邀请好友机制调研
邀请码
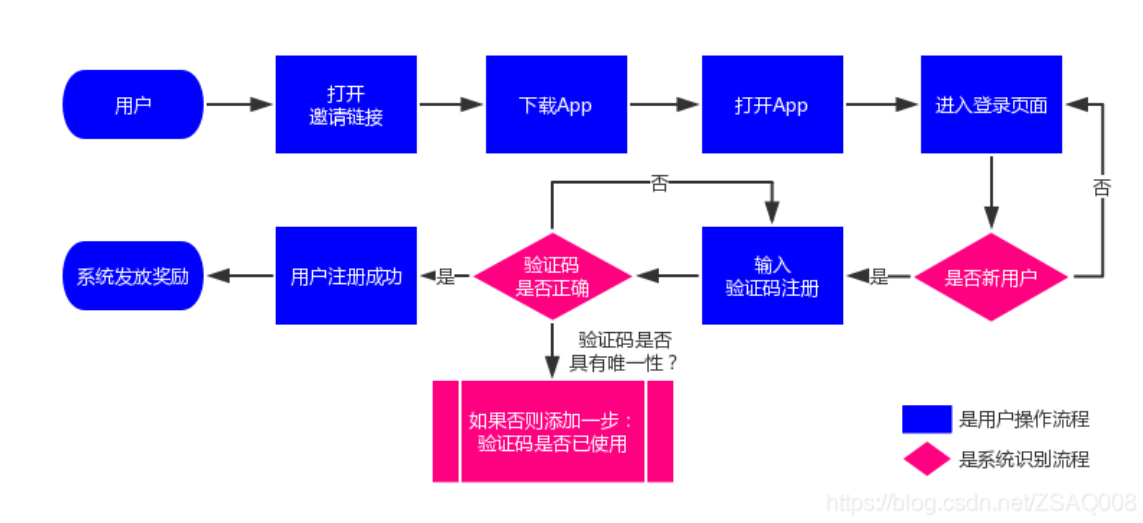
邀请链接
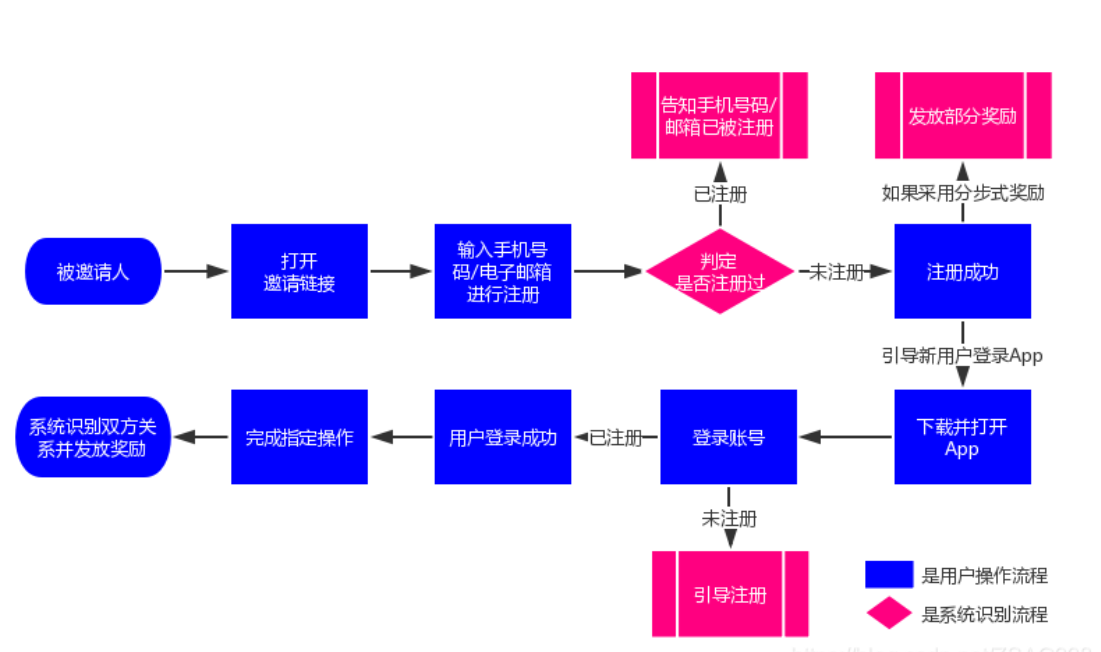
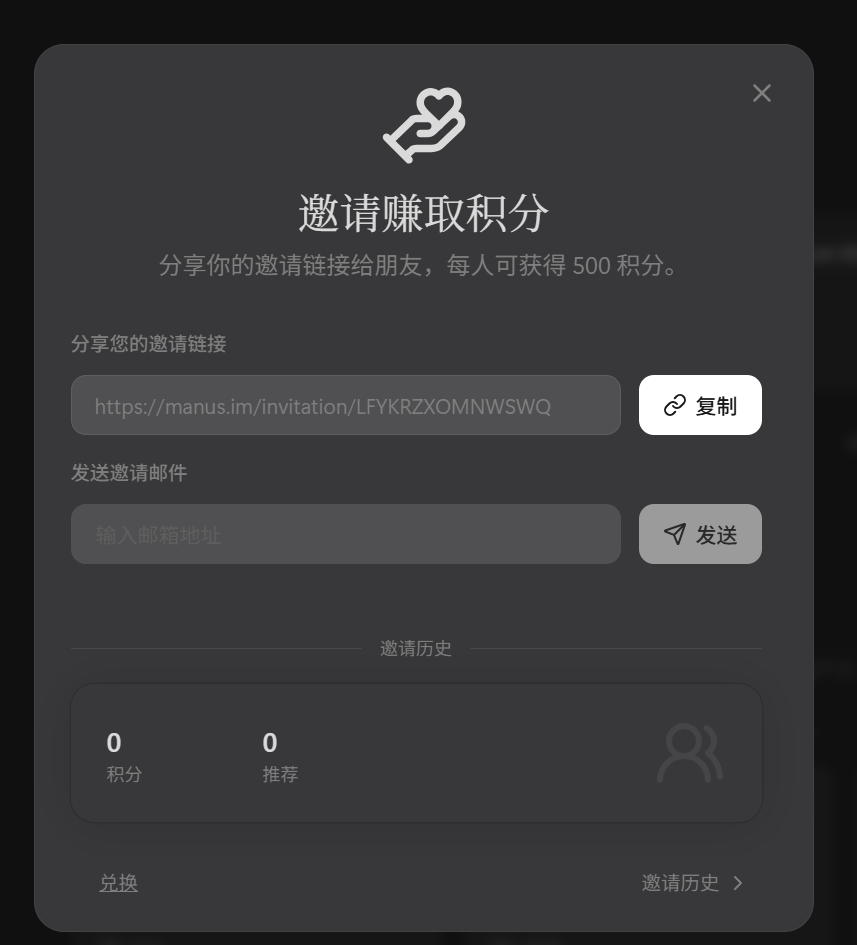
在表里面增加一个邀请链接的字段,每个用户有专属的邀请链接
在表里面增加一个邀请链接的字段,每个用户有专属的邀请链接
1 | from sklearn.preprocessing import MinMaxScaler |
1 | from sklearn.preprocessing import StandardScaler |
StandardScaler (Z-score标准化) RobustScaler
(鲁棒标准化)1
2
3
4
5
6
7
8
9公式: (x - 均值) / 标准差
问题: 均值和标准差都会被异常值严重影响!
例如:
正常值: [100, 150, 200, 180, 220] → 均值 = 170
加入异常值: [100, 150, 200, 180, 220, 6445] → 均值 = 1216 ❌
结果: 所有正常值都变成负数,异常值主导了整个标准化过程
1 | 公式: (x - 中位数) / IQR |
Apriori 算法 是一种用于 频繁项集挖掘(Frequent Itemset Mining) 和 关联规则学习(Association Rule Learning) 的经典算法。
Apriori 基于一个非常重要的性质,叫 先验性质(Apriori Property):
如果一个项集是频繁的,那么它的所有子集也一定是频繁的。 反过来:如果一个项集是非频繁的,那么它的所有超集也一定是非频繁的。
这个性质可以用来 剪枝(prune),避免穷举所有可能的组合。
Apriori 的 候选生成规则:
当且仅当它们的前 (k-1) 个项相同,两个频繁 k项集才可以连接生成 (k+1)项集。
剪枝规则只有一句话:
对候选 k-项集 c,只要存在任何一个 (k−1)-子集 不在 Lₖₖ₋₁ 里, 就把 c 整集扔掉,不再给它计数。
为什么这样做合法?
基于 Apriori 向下封闭性(频繁项集的所有子集必频繁)。 若 c 哪怕只有一个 (k−1)-子集是非频繁的,c 自己绝对不可能频繁, 所以没必要浪费一次数据库扫描去数它的支持度。
1 | transactions = [ |
我们的目标是找出 频繁项集(比如哪些商品经常一起出现)。
步骤 1:设定最小支持度(min_support)
假设我们设 min_support = 2,意思是:至少出现在 2
个购物篮中才算“频繁”。
支持度(Support) = 包含该项集的交易数 / 总交易数
这里我们直接用“出现次数 ≥ 2”来简化。
步骤 2:生成 1-项集(单个商品)
统计每个商品出现次数:
| 项集 | 出现次数 |
|---|---|
| {‘牛奶’} | 4 |
| {‘面包’} | 4 |
| {‘黄油’} | 2 |
| {‘可乐’} | 2 |
全部 ≥2 → 都是频繁 1-项集。
步骤 3:生成 2-项集(两两组合)
从频繁 1-项集中两两组合(注意:只组合那些“所有子集都频繁”的):
可能的组合: - {‘牛奶’, ‘面包’} - {‘牛奶’, ‘黄油’} - {‘牛奶’, ‘可乐’} - {‘面包’, ‘黄油’} - {‘面包’, ‘可乐’} - {‘黄油’, ‘可乐’}
现在统计它们在交易中出现的次数:
| 项集 | 出现次数 |
|---|---|
| {‘牛奶’, ‘面包’} | 3 ✅ |
| {‘牛奶’, ‘黄油’} | 1 ❌ |
| {‘牛奶’, ‘可乐’} | 2 ✅ |
| {‘面包’, ‘黄油’} | 2 ✅ |
| {‘面包’, ‘可乐’} | 1 ❌ |
| {‘黄油’, ‘可乐’} | 0 ❌ |
保留 ≥2 的 → 频繁 2-项集: - {‘牛奶’, ‘面包’} - {‘牛奶’, ‘可乐’} - {‘面包’, ‘黄油’}
步骤 4:生成 3-项集
从频繁 2-项集中尝试组合。
比如:{‘牛奶’,‘面包’} 和 {‘牛奶’,‘可乐’} → 可以组合成
{‘牛奶’,‘面包’,‘可乐’}
但必须检查它的所有 2-项子集是否都在频繁 2-项集中:
→ 所以 {‘牛奶’,‘面包’,‘可乐’} 不合法,不能生成。
再试:{‘牛奶’,‘面包’} + {‘面包’,‘黄油’} →
{‘牛奶’,‘面包’,‘黄油’}
检查子集: - {‘牛奶’,‘面包’} ✅ - {‘牛奶’,‘黄油’} ❌(之前只有1次) -
{‘面包’,‘黄油’} ✅
→ 有一个子集不频繁 → 整个 3-项集被剪枝!
结论:没有频繁 3-项集。
算法结束。
FP-growth(Frequent Pattern Growth)算法,它是一种用于频繁项集挖掘的高效算法
第一步:构建 FP 树(FP-Tree)
第二步:从 FP 树中挖掘频繁项集
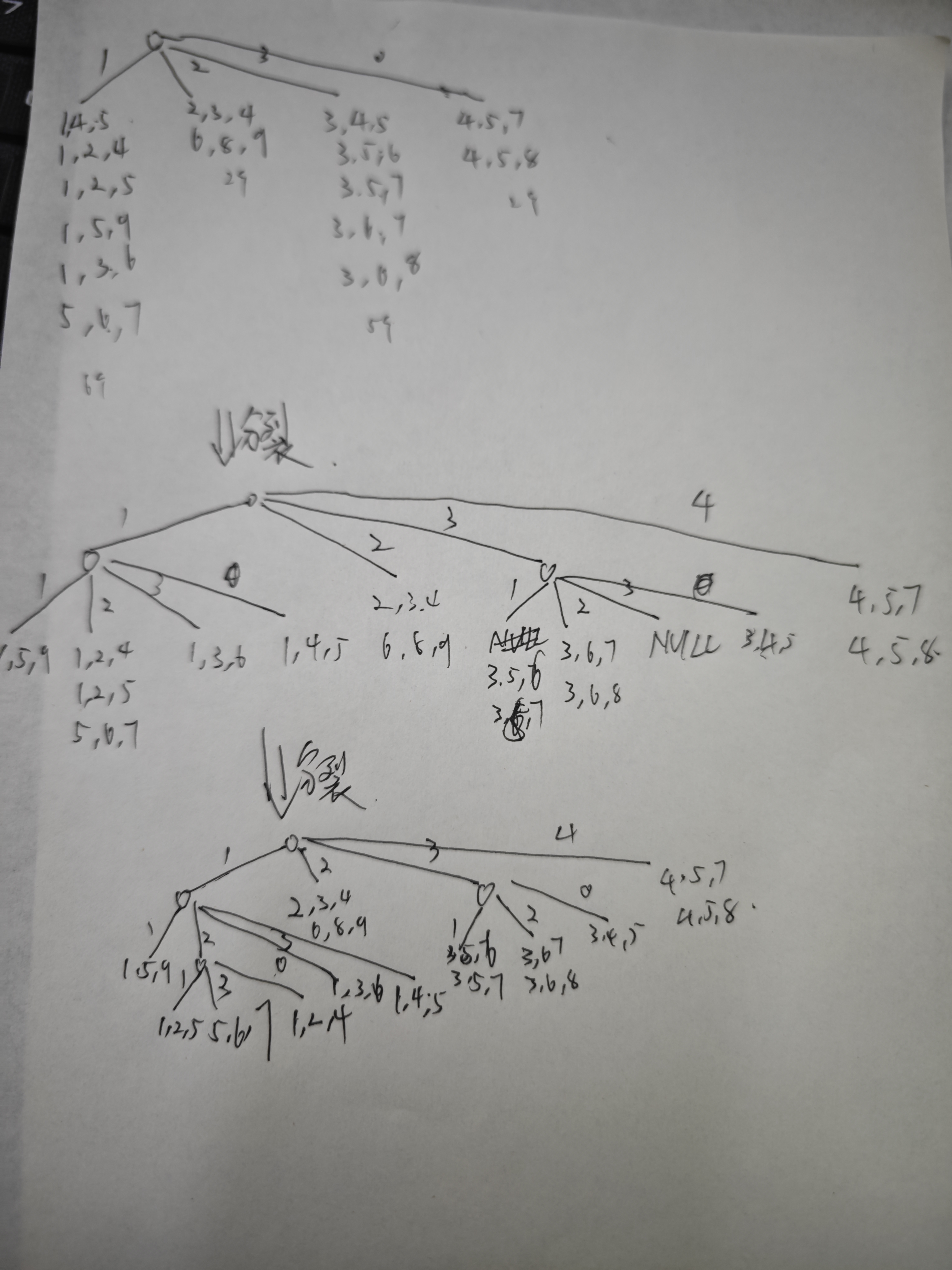
考虑表1中的候选3-项集,假设hash函数为h(x)=x mod 4,叶节点最大尺寸为2,构造hash树。
表1. 候选3-项集
| 编号 | 项集 |
|---|---|
| 1 | {1, 4, 5} |
| 2 | {1, 5, 9} |
| 3 | {3, 5, 6} |
| 4 | {1, 2, 4} |
| 5 | {1, 3, 6} |
| 6 | {3, 5, 7} |
| 7 | {4, 5, 7} |
| 8 | {2, 3, 4} |
| 9 | {6, 8, 9} |
| 10 | {1, 2, 5} |
| 11 | {5, 6, 7} |
| 12 | {3, 6, 7} |
| 13 | {4, 5, 8} |
| 14 | {3, 4, 5} |
| 15 | {3, 6, 8} |
事务集如表2所示,最小支持度阈值是30%。
根据表2的事务集,在格结构上对每个结点添加所有符合条件的字母标记:
N:如果该项集被Apriori算法认为不是候选项集。(一个项集不是候选项集有两种可能的原因,一个是它们没有在候选项集产生步骤产生,另一个是它虽然在候选项集产生步骤产生,但是在剪枝步骤被丢掉)
I:如果计算支持度计数后,该候选项集被认为是非频繁的。
表2. 事务集:
| TID | 项集 |
|---|---|
| 1 | {a, b, d, e} |
| 2 | {b, c, d} |
| 3 | {a, b, d, e} |
| 4 | {a, c, d, e} |
| 5 | {b, c, d, e} |
| 6 | {b, d, e} |
| 7 | {c, d} |
| 8 | {a, b, c} |
| 9 | {a, d, e} |
| 10 | {b, d} |
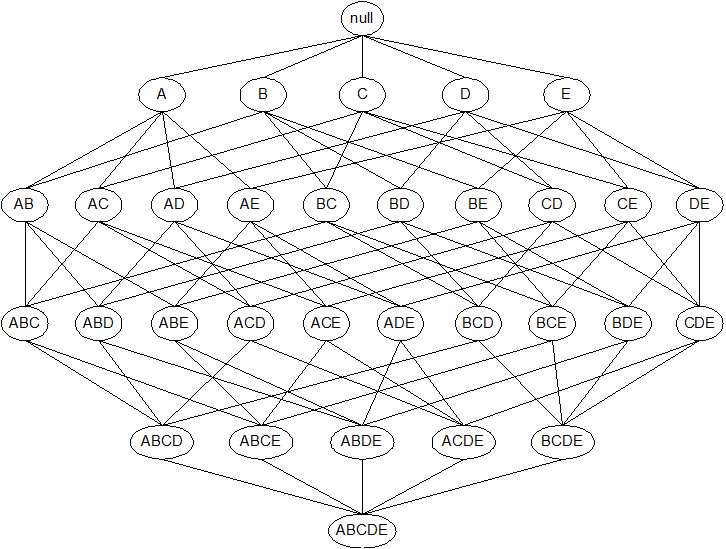

极大频繁项集:是频繁的,且没有频繁的真超集。
定义:极大频繁项集(Maximal Frequent Itemset)是一个频繁项集,其所有超集都不是频繁的。
检查每个频繁项集:
闭项集:一个项集 X 是闭的,如果不存在超集 Y ⊃ X 使得 support(Y) = support(X)。
即:它的支持度严格大于所有超集的支持度(或者没有超集具有相同支持度)。
以单项集为例:
单项集:
假设最小支持度阈值为40%,基于以下事务集写出使用FP-growth挖掘频繁项集的过程。
表1. 事务集
| TID | 项集 |
|---|---|
| 1 | {a,b,d,e} |
| 2 | {b,c,d} |
| 3 | {a,b,d,e} |
| 4 | {a,c,d,e} |
| 5 | {b,c,d,e} |


条件 FP 树(Conditional FP-tree)是 FP-growth 算法在“递归”阶段用来压缩“条件模式基”的一棵小 FP 树。 它的构建过程与初始 FP 树几乎一样,只是输入数据换成了“条件模式基”,并且再扫一遍、删低计数、排序、插入即可。下面用 “以 e 为后缀” 的例子把每一步都写出来,你就能完全复现。
一、准备:条件模式基(Conditional Pattern Base)
从主 FP 树里提取所有以 e 结尾的路径,并记录该路径的出现次数:
| 路径(删去 e 本身) | 该路径计数 |
|---|---|
| d b a | 2 |
| d a c | 1 |
| d b c | 1 |
这就是“e 的条件模式基”。
二、第一次扫描:算单项计数
把上面 3 条记录拆成单项累加:
最小支持度计数仍是 2,因此全部保留(若某项 <2 则直接丢弃)。
三、第二次扫描:排序 + 插入
| 原路径 | 排序后路径 | 计数 |
|---|---|---|
| d b a | d b a | 2 |
| d a c | d a c | 1 |
| d b c | d b c | 1 |
d b a(计数 2) 根 → d(2) → b(2) → a(2)d a c(计数 1) 根 → d(3) → a(1) → c(1)d b c(计数 1) 根 → d(4) → b(3) → c(1)最终得到的条件 FP 树文字表示:
1 | null |
为系统添加以下四个用户:
alicebobjohnmike1 | useradd -d /home/bob -m bob |
1 | passwd alice |
在 /home 目录下创建一个名为 work
的共享目录:
1 | mkdir /home/work |
创建一个名为 workgroup 的用户组:
1 | groupadd workgroup |
将用户 alice, bob, john
加入该组:
1 | usermod -a -G workgroup alice # 添加为附加组 |
查看某个组(group)的信息
1 | getent group workgroup |
将 /home/work 目录的属主改为
alice,属组改为 workgroup:
1 | chown alice:workgroup /home/work |
1 | chmod ug+rwx,o-rwx /home/work |
ug+rwx:用户(user)和组(group)都加上读、写、执行权限o-rwx:其他人(others)去掉所有权限(读、写、执行)切换到 bob 用户:
1 | su - bob |
创建文件:
1 | touch /home/work/bob.txt |
查看是否成功:
1 | ls -l /home/work/bob.txt |
1 | su - john |
1 | su - mike |
badproc.sh 脚本Shell 程序(Shell Script) 就是一系列 Shell 命令的集合,写在一个文件里,可以像程序一样自动、批量、重复执行。
1 | #!/bin/bash |
#!/bin/bash → 指定用 bash 解释器执行
while echo "..." →
无限循环,每次循环前先打印一句话(等价于
while true; do ... done)
循环体内:
adirafile1 | chmod +x badproc.sh |
1 | ./badproc.sh & |
1 | ps aux | grep badproc |
1 | kill 12345 |
1 | rm -rf adir |
fork.c1 | #include <stdio.h> |
1 | gcc -g -o fork fork.c |
1 | ./fork |
gdb 调试 fork 程序1 | gdb ./fork |
创建一个名为 helloworld.cpp
的文件,nano helloworld.cpp
1 | #include <iostream> |
按 Ctrl+O 保存,再按 Ctrl+X 退出 nano
1 | #编译程序 |
创建源文件 fred.c 和 bill.c
1 | /* fred.c */ |
编译成目标文件(.o)
1 | gcc -c bill.c fred.c |
创建头文件 lib.h
1 | /* lib.h */ |
创建主程序 program.c
1 | /* program.c */ |
编译主程序(只编译,不链接)
1 | gcc -c program.c |
创建静态库 libfoo.a
使用 ar 命令把 bill.o 和
fred.o 打包成一个静态库:
ar:archive 工具,用于创建静态库c:创建新库r:将文件插入到库中(如果不存在则添加)v:显示详细信息1 | ar crv libfoo.a bill.o fred.o |
链接主程序和静态库
现在我们要把 program.o 和 libfoo.a
链接起来,生成最终可执行文件 program。
1 | gcc -o program program.o libfoo.a |
运行程序
1 | ./program |
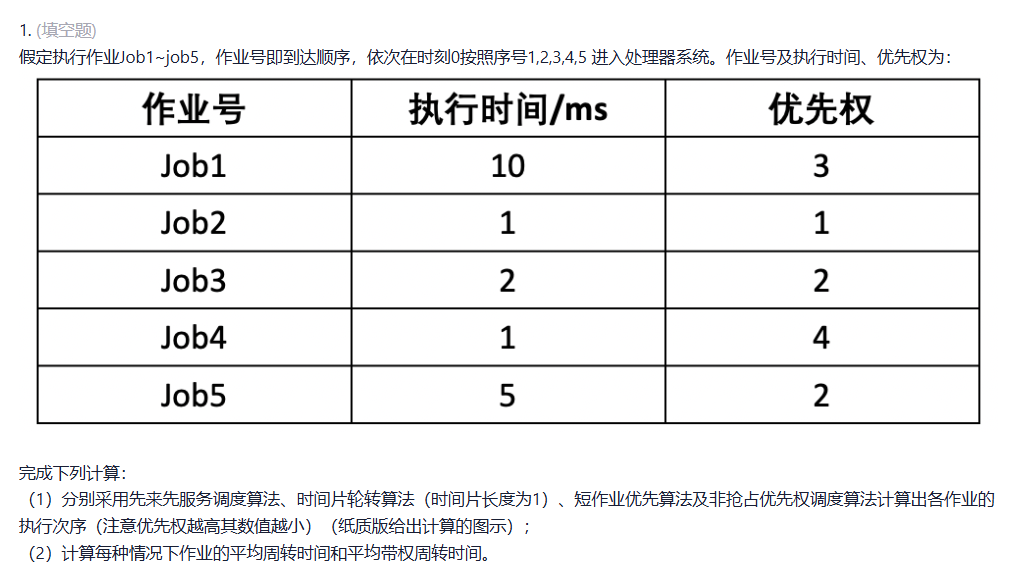
题目:
在某个计算机系统中有一台输入机和一台打印机,现有两道程序投入运行,且程序A先运行,程序B后开始运行。
程序A的运行轨迹为:
计算50ms,打印100ms,再计算50ms,打印100ms。
程序B的运行轨迹为:
计算50ms,输入80ms,再计算100ms,结束。
问题:
两道程序运行时,CPU是否空闲等待?____(有空闲等待 /
无空闲等待)
若有,在哪段时间内等待?_ms -
_ms(两个空,第一个填起始时间,第二个填结束时间,仅数字)
程序A,B是否有等待CPU的情况?
A:(有等待 / 无等待)
B:(有等待 / 无等待)
若有,指出发生等待的时刻(若无等待,空格填0)
(若有两段以上等待时间,用“/”标表示不同等待时间,如0/30和20/40表示0ms-20ms是第一段空闲;30ms-40ms是第二段空闲)
A:_ms - _ms
B:___ms - ___ms

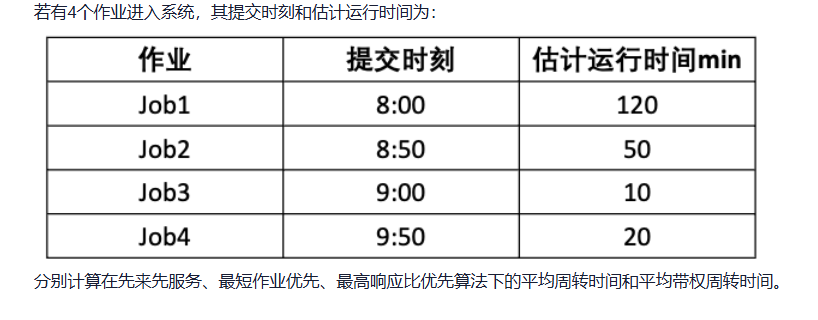
题目:
在单CPU和两台I/O设备(I1和I2)的多道程序设计环境下,同时投入三个作业运行,其执行轨迹如下:
已知条件:
问题:

题目:
在单机系统中,有同时到达的两个程序A、B,若每个程序单独运行,则使用CPU,DEV1(设备1)、DEV2(设备2)的顺序和时间如下表所示。
| 运行情况 | 程序A | 程序B |
|---|---|---|
| CPU | 25 | 20 |
| DEV1 | 39 | 50 |
| CPU | 20 | 20 |
| DEV2 | 20 | 20 |
| CPU | 20 | 10 |
| DEV1 | 30 | 20 |
| CPU | 20 | 45 |
给定条件:
问题:



 3.
3.

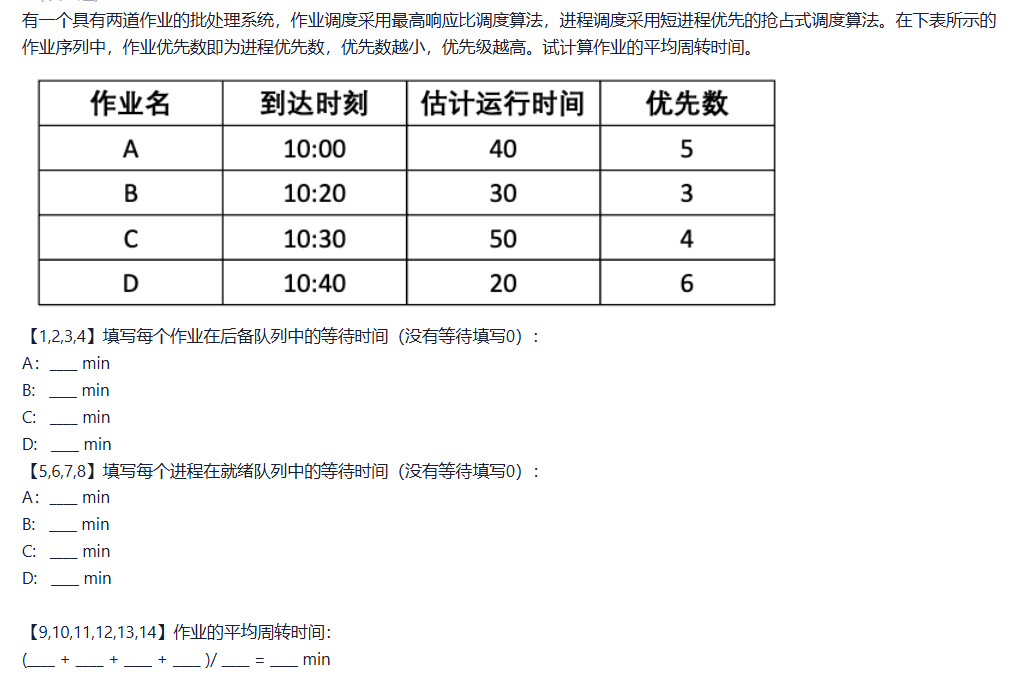

有一个盒子里混装了数量相等的黑白围棋子,现在利用自动分拣系统把黑子、白子分开,设分拣系统有两个进程P1和P2,其中进程P1拣白子,进程P2拣黑子。规定每个进程每次拣一子;当一个进程在拣时,不允许另一个进程去拣;当一个进程拣了一子时,必须让另一个进程去拣。试写出进程P1和P2能够正确并发执行的程序。
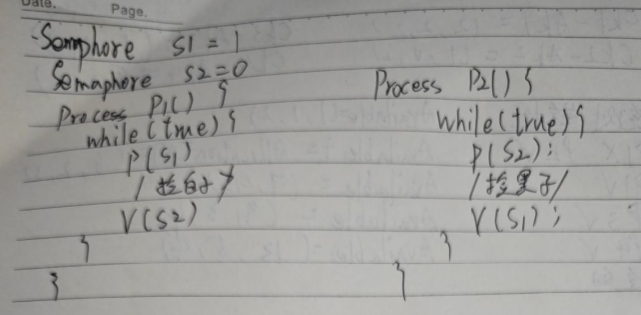
请用信号量和PV操作解决以下问题:桌上有一只盘子,最多可以容纳两个水果,每次仅能放入或取出一个水果。爸爸专向盘子中放苹果(apple),妈妈专向盘子中放橘子(orange),两个儿子专等吃盘子中的桔子,两个女儿专等吃盘子里的苹果。写出爸爸(father)、妈妈(mother)、儿子(son)和女儿(daughter)进程及所需定义的变量和信号量。用PV操作实现爸爸、妈妈、儿子、女儿间的同步与互斥关系。

设当前的系统状态如下,此时Available=(1,1,2)
| 进程 | Claim (R1, R2, R3) | Allocation (R1, R2, R3) | Available (R1, R2, R3) |
|---|---|---|---|
| P1 | 3, 2, 2 | 1, 0, 0 | 1, 1, 2 |
| P2 | 6, 1, 3 | 5, 1, 1 | |
| P3 | 3, 1, 4 | 2, 1, 1 | |
| P4 | 4, 2, 2 | 0, 0, 2 |

数组int A[100][100];元素按行存储,在虚拟系统中,采用LRU淘汰算法,一个进程有3页内存空间,每页可以存放200个整数,其中第1页存放程序,假定程序已在内容中,问:
A程序缺页次数为:____次;
B程序缺页次数为:____次。
程序A:
for(int i=0; i<100; i++)
for(int j=0; j<100; j++)
A[i,j]=0;程序B:
for(int j=0;j<100;j++)
for(int i=0;i<100;i++)
A[i,j]=0;程序 A 分析
代码逻辑:
1 | for(int i=0; i<100; i++) // 外层循环:行 |
访问顺序:A[0][0], A0, …, A[0][99], A[1][0], …
这是按行访问,与数组的按行存储顺序一致。
缺页计算过程:
A[0][0] 时,内存为空,发生
1次缺页,调入页0。A[2][0] 时,页1不在内存,发生
1次缺页,调入页1。结果:共有50个页面,每页调入一次。
Total = 50 次缺页。
程序 B 分析
代码逻辑:
1 | for(int j=0; j<100; j++) // 外层循环:列 |
访问顺序:A[0][0], A[1][0], A[2][0], …
这是按列访问,即“跳跃式”访问。
缺页计算过程:
i=0, 1: 访问第0、1行 →
需要 虚拟页0。i=2, 3: 访问第2、3行 →
需要 虚拟页1。i=98, 99: 访问第98、99行 → 需要 虚拟页49。j 从 0 到 99,共执行
100次。结果:5000 次缺页。
在一个请求分页虚存管理系统中,一个程序运行的页面走向是:1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3 6
分别用FIFO、OPT、和LRU算法,对于分配给程序3个页框的情况,求出缺页异常次数和缺页中断率:
(1)FIFO:缺页异常次数:_____次, 缺页中断率:______%.
(2)OPT:缺页异常次数:_____次, 缺页中断率:______%.
(3)LRU:缺页异常次数:_____次, 缺页中断率:______%.

一个页式虚拟存储管理系统中的用户空间为1024KB,页面大小为4KB,内存空间为512KB。已知用户的10、11、12、13号虚页分得的内存页框号为62、78、25、36,试将逻辑地址0BEBCH转换为对应的物理地址: _______H。
| 名词 | 英文 | 所在空间 | 本质 | 通俗解释(类比) |
|---|---|---|---|---|
| 页面 (Page) | Page | 逻辑/虚拟空间 (程序里) | 程序被切分成的“块” | 客人 (要住店的人) |
| 页号 (Page No.) | VPN | 逻辑/虚拟空间 | 页面的编号/索引 | 客人的身份证号 |
| 页框 (Page Frame) | Page Frame | 物理内存 (硬件里) | 内存条被切分成的“格” | 酒店的房间 (物理存在的空间) |
| 页块 (Block) | Physical Block | 物理内存 | 完全等同于“页框” (别名) | 完全等同于“房间” |
| 页框号 (PFN) | PFN | 物理内存 | 页框的物理编号 | 房间号码 (如 302 号房) |
| 页表 (Page Table) | Page Table | 内存中 (系统管理) | 映射表 (记录对应关系) | 前台登记簿 (记录谁住哪个房间) |


本文讲解matlab与opencv对图像处理的基础操作,代码会有matlab与python两版,可对比学习。
matlab
1 | I = imread('cameraman.jpg'); |
python
1 | I = cv2.imread('cameraman.jpg', cv2.IMREAD_COLOR) |
cv2.IMREAD_COLOR = 强制读成 3 通道 BGR
彩色图。
matlab
1 | imwrite(J,'cameramanC.jpg'); |
python
1 | cv2.imwrite('cameramanC.jpg', J) |
matlab
1 | Image1 = im2double(imread('lotus.jpg')); |
imread 把图像读成 0-255 的 uint8。im2double 把像素值线性缩放到 0–1
浮点,方便后续计算。为什么要转成double
如果像素是 0–255,你在代码里写
0.299*r就永远只用到 0.299×255≈76 灰度级,结果会整体偏暗甚至直接截断。几级灰度的含义是什么
几级灰度”这句话里的“级”就是“台阶”的意思: 把黑→白这段连续亮度等间隔切成多少份,就有多少个离散台阶,叫多少灰度级。
- 2 级灰度 → 纯黑 + 纯白,一共 2 个台阶(1 bit)
- 8 级灰度 → 0, 36, 73, 109, 146, 182, 219, 255(3 bit)
- 256 级灰度 → 0–255,共 256 个台阶(8 bit)
uint8是“Unsigned Integer, 8 bit”的缩写,含义一句话:无符号、8 位、整型数字,只能放 0–255 的整数。
1 | J=255-I; |
matlab
1 | r = Image1(:,:,1); |
分别提取rgb三个通道
opencv
1 | matlab:g = Image1(1,1,2)提取G通道的第一个像素点 |
opencv是从下标0开始
NTSC 标准
1 | Y = 0.299*r + 0.587*g + 0.114*b; |
0.299、0.587、0.114 是 NTSC 在 1953 年定下的“亮度加权系数”,源于人眼三种视锥细胞对 R、G、B 光谱的灵敏度——绿最亮、红次之、蓝最暗
1 | BW = zeros(size(Y)); % 先全黑 |
matlab
1 | hsi = rgb2hsv(img); |
HSI 颜色空间是把一幅彩色图像的每个像素拆成 3 个独立、且更符合人眼感知习惯的物理量:
1 | [N,M,~]=size(r); |
把二维矩阵 r 的“行数”赋给
N,“列数”赋给 M。
1 | newimage=img(H/4:H*3/4,W/4:W*3/4,:); |
Y “Luma”——亮度(Luminance)。 对应人眼最敏感的黑↔︎白信息,决定了你看到的“明暗”。 计算公式近似:
1 | Y = 0.299·R + 0.587·G + 0.114·B |
Cr “Chroma-red”——红色色度。 表示
红色与亮度的差值:Cr = R – Y
Cb “Chroma-blue”——蓝色色度。 表示
蓝色与亮度的差值:Cb = B – Y
人眼对 绿色最敏感,对 红、蓝最迟钝。 把“绿色”信息扔掉,只保留 R-Y 和 B-Y 两个差值,就能 最小化数据量,同时 还能把颜色还原回来。
1 | def skin_YCrCb(img): |
肤色聚类现象 大量统计表明:
1 | def skin_HSV(img): |
原理:将RGB图像转换到YCRCB空间,肤色像素点会聚集到一个椭圆区域。先定义一个椭圆模型,然后将每个RGB像素点转换到YCRCB空间比对是否再椭圆区域,是的话判断为皮肤。
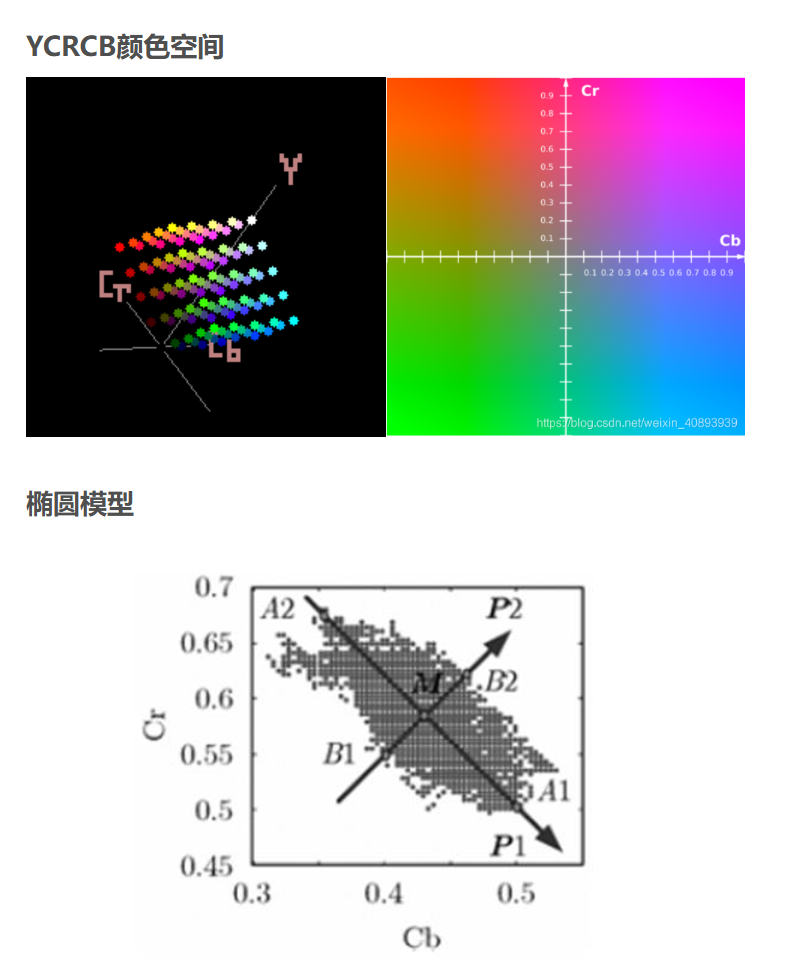
1 | # ---------------- 3. 椭圆模型法 ---------------- |
1 | img_swap = img(:,:,[3 1 2]); |
在 MATLAB 中,读取彩色图像(如用
imread)默认是 RGB 顺序:
但在 OpenCV(Python/C++) 中,图像默认是 BGR 顺序:
1 | clear; clc; close all; % 清空所有变量 |
1 | I = imread('gugong1.jpg'); |

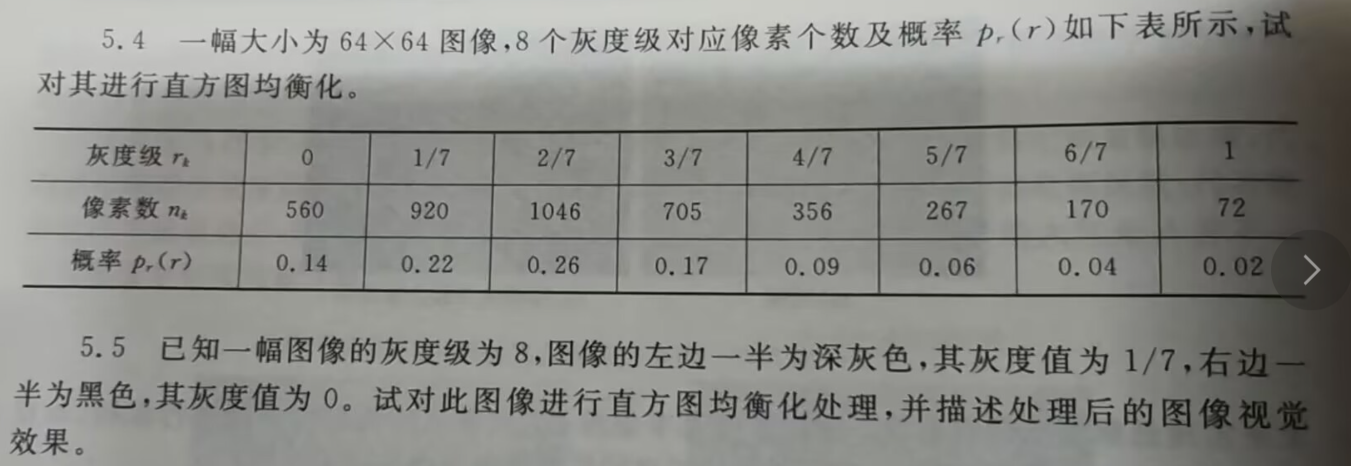


5.4代码
opencv
1 | import numpy as np |
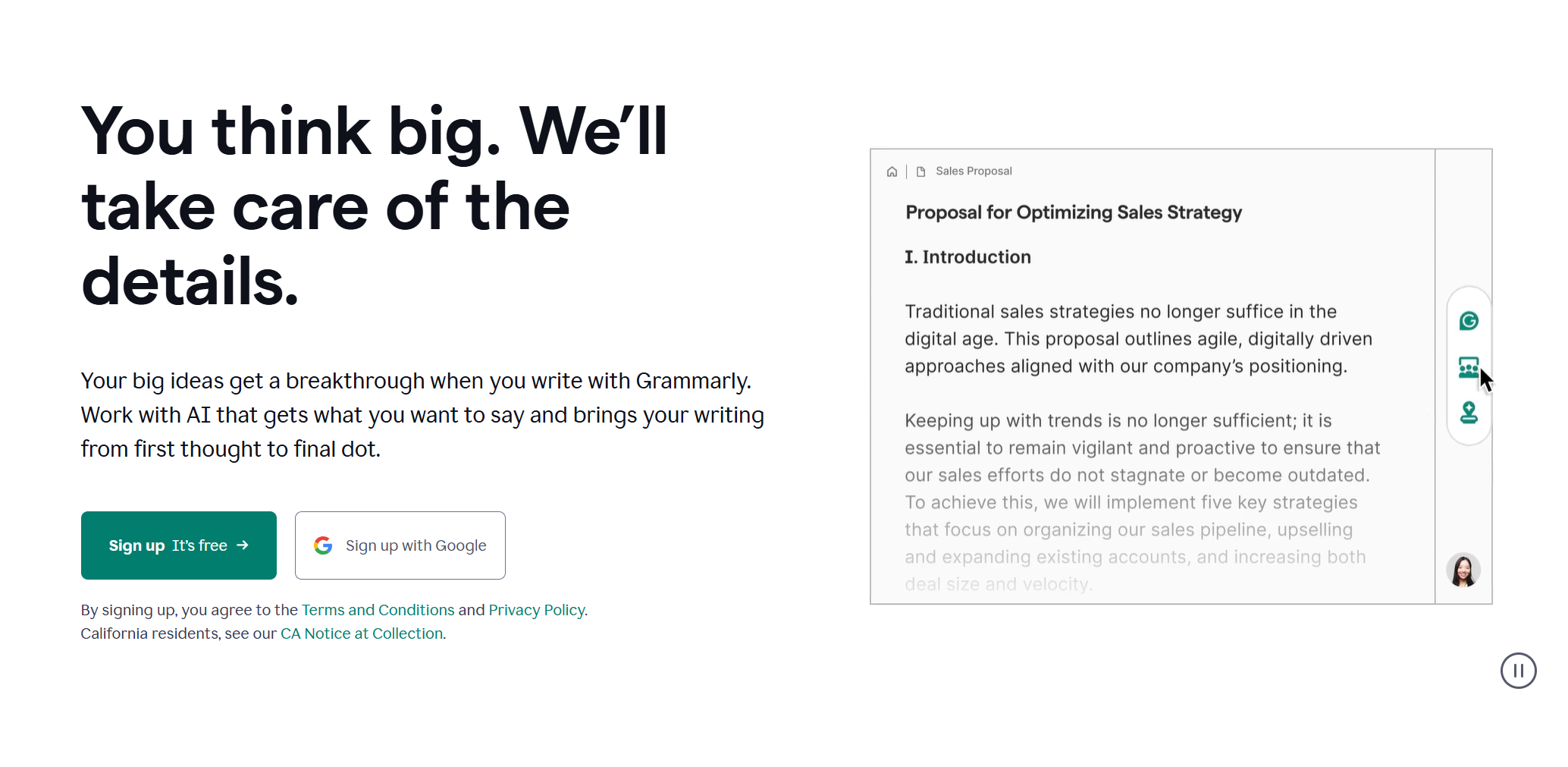
1.开始界面,大概说明产品的定位和作用,让用户可以快速注册后进入
Grammarly: Free AI Writing Assistance
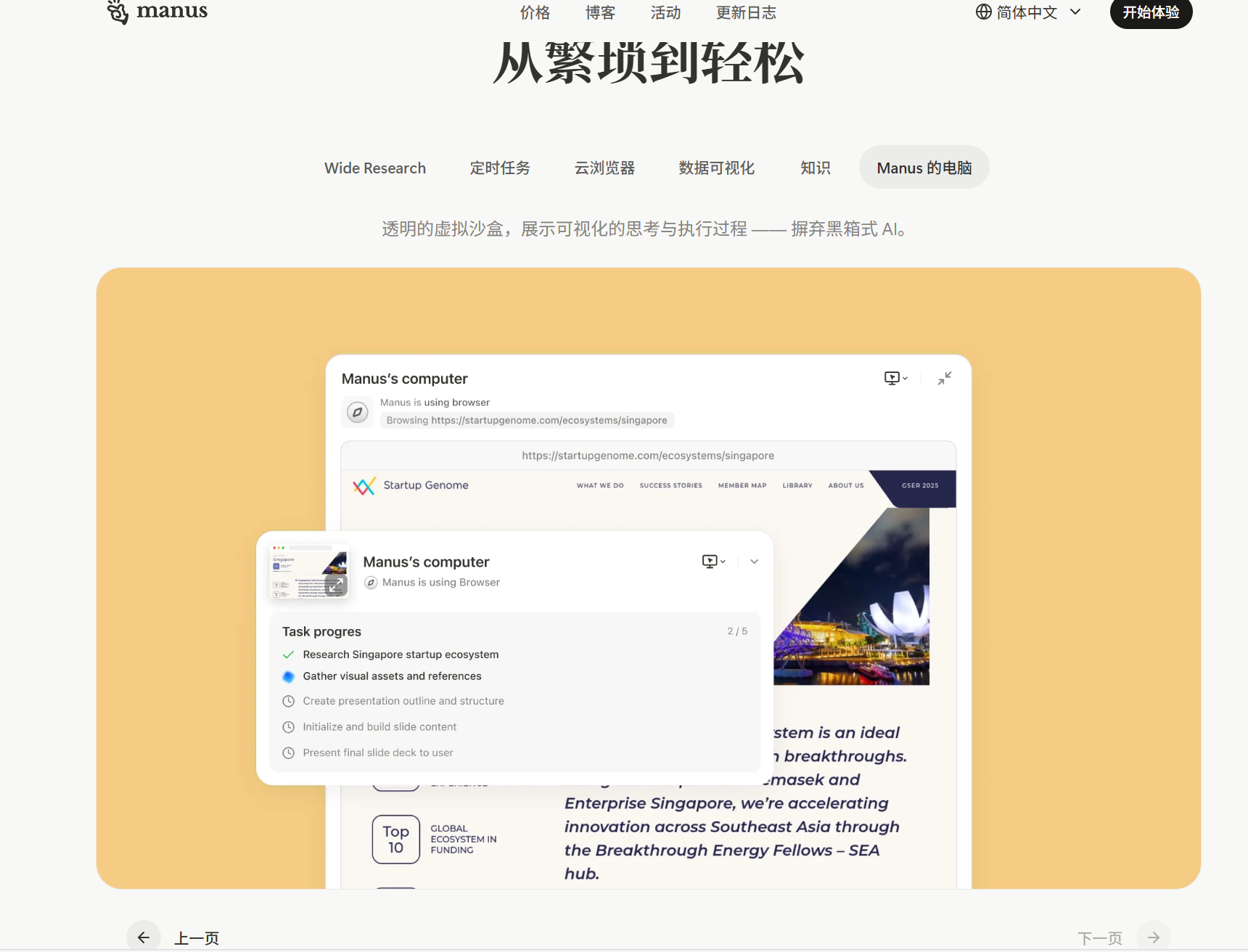
2.展示产品的特点功能和使用范例:1.特点功能这块可以像manus把使用过程中比较有特点的功能截屏,做成下面这样;2.范例部分结构可以参考manus或者lovart垂直滑动的效果,效果可以参考genspackGenspark - AI 幻灯片
专为演示文稿打造的 Gamma | 利用 AI 立即构建演示文稿 | Gamma

3.用户的声音,价格。用户声音我觉得参考lovart就可以,声音这边也可以使用一个滚动的效果
TRAE - Collaborate with Intelligence
我感觉我们的风格应该还是要简约大气
这个项目的核心就是基于python-pptx的这个包,其实跟我们不是很符合。
他们ppt生成的逻辑核心是模板,一定要有pptx模板,并带有每个部分的备注,上传后解析,把ppt的各个结构转化成json存储
1 | file = models.FileField( |
生成ppt时,也是让大模型生成符合这种规范的json,然后通过python-pptx填入。
这样好处确实是解决了使用python-pptx时,生成的ppt结构混乱的问题,但是这样生成的ppt完全依赖于你输入的模板,灵活性上有所缺陷。
1.导出speaknotes-pdf后端
2.生成完整presentation
1 | docker pull postgres |
docker 运行postgresql 极限简洁教程 - 刘老六 - 博客园
使用pg_restore
1 | # 1. 删除现有数据库 |
以下是数据库导入的原理
作用 :Table of Contents,包含备份的元数据信息
内容 :数据库结构、表定义、索引、约束、函数等的描述
格式 :二进制格式,记录了所有数据库对象的信息
作用 :存储实际的表数据
命名规则 :数字对应数据库对象的 OID(Object Identifier)
作用 :包含恢复数据库的 SQL 命令
内容 :CREATE TABLE、INSERT、索引创建等语句
pg_restore 工作流程
范例
1 | --- |
1 | # models.py |
建立表
1 | DATABASE_URL = "postgresql://postgres:123456@localhost:5432/factory_db" |
1 | # create_tables.py |
可以通过此GitHub 链接获得本文所列主要方法的简单实现。
我们可以根据 RAG 管道各阶段的作用对不同的 RAG 增强方法进行分类。
接下来,我们将介绍每个类别下的具体方法。
共有四种方式:假设问题、假设文档嵌入、子查询和回溯提示。接下来我将选取几个具体说明。
HyDE 是假设文档嵌入的缩写。它利用 LLM 制作一个“假设文档*”或虚假*答案,以回应没有上下文信息的用户查询。然后,这个假答案会被转换成向量嵌入,并用于查询向量数据库中最相关的文档块。随后,向量数据库会检索出 Top-K 最相关的文档块,并将它们传送给 LLM 和原始用户查询,从而生成最终答案。
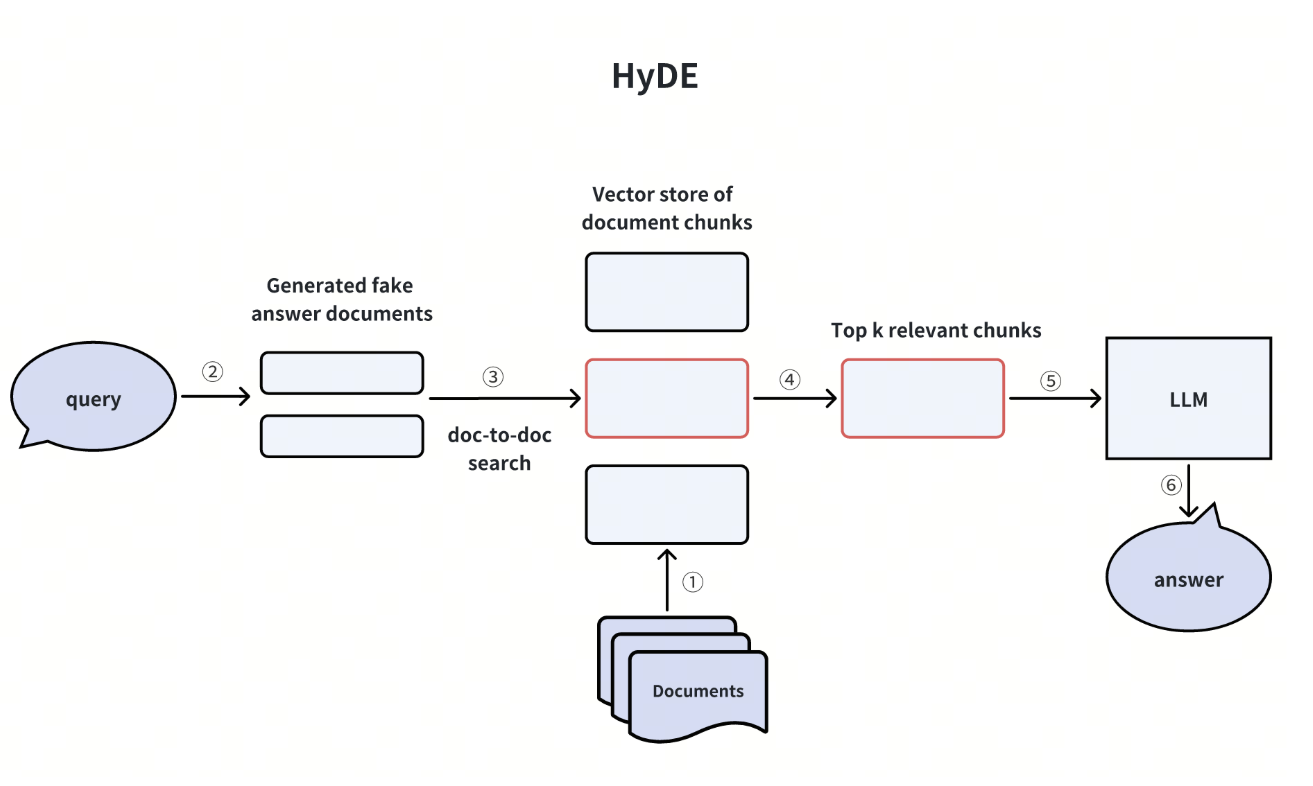
这种方法在解决向量搜索中的跨域不对称问题方面与假设问题技术类似。不过,它也有缺点,如增加了计算成本和生成虚假答案的不确定性。
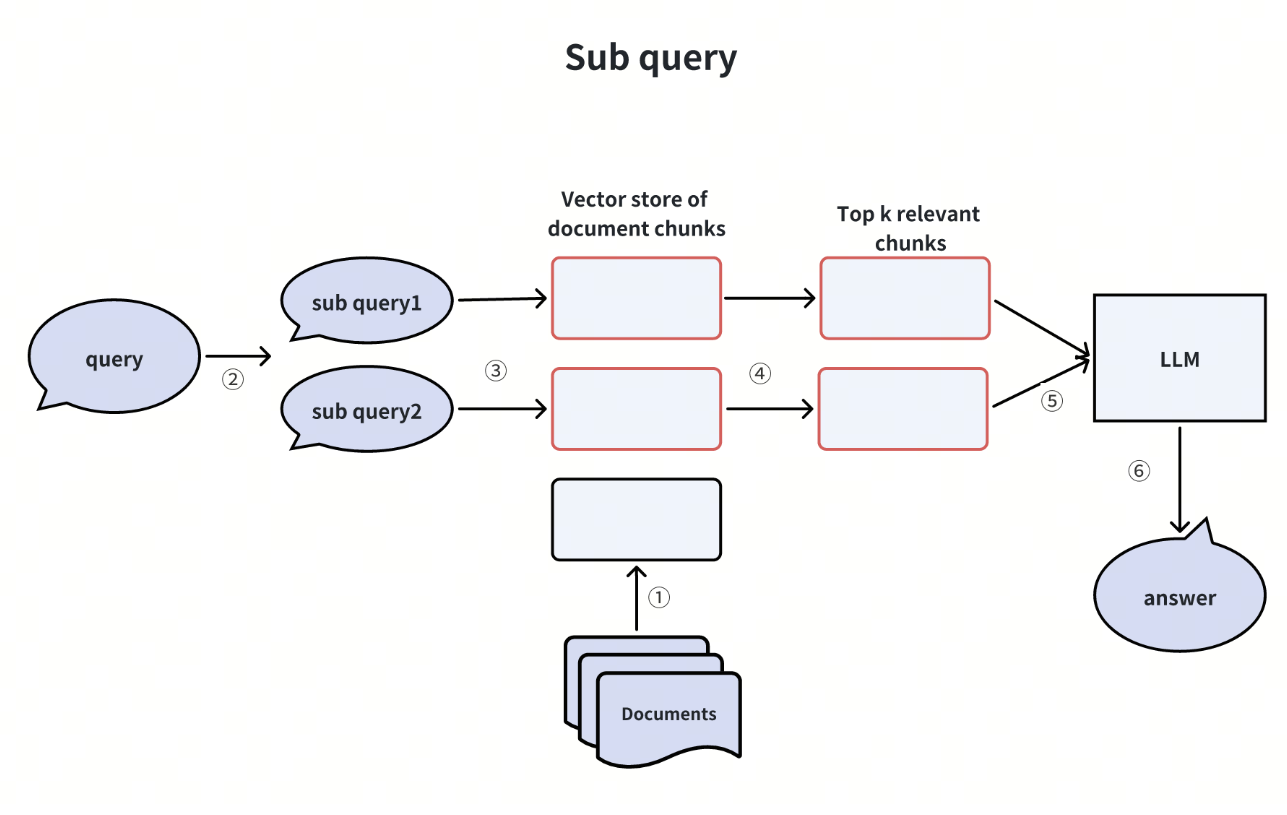
当用户查询过于复杂时,我们可以使用 LLM 将其分解为更简单的子查询,然后再将其传递给向量数据库和 LLM。让我们来看一个例子。
想象一下,用户会问*“Milvus 和 Zilliz Cloud 在功能上有什么不同?*”这个问题相当复杂,在我们的知识库中可能没有直接的答案。为了解决这个问题,我们可以将其拆分成两个更简单的子查询:
有了这些子查询后,我们将它们全部转换成向量嵌入后发送给向量数据库。然后,向量数据库会找出与每个子查询最相关的 Top-K 文档块。最后,LLM 利用这些信息生成更好的答案。
增强索引是提高 RAG 应用程序性能的另一种策略。让我们来探讨三种索引增强技术:自动合并文档块,构建分层索引,混合检索和重新排名
在创建文档索引时,我们可以建立两级索引:一级是文档摘要索引,另一级是文档块索引。向量搜索过程包括两个阶段:首先,我们根据摘要过滤相关文档,随后,我们在这些相关文档中专门检索相应的文档块。
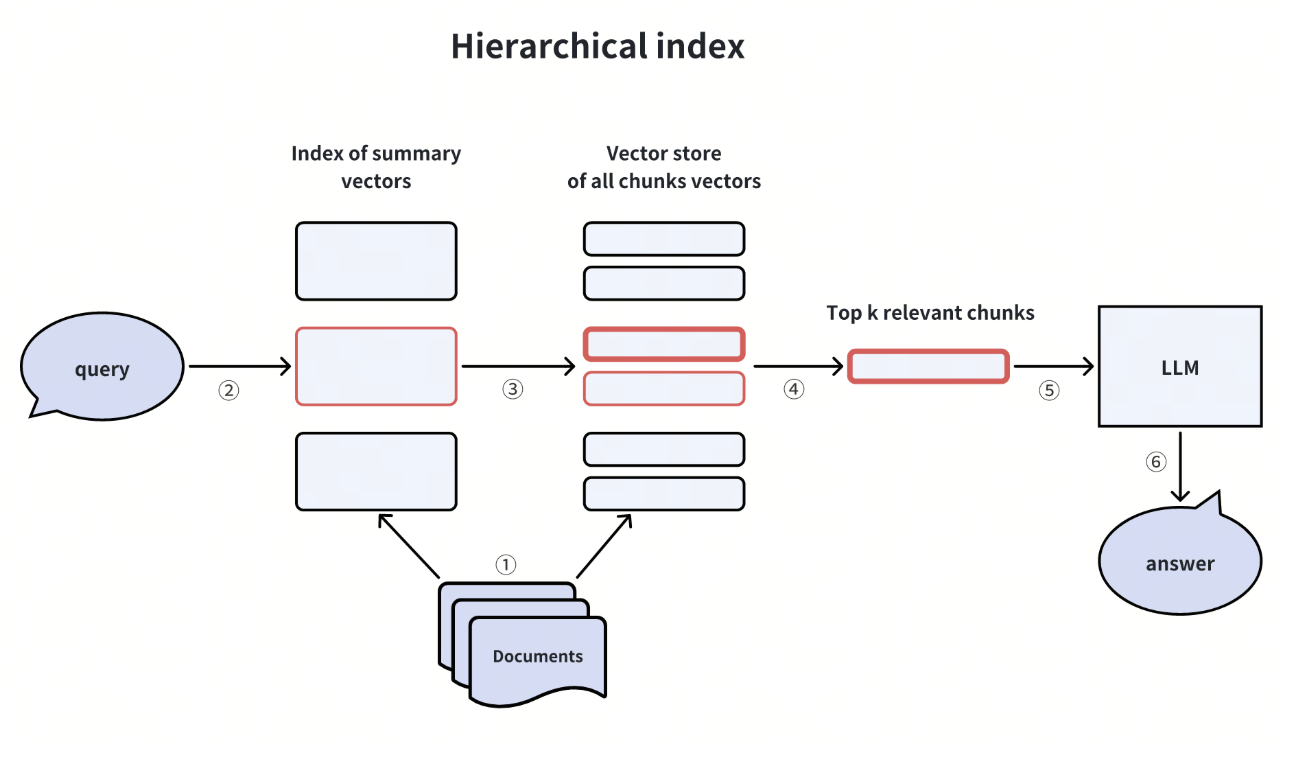
在涉及大量数据或数据分层的情况下,例如图书馆 Collections 中的内容检索,这种方法证明是有益的。
混合检索和重排技术将一种或多种辅助检索方法与向量相似性检索相结合。然后,Reranker会根据检索结果与用户查询的相关性对检索结果重新排序。
常见的补充检索算法包括基于词频的方法(如BM25)或利用稀疏嵌入的大模型(如SPLADE)。重新排序算法包括 RRF 或更复杂的模型,如Cross-Encoder(类似于 BERT 的架构)。
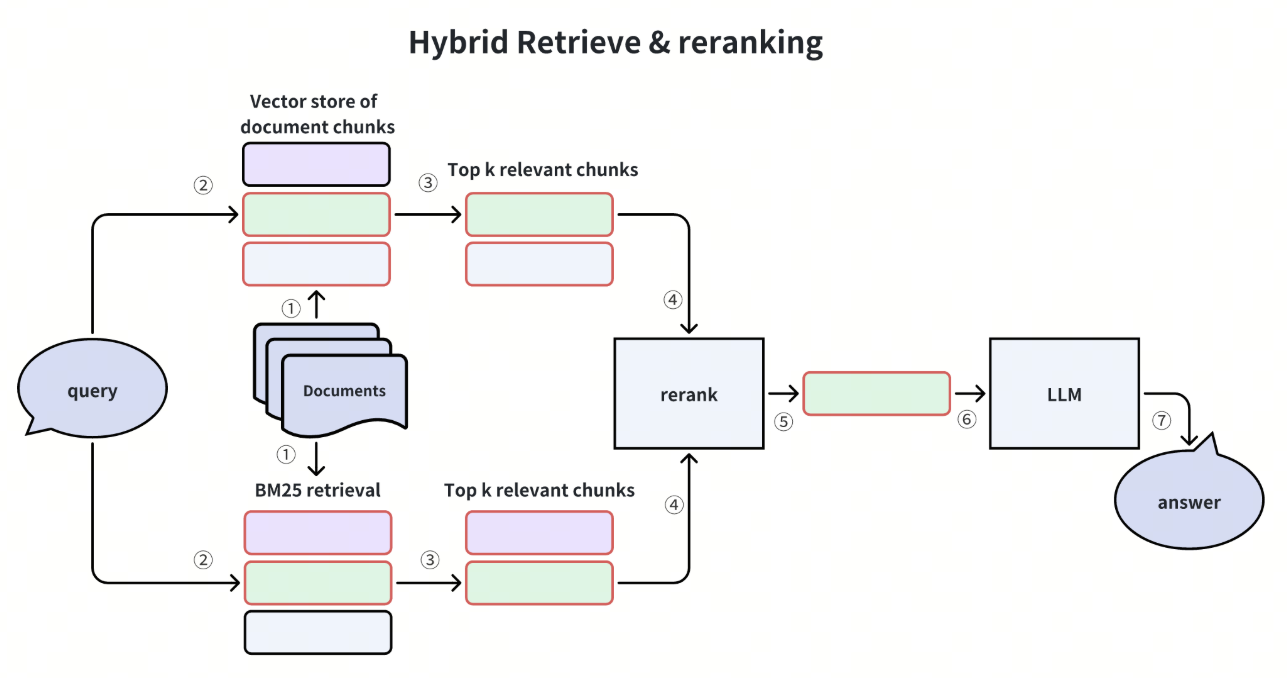
改进 RAG 系统中的检索器组件也能改进 RAG 应用。让我们来探讨一些增强检索器的有效方法:句子窗口检索,元数据过滤
让我们通过改进 RAG 系统中的生成器来探索更多 RAG 优化技术:压缩 LLM 提示,调整提示中的块顺序
在论文Lost in the Middle“中,研究人员观察到,LLMs 在推理过程中经常会忽略给定文档中间的信息。相反,他们往往更依赖于文档开头和结尾的信息。
根据这一观察结果,我们可以调整检索知识块的顺序来提高答案质量:在检索多个知识块时,将置信度相对较低的知识块放在中间,而将置信度相对较高的知识块放在两端。
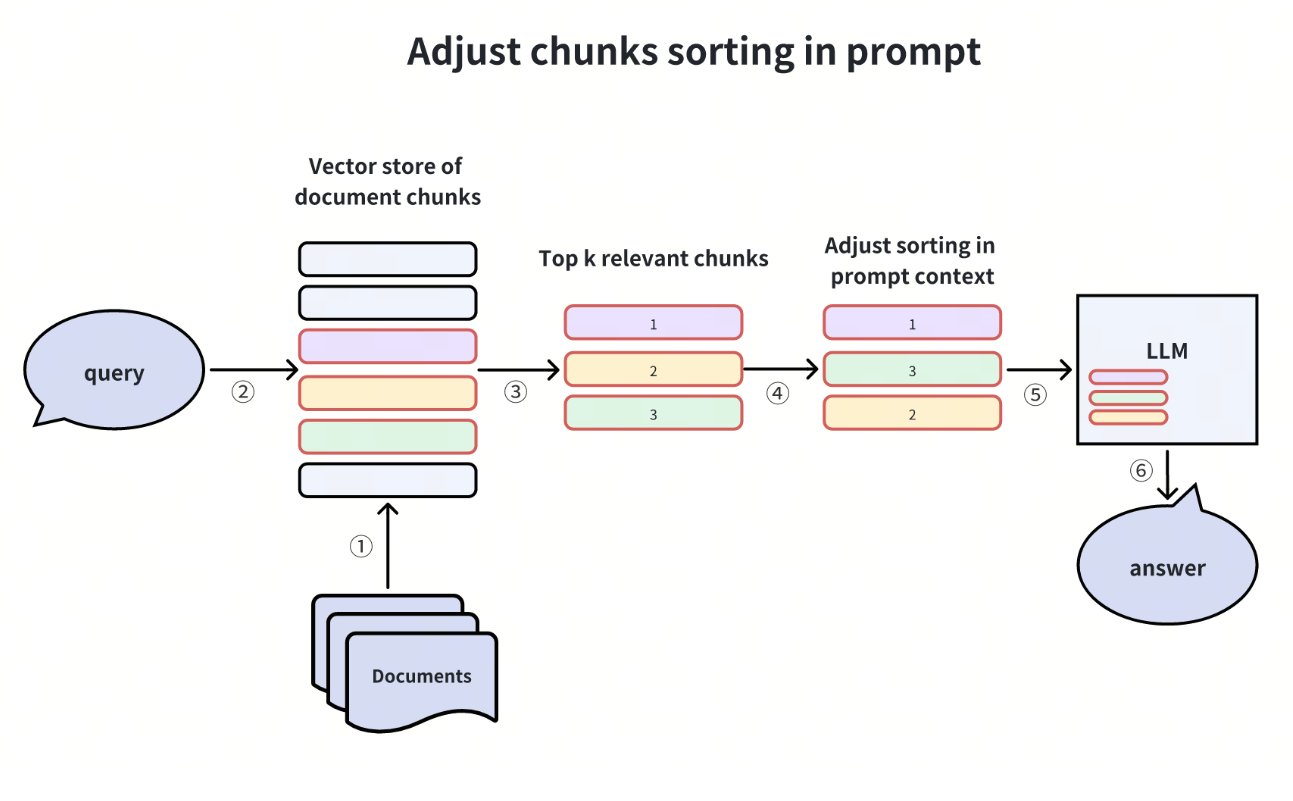
我们还可以通过增强整个 RAG 管道来提高 RAG 应用程序的性能。
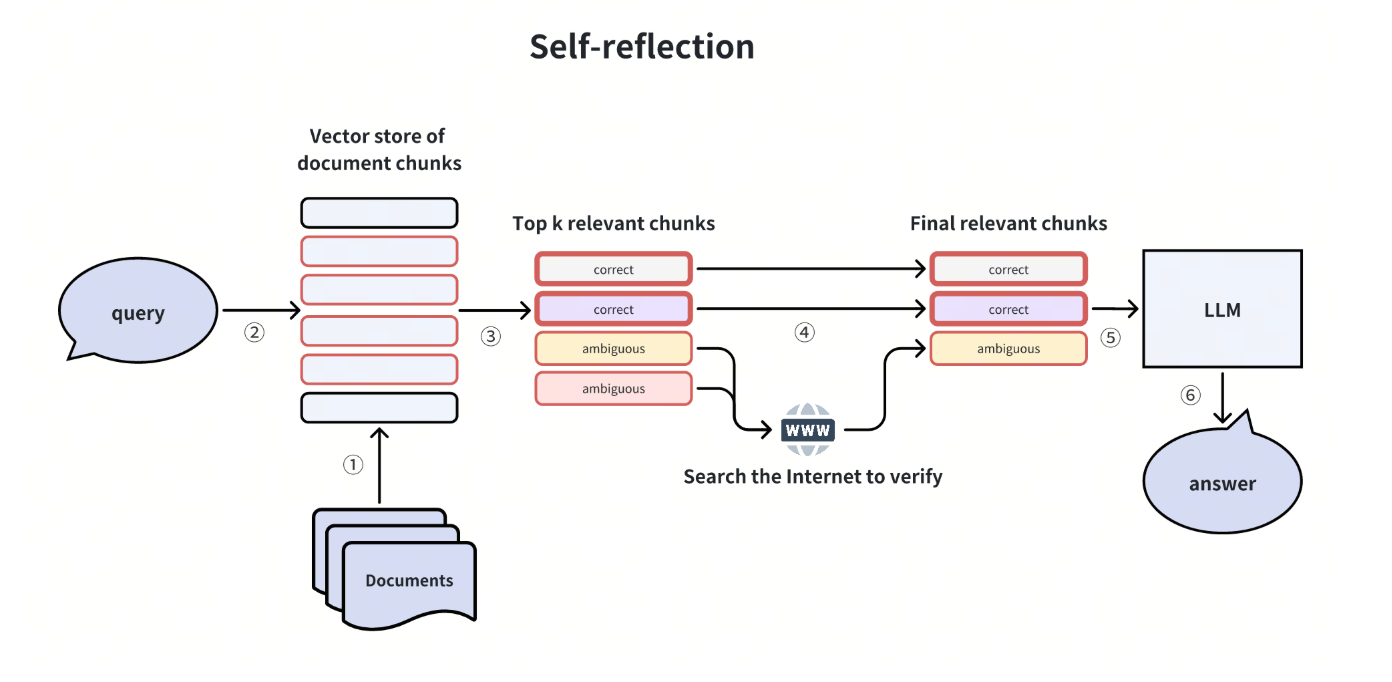
这种方法在人工智能 Agents 中融入了自我反思的概念。那么,这种技术是如何工作的呢?
一些最初检索到的 Top-K 文档块是模棱两可的,可能无法直接回答用户的问题。在这种情况下,我们可以进行第二轮反思,以验证这些文档块是否能真正解决查询问题。
我们可以使用高效的反思方法(如自然语言推理(NLI)模型)进行反思,也可以使用互联网搜索等其他工具进行验证。
有时,我们不必使用 RAG 系统来回答简单的问题,因为它可能会导致更多的误解和对误导信息的推断。在这种情况下,我们可以在查询阶段使用代理作为路由器。这个 Agents 会评估查询是否需要通过 RAG 管道。如果需要,则启动后续的 RAG 管道;否则,LLM 直接处理查询。
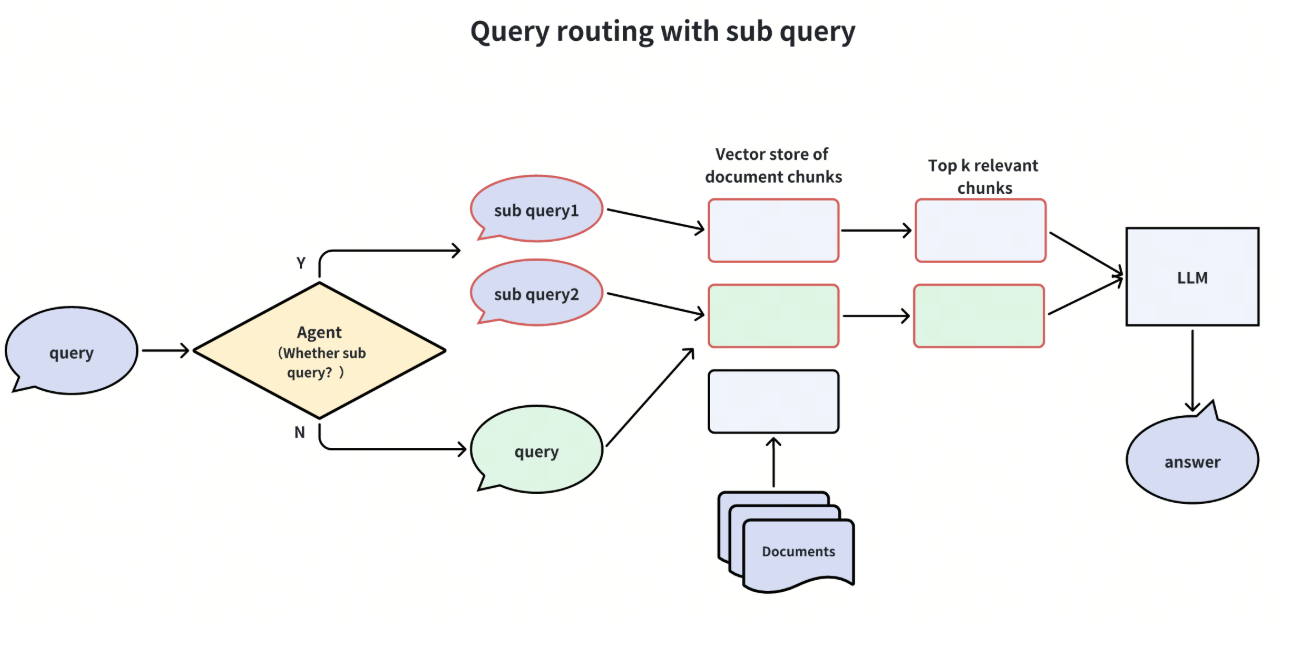
Agents 可以有多种形式,包括 LLM、小型分类模型,甚至是一组规则。
通过根据用户意图路由查询,可以重新定向部分查询,从而显著提高响应时间,并明显减少不必要的噪音。
我们可以将查询路由技术扩展到 RAG 系统内的其他流程,例如确定何时利用网络搜索等工具、进行子查询或搜索图片。这种方法可确保 RAG 系统中的每个步骤都能根据查询的具体要求进行优化,从而提高信息检索的效率和准确性。
非结构化数据(如文本、图像和音频)格式各异,蕴含丰富的潜在语义,因此分析起来极具挑战性。为了处理这种复杂性,Embeddings 被用来将非结构化数据转换成能够捕捉其基本特征的数字向量。然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。
Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON,为您节省了维护多个数据库系统的精力。
在 Docker(Linux)中运行 Milvus | Milvus 文档
1 | # Download the configuration file and rename it as docker-compose.yml |
注意设置环境变量DOCKER_VOLUME_DIRECTORY来决定卷映射的路径
| 容器 | 镜像 | 在 Milvus 中的角色 | 一句话说明 |
|---|---|---|---|
| etcd | quay.io/coreos/etcd:v3.5.18 | 元数据与协调中心 | 负责“记帐”——存索引结构、集合信息、节点心跳等,相当于 Milvus 的“大脑备忘录”。 |
| minio | minio/minio:RELEASE.2024-12-18T13-15-44Z | 对象存储 | 负责“存文件”——把向量索引文件、大字段、日志快照等落地成对象,相当于 Milvus 的“硬盘”。 |
| standalone | milvusdb/milvus:v2.6.0 | 计算节点(单机版) | 负责“干活”——接受 SDK 请求、做向量检索、构建索引,相当于 Milvus 的“工人”。 |
1 | pip install -U pymilvus |
在 Milvus 中,数据库是组织和管理数据的逻辑单元。为了提高数据安全性并实现多租户,你可以创建多个数据库,为不同的应用程序或租户从逻辑上隔离数据。例如,创建一个数据库用于存储用户 A 的数据,另一个数据库用于存储用户 B 的数据。
在 Milvus 上,您可以创建多个 Collections 来管理数据,并将数据作为实体插入到 Collections 中。Collections 和实体类似于关系数据库中的表和记录。
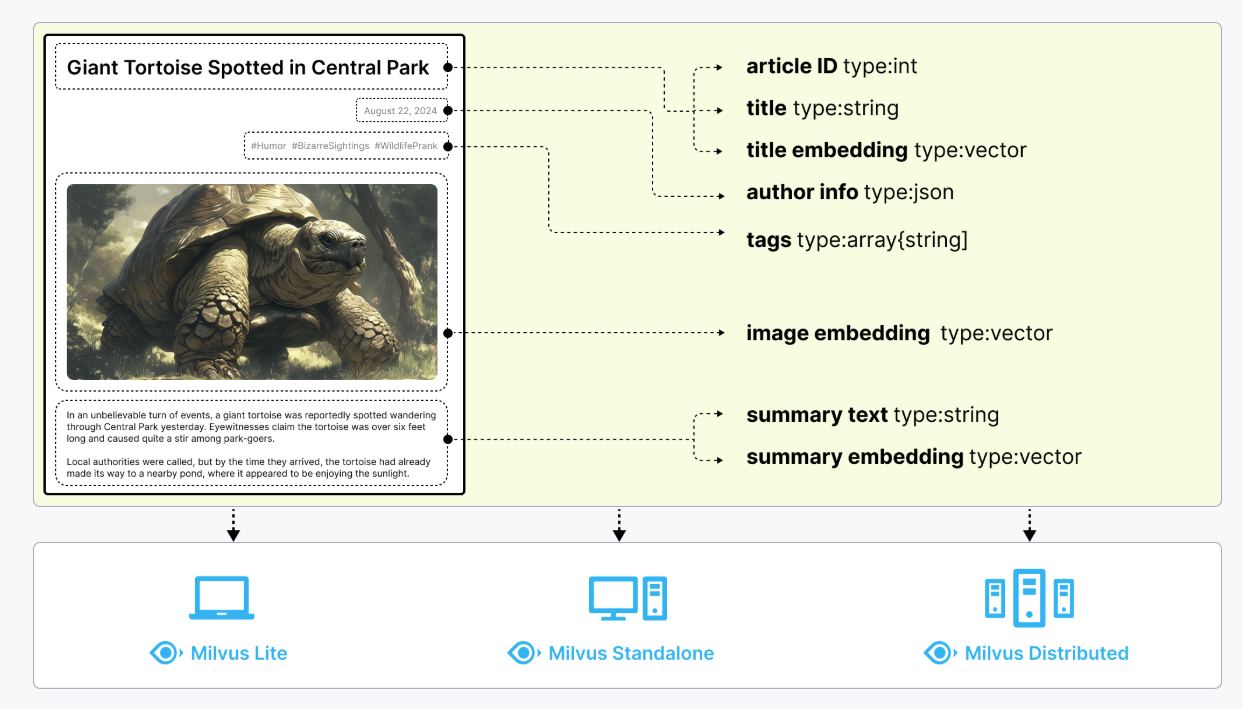
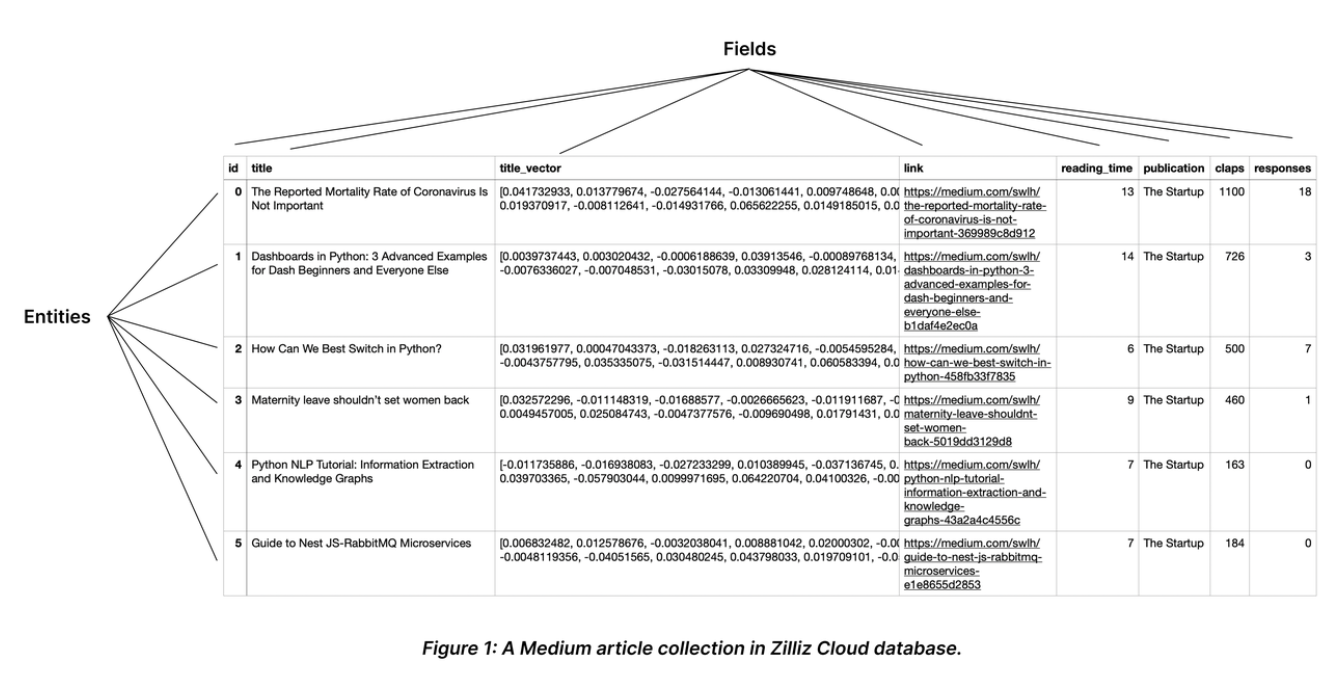
Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。
下图显示了一个有 8 列和 6 个实体的 Collection。
Schema 定义了 Collections 的数据结构。在创建一个 Collection 之前,你需要设计出它的 Schema。
设计良好的 Schema 至关重要,因为它抽象了数据模型,并决定能否通过搜索实现业务目标。此外,由于插入 Collections 的每一行数据都必须遵循 Schema,因此有助于保持数据的一致性和长期质量。从技术角度看,定义明确的 Schema 会带来组织良好的列数据存储和更简洁的索引结构,从而提升搜索性能。
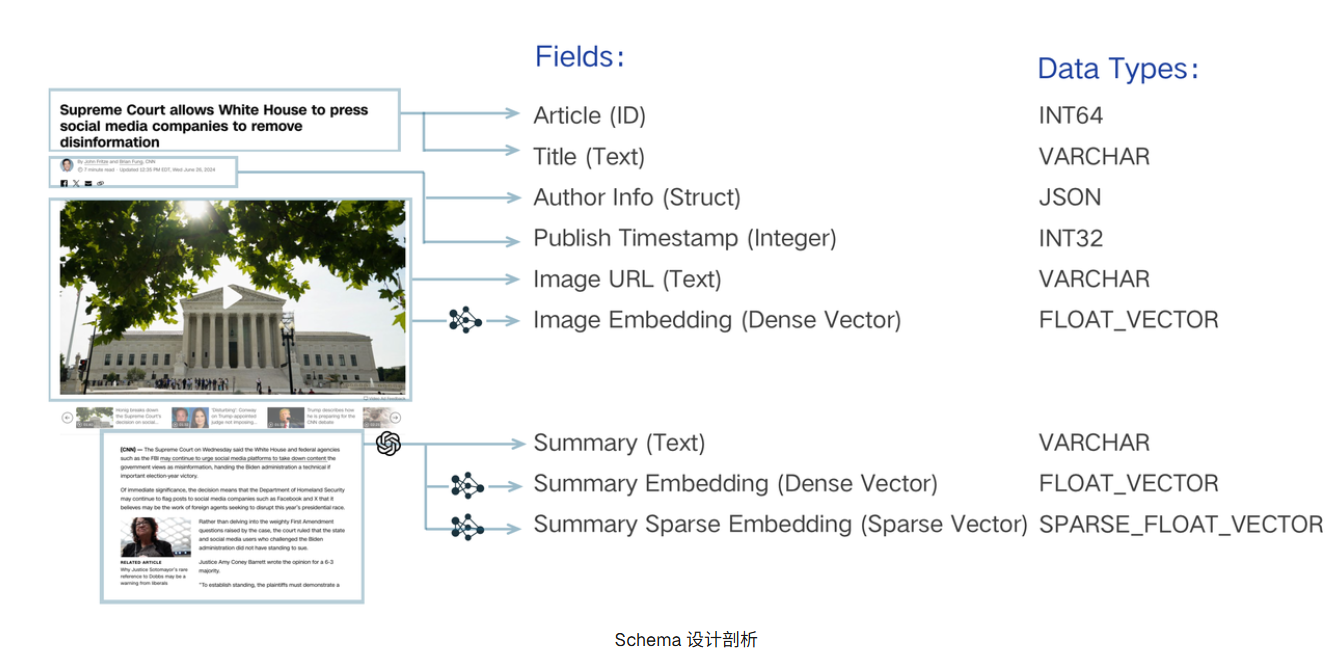
一个 Collection Schema 有一个主键、最多四个向量字段和几个标量字段。下图说明了如何将文章映射到模式字段列表。
使用 Milvus 和 LangChain 的检索增强生成(RAG) | Milvus 文档
本人实现的用于分块后存储入milvus的类
1 | class MilvusStorage: |
近似近邻(ANN)搜索以记录向量嵌入排序顺序的索引文件为基础,根据接收到的搜索请求中携带的查询向量查找向量嵌入子集,将查询向量与子群中的向量进行比较,并返回最相似的结果。
ANN 和 k-Nearest Neighbors (kNN) 搜索是向量相似性搜索的常用方法。在 kNN 搜索中,必须将向量空间中的所有向量与搜索请求中携带的查询向量进行比较,然后找出最相似的向量,这既耗时又耗费资源。
与 kNN 搜索不同,ANN 搜索算法要求提供一个索引文件,记录向量 Embeddings 的排序顺序。当收到搜索请求时,可以使用索引文件作为参考,快速找到可能包含与查询向量最相似的向量嵌入的子组。然后,你可以使用指定的度量类型来测量查询向量与子组中的向量之间的相似度,根据与查询向量的相似度对组成员进行排序,并找出前 K 个组成员。
ANN 搜索依赖于预建索引,搜索吞吐量、内存使用量和搜索正确性可能会因选择的索引类型而不同。您需要在搜索性能和正确性之间取得平衡。
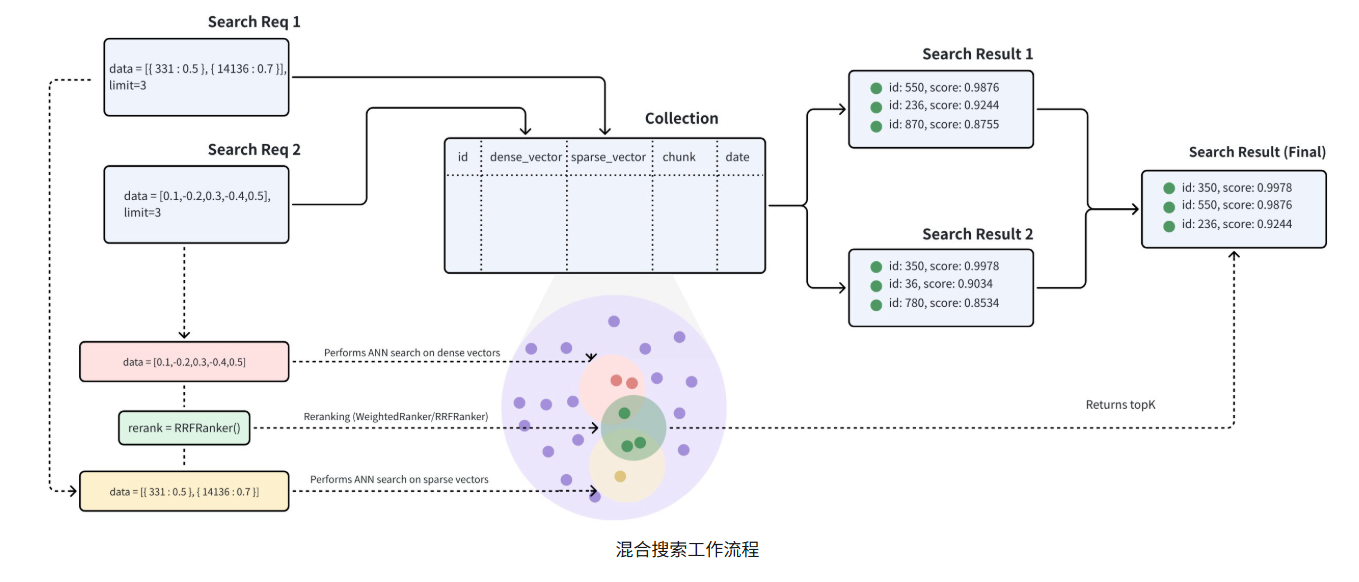
让我们考虑一个真实世界的使用案例,其中每个产品都包含文字描述和图片。根据可用数据,我们可以进行三种类型的搜索:
混合检索的构建流程:
创建具有多个向量场的 Collections
插入数据‘
执行混合搜索
创建多个 AnnSearchRequest 实例
混合搜索是通过在hybrid_search()
函数中创建多个AnnSearchRequest
来实现的,其中每个AnnSearchRequest 代表一个特定向量场的基本
ANN
搜索请求。因此,在进行混合搜索之前,有必要为每个向量场创建一个AnnSearchRequest
。
配置 Rerankers 策略
要对 ANN 搜索结果集进行合并和重新排序,选择适当的重新排序策略至关重要。Milvus 提供两种重排策略:
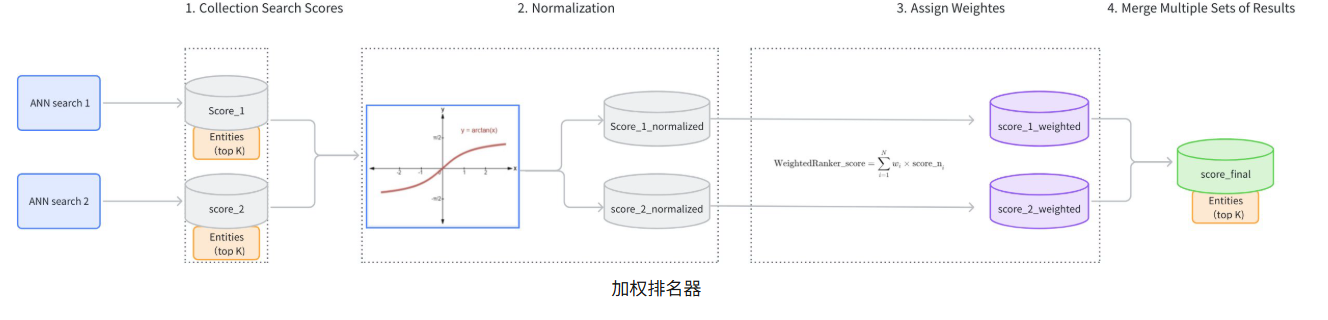
加权排名器通过为每个搜索路径分配不同的重要性权重,智能地组合来自多个搜索路径的结果并确定其优先级。与技艺高超的厨师平衡多种配料以制作完美菜肴的方式类似,加权排名器也会平衡不同的搜索结果,以提供最相关的综合结果。这种方法非常适合在多个向量场或模式中进行搜索,其中某些场对最终排名的贡献应比其他场更大。
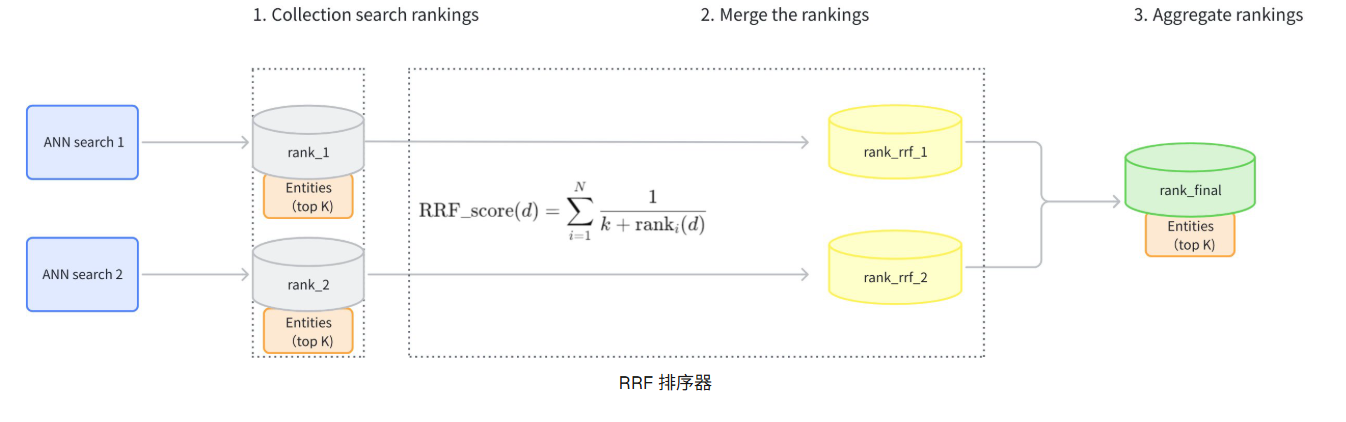
互惠排名融合(RRF)排名器是 Milvus 混合搜索的一种重新排名策略,它根据多个向量搜索路径的排名位置而不是原始相似度得分来平衡搜索结果。就像体育比赛考虑的是球员的排名而不是个人统计数据一样,RRF Ranker 根据每个项目在不同搜索路径中的排名高低来组合搜索结果,从而创建一个公平、均衡的最终排名。
RRF Ranker 专门设计用于混合搜索场景,在这种场景中,您需要平衡来自多个向量搜索路径的结果,而无需分配明确的重要性权重。
Milvus 支持四个级别的多租户:数据库、Collection、Partition 和Partition Key。
| ** 数据库级** | Collections 级 | 分区级 | 分区 Key 级 | |
|---|---|---|---|---|
| 数据隔离 | 物理 | 物理 | 物理 | 物理 + 逻辑 |
| 最大租户数 | 默认为 64 个。您可以通过修改 Milvus.yaml
配置文件中的maxDatabaseNum 参数来增加租户数。 |
默认为 65,536。可以通过修改 Milvus.yaml
配置文件中的maxCollectionNum 参数来增加。 |
每个 Collection 最多 1,024 个。 | 百万 |
| 数据 Schema 灵活性 | 高 | 中 | 低 | 低 |
| RBAC 支持 | 支持 | 支持 | 支持 | 不支持 |
| 搜索性能 | 强 | 强 | 中等 | 中等 |
| 跨租户搜索支持 | 不支持 | 支持 | 支持 | 是 |
| 支持有效处理冷热数据 | 是 | 是 | 支持 | 否 目前不支持 Partition Key 级策略。 |
多模态rag用 Milvus 制作多模态 RAG | Milvus 文档
交叉熵(Cross-Entropy)主要用于衡量两个概率分布之间的差异。在分类任务中,它被广泛用作损失函数,来评估模型预测结果与真实标签之间的“不匹配程度”。
一个事件 ( x ) 发生的概率为 ( p(x) ),其信息量定义为: [ I(x) = -p(x) ] - 概率越小的事件,发生时带来的信息量越大(比如“太阳从西边升起”)。 - 单位通常是 比特(bit)(以 2 为底)或 纳特(nat)(以自然对数 ( e ) 为底)。
熵是一个概率分布的平均信息量,表示该分布的不确定性: [ H(p) = -_{x} p(x) p(x) ] - 熵越大,不确定性越高(比如公平硬币的熵比偏硬币大)。
现在有两个分布: - 真实分布 ( p(x) )(比如真实标签) - 模型预测分布 ( q(x) )(比如神经网络输出的概率)
交叉熵衡量的是:当我们用分布 ( q ) 来编码来自分布 ( p ) 的事件时,平均需要多少比特。
数学定义为: [ H(p, q) = -_{x} p(x) q(x) ]
🔍 注意:交叉熵 ≠ 熵。
- 熵:( H(p) = -p p )
- 交叉熵:( H(p, q) = -p q )
Sigmoid 的交叉熵损失函数(通常称为 二元交叉熵损失,Binary Cross-Entropy Loss)是用于二分类问题中,结合 Sigmoid 激活函数使用的损失函数。
在二分类任务中,模型输出一个实数值 ( z )(logit)。
通过 Sigmoid 函数将其映射到概率区间 ([0, 1]): [ = (z) = ] 其中 () 表示预测为正类(标签为 1)的概率。
真实标签 ( y {0, 1} )。
对于单个样本,损失函数定义为:
[ (y, ) = -]
其中: - 若 ( y = 1 ),损失为 ( -() ) - 若 ( y = 0 ),损失为 ( -(1 - ) )
Softmax 函数
给定 logits 向量 ( = [z_1, z_2, …, z_C] )(C 为类别数),Softmax 输出预测概率:
[ _i = (z_i) = ]
交叉熵损失(单个样本)
真实标签为 one-hot 向量 ( = [y_1, y_2, …, y_C] ),其中只有真实类别位置为 1,其余为 0。
损失函数为:
[ = -_{i=1}^{C} y_i (_i) ]
由于 ( y_i ) 只有一个为 1(设真实类别为 ( c )),上式简化为:
[ = -(_c) = -( ) ]
进一步化简:
[ = -z_c + ( _{j=1}^{C} e^{z_j} ) ]
1.Sigmoid(逐元素)
对输入 ( x )(标量或向量中的每个元素): [ (x) = (0, 1) ]
📌 如果输入是向量 ( = [x_1, x_2, …, x_n] ),则输出: [ [(x_1), (x_2), …, (x_n)] ] 每个元素独立计算,彼此无关。
2. Softmax(整体归一化)
对输入向量 ( = [z_1, z_2, …, z_C] ): [ (z_i) = (0, 1) ]
✅ 满足:( _{i=1}^{C} (z_i) = 1 )
应用场景对比
Sigmoid 适用场景:
多标签分类(Multi-label)
[0.9, 0.2, 0.8] 表示属于类别 0 和 2Softmax 适用场景:
多分类问题(Multi-class, 互斥)
[0.1, 0.7, 0.2] 表示最可能是类别 1简单来说
- “多选一” → Softmax
- “可多选” 或 “是/否” → Sigmoid
问题在于 损失函数:
如果你用 Binary Cross-Entropy (BCE)(Sigmoid 的配套损失):
- [y₁·log(p₁) + y₂·log(p₂) + y₃·log(p₃)][0, 1, 0],损失只惩罚“狗”的预测(希望
p₂→1),但不惩罚“猫”和“鸟”是否太高![0.9, 0.95, 0.8],虽然选对了“狗”,但对其他类也过于自信,泛化差。而 Softmax + Cross-Entropy:
-log(p₂)p₂ = e^{z₂}/(e^{z₁}+e^{z₂}+e^{z₃}),要让
p₂ 变大,必须让 z₂ 相对于 z₁、z₃ 更大。