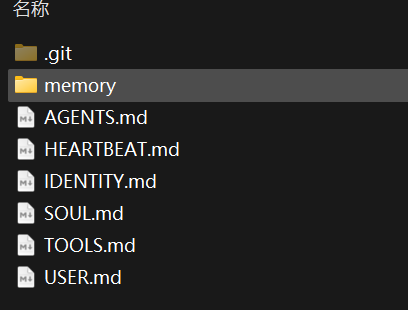
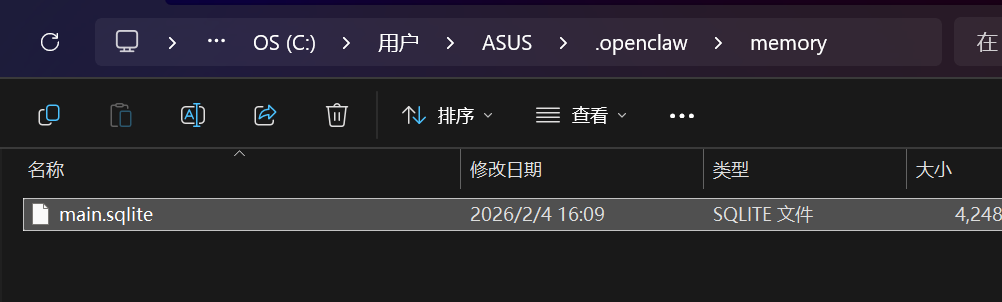
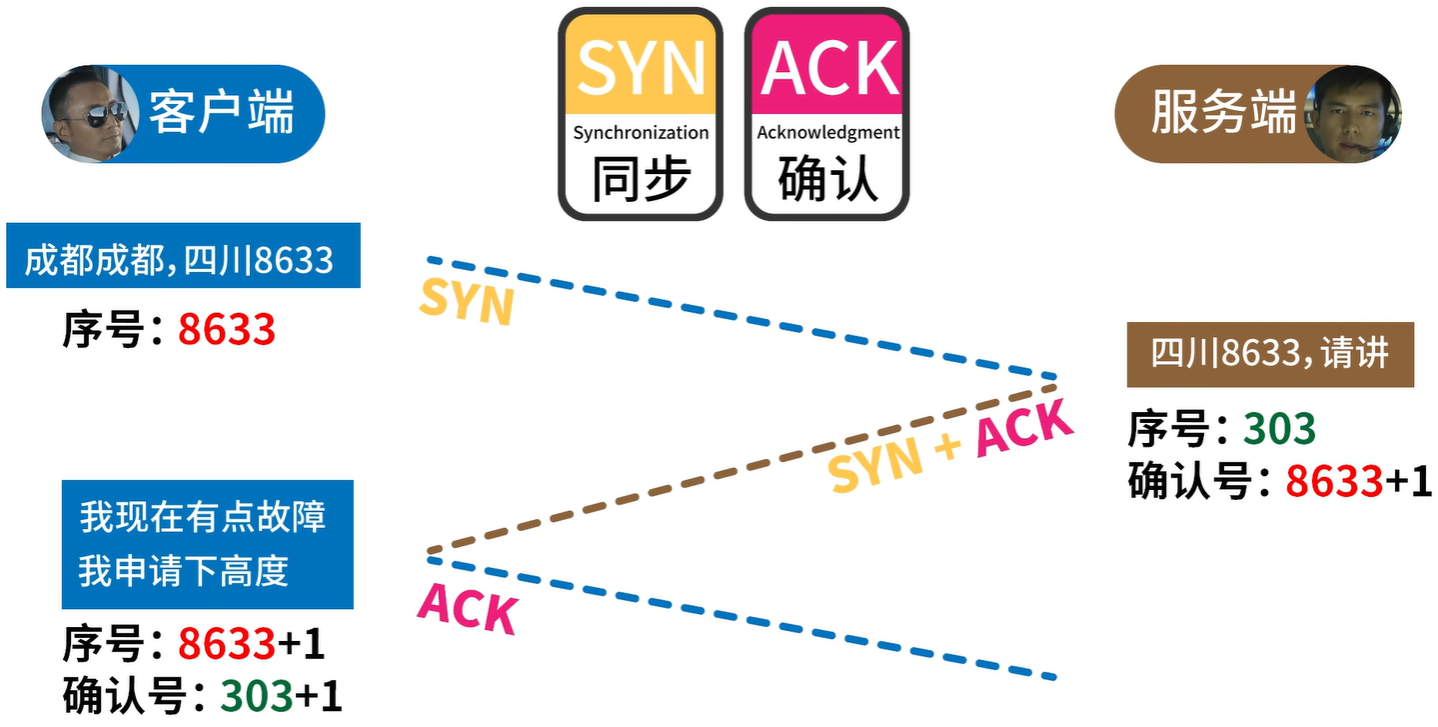
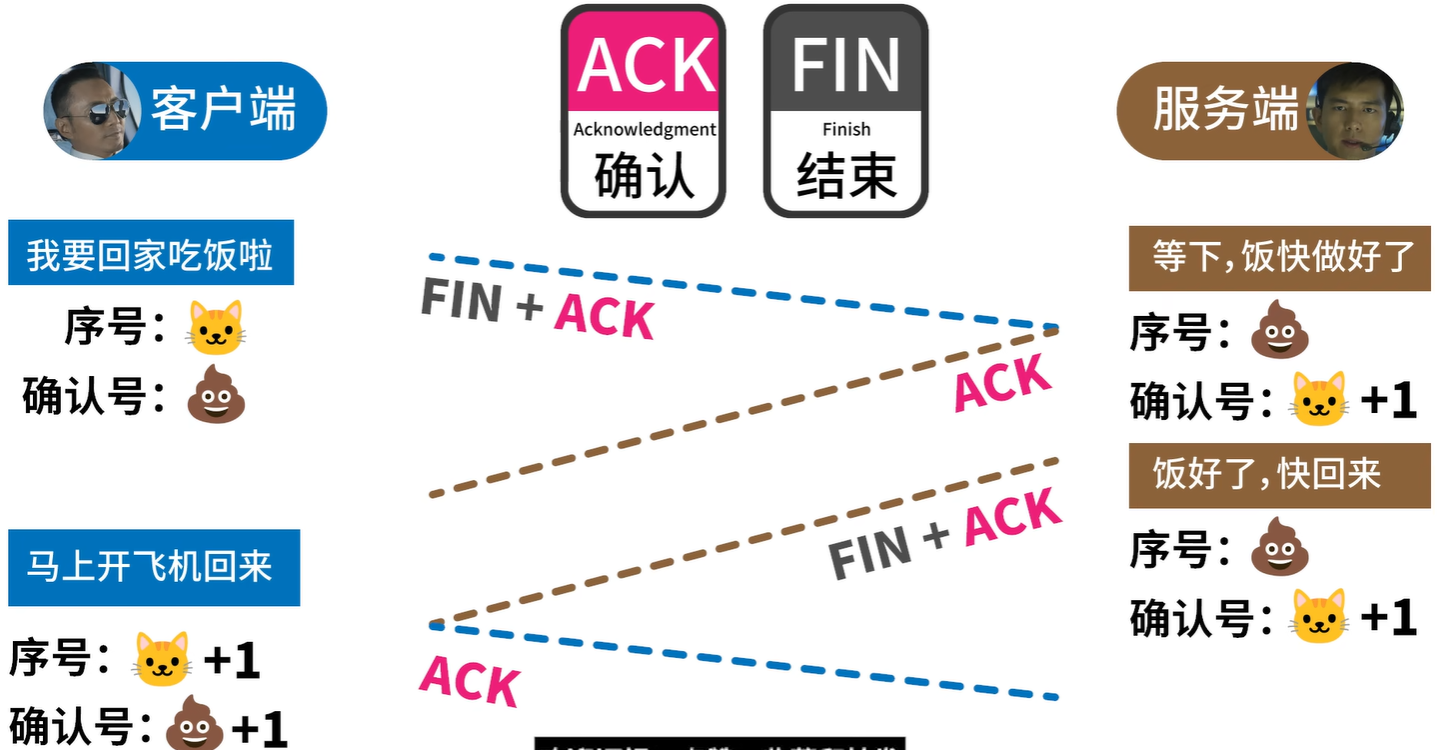
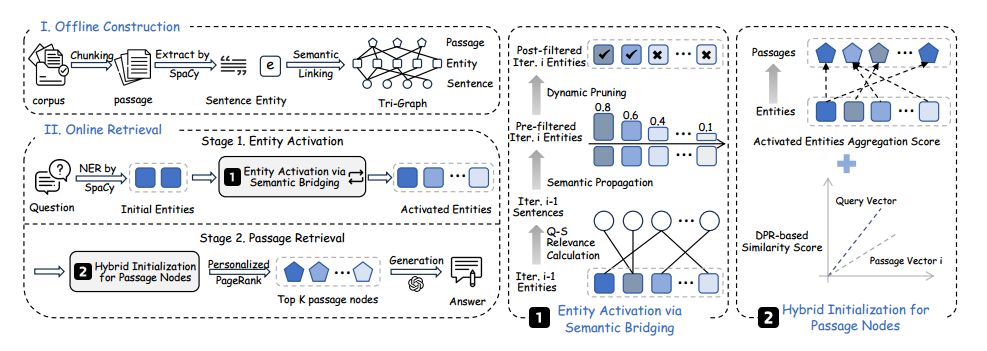
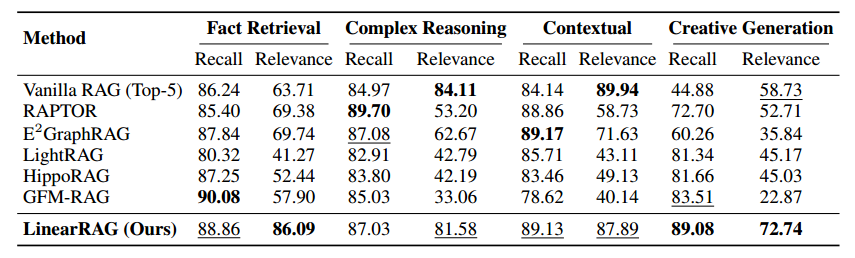
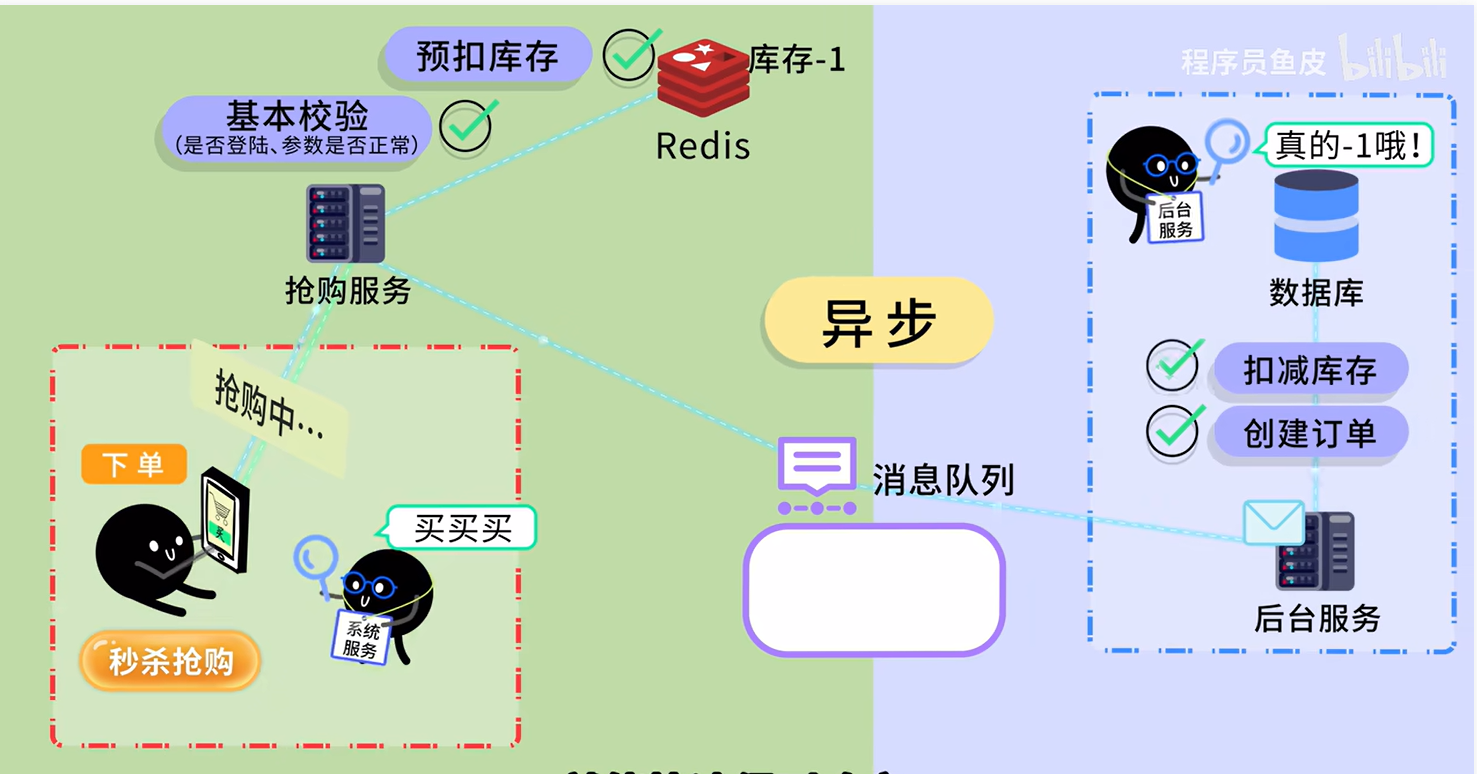
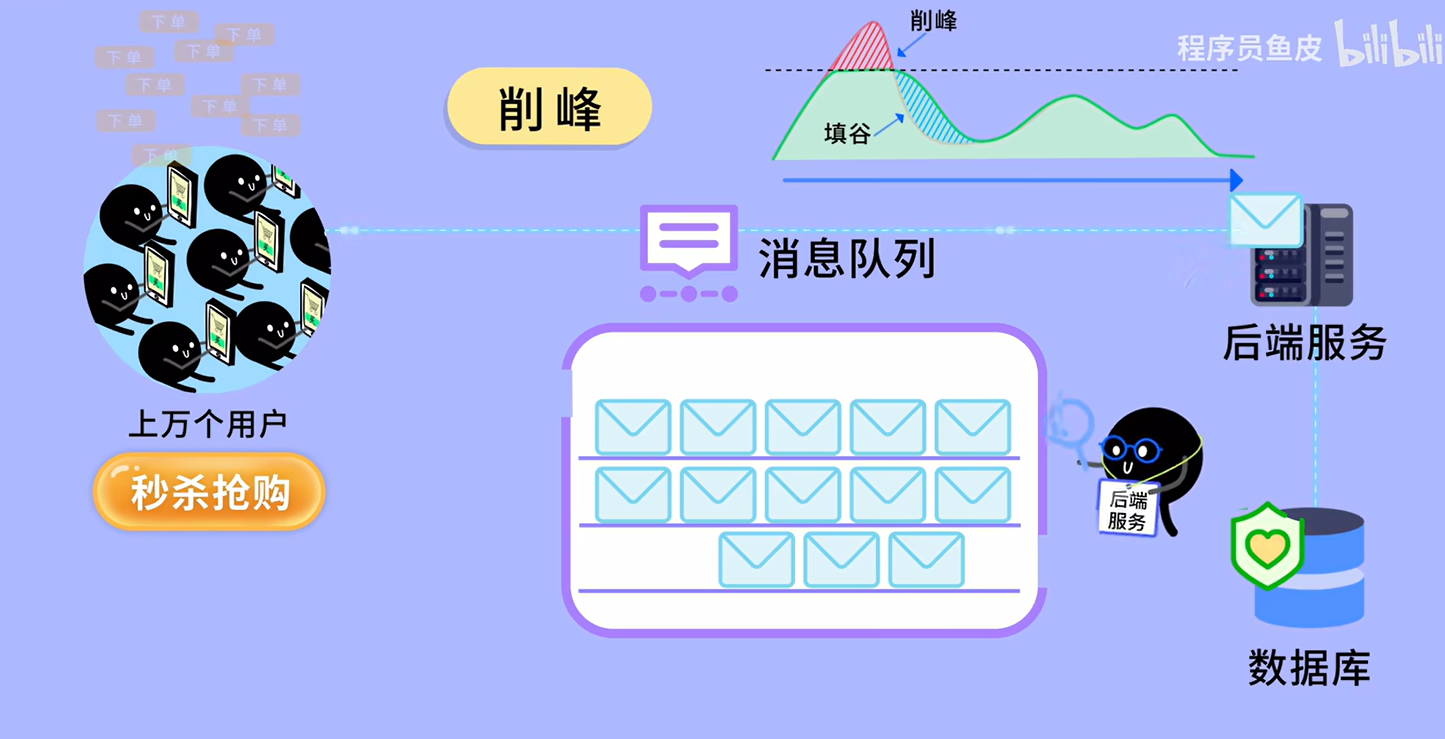
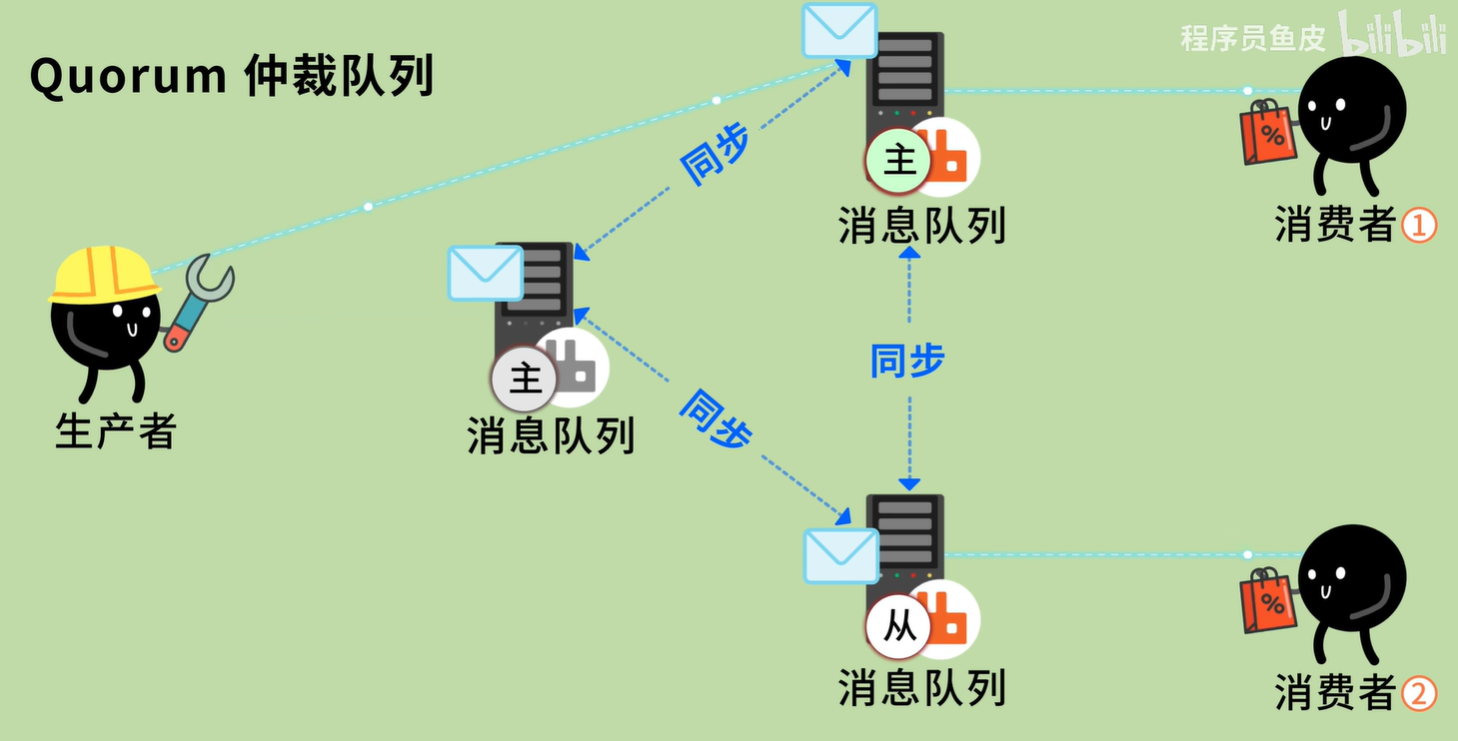
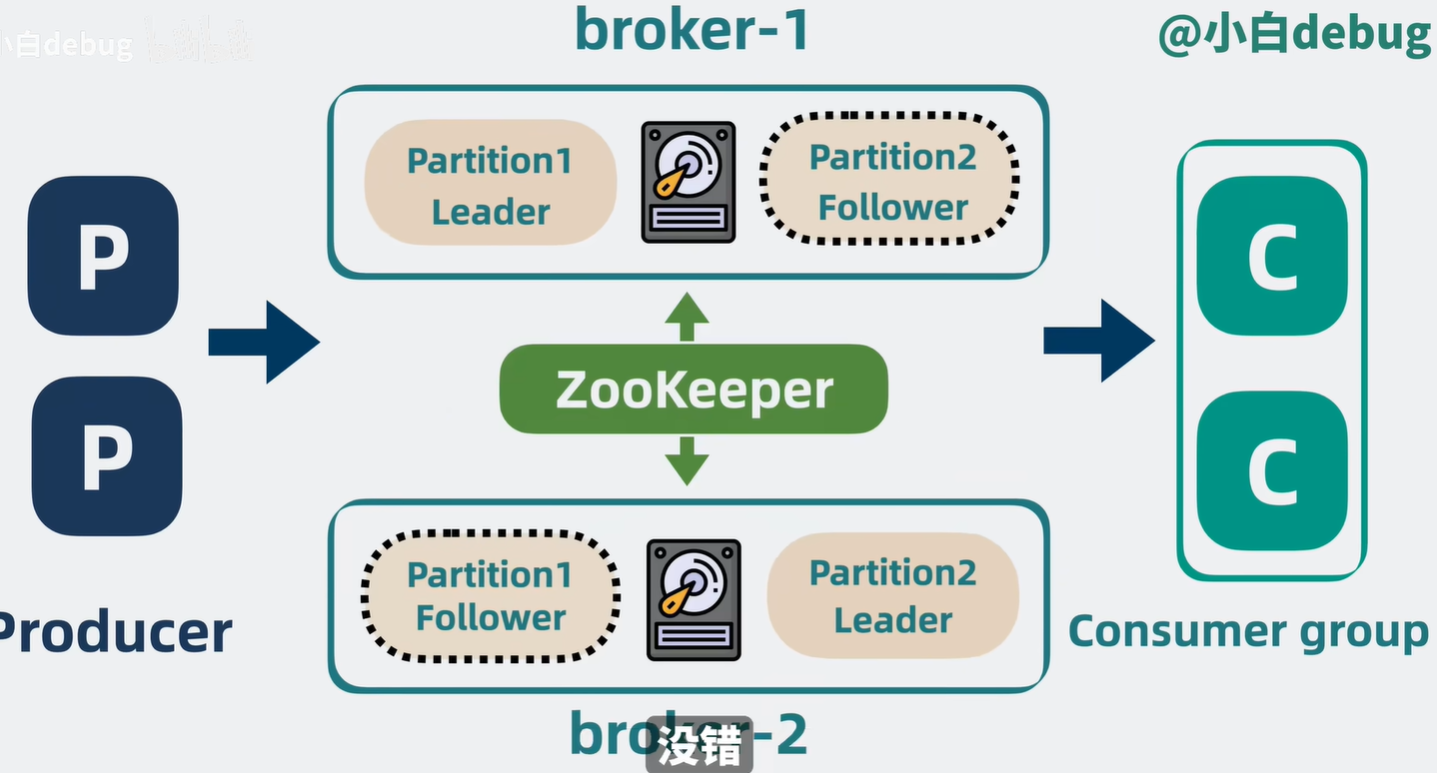
数据库系统三级模式结构
image-20260101235942961
1. 最外层:外模式 (External
Schema)
—— 用户看数据的视角(“我要看什么”)
别名 :也称为子模式 或用户模式 。定义 :它是数据库用户 (包括应用程序)能够看见和使用的局部 数据的逻辑结构和特征的描述。
通俗理解 :就像在这个系统中,财务只看“工资表”,HR
只看“人事表”。每个人只关心和自己有关的那一小部分数据,这就是外模式。 数量关系 :
一个数据库可以有多个 外模式。
一个外模式可以被多个 应用系统使用。
作用 :
定制化 :反映了不同用户对数据的不同需求和看待方式。安全性 :用户只能访问对应的外模式中的数据,以此保证数据安全。
2. 中间层:模式 (Schema)
—— 数据库的全局逻辑视角(“数据到底是什么”)
别名 :也称为逻辑模式 。定义 :它是数据库中全体 数据的逻辑结构和特征的描述。它定义了数据的名字、类型、取值范围以及数据之间的联系。
通俗理解 :这是数据库的“本体”。它不关心你是哪个部门的(不分局部),也不关心数据具体存在哪个硬盘扇区(不分物理),它只关心数据本身的逻辑完整性。 地位 :它是数据库系统模式结构的中心 。数量关系 :一个数据库只有一个 模式。特点 :
与数据的物理存储细节无关。
与具体的应用程序无关。
3. 最内层:内模式 (Internal
Schema)
—— 数据的物理存储视角(“数据怎么存”)
别名 :也称为存储模式 。定义 :它是数据物理结构 和存储方式 的描述。具体内容 :它决定了数据在硬盘上怎么躺着。例如:
记录是顺序存储还是哈希存储?
索引是怎么组织的(B+树、Bitmap)?
数据是否压缩、是否加密?
数量关系 :一个数据库只有一个 内模式。
集数据定义语言(DDL),数据操纵语言
(DML),数据控制语言(DCL)
这三个概念(DDL, DML, DCL)是 SQL(结构化查询语言)的基石。你可以把
SQL
想象成一套用于管理数据的“瑞士军刀”,而这三者就是刀上不同的工具组件,分别负责不同的任务。
我们可以用“盖房子” 和“住房子” 的类比来理解它们:
1. DDL (Data
Definition Language) —— 数据定义语言
角色:建筑师/装修队
核心功能 :用来定义数据库的骨架和结构 。它不涉及具体的数据内容,而是决定“这里要有一张表”、“这张表有几列”、“那一列是什么类型”。特点 :一旦执行,通常无法回滚(Auto-commit),结构立马改变。常用命令 :
CREATE:新建。比如建库(CREATE DATABASE)、建表(CREATE
TABLE)、建索引。ALTER:修改结构。比如给表增加一列字段,或者修改字段类型。DROP:彻底删除。把表连同结构直接炸毁。TRUNCATE:清空表。保留表结构,但把里面所有数据一次性清空(效率比逐行删除高)。
举个栗子(建房子):
DDL 就像是你在工地上喊:“这里建一面墙(Create
Table)”,“把这扇窗户改大一点(Alter)”,“把那个旧仓库拆了(Drop)”。
1 2 3 4 5 -- DDL 示例 CREATE TABLE Students ( id INT, name VARCHAR(50) );
2. DML (Data
Manipulation Language) —— 数据操纵语言
角色:住户/搬运工
核心功能 :用来对数据库里的具体数据 进行操作。这是开发人员日常写代码用得最多的部分(增删改查)。特点 :可以被事务(Transaction)控制,如果你操作错了,在提交之前通常可以回滚(Rollback/Undo)。常用命令 :
INSERT:插入。往表里放一条新数据。UPDATE:更新。修改表里已有的数据。DELETE:删除。删掉表里的某一行数据。(注:SELECT 查询语句有时被单独归为 DQL - Data Query
Language,但在广义上常被归入 DML,因为它也是在操作/处理数据)
举个栗子(搬家具):
房子建好了(DDL完成),现在 DML
进场:“往卧室搬一张床(Insert)”,“把沙发换个位置(Update)”,“把坏掉的椅子扔出去(Delete)”。
1 2 3 4 -- DML 示例 INSERT INTO Students (id, name) VALUES (1, '张三'); UPDATE Students SET name = '李四' WHERE id = 1; DELETE FROM Students WHERE id = 1;
3. DCL (Data Control
Language) —— 数据控制语言
角色:保安/物业
核心功能 :用来定义数据库的访问权限 和安全级别 。决定谁能进来,进来了能干什么。特点 :通常由数据库管理员(DBA)使用。常用命令 :
GRANT:授权。给某个用户赋予权限(比如允许他查询,但不允许他删除)。REVOKE:撤销。收回之前赋予的权限。
举个栗子(发钥匙):
DCL 就像是房东给租客配钥匙:“给你一把大门钥匙,你可以进屋(Grant
Select)”,“但不给你保险柜钥匙,你不能拿里面的钱(Revoke/Deny)”。
1 2 3 -- DCL 示例 GRANT SELECT ON Students TO user_xiaoming; -- 允许小明查询学生表 REVOKE DELETE ON Students FROM user_xiaoming; -- 禁止小明删除学生表数据
分类 全称 (英文) 全称 (中文) 包含的具体语句 (Keywords) 作用描述
DDL Data Definition Language
数据定义语言 CREATEALTERDROPTRUNCATERENAME
(重命名) COMMENT (注释)用来定义数据库对象(表、视图、索引等)的结构 。一旦执行,立即生效,无法回滚 。
DML Data Manipulation Language
数据操纵语言 SELECTINSERTUPDATEDELETEMERGE
(合并)用来对数据库表中的数据 进行增、删、改、查。可以回滚 (需要配合事务)。
DCL Data Control Language
数据控制语言 GRANTREVOKE用来定义数据库的访问权限和安全级别。
数据类型,列级约束,表级约束
一、 常见的数据类型 (Common
Data Types)
数据库的数据类型远比课件里讲的要丰富。我们按使用场景 来分类:
1. 数值类型 (Numbers)
INT /
INTEGERBIGINT
场景 :Twitter 的推文 ID、银行流水号(当 INT
不够存时,这在互联网大厂很常见)。 DECIMAL(M, D)定点数(高精度) 。这是金融核心!
区别 :FLOAT 和 DOUBLE
是浮点数,存 “0.1 + 0.2” 可能会变成 “0.300000004”。场景 :存钱 。涉及金额必须用
DECIMAL,绝对不能用 FLOAT。 FLOAT / DOUBLE
场景 :科学计算、经纬度、物理测量值(允许微小误差)。
2. 字符串类型 (Strings)
CHAR(n)定长 字符串。
原理 :不管存多少,都占 n 个字节。场景 :身份证号、手机号、哈希值(MD5)、国家代码(CN,
US)。 VARCHAR(n)变长 字符串。
原理 :存多少占多少 + 额外 1-2 字节记录长度。场景 :姓名、地址、邮箱、绝大多数文本字段。 TEXT / LONGTEXT
场景 :文章正文、商品详情描述、用户评论(超过 255 或 65535
字符时使用)。
3. 日期与时间 (Date & Time)
DATEDATETIMETIMESTAMP
特点 :会随着时区变化,通常用于记录“最后修改时间”。
4. 其他重要类型
BOOLEAN /
TINYINT(1)
场景 :是否删除(is_deleted)、是否激活(is_active)。 BLOB
场景 :虽然可以存图片/文件,但工业界通常只存文件路径(URL),不直接把文件塞进数据库。
二、 列级约束 vs 表级约束
这两个概念的区别主要在于“写的位置” 和“能管的范围” 。
1. 列级约束 (Column-level
Constraints)
“单兵作战” 。定义在列的屁股后面,只管这一列。
NOT NULL非空 。
作用 :必须要填。例子 :username VARCHAR(50) NOT NULL DEFAULT默认值 。
作用 :如果你不填,我就给你个默认的。例子 :is_active BOOLEAN DEFAULT TRUE
(注册默认激活)。 UNIQUE唯一 (单列)。
作用 :这列的值不能重复。例子 :email VARCHAR(100) UNIQUE。 PRIMARY KEY主键 (单列)。
AUTO_INCREMENTSERIAL
作用 :自增。你不用填,数据库自动 1, 2, 3… 往下排。
2. 表级约束 (Table-level
Constraints)
“团队协作” 。定义在所有列写完之后,可以管多列,也可以管跨表关系。
PRIMARY KEY (列A, 列B)联合主键 。
场景 :比如“关注列表”,你是 UserA,你关注了 UserB。UserA
可以出现多次,UserB 也可以出现多次,但 (UserA, UserB)
这个组合只能出现一次。 FOREIGN KEY外键 。
场景 :订单表里的 user_id
必须引用用户表里存在的 id。写法 :FOREIGN KEY (user_id) REFERENCES Users(id) UNIQUE (列A, 列B)联合唯一 。
场景 :在这个班级(ClassID)里,这个座位号(SeatID)只能有一个人。单独看班级或座位号都可重复,合起来必须唯一。 CHECK复杂检查 。
场景 :跨列检查。比如
CHECK (end_time > start_time)(结束时间必须晚于开始时间)。
CREATE TABLE
1 2 3 4 5 6 CREATE TABLE 表名 ( 列名1 数据类型 [列级约束], 列名2 数据类型 [列级约束], ... [表级约束] );
建立学生选课表 SC (例 3.7)
这里展示了多对多关系 的实现,以及联合主码 (表级约束)的写法。
Sno,
Cno :由两个属性构成主码,必须作为表级完整性 进行定义。Sno :外键,指向 Student 表。Cno :外键,指向 Course 表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 CREATE TABLE SC ( Sno CHAR(9), Cno CHAR(4), Grade SMALLINT, /* 主码由两个属性构成,必须作为表级完整性进行定义 */ PRIMARY KEY (Sno, Cno), /* 表级完整性约束条件,Sno是外键,被参照表是Student */ FOREIGN KEY (Sno) REFERENCES Student(Sno), /* 表级完整性约束条件,Cno是外键,被参照表是Course */ FOREIGN KEY (Cno) REFERENCES Course(Cno) );
ALTER TABLE
1. 核心语法骨架
先看一眼这张语法图,它的通用公式是:
1 2 ALTER TABLE <表名> [ 修改动作 ];
所有的操作都必须以 ALTER TABLE
开头,告诉数据库你要动哪张表。
2. 三大核心操作详解
A. 增加 (ADD) —— 给房子加个房间
你可以增加新的列 ,或者增加新的约束 (比如给某列补一个唯一约束)。
语法 :
ADD [COLUMN] <新列名> <数据类型> [完整性约束]
场景举例 : 之前建立的 Student
表忘了记“入学时间”,现在补上。
1 2 ALTER TABLE Student ADD S_entrance DATE;
课件说明 :ADD
子句既可以加新列,也可以加新的列级/表级完整性约束。
B. 修改 (ALTER COLUMN) ——
给房间换个地板
你可以修改现有列的数据类型 。
语法 :
ALTER COLUMN <列名> TYPE <数据类型>
场景举例 : 之前 Sage (年龄) 用的是
SMALLINT,现在觉得不够用(虽然不太可能),想改成更大的
INT。
1 2 ALTER TABLE Student ALTER COLUMN Sage TYPE INT;
注意 :有些数据库(如 Oracle)修改类型的关键字是
MODIFY,但你的课件是标准的 SQL 或 PostgreSQL 风格,使用的是
ALTER COLUMN ... TYPE。
C. 删除 (DROP) —— 把房间拆了
这是最需要小心的操作!你可以删除某个列 ,或者删除某个约束 。
3. 重难点:CASCADE vs
RESTRICT (级联与限制)
在删除 (DROP)
操作中,你会在课件里看到这两个关键词,这是考试必考 的概念:
假设你想删除 Student 表里的 Sno (学号)
列。
RESTRICT (限制/拒绝)
含义 :“如果有别人依赖我,那我就不准你删我。” 例子 :如果你想删 Sno,但
Sno
被这一张视图(View)或者索引引用了,数据库会直接报错,拒绝执行删除命令。这是默认的安全选项。 CASCADE (级联)
含义 :“斩草除根。” 例子 :如果你删了
Sno,数据库会自动把所有引用了 Sno
的视图、索引、触发器全部一起删掉 。警告 :这是一个很危险的操作,除非你非常清楚自己在做什么,否则慎用。
DROP TABLE
1. 核心语法
1 DROP TABLE <表名> [ RESTRICT | CASCADE ];
<表名>[ RESTRICT | CASCADE ]
2. 两种删除模式详解
A. RESTRICT
(默认/保守模式) —— “有牵挂就不走”
B. CASCADE
(级联/强制模式) —— “连根拔起”
含义 :没有限制的删除 。
规则 :
不管有没有人引用我,强制删除。
关键点 :在删除这张表的同时,相关的依赖对象 (比如引用它的外键约束、基于它的视图)都会被一起删掉 。 场景演示 : 如果你执行:
1 DROP TABLE Student CASCADE;
结果 :✅ 成功删除。
后果 :
Student 表没了,数据也没了。SC 表不会 被删掉(表还在),但是
SC 表里那个指向 Student
的外键约束 会被自动剥离/删除。从此 SC
表就变成了一张没有外键约束的普通表。
schema
1. 什么是 Schema?
在数据库教科书里,Schema 被定义为
“数据库对象的集合” 。 但在我们脑海里,它就是
“数据库内部的逻辑分组容器” 。
物理上 :数据库文件(如 .mdf,
.db)可能存在硬盘的同一个地方。逻辑上 :通过 Schema 把它们隔离开,互不干扰。
2. Schema 的三大核心作用
除了你已经知道的“防止重名”,Schema
还有两个非常重要的功能,这在企业级开发中至关重要。
A. 命名空间 (Namespace) ——
防止打架
这就是你总结的“文件夹”功能。
场景 :你们公司开发一个电商系统。
销售部 需要一个 User
表(存客户信息)。人力部 也需要一个 User
表(存员工信息)。 解决 :
Sales.User (销售部的用户表)HR.User (人力部的用户表)结果 :它们和平共处,互不冲突。
B. 权限管理 (Security) ——
安全围栏
Schema 是权限控制的天然边界 。
场景 :财务部的表非常敏感,不能让IT部的实习生看到。做法 :你不需要给财务部的 100
张表一张一张地设置权限。你只需要设置:
GRANT SELECT ON SCHEMA Finance TO Manager;
(给经理看财务文件夹的权限)REVOKE ALL ON SCHEMA Finance FROM Intern;
(禁止实习生进财务文件夹) 比喻 :Schema
就像办公楼里的“部门办公室” 。你有大楼的门禁卡(连上了数据库),但你进不去“财务部”的办公室(没有
Schema 权限)。
C. 逻辑分类 (Organization)
—— 治愈强迫症
当一个数据库里有 2000 张表时,如果全堆在一起,找表会疯掉的。
把报表相关的放 Report 模式。
把历史归档的放 Archive 模式。
把系统自带的放 System 模式。
CREATE SCHEMA
1. 核心语法:怎么建?
图片中给出的标准语法是这样的:
CREATE SCHEMA <模式名> AUTHORIZATION <用户名> ...
这里有两个关键部分:
<模式名>Sales, HR, School)。AUTHORIZATION <用户名>谁是这个文件夹的主人?
这非常重要。通常 DBA(管理员)在创建 Schema
时,会将它的所有权直接赋给具体的业务用户(比如张三)。
比喻 :你是盖楼的包工头(DBA),你盖了一个叫“财务室”的房间(Schema),然后把钥匙直接交给“财务经理”(User),而不是自己拿着。
2. 进阶玩法:“打包创建” (Combo)
注意看图片语法的第二行:
[ <表定义子句> | <视图定义子句> | <授权定义子句> ]
这意味着:你可以在创建 Schema
的同时,顺便把里面的表、视图都一起建好!
普通做法 :先建 Schema -> 结束语句 -> 切换进
Schema -> 建表 -> 建视图。高手做法 (打包) :一条语句搞定所有。
实战示例:
假设你要为“教务处”建一个模式,并直接在里面建好“学生表”,且把所有权交给用户
ZhangSan。
1 2 3 4 5 6 7 8 CREATE SCHEMA School AUTHORIZATION ZhangSan -- 顺便建个表 CREATE TABLE Student ( Sno CHAR(9) PRIMARY KEY, Sname CHAR(20) ) -- 顺便再建个视图 CREATE VIEW V_Student AS SELECT * FROM Student;
注意:在这种“打包写法”中,里面的 CREATE TABLE
语句通常不需要写分号,直到最后整个 Schema
定义结束才写分号(具体视数据库产品而定,标准SQL是这样的)。
授权定义子句
一、 核心概念:什么是 GRANT?
GRANT 的本质是
“权力的分发” 。在数据库中,除非你是数据库管理员(DBA)或对象的所有者,否则你默认没有权限访问任何不属于你的数据。
执行者 :通常是 DBA
或拥有相应对象所有权的用户。语法结构 :GRANT <权限列表> ON <对象类型> <对象名> TO <用户/角色> [WITH GRANT OPTION];
二、 权限的种类(按层级划分)
根据你提供的课件以及标准 SQL 规范,权限可以分为以下三个维度:
1. 模式级别权限 (Schema
Level) —— 进入与创建
这是管理“文件夹”(Schema)的钥匙,是访问数据的第一道关卡。
USAGE (使用权)
作用 :允许用户访问、穿过某个模式。重要性 :它是最基础的权限 。如果用户没有
USAGE 权限,即使拥有该模式下某张表的 SELECT
权限,也无法进行查询,因为他连“房间门”都进不去。 CREATE (创建权)
作用 :允许用户在非其拥有的模式中创建新对象(如建表、建视图)。
2. 对象级别权限 (Object
Level) —— 数据读写
针对具体的表(Table) 、视图(View) 或序列(Sequence) 等对象。
SELECTINSERTUPDATEDELETEREFERENCESALL PRIVILEGES
3. 授权权力 (WITH GRANT
OPTION) —— “转授权”
这是一种特殊的权力附加选项。
如果用户在获得权限时带有
WITH GRANT OPTION,他不仅自己可以使用该权限,还可以将该权限再次授予 给其他用户。
DROP SCHEMA
1 DROP SCHEMA <模式名> <CASCADE | RESTRICT>
如何在定义基本表时设定所属模式?
1. 在创建模式语句中同时创建表
这是最直接的“打包”方式。在执行 CREATE SCHEMA
语句时,可以紧接着编写 CREATE TABLE 子句。
2. 在表名中显式给出模式名
如果在已经存在的模式中创建表,可以在 CREATE TABLE
语句中通过“点号”连接的方式明确指定模式。
格式 :"模式名".表名。课件示例 (模式名为 S-T):
CREATE TABLE "S-T".Student(......);CREATE TABLE "S-T".Course(......);CREATE TABLE "S-T".SC(......);
3. 设置搜索路径(Search Path)
这是一种隐式关联的方法,通过设置数据库系统的环境参数来决定新建表的去向。
原理 :当你在 CREATE TABLE
中只写表名而没有指定模式名时,系统会根据当前的搜索路径 (Search
Path)按顺序查找,并通常将新表创建在搜索路径中的第一个模式下。
模式的搜索路径
1.
核心概念:为什么要用搜索路径?
简化书写 :虽然可以使用“全称定位”(模式名 +
对象名)来访问数据,但名称太长会导致书写繁琐。环境变量类比 :它类似于 Windows 系统中的
path 变量或 Java 中的
classpath。当你输入一个命令时,系统会按顺序在这些路径下查找对应的文件。
2. 如何查看当前的搜索路径?
你可以通过 SQL 命令查看系统当前的查找顺序:
命令 :SHOW search_path;缺省设置(默认值) :通常显示为
"$user", public。
$userpublic查找逻辑 :系统优先查找 $user
模式,如果没有找到,再查找 public。
3. 搜索路径与“创建表”的关系
当你定义一张新表且没有显式指定模式名 时,搜索路径决定了这张表的“落户地址”:
第一个原则 :系统会将新对象创建在搜索路径列表中的
第一个存在 的模式中。设置方法 :数据库管理员可以使用
SET search_path TO ... 来更改路径。
实例 :执行
SET search_path TO "S-T", public; 后再执行
Create table Student(...);,结果会建立
S-T.Student 基本表。 错误处理 :如果路径中列出的所有模式都不存在,系统将直接报错。
💡 核心总结
操作目的 SQL 命令示例 说明
查看路径 SHOW search_path;确认当前的查找顺序
修改路径 SET search_path TO schema1, schema2;改变默认的对象查找和创建位置
全称调用 SELECT * FROM "S-T".Student;绕过搜索路径,直接定位对象
隐式调用 SELECT * FROM Student;依靠搜索路径自动匹配模式
索引 (Index)
1. 核心目的:以空间换时间
加快查询速度 :这是建立索引最主要的目的。代价 :索引本身需要占用物理存储空间,且在数据更新(增、删、改)时,数据库还需要维护索引,因此会略微增加写操作的开销。备注 :虽然它增加了空间负担,但由于数据的“删、改”操作通常也需要先通过“查询”定位目标,所以索引在整体上能显著提升性能。
2. 索引的本质是什么?
逻辑指针清单 :索引存储了表中某一列或多列的值,以及这些值对应的数据库页(Data
Page)的物理地址。排序结构 :索引会对这些值进行排序 ,从而允许数据库使用更高效的算法(如二分查找)来快速定位。
3. 常见的索引类型
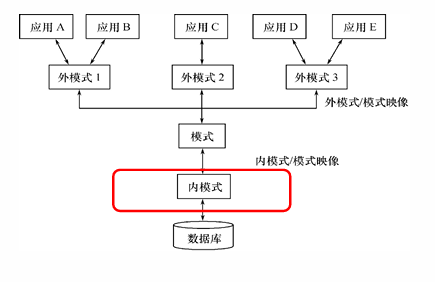
1. B+树索引 (B+Tree Index)
这是最常用、最典型的索引类型。
组织形式 :索引属性以 B+树
的形式进行组织,这种树形结构具有 动态平衡 的优点。结构层次 :
根节点与内部节点 :存储索引值,用于引导查找方向。叶子节点 :存储具体的索引值及其对应的
数据指针 。同时,叶子节点之间有指针相连,方便进行范围查找。 优势 :非常适合精确查找和范围查询(Range
Scan)。
image-20251225162135184
2. 散列/哈希索引 (Hash Index)
一种基于键值对(key-value)的极速查找方案。
存储结构 :它将索引列的值作为“键”,通过哈希算法映射到特定的存储位置。特点 :
具有 查找速度快 的显著优点。
局限性 :只适合 等值查询 (即
WHERE column = 'value')。由于哈希值是无序的,它无法处理“大于”或“小于”的范围查找。
3. 顺序文件上的索引
(Indexed Sequential File)
这是一种较为传统的物理索引方式。
核心逻辑 :建立一个独立的
索引文件 ,其中包含 [属性值, 元组指针]
的对应关系。排序方式 :索引属性可以按照
升序或降序 排列。灵活性 :可以选择非主属性(即不是主键的列)作为索引属性来建立索引。
4. 位图索引 (Bitmap Index)
适用于特定数据分布的索引方式。
适用场景 :当某列的取值范围(基数)非常有限时效果最好,例如“性别”(男/女)或“婚姻状况”。原理 :用二进制的“位”(0 或
1)来标记每一行是否包含某个特定的值。优势 :节省空间,且在处理多个条件的逻辑运算(AND/OR)时速度极快。
建立索引
在数据库中,建立索引是提高查询效率的关键操作。根据课件图片,该语句的完整格式如下:
CREATE [UNIQUE] [CLUSTER] INDEX
<索引名> ON
<表名>(<列名>[<次序>][,<列名>[<次序>]]...);
我们可以从基础语法 、核心关键字 以及排序次序 三个维度来深度拆解:
1. 基础语法组件
<索引名><表名><列名>一列或多列 (即复合索引)上,多个列名之间用逗号分隔。
2. 核心关键字解析
UNIQUE (唯一索引)
含义 :指定此索引的每一个索引值只能对应一条唯一的数据库记录。作用 :除了加速查询,它还起到约束 作用,确保该列不会出现重复数据。
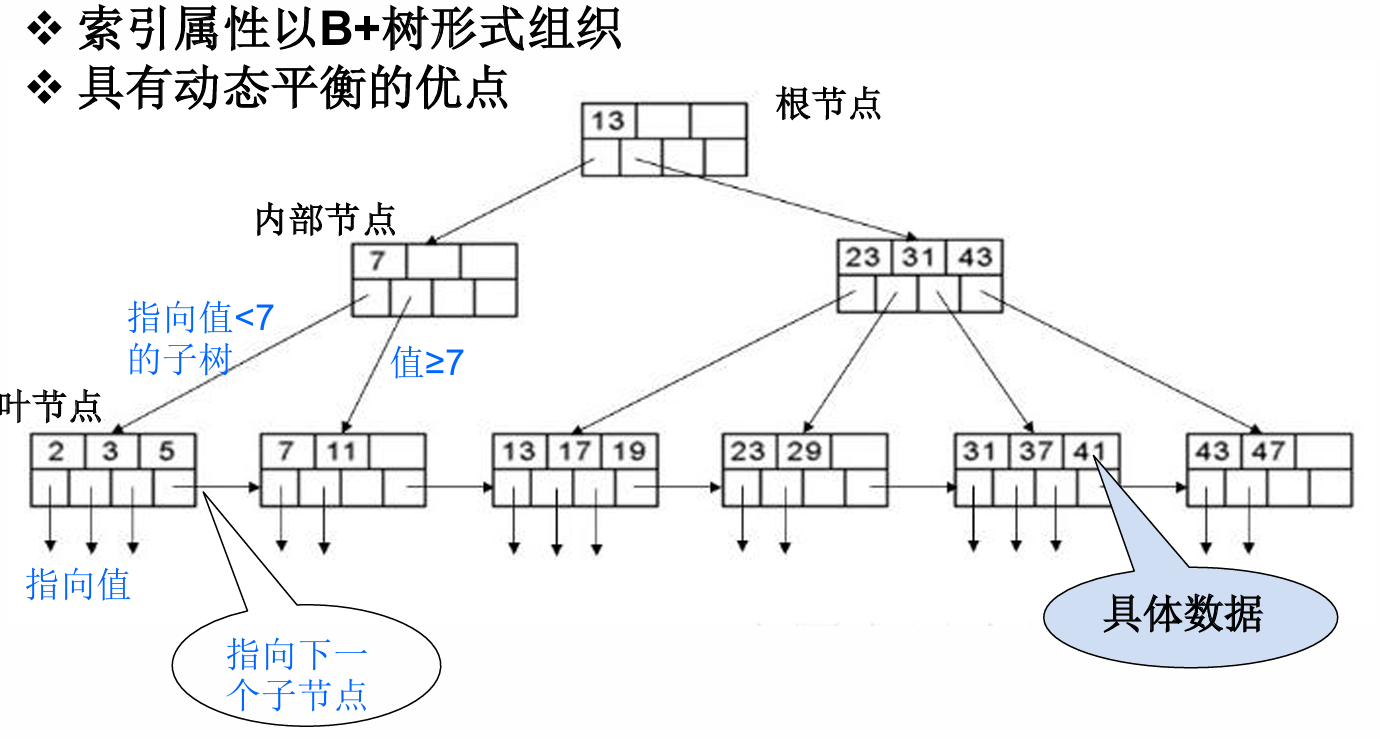
CLUSTER (聚簇索引)
含义 :表示要建立的是聚簇索引 。原理 :将具有相同或相近索引值的元组(记录)在物理上存放在连续的磁盘块中。注意 :由于数据在物理上只能有一种排列顺序,因此一张表通常只能有一个聚簇索引。
image-20251225162530664
3. 次序 (Order)
在定义索引列时,可以指定数据的排列方式:
ASCDESC
修改索引与删除索引
一、 修改索引 (ALTER INDEX)
修改索引的主要操作是重命名 。由于索引的物理结构通常比较复杂,直接“修改”索引内部逻辑并不常见,通常是通过更名来使其符合新的命名规范。
二、 删除索引 (DROP INDEX)
当某些索引不再能提高查询速度,或者因为维护索引(如在插入/删除数据时同步更新索引)带来的负担超过了它的价值时,就需要将其删除。
特殊情况:同名索引的处理 如果不同的表(如 Student 表和 Course
表)都有一个同名的索引
index1,为了避免误删,通常需要指定表名:
方式一 :ALTER TABLE Student DROP INDEX index1;方式二 :DROP INDEX index1 ON Student;
数据查询
1. 查询语句的标准格式
一个完整的 SELECT
语句由多个子句组成,它们的书写顺序 是固定的:
SELECT [ALL|DISTINCT]
<目标列>
FROM <表名/视图名>
[WHERE <条件表达式>]
[GROUP BY <列名> [HAVING
<条件表达式>]]
[ORDER BY <列名>
[ASC|DESC]];
2. 各个子句的功能拆解
我们按照执行逻辑,来看看每个部分是干什么的:
子句关键字 功能描述 通俗比喻
SELECT 指定要显示的属性列(可以选全部或部分)。
“我要看哪几列?”
FROM 指定查询的对象(基本表、视图或另一个查询结果)。
“去哪张表里找?”
WHERE 指定元组(行)的筛选条件。
“哪些行是我想要的?”
GROUP BY 将查询结果按指定列的值进行分组。
“把相同特征的人凑成一堆。”
HAVING 仅用于分组后 ,筛选满足特定条件的组。“在分好的组里再挑一遍。”
ORDER BY 对查询结果进行升序(ASC)或降序(DESC)排序。
“按高矮顺序排好队。”
3. 初学者最容易混淆的两个点
根据课件内容,有两对概念需要特别注意:
A. ALL vs
DISTINCT
ALLDISTINCT
例子 :你想查“有哪些系的学生选了课”,用
DISTINCT 就能保证每个系只出现一次。
B. WHERE vs
HAVING
WHERE分组前 过滤每一行数据。HAVINGGROUP BY 分组后
关键点 :通常 HAVING 会配合“集计函数”(如
COUNT, AVG,
SUM)使用。例如:“筛选平均分大于 80 的小组”。
为什么WHERE子句中是不能用聚集函数作为条件表达式
WHERE 子句和聚集函数(如 SUM,
AVG,
COUNT)处于不同的“时空”
根据你提供的课件逻辑,原因可以拆解为以下三点:
1. 执行顺序的矛盾(核心原因)
数据库在处理查询语句时,并不是按照我们书写的顺序执行的,而是遵循以下逻辑顺序:
FROMWHERE进行行过滤 。此时数据库是一行一行检查数据,决定哪些行该留,哪些行该丢。GROUP BY聚集函数计算
矛盾点在于 :当你写
WHERE AVG(Grade) > 60
时,数据库正在过滤每一行,它还没把数据聚在一起,根本不知道“平均分”是多少。
2. 作用对象的不同
WHERE
子句元组(行) 。它在判断“某一个学生”的成绩是否合格。聚集函数 :它的作用对象是元组集(多行) 。它在判断“一群学生”的平均分。
由于 WHERE
的本质是筛选“个体”,而聚集函数处理的是“群体”,所以两者在逻辑上不兼容。
3. 正确的解决办法:使用
HAVING
如果你想针对聚集函数的结果进行筛选(比如筛选平均分大于 60
的系),必须使用专门为分组后设计的 HAVING
短语
LIMIT 子句
LIMIT 子句限制查询结果返回的行数(元组数量) 。当你面对成千上万条数据,却只想看前几名(比如“查询成绩前三的学生”)或者需要进行分页显示时,它就是不可或缺的。
以下是根据课件内容的深度拆解:
1. 核心语法格式
LIMIT 通常放在整个查询语句的最后面,其完整格式如下:
LIMIT <行数1> [ OFFSET <行数2>
];
<行数1>OFFSET <行数2>可选参数 。表示在返回结果之前,先跳过(忽略) 前多少行。
2. 参数组合的使用语义
A. 基础用法(只限制数量)
如果你省略
OFFSET,则代表不忽略任何行,直接从第一行开始取。
例子 :LIMIT 5; —— 取结果集的前 5
行。
B. 进阶用法(跳过 + 限制)
当你同时使用两个参数时,它能实现精准截取 。
语义 :忽略前 <行数2>
行,然后取接下来的 <行数1> 行作为结果。例子 :LIMIT 10 OFFSET 20; —— 跳过前 20
条,从第 21 条开始取 10 条数据。
3. 黄金搭档:LIMIT + ORDER BY
课件特别提到:LIMIT 子句经常和
ORDER BY 子句一起使用
为什么?
因为如果不进行排序,数据库返回的行顺序可能是随机的。只有先排好序,LIMIT
才有意义。
场景 :查询全校成绩最好的前 3 名。
1 2 3 4 SELECT Sname, Grade FROM SC ORDER BY Grade DESC -- 先按成绩降序排 LIMIT 3; -- 再取前3名
连接查询
1. 核心概念:什么是连接?
根据你的课件定义:
连接查询 :同时涉及两个以上的表的查询。连接条件(连接谓词) :用来连接两个表的条件,它决定了表
A 的哪一行应该和表 B 的哪一行配对。连接字段 :连接谓词中涉及的列名。
注意 :连接字段的类型必须是可比的 (例如都是数字或都是字符),但名字不必相同。
2. 连接条件的两种表达方式
课件中给出了连接条件的通用格式:
A. 使用比较运算符
这是最常见的写法,通常用于“外键 = 主键”。
格式 :[表名1.]列名1 <比较运算符> [表名2.]列名2例 :Student.Sno = SC.Sno
(将学生表和选课表通过学号关联起来)。
B. 使用 BETWEEN … AND
用于范围类的连接。
格式 :[表名1.]列名1 BETWEEN [表名2.]列名2 AND [表名2.]列名3
3.
连接查询的执行“大餐”:等值连接与自然连接
虽然连接有很多种,但你最先需要掌握的是最基础的两种:
等值连接 (Equijoin)
特点 :连接运算符为 =。结果 :把所有满足条件的行拼在一起,如果两个表有同名的列,结果集中会保留两列 (哪怕它们的值完全一样)。
自然连接 (Natural
Join)
特点 :它是等值连接的一种特殊形式。区别 :它会自动寻找两个表中名称相同 的列进行连接,并且在结果中去掉重复的列 。
4.
实战演示:查出每个学生及其选修课程的情况
我们需要把 Student 表和 SC 表连接起来:
SQL
1 2 3 SELECT Student.*, SC.* FROM Student, SC WHERE Student.Sno = SC.Sno; -- 连接条件
执行逻辑解析:
FROM :告诉数据库我要用到 Student 和
SC 两张表。WHERE :这是关键!如果没有
Student.Sno = SC.Sno
这个条件,数据库会把每一名学生和所有 选课记录强行配对(产生笛卡尔积),结果会一团糟。结果 :你现在能看到张三选了数据库、李四选了数学,所有信息一目了然。
嵌套查询
1. 嵌套查询的结构:父与子
嵌套查询通常由两部分组成,它们的关系就像“父子”一样:
外层查询(父查询) :最外面的查询块,它接收内层查询的结果作为自己的筛选条件。内层查询(子查询) :被嵌入在括号内的查询块,它先执行并返回一个集合给外层。
2.
经典案例解析:查询选修了 2 号课程的学生姓名
这是一个非常典型的利用嵌套查询解决问题的例子:
SQL
1 2 3 4 5 6 SELECT Sname /* 外层查询:我要查的是姓名 */ FROM Student WHERE Sno IN (SELECT Sno /* 内层查询:先查出选了2号课的学生学号 */ FROM SC WHERE Cno = '2');
执行逻辑:
子查询先跑 :数据库先去 SC
表里找到所有选修了 '2' 号课的学号集合,比如
{201215121, 201215122}。父查询接力 :父查询拿着这个集合,回到
Student 表中找学号在这个集合里的学生,最后吐出他们的姓名
Sname。
3. 子查询的重要限制:不能用
ORDER BY
课件中特别强调了一个考点:子查询中不能使用
ORDER BY 子句 。
原因 :ORDER BY
是用来对最终查询结果 进行排序展示的。逻辑 :子查询只是给父查询提供一个中间数据集合(就像原材料),对中间数据进行排序是没有意义且浪费性能的。
4. 嵌套查询的灵活性
多层嵌套 :SQL
允许子查询中再嵌套子查询,形成多层结构。连接 vs
嵌套 :很多嵌套查询可以用我们之前学的“连接查询”来实现。嵌套查询的优点是符合人的逻辑思维(先找学号,再找姓名),而连接查询在某些数据库系统中的执行效率可能更高。
插入数据
1. 插入元组的基本语法
这是最常用的方式,用于手动向表中添加新记录。
语法格式:
INSERT INTO <表名>
[(<属性列1>[, <属性列2>]...)]
VALUES (<常量1>[,
<常量2>]...);
要点解析:
INTO
子句 :指定目标表名。你可以选择性地列出属性列名。
如果不指定属性列 :VALUES
中提供的数据必须包含该表所有 字段的值,且顺序必须与表定义时完全一致。
如果指定部分属性列 :没被提到的列会自动取空值(NULL) 。
VALUES 子句 :提供具体的数据内容。
匹配规则 :提供的值在个数 和数据类型 上必须与
INTO 子句中的属性列一一对应。
2. 插入子查询结果的语法
这种方式用于将一个查询的结果批量“搬运”到另一个表中。
语法格式:
INSERT INTO <表名>
[(<属性列1>[, <属性列2>]...)]
子查询;
要点解析:
无需 VALUES 关键字 :直接在 INTO
子句后写 SELECT 语句即可。批量性 :可以一次性插入多个元组,非常适合做数据备份或生成汇总报表。
修改数据
在掌握了如何插入数据后,接下来我们学习如何对数据库中已有的信息进行更新。这就是
数据修改(UPDATE) 操作。
修改数据的核心逻辑是:找到它,然后改掉它 。
一、 修改数据的基本语法
SQL 使用 UPDATE 语句来改变表中元组(行)的属性值:
UPDATE <表名>
SET <列名>=<表达式>[,
<列名>=<表达式>]...
[WHERE <条件>];
UPDATE 子句 :指定要修改哪张表。SET
子句 :指定要修改哪些列,以及赋予它们的新值。WHERE
子句(最关键) :指定哪些行需要被修改。如果省略 WHERE
子句,则表示要修改表中的所有元组 。
二、 三种常见的修改方式
根据你提供的课件,修改操作可以根据“锁定范围”分为以下三类:
1. 修改单个元组(精准打击)
通常利用“候选码(如学号)=”作为条件,锁定唯一的一行。
2. 修改多个元组(批量操作)
通过满足特定条件的 WHERE 子句,一次性修改多行。
例子 :将所有学生的年龄限制增加 1 岁。
SQL
1 UPDATE Student SET Sage=Sage+1; -- 不带WHERE,全体生效
3. 带子查询的修改(动态关联)
WHERE
子句中可以包含子查询,根据另一张表的状态来决定修改哪些行。
例子 :将计算机系(CS)所有学生的成绩置为 0。
SQL
1 2 UPDATE SC SET Grade=0 WHERE Sno IN (SELECT Sno FROM Student WHERE Sdept='CS');
三、 修改数据时的注意事项
备份意识 :在执行不带 WHERE 条件的
UPDATE
前,务必确认你真的想修改全表数据,否则后果很严重。约束检查 :修改后的值必须仍然满足表的完整性约束(例如:不能把主键改重复,不能把非空列改为
NULL)。表达式计算 :SET
子句中可以使用表达式(如
Sage = Sage + 1),数据库会先计算出新值再更新。
删除数据
1. 删除数据的基本语法
SQL 使用 DELETE
语句来删除表中的一个或多个元组(行):
DELETE FROM <表名>
[WHERE <条件>];
DELETE FROM 子句 :指定要从哪张表中删除数据。WHERE 子句(极其关键) :指定删除的条件。
如果省略 WHERE
子句 :意味着删除表中的所有元组 (但表结构本身还在,只是变成了一个空表)。
2. 三种常见的删除方式
根据你提供的课件,删除操作通常分为以下三类:
A. 删除单个元组(精准删除)
通常通过主键来锁定唯一的一行。
B. 删除多个元组(批量删除)
删除满足某一特定条件的所有行。
C. 带子查询的删除(关联删除)
根据另一张表的信息来决定删除哪些行。
3. 重要区别:DELETE vs DROP
很多初学者会把这两个命令搞混,它们的区别非常巨大:
命令 操作对象 结果
DELETE表中的数据(行)
“房子还在,家具搬走了” 。表结构依然存在,你可以继续插入数据。
DROP整个表(结构)
“房子拆了” 。表结构、索引、数据全部消失,数据库里不再有这张表。
4. ⚠ 安全警告:删除前的“潜规则”
在执行 DELETE
尤其是带条件的删除时,建议遵循以下职业规范:
先查后删 :在把 SELECT * 改成
DELETE
之前,先运行一遍查询,看看选出来的行是不是你真的想删掉的那些。检查外键约束 :如果你尝试删除 Student
表中的张三,但 SC
表里还有张三的成绩,数据库可能会因为参照完整性约束 而拒绝你的删除请求(除非设置了级联删除)。
💡 核心总结
DELETE 删除的是行 ,不是列。不带 WHERE 的 DELETE
是清空整张表的“大杀器”。
可以使用嵌套查询来实现跨表关联删除。
数据库完整性 (Data Integrity)
1. 完整性的两个核心维度
根据课件定义,完整性主要包含以下两方面:
正确性 :指数据符合现实世界语义,反映当前实际状况。
例子 :学号必须是唯一的;学生的性别只能是“男”或“女”。 相容性 :指数据库同一对象在不同关系表中的数据是符合逻辑的。
例子 :学生选的课必须是学校确实开设的课程;学生所在的院系必须是已成立的院系。
2. 完整性
vs. 安全性:易混淆点拨
虽然两者都关乎数据质量,但防范的对象截然不同:
特性 数据完整性 数据安全性
防范对象 不合语义、不正确的数据 恶意破坏和非法存取
根源 来自不当的数据库操作(如输入错误)
来自非法用户和非法操作
目标 确保数据是“对”的
确保数据是“保密且安全”的
3. DBMS 维护完整性的三套机制
为了保证数据不出乱子,数据库管理系统(DBMS)必须提供以下三项功能:
①
提供定义完整性约束条件的机制
通过 SQL 的数据定义语言(DDL) ,DBA
可以描述数据必须满足的“完整性规则”。
实体完整性 :主键不能为空且唯一。参照完整性 :外键必须引用已存在的主键值。用户定义完整性 :针对具体数据的自定义限制(如年龄必须在
0-120 之间)。
② 提供完整性检查的方法
DBMS 会在特定的时间点(一般是在执行
INSERT、UPDATE、DELETE
语句后,或事务提交时)检查数据是否违反了定义的规则。
③ 违约处理
如果发现用户的操作违反了完整性约束,DBMS 会采取一定的动作:
拒绝 (NO ACTION) :直接报错并撤销该操作。级联
(CASCADE) :为了维持完整性,自动执行其他关联操作(如删除一个班级时,自动删除该班级下的所有学生记录)。
实体完整性 (Entity Integrity)
1. 实体完整性的核心规则
在关系模型中,实体完整性通过 主键 (Primary Key)
来实现,其规则如下:
唯一性 :主键的值必须是唯一的,不能出现重复。非空性 :主键列(或构成主键的所有属性列)不能取空值(NULL)。
2. 如何定义实体完整性?
根据课件,在创建表(CREATE TABLE)时,我们可以使用
PRIMARY KEY 关键字来定义主键。
A.
单属性主键(码由一个属性构成)
有两种说明方法:
列级约束条件 :直接在属性定义后加上关键字。
SQL
1 2 3 4 CREATE TABLE Student ( Sno CHAR(9) PRIMARY KEY, /* 列级定义 */ Sname CHAR(20) NOT NULL );
表级约束条件 :在所有列定义完后单独说明。
SQL
1 2 3 4 5 CREATE TABLE Student ( Sno CHAR(9), Sname CHAR(20), PRIMARY KEY (Sno) /* 表级定义 */ );
B.
多属性主键(码由多个属性构成)
当主键由多个列共同组成时(联合主键),只能使用表级约束条件 来定义。
3. 实体完整性检查与违约处理
当你尝试执行 INSERT 或 UPDATE
操作时,数据库管理系统(DBMS)会自动按照以下逻辑进行检查:
检查主键是否为空 :如果为空,拒绝插入/修改。检查主键值是否唯一 :DBMS
会通过主键索引快速查找是否存在相同的值。如果已存在,则拒绝操作。
参照完整性 (Referential
Integrity)
1. 什么是参照完整性?
参照完整性用于定义外码(Foreign Key)与主码(Primary
Key)之间的引用规则。它确保了:在一个表中引用的数据,必须在另一个表中确实存在 。
例子 :如果选课表 SC 中记录学号为
201215121 的学生选了课,那么这个学号必须在学生表
Student 中能查到,不能凭空出现。
2. 如何定义参照完整性?
在 SQL 中,我们通过 FOREIGN KEY 和
REFERENCES 两个短语来共同实现这一约束:
FOREIGN KEY外码 。REFERENCES主码 。
语法实例:定义选课表 (SC)
在创建 SC 表时,我们需要通过参照完整性将其与
Student 表和 Course 表挂钩:
SQL
1 2 3 4 5 6 7 8 CREATE TABLE SC ( Sno CHAR(9) NOT NULL, Cno CHAR(4) NOT NULL, Grade SMALLINT, PRIMARY KEY (Sno, Cno), /* 实体完整性:定义主码 */ FOREIGN KEY (Sno) REFERENCES Student(Sno), /* 参照完整性:Sno参照Student表 */ FOREIGN KEY (Cno) REFERENCES Course(Cno) /* 参照完整性:Cno参照Course表 */ );
3. 参照完整性的检查逻辑
每当你执行涉及外码的操作时,DBMS 都会进行严格检查:
操作类型 检查逻辑
向 SC 插入数据 检查该学号是否已在 Student
表中。如果没有,拒绝插入。
修改 SC 的 Sno 检查新学号是否在 Student
表中。如果没有,拒绝修改。
删除 Student 记录 最危险操作 。如果要删除的学生在 SC
里还有选课记录,DBMS 会根据“违约处理”决定是拒绝删除还是连带删除。
4. 违约处理 (Violation
Handling)
如果操作违反了规则,DBMS 允许设置不同的动作:
拒绝 (NO ACTION) :默认操作,报错并撤销。级联
(CASCADE) :比如删除一个学生时,自动把他所有的选课记录也删掉。置空值
(SET-NULL) :比如删除一个院系时,把该系下所有学生的“所在系”字段设为
NULL。
用户定义的完整性
(User-defined Integrity)
1. 为什么需要用户定义的完整性?
虽然主键和外键能保证数据的基本逻辑,但现实业务往往有更细致的要求:
语义要求 :例如,学生的年龄不能是负数,成绩必须在 0
到 100 之间。业务逻辑 :关系数据库管理系统(RDBMS)提供了定义和检验这些规则的机制,这样就不必由应用程序来承担这些繁重的检查工作。
2. 属性上的约束条件定义
当你使用 CREATE TABLE
创建表时,可以针对单个列(属性) 设置以下三种限制:
列值非空
(NOT NULL) :强制该列必须有值,不能留白。列值唯一
(UNIQUE) :保证该列的值在全表中不重复。检查条件
(CHECK) :使用特定的逻辑表达式来限制取值范围。
例子 :Ssex CHAR(2) CHECK (Ssex IN ('男', '女'))
—— 限制性别只能填这两项。
3. 元组上的约束条件定义
有时,限制条件并不只针对某一列,而是涉及多个属性之间的相互关系 ,这时就需要在元组级(行级) 设置限制。
实现方式 :同样在 CREATE TABLE 时使用
CHECK 短语定义。核心优势 :它可以设置不同属性之间取值的相互约束条件。
例子 :在一个员工表中,你可以设置“基本工资 + 奖金 >
3000”的约束。
4. 违约处理
与参照完整性不同,用户定义完整性的违约处理通常非常简单直接:
拒绝操作 :如果 INSERT 或
UPDATE 的数据不满足
CHECK、NOT NULL 或 UNIQUE
条件,DBMS 会直接报错并拒绝执行该操作 。
完整性约束命名子句
1. 为什么要给约束起名字?
在大型数据库中,一张表可能有几十个约束。如果你发现某条规则不再适用(比如学生年龄上限从
30 岁改成了 35
岁),如果你没有给它起名,你就很难单独删掉它,只能把整张表删掉重建。
通过命名子句,你可以实现:
精准定位 :明确知道报错信息是指向哪一条具体规则。动态修改 :可以在表创建好之后,通过名字随时删除或修改特定的约束。
2. 核心语法:CONSTRAINT
在 CREATE TABLE 语句中,你可以在具体的约束条件前加上
CONSTRAINT 关键字:
CONSTRAINT <完整性约束条件名>
<完整性约束条件>
这里的 “完整性约束条件” 包括我们学过的:
NOT NULL(非空)UNIQUE(唯一)PRIMARY KEY 短语(主码)FOREIGN KEY 短语(外码)CHECK 短语(检查条件)
3. 实战案例解析
我们来看课件中的这个典型例子:建立学生登记表
Student,并为每个限制命名。
SQL
1 2 3 4 5 6 7 8 9 10 11 CREATE TABLE Student ( Sno NUMERIC(6) CONSTRAINT C1 CHECK (Sno BETWEEN 000 AND 999), /* 约束命名为 C1 */ Sname CHAR(20) CONSTRAINT C2 NOT NULL, /* 约束命名为 C2 */ Sage NUMERIC(3) CONSTRAINT C3 CHECK (Sage < 30), /* 约束命名为 C3 */ Ssex CHAR(2) CONSTRAINT C4 CHECK (Ssex IN ('男', '女')), /* 约束命名为 C4 */ CONSTRAINT StudentKey PRIMARY KEY(Sno) /* 主码约束命名为 StudentKey */ );
逻辑点拨:
学号范围 :通过 C1 确保学号在 000 到
999 之间。姓名必填 :通过 C2
确保姓名不为空。年龄限制 :通过 C3 强制要求学生必须小于
30 岁。性别限制 :通过 C4
限制性别只能在“男”和“女”中二选一。主键标识 :通过 StudentKey
唯一标识每一条学生记录。
4. 这种命名有什么后续好处?
如果你以后想取消“年龄必须小于 30
岁”这个限制,你不需要大动干戈,只需一条命令:
SQL
1 ALTER TABLE Student DROP CONSTRAINT C3;
触发器
1. 什么是触发器?
触发器是用户定义在关系表上的一类由事件驱动 的特殊过程。
自动激活 :任何用户对表进行的“增(INSERT)、删(DELETE)、改(UPDATE)”操作,都会由服务器自动激活相应的触发器。功能强大 :它可以实施比普通 CHECK
约束更复杂的检查和操作,具有更精细的数据控制能力。存储位置 :触发器保存在数据库服务器中。
2.
触发器的“三要素”:事件-条件-动作
触发器也被称为
事件-条件-动作(event-condition-action)规则 。
事件(Event) :触发的开关。包括
INSERT、DELETE 或 UPDATE。条件(Condition) :触发的门槛。由
WHEN <触发条件>
指定,只有满足该条件时,动作才会执行。动作(Action) :触发的结果。由
<触发动作体> 指定,通常是一段 SQL 程序段。
定义触发器
1. 触发器定义的语法核心
根据语法格式,一个完整的触发器定义包含以下核心要素:
CREATE TRIGGER <触发器名>
{BEFORE | AFTER}<触发事件> ON
<表名>
REFERENCING corr_name_def
FOR EACH {ROW | STATEMENT}
[WHEN <触发条件>]
<触发动作体>
关键参数拆解:
触发器名 :在同一模式下必须是唯一的。触发时机 :
BEFORE之前 激活,常用于检查或修改即将插入的数据。AFTER之后 激活,常用于跨表同步或日志记录。 触发事件 :可以是
INSERT、DELETE 或
UPDATE,也可以是它们的组合。触发频率 :
FOR EACH ROW(行级)FOR EACH STATEMENT(语句级)
2. 定义时的重要限制
在动手编写之前,有几个“红线”需要遵守:
对象限制 :触发器只能定义在基本表 上,不能定义在视图(View)上。权限要求 :只有表的拥有者 才有权在该表上创建触发器。引用变量 :可以使用 REFERENCING
来引用修改前的数据(OLD)和修改后的数据(NEW),以便在动作体中使用。
3.
实战模拟:定义一个简单的触发器
假设我们要定义一个触发器:当有新学生插入 Student
表时,如果他的年龄超过 100 岁,则自动将其改为 18
岁(防止异常数据)。
1 2 3 4 5 6 7 8 CREATE TRIGGER Check_Age_Trigger BEFORE INSERT ON Student /* 触发时机:插入前 */ FOR EACH ROW /* 触发频率:行级 */ BEGIN IF (NEW.Sage > 100) THEN /* 触发条件 */ SET NEW.Sage = 18; /* 触发动作 */ END IF; END;
关系模式(Relational Schema)
1. 关系模式的数学定义
根据课件,关系模式由五部分组成,数学上可以用一个五元组来表示:
R (U , D , D O M , F )
这五个符号分别代表了设计一张表时需要考虑的核心维度:
R 元组语义 ,即给这张表起个名字(如
Student 或 Teacher)。U 属性 (列名),比如学生表里的学号、姓名、年龄。D U 域 (即数据类型的取值范围)。D O M 映射 ,即指定每一列具体属于哪个数据类型。F U 数据依赖 。这是进行逻辑设计和数据库规范化(范式理论)的关键 。
2. 为什么 F
在定义中特别强调了:“如何进行逻辑设计的关键”在于 F 。
数据依赖 描述了属性之间内在的逻辑联系。最常见的是函数依赖(Functional
Dependency) 。例如:在学生表中,一旦知道了“学号”,就能唯一确定“姓名”。这种“学号
→ 姓名”的关系就是一种依赖。
如果 F 数据冗余、更新异常、删除异常 等一系列问题。
完全函数依赖与部分函数依赖
1. 完全函数依赖 (Full
Functional Dependency)
定义 :在关系模式 R (U )X → Y X 任何一个真子集
X ′ X ′ ↛ Y Y X
记作 :$X \xrightarrow{F}
Y$ 。直白解释 :Y X 所有 属性,缺一不可。例子 :在选课表 (学号, 课名, 成绩) 中:
(学号, 课名) → 成绩 是完全函数依赖。因为只知道“学号”不能定成绩,只知道“课名”也不能定成绩,必须两者结合。
2. 部分函数依赖
(Partial Functional Dependency)
定义 :如果 X → Y Y 不完全 函数依赖于
X Y X
条件 :这意味着存在 X X ′ X ′ → Y 记作 :$X \xrightarrow{P}
Y$ 。直白解释 :Y X X 一部分 属性就能定下来。例子 :在选课表 (学号, 课名, 学生姓名)
中:
(学号, 课名) → 学生姓名 是部分函数依赖。因为只要知道“学号”就能确定“学生姓名”了,那个“课名”在决定姓名时是多余的。
3. 为什么区分它们很重要?
部分函数依赖是导致数据库“病态”的元凶 :
数据冗余 :如果在选课表里有部分依赖,那么每选一门课,就要重复存一次学生姓名。逻辑设计目标 :逻辑设计的关键就是通过模式分解,消除非主属性对码的部分函数依赖 。
传递函数依赖
1. 严格定义与前提条件
在关系模式 R (U )Z X $X \xrightarrow{T} Z$ :
X → Y Y ⊈ X X Y Y ↛ X 关键前提 。Y X Y → Z Z ⊈ Y Y Z
⚠️ 特别注意: 如果 Y → X X ↔︎ Y Z 直接 依赖于 X
2.
实例分析:学生、系与系主任的关系
通过关系模式 Std(Sno, Sdept, Mname)(学号, 系名,
系主任姓名)来理解:
第一步 :S n o → S d e p t 第二步 :S d e p t ↛ S n o 第三步 :S d e p t → M n a m e 结论 :因为学号定了系,系又定了主任,所以
M n a m e S n o
3. 为什么我们要警惕“传递依赖”?
传递依赖是导致数据库冗余 和更新异常 的另一个元凶:
数据冗余 :同一个系的 500 个学生,在表里就要重复记录
500 次该系的系主任姓名。更新异常 :如果该系换了主任,你需要修改 500
条记录,否则数据就会不一致。设计规范 :逻辑设计的进阶目标是进入
3NF(第三范式) ,其核心要求就是:消除非主属性对码的传递函数依赖 。
码(Key)
1. 候选码 (Candidate Key)
这是最基础的“码”定义。
定义 :设 K R < U , F >U K 完全函数依赖 ($K
\xrightarrow{F} U$ ),则称 K 通俗理解 :
唯一性 :通过 K 最小性 :K 例子 :在选课表 S C (Sno, Cno)(学号和课号组合)就是一个候选码。
2. 超码 (Superkey)
定义 :如果 U K 部分函数依赖
($K \xrightarrow{P} U$ ),则 K 理解 :超码包含候选码,但可能含有多余的属性。
候选码的任意超集一定是超码。
但候选码的真子集一定不是超码,也不是候选码。
3. 主码 (Primary Key)
定义 :若一个关系模式 R 一个 作为主码。作用 :在实际数据库操作(如 SQL
编程)中,主码是系统用来区分不同记录的首要依据。
1. 外码的严格定义
根据定义 6.5,如果关系模式 R X X R 外码 :
X 不是 当前关系模式 R X 另一个 关系模式的码。
4. 属性的分类:主属性 vs
非主属性
根据属性是否包含在码中,我们可以对表中的列进行归类:
类别 定义 形象理解
主属性 (Prime attribute) 包含在任何一个 候选码中的属性。
它是“身份证号”的组成部分。
非主属性 (Nonprime attribute) 不包含在任何码中的属性。又称非码属性。
它是被身份证号决定的“姓名、地址”等。
1. 范式的种类与关系
关系数据库中的关系必须满足一定的要求。满足不同程度要求的被称为不同范式。主要分为以下六个级别:
第一范式 (1NF) :最基础的要求。第二范式 (2NF) 第三范式 (3NF) BC范式 (BCNF) 第四范式 (4NF) 第五范式 (5NF)
这些范式之间存在包含关系,就像俄罗斯套娃一样:
1N F ⊃ 2N F ⊃ 3N F ⊃ B C N F ⊃ 4N F ⊃ 5N F
这意味着:如果一个关系模式是 3NF,那它一定也是 2NF 和 1NF。
2.
什么是“规范化(Normalization)”?
规范化是一个将低一级范式的关系模式,通过模式分解 ,转换为若干个高一级范式的关系模式的集合的过程。
目的 :消除数据冗余、更新异常、插入异常和删除异常。手段 :利用我们之前学的函数依赖(如消除部分函数依赖、传递函数依赖)来拆分表格。
第一范式(1NF)
1. 1NF 的核心定义
第一范式(1NF) 规定:关系中的每一个属性(列)都必须是不可再分的原子项 。
通俗地说,就是:每一个格子(单元格)里只能放一个单一的值,不能再套一个小表,也不能放一组数据。
2. 什么样的设计违反了 1NF?
让我们看一个典型的反面教材。假设我们设计一张“学生联系方式表”:
学号 姓名 联系方式 (违反 1NF)
001
张三
电话: 138…; 邮箱: zhang@…
002
李四
电话: 139…; 邮箱: li@…
为什么它不符合 1NF?
因为“联系方式”这一列可再分 。它同时包含了电话和邮箱两个信息。
如果你想查询所有使用“138”号段的学生,数据库引擎会非常痛苦,因为它得去解析这个字符串内部的逻辑。
3. 如何将其规范化为 1NF?
我们需要把“联系方式”拆解开,确保每一列都是纯粹、单一的属性:
学号 姓名 电话 邮箱
001
张三
138…
zhang@…
002
李四
139…
li@…
此时,每一个属性都是原子性 的,满足了 1NF
的要求。
4. 1NF
存在的问题(为什么要追求更高级的范式?)
虽然 1NF
解决了“数据能不能存”的问题,但它还没有解决“存得好不好”的问题。正如你之前看过的例子:
数据冗余 :如果学号、姓名、课程、成绩都在一张 1NF
表里,姓名会重复出现很多次。异常风险 :修改一个人的姓名可能要改几十行。
第二范式(2NF)
1. 第二范式(2NF)的定义
定义 :若关系模式 R ∈ 1N F 完全函数依赖 于任何一个候选码,则
R ∈ 2N F
通俗解释 :
首先,它必须满足 1NF。
其次,表里的每一列(非主属性),都必须依赖于主键的全集 。
核心目标 :消除部分函数依赖 。
2. 为什么要
2NF?(通过“反面教材”理解)
让我们看一个经典的违反 2NF 的选课关系模式 S L C
S L C (Sno, Cno,
Grade, Sdept, Sloc)
(学号, 课程号, 成绩, 所在系, 学生住处)
结论 :因为存在非主属性(Sdept, Sloc)对码(Sno,
Cno)的部分函数依赖 ,所以它不属于
2NF 。
3. 不满足 2NF 会有什么恶果?
这种“大杂烩”表会导致四个典型问题:
数据冗余 :张三选了 10 门课,他的系名和住处就要存 10
遍。更新异常 :张三搬家了,你得去改 10
行记录,漏了一行数据就不一致。插入异常 :一个新同学刚入学,还没选课(没
Cno),因为码的一部分为空,他的系和住处信息存不进去。删除异常 :某同学只选了一门课,由于课程取消删除了记录,结果这个同学的学籍信息(系、住处)也跟着消失了。
4. 规范化:如何变成 2NF?
解决办法就是“模式分解” 。我们将表一分为二,让不同的事实待在不同的表里:
表 A (选课表) :(S n o , C n o , G r a d e )
此时码是 (S n o , C n o ) ,成绩完全依赖于码。符合
2NF 。
表 B (学生信息表) :(S n o , S d e p t , S l o c )
此时码是 S n o S n o 符合
2NF 。
第三范式(3NF)
1. 第三范式(3NF)的严格定义
定义 6.7 :设关系模式 R < U , F > ∈ 1N F R X Y Z Z ⊈ Y X → Y Y → Z Y ↛ X R ∈ 3N F
通俗解释 :
首先,它必须满足 1NF(进阶要求通常也包含满足 2NF)。
其次,非主属性之间不能有“连环套” 。即:不能让码先决定一个中间人
Y Y Z
一句话总结:任何非主属性都必须直接依赖于码,不能“间接”依赖 。
2. 实例分析:为什么 S-L 不符合
3NF?
在之前的分解中,我们得到了学生表 S-L(Sno, Sdept,
Sloc) (学号, 所在系, 住处):
路径 :S n o → S d e p t S d e p t → S l o c 判定 :这里 S d e p t S l o c S l o c S n o 结果 :S-L 虽然满足 2NF,但不满足
3NF。这会导致我们之前讨论的“换系主任/住处要改全表”等冗余问题。
3. 规范化处理:迈向 3NF
解决办法依然是模式分解 。我们要把那个“中间人” Y S d e p t
表 1:S-D(Sno, Sdept)
学号决定所在的系。
非主属性直接依赖于码,满足 3NF。
表 2:D-L(Sdept, Sloc)
系决定所在的住处。
非主属性直接依赖于码,满足 3NF。
2NF 升级到 3NF 举例1. 现状分析:为什么是 2NF
但不是 3NF?
关系模式为 F = {S n o , S a g e , S s e x , S d e p t , M n a m e }
它是 2NF :因为码是单属性 S n o 完全函数依赖 于
S n o 它不是 3NF :因为存在传递函数依赖 。
S n o → S d e p t S d e p t → M n a m e 由于系主任是通过“系”这个中间环节间接被学号确定的,即 $Sno \xrightarrow{T}
Mname$
2. 存在的问题:不规范带来的麻烦
如你之前所见,这种设计会导致:
数据冗余 :同一个系有多少学生,系主任的名字就要存多少遍。操作异常 :想存一个没有学生的新系及其主任却存不进去(插入异常);删掉某个系的最后一个学生,主任信息也没了(删除异常)。
3. 解决方案:模式分解(迈向 3NF)
为了达到
3NF,我们需要把这个“连环套”解开,将原表拆分为两个独立的关系模式:
表 1:学生表 F = {S n o , S a g e , S s e x , S d e p t }
此时,每个非主属性(年龄、性别、系别)都直接 依赖于码
S n o
不存在非主属性之间的相互依赖。符合 3NF 。
表 2:系部表 D = {S d e p t , M n a m e }
此时,码变成了 S d e p t
系主任 M n a m e 符合 3NF 。
1. BCNF 的核心定义
一个关系模式 R ∈ B C N F X → Y X X
通俗理解 :在表里的每一个函数依赖中,箭头左边的“决定因素”必须是候选码 。大白话口号 :“只有主键才有权决定别人!”
如果一个不是主键的属性组(哪怕它包含主属性)能决定别人,就不符合
BCNF。
2. 为什么需要 BCNF?(对比 3NF)
3NF 的标准相对宽松:它只要求非主属性不能部分或传递依赖于码。
但是,3NF 允许以下情况存在:
主属性 对码的部分函数依赖。主属性 对码的传递函数依赖。
这些主属性之间的“勾结”依然会引发数据冗余和操作异常。而 BCNF
排除了任何属性 (无论主属性还是非主属性)对码的部分或传递依赖。
3. BCNF 的性质
如果一个关系模式达到了 BCNF,它必然具备以下特征:
满足 3NF
的所有要求 :所有非主属性都完全且直接地依赖于每个候选码。主属性也“干净” :所有主属性都完全函数依赖于每个不包含它的候选码。决定因素必为码 :没有任何属性依赖于非码的任何属性组。
4. 判定 BCNF 的实战技巧
判定一个表是否符合 BCNF,可以遵循以下三个步骤:
找出所有候选码 。列出所有的函数依赖 X → Y 。检查左侧 :看每一个依赖的左侧 X
是 → 符合
BCNF。否 → 只是
3NF(或更低),存在冗余隐患。
多值依赖
1. 核心直觉:独立的一对多
回到你给出的 PPT 例子:Teaching(课程 C, 教师 T, 参考书
B) 。
业务规则如下:
一门课程可以由多个教师 讲授。
一门课程使用一套(多个)参考书 。
关键点 :谁来教这门课,和这门课用什么参考书,是完全无关 的。
2. 为什么会有“依赖”?
虽然教师 T B
但因为“老师”和“书”是独立的 ,数据库为了保证逻辑完整,必须穷举所有组合:
假设《数据库》有 2 名老师(张、李)和 2
本书(书A、书B),表里必须出现:
(数据库, 张 , 书A)
(数据库, 张 , 书B)
(数据库, 李 , 书A)
(数据库, 李 , 书B)
这就是多值依赖: 给定一个课程 C T T 完全不受到 参考书 B C → → T C → → B
3. 多值依赖带来的麻烦
这种依赖会导致严重的冗余 和异常 :
冗余 :如果有 10 个老师和 10 本书,你得存 100
行数据。插入异常 :如果《数据库》新聘请了一位“赵老师”,你不能只加一行。你必须为他配齐所有的参考书,插入多行记录。删除异常 :如果你想取消《数据库》的一本参考书,你必须把所有老师关联的那本书记录全部删掉。
4. 判定与解决 (第四范式 4NF)
判定:
如果一个表里存在多值依赖,且这个依赖的起始属性(左部)不是候选码,那么它就违反了
4NF。
在我们的例子中,候选码是全码 (C , T , B ) ,而
C → → T C
解决方法:拆分(一事一表)
将这种“被迫组合”的关系拆开,变成两个独立的表:
CT 表 (课程, 教师) :只记录谁教什么。CB 表 (课程, 参考书) :只记录什么课用什么书。
第四范式(4NF)
1. 什么是 4NF?(核心定义)
根据 PPT 的定义,一个关系模式 R
前提 :必须先满足第一范式(1NF)。核心规则 :对于 R 非平凡多值依赖 X → → Y X X
简单来说:如果一个表里存在“一对多”的对应关系,这个“一”必须是该表的候选码 。
2. 为什么要搞出 4NF?(BCNF
的局限性)
很多时候我们以为达到 BCNF 就完美了,但看 PPT
中的这个例子:Teaching(课程 C, 教师 T, 参考书 B) 。
它的情况 :没有函数依赖,候选码是全码 (C , T , B ) 。范式级别 :因为它没有不含码的函数依赖,所以它属于
BCNF 。问题所在 :虽然它是
BCNF,但依然存在严重的冗余。因为“教师”和“参考书”是互相独立 的,但它们都得围着“课程”转。结论 :这个表不满足 4NF,因为它存在多值依赖 C → → T C → → B C
3. 理解“非平凡多值依赖”
PPT 提到 4NF 限制的是“非平凡且非函数依赖的多值依赖”。
平凡多值依赖 :如果 Y ⊂ X X ∪ Y = U 非平凡多值依赖 :像课程决定一组老师,这组老师和表里的其他东西(书)没关系。这种“各管各的一对多”强行凑在一起,就是灾难。
4. 4NF
的实际意义:消除“独立组合”
4NF
的本质是要求:一个表里不准同时存在两类独立的“一对多”关系 。
在 Teaching(C, T, B) 中:
课程 C T
课程 C B
T B
为了满足 4NF,你必须把这个表“劈开” :
表1:(C , T ) ——
专门记录课程有哪些老师。
表2:(C , B ) ——
专门记录课程有哪些参考书。
5. 总结 4NF 的特点
包容性 :如果一个模式是 4NF,那它必为
BCNF 。针对性 :4NF
删除了非主属性对候选码以外属性的多值依赖。直观理解 :4NF
实现了真正的“一事一表” 。如果一个属性组(比如课程)能对应多个独立的值域(教师组、图书组),就必须分家。
概念模型(Conceptual Model)
1. 什么是概念模型?
概念结构设计是将需求分析得到的用户需求抽象为信息结构 (即概念模型)的过程。在这个过程中,设计师的主要任务是发现信息的内在本质联系 。
它不关心数据在计算机里是怎么存的,只关心现实世界中有哪些“人、事、物”以及它们之间是什么关系。
2. 概念模型的核心特点
根据 PPT 总结,概念模型具有以下四个显著特点:
真实性 :能够真实、充分地反映现实世界,是现实世界的真实模型。易沟通性 :易于理解,可以用它和不熟悉计算机的用户交换意见。这意味着客户不需要懂代码,看懂模型图就能确认需求是否正确。易修改性 :易于更改,当应用环境和应用要求改变时,容易对概念模型进行修改和扩充。中立性(易转换性) :它不依赖于具体的数据库管理系统,易于向关系、网状、层次等各种逻辑模型转换。
3. 描述工具:E-R 模型
PPT 明确指出,描述概念模型最常用的工具是 E-R
模型(Entity-Relationship Model,实体-联系模型) 。
在 E-R 模型中:
实体(Entity) :客观存在并可相互区别的事物(如:学生、老师、商店)。属性(Attribute) :实体所具有的特征(如:学生的姓名、商店的地址)。联系(Relationship) :实体之间的相互关联(如:教师“讲授”课程、学生“选修”课程)。
E-R模型的实体之间的联系
1. 两个实体型之间的联系
这是最常见的情况,描述两个不同类别的实体(如“学生”和“班级”)之间的对应关系。主要分为三种类型:
一对一联系 (1:1)
定义 :实体集 A 中的每一个实体,在实体集 B
中至多有一个实体与之联系;反之亦然。例子 :一个班级只有一个正班长,而一个班长只在一个班级中任职。 一对多联系 (1:n)
定义 :实体集 A 中的每一个实体,在实体集 B 中有
n n ≥ 0例子 :一个班级中有若干名学生,而每个学生只在一个班级中学习。 多对多联系 (m:n)
定义 :实体集 A 中的每一个实体,在实体集 B 中有
n m 例子 :一门课程同时有若干个学生选修,而一个学生可以同时选修多门课程。
2. 两个以上实体型之间的联系
有时候,一个联系会同时涉及三个或更多的实体。
多元联系 :描述多个实体间的相互作用。例子 :课程、教师与参考书之间的联系。
如果一门课程有若干个教师讲授,使用若干本参考书,而每一个教师只讲授一门课程,每一本参考书只供一门课程使用 ,那么这三个实体之间就是一个
1:m:n 的一对多联系。
3. 单个实体型内的联系(自联系)
同一个实体集内部的不同实体之间也可以存在联系。
定义 :这种联系描述了同一类事物内部的层级或关联。例子 :职工实体型内部的“领导”联系。
某一个职工(干部)可以领导若干名职工,而一个职工仅被另外一个职工直接领导,这在职工实体内部构成了一个
1:n 的联系。
学习小结
联系类型 符号表示 关键点
一对一 1 : 1 双向唯一对应。
一对多 1 : n 一方对应多个,另一方最多对应一个。
多对多 m : n 双向都是“一对多”关系。
逻辑结构设计
1. 逻辑结构设计的核心定位
在整个数据库设计流程中,逻辑结构设计起到了“承上启下”的作用:
承上 :它接收概念模型(E-R
图),这些图描述的是现实世界的本质联系,与计算机无关。启下 :它的输出是一组关系模式 (即表格定义),这些模式随后会被用于物理设计,并在实际的数据库软件(如
MySQL, Oracle)中建立起来。
2. 逻辑结构设计的主要任务
逻辑结构设计不仅仅是“画表格”,它包含两个关键步骤:
将 E-R 图中的实体、属性和联系按照特定的规则转化为关系模式。
实体的转换 :每一个实体型转换为一个关系模式,实体的属性变为关系的属性。联系的转换 :根据联系的类型(1:1, 1:n,
m:n)决定是合并到已有表格还是独立建表。
1:n 联系 :通常合并到 n 端关系模式中。m:n 联系 :必须转换为一个独立的、新的关系模式。
第二步:规范化与优化
(Normalization & Optimization)
这是为了确保生成的表格结构是科学且高效的:
应用范式理论 :利用你之前学习的 3NF、BCNF 或
4NF
对转换后的关系模式进行分析和分解,以消除数据冗余和操作异常。处理多值依赖 :识别并处理类似 C → → T
3. 逻辑结构设计的产出结果
完成逻辑设计后,你将得到一组完整的关系模式集合 。例如在之前“商店-商品”的例子中,逻辑设计的最终产出就是两个规范化的表结构:
R1 (商店S, 商品T, 商品经营部D) R2 (商店S, 商品经营部D, 经营部经理M)
这些模式明确了每个表的属性 、候选码 以及表与表之间的参照关系 。
关系代数(Relational Algebra)
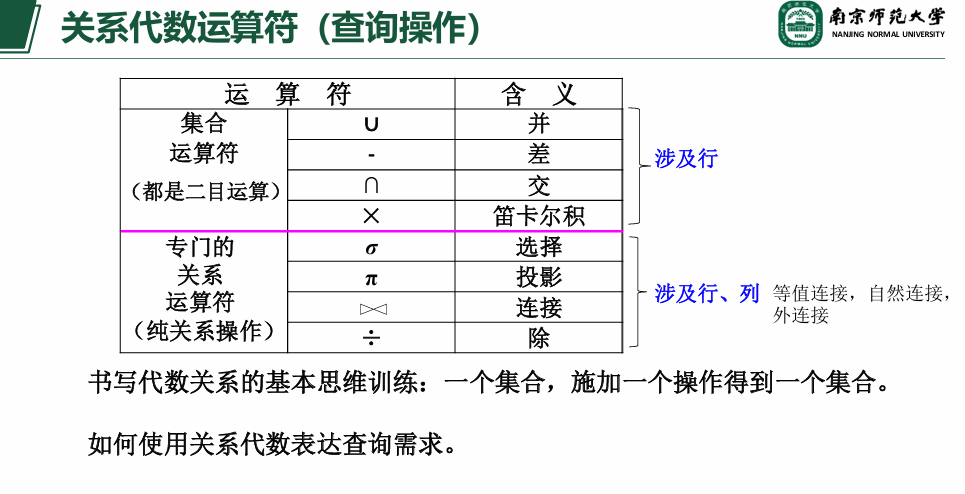
image-20260101235719915
1. 五种基本操作
这些是构成所有复杂查询的“原子”动作:
选择 (σ :从关系中挑出满足特定条件的行(元组) 。
优化直觉 :尽早执行选择(选择下推),可以极大减少中间数据量。 投影 (π :从关系中选出指定的列(属性) ,并去掉重复行。并 (∪ -
Union) :合并两个结构相同的表。差 (− -
Difference) :找出存在于表 A 但不存在于表 B 的行。笛卡尔积 (× - Cartesian
Product) :将两张表的每一行进行所有可能的组合。
注意 :它是连接(Join) 的基础,但直接计算它代价极大。
2.
为什么学习关系代数对“查询优化”至关重要?
通过你提供的案例,我们可以看到关系代数如何揭示性能差异:
场景:求选修了 2
号课程的学生姓名
SQL
表达 :SELECT Sname FROM Student, SC WHERE Student.Sno=SC.Sno AND SC.Cno='2'。低效的代数等价式 :Π S n a m e σ S t u d e n t .S n o = S C .S n o ∧ S C .C n o =′ 2′ S t u d e n t × S C ))
执行逻辑 :先做巨大的笛卡尔积(1000 × 10000 = 1000万行),再过滤。 高效的代数等价式(优化后的) :Π S n a m e S t u d e n t ⋈ σ S C .C n o =′ 2′ S C ))
执行逻辑 :先过滤出 50
条选课记录,再进行自然连接(⋈ ) 。
事务
1. 什么是事务?(Definition)
定义:事务是用户定义的一个数据库操作序列。
核心特征:“不可分割” (Indivisible)。
要么全做 (All) :序列中的所有操作都成功。要么全不做
(Nothing) :只要有一个操作失败,前面做过的所有操作都要撤销,就像没发生过一样。
误区澄清 :
事务 ≠ 程序。一个程序(比如一个
Java 后端服务)可能包含多个事务。
事务 ≠ 一条 SQL。虽然一条 SQL
可以是一个事务,但事务通常包含一组相关的 SQL 语句(比如先
UPDATE 再 INSERT)。
2. 事务的两条路:提交与回滚
一旦使用了 BEGIN TRANSACTION
开启了事务,它最终只有两个结局:
结局 A:正常结束 —— 提交
(COMMIT)
命令 :COMMIT含义 :
事务中所有的操作(读+更新)全部生效。
持久化 :数据库会将这些更新真正写入到磁盘 上的物理数据库中,即使之后系统断电,数据也不会丢。
结局 B:异常终止 —— 回滚
(ROLLBACK)
命令 :ROLLBACK含义 :
事务运行过程中发生了故障,或者用户主动取消。
撤销 :系统会将该事务中所有已完成 的操作全部撤销。复原 :数据库“滚回”到事务开始时的状态,仿佛什么都没发生过。
经典案例(转账):
事务开始 -> A 账户扣 100 元 -> (突然断电/系统报错) ->
ROLLBACK。
结果:A 账户的钱没少。如果没有事务回滚,A 的钱扣了但 B
没收到,钱就“蒸发”了。
3. 如何定义事务?(Explicit vs
Implicit)
显式定义 (Explicit) 你需要明确告诉数据库哪里是开始,哪里是结束。
SQL
1 2 3 4 5 6 7 BEGIN TRANSACTION; -- 开始 SQL 语句1; SQL 语句2; ... COMMIT; -- 成功提交 -- 或者 ROLLBACK; -- 失败回滚
隐式方式 (Implicit)
默认行为 :如果你不写
BEGIN,大多数数据库管理系统(DBMS)会按“缺省规定” 自动划分事务。一句一事务 :通常情况下,DBMS 会把你写的每一条独立的
SQL 语句当做一个独立的事务。执行完一句,自动 COMMIT
一句。
4. 为什么要引入事务?
PPT 2c5f13 的最后一句点出了事务的地位: 它是恢复
(Recovery) 和 并发控制 (Concurrency Control)
的基本单位。
恢复 :系统崩溃了,重启后依靠事务日志来回滚未完成的操作。并发 :多个用户同时操作一张表,靠事务来隔离彼此,防止数据打架。
事务的特性(ACID特性)
1. 原子性 (Atomicity)
定义 :事务是一个不可分割的工作单位。事务中的操作,要么全部做,要么全部不做 。通俗理解 :就像原子在化学反应中不可再分一样。案例 :银行转账。从 A 账户扣 100 元,往 B 账户加 100
元。这两个动作必须捆绑在一起。如果扣钱成功了但加钱失败了,数据库必须把扣掉的钱“退回去”(回滚),绝对不允许出现“钱扣了但对方没收到”的中间状态。
2. 一致性 (Consistency)
定义 :事务执行的结果必须使数据库从一个一致性状态 变到另一个一致性状态 。通俗理解 :数据必须守规矩,不能违反业务逻辑或约束。案例 :
守恒律 :转账前后,A 和 B
的账户余额总和必须保持不变。完整性约束 :如果数据库规定“余额不能为负数”,那么任何导致余额为负的事务都必须失败,不能让数据库进入“非法状态”。
3. 隔离性 (Isolation)
定义 :一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。通俗理解 :虽然大家在同时用数据库,但感觉上就像只有我一个人在用一样。案例 :
A 正在给 B 转账,还没提交。
C 去查 B 的余额。
隔离性保证 :C
查到的应该是转账前 的余额,或者是转账后 的余额,而绝对不该看到“钱正在路上”的临时混乱状态。
4. 持续性 (Durability)
定义 :一个事务一旦提交
(COMMIT),它对数据库中数据的改变就应该是永久性 的。通俗理解 :落袋为安。只要数据库告诉你“成功了”,这事就算天塌下来(断电、宕机)也赖不掉。机制 :接下来的系统故障(如断电)不应该导致已提交的数据丢失。数据库通常通过重做日志
(Redo Log) 来保证这一点。
总结
Atomicity (原子性) → 要么全做,要么不做 。Consistency (一致性) → 数据始终合法 。Isolation (隔离性) → 你干你的,我干我的 。Durability (持续性) → 说了算数,永久保存 。
事务故障的恢复步骤
1. 什么是事务故障?
定义 :事务在运行到正常终点(COMMIT)之前被强行终止。原因 :可能是程序逻辑错误、运算溢出、死锁被系统选中牺牲,或者用户主动取消等。恢复目标 :清除该事务对数据库产生的所有“半成品”影响。
2. 恢复的核心机制
自动完成 :这个过程由 DBMS
的恢复子系统自动完成,对用户是透明 的(用户完全不需要干预,甚至可能感觉不到)。利用日志 :系统通过读取日志文件 来实现撤销(UNDO)。
3. 具体恢复步骤 (4步走)
整个过程就像是在倒带 看电影:
第一步:反向扫描 (Reverse Scan)
系统从日志文件的最后面开始向前扫描 ,查找属于该故障事务的更新操作记录。
为什么要反向?
因为我们要撤销最近的操作,必须按照“后做的先撤销”的顺序进行。 第二步:执行逆操作 (Inverse Operation)
对找到的每一个更新操作,执行它的反操作 ,将数据库恢复到“更新前的值”。
如果是插入操作
(INSERT) :日志里记了插入了什么,恢复时就删除
(DELETE) 它。如果是删除操作
(DELETE) :日志里记了删除了什么(更新前的值),恢复时就重新插入
(INSERT) 回去。如果是修改操作
(UPDATE) :用日志中记录的“修改前的值” 去覆盖现在的“修改后的值”。 第三步:继续扫描
继续反向扫描日志文件,查找该事务的其他更新操作,并重复执行第二步的处理。第四步:结束
如此一直处理下去,直到读到该事务的“开始标记” (BEGIN
TRANSACTION) 。这意味着该事务的所有操作都已撤销完毕,故障恢复完成
系统故障的恢复
1.
为什么系统故障会导致数据不一致?
当系统崩溃时,可能会出现两种糟糕的情况:
坏人进门了 :有些未完成 的事务,它们修改的数据可能已经偷偷写入了磁盘(Undo
需求)。好人没进门 :有些已提交 的事务,它们的数据可能还在内存缓冲区里排队,没来得及写入磁盘就断电了(Redo
需求)。
因此,系统重启时的恢复策略是:Undo(撤销)未完成的事务,Redo(重做)已提交的事务 。
2. 恢复的具体步骤(三遍扫描法)
这个过程由系统在重启时自动完成,不需要人工干预。系统会像侦探一样扫描日志文件,分三步走:
第一步:正向扫描,划分阵营 系统从头到尾扫描日志文件,建立两个队列(名单):
重做队列 (REDO Queue) :凡是既有 BEGIN
又有 COMMIT
记录的事务,说明它在故障前已经成功了,属于“好人”,放入 Redo 队列。撤销队列 (UNDO Queue) :凡是只有 BEGIN
却找不到 COMMIT
记录的事务,说明它在故障时还没跑完,属于“坏人”,放入 Undo 队列。
示例演示:
日志记录:t1 begin, t2 begin, t1 commit … (BOOM! 故障发生)
t1 :有头有尾 →
进入 REDO 队列 。t2 :有头无尾 →
进入 UNDO 队列 。
第二步:反向扫描,撤销坏人
(Undo)
方向 :从后向前扫描日志。对象 :针对 UNDO 队列
中的事务。动作 :执行逆操作 。将日志中记录的“更新前的值”写回数据库,把它们产生的影响彻底抹除。
第三步:正向扫描,重做好人
(Redo)
方向 :从头向后扫描日志。对象 :针对 REDO 队列
中的事务。动作 :重新执行登记的操作。将日志中记录的“更新后的值”写入数据库。
为什么要重做?
因为虽然它们提交了,但数据可能还没来得及从内存写到硬盘。重做一遍确保数据万无一失。
利用检查点的恢复策略
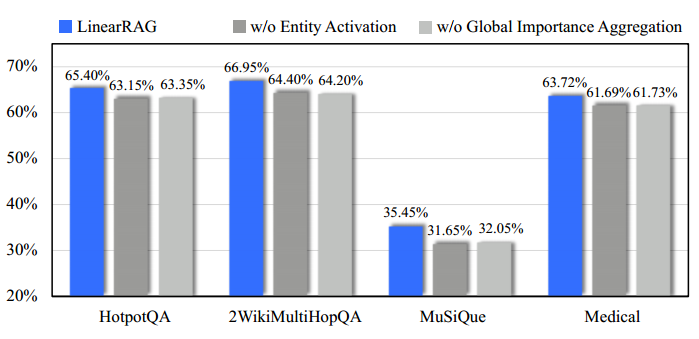
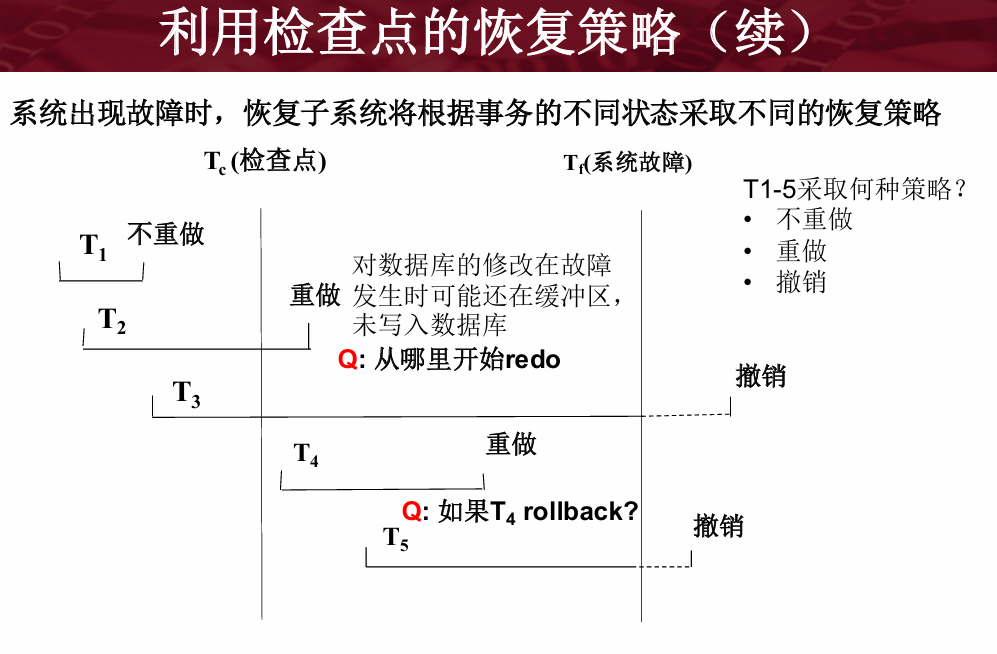
image-20260101235032775
1. 核心思想:为什么要用检查点?
问题 :如果没有检查点,系统故障后必须扫描整个日志。解决 :如果在某个时间点(T c 安全写入磁盘 了。结论 :恢复时,对于检查点之前就已经结束的事务(如
T 1
2. 场景解析:T1-T5 的命运
(关键图解)
请重点看图片
image_37aa4b.png。图中定义了两个关键时刻:
T c T f
我们根据事务在这两个时刻的状态,决定怎么处理它们:
事务 状态描述 恢复策略 原因
T 1 在 T c
不重做 (Ignore) 它的修改在打检查点前就已经写入磁盘,安全了。
T 2 跨越了 T c T f
重做 (REDO) 虽然提交了,但部分数据可能还在内存里,没来得及写盘。
T 3 跨越了 T c T f
撤销 (UNDO) 这是一个“烂尾”的事务,必须回滚。
T 4 在 T c T f
重做 (REDO) 它是“好人”,但数据可能丢失了。
T 5 在 T c
撤销 (UNDO) 纯粹的“烂尾”事务,回滚。
3. 恢复算法的具体步骤
系统重启时,会执行以下逻辑来自动分类 T 1 T 5
第一步:找到最近的检查点 系统从“重新开始文件”中找到最后一个检查点的记录地址,然后在日志文件中找到这个
CheckPoint 记录 。
第二步:初始化队列 检查点记录里会保存一个 “当时正在执行的事务清单”
(ACTIVE-LIST) 。
先把 ACTIVE-LIST 里的事务暂时放入
UNDO-LIST (撤销队列)。
REDO-LIST (重做队列)暂时为空。对应图中 :此时 T 2 , T 3 T c T 1
第三步:正向扫描 (从
T c T f 系统从检查点开始,往后扫描日志:
遇到新开始的事务 (T 4 , T 5 :把它放入
UNDO-LIST 。
现在的 UNDO 队列 :{T 2 , T 3 , T 4 , T 5 } 。 遇到提交 (COMMIT) 的事务 (T 2 , T 4 :把它从
UNDO-LIST 移到 REDO-LIST 。
移动后 :
UNDO 队列 (烂尾的):{T 3 , T 5 } 。REDO 队列 (成功的):{T 2 , T 4 } 。
第四步:执行恢复
撤销 (Undo) :对 UNDO 队列中的事务 (T 3 , T 5 逆向扫描 和撤销操作。重做 (Redo) :对 REDO 队列中的事务 (T 2 , T 4 正向扫描 和重做操作。