0-af20a783540f” }
vercel
1 | [mcp_servers.vecel] |
GitHub
github/github-mcp-server: GitHub’s official MCP Server
1 | [mcp_servers.github] |
Chrome DevTools
ChromeDevTools/chrome-devtools-mcp: Chrome DevTools for coding agents
langchain docs
https://docs.langchain.com/mcp
1 | "Docs by LangChain": { |
1 | [mcp_servers.docs_by_langchain] |
vscode mcp配置文档
codex mcp配置文档
模型上下文协议 — Model Context Protocol
其他
figma
stripe
shadcn
semgrep
semgrep/cli/src/semgrep/mcp at develop · semgrep/semgrep
mcp市场
skills
uiuxpromax
simple-code
lsp
claude-plugins-official/plugins/pyright-lsp at main · anthropics/claude-plugins-official
Planning with Files
remotion
remotion-dev/skills: Agent Skills
skills市场
参考
用过上百款编程MCP,只有这15个真正好用,Claude Code与Codex配置MCP详细教程_哔哩哔哩_bilibili
LangChain官方教程
前言
什么是langchain
LangChain作为目前最流行的大模型应用开发框架,可以简单快速地构建由 LLM 驱动的 Agent 和应用程序的方式。
在今年的十月份,langchain也是发布了他的1.0版本,再次掀起了一波热潮。目前市面上类似的大模型开发框架可以说是百花齐放,比如LlamaIndex,AutoGen等,还有各家的adk(Agent Development Kit),而langchain在其中可以算的上最热门的,社区最活跃的框架。所以,对于所有后续有进行大模型应用开发工作的同学们,学习langchain框架是一个稳赚不赔的买卖
为什么要学习langchain
我个人觉得学习任何东西之前,都要先清楚我们学习这个东西的目的,这样才会更有动力去学习他。对于这个问题我想拆分成两个:一个是为什么我要学习这样一个大模型开发框架;另一个是,相对于其他框架,我们为什么要学习langchain
对于第一个问题,我的理解是:
- 与模型对话,或者说是调用api,不是像我们平时对话那样,只要把文字传过去,厂商模型就把答案传回来了,其背后有的请求响应是有一定格式的,常见的有openai和anthropic,而框架做的事情就帮我封装对这些复杂请求响应的处理,让我们几行代码就可以实现模型的调用
- 如果想搭建agent,光依靠调用模型是不够的,我们需要增加更多的功能,常见的如提示词,记忆功能,检索等,而langchain就帮我们做了这件事

对于第二个问题,我们可以了解一下langchain的优势,如下
LangChain 有四个核心优势:
1. 标准化的模型接口 - 不同提供商有独特的 API,但 LangChain 标准化了交互方式,让你无缝切换提供商,避免被锁定。
2. 易用且高度灵活的 Agent - 简单的 Agent 可以 10 行代码搞定,但也提供足够的灵活性让你进行所有的上下文工程优化。
3. 建立在 LangGraph 之上 - LangChain Agent 使用 LangGraph 构建,自动获得持久化执行、人工介入、流式传输和对话记忆等能力。
4. 用 LangSmith 调试 - 获得深度可观测性,追踪执行路径、捕获状态转换,提供详细的运行时指标。
langchain和langgraph的区别
关键点: LangChain Agents 实际上是建立在 LangGraph 之上的。这意味着:
- 如果你只是想快速构建 Agent,用 LangChain 就够了
- 如果你需要复杂的工作流、需要对执行流程进行精细控制,才需要使用 LangGraph
- 使用 LangChain 时,你不需要了解 LangGraph,但你自动获得了 LangGraph 的所有底层能力(持久化、流式处理、中断等)
资料
langchain的官方文档LangChain overview - Docs by LangChain
langchain与langgraph的官方教程LangChain Academy
大家如果想学习langchain或者langgraph的话,我只推荐官方教程
课前准备
1 | git clone https://github.com/zxj-2023/academy-langchain.git |
请大家克隆我为大家准备的课件
Lesson 1: Create Agent
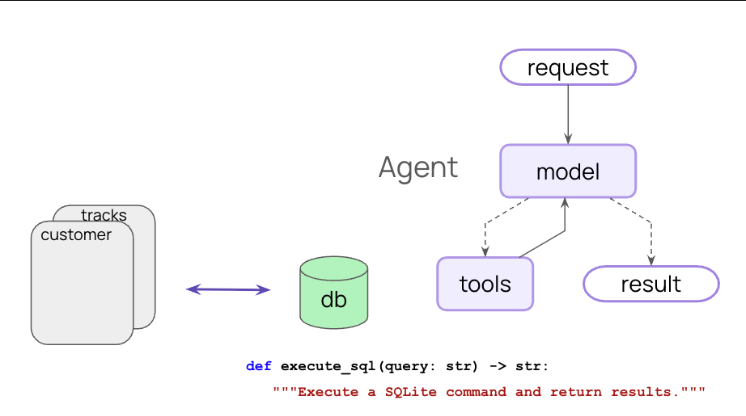
这一部分我会带大家构建一个ReAct架构的agent,可以通过调用tool,进行sql的查询
初始化
加载并所需的环境变量
1 | from dotenv import load_dotenv |
导入实例数据库
1 | from langchain_community.utilities import SQLDatabase |
Chinook.db 是数据库和 SQL 学习领域最著名的示例数据库(Sample Database)之一。
定义上下文信息,工具与系统提示词
定义运行时上下文,为代理和工具提供指定数据库访问。
1 | from dataclasses import dataclass |
Context(上下文)是为 Agent 提供正确信息和工具的方式
该工具将连接数据库,注意使用 get_runtime
访问图的运行时上下文。
1 | from langchain_core.tools import tool |
添加系统提示语以定义代理的行为。
1 | SYSTEM_PROMPT = """You are a careful SQLite analyst. |
你是一名谨慎的 SQLite 分析员。
规则:
按步骤思考。
需要数据时,使用工具 execute_sql 发起「单条」SELECT 查询。
只读:不允许 INSERT/UPDATE/DELETE/ALTER/DROP/CREATE/REPLACE/TRUNCATE。
输出默认限制 5 行,除非用户明确要求更多。
如果工具返回 “Error:”,请修改 SQL 再试。
优先写明列名,避免使用 SELECT *。
定义模型与智能体
这里我使用阿里百炼平台的apikey进行测试,对于不同家的模型langchain提供了不同的集成方式,对于qwen模型,我一般会选择langchain_qwq这个包
langchain-qwq · PyPI — langchain-qwq · PyPI
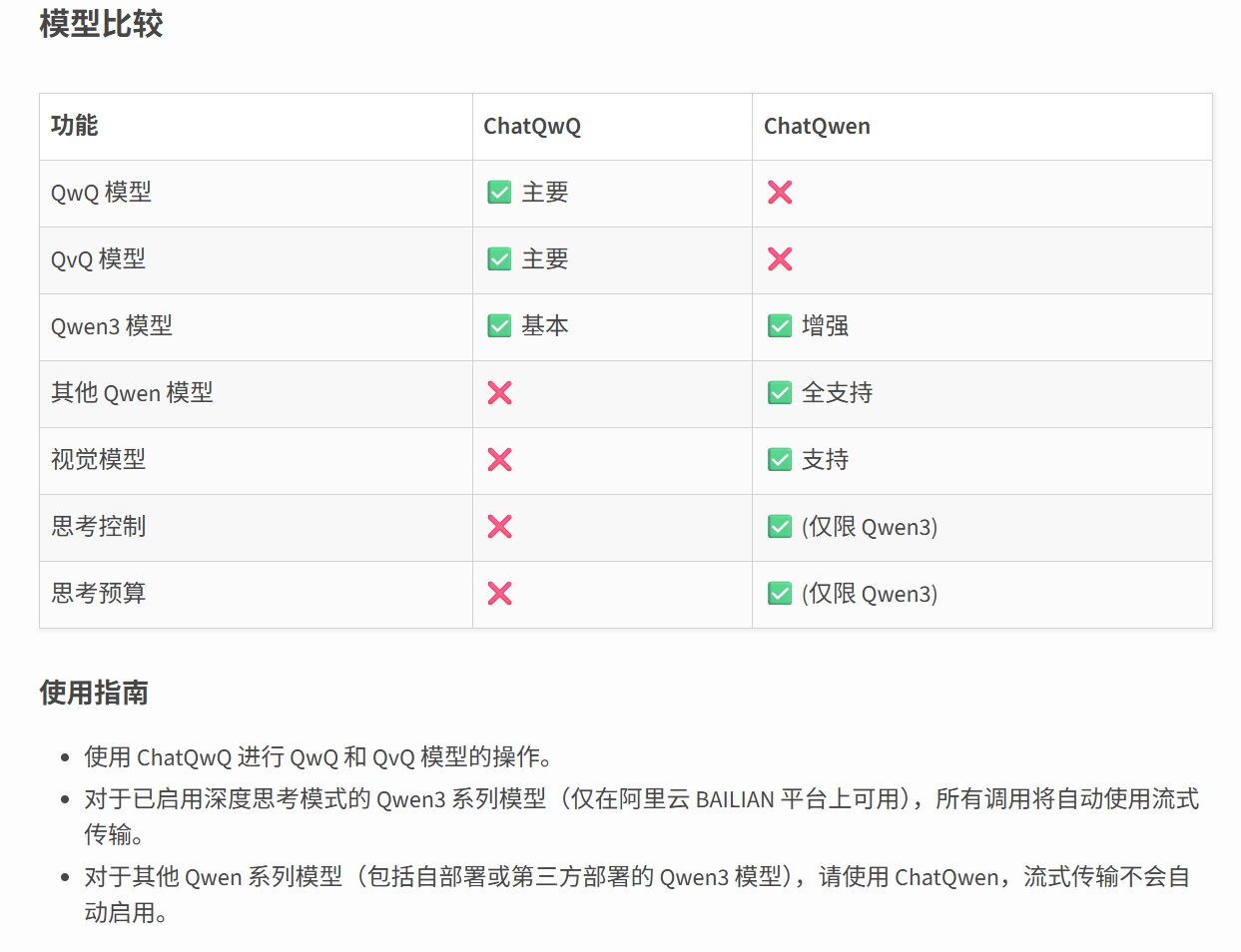
对于兼容openai格式的模型调用,通常也都可以使用langchain-openai这个包通过修改base_url进行模型的初始化
1 | from langchain_qwq import ChatQwen |
接下来我们使用langchain快速搭建一个ReAct智能体
1 | from langchain.agents import create_agent |
调用智能体
1 | question = "Which table has the largest number of entries?" |
ReAct就是Reasoning +
Acting,推理+行动,pretty_print
可以更优雅地展示模型与工具之间传递的消息。
运行结果如下

使用langsmith观察过程 https://smith.langchain.com/public/114e9325-12c2-4a6f-a0f1-25087b66278c/r
Lesson 2: Models and Messages
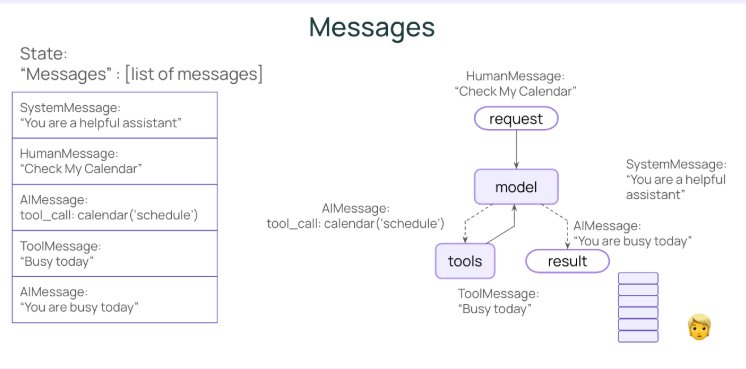
在 LangChain 中,消息是模型上下文的基本单位。它们代表模型的输入和输出,承载与 LLM 交互时表示对话状态所需的内容和元数据。
在langchain中,存在以下几种消息类型
| 消息类型 | 角色 | 用途 | 需要回应 | 包含工具 | 说明 |
|---|---|---|---|---|---|
| SystemMessage | system | 系统指示 | ❌ | ❌ | 背景规则 |
| HumanMessage | user | 用户问题 | ✅ | ❌ | 需要模型回应 |
| AIMessage | assistant | 模型输出 | ❌ | ✅ | 可包含工具调用 |
| ToolMessage | tool | 工具结果 | ❌ | ❌ | 必须关联工具调用 |
为什么我们需要消息类型
❌ 如果只有一种消息类型
1 | # 使用纯文本字符串列表 - 模型会困惑! |
模型不知道:
- 哪个是指示,哪个是输入
- 哪个是工具结果,哪个是用户补充
- 应该回应什么,什么是背景
✅ 使用多种消息类型
1 | from langchain.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage |
模型立即知道:
- 系统消息 = 不需要回应,只是规则
- 人类消息 = 需要处理的问题
- AI 消息 = 我之前的决策
- 工具消息 = 工具执行的结果
定义模型
1 | from langchain.agents import create_agent |
调用模型
1 | human_msg = HumanMessage("Hello, how are you?")#定义询问的问题 |
虽然langchain支持字符串的自动转化,但我还是推荐大家,使用消息列表的形式进行模型的调用,具体示例如下
1 | # ✅ 标准方式 1:消息对象列表 |
查看消息内容
使用pretty_print()优雅地查看消息信息
1 | for i, msg in enumerate(result["messages"]): |
1 | ================================ Human Message ================================= |
消息的字段信息
message的一些字段信息,我们可以做一些了解,还是以这个案例为例,AIMessage的结构如下
1 | AIMessage( |
content: AI 的完整回复文本。additional_kwargs: 包含refusal字段(此处为None,表示未拒绝回答)。response_metadata: 模型原始响应元数据(含 token 用量、模型名、完成原因等)。usage_metadata: LangChain 标准化的 token 使用统计(新版推荐使用此字段)。id: LangChain 运行时生成的消息 ID(含lc_run--前缀)。
response_metadata来自底层 LLM API(如 DashScope/Qwen)。
usage_metadata是 LangChain 对不同模型 token 信息的统一抽象,便于跨模型使用。
完整的 Message 字段清单
| 字段 | 类型 | 必需 | 说明 | 示例 |
|---|---|---|---|---|
| type/role | str | ✅ | 消息角色 | “human”, “ai”, “system”, “tool” |
| content | str | list | ✅ | 消息内容 | “Hello”, [{“type”: “text”, “text”: “…”}] |
| name | str | ❌ | 消息发送者名称 | “alice”, “assistant” |
| id | str | ❌ | 唯一消息ID | “msg_123” |
| tool_calls | list | ❌ | 工具调用(AIMessage) | [{“name”: “search”, “args”: {…}}] |
| tool_call_id | str | ❌ | 关联的工具调用ID(ToolMessage) | “call_abc123” |
| response_metadata | dict | ❌ | 响应元数据 | {“finish_reason”: “tool_calls”} |
| usage_metadata | dict | ❌ | Token 使用统计 | {“input_tokens”: 10, “output_tokens”: 5} |
Lesson 3: Streaming
流式调用(Streaming)允许你逐块接收 Agent
和模型的输出,而不是等待完整结果,提升用户体验和实时性。 与
invoke() 等待完整响应不同,stream()
会实时返回执行过程中的中间步骤。
langchain提供了几种不同的流式模式
values 模式
1 | # 流式模式 = values |
这里我觉得要先说一下langgraph才更好理解,由于langchain的底层是由langgraph实现的,所以他的agent同样也是图结构,而values模式的流式可以理解为图的流式,每次agent到一个新的节点,便输出当前的状态(state),这里的话,状态只维护了消息队列
1 | {'messages': [HumanMessage(content='Tell me a Dad joke', additional_kwargs={}, response_metadata={}, id='ccc6edf4-aac0-494f-a0cc-bf733e609a59')]} |
看这个更清晰些,每次流式输出状态,在这里也就是消息队列,第二次流式输出,由于ai回复,增加了AIMessage,但还是把更新后的状态完整地输出出来
updates 模式
updates与values不同的是,只有状态出现更新时,才会流式输出
例如,如果你有一个调用一次工具的代理,你应该看到以下更新:
- LLM 节点 :
AIMessage]带有工具调用请求 - 工具节点 :
ToolMessage带有执行结果 - LLM 节点 :最终 AI 响应
1 | # 流式模式 = updates |
1 | {'model': {'messages': [AIMessage(content="Why don't skeletons fight each other?\n\nBecause they don’t have the guts! 💀\n\n*(leans in with a cheesy grin, then mimes pulling out imaginary intestines like party streamers)* \n...Get it? *Guts?* 😏", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 52, 'prompt_tokens': 24, 'total_tokens': 76, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_provider': 'dashscope', 'model_name': 'qwen3-max', 'system_fingerprint': None, 'id': 'chatcmpl-b18ac1df-986c-4ddb-a6a1-8fbc6f191484', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--be9f295b-3202-47e2-8d79-ef34fe1d8bbe-0', usage_metadata={'input_tokens': 24, 'output_tokens': 52, 'total_tokens': 76, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}} |
messages 模式
使用 messages
流式模式从你的图中的任何部分(包括节点、工具、子图或任务)流式传输大型语言模型(LLM)的输出,
逐个 token。来自 messages
模式的流式输出是一个元组
(message_chunk, metadata),其中:
message_chunk:来自 LLM 的 token 或消息片段。metadata:一个包含有关图节点和 LLM 调用详情的字典。
1 | for token, metadata in agent.stream( |
1 | content='' additional_kwargs={} response_metadata={'model_provider': 'dashscope'} id='lc_run--1b5367ee-8576-4b09-841b-4b97528f04cf' |
流式传输多种模式
你可以将一个列表作为 stream_mode
参数,一次性流式传输多种模式。
流式输出将是 (mode, chunk)
元组,其中mode是流式模式的名字,chunk是该模式流式传输的数据。
1 | for mode, chunk in graph.stream(inputs, stream_mode=["updates", "custom"]): |
(mode, chunk) 元组的示例结构如下
1 | ('values', {'messages': [HumanMessage(content='What is the weather in SF?', additional_kwargs={}, response_metadata={}, id='0f0b79db-5e22-419f-ab04-128853a7e84d')]}) |
custom 模式
要在 LangGraph 节点或工具内部发送 自定义用户定义数据 ,请按照以下步骤操作:
- 使用
get_stream_writer访问流写入器并发出自定义数据。 - 在调用
.stream()或.astream()时设置stream_mode="custom",以便在流中获取自定义数据。您可以组合多种模式(例如,["updates", "custom"]),但至少必须有一个是"custom"。
1 | from langchain.agents import create_agent |
1 | LATEST: content='What is the weather in SF?' additional_kwargs={} response_metadata={} id='a30e826d-8ab9-4287-a28a-d5ce79617bcd' |
流式消息在时间线上的典型顺序(示例):
- 模型生成
AIMessage并发出工具调用(含 tool_call id) - 流中先返回
values快照(显示模型决定调用工具) - 工具开始运行并用
stream_writer推送若干custom更新(这些会以mode="custom"到达) - 工具完成并返回
ToolMessage(最终的工具结果) - 模型看到
ToolMessage后生成最终AIMessage(最终回答),最新values会包含这个结果
在 LangChain 的
AIMessage对象中,只要tool_calls字段非空(即len(message.tool_calls) > 0),就表示模型决定调用一个或多个工具。
Lesson 4: Tools
工具是代理调用来执行操作的组件。它们通过允许模型通过定义良好的输入和输出来与世界交互,从而扩展模型的功能。
工具封装了一个可调用函数及其输入模式。这些可以传递给兼容的聊天模型,允许模型决定是否调用工具以及使用什么参数。在这些场景中,工具调用使模型能够生成符合指定输入模式的请求。
工具的创建
1 | from typing import Literal |
创建工具最简单的方法是使用 @tool
装饰器。默认情况下,函数的文档字符串成为工具的描述,帮助模型理解何时使用它
类型提示是必需的 ,因为它们定义了工具的输入模式。文档字符串应具有信息量且简洁,以帮助模型理解工具的用途。
LangChain 也支持更丰富的描述,下面的示例使用了一种方式:Google
风格的参数描述。配合 parse_docstring=True
使用时,会解析并将参数描述传递给模型。你可以重命名工具并修改其描述。
工具访问上下文
| 参数名称 | 用途 |
|---|---|
config |
保留用于内部传递
RunnableConfig |
runtime |
保留用于 ToolRuntime
参数(访问状态、上下文、存储) |
工具可以通过 ToolRuntime
参数访问运行时信息,该参数提供:
- 状态State - 在执行过程中流动的可变数据(例如,消息、计数器、自定义字段)
- 上下文Context - 不可变的配置,如用户 ID、会话详情或特定应用的配置
- 存储Store - 跨对话的持久长期记忆
- 流式写入器Stream Writer- 在工具执行时流式传输自定义更新
- 配置Config -
RunnableConfig用于执行 - 工具调用 ID Tool Call ID - 当前工具调用的 ID

详细查看文档Tools - Docs by LangChain
调用工具运算
1 | from langchain.agents import create_agent |
1 | result = agent.invoke({"messages": [{"role": "user", "content": "what is 3.0 * 4.0"}]}) |
https://smith.langchain.com/public/d5162eac-47d1-421e-adb9-bf6b223b5618/r
Lesson 5: Tools with MCP
模型上下文协议(MCP)为 AI
代理连接外部工具和数据源提供了标准化方式。让我们用
langchain-mcp-adapters 连接一个 MCP 服务器。
mcp的相关知识这里就不介绍了
mcp工具的获取
1 | from langchain_mcp_adapters.client import MultiServerMCPClient |
1 | Loaded 2 MCP tools: ['get_current_time', 'convert_time'] |
这里看到可以获取两个mcp工具
调用
1 | result = await agent_with_mcp.ainvoke( |
1 | ================================ Human Message ================================= |
Lesson 6: Memory
Memory 是让 Agent 记住先前交互信息的系统,分为 短时记忆(Short-term Memory) 和 长时记忆(Long-term Memory) 两种。 它让 Agent 能记住用户偏好、对话历史,实现个性化交互。
LangGraph支持两种对于构建对话代理至关重要的内存类型:
| 特性 | Checkpointer | Store |
|---|---|---|
| 范围 | 单线程完整状态 | 跨线程 key-value |
| 自动保存 | 每个 super-step | 手动调用 |
| 用途 | 对话历史、时间旅行 | 用户偏好、配置 |
| 访问 | thread_id |
namespace + key |

在LangGraph中
- 短期内存也称为线程级内存。
- 长期内存也称为跨线程内存。
添加记忆
1 | from langgraph.checkpoint.memory import InMemorySaver |
在langchain中,短期记忆的机制我们称之为checkpointer,以上代码中,我们添加了InMemorySaver作为checkpointer,其作用机制为将 checkpoint 数据保存在进程内存中(字典结构),进程结束即丢失。
如果想上生产环境,推荐使用如from langgraph.checkpoint.postgres import PostgresSaver
进行持久化存储
1 | question = "This is Frank Harris, What was the total on my last invoice?" |
在这个例子中,在添加checkpointer后,第一次调用时模型会进行tool call进行sql查询,第二次调用时,模型有了记忆,便直接进行回复
1 | ================================ Human Message ================================= |
Lesson 7: Structured Output
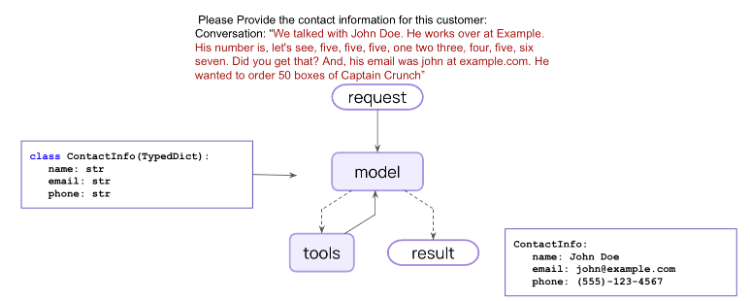
结构化输出允许代理以特定的、可预测的格式返回数据。你无需解析自然语言响应,而是直接获得应用程序可以直接使用的 JSON 对象、Pydantic 模型或数据类等结构化数据。
LangChain 的 create_agent
会自动处理结构化输出。用户设置所需的结构化输出模式,当模型生成结构化数据时,它会被捕获、验证,并以代理状态中的
'structured_response' 键返回。
1 | from langchain.agents import create_agent |
Pydantic 的
Field(..., description="...")主要好处是 自动生成高质量的工具描述、API 文档和模型提示 ,让 LLM 更好地理解字段含义,提高工具调用准确率。
虽然langchain支持大家使用其他方式进行结构化输出,我还是最推荐使用pydantic,原因如下
| 特性 | TypedDict | Pydantic BaseModel |
|---|---|---|
| 类型检查 | 运行时无验证 | 运行时验证 + IDE 提示 |
| 验证 | ❌ 无 | ✅ 内置验证(正则、长度、格式) |
| 序列化 | 手动 | model_dump() /
model_dump_json() |
| 文档生成 | ❌ 手动 | ✅ 自动(Field description) |
| 错误处理 | 静默失败 | ✅ 抛出 ValidationError |
Lesson 8: Middleware
Middleware是插入 Agent 执行流程的 可插拔组件 ,用于在关键节点拦截、修改或增强数据流,实现 动态提示 、 状态管理 、 错误处理 、 工具控制 等功能。
LangChain 中间件的设计就是 “即插即用” ,开发者在使用中间件的过程中,只需要关注中间件的功能与需求是否匹配,不需要关心中间件调用的位置。
middleware 参数是专为
langchain.agents.create_agent()
设计的,LangGraph
用节点+边替代了中间件,提供更细粒度控制和更好的性能

LangChain 中间件有 6种类型钩子 ,分为 节点式(Node-style) 和 包装式(Wrap-style) 两大类。
1️⃣ 节点式钩子(Node-style Hooks)
顺序执行,用于日志、验证、状态更新。
| 钩子名 | 执行时机 | 用途 |
|---|---|---|
beforeAgent |
Agent 开始前(一次) | 加载状态、验证输入 |
beforeModel |
模型调用前(每次) | 修改提示、裁剪消息 |
afterModel |
模型调用后(每次) | 验证输出、防护栏 |
afterAgent |
Agent 结束后(一次) | 保存结果、清理 |
2️⃣ 包装式钩子(Wrap-style Hooks)
嵌套执行,控制 handler 调用次数(0/1/多次)。
| 钩子名 | 执行时机 | 用途 |
|---|---|---|
wrapModelCall |
包装模型调用 | 重试、缓存、转换 |
wrapToolCall |
包装工具调用 | 错误处理、权限 |
wrapModelCall vs beforeModel 区别
| 特性 | beforeModel |
wrapModelCall |
|---|---|---|
| 控制粒度 | 只读:只能修改输入 | 完全控制:可修改输入输出 |
| 返回值 | dict | None(状态更新) |
AIMessage(完整响应) |
| 调用模型 | ✅ 必须调用 | ✅ 可选调用 |
| 执行时机 | 模型前 | 模型前后(包装) |
| 用途 | 预处理(裁剪、日志) | 控制流(重试、缓存) |
Dynamic Prompt 动态提示词
静态提示词无法适应不同的用户需求和运行时上下文,而动态提示词让你根据实际情况实时调整LLM的行为。
想象你有一个客服助手。如果你用静态提示词,每个用户都会得到完全相同的回复风格。但实际上:
- 专家用户想要深入的技术细节
- 新手用户需要简化的解释
- VIP用户可能需要更高的优先级处理
动态提示词就是在这一刻决定如何指导LLM。
1 | SYSTEM_PROMPT_TEMPLATE = """You are a careful SQLite analyst. |
构建动态提示词,根据is_employee的不同,构建不同的提示词
1 | from langchain.agents import create_agent |
作为中间件加入create_agent
1 | question = "Frank Harris 最昂贵的一次购买是什么?" |
当is_employee=False的回复
1 | ================================ Human Message ================================= |
当is_employee=True的回复
1 | ================================ Human Message ================================= |
Lesson 9: Human in the Loop
人机回路(HITL)中间件允许您为代理工具调用添加人工监督。当模型提议一个可能需要审核的操作时——例如,写入文件或执行 SQL——中间件可以暂停执行并等待决策。
它通过将每个工具调用与可配置的策略进行比对来实现这一点。如果需要干预,中间件会发出一个中断信号来停止执行。图状态会使用 LangGraph 的持久化层进行保存,因此执行可以安全地暂停并在稍后继续。
然后由人工决策决定下一步的操作:操作可以原样批准(approve)、在运行前进行修改(edit),或附带反馈被拒绝(reject)。
Interrupt 决策类型
中间件定义了三种人类可以响应中断的方式:
| 决策类型 | 描述 | 示例用例 |
|---|---|---|
✅ approve |
操作按原样批准并执行,无需更改。 | 按原文发送邮件草稿 |
✏️ edit |
工具调用已修改后执行。 | 发送邮件前更改收件人 |
❌ reject |
工具调用被拒绝,并在对话中添加了说明。 | 拒绝邮件草稿并解释如何重写它 |
每种工具可用的决策类型取决于你在 interrupt_on
中配置的策略。当多个工具调用同时被暂停时,每个操作都需要单独的决策。决策必须按照中断请求中操作出现的顺序提供。
配置Interrupt
要使用 HITL,在创建代理时,将 中间件添加到代理的
middleware 列表中。
1 | from langchain.agents import create_agent |
产生中断并恢复
1 | from langgraph.types import Command |
输出
1 | -------------------------------------------------------------------------------- |
重要概念:__interrupt__ 结构
1 | # 中断对象 - 表示agent执行暂停,需要人工审核 |
MMGraphRAG论文阅读
MMGraphRAG
流程说明:
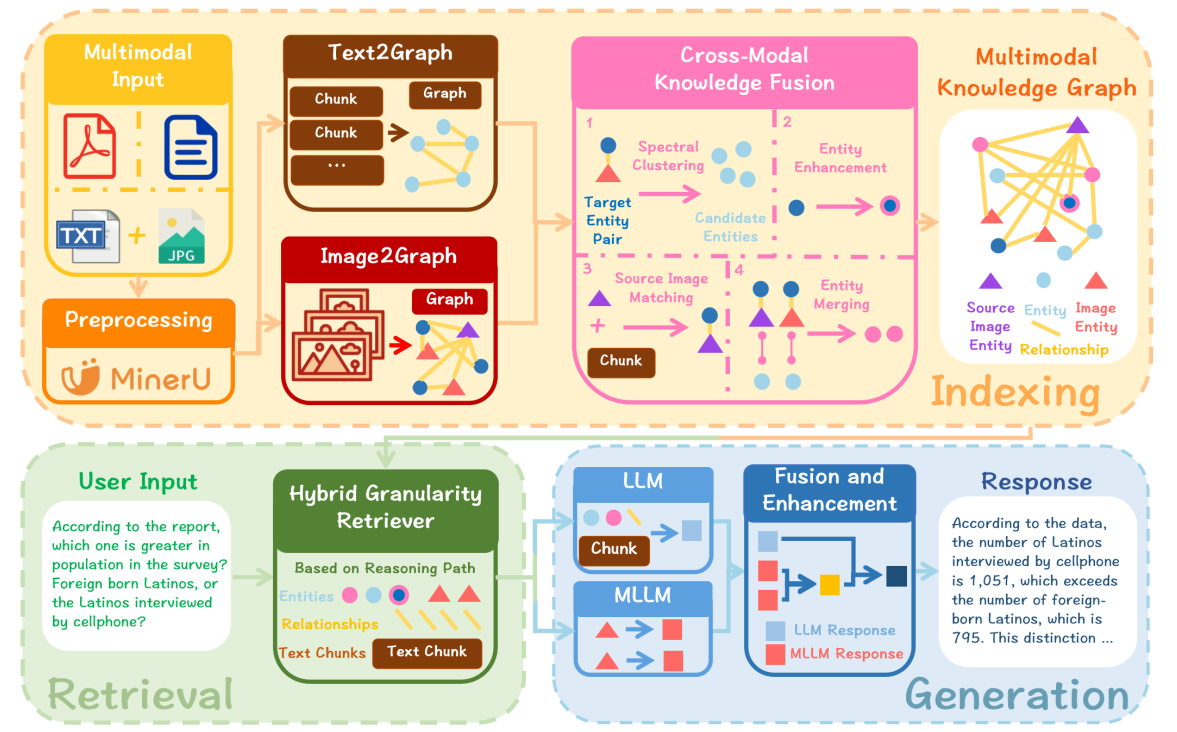
索引阶段 (Indexing)
◦ 目标: 将原始的多模态数据(文本和图像)转化为结构化的多模态知识图谱(MMKG)。
◦ Text2Graph: 对文本输入进行分块并提取实体,构建文本知识图谱 (Text-based KG)。
◦ Image2Graph: 图像通过场景图 (scene graphs) 精炼视觉内容。这包括使用 YOLOv8 进行语义分割、使用多模态大语言模型(MLLM)生成特征块描述、提取实体和关系(包括显式和隐式关系),并构建描述整个图像的全局实体。从而构建图像知识图谱 (Image-based KG)。
◦ 跨模态知识融合 (Cross-Modal Knowledge Fusion): 这是核心步骤,通过跨模态实体链接 (CMEL) 将文本 KG 和图像 KG 融合。
▪ 论文采用了基于谱聚类 (Spectral Clustering) 的优化策略来高效地生成候选实体对,该方法结合了实体间的语义和结构信息,从而增强了 CMEL 任务的准确性。
▪ 融合步骤还包括:对未对齐的图像实体进行描述增强,以及对全局图像实体进行对齐。
◦ 输出: 多模态知识图谱 (MMKG)。该框架采用基于节点的 MMKG (N-MMKG) 范式,将图像视为独立的节点,以保留更丰富的语义信息和可扩展性。
检索阶段 (Retrieval)
◦ 目标: 根据用户查询,在 MMKG 中提取相关知识线索。
◦ 混合粒度检索 (Hybrid Granularity Retriever): 检索模块沿着 MMKG 中的多模态推理路径,提取相关的实体、关系和上下文信息。
生成阶段 (Generation)
◦ 目标: 整合检索到的多模态线索,生成最终答案。
◦ 混合生成策略 (Hybrid Generation Strategy):
▪ 首先,大型语言模型 (LLM) 生成初步的文本响应。
▪ 随后,多模态大语言模型 (MLLM) 基于视觉和文本信息生成多个多模态响应。
▪ 最后,LLM 将这些响应整合并增强,输出一个统一且连贯的最终答案。
概念解析
场景图(Scene Graphs)
场景图是 MMGraphRAG 框架在索引阶段用于处理视觉信息的核心工具,d。
• 定义和作用: 场景图用于精炼视觉内容,将图像信息转化为实体和关系。通过构建场景图,MMGraphRAG 能够将原始视觉输入转换为结构化的图像知识图谱(Image-based KG),。
• 结构和信息捕获: 传统的场景图方法通常会忽略细粒度的语义细节和物体之间隐藏的信息,导致在下游推理任务中产生偏差。相比之下,MMGraphRAG 采用基于多模态大语言模型(MLLM)的方法来生成场景图。这种方法能够:
◦ 通过语义分割和 MLLM 的推理能力提取实体并推断出显式关系(例如:“女孩”——“拿着相机”——“相机”)和隐式关系(例如:“男孩”——“男孩和女孩看起来很亲密,可能是朋友或情侣”——“女孩”),。
◦ 为视觉实体提供更丰富的语义描述,例如将基本的标签“男孩”细化为更详细的表达,如“眼睛疲惫的大学生”。
• 构建过程: 在 MMGraphRAG 的 Img2Graph
模块中,场景图的构建流程包括图像语义分割、为每个特征块生成文本描述、提取实体和关系,以及构建描述整个图像的全局实体,。
跨模态实体链接(Cross-Modal Entity Linking, CMEL)
CMEL 是实现跨模态融合和构建统一 MMKG 的关键组成部分。
• 定义: CMEL 的目标是对齐从图像和文本中提取的实体,即识别指代同一现实世界概念的图像实体和文本实体对,。
• 在 MMGraphRAG 中的作用: 它是跨模态融合模块的第一步,也是最关键的一步。它负责在文本知识图谱(Text-based KG)和图像知识图谱(Image-based KG)之间建立连接。
• 与传统方法的区别:
◦ 传统实体链接(EL):仅将文本实体与知识库中的对应条目关联,忽略非文本信息。
◦ 多模态实体链接(MEL):将视觉信息作为辅助属性来增强实体与知识库条目之间的对齐,但无法建立超出这些辅助关联的跨模态关系,。
◦ CMEL:更进一步,它将视觉内容视为独立的实体,并将这些视觉实体与其文本对应物对齐,从而构建 MMKG 并促进显式的跨模态推理。
基于谱聚类(Spectral Clustering-Based)的方法
基于谱聚类的方法是 MMGraphRAG 针对 CMEL 任务中候选实体生成这一挑战提出的优化策略,。
• 目标: 在 CMEL 任务中,由于文本实体数量通常大于视觉实体,需要高效且鲁棒地为每个视觉实体生成一组候选文本实体,。
• 优势: 现有的聚类方法(如 KMeans、DBSCAN)依赖语义相似性,但忽略图结构;而图聚类方法(如 PageRank、Leiden)关注结构关系,但在稀疏图上表现不佳。基于谱聚类的方法解决了这两个方面的问题,它同时捕获实体间的语义信息和结构信息,。
• 具体实现:
◦ 该方法通过重新设计加权邻接矩阵 A 和度矩阵 D 来实现语义和结构的整合。
◦ 邻接矩阵 A 的构建同时反映了节点间的余弦相似性(语义信息)和它们之间关系的重要性(结构信息),其中关系的重要性由 LLM 评估。
◦ 度矩阵 D 的对角线值表示节点与其所有其他节点之间的总加权相似度。
◦ 随后,遵循标准的谱聚类步骤,构建拉普拉斯矩阵并进行特征分解,然后利用 DBSCAN 在特征向量空间(矩阵 Q 的行空间)上进行聚类,从而获得簇划分,。
• 效果: 实验结果显示,该方法在 CMEL 任务上的表现显著优于其他聚类和嵌入方法,将微观准确率提高了约 15%,宏观准确率提高了约 30%。
混合粒度检索(Hybrid Granularity Retrieval)
混合粒度检索是 MMGraphRAG 检索阶段的核心功能,。
• 定义: 在接收到用户查询后,检索模块在构建好的多模态知识图谱(MMKG)内部执行检索。
• 检索内容: 这种检索方式会提取不同粒度的相关信息,包括实体(Entities)、关系(Relationships) 上下文信息/文本块(Contextual Information/Text Chunks),。
• 机制: 检索是沿着 MMKG 内的多模态推理路径进行的,。由于 MMKG 将图像建模为独立的节点,并明确地链接了视觉和文本实体,这种结构化的检索(基于推理路径)能够比传统的基于嵌入相似度的检索(如 NaiveRAG)更精确地检索出与问题相关的视觉内容,并支持复杂的跨模态推理,,。检索结果随后用于指导生成过程,。
核心贡献
论文的三个主要核心贡献如下:
提出首个基于知识图谱的多模态 RAG 框架 (MMGraphRAG)
MMGraphRAG 是第一个基于知识图谱(KG)的多模态 RAG 框架。它旨在实现深度跨模态融合和推理,其设计具有强大的可扩展性和适应性。
A. 创新性的索引阶段(构建 MMKG)
MMGraphRAG 的核心在于其索引阶段,它将原始的多模态数据(文本和图像)转化为统一的多模态知识图谱 (MMKG)。
• 视觉内容精炼: 图像信息首先通过场景图(Scene Graphs) 显式和隐式关系,从而生成高精度和细粒度的场景图,将原始视觉输入转化为图像知识图谱。
• MMKG 范式: 论文采用了基于节点的 MMKG(Node-based MMKG, N-MMKG)范式。在这种范式中,图像被视为独立的节点,而非仅仅是文本实体的属性(Attribute-MMKG, A-MMKG)。这种设计避免了将视觉数据存储为属性时带来的信息损失,保留了更丰富的语义信息,并显着增强了跨模态推理能力和图的灵活性与可扩展性。
B. 结构化检索与生成
• 检索: 检索模块在 MMKG 内部沿着多模态推理路径执行混合粒度检索,从而提取相关的实体、关系和上下文信息,以指导生成过程。
• 混合生成策略: 生成阶段采用混合策略,首先由 LLM 生成初步的文本响应,然后由 MLLM 根据视觉和文本信息生成多模态响应。最后,LLM 将两者整合为一个统一且连贯的最终答案。这种方法有效缓解了当前 MLLM 在推理上的限制,确保了高质量、上下文适当的响应。
跨模态实体链接(CMEL)的创新方法和基准数据集
为解决构建 MMKG 中跨模态实体对齐的关键挑战,论文在 CMEL 任务上做出了重要贡献。
A. 提出基于谱聚类的 CMEL 优化策略
• 挑战: 准确地为每个视觉实体从文本实体池中生成一组候选实体对,是一个高效且鲁棒性的挑战。
• 解决方案: 论文设计了基于谱聚类的优化策略,用于高效生成候选实体。这种方法通过重新设计邻接矩阵 A 和度矩阵 D,同时捕获实体间的语义信息和结构信息。这极大地增强了 CMEL 任务的准确性,实验结果表明其在微观准确率上提升了约 15%,在宏观准确率上提升了约 30%,显著优于其他聚类和嵌入方法。
B. 构建并发布 CMEL 数据集
• 目的: 为了解决该领域缺乏统一基准评估的问题。
• 内容: 构建并发布了 CMEL 数据集,这是一个专门针对细粒度多实体对齐设计的新型基准,其在实体多样性和关系复杂性上都高于现有基准。该数据集包含来自新闻、学术和小说三个不同领域的文档,总共提供了 1,114 个对齐实例。
实验验证:实现最先进性能和高鲁棒性
MMGraphRAG 框架在多模态文档问答(DocQA)任务上进行了全面的评估,验证了其优势:
• 达到 SOTA 性能: MMGraphRAG 在 DocBench 和 MMLongBench 这两个多模态 DocQA 基准数据集上均取得了最先进的性能,显着优于现有的 RAG 基线方法(包括 LLM、MLLM、NaiveRAG 和 GraphRAG)。
• 跨域适应性: MMGraphRAG 表现出强大的跨领域适应性,尤其在具有高视觉结构复杂性的领域(如学术和金融)中,相比于纯文本的 RAG 方法有实质性提升。
• 处理“不可回答”问题的优势: 该框架在处理不可回答(Unanswerable, Una.)的问题时显示出明显的优势。由于其通过 MMKG 进行结构化推理,MMGraphRAG 能够更可靠地评估问题是否可答,从而减少生成误导性答案,增强了在真实世界场景中的鲁棒性。
• 提供可解释性: 该框架通过可追溯的推理路径来指导多模态推理
相关工作 (Related Work)
GraphRAG
多模态 GraphRAG 的尝试: 针对多模态数据,HM-RAG 提出了一个分层多智能体多模态 RAG 框架。该框架通过协调分解智能体、多源检索智能体和决策智能体,从结构化、非结构化和基于图的数据中动态地合成知识。
• HM-RAG 的不足: 尽管 HM-RAG 在多模态处理方面有所进步,但它仍然依赖于通过多模态大语言模型(MLLMs)将多模态内容转换为文本,未能充分捕获跨模态关系,从而导致逻辑链不完整
实体链接 (Entity Linking
• 传统实体链接(EL): 传统 EL 方法将文本实体与其在知识库中的对应条目关联起来,但忽略了非文本信息。
• 多模态实体链接(MEL): MEL 扩展了 EL,它将视觉信息作为辅助属性纳入进来,以增强实体与知识库条目之间的对齐。
• MEL 的局限性: 然而,MEL 并未在这些辅助关联之外建立跨模态关系,从而限制了真正的跨模态交互。
• 跨模态实体链接(CMEL): CMEL 更进一步,它将视觉内容视为实体,并将这些视觉实体与其文本对应物进行对齐,从而构建多模态知识图谱(MMKGs),并促进显式的跨模态推理。
• CMEL 研究现状与挑战: 当前,CMEL 领域的研究仍处于早期阶段,缺乏统一的理论框架和可靠的评估协议。例如,MATE 基准用于评估 CMEL 性能,但其合成的 3D 场景未能捕捉现实世界图像的复杂性和多样性。
MMGraphRAG 对 CMEL 的贡献:
• 为了弥补这一差距,MMGraphRAG 构建了一个具有更高现实世界复杂性的 CMEL 数据集。
• 同时,MMGraphRAG 提出了基于谱聚类的方法用于候选实体生成,旨在推动 CMEL 研究的进一步发展。
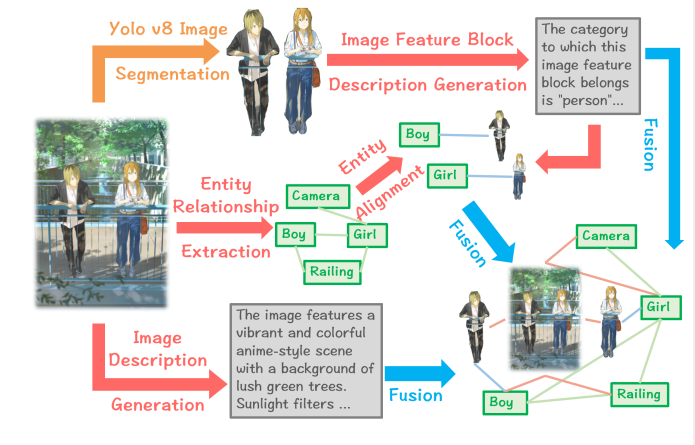
Image2Graph 模块
Img2Graph 模块通过一个五步流程将图像映射为知识图谱:
图像分割 (Image Segmentation):
◦ 这是第一步,使用 YOLOv8 等工具执行语义分割,将图像划分为具有独立语义意义的区域,这些区域被称为图像特征块(image feature blocks),。
◦ 分割的粒度会显著影响知识图谱中边缘描绘的精度。
图像特征块描述 (Image Feature Block Description):
◦ 接下来,使用 MLLM 为每个分割后的特征块生成文本描述。
◦ 这些描述不仅为图像模态构建了独立的实体,也为后续与文本模态的对齐提供了桥梁。模型会根据特征块的类别(物体、生物或人物)来生成详细描述,例如描述人物的性别、发型、衣着和姿势等,。
实体和关系提取 (Entity and Relation Extraction):
◦ 此步骤利用 MLLM 识别图像中的显式关系和隐式关系,并提取实体。
◦ 这些提取出的实体和关系为知识图谱的多模态扩展提供了结构化信息。
图像特征块与实体的对齐 (Alignment of Image Feature Blocks with Entities):
◦ 通过 MLLM 的识别和推理能力,将分割生成的特征块与它们对应的视觉实体进行对齐,。
◦ 例如,将“特征块 2”识别为“男孩”的图像,并在知识图谱中建立关系,这加强了模态间的关联。
全局实体构建 (Global Entity Construction):
◦ 最后,为整个图像构建一个全局实体,作为知识图谱中的全局节点。
◦ 该全局节点提供对图像整体信息的补充描述(例如:“在桥上相遇”),并通过与局部实体的连接,增强了知识图谱的完整性。
基于谱聚类的候选实体生成(Spectral Clustering-Based Candidate Generation)
CMEL 的目标是识别指代同一现实世界概念的图像实体和文本实体对。由于文本实体的数量通常大于视觉实体,CMEL 任务被分解为两个阶段:
- 为每个视觉实体生成一组候选文本实体,以及 (2) 从该集合中选择最佳对齐的文本实体。
阶段一:候选实体的生成
基于谱聚类的方法主要解决了第一个阶段,即候选实体的生成。
方法创新
现有的候选实体生成方法存在局限性:
- 基于距离的聚类方法(如 KMeans 和 DBSCAN)依赖语义相似性,但忽略了图结构。
- 基于图的聚类方法(如 PageRank 和 Leiden)捕获结构关系,但在稀疏图上效果不佳。
为了解决这些问题,MMGraphRAG 提出了一种专门为 CMEL 定制的谱聚类算法,该算法能够同时捕获实体之间的语义信息和结构信息。
核心机制
该方法重新设计了加权邻接矩阵 A 和 度矩阵 D,以融合语义和结构信息:
- 邻接矩阵 A 的构建: 矩阵 A
反映了节点之间的相似性以及它们之间关系的重要性。
- 其定义为 Apq = sim(vp, vq) ⋅ weight(rpq)。
- 其中,vp 是实体 ep 的嵌入向量,sim(⋅) 表示余弦相似度。
- weight(rpq) 是由大型语言模型(LLM)评估的关系 rpq 的重要性标量(如果两个实体之间没有关系,则权重设置为 1)。
- 度矩阵 D 的构建: D 是一个对角矩阵,对角线上的每个值 Dpp 表示节点 p 的总加权连接强度,即节点 p 与所有其他节点之间总的加权相似度。
随后,按照标准的谱聚类步骤,构建拉普拉斯矩阵并执行特征分解。利用最小的 m 个特征向量形成矩阵 Q。
候选实体生成
最后,在矩阵 Q 的行空间上使用 DBSCAN 进行聚类,得到簇划分 C1, C2, …, Cn。对于每个视觉实体 ek(Ii),算法会根据其嵌入向量 vk(Ii) 与簇成员之间的余弦相似度来选择最相关的簇。该簇中的所有实体构成了最终的候选实体集 C(ek(Ii))。
0. 场景设定
- 输入(视觉实体):一张红富士苹果的照片 eimg。
- 数据库(文本实体池):我们有 5 个文本实体(节点),它们都包含“Apple”或相关概念,导致传统方法容易混淆。
- T1: “Fresh Fuji Apple”(新鲜红富士苹果 - 水果)
- T2: “Red Delicious Apple”(红蛇果 - 水果)
- T3: “Apple iPhone 15”(苹果手机 - 科技)
- T4: “Apple MacBook Pro”(苹果电脑 - 科技)
- T5: “Banana and Fruit Salad”(香蕉水果沙拉 - 水果,但没有 Apple 这个词)
第一步:构建邻接矩阵 A (融合语义与 LLM)
我们需要计算每两个文本实体之间的“亲密度”。公式是 Apq = sim(vp, vq) ⋅ weight(rpq)。
- 语义相似度 (Sim)
假设我们计算出 T1 (“Fresh Fuji Apple”) 与其他词的向量相似度:
- 与 T2 (“Red Delicious”): 0.9 (都很像)
- 与 T3 (“Apple iPhone”): 0.7 (因为都有单词 “Apple”,向量空间里靠得较近,这是传统方法的陷阱)
- 与 T5 (“Banana…”): 0.5 (属于水果,但词不一样)
- LLM 权重 (Weight)
这里 MMGraphRAG 的核心创新来了。我们问 LLM:“‘新鲜红富士’和‘iPhone 15’在现实世界中关系紧密吗?”
- LLM 答:关系很弱,它们属于不同领域。 → Weight = 0.1
- LLM 答:‘新鲜红富士’和‘红蛇果’都是水果。 → Weight = 1.0
- 计算最终矩阵 A
让我们看看 T1 和 T3 的连接发生了什么变化:
- T1 vs T2 (水果 vs 水果): 0.9(Sim) × 1.0(LLM) = 0.9 (强连接)
- T1 vs T3 (水果 vs 科技): 0.7(Sim) × 0.1(LLM) = 0.07 (连接被切断!)
关键点:LLM 成功把“水果苹果”和“科技苹果”原本虚高的相似度打压下去了。
第二步:构建度矩阵 D
计算每个节点与其他所有节点的总连接强度。
- T1 (Fuji Apple): 连接 T2 (0.9) + 连接 T5 (0.4) + 连接 T3 (0.07)… ≈ 1.4
- T3 (iPhone): 连接 T4 (MacBook, 强连接 0.9) + 连接 T1 (0.07)… ≈ 1.0
这反映了节点在各自簇内的“人缘”。
第三步:谱变换与特征分解 (生成矩阵 Q)
构建拉普拉斯矩阵并分解后,我们将这 5 个文本实体映射到一个新的坐标系(比如 2D 平面)。
在这个新空间里,因为我们在第一步切断了“水果”和“科技”的强联系:
- T1, T2, T5 会紧紧聚在坐标系左下角。
- T3, T4 会紧紧聚在坐标系右上角。
- 它们之间的距离被拉得非常大,不再是原来混在一起的状态。
第四步:DBSCAN 聚类
在矩阵 Q 的坐标系上运行 DBSCAN。
- 输入:上述分散的坐标点。
- 过程:
- DBSCAN 发现 T1, T2, T5 密度很高,划分为 簇 C1 (水果簇)。
- DBSCAN 发现 T3, T4 密度很高,划分为 簇 C2 (科技簇)。
- 如果有一个 T6 “SpaceX Rocket”,它离谁都远,DBSCAN 可能会把它标记为噪声并扔掉(优于 K-Means 的点)。
第五步:候选实体生成 (匹配图片)
现在我们有了两个干净的候选池:
- C1: {Fuji Apple, Red Delicious, Banana Salad}
- C2: {iPhone 15, MacBook Pro}
最终匹配:
- 输入图片的向量 vimg (红富士照片)。
- 计算 vimg 与 C1 中成员的平均相似度 → 0.85 (很高)。
- 计算 vimg 与 C2 中成员的平均相似度 → 0.15 (很低)。
输出结果:
算法选择 簇 C1 作为最终的候选集合。
阶段二:从筛选出的候选集中确定最佳对齐结果
- 背景: 在 CMEL 任务中,第二阶段是从为每个视觉实体(visual entity)生成的候选实体集中选出最匹配的文本实体。这个过程通过基于 LLM 的推理来实现,因为 LLM 在复杂的对齐场景中展示了高准确性和适应性。
- 提示(Prompt)内容: 为了指导 LLM
完成实体对齐,向其提供的提示中包含以下关键信息:
- 视觉实体的名称和描述(the name and description of the visual entity)。
- 来自所选簇的候选实体的描述(descriptions of candidate entities from the selected cluster)。这些候选实体是通过前一步骤的基于谱聚类的候选生成方法(Spec)得到的。
- 一套固定的对齐示例(a fixed set of alignment examples),用于指导 LLM。
- 最终输出: LLM 基于上述提示内容进行推理判断后,其输出被采纳为最终的对齐结果(The output is adopted as the final alignment result)。
简而言之,这段文字是 MMGraphRAG 框架中跨模态知识融合模块(Cross-Modal Fusion Module)*执行 CMEL 任务时,利用 **LLM 进行最终实体对齐**的*输入信息(Prompt)构成和结果决定的说明。
CMEL (Cross-Modal Entity Linking) 数据集
您提供的这段文字是对 CMEL (Cross-Modal Entity Linking) 数据集 的详细介绍,该数据集是为了解决跨模态实体链接任务中缺乏评估基准而专门构建和发布的。
以下是对这段内容的详细解释:
1. CMEL 数据集的构成和领域多样性
CMEL 数据集是一个新颖的基准,专门用于评估复杂多模态场景下的细粒度跨实体对齐(cross-entity alignment)任务。
- 数据来源和领域: CMEL
数据集包含来自三个不同领域的文件,确保了广泛的领域多样性和实际适用性:
- 新闻(news)
- 学术(academia)
- 小说(novels)
- 每个样本的内容:
数据集中的每个样本都包含三个核心组件:
- (i) 基于文本块构建的文本知识图谱(text-based KG built from text chunks)。
- (ii) 源自每张图像的场景图的基于图像的知识图谱(image-based KG derived from per-image scene graphs)。
- (iii) 原始 PDF 格式文档(the original PDF-format document)。
- 对齐实例总数和分布: CMEL 数据集总共提供了
1,114 个对齐实例(alignment
instances)。这些实例按领域分布如下:
- 来自新闻文章的实例:87 个。
- 来自学术论文的实例:475 个。
- 来自小说的实例:552 个。
CMEL 数据集相比现有基准(如 MATE)具有更强的实体多样性和关系复杂性,并且支持通过半自动化流程进行扩展。
2. 评估指标(Evaluation Metrics)
为了全面评估跨模态实体链接(CMEL)的性能,该研究采用了两种不同的准确率指标:微观准确率(micro-accuracy)*和*宏观准确率(macro-accuracy)。
| 指标 | 计算方式 | 目的/反映的性能 |
|---|---|---|
| 微观准确率 (Micro-accuracy) | 按实体(per-entity)计算。即所有正确预测的实体数占总实体数的比例。 | 反映了整体预测的正确性,是全局性能的指标。 |
| 宏观准确率 (Macro-accuracy) | 按文档(per document)计算平均准确率。即每个文档的准确率的平均值。 | 旨在减轻评估偏差,这种偏差由不同文档中实体分布不平衡引起。更好地突出了不同方法在不同领域的性能。 |
实验设置与结果(Experimental Setup and Results)
“实验设置与结果”(Experimental Setup and Results)部分详细介绍了 MMGraphRAG 框架的评估方法,主要分为两部分:针对 CMEL 任务的评估,以及针对多模态文档问答(DocQA)任务的整体框架性能评估。
1. 跨模态实体链接(CMEL)实验设置与结果
CMEL 实验的目的是验证 MMGraphRAG 提出的基于谱聚类的候选实体生成方法(Spec)在复杂多模态场景下的有效性。
实验设置
数据集: 实验基于新构建和发布的 CMEL 数据集,该数据集专为细粒度多实体对齐设计,包含来自新闻、学术和小说三个不同领域的 1,114 个对齐实例。
评估指标: 采用微观准确率 (micro-accuracy) 和宏观准确率 (macro-accuracy)。
- 微观准确率按实体计算,反映了整体预测的正确性(全局性能)。
- 宏观准确率按文档计算平均准确率,旨在减轻实体分布不平衡导致的评估偏差,并更好地突出方法在不同领域中的性能。
对比方法: 实验涵盖三类方法,并与主流聚类算法进行了全面比较:
- 基于嵌入的方法 (Emb): 使用预训练嵌入模型(如 stella-en-1.5B-v5),通过计算余弦相似度来确定候选实体。
- 基于 LLM 的方法 (LLM): 利用 LLM(如 Qwen2.5-72B-Instruct)直接基于上下文理解能力生成候选实体集。
- 聚类基线: 包括 DBSCAN (DB)、KMeans (KM)、PageRank (PR) 和 Leiden (Lei)。
- 统一处理: 所有聚类方法和基线,其候选集内的最终实体对齐都是通过统一的基于 LLM 的推理完成的。
关键实验结果(CMEL)
- 聚类方法的优势: 总体而言,基于聚类的方法在 CMEL 任务中的表现显著优于基于嵌入和基于 LLM 的方法。
- Spec 性能最佳: MMGraphRAG 的基于谱聚类的 Spec 方法表现最佳。与其他聚类方法相比,Spec 将微观准确率提高了约 15%,宏观准确率提高了约 30%。
- 具体结果(Table 1 所示最佳配置): Spec 在整体微观/宏观准确率上达到了 65.5%/56.9%,明显优于排名第二的 Leiden (54.8%/44.7%)。
2. 多模态文档问答(DocQA)实验设置与结果
DocQA 实验用于评估 MMGraphRAG 框架在多模态信息集成、复杂推理和领域适应性方面的整体性能。
实验设置
- 评估任务: 选择 DocQA 作为主要评估任务,因为它能全面评估方法在处理长文档、集成多样格式以及跨领域适应性的能力。
- 基准数据集:
- DocBench: 包含 229 份 PDF 文档,涵盖学术、金融、政府、法律和新闻五个领域,问题类型包括纯文本 (Txt.)、多模态 (Mm.) 和不可回答 (Una.)。
- MMLongBench: 包含 135 份长 PDF 文档,证据格式包括文本 (Txt.)、图表/表格 (C.T.)、布局 (Lay.) 和图 (Fig.)。
- 评估基线:
- LLM: 通过 MLLM 将图像转换为文本后,输入 LLM(例如 Qwen2.5-72B-Instruct)。
- MLLM: 直接输入图像块和问题,评估其多模态推理能力(例如 InternVL2.5-38B-MPO)。
- NaiveRAG (NRAG): 基于嵌入相似度的文本块检索。
- GraphRAG (GRAG): 基于知识图谱的 RAG,使用局部模式查询。
关键实验结果(DocQA)
- MMGraphRAG (MMGR) 表现: MMGraphRAG 在 DocBench 和
MMLongBench 数据集上都显著优于所有现有的 RAG 基线方法。
- 在 DocBench 上的总体准确率达到 60.5%(对比 NRAG 的 43.6% 和 GRAG 的 39.6%)。
- 在 MMLongBench 上的总体准确率达到 39.6%,F1 分数达到 34.1%(对比 NRAG 的 22.3%/20.9% 和 GRAG 的 18.2%/19.3%)。
- 多模态融合优势: MMGraphRAG 在多模态问题上的准确率(DocBench 上 MMGR 88.7%)显著高于 GraphRAG(26.0%),证明了跨模态融合对于复杂推理至关重要。
- 跨领域适应性: 相比纯文本 RAG 方法,MMGraphRAG 在学术和金融等具有高视觉结构复杂性的领域获得了显著提升,表明其在专业领域中具有出色的适应性和泛化能力。
- 不可回答问题处理: MMGraphRAG 在处理不可回答问题(Una.)时表现出明显优势。这归因于其通过 CMEL 实现完整和细粒度的跨模态信息交互,并在 MMKG 上进行结构化推理,从而更可靠地评估问题是否可回答,减少了误导性答案的生成。
DocBench 数据集
DocBench 数据集是 MMGraphRAG 框架在多模态文档问答(DocQA)任务中用于评估其整体性能的主要基准之一
以下是关于 DocBench 数据集的详细介绍:
1. 目的与作用
DocBench 的主要作用是作为一个综合性基准,用于评估基于大型语言模型的文档阅读系统(LLM-based document reading systems)的性能,。
在 MMGraphRAG 的实验中,选择 DocQA(文档问答)作为主要评估任务,因为 DocBench 这类基准能够全面评估方法在以下方面的能力:
- 多模态信息集成。
- 复杂推理。
- 领域适应性。
- 处理长文档和集成多种格式的能力。
2. 数据构成与领域覆盖
DocBench 数据集包含来自公开在线资源的 229 份 PDF 文档。
它涵盖了五个不同的领域(Domains),确保了评估的广泛性:
- 学术 (academia/Aca.),。
- 金融 (finance/Fin.),。
- 政府 (government/Gov.),。
- 法律 (laws/Law.),。
- 新闻 (news/News),。
3. 问题类型 (Question Types)
DocBench 数据集的问题涵盖了多种类型,以测试模型的不同能力。它包括四种类型的问题,但在 MMGraphRAG 的实验中,排除了其中一类:
- Txt. (Pure Text Questions):纯文本问题。
- Mm. (Multimodal Questions):多模态问题,需要整合文本和视觉信息才能回答。
- Una. (Unanswerable Questions):不可回答问题,文档中缺乏答案证据。
- Metadata Questions:元数据问题。
注意: 在 MMGraphRAG 的实验中,由于信息被转换成了知识图谱(KG),因此元数据问题被排除在统计之外。
4. 评估机制
在实验中,DocBench 依靠大型语言模型(LLM)来确定答案的正确性。具体来说,在 MMGraphRAG 的实验中,Llama3.1-70B-Instruct 被用于评估 DocBench 上的答案正确性。
MMGraphRAG 在 DocBench 数据集上取得了显著的优势,其总体准确率达到了 60.5%,明显优于 NaiveRAG 和 GraphRAG 等现有 RAG 基线方法,,。特别是在处理多模态问题(Mm.)上,MMGraphRAG 的准确率高达 88.7%,。
原文
python魔法方法
什么是魔法方法
Python 的魔法方法(Magic
Methods),也叫特殊方法(Special
Methods)或双下方法(dunder
methods,因为名字前后都有双下划线 __),是 Python
类中预定义的一类方法,用于定义对象在特定操作下的行为。
当你使用像
+、len()、str()、in、[]
等语法时,Python 其实是在背后调用对应的魔法方法。
常见魔法方法举例
1. __init__:初始化对象
1 | class Person: |
2. __str__
和 __repr__:控制对象的字符串表示
__str__用于str(obj)或print(obj),面向用户。__repr__用于调试,面向开发者,通常返回可执行的代码字符串。
1 | class Point: |
3. __len__:支持
len(obj)
1 | class MyList: |
4.
__getitem__ / __setitem__:支持
obj[key] 和 obj[key] = value
1 | class Vector: |
5. __add__:支持 +
运算符
1 | class Vector: |
6. __eq__:支持 ==
比较
1 | class Book: |
7.
__call__:让对象像函数一样被调用
1 | class Multiplier: |
参考资料
Cookie、Session、JWT
Cookie
HTTP Cookie(通常简称为 Cookie)是由
服务器通过 HTTP 响应头 Set-Cookie
发送给用户代理(如浏览器)的一小段数据,用户代理随后会在后续的、满足条件的
HTTP 请求中,通过 Cookie 请求头自动将其发送回服务器。
- 核心目的:在无状态的 HTTP 协议之上,实现 状态管理(State Management) 和 客户端数据持久化。
浏览器会:
- 保存它
- 在后续同域名的请求中,自动通过
Cookie请求头发回给服务器
🔑 Cookie 的核心作用:在无状态的 HTTP 协议上实现“会话跟踪”
前端构建
使用 Vite 快速创建 React 项目
1 | #用最新版 Vite 脚手架,在名为 react-app 的文件夹中,创建一个基于 React 的项目。 |
Vite(发音同 “veet”,法语“快”)是一个现代化的前端构建工具,由 Vue.js 作者尤雨溪(Evan You)开发,但不仅限于 Vue——它对 React、Svelte、Lit 等主流框架都有官方支持。
1 | #安装项目依赖 |
项目结构
1 | react-app/ |
启动链条
1 | 1. 浏览器加载 index.html |
index.html
脚本标签指定入口
1 | <script type="module" src="/src/main.jsx"></ |
- src=“/src/main.jsx” 明确指定 了入口文件路径
- type=“module” 表示这是ES6模块,支持import/export语法
- 浏览器加载这个脚本时,就会执行main.jsx中的代码
main.jsx 中的这行代码:
1 | createRoot(document.getElementById('root')) |
与 index.html 中的:
1 | <div id="root"></div> |
通过 id=“root” 建立了连接!
main.jsx
main.jsx 是整个React应用的 入口文件
1 | import { StrictMode } from 'react' |
创建React根节点 - 在HTML页面中找到id为’root’的DOM元素 -
创建一个React根渲染器,这是React应用挂载的地方1
createRoot(document.getElementById('root'))
渲染应用
1 | .render( |
- 将整个React应用渲染到根节点
- StrictMode 包裹应用,提供开发时的额外检查和警告
是你的主应用组件
App.jsx
组件(Component) 是React的核心概念,可以理解为:
- 可复用的UI构建块
- 独立的功能单元
- 像乐高积木一样可以组合的代码片段
以App组件为例
1 | function App() { |
🔍 组件的核心特征
- 函数式组件
1 | function App() { |
- App是一个 JavaScript函数
- 函数名就是 组件名 (必须大写开头)
- 返回 JSX (类似HTML的语法)
- 状态管理(State)
1 | const [isLoggedIn, setIsLoggedIn] = useState(false) |
isLoggedIn - 状态变量 - 存储 当前的登录状态 - 初始值是 false (未登录) - 只能 读取 ,不能直接修改
setIsLoggedIn - 状态更新函数
- 用来 更新 isLoggedIn 的值
- 调用时会 触发组件重新渲染
- 是修改状态的 唯一正确方式
useState(false) - Hook调用
- false 是 初始值 ,表示默认未登录
- 返回一个 数组 : [当前值, 更新函数]
- 事件处理
1 | const handleLoginSuccess = () => { |
- 组件可以 响应用户交互
- 处理点击、输入等事件
- 更新状态,触发UI更新
- 条件渲染
1 | {!isLoggedIn ? ( |
- 根据 状态条件 显示不同内容
- 动态决定渲染哪些子组件
- 组件组合
1 | <Login onLoginSuccess={handleLoginSuccess} / |
- 大组件由 小组件组合 而成
- 通过 Props 传递数据给子组件
组件组合完整的数据流
- 父组件(App.jsx)定义函数
1 | function App() { |
- 子组件(Login.jsx)接收并使用
1 | function Login({ onLoginSuccess }) { // 通过Props接收函数 |
Login.jsx
1 | function Login({ onLoginSuccess }) { |
Profile.jsx
1 | function Profile({ isLoggedIn }) { |
后端构建
1 | from fastapi import FastAPI, Response, Request |
CORS(Cross-Origin Resource Sharing) = 跨域资源共享
否则会出现
1 | Access to fetch at 'http://localhost:8000/login' |
- 从 http://localhost:5173 (前端)
- 访问 http://localhost:8000/login (后端)
- 被CORS策略阻止了
cookie机制
POST /login:登录成功,服务器“记住”用户GET /profile:获取用户资料,服务器“认出”用户
关键就靠 Cookie 在浏览器和服务器之间传递身份。
🔧 1.
response.set_cookie(key="user_id", value="123", httponly=True)
✅ 作用:
让服务器告诉浏览器:“请保存一个叫
user_id的 Cookie,值是123”
📡 实际发生了什么?
当 FastAPI 执行这行代码时,它会在 HTTP 响应头(Response Headers) 中添加一行:
1 | Set-Cookie: user_id=123; HttpOnly |
然后整个响应看起来像这样: 1
2
3
4
5 200 OK
Content-Type: application/json
Set-Cookie: user_id=123; HttpOnly
{"msg": "Logged in"}
🌐 浏览器收到后会:
- 解析
Set-Cookie头 - 在本地(内存或磁盘)保存这个 Cookie:
- 名字:
user_id - 值:
123 - 属性:
HttpOnly(JS 无法读取)
- 名字:
- 以后每次向该域名发请求,自动带上这个 Cookie
🔐 参数详解(你用的三个):
| 参数 | 作用 | 安全建议 |
|---|---|---|
key="user_id" |
Cookie 的名字 | 用语义化名称,如 session_id |
value="123" |
Cookie 的值 | 不要直接存用户 ID! 应该存随机 session ID(后面讲) |
httponly=True |
禁止 JavaScript 读取 | ✅ 强烈建议开启,防 XSS 攻击 |
📥 2. user_id = request.cookies.get("user_id")
✅ 作用:
从当前请求中读取浏览器自动发送的 Cookie
📤 实际发生了什么?
当浏览器访问 /profile 时,它会自动在 HTTP
请求头(Request Headers) 中加上:
1 | Cookie: user_id=123 |
FastAPI 的 request.cookies
是一个字典,.get("user_id") 就是读取这个值。
1 | sequenceDiagram |
Session
Session(会话) 是一种 服务器端状态管理机制,用于在无状态的 HTTP 协议之上,维护客户端与服务器之间的持续交互状态。
- 核心思想:为每个客户端分配一个唯一的会话标识符(Session ID),服务器通过该 ID 查找对应的会话数据。
- 存储位置:会话数据(如用户身份、权限、购物车等)存储在服务器端(内存、数据库、缓存等)。
- 传输载体:Session ID 通常通过 Cookie(最常见)、URL 重写或 HTTP 头在客户端与服务器之间传递。
为什么需要session
HTTP 协议是无状态的:
- 每次请求都是独立的,服务器不知道你是谁
- 如果你登录后访问个人页面,服务器怎么知道你是谁?
解决方案:
- Cookie:浏览器存数据(但不安全,不能存敏感信息)
- Session:服务器存数据,浏览器只存 ID(安全!)
💡 Session 是实现“登录状态”的标准方式
1 | sequenceDiagram |
后端构建
1 | # 简化的内存session存储 |
重复部分进行省略
JWT
jwt是什么
JWT(JSON Web Token) 是一种 开放标准(RFC 7519),用于在各方之间安全地传输声明(claims)。它是一种紧凑、自包含(self-contained) 的令牌格式,通常用于 身份认证(Authentication) 和 信息交换(Information Exchange)。
- 核心特点:
- 无状态(Stateless):服务器无需存储令牌
- 自包含:令牌本身包含用户身份和元数据
- 可验证:通过数字签名确保完整性与真实性
✅ JWT 的本质是 “签名的用户声明”,而非会话 ID。
JWT 的结构
JWT 由三部分组成,用 . 连接:
1 | xxxxx.yyyyy.zzzzz |
| 部分 | 说明 | 内容示例 |
|---|---|---|
| Header | 令牌类型 + 签名算法 | {"alg": "HS256", "typ": "JWT"} |
| Payload | 声明(Claims) | {"sub": "123", "name": "Alice", "exp": 1735689600} |
| Signature | 签名(防篡改) | HMACSHA256(base64UrlEncode(header)+'.'+base64UrlEncode(payload), secret) |
🔐 只有签名部分能防止篡改,Header 和 Payload 只是 Base64Url 编码(可解码!勿存敏感信息)。
JWT 的 sub是什么
在 JSON Web Token (JWT) 中,sub 是
Subject(主题)的缩写。
它是 JWT 规范(RFC 7519)中定义的一个注册声明(Registered
Claim)。简单来说,sub
用于回答这个问题:“这个 Token 是代表谁的?”
含义:它标识了该 JWT 所面向的主体(Principal)。在绝大多数应用场景中,这个主体就是用户。
作用:当服务器收到一个 JWT 时,它通过读取
sub 字段来知道“当前请求是谁发起的”或“当前登录的是哪个用户
ID”。
在 JWT 的 Payload(载荷)部分,sub 通常是这样的:
1 | { |
为什么用 JWT,相比较session优势在哪
- 无状态(Stateless) → 天然支持水平扩展
- Session:服务器必须存储会话数据(内存/Redis),所有实例需共享存储。
- JWT:服务器不存储任何状态,任意实例均可独立验证 Token。
🌐 适用场景:微服务架构、Serverless、高并发 API 网关
💡 优势:去中心化、无共享存储依赖、部署简单
- 跨域与跨平台原生支持
- Session:依赖 Cookie,受同源策略限制,跨域需复杂 CORS 配置。
- JWT:通过
Authorization: Bearer <token>传输,无 Cookie 依赖。
📱 适用场景: - 移动 App(iOS/Android) - 多前端(Web + 小程序 + 桌面端) - 第三方集成(如开放平台 API)
💡 优势:一套 API 服务所有客户端
- 自包含(Self-contained) → 减少数据库查询
- Session:每次请求需查存储(如 Redis)获取用户信息。
- JWT:Payload 可直接携带用户 ID、角色、权限等信息。
1 | { |
⚡ 优势:减少 I/O,提升性能(尤其对权限频繁校验的系统)
- 标准化 & 生态成熟
- JWT 是 IETF 标准(RFC 7519),各语言均有高质量库。
- 与 OAuth 2.0、OpenID Connect 深度集成,适合现代身份认证体系。
🔌 优势:无缝对接 Auth0、Keycloak、Firebase 等身份提供商
1 | sequenceDiagram |
JWT的缺点
- 无法主动撤销:一旦签发,在过期前始终有效,难以实现“立即登出”或“账号禁用”。
- XSS 风险高:通常需存于前端(如内存或 localStorage),若存在 XSS 漏洞,Token 易被窃取。
- Payload 可解码:Header 和 Payload 仅 Base64 编码,不是加密,不能存敏感信息。
- 体积较大:每次请求都要携带完整 Token,增加带宽开销(相比 Session ID)。
jwt三种签名算法
1. HS256 (HMAC with SHA-256)
类型:对称加密 (Symmetric)
这是最简单、最常见的算法,适合单体应用或内部受信任的服务之间通信。
具体原理
“共享密钥”模式。
签发 Token 的一方(认证服务器)和验证 Token 的一方(应用服务器)必须持有完全相同的密钥(Secret)。
- 签名过程: 将 Header 和 Payload 进行 Base64Url
编码,用
.连接。然后使用 Secret 对这个字符串进行 SHA-256 哈希计算。 - 验证过程: 接收方收到 Token 后,用同一个 Secret 对 Header 和 Payload 再次进行同样的哈希计算。如果计算出的结果与 Token 中的签名一致,则验证通过。
核心公式
$$Signature = HMACSHA256(base64Url(Header) + "." + base64Url(Payload), secret)$$
举例说明
场景: 你是一个独自开发的网站站长。
Secret:
"my_super_secret_password"(只有你的服务器知道)。
流程:
- 用户登录,你的代码生成 Payload
{"user": "admin"}。 - 代码混合 Secret 进行哈希,生成签名
abc123...。 - 当用户下次带着 Token 请求时,你的代码再次用
"my_super_secret_password"算一遍。如果算出来也是abc123...,说明 Token 没被黑客改过。
优点: 速度极快,生成签名极其简单。
缺点: 密钥一旦泄露,黑客既能验证也能伪造任意 Token。不适合多方系统(因为要把密钥分发给所有验证者,风险扩散)。
2. RS256 (RSA Signature with SHA-256)
类型:非对称加密 (Asymmetric)
这是企业级应用、微服务架构和 OAuth2/OIDC(如 Auth0, Okta)中的行业标准。
具体原理
“私钥签名,公钥验证”模式。 使用一对密钥:私钥 (Private Key) 和 公钥 (Public Key)。
- 私钥: 只有认证服务器(Auth Server)拥有,绝不公开。用于生成签名。
- 公钥: 可以公开给任何服务(资源服务器、网关等)。用于验证签名。
核心原理
RSA 利用了大数因数分解的数学难题。私钥加密的数据,只能用公钥解密(在签名场景下,这意味着只有公钥能验证是由私钥签名的)。
举例说明
- 场景: Google 颁发 Token 给第三方 App(如 Notion)。
- 私钥: Google 只有一把,锁在 Google 的保险柜里。
- 公钥: 公布在网上(JWKS 端点),Notion 可以随时下载。
- 流程:
- Google 用私钥给 Payload
{"sub": "123"}盖了一个“数字章”(签名)。 - Notion 收到 Token,去 Google 下载公钥。
- Notion 用公钥验证这个“章”。如果验证通过,Notion 就能 100% 确定这个 Token 是 Google 签发的,而不是黑客伪造的。
- Google 用私钥给 Payload
- 优点: 安全性高。即使公钥泄露,黑客也只能验证 Token,无法伪造 Token。非常适合微服务(Auth 服务发 Token,其他几十个微服务只拿公钥验 Token)。
- 缺点: 签名速度比 HS256 慢,生成的签名字符串较长。
3. ES256 (ECDSA using P-256 and SHA-256)
类型:非对称加密 (Asymmetric - Elliptic Curve)
这是目前推荐的新兴标准。它在保持非对称加密安全性的同时,解决了 RSA 的性能和体积问题。
具体原理
“椭圆曲线”模式。 同样使用公钥和私钥,但基于椭圆曲线密码学 (ECC)。 与 RSA 相比,ECC 可以在密钥长度短得多的情况下,提供同等甚至更高的安全性。
核心原理
它利用了椭圆曲线上的离散对数问题。简而言之,在一个特定的数学曲线上做点运算非常容易,但反向推导非常困难。
举例说明
场景: 需要高并发、低带宽的物联网 (IoT) 设备或移动端 App。
对比 RSA:
- 要达到 128 位安全级别,RS256 需要 3072 位的密钥(生成的 Token 会很长,占用流量)。
- ES256 只需要 256 位的密钥(Token 非常短,传输快)。
流程: 逻辑与 RS256 一样(私钥签、公钥验),但数学计算过程不同。
优点:
- Token 更短:节省带宽,HTTP Header 更小。
- 生成速度快:在某些硬件上,签名速度比 RSA 更快。
缺点: 相对较新,极老旧的系统可能不支持;数学原理比 RSA 更复杂,排查问题稍难。
后端构建
1 | from pydantic import BaseModel |
参考资料
JWT身份认证算法、落地方案及优缺点_哔哩哔哩_bilibili
REST | GraphQL | gRPC | tRPC
REST api
REST(Representational State Transfer)
是一种软件架构风格,用于设计网络应用程序的 API。
REST API 就是遵循 REST 原则的 Web 接口,通常基于 HTTP
协议。
✅ 核心思想:把一切看作“资源”(Resource),通过标准 HTTP 方法对资源进行操作。
REST 的六大约束(简化版理解)
| 约束 | 含义 | 举例 |
|---|---|---|
| 统一接口 | 所有操作通过标准 HTTP 方法(GET/POST/PUT/DELETE) | /books 表示“图书资源” |
| 无状态 | 服务器不保存客户端状态,每次请求必须包含全部信息 | 用 Token 认证,而不是 Session |
| 可缓存 | 响应应标明是否可缓存 | GET 请求通常可缓存 |
| 分层系统 | 客户端无需知道是否直接连服务器(可经过代理、网关) | Nginx 反向代理 FastAPI |
| 按需代码(可选) | 可返回可执行代码(如 JS) | 较少用 |
| 资源标识 | 每个资源有唯一 URI | /books/123 唯一标识 ID 为 123 的书 |
常用 HTTP 方法与语义
| 方法 | 含义 | 幂等性 | 安全性 | 例子 |
|---|---|---|---|---|
GET |
获取资源 | ✅ 是 | ✅ 是 | 获取所有图书 |
POST |
创建资源 | ❌ 否 | ❌ 否 | 新增一本图书 |
PUT |
完整更新资源 | ✅ 是 | ❌ 否 | 替换 ID 为 123 的图书全部信息 |
PATCH |
部分更新资源 | ❌ 否 | ❌ 否 | 只修改图书的标题 |
DELETE |
删除资源 | ✅ 是 | ❌ 否 | 删除 ID 为 123 的图书 |
🔔 幂等性:多次执行结果相同(如 DELETE /books/123,删一次和删十次效果一样)
🔔 安全性:不改变服务器状态(GET 是安全的,POST 不是)
举个 FastAPI 的完整例子
假设你正在开发图书管理系统,下面是典型 REST API:
1 | # main.py |
启动后,你就可以通过:
GET /books→ 获取所有书POST /books→ 创建新书GET /books/1→ 获取 ID=1 的书PUT /books/1→ 完全替换 ID=1 的书DELETE /books/1→ 删除 ID=1 的书
REST API 常见响应格式(JSON)
1 | // 成功创建 |
HTTP 状态码也很关键:
| 状态码 | 含义 |
|---|---|
| 200 | OK(GET 成功) |
| 201 | Created(POST 成功) |
| 204 | No Content(DELETE 成功,无返回体) |
| 400 | Bad Request(参数错误) |
| 404 | Not Found(资源不存在) |
| 500 | Internal Server Error |
GraphQL
GraphQL 是由 Facebook 开发的一种 API 查询语言 和 运行时,用于客户端精确声明它需要什么数据,服务器则按需返回这些数据。
✅ 核心理念:“客户端要什么,服务端就给什么”,避免 REST 中常见的“过载”或“多次请求”问题。
场景
你想获取用户 ID=1 的 姓名 和他最新的 两篇文章标题
🔹 REST 方式(你熟悉的方式)
1 | GET /users/1 → 返回 {id, name, email, avatar, ...} (可能含不需要的 email/avatar) |
→ 2 次请求 + 数据冗余
🔸 GraphQL 方式
客户端发送一个 查询(Query):
1 | query { |
服务器返回:
1 | { |
→ 1 次请求 + 精确数据
1. Schema(类型系统)
定义 API 的能力:有哪些类型?有哪些字段?
1 | type User { |
2. Query(查询)
客户端请求数据(类似 REST 的 GET)
3. Mutation(变更)
客户端修改数据(类似 REST 的 POST/PUT/DELETE)
1 | mutation { |
RPC
RPC(Remote Procedure Call) 是一种让程序调用另一个地址空间(通常是远程服务器)上的函数/过程,就像调用本地函数一样的机制。
✅ 核心思想:“像调用本地函数一样调用远程服务”
你不需要关心网络细节(HTTP、序列化等),框架会自动处理。
为什么有了 HTTP 还需要 RPC?
我们可以把 HTTP/REST 比作 “写信”,把 RPC 比作 “发电报”。
A. 数据包的大小(信封 vs. 代码)
- HTTP (REST+JSON): 为了让人看懂,JSON 极其啰嗦。
- 比如传递一个数字
1000,JSON 需要写成字段"balance": 1000。为了传这一个数,你得带上"balance"这个单词,还有大括号、冒号。这就像写信时要写满客套话。
- 比如传递一个数字
- RPC (Protobuf/二进制):
机器不需要看懂单词,它只需要知道位置。
- RPC 协议会约定:“第2个位置放余额”。传输时,直接发二进制的
1000即可。数据体积可以缩小 50%~80%。
- RPC 协议会约定:“第2个位置放余额”。传输时,直接发二进制的
B. 解析速度(阅读 vs. 直觉)
- HTTP: 服务器收到 JSON 后,CPU 需要一行行去“读”文本,把字符串转换成对象。这非常消耗 CPU 资源。
- RPC: 二进制数据到了服务器,几乎不需要转换,直接就能由计算机内存读取。解析速度比 JSON 快很多倍。
C. 约束力(口头约定 vs. 法律合同)
- HTTP: REST API 的文档通常写在网页上(比如 Swagger)。如果后端改了字段名,前端没注意,上线可能就崩了。这属于“弱约束”。
- RPC: 强依赖 IDL(接口定义语言)。在代码编译阶段,如果客户端和服务端定义的参数类型对不上,代码直接报错,编译不过。这大大减少了上线后的低级错误。
注意: 现代的 RPC(如 gRPC)其实底层往往也是基于 HTTP/2 协议传输的。所以准确地说,并不是“抛弃 HTTP 用 RPC”,而是“在 HTTP 之上通过 RPC 机制来优化传输效率”。
RPC 主要用于什么场景?
RPC 并不是为了取代 REST,而是为了在特定领域“称王”。
场景一:微服务架构的内部通信(这是绝对的主战场)
想象一个像淘宝或亚马逊这样的大型系统,一个“用户下单”的请求,在后台可能要触发 50 次 内部调用(查库存、算优惠、校验风控、写日志、通知物流…)。
- 如果全用 REST:
- 每次调用都要解析一遍 JSON,CPU 累死。
- 每次传输都带一堆冗余的 HTTP 头,网络堵死。
- 总延迟 = 50 次 HTTP 请求的累加,用户会感觉“卡顿”。
- 如果用 RPC:
- 二进制传输,极快。
- 内部带宽占用极低。
- 结论: 对外(给浏览器/App)用 REST,对内(服务器之间)用 RPC。
场景二:高频交易与实时系统
在股票交易、实时游戏同步等对延迟(Latency)极其敏感的场景。
- 每一毫秒都决定盈亏。RPC 省去了繁琐的 HTTP 报文头解析,能把延迟压榨到极限。
场景三:多语言混合开发 (Polyglot)
公司里,算法团队用 Python(搞 AI),后端团队用 Java(搞业务),数据团队用 Go。
- 使用 gRPC(Google 的 RPC 框架),只需要定义一份
.proto文件,就能自动生成 Python、Java、Go 的代码。这三个团队不需要互相通过文档扯皮,直接调用生成的代码即
RPC 调用流程
1 | sequenceDiagram |
对比 REST 的资源操作:
1 | sequenceDiagram |
gRPC:跨语言的通用翻译官
gRPC 是由 Google 开发并开源的高性能 RPC 框架。它是目前微服务架构中的事实标准。
核心特点:
- 基于 HTTP/2: 它利用 HTTP/2 的特性(如多路复用、头部压缩),传输效率极高。
- Protocol Buffers (Protobuf): 这是 gRPC
的灵魂。它不使用 JSON,而是使用 Google 发明的
.proto文件来定义接口和数据结构。 - 多语言支持 (Polyglot):这是它最大的杀手锏。
适用场景:
- 微服务架构: 几十个服务,有的用 Java 写,有的用 Python 写,需要互相通信。
- 移动端对接: 手机 App 与服务器通信(省流量、省电)。
tRPC:TypeScript 开发者的“心灵感应”
tRPC (TypeScript RPC) 是近年来在前端圈(特别是 React/Next.js 社区)爆火的库。
注意: tRPC 只能用于 TypeScript。如果你的后端是 Java 或 Go,那就不能用它。
核心特点:
- 端到端类型安全 (End-to-End Type Safety): 这是它存在的全部意义。
- 无代码生成 (No Code Gen): 不需要写
.proto文件,也不需要运行脚本生成代码。 - 基于标准 HTTP: 底层通常还是普通的 HTTP 请求,但写代码的感觉是 RPC。
适用场景:
- 全栈 TypeScript 项目: 比如使用 Next.js, Nuxt.js 等框架,前后端都在一个代码仓库(Monorepo)里。
- 中小型快速开发: 一个团队同时负责前后端,追求极致的开发速度。
参考资料
Websockets
🕰️ 什么是长轮询(Long Polling)?
长轮询 是一种在 没有 WebSocket 或 Server-Sent Events(SSE) 的环境下,模拟“服务器推送” 的技术。
客户端发起 HTTP 请求后,服务器不会立即响应,而是挂起连接,直到有新数据可返回或超时才发送响应;客户端收到响应后立即重新发起请求,从而实现准实时的双向通信。
❌ 但最坏情况是:
- 前端在 t=0s 发起请求
- 新数据在 t=0.1s 产生
- 但后端没检测到(比如检查间隔是 1 秒)
- 后端一直等到 t=10s 超时,才返回“无数据”
- 前端在 t=10s 收到响应,显示“没更新”
- 然后立刻发起下一轮请求(t=10s)
- 后端这次检测到数据(t=10.1s)→ 返回
- 前端在 t=10.2s 才显示!
→ 延迟 = 10.1 秒!
🧠 核心问题:检测粒度 + 请求对齐
长轮询的延迟主要来自两个地方:
| 延迟来源 | 说明 |
|---|---|
| 1. 后端检查间隔 | 如果后端每 1 秒检查一次数据,那么数据产生后最多要等 1 秒才被发现 |
| 2. 请求发起时机 | 如果数据在“上一轮请求刚结束、下一轮还没发”时产生,就要等下一轮超时结束 |
💡 即使后端“一有数据就返回”,前提是它在“当前这个请求还在挂起时”检测到了数据。
🌐 什么是 WebSocket?
WebSocket 是一种全双工通信协议,建立在 TCP 之上,允许客户端和服务器之间实时、双向地传输数据。
对比传统的 HTTP:
- HTTP 是请求-响应模式:客户端发请求,服务器响应,然后连接关闭。
- WebSocket 是持久连接:连接建立后,双方可以随时主动发消息,适合聊天、实时通知、在线游戏等场景。
🔁 WebSocket vs HTTP 轮询(举例说明)
假设你要做一个实时股票价格更新页面:
- HTTP 轮询:前端每 1 秒发一次请求问“价格变了吗?”,服务器回答。浪费带宽,延迟高。
- WebSocket:连接一次,服务器价格一变就主动推给前端,高效实时。
🧱 WebSocket 通信流程(简化版)
- 客户端发起 HTTP 请求,带
Upgrade: websocket头。 - 服务器同意升级协议,返回
101 Switching Protocols。 - 连接升级为 WebSocket,之后双方通过这个连接发消息(不是 HTTP 了!)。
- 任意一方可主动关闭连接。
websocket通信图解
1 | sequenceDiagram |
与长轮询对比
1 | sequenceDiagram |