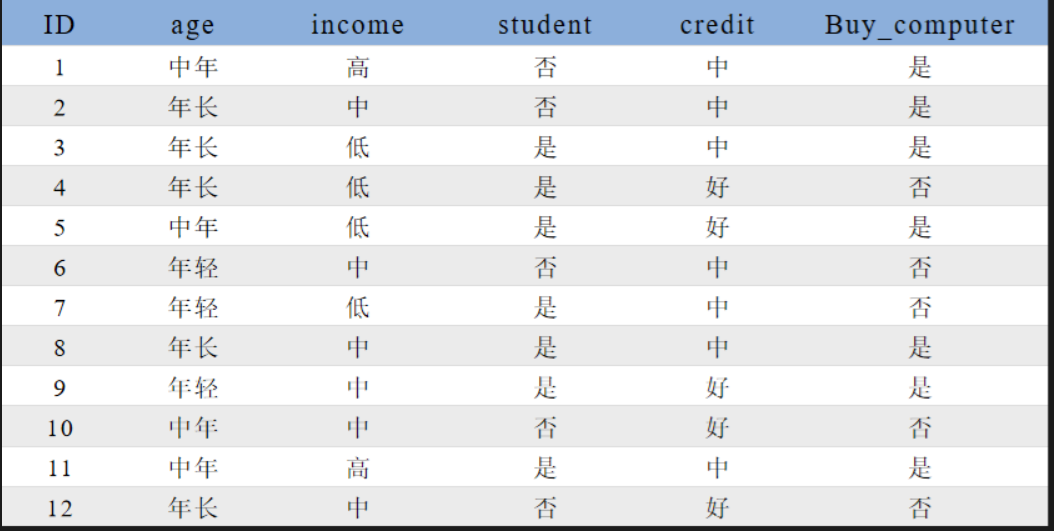
期末复习
方差与偏差
方差(Variance)和偏差(Bias)是机器学习中衡量模型性能的两个核心概念,它们共同构成了偏差-方差权衡 (Bias-Variance
Tradeoff)的基础框架。以下是两者的定义与区别:
1. 偏差(Bias)
定义 :偏差是指模型预测的期望值与真实值之间的差异。它反映了模型本身的拟合能力,即是否能够准确捕捉数据中的规律。
2. 方差(Variance)
定义 :方差是指模型在不同训练数据集下预测结果的波动程度。它衡量了模型对训练数据中噪声或微小变化的敏感性。
3. 如何降低偏差与方差
目标 方法 示例
降低偏差 增加模型复杂度(如更多特征、更深的神经网络)、减少正则化强度
使用多项式回归替代线性回归
降低方差 增加训练数据、引入正则化(L1/L2)、使用集成方法(如
Bagging、Boosting)
随机森林(Bagging)降低决策树的方差
4. 总结
偏差 关注模型是否能准确拟合数据(学习能力 ),而方差 关注模型对数据波动的稳定性(泛化能力 )。实际应用中需通过交叉验证、正则化或集成学习等技术平衡两者的关系。
监督学习与无监督学习
以下是关于监督学习与无监督学习的核心区别总结:
1. 监督学习(Supervised Learning)
任务类型 :分类(Classification) :预测离散类别标签(如垃圾邮件/非垃圾邮件)。回归(Regression) :预测连续数值标签(如房价预测)。
特点 :带标签的样本 (Labeled
Data),即每个训练样本都有明确的输入 $ x $ 和输出 $ y $。
2. 无监督学习(Unsupervised Learning)
任务类型 :
聚类(Clustering) :将样本划分为具有相似特征的群体(如客户分群)。降维(Dimensionality
Reduction) :压缩数据维度同时保留关键信息(如PCA)。
特点 :无标签的样本 (Unlabeled
Data),无需预先定义输出目标。
贝叶斯分类
贝叶斯分类器
贝叶斯决策论
本质思想:寻找合适的参数使得「当前的样本情况发生的概率」最大。
又由于假设每一个样本相互独立(概率条件理想的情况下),因此可以用连乘的形式表示上述概率,当然由于概率较小导致连乘容易出现浮点数精度损失,因此尝尝采用取对数的方式来避免「下溢」问题。也就是所谓的「对数似然估计」方法。
在已知样本特征 $ $ 的条件下,选择分类结果 $ c_i
$,使得分类的期望损失(Risk)最小。
**(1) 损失函数 $ _{ij} $**
定义 :$ _{ij} $ 是将真实类别为 $ c_j $
的样本误分类为 $ c_i $ 所产生的损失。
例如:
在医学诊断中,若 $ c_1 $ 表示“患病”,$ c_2 $ 表示“未患病”:
$ _{21} :将 实 际 患 病 (
c_1 )误 判 为 未 患 病 (
c_2 $)的损失(可能更高)。
$ _{12} :将 实 际 未 患 病 (
c_2 )误 判 为 患 病 (
c_1 $)的损失(可能较低)。
(2) 条件风险(单个样本的期望损失)
对于给定样本 $ $,若将其分类为 $ c_i ,则 其 * *条 件 风 险 * *为 : $
R(c_i | ) = {j=1}^N {ij} P(c_j | ) $$ -
含义 :在已知 $ $ 的情况下,分类为 $ c_i $ 的平均损失。
- 推导 : - $ P(c_j | ) $:样本 $ $ 真实属于 $ c_j $
的后验概率。 - $ {ij} $:若真实类别是 $ c_j $,但被分到 $ c_i
$,则产生损失 $ {ij} $。 -
因此,总期望损失是所有可能真实类别的加权和(权重为后验概率)。
(3) 总体风险
对于整个数据集,分类器 $ h() $ 的总体风险 为: R (h ) = 𝔼x R (h (x )|x )] = ∫R (h (x )|x )p (x )d x 含义 :所有样本的平均条件风险。h为分类器(模型) -
目标 :找到使 $ R(h) $ 最小的分类器 $ h() $。
贝叶斯决策规则 根据上述定义,贝叶斯决策论的分类规则是: > 对于样本 $
$,选择使其条件风险 $ R(c_i | ) $ 最小的类别 $ c_i $
作为预测结果。
即: $$
h^*(\mathbf{x}) = \arg\min_{c_i} R(c_i | \mathbf{x}) = \arg\min_{c_i}
\sum_{j=1}^N \lambda_{ij} P(c_j | \mathbf{x})
$$
特殊情况:0-1
损失函数
当所有误分类的损失相同(即 $
{ij} = 1 $ 对于 $ i j , {ii} = 0
) * *0 − 1损 失 函 数 * *: $
_{ij} =
此 时 条 件 风 险 简 化 为 :{j i} P(c_j | ) = 1 - P(c_i | ) $$ 原因:概率之和为 1:$
{j=1}^N P(c_j | ) = 1 $,因此 $ _{j i} P(c_j | ) = 1 - P(c_i | )
$。
此时,最小化风险等价于最大化后验概率 ,即: h * (x ) = arg maxc i P (c i x )
即在x样本的情况下,分类正确的概率最大
后验概率与先验概率
后验概率
后验概率(Posterior
Probability)是贝叶斯理论中的核心概念,指的是在观察到新证据(数据)后,对事件发生概率的修正
。 其本质是:
“已知结果(数据),反推原因(类别或参数)的概率”
。
已知结果(数据)B,反推最可能的原因A(后验概率
P (A ∣B ) )
先验概率(Prior
Probability) 先验概率是贝叶斯统计中的核心概念,指的是在观察到新数据之前 ,对某一事件或假设的概率估计。它是基于已有知识、经验或假设 得出的初始概率,后续会通过新数据更新为更准确的后验概率 。
1. 核心定义
数学表达 :P (A )
$ P(A) $:事件 $ A $ 的先验概率。
例如:$ A $ 表示“某人患有某种疾病”,则 $ P(A) $
是该疾病的已知发病率(在未进行检测前的概率)。
与后验概率的区别 :
先验概率 :$ P(A) $,在无新数据时的概率。后验概率 :$ P(A|B) $,在观察到数据 $ B $
后更新的概率(通过贝叶斯定理计算)。
2. 直观理解
(1) 类比:医学诊断
先验概率 :某种疾病的已知发病率(如 1%)。新数据 :患者接受检测,结果为阳性。后验概率 :结合发病率和检测结果,计算实际患病的概率(如
8.7%,参考贝叶斯定理的经典医学测试案例)。
生成式模型和判别式模型
核心区别
模型类型 建模目标 数学表达
判别式模型 直接建模 $ P(c
) $
生成式模型 先建模联合概率 $ P(, c) $,再推导 $ P(c
) $
详细解释 1. 判别式模型(Discriminative Model)
目标 :直接学习从输入 $ $ 到标签 $ c $
的映射关系。数学本质 :建模条件概率 $ P(c|) $,即“已知特征 $
$,预测类别 $ c $”。特点 :
不关心数据本身的分布,只关注分类边界。
例如:逻辑回归、支持向量机(SVM)、神经网络等。
2. 生成式模型(Generative Model)
示例:二分类问题 假设我们要判断一封邮件是否为垃圾邮件($ c=spam $ 或 $ ham $)。
判别式模型(逻辑回归)
直接建模: $$
P(spam|\mathbf{x}) = \frac{1}{1 + e^{-(w^T \mathbf{x} + b)}}
$$ 若 $ P(spam|) > 0.5 $,则判定为垃圾邮件。
生成式模型(朴素贝叶斯)
建模联合概率: P (x , s p a m ) = P (s p a m )∏i P (w o r d i s p a m )P (x , h a m ) = P (h a m )∏i P (w o r d i h a m )
计算后验概率: $$
P(spam|\mathbf{x}) = \frac{P(\mathbf{x}|spam)P(spam)}{P(\mathbf{x})}
$$ $$
P(ham|\mathbf{x}) = \frac{P(\mathbf{x}|ham)P(ham)}{P(\mathbf{x})}
$$
选择概率更大的类别。
生成式模型的建模思路
根据概率论的基本定义: $$
P(c|\mathbf{x}) = \frac{P(\mathbf{x}, c)}{P(\mathbf{x})}
$$ - 含义 : - $ P(, c) $:联合概率,表示特征 $ $
和类别 $ c $ 同时发生的概率。 - $ P() $:边缘概率(证据),表示特征 $ $
出现的概率,用于归一化。
根据贝叶斯定理,联合概率 $ P(, c) $ 可以分解为: P (x , c ) = P (c ) ⋅ P (x |c )
将上述分解代入条件概率公式,得到: $$
P(c|\mathbf{x}) = \frac{P(c) \cdot P(\mathbf{x}|c)}{P(\mathbf{x})}
$$ 产生问题:
在贝叶斯分类中,需要计算联合概率
P (x ∣c ) ,即在类别 c
下,特征向量 x =(x 1,x 2,…,*x**d)
的条件概率。 若直接建模联合概率,需估计 d*
个特征的所有可能组合的概率。例如:
若每个特征有 k 个取值,类别数为 K ,则需要估计
K ⋅*k**d* 个参数。
当特征维度 d
很大时(如文本分类中成千上万的词汇),参数数量呈指数级增长,导致计算不可行(维度灾难
)。
举例:
低维空间 :假设只有 2
个特征(如“免费”和“中奖”),每个特征取值为 0 或 1,则特征空间共有 22=4
个可能的组合(即四个格子)。
如果有 100 封邮件,每个格子平均有 25 封邮件(数据较密集)。
高维空间 : 当特征维度增加到 d =10,000
时,特征空间的组合数是 210,000 ,远大于宇宙中原子的数量(约 1080 )。
即使有 100 万封邮件,每个组合几乎都是空的(数据极度稀疏)。
结果 :
在高维空间中,训练数据无法覆盖所有可能的特征组合,导致模型无法可靠估计联合概率
P (x∣c) 。
因此产生属性条件独立性假设
朴素贝叶斯分类器
朴素贝叶斯分类器的核心思想是通过贝叶斯定理 和属性条件独立性假设 来简化计算,从而高效地进行分类。
属性条件独立性假设
朴素贝叶斯的核心假设是:在已知类别 $ c $
的条件下,所有属性(特征)之间相互独立 。$$
P(\mathbf{x}|c) = \prod_{i=1}^d P(x_i|c)
$$ 其中 $ d $ 是特征的数量,$ x_i $ 是第 $ i $ 个特征的取值。
将此代入贝叶斯公式: $$
P(c|\mathbf{x}) = \frac{P(c) \cdot \prod_{i=1}^d
P(x_i|c)}{P(\mathbf{x})}
$$
为何可以忽略 $ P() $? 在分类任务中,我们的目标是比较不同类别 $ c $ 的后验概率 $ P(c|)
$,并选择最大值。由于 $ P() $
对所有类别来说是相同的常量(与类别无关),因此在最大化过程中可以忽略:
$$
\arg\max_{c} P(c|\mathbf{x}) = \arg\max_{c} \left[ \frac{P(c) \cdot
\prod_{i=1}^d P(x_i|c)}{P(\mathbf{x})} \right] = \arg\max_{c} \left[
P(c) \cdot \prod_{i=1}^d P(x_i|c) \right]
$$ 这就是公式中 $ P() $ 被省略的原因。
在比较的过程中,分母相同,可以忽略
朴素贝叶斯的最终决策规则 简化后的决策规则为: $$
h_{nb}(\mathbf{x}) = \arg\max_{c} \left[ P(c) \cdot \prod_{i=1}^d
P(x_i|c) \right]
$$ 即: - 计算每个类别的先验概率 $ P(c) $。 -
计算每个特征在该类别下的条件概率 $ P(x_i|c) $。 -
将这些概率相乘,选择乘积最大的类别作为预测结果。
类先验概率 $ P(c) $
的估计方法 基于大数定律 $$
P(c) = \frac{|D_c|}{|D|}
$$ - 符号含义 : - $ D $:训练集,包含所有样本。
- $ D_c $:训练集中类别为 $ c $ 的样本子集。 - $ |D_c| $:类别 $ c $
的样本数量。 - $ |D| $:训练集总样本数量。
直观解释 :
类先验概率等于该类别样本数占总样本数的比例。
条件概率 $ P(x_i | c) $
的估计方法 在生成式模型(如朴素贝叶斯分类器)中,条件概率 $ P(x_i | c)
$ 表示在类别 $ c $ 下,第 $ i $ 个属性取值为 $ x_i $
的概率。根据属性类型(离散或连续),其估计方法不同:
1. 离散属性的条件概率估计
公式 : $$
P(x_i | c) = \frac{|D_{c,x_i}|}{|D_c|}
$$ - 符号含义 : - $ D_c $:训练集中类别为 $ c $
的样本集合。 - $ D_{c,x_i} : D_c $
中第 $ i $ 个属性取值为 $ x_i $ 的样本子集。 - $ |D_{c,x_i}| : D_{c,x_i} $ 的样本数量。 - $ |D_c| $:类别
$ c $ 的总样本数量。
直观解释 :
在类别 $ c $ 的样本中,统计第 $ i $ 个属性取值为 $ x_i $
的频率,作为 $ P(x_i | c) $ 的估计。
示例 :(垃 圾 邮 件 )有 200封 ,其 中 150封 包 含 “ 免 费 ” 一 词 ,则 : $
P( | spam) = = 0.75 $$
注意事项 :
零概率问题 :若某属性值在类别 $ c $ 中未出现,则 $
P(x_i | c) = 0 ,可 能 导 致 后 续 计 算 失 效 。 * *解 决 方 案 * *:使 用 * *拉 普 拉 斯 平 滑 (L a p l a c e S m o o t h i n g ) * *,将 公 式 改 为 : $
P(x_i | c) = $$ 其中 $ K $ 是该属性的取值总数。
2. 连续属性的条件概率估计
假设 :属性服从正态分布(高斯分布) $$
p(x_i | c) = \frac{1}{\sqrt{2\pi}\sigma_{c,i}} \exp\left( -\frac{(x_i -
\mu_{c,i})^2}{2\sigma_{c,i}^2} \right)
$$ - 符号含义 : - $ {c,i} $:类别 $ c $ 在第
$ i $ 个属性上的均值。 - $ {c,i}^2 $:类别 $ c $ 在第 $ i $
个属性上的方差。
直观解释 :
假设在类别 $ c $ 下,属性 $ x_i $ 服从均值为 $ {c,i} $、方差为 $
{c,i}^2 $ 的正态分布。
示例 :{spam, } = 500 $,方差 $
{spam, }^2 = 100 ,则 : $
p(600 | spam) = ( - ) $$
注意事项 :
分布假设 :若实际数据不符合正态分布,需调整假设(如使用核密度估计、对数变换等)。参数估计 :均值和方差通过训练数据计算: $$
\mu_{c,i} = \frac{1}{|D_c|} \sum_{x \in D_c} x_i, \quad \sigma_{c,i}^2 =
\frac{1}{|D_c|} \sum_{x \in D_c} (x_i - \mu_{c,i})^2
$$
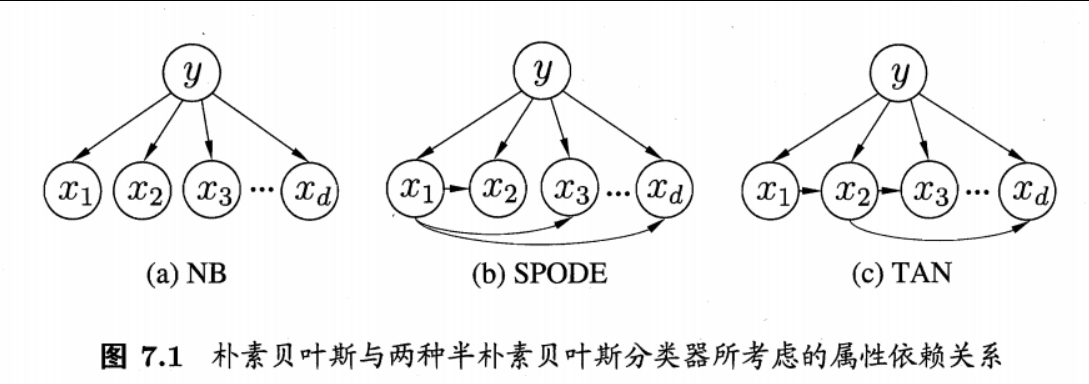
半朴素贝叶斯分类器
半朴素贝叶斯分类器是对传统朴素贝叶斯 的改进,它在保留计算效率的同时,适当引入部分属性间的依赖关系 ,从而在分类性能和计算复杂度之间取得平衡。
独依赖估计(ODE)方法 (1) 定义
独依赖估计(One-Dependent Estimator,
ODE)是半朴素贝叶斯的一种实现方式,其核心假设是: > 每个属性
$ x_i $ 在类别 $ c $ 之外最多依赖于一个其他属性(称为父属性 $ pa_i
$) 。
数学表达式为: $$
P(c|\mathbf{x}) \propto P(c) \prod_{i=1}^d P(x_i | c, pa_i)
$$ 其中: - $ pa_i $:属性 $ x_i $ 的父属性(依赖的单一属性)。 -
$ P(x_i | c, pa_i) $:在类别 $ c $ 和父属性 $ pa_i $ 下,属性 $ x_i $
的条件概率。
(2) 直观理解
每个属性 $ x_i $ 的分布不仅受类别 $ c $ 影响,还受其父属性 $ pa_i $
的影响。
例如,在文本分类中,若属性 $ x_1 $ 是“免费”,$ x_2 $
是“中奖”,可设定 $ pa_2 = x_1
$,表示“中奖”在类别和“免费”的共同作用下出现。
超父独依赖估计(SPODE) 超父独依赖估计(Super Parent One-Dependent Estimator,
SPODE)是半朴素贝叶斯分类器 的一种扩展,其核心思想是:
> 所有属性都依赖于同一个“超父”属性 $ x_i
$ ,从而在保留部分依赖关系的同时避免完全联合概率的计算。
(1) 贝叶斯定理展开 $$
P(c|\mathbf{x}) = \frac{P(\mathbf{x}, c)}{P(\mathbf{x})}
$$ 其中: - $ P(, c) $:联合概率,表示特征 $ $ 和类别 $ c $
同时发生的概率。 - $ P() $:证据(归一化因子)。
(2) 引入“超父”属性 $ x_i $
假设所有属性 $ x_j (j i) $ 在类别 $ c $ 下仅依赖于 $ x_i ,则 : $ P(, c) = P(c, x_i) P(x_1, ,
x_{i-1}, x_{i+1}, , x_d | c, x_i) 进 一 步 分 解 为 :
(3) 最终形式
由于 $ P() $ 对所有类别相同,可忽略,最终决策规则为: $$
P(c|\mathbf{x}) \propto P(c, x_i) \cdot \prod_{j=1}^d P(x_j | c, x_i)
$$ 其中: - $ P(c, x_i) $:类别 $ c $ 和属性 $ x_i $ 的联合概率。
- $ P(x_j | c, x_i) $:在类别 $ c $ 和 $ x_i $ 的条件下,属性 $ x_j $
的概率。
树增强朴素贝叶斯(TAN:
Tree-Augmented Naive Bayes) TAN (Tree-Augmented Naive
Bayes)是半朴素贝叶斯分类器 的一种扩展,旨在通过引入属性间的树状依赖关系 ,在保留计算效率的同时,显著提升分类性能。它结合了贝叶斯网络 的建模能力和生成式模型 的概率推理优势。
1. 核心思想
TAN 的核心假设是: > 所有属性(特征)在类别 $ c $
的基础上,形成一个以属性为节点的树状依赖结构 ,即每个属性最多依赖一个其他属性(父属性),且整个依赖图是一棵无环的树。
数学表达 : $$
P(c|\mathbf{x}) \propto P(c) \cdot \prod_{i=1}^d P(x_i | c, pa_i)
$$ 其中: - $ pa_i $:属性 $ x_i $ 的父属性(依赖的单一属性)。 -
$ P(x_i | c, pa_i) $:在类别 $ c $ 和父属性 $ pa_i $ 的条件下,属性 $
x_i $ 的条件概率。
2. TAN 的构建步骤
TAN 通过以下步骤构建属性间的依赖结构:
(1) 计算互信息(Mutual Information)
互信息衡量两个属性之间的相关性: $$
I(x_i, x_j) = \sum_{x_i, x_j} P(x_i, x_j) \log \frac{P(x_i,
x_j)}{P(x_i)P(x_j)}
$$ -
含义 :互信息越大,两个属性之间的依赖关系越强。
(2) 构建带权图
将所有属性视为图中的节点。
每对属性间的边权重设为互信息 $ I(x_i, x_j) $。
(3) 最大带权生成树(Maximum Weight Spanning Tree,
MWST)
使用克鲁斯卡尔(Kruskal)算法或普里姆(Prim)算法,选择一棵连接所有属性节点的树,使得:
- 树的边权重(互信息)总和最大。 - 树中无环。
(4) 确定依赖方向
随机选择一个根节点(或根据领域知识指定)。
从根节点出发,确定每条边的方向(父属性 → 子属性)。
image-20250605223036362
贝叶斯网
待学习
EM算法
EM算法(Expectation-Maximization
Algorithm)是一种迭代优化算法 ,用于处理含有隐变量 (Hidden
Variables)或缺失数据 的概率模型参数估计问题。它的核心思想是通过交替执行期望(E)步 和最大化(M)步 ,逐步逼近模型参数的最大似然估计。
1.
核心思想:解决隐变量问题 (1) 什么是隐变量?
隐变量(Latent
Variables)是模型中不可观测但影响观测数据 的变量。例如:
-
混合高斯模型(GMM) :每个样本属于哪个高斯分布是隐变量。
- 聚类任务 :样本所属的聚类标签是隐变量。
(2) 问题挑战
当存在隐变量时,直接最大化似然函数变得困难。例如: log P (x |θ ) = log ∑z P (x , z |θ )
其中 $ z $ 是隐变量,$ $
是模型参数。由于对数中包含求和,直接求导无法分离参数。
(3) EM算法的解决方案
EM算法通过以下步骤迭代求解: 1.
E步(期望) :用当前参数估计隐变量的后验分布(即“责任”分配)。
2.
M步(最大化) :基于隐变量的后验分布,最大化期望似然函数以更新参数。
2. 算法流程 (1) 初始化参数
选择初始参数 $ ^{(0)} $,例如随机初始化或通过启发式方法设定。
(2) E步:计算隐变量后验分布
给定当前参数 $ ^{(t)} $,计算隐变量 $ z $ 的后验概率: Q (t ) (z ) = P (z |x , θ (t ) )
(3) M步:最大化期望似然
基于 $ Q^{(t)}(z) ,构 造 期 望 似 然 函 数 并 最 大 化 : $
^{(t+1)} = _{} _z Q^{(t)}(z) P(, z|) $$ 这一步更新参数 $
$,使得期望似然最大。
(4) 收敛判断
重复E步和M步直到参数收敛(如 $ |^{(t+1)} - ^{(t)}| <
$)或达到最大迭代次数。
3.
示例:混合高斯模型(GMM) 假设数据由多个高斯分布生成,但不知道每个样本属于哪个分布。
(1) 模型定义
观测变量 $ x_i ^d $:第 $ i $ 个样本。
隐变量 $ z_i {1, …, K} $:样本 $ x_i $ 所属的高斯分布。
参数 $ = {_k, _k, k} {k=1}^K $:
$ _k $:第 $ k $ 个高斯分布的均值。
$ _k $:第 $ k $ 个高斯分布的协方差矩阵。
$ _k $:第 $ k $ 个高斯分布的权重(先验概率)。
(2) E步:计算责任分配
对于每个样本 $ x_i $ 和类别 $ k ,计 算 责 任 (r e s p o n s i b i l i t y ): $
_{ik}^{(t)} = P(z_i=k|x_i, ^{(t)}) = $$ 含义:在当前参数下,样本 $ x_i $
属于类别 $ k $ 的概率。
(3) M步:更新参数
根据责任 $ _{ik} $ 更新参数: - 均值更新 : $$
\mu_k^{(t+1)} = \frac{\sum_{i=1}^N \gamma_{ik}^{(t)} x_i}{\sum_{i=1}^N
\gamma_{ik}^{(t)}}
$$ - 协方差更新 : $$
\Sigma_k^{(t+1)} = \frac{\sum_{i=1}^N \gamma_{ik}^{(t)} (x_i -
\mu_k^{(t+1)})(x_i - \mu_k^{(t+1)})^T}{\sum_{i=1}^N \gamma_{ik}^{(t)}}
$$ - 权重更新 : $$
\pi_k^{(t+1)} = \frac{\sum_{i=1}^N \gamma_{ik}^{(t)}}{N}
$$
(4) 迭代终止
当参数变化小于阈值或达到最大迭代次数时停止。
作业
1
image-20250606143758565
image-20250606143819352
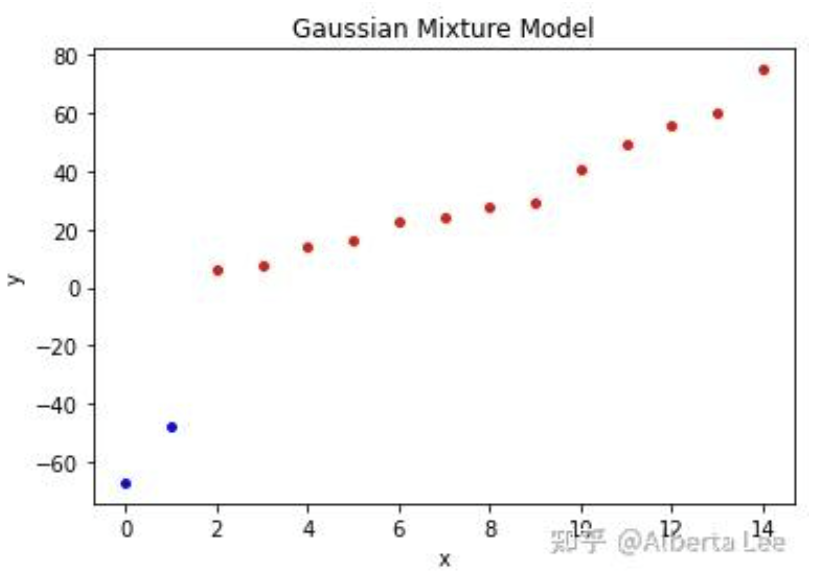
2
已知观测数据-67,-48,6,8,14,16,23,24,28,29,41,49,56,60,75,试估计两个分量的高斯混合模型的5个参数。
image-20250606150830535
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from sklearn.mixture import GaussianMixtureimport numpy as npimport matplotlib.pyplot as pltdata = np.array([-67 , -48 , 6 , 8 , 14 , 16 , 23 , 24 , 28 , 29 , 41 , 49 , 56 , 60 , 75 ]).reshape(-1 , 1 ) gmmModel = GaussianMixture(n_components=2 ) gmmModel.fit(data) labels = gmmModel.predict(data) print ("labels =" , labels)labels = [1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 ] for i in range (0 , len (labels)): if labels[i] == 0 : plt.scatter(i, data.take(i), s=15 , c='red' ) elif labels[i] == 1 : plt.scatter(i, data.take(i), s=15 , c='blue' ) plt.title('Gaussian Mixture Model' ) plt.xlabel('x' ) plt.ylabel('y' ) plt.show() print ("means =" , gmmModel.means_.reshape(1 , -1 ))print ("covariances =" , gmmModel.covariances_.reshape(1 , -1 ))print ("weights = " , gmmModel.weights_.reshape(1 , -1 ))
image-20250606150906475
3
简要阐述下EM算法的原理,并给出EM算法对高斯混合模型GMM进行求解的具体过程。
EM算法的原理
EM算法(期望最大化算法)是一种用于含有隐变量的概率模型参数估计的迭代优化方法。其核心思想是通过交替执行两个步骤来最大化观测数据的似然函数:
E步(期望步) :计算隐变量的后验期望(即责任),给定当前参数估计。M步(最大化步) :基于责任,最大化完全数据的期望似然函数以更新参数。
EM算法通过不断优化似然函数的下界,最终收敛到局部最优解。以下具体阐述EM算法对高斯混合模型(GMM)的求解过程。
EM算法对GMM的具体求解过程 1. GMM模型定义
GMM假设数据由 $ K $ 个高斯分布线性组合生成,其概率密度函数为: $$
p(\mathbf{x}|\theta) = \sum_{k=1}^K \alpha_k \cdot
\mathcal{N}(\mathbf{x}|\mu_k, \Sigma_k)
$$ 其中: - $ k $:第 $ k $ 个高斯分布的权重($ {k=1}^K
_k = 1 $)。 - $ _k $:第 $ k $ 个高斯分布的均值向量。 - $ _k $:第 $ k
$ 个高斯分布的协方差矩阵。 - $ = {_k, _k, k} {k=1}^K
$:模型参数。
隐变量 $ z_i {1,,K} $ 表示样本 $ _i $ 的类别标签(未知)。
2. EM算法步骤
(1) 初始化参数
随机或通过K-means初始化: - 每个高斯分布的均值 $ _k^{(0)} $、协方差 $
_k^{(0)} $、权重 $ _k^{(0)} $。
(2) 迭代优化(E步与M步)
E步:计算责任(后验概率) 对每个样本 x i $$
\gamma(z_{ik}) = \frac{\alpha_k \cdot \mathcal{N}(\mathbf{x}_i | \mu_k,
\Sigma_k)}{\sum_{j=1}^K \alpha_j \cdot \mathcal{N}(\mathbf{x}_i | \mu_j,
\Sigma_j)}
$$ 此概率表示在当前参数下,样本 $ _i $ 属于第 $ k $
个高斯分布的“责任”。
M步:更新参数
权重更新 : $$
\alpha_k^{(new)} = \frac{1}{N} \sum_{i=1}^N \gamma(z_{ik})
$$ 均值更新 : $$
\mu_k^{(new)} = \frac{\sum_{i=1}^N \gamma(z_{ik})
\mathbf{x}_i}{\sum_{i=1}^N \gamma(z_{ik})}
$$ 协方差更新 : $$
\Sigma_k^{(new)} = \frac{\sum_{i=1}^N \gamma(z_{ik}) (\mathbf{x}_i -
\mu_k^{(new)})(\mathbf{x}_i - \mu_k^{(new)})^\top}{\sum_{i=1}^N
\gamma(z_{ik})}
$$ 若为单变量高斯分布,则更新方差: $$
\sigma_k^{(new)} = \frac{\sum_{i=1}^N \gamma(z_{ik}) (x_i -
\mu_k^{(new)})^2}{\sum_{i=1}^N \gamma(z_{ik})}
$$
(3) 收敛判断
计算对数似然函数: $$
\log p(\mathbf{X}|\theta) = \sum_{i=1}^N \log \left( \sum_{k=1}^K
\alpha_k \cdot \mathcal{N}(\mathbf{x}_i|\mu_k, \Sigma_k) \right)
$$
若对数似然的变化量小于阈值或达到最大迭代次数,则停止;否则重复E步和M步。。
参考资料
[5分钟学算法]
#06 EM算法 你到底是哪个班级的_哔哩哔哩_bilibili
《统计学习方法_第二版》学习笔记第九章
- 知乎
集成学习
个体与集成
集成学习的基本概念 集成学习(Ensemble
Learning)通过构建并结合多个学习器(基模型) 来完成学习任务,其核心思想是“优而不同 ”,即通过多个弱学习器的协作提升整体性能 ,通常能获得比单一学习器更优的泛化能力
。
image-20250606154731476
在上图的集成模型中,若个体学习器都属于同一类别,例如都是决策树或都是神经网络,则称该集成为同质的(homogeneous);若个体学习器包含多种类型的学习算法,例如既有决策树又有神经网络,则称该集成为异质的(heterogenous)。
同质集成 :个体学习器称为“基学习器”(base
learner),对应的学习算法为“基学习算法”(base learning algorithm)。
异质集成 :个体学习器称为“组件学习器”(component
learner)或直称为“个体学习器”。
集成学习的两个重要概念:准确性 和多样性 (diversity)。准确性指的是个体学习器不能太差,要有一定的准确度;多样性则是个体学习器之间的输出要具有差异性。
通过下面的这三个例子可以很容易看出这一点,准确度较高,差异度也较高,可以较好地提升集成性能。
image-20250606155939884
集成策略 :如何结合多个基模型的预测结果,例如:
投票法 (Voting):多数投票(硬投票)或概率加权(软投票)。加权平均法 :对基模型的输出赋予不同权重 。Stacking :用元模型(Meta-Model)学习基模型的输出作为新特征
。
基于投票法的集成个体学习器的收敛性保证 :公式解析 $$
P(H(\boldsymbol{x}) \neq f(\boldsymbol{x})) = \sum_{k=0}^{\lfloor T/2
\rfloor} \binom{T}{k} (1-\epsilon)^k \epsilon^{T-k} \leq
\exp\left(-\frac{1}{2} T (1 - 2\epsilon)^2\right)
$$
1. 公式含义
H (x )f (x )ϵ P (h t x ) ≠ f (x ))T 左边 :集成学习器预测错误的概率(即至少有超过 T /2右边 :对左边概率的指数级上限估计。
2. 推导思路
假设每个基学习器独立且错误率为 ϵ 二项分布
B (T , ϵ )
集成错误的条件是“超过半数基学习器错误”,即错误次数 k ≤ ⌊T /2⌋
两个基本结论
1. 收敛速率随个体学习器数量 T
数学体现 :错误概率的上界是 exp (−c T ) 形式,其中 $c = \frac{1}{2}(1 - 2\epsilon)^2$ 。
2. ϵ = 0.5
数学原因 :当 ϵ = 0.5(1 − 2ϵ )2 = 0 ,指数项变为
0,错误概率上界为 exp (0) = 1 ,即错误概率无法降低。
根据个体学习器的生成方式 ,目前集成学习可分为两类,代表作如下:
个体学习器直接存在强依赖关系,必须串行生成的序列化方法:Boosting ;
个体学习器间不存在强依赖关系,可以同时生成的并行化方法:Bagging
和 随机森林 (Random Forest) 。
Boosting Boosting是一种串行 的工作机制,即个体学习器的训练存在依赖关系 ,必须一步一步序列化进行。
其基本思想 是:增加前一个基学习器在训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,然后基于调整后的样本分布训练下一个基学习器 ,如此重复,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合,产生学习器委员会。
Boosting族算法最著名、使用最为广泛的就是AdaBoost ,因此下面主要是对AdaBoost算法进行介绍。
AdaBoost使用的是指数损失函数 ,因此AdaBoost的权值与样本分布的更新都是围绕着最小化指数损失函数进行的。
看到这里回想一下之前的机器学习算法,不难发现机器学习的大部分带参模型只是改变了最优化目标中的损失函数 :如果是Square
loss,那就是最小二乘了;如果是Hinge
Loss,那就是著名的SVM了;如果是log-Loss,那就是Logistic
Regression了。
AdaBoost
公式解析 $$
H(\boldsymbol{x}) = \sum_{t=1}^T \alpha_t h_t(\boldsymbol{x})
$$ ℓ exp (H |𝒟) = 𝔼x ∼ 𝒟e −f (x )H (x ) ]
1. 符号含义
H (x )T h t x )α t t h t x )t f (x ){−1, +1} (二分类问题)。𝒟 ℓ exp
2. 指数损失函数的意义
指数损失函数的形式为: ℓ exp (H |𝒟) = 𝔼x ∼ 𝒟e −f (x )H (x ) ]直观解释 : - 当 H (x )f (x )e −f (x )H (x ) H (x )f (x )
AdaBoost的优化目标 AdaBoost的目标是选择基学习器 h t α t H (x )最小化指数损失函数 : $$
\min_{\alpha_1, h_1, \dots, \alpha_T, h_T} \mathbb{E}_{\boldsymbol{x}
\sim \mathcal{D}} \left[ e^{-f(\boldsymbol{x}) \sum_{t=1}^T \alpha_t
h_t(\boldsymbol{x})} \right]
$$
优化策略
AdaBoost采用前向分步算法(Forward Stagewise
Algorithm) ,逐轮迭代优化: 1.
初始化样本权重 :初始时所有样本权重相等。 2.
训练基学习器 h t :在当前样本权重分布下,训练一个弱学习器
h t 计算权重 α t :根据
h t ϵ t $$
\alpha_t = \frac{1}{2} \ln \left( \frac{1 - \epsilon_t}{\epsilon_t}
\right)
$$ 4. 更新样本权重 :提高被 h t 重复步骤
2-4 ,直到训练完成 T
示例:二分类问题 假设一个二分类任务,真实标签 f (x ) ∈ {−1, +1}$H(\boldsymbol{x}) = \sum_{t=1}^T \alpha_t
h_t(\boldsymbol{x})$ : - 若 H (x ) > 0+1 ; - 若 H (x ) < 0−1 。
此时,指数损失函数的值反映了模型对错误样本的惩罚程度: -
正确预测时,e −f (x )H (x ) ≈ 0e −f (x )H (x ) ≫ 1
AdaBoost的算法流程
image-20250606172851748
重赋权法与重采样法
在集成学习中,Boosting
算法的核心在于动态调整样本权重 ,以逐步聚焦难分类样本。Boosting
主要通过两种方法实现样本权重的更新:重赋权法(re-weighting)
和 重采样法(re-sampling) 。
重赋权法 :
对每个样本附加一个权重,这时涉及到样本属性与标签的计算,都需要乘上一个权值。
重采样法 :
对于一些无法接受带权样本的及学习算法,适合用“重采样法”进行处理。方法大致过程是,根据各个样本的权重,对训练数据进行重采样,初始时样本权重一样,每个样本被采样到的概率一致,每次从N个原始的训练样本中按照权重有放回采样N个样本作为训练集,然后计算训练集错误率,然后调整权重,重复采样,集成多个基学习器。
从偏差-方差分解来看:Boosting算法主要关注于降低偏差,每轮的迭代都关注于训练过程中预测错误的样本,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成学习器。
拓展:Gradient Boosting
任务分为分类,回归,聚类,降维等,而分类中还分为二分类和多分类
从AdaBoost的算法流程来看,标准的AdaBoost只适用于二分类问题。
通过改造AdaBoost对样本分类的限制和损失函数,可以实现多分类或回归问题,这样改造出来的算法框架成为Gradient
Boosting
GBDT(Gradient
Boosting Decision Tree)与XGBoost 1. GBDT 的核心思想
GBDT 是基于梯度提升(Gradient
Boosting) 框架的集成学习方法,其特点包括: -
基学习器 :使用CART(分类与回归树) 作为个体学习器。
- 损失函数 : -
回归问题 :平方损失(Squared Loss): err(H t x ), f (x )) = (H t x ) − f (x ))2
- 二分类问题 :对数似然损失(Log-Likelihood
Loss,类似逻辑回归): err(H t x ), f (x )) = log (1 + exp (−f (x )H t x )))
- 多分类问题 :扩展为多分类对数损失。
2. XGBoost 的定位
XGBoost(eXtreme Gradient Boosting)是 GBDT
的一种高效实现和改进 ,类似于 LIBSVM 对 SVM
的优化关系。其核心目标是: -
提升训练速度 :通过并行计算 、内存优化 等工程技巧。
-
增强模型性能 :引入正则化项 、缺失值处理 、自适应学习率 等改进。
XGBoost即eXtremeGradient
Boosting的缩写,XGBoost与GBDT的关系可以类比为
LIBSVM和SVM的关系,即XGBoOst是GBDT的一种高效实现和改进。
它并非一个全新的算法框架,而是对标准 GBDT
进行了大量的工程优化和算法增强 。
image-20250606175536310
Bagging
Bagging是一种并行式 的集成学习方法,即基学习器的训练之间没有前后顺序可以同时进行
Bagging使用“有放回”采样的方式选取训练集 ,对于包含m个样本的训练集,进行m次有放回的随机采样操作,从而得到m个样本的采样集,这样训练集中有接近36.8% 的样本没有被采到,可用作验证集来对泛化性能进行“包外估计”(out-of-bag
estimate)。
按照相同的方式重复进行,我们就可以采集到T个包含m个样本的数据集,从而训练出T个基学习器 ,最终对这T个基学习器的输出进行结合 。
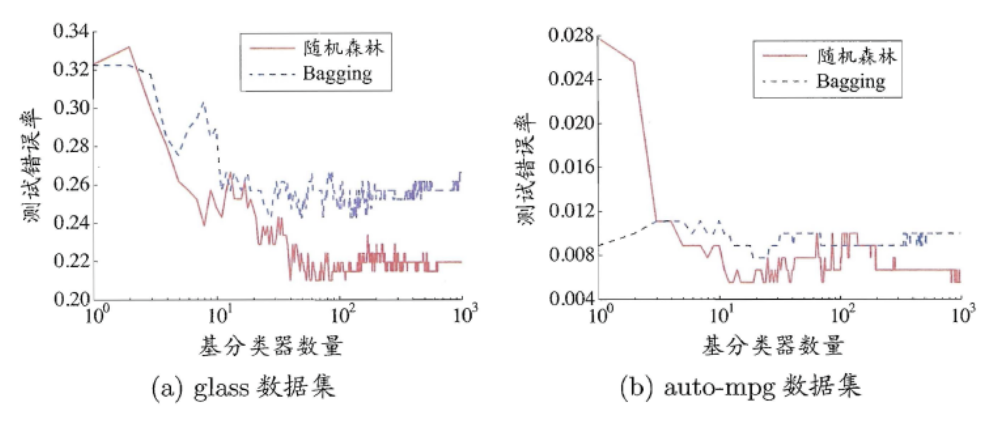
Bagging与Boosting的差异
Boosting算法一大特点是串行,这样诚然可以降低模型的偏差,增强拟合能力,但是当数据过大时,一大缺点就是会降低学习效率
Bagging作为并行式的集成学习方法,通过综合多个基学习器的结果,可以增加学习效率
二者差异性:
1.对目标的拟合程度:Boosting对目标有更好的拟合能力(偏差小);Bagging则偏差相对大一些
2.运行效率:由于并行的特点,Bagging的运行效率是大于Boosting的
3.泛化能力:由于Bagging每个学习器不会受其他学习器的影响,泛化能力(方差大)相对于Boosting
更好
Bagging的算法流程
image-20250606182733022
可以看出Bagging主要通过样本的扰动 来增加基学习器之间的多样性,因此Bagging的基学习器应为那些对训练集十分敏感的不稳定学习算法,例如:神经网络与决策树等。
从偏差-方差分解来看,Bagging算法主要关注于降低方差,即通过多次重复训练提高稳定性。
不同于AdaBoost的是,Bagging可以十分简单地移植到多分类、回归等问题。总的说起来则是:AdaBoost关注于降低偏差,而Bagging关注于降低方差。
自助采样法(Bootstrap
Sampling)
在机器学习中,自助采样法(Bootstrap Sampling) 是
Bagging
算法的核心技术之一。其核心思想是从原始数据集中有放回地随机抽取样本,形成新的训练子集。这一过程的一个重要数学性质是:当样本量
n 未被抽中 的概率趋近于 $\frac{1}{e} \approx
36.6\%$ 。以下是详细解析:
1. 公式推导
假设我们从 n 有放回地 抽取 n i 未被选中 的概率为: $$
1 - \frac{1}{n}
$$ 因此,它在整个 n 从未被选中 的概率为: $$
\left(1 - \frac{1}{n}\right)^n
$$ 当 n → ∞$$
\lim_{n \to \infty} \left(1 - \frac{1}{n}\right)^n = \frac{1}{e} \approx
0.3679 \quad (\text{即 } 36.6\%)
$$ 在每次 Bootstrap 采样中,约有 36.6%
的样本未被选中 ,这些样本称为
Out-of-Bag(OOB,包外估计)样本 。
2. OOB 样本的应用
在 Bagging 算法中,OOB 样本具有以下重要作用: 1.
无偏验证 :特征重要性评估 :
3. 与其他采样方法的对比
采样方法 是否放回 样本覆盖范围 典型应用场景
Bootstrap 采样 是
约 63.4% 样本被重复使用
Bagging、随机森林
简单随机采样 否
所有样本唯一出现
传统交叉验证
随机森林
随机森林(Random
Forest)是Bagging的一个拓展体,它的基学习器固定为决策树 ,多棵树也就组成了森林,而“随机”则在于选择划分属性的随机 ,随机森林在训练基学习器时,也采用有放回采样的方式添加样本扰动,同时它还引入了一种属性扰动 ,即在基决策树的训练过程中,在选择划分属性时,RF先从候选属性集中随机挑选出一个包含K个属性的子集,再从这个子集中选择最优划分属性
。
这样随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动 ,从而进一步提升了基学习器之间的差异度。相比决策树的Bagging集成,随机森林的起始性能较差(由于属性扰动,基决策树的准确度有所下降),但随着基学习器数目的增多,随机森林往往会收敛到更低的泛化误差。同时不同于Bagging中决策树从所有属性集中选择最优划分属性,随机森林只在属性集的一个子集中选择划分属性,因此训练效率更高 。
image-20250606184958951
结合策略
在集成学习中,结合策略是将多个基学习器的输出整合为最终预测结果的关键步骤。以下是针对回归和分类问题的不同结合策略及其核心要点:
定义 :在训练好多个基学习器后,如何将其输出组合成集成模型的最终输出。
1.平均法(回归问题)
简单平均法(Simple Averaging)
公式 :$$
H(x) = \frac{1}{T} \sum_{i=1}^{T} h_i(x)
$$ 特点 :
直接对所有基学习器的预测结果取算术平均。
计算简单,适合基学习器性能相近的场景。
若部分基学习器表现较差,可能拖累整体性能。
加权平均法(Weighted Averaging)
公式 :$$
H(x) = \sum_{i=1}^{T} w_i h_i(x)
$$ 其中,$ w_i $ 且 $ _{i=1}^{T} w_i = 1 $。特点 :
通过权重 $ w_i $ 调节各基学习器的贡献,灵活性更高。
适用于基学习器性能差异较大的情况,可提升鲁棒性。
权重可通过验证集性能(如RMSE、MAE)或优化算法(如梯度下降)确定。
2.投票法(分类问题)
简单投票法(Majority Voting)
原理 :公式 (二分类示例):$$
H(x) =
\begin{cases}
1 & \text{若} \sum_{i=1}^{T} I(h_i(x) = 1) > T/2 \\
0 & \text{否则}
\end{cases}
$$ 其中,$ I() $ 为指示函数。特点 :
简单高效,适合基学习器性能相近的场景。
对异常分类器的鲁棒性较弱。
加权投票法(Weighted Voting)
原理 :公式 (二分类示例):$$
H(x) =
\begin{cases}
1 & \text{若} \sum_{i=1}^{T} w_i I(h_i(x) = 1) > 0.5
\sum_{i=1}^{T} w_i \\
0 & \text{否则}
\end{cases}
$$ 特点 :
权重可根据基学习器的验证集准确率或领域知识设定。
更适合处理性能差异较大的基学习器。
绝对多数投票法(majority
voting)提供了拒绝选项,这在可靠性要求很高的学习任务中是一个很好的机制。同时,对于分类任务,各个基学习器的输出值有两种类型,分别为类标记和类概率。
image-20250606195241433
一些在产生类别标记的同时也生成置信度的学习器,置信度可转化为类概率使用,一般基于类概率进行结合往往比基于类标记进行结合的效果更好 ,需要注意的是对于异质集成,其类概率不能直接进行比较,此时需要将类概率转化为类标记输出,然后再投票。
3.学习法(Stacking) 学习法 是一种更高级的结合策略,其核心思想是通过训练一个次级学习器(Meta-Learner)
来动态融合多个基学习器的输出。其中,Stacking(堆叠泛化)
是学习法的典型代表,它通过将基学习器的预测结果作为新特征,进一步训练一个次级模型,最终实现更优的泛化性能。
Stacking 的基本原理
步骤概述 :
训练基学习器 :使用原始数据训练 $ T $
个基学习器(如决策树、SVM、神经网络等)。生成新特征 :对于每个样本,将 $ T $
个基学习器的输出(预测结果)作为该样本的新特征,形成一个 $ m T $
的数据集($ m $ 为样本数量)。训练次级学习器 :使用新数据集(基学习器输出 +
真实标签)训练一个次级学习器(如逻辑回归、梯度提升树等),该学习器负责融合基学习器的预测结果。
Stacking 的优势
动态权重分配 :异质模型融合 :提升泛化能力 :
Stacking 的实现细节
数据划分 :
通常需将原始数据分为两部分:
训练集 :用于训练基学习器。验证集 :用于生成基学习器的输出(避免过拟合)。
或采用交叉验证(如 $ k
$-折)生成基学习器的预测结果,确保次级学习器的训练数据不被污染。
基学习器输出类型 :
分类任务 :基学习器输出类概率(Soft
Voting),而非类别标签(Hard Voting)。例如,逻辑回归输出 $ P(c_j | x)
$,随机森林输出节点样本的类别分布。回归任务 :基学习器直接输出预测值(如线性回归的
ŷ 次级学习器选择 :
多响应线性回归(MLR) :适用于基学习器输出可加权平均的情况,计算简单且鲁棒。$$
H(x) = \sum_{i=1}^{T} w_i h_i(x)
$$ 复杂模型 :如梯度提升树、神经网络,可捕捉基学习器输出之间的非线性关系。
多样性
在集成学习中,多样性增强(Diversity Enhancement)
是提升模型性能的关键策略。通过引入多样性,可以降低基学习器之间的相关性,从而减少误差传递和过拟合风险。以下是四种常见的多样性增强方法及其核心要点:
1. 数据样本扰动(Data Perturbation)
原理 :通过修改训练数据的分布或采样方式,使每个基学习器看到不同的数据子集。
实现方式 :Bagging(如随机森林) :示例 :
2. 输入属性扰动(Input Attribute Perturbation)
原理 :通过改变输入特征的表示或选择,增加基学习器间的差异。
实现方式 :特征子集采样 :每次随机选择部分特征进行训练(如随机森林中的列扰动)。特征变换 :对特征进行缩放、旋转或加噪声等操作。适用场景 :
3. 输出属性扰动(Output Attribute Perturbation)
原理 :通过修改训练样本的标签,间接影响基学习器的学习过程。
实现方式 :随机翻转标签 :对部分样本的标记进行随机更改(需谨慎使用,避免干扰模型)。Dropout(神经网络) :
4. 算法参数扰动(Algorithm Parameter
Perturbation)
原理 :通过调整基学习器的超参数,生成不同的模型行为。
实现方式 :
正则化方法 :L1/L2 正则化(如
Ridge、Lasso)限制模型复杂度,降低过拟合风险。随机初始化 :
神经网络的随机权重初始化可能导致收敛到不同局部最优解。
作业
1
集成学习中常见的两种方法是什么?请分别介绍它们的原理和特点。集成学习相比于单个模型有什么优势和应用场景?
集成学习常见方法、原理、特点及优势
常见方法 :Bagging 和 Boosting原理与特点 :
方法 原理 特点
Bagging 1. 自助采样 :从训练集有放回抽取多个子集并行训练 基模型聚合预测 (投票/平均)
- 降低方差
Boosting 1. 顺序训练 :后一个模型修正前一个模型的错误加权困难样本 加权组合 模型
- 降低偏差
集成学习的优势 :提升泛化能力 :降低过拟合(Bagging)或欠拟合(Boosting)风险增强鲁棒性 :减少异常值/噪声影响(如投票机制)突破性能上限 :组合多个弱模型达到强模型效果
应用场景 :分类任务 :医疗诊断(整合多模型减少误诊)回归任务 :房价预测(融合不同树模型提升精度)不平衡数据 :Boosting 加权少数类样本高维数据 :随机森林自动特征选择
2
如果在完全相同的训练集上训练了五个不同的模型,并且它们都达到了95%的准确率,是否还有机会通过结合这些模型来获得更好的结果?如果可以,该怎么做?如果不行,为什么?
模型结合提升性能的可能性与方法
是否可能提升 :是 ,但需满足条件:模型错误不相关 (即犯错样本不同)。
如何实现 :
投票法(分类) :
多数投票:5个模型对样本 (x) 的预测为 ([A, A, B, A, C]) → 最终输出
(A)
关键要求 :模型存在多样性 (如使用SVM、决策树等不同算法) 加权平均(回归) :
若模型精度不同,分配权重:$ y_{} = w_1 y_1 + w_2 y_2 + + w_5
y_5$
权重可通过验证集性能确定
若无法提升的情况 :原因 :模型高度相关(如相同算法、相同特征、相同超参)数学解释 :误差相关性 r h o ≈ 1≈ 单一模型误差
3
是否可以通过在多个服务器上并行来加速随机森林的训练?AdaBoost集成呢?为什么?
算法 是否支持并行 原因
随机森林 ✅ 是
1. 树之间独立训练
AdaBoost ❌ 否
1.
模型必须顺序训练 :后一个模型依赖前一个模型的样本权重更新
聚类
聚类任务
我们之前学习的分类/回归任务都属于 有监督学习
需要我们提供样本与标签
而马上要学习的聚类任务和后续学习的降维则属于 无监督学习
仅需提供样本
聚类是一种经典的无监督学习 (unsupervised
learning)方法,无监督学习的目标是通过对无标记训练样本的学习,发掘和揭示数据集本身潜在的结构与规律 ,即不依赖于训练数据集的类标记信息。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”(
cluster) 。通过这样的划分,每簇可能对应于一些潜在的概念(类别),如“浅色瓜”“深色瓜”,“有籽瓜”“无籽瓜”,甚至“本地瓜”“外地瓜”等;需说明的是,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,
簇所对应的概念语义需由使用者来把握和命名 。
直观上来说,聚类是将相似的样本聚在一起,从而形成一个类簇(cluster) 。涉及两个问题
如何度量相似性 (similarity
measure),这便是距离度量 (distance
measure),在生活中我们说差别小则相似,对应到多维样本,每个样本可以对应于高维空间中的一个数据点,若它们的距离相近,我们便可以称它们相似。
如何评价聚类结果 ,这便是性能度量 (validity
index)
距离度量
连续/离散有序
明可夫斯基距离(Minkowski Distance)
明可夫斯基距离是一组常用的连续型距离度量 ,通过调整参数
$ p $ 可以统一表示多种距离形式,是欧氏距离和曼哈顿距离的推广。
1. 公式定义
对于两个 $ n $ 维向量 $ i = (x {i1}, x_{i2}, , x_{in}) $ 和 $
j = (x {j1}, x_{j2}, , x_{jn}) ,明 可 夫 斯 基 距 离 的 计 算 公 式 为 : $
{}(i, j) = ( {u=1}^{n} |x {iu} - x {ju}|^p )^{}
$$ 其中,$ p $ 是一个可调节的参数。
2. 特殊情况
**当 $ p = 2 * * :退 化 为 * *欧 氏 距 离 (E u c l i d e a n D i s t a n c e ) * * $
_{}(_i, _j) = $$
几何意义 :两点之间的直线距离。适用场景 :大多数机器学习算法(如KNN、PCA)默认使用欧氏距离。
**当 $ p = 1 * * :退 化 为 * *曼 哈 顿 距 离 (M a n h a t t a n D i s t a n c e ) * * $
{}(i, j) = {u=1}^{n} |x {iu} - x {ju}| $$
几何意义 :沿坐标轴移动的总距离(如棋盘格路径)。适用场景 :高维稀疏数据(如文本特征)、计算资源受限的场景。
**当 $ p * * :退 化 为 * *切 比 雪 夫 距 离 (C h e b y s h e v D i s t a n c e ) * * $
{}(i, j) = {u} |x {iu} - x {ju}| $$
几何意义 :各维度差值的最大值。适用场景 :关注最坏情况下的误差(如游戏AI路径规划)。
3. 参数 $ p $ 的影响
$ p $
越小 :距离计算越关注较小的维度差异(如曼哈顿距离对单个维度的扰动更敏感)。$ p $
越大 :距离计算越关注较大的维度差异(如切比雪夫距离仅关注最大差值)。选择依据 :
数据分布是否均匀:若某些维度差异显著,可增大 $ p $。
算法需求:如KNN中,高维数据可能更适合曼哈顿距离(缓解“维度灾难”)。
离散无序
我们知道属性分为两种:连续属性 (continuous
attribute)和离散属性 (catergorical
attribute有限个取值)。对于连续值的属性,一般都可以被学习器所用,有时会根据具体的情形作相应的预处理,例如:归一化等;而对于离散值的属性,需要作下面进一步的处理:
若属性值之间存在序关系 (ordinal
attribute),则可以将其转化为连续值,例如:身高属性“高”“中等”“矮”,可转化为{1,
0.5, 0}。
若属性值之间不存在序关系 (non-ordinal
attribute),则通常将其转化为向量的形式,例如:性别属性“男”“女”,可转化为{(1,0),(0,1)}。
连续属性和存在序关系的离散属性都可以直接参与计算 ,而不存在序关系的无序属性,我们一般采用VDM(Value
Difference Metric)进行距离的计算
VDM
是一种专门用于离散无序属性 的距离度量方法,通过统计信息量化不同类别间的差异。其核心思想是:若两个类别的样本在目标变量上的分布差异越大,则它们的距离越大 。
1. 公式解析 $$
\text{VDM}_p(a, b) = \sum_{i=1}^{k} \left| \frac{m_{u,a,i}}{m_{u,a}} -
\frac{m_{u,b,i}}{m_{u,b}} \right|^p
$$ - 符号含义 :
2. 核心思想
统计分布差异 :$$
\left| \frac{m_{u,a,i}}{m_{u,a}} - \frac{m_{u,b,i}}{m_{u,b}} \right|
$$ 该值越大,说明两个类别在该取值上的分布差异越大。加权求和 :
3. 示例说明
假设我们有一个“颜色”属性(红、蓝、绿),目标变量是“是否购买商品”(0/1)。统计结果如下:
颜色
购买(1)
不购买(0)
总计
红
10
5
15
蓝
8
12
20
绿
3
7
10
计算“红”与“蓝”之间的 VDM 距离($ p=1 ):1.计 算 每 个 颜 色 在 购 买 /不 购 买 的 比 例 : − 红 :
P(1) = 10/15 , P(0) = 5/15 $, P(0) =
12/20 = 0.6 $VDM1 (红, 蓝) = |0.67 − 0.4|+|0.33 − 0.6| = 0.27 + 0.27 = 0.54
性能度量
于聚类算法不依赖于样本的真实类标,就不能像监督学习的分类那般,通过计算分对分错(即精确度或错误率)来评价学习器的好坏或作为学习过程中的优化目标。
直观上看,我们希望“物以类聚” ,即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同换言之,聚类结果的“簇内相似度”(
intra-cluster similarity)高且“簇间相似度” inter-cluster
similarity)低
聚类性能度量有两类
“外部指标”(external
index):所谓外部指标就是已经有一个“参考模型”存在了,将当前模型与参考模型的比对结果作为指标。
“内部指标”( internal
index):所谓内部指标就是仅仅考虑当前模型的聚类结果。
外部指标
1.基本概念
image-20250607110103570
显然,$ a + b + c + d = $ 。
2. 常用外部指标
(1)Jaccard系数(JC) $$
\text{JC} = \frac{a}{a + b + c}
$$ -
含义 :衡量两个划分的重叠程度,仅考虑正确匹配($ a )与 矛 盾 情 况 (
b + c )。 − * * 范 围 * *: [0,
1] $,值越大越好。特点 :对称性差,对噪声敏感 。
(2)Fowlkes-Mallows指数(FMI) $$
\text{FMI} = \sqrt{\frac{a}{a + b} \cdot \frac{a}{a + c}}
$$ - 含义 :结合查准率($ )和 查 全 率 (
),反 映 正 确 匹 配 的 综 合 能 力 。 − * * 范 围 * *:
[0, 1] $,值越大越好。特点 :平衡性较好,适合小样本 。
(3)Rand指数(RI) $$
\text{RI} = \frac{2(a + d)}{m(m - 1)}
$$ - 含义 :同时考虑正确匹配($ a + d )与 总 样 本 对 数 ,适 用 于 大 规 模 数 据 。 − * * 范 围 * *:
[0, 1] $,值越大越好。特点 :计算简单,但对噪声较鲁棒 。
常用指标
调整兰德指数(Adjusted Rand Index, ARI)
定义 :衡量聚类结果与真实标签的匹配程度,调整随机聚类的影响,取值范围
[-1, 1],值越大越好。公式 :$$
\text{ARI} = \frac{\text{RI} - \mathbb{E}[\text{RI}]}{\max(\text{RI}) -
\mathbb{E}[\text{RI}]}
$$ 其中 RI 是兰德指数(匹配样本对的比例)。 归一化互信息(Normalized Mutual Information, NMI)
定义 :衡量聚类结果与真实标签的信息共享程度,值越大越好。公式 :$$
\text{NMI} = \frac{I(C; K)}{\sqrt{H(C) H(K)}}
$$ 其中 $ I(C; K) $ 是互信息,$ H(C) $ 和 $ H(K) $ 是熵。 Fowlkes-Mallows 指数(FMI)
定义 :基于聚类结果与真实标签的 TP、FP、TN、FN
计算,值越大越好。公式 :$$
\text{FMI} = \sqrt{\frac{\text{TP}}{\text{TP} + \text{FP}} \cdot
\frac{\text{TP}}{\text{TP} + \text{FN}}}
$$
优点
在有真实标签时,能更客观地评估聚类效果。
适用于验证聚类结果的业务意义(如客户分群是否符合预期)。
局限性
需要真实标签,不适用于纯无监督任务。
对标签噪声敏感(如标签错误会误导 $ K $ 的选择)。
3. 应用示例
假设一个包含4个样本的数据集,参考标签为 {A , A , B , B } ,聚类结果为
{C , C , D , D } :
- 计算样本对 :指标结果 :
内部指标
内部指标不依赖任何外部参考模型,直接通过簇内紧凑性 和簇间分离性 评估聚类结果。其核心思想是:
- 簇内高内聚 :同一簇的样本尽可能相似(距离小)。簇间低耦合 :不同簇的样本尽可能不同(距离大)。
1. 基本定义
设聚类结果为 $ C = {C_1, C_2, , C_k} $,定义以下四个关键距离:
(1)簇内平均距离(avg(C)) $$
\text{avg}(C) = \frac{2}{|C|(|C| - 1)} \sum_{1 \leq i < j \leq |C|}
\text{dist}(\boldsymbol{x}_i, \boldsymbol{x}_j)
$$ - 含义 :簇内所有样本对的平均距离。目标 :越小越好,表示簇内样本更紧密。
(2)簇内最大距离(diam(C)) diam(C ) = max1 ≤ i < j ≤ |C | dist(x i x j
- 含义 :簇内最远的两个样本之间的距离。目标 :越小越好,避免簇内存在离群点。
**(3)簇间最小距离($ d_{}(C_i, C_j) ) * * $ d_{}(C_i, C_j) = _{_i C_i, _j C_j}
(_i, _j) $$ - 含义 :簇 $ C_i $ 和 $ C_j $
之间最近的两个样本的距离。目标 :越大越好,表示簇间分离度高。
**(4)簇中心距离($ d_{}(C_i, C_j) ) * * $ d_{}(C_i, C_j) = (_i, _j) $$ -
含义 :簇 $ C_i $ 和 $ C_j $
的中心点(均值向量)之间的距离。目标 :越大越好,表示簇中心相隔较远。
2. 常用内部指标
1. DB指数(Davies-Bouldin Index, DBI)
公式 :$$
\text{DBI} = \frac{1}{k} \sum_{i=1}^{k} \max_{j \neq i} \left(
\frac{\text{avg}(C_i) + \text{avg}(C_j)}{d_{\text{cen}}(\mu_i, \mu_j)}
\right)
$$
符号含义 :
$ k $:簇的数量。
$ (C_i) $:簇 $ C_i $ 内部样本的平均距离。
$ d_{}(_i, _j) $:簇 $ C_i $ 和 $ C_j $
的中心点(均值向量)之间的距离。
目标 :越小越好。核心思想 :对于每个簇 $ C_i $,找到与其“最竞争”的簇
$ C_j $(即 $ $ 最大的簇),并取所有簇的平均值。 示例 :
2. Dunn指数(Dunn Index, DI)
公式 :$$
\text{DI} = \min_{1 \leq i \leq k} \left\{ \frac{\min_{j \neq i}
d_{\min}(C_i, C_j)}{\max_{1 \leq l \leq k} \text{diam}(C_l)} \right\}
$$
符号含义 :
$ d_{}(C_i, C_j) $:簇 $ C_i $ 和 $ C_j $
之间的最小距离(最近样本对的距离)。
$ (C_l) $:簇 $ C_l $ 内的最大距离(最远样本对的距离)。
目标 :越大越好。核心思想 :
分子:所有簇对之间的最小距离中的最小值(即最“脆弱”的簇间分离度)。
分母:所有簇中的最大直径(最“松散”的簇内紧凑度)。
指数越大,表示簇间分离度高且簇内紧凑。
示例 :
3. 轮廓系数(Silhouette Coefficient)
4.肘部法则(Elbow Method)
肘部法则是一种经验性方法 ,常用于确定K-means等聚类算法的最优簇数($
K $)。其核心思想是通过观察误差平方和(SSE, Sum of Squared Errors)随 $
K $ 值变化的趋势,寻找“肘部点”(即 SSE
下降速度明显减缓的拐点),从而选择最优的 $ K $ 值
指标对比与选择
指标 计算方式 目标 适用场景 局限性
DBI
簇内平均距离与簇中心距离的比值
越小越好
球形簇,需指定 $ k $
对离群点敏感
Dunn指数
簇间最小距离与簇内最大直径的比值
越大越好
强调簇间分离与簇内紧凑
计算复杂,受离群点影响
轮廓系数
样本到同簇/异簇的平均距离差
越接近 1 越好
快速评估,适合 K-Means
对非球形簇不敏感
原型聚类与kmeans
原型聚类
原型聚类即“基于原型的聚类 ”(prototype-based
clustering),原型表示模板的意思,就是通过参考一个模板向量或模板分布的方式来完成聚类的过程,通常情形下算法先对原型进行初始化,然后对原型进行迭代更新求解。采用不同的原型表、不同的求解方式,将产生不同的算法。
常见的K-Means便是基于簇中心(原型向量)来实现聚类,混合高斯聚类则是基于簇分布(概率模型)来实现聚类。
K-Means 聚类算法详解 目标函数 :最小化所有样本到其所属簇中心的平方距离之和:$$
E = \sum_{i=1}^{k} \sum_{\boldsymbol{x} \in C_i} \|\boldsymbol{x} -
\boldsymbol{\mu}_i\|_2^2
$$ 其中,$ i = { C_i} $ 是簇 $ C_i $ 的均值向量。
算法步骤
初始化簇中心 :随机选择 $ k $ 个样本作为初始簇中心。
改进方法 :K-Means++
算法可提升初始中心的质量。 分配样本到最近簇 :对每个样本 $
$,计算其到所有簇中心的距离,将其分配到距离最近的簇 $ C_i $。更新簇中心 :重新计算每个簇的均值向量 $ _i $。迭代终止条件 :
达到预设的最大迭代次数;
簇中心不再显著变化(如变化幅度小于阈值 $ $);
样本分配不再改变。
如何选择 $ k $ 值?
肘部法则(Elbow Method) :绘制 $ k $ 与误差 $ E $
的关系曲线,选择误差下降显著变缓的 $ k $ 值。轮廓系数(Silhouette
Coefficient) :计算每个样本的轮廓系数,选择平均轮廓系数最大的 $
k $。
K-Means的算法流程
image-20250607114743211
K-means++
此法相对于 K-means 做出了一个小的改进。在一开始选择 k
个聚类中心时,并不是随机初始化 k 个,而是首先随机出 1 个,然后循环
k−1k −1 次选择剩下的 k-1
个聚类中心。选择的规则是:每次选择最不可能成为新的聚类中心的样本,或者是到所有聚类中心的最小距离最大的样本。
优势 避免不良初始化
:传统K-means随机初始化可能导致中心过于集中,而K-means++通过“最大化最小距离”策略,使初始中心分布更均匀。
Bisecting K-means
此法叫做二分 K-means
算法。具体的,在一开始将所有的样本划分为一个簇,然后每次选择一个误差最大的簇进行二分裂,不断分裂直到收敛。这种方法不能使得
Loss 最小,但是可以作为 K-means
算法的一个预热,比如可以通过这种方法得到一个相对合理的簇中心,然后再利用
K-means 算法进行聚类。
优势 降低计算复杂度
:每次仅对一个簇进行二分,时间复杂度为
O (k ⋅m ⋅n ) ,适合大规模数据。
提供合理初始中心
:可作为传统K-means的预处理,减少随机初始化的影响。
LVQ(学习向量量化) 核心思想 :有监督的原型聚类算法 ,结合了神经网络与向量量化技术。它通过维护一组原型向量 (Prototype
Vectors)来代表不同类别,并利用这些原型对数据进行分类或聚类。与 K-Means
类似,LVQ
会为每个簇分配一个原型向量,但其更新规则受类别标签的指导,因此更适用于分类任务
。
算法特点 :
有监督学习 :需要已知类别标签来调整原型向量,使同类样本更接近对应原型,异类样本远离原型。拓扑结构建模 :通过原型向量捕捉数据的局部特征,类似于自组织映射(SOM),但更具针对性。硬聚类 :每个样本最终被分配到最近的原型对应的类别,不提供概率输出
。
高斯混合聚类(Gaussian
Mixture Model, GMM) 一句话概述算法:高斯混合聚类算法是一种概率模型,假设数据由多个高斯分布混合而成,通过迭代优化参数以拟合数据分布,常用于无监督学习中的聚类任务。
算法过程:
初始化参数: 随机初始化每个分量的均值、协方差矩阵和混合系数。
E 步(Expectation):
对每个数据点,计算它属于每个分量的后验概率,即计算每个分量的权重。
M 步(Maximization):
使用E步计算得到的后验概率,更新每个分量的均值、协方差矩阵和混合系数。
迭代: 重复执行E步和M步,直到模型参数收敛或达到预定的迭代次数。
GMM的优点包括对各种形状和方向的聚类簇建模能力,以及对数据分布的灵活性。它在许多领域,如模式识别、图像处理和自然语言处理等,都有广泛的应用。
以下是高斯混合聚类(GMM)算法的详细步骤及EM算法中E步与M步的解释:
算法流程解析
输入 :样本集 $ D = {x_1, x_2, , x_m} $,混合成分个数
$ k $。输出 :簇划分 $ C = {C_1, C_2, , C_k} $。
步骤详解
初始化模型参数
混合系数 $ i $(满足 $ {i=1}^k _i = 1
$)。均值向量 $ _i $。协方差矩阵 $ _i $。 迭代优化参数(EM循环)
E步(期望步) :后验概率 (责任度 $ {ji} ): $ {ji} = p(z_j = i | x_j) = $$ 其中
$ (x | , ) $ 是高斯分布的概率密度函数。
M步(最大化步) :
新均值向量 : $$
\mu_i' = \frac{\sum_{j=1}^m \gamma_{ji} x_j}{\sum_{j=1}^m \gamma_{ji}}
$$ 新协方差矩阵 : $$
\Sigma_i' = \frac{\sum_{j=1}^m \gamma_{ji} (x_j - \mu_i')(x_j -
\mu_i')^\top}{\sum_{j=1}^m \gamma_{ji}}
$$ 新混合系数 : $$
\alpha_i' = \frac{\sum_{j=1}^m \gamma_{ji}}{m}
$$ 簇划分
初始化空簇 $ C_i = $。
对每个样本 $ x_j $,计算其属于各簇的后验概率 $ _j = i {ji}
$。
将 $ x_j $ 分配到簇 $ C_{_j} $ 中。
E步与M步的核心作用
E步(期望步)
目标 :基于当前参数 $ (_i, _i, i)
$,计算每个样本 $ x_j $ 属于各高斯分布的责任度 $
{ji} $。意义 :
责任度反映了在当前模型下,样本 $ x_j $ 由第 $ i $
个高斯分布生成的概率。
软分配 :允许样本部分属于多个簇,而非硬划分。
M步(最大化步)
目标 :根据责任度 $ _{ji} $,重新估计模型参数 $
(_i’, _i’, _i’) $,以最大化数据的对数似然。关键公式 :
均值更新 :加权平均样本点,权重为责任度。协方差更新 :加权样本点的方差,反映簇内数据分布。混合系数更新 :各簇样本的“有效数量”占总样本的比例。
参考资料
西瓜书读书笔记整理(九)
—— 第九章 聚类_西瓜书笔记第9章-CSDN博客
密度聚类与DBSCAN
若样本分布为同心的两个环,kmeans则无法做到良好的聚类效果,因此引出密度聚类
密度聚类是一种基于样本分布密集程度 的无监督学习方法,其核心思想是:将高密度区域划分为同一簇,低密度区域视为噪声或边界 。
DBSCAN(Density-Based Spatial Clustering of Applications with
Noise)是密度聚类的典型代表,通过两个关键参数 $ $ 和 $ MinPts $
描述样本分布的紧密性。
1. 核心概念
$ $-邻域
定义:与样本 $ x $ 距离不超过 $ $ 的所有样本集合。
作用:衡量样本周围的局部密度。
核心对象(Core Object)
定义:若样本 $ x $ 的 $ $-邻域内包含至少 $ MinPts $ 个样本,则 $ x $
是核心对象。
作用:作为簇的生长起点,确保簇的最小密度要求。
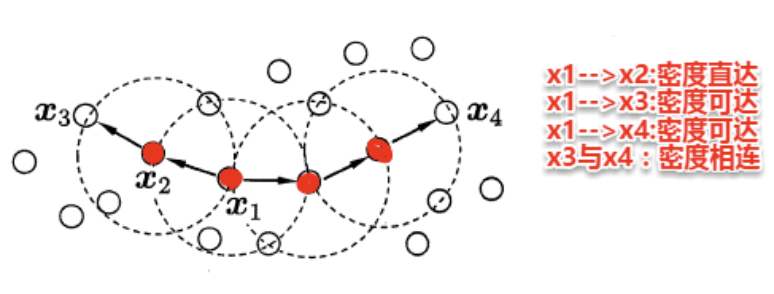
密度直达(Directly Density-Reachable)
定义:若样本 $ x_j $ 位于核心对象 $ x_i $ 的 $ $-邻域内,则称 $ x_i
$ 可密度直达 $ x_j $。
作用:建立核心对象与邻近样本的直接连接。
密度可达(Density-Reachable)
定义:若存在样本序列 $ x_i, p_1, p_2, , p_n, x_j $,其中 $ p_i $
密度直达 $ p_{i+1} $,则称 $ x_i $ 可密度可达 $ x_j $。
作用:通过链式传递扩展簇的范围。
密度相连(Density-Connected)
定义:若样本 $ x_i $ 和 $ x_j $ 均可密度可达某个公共样本 $ x_k
$,则称 $ x_i $ 和 $ x_j $ 密度相连。
作用:确保簇的连通性,避免碎片化。
image-20250607124326529
DBSCN定义的簇
定义:最大密度相连的样本集合为一个簇
有两个性质:1.连接性:同一个簇内任意两样本,必然密度相连2.最大性:密度可达的两个样本必
定属于同一个簇
2. DBSCAN 算法流程 简单来理解DBSCAN:找出一个核心对象所有密度可达的样本集合形成簇 。首先从数据集中任选一个核心对象A,找出所有A密度可达的样本集合,将这些样本形成一个密度相连的类簇,直到所有的核心对象都遍历完。DBSCAN算法的流程如下图所示:
image-20250607124446432
3. 参数选择与影响
$ $(邻域半径) :
过小:可能导致多数样本被标记为噪声,簇数量增加。
过大:可能导致不同簇合并,簇数量减少。
选择方法 :通过K-Distance图 (排序后的第
$ k $ 近邻距离)观察“拐点”。 $ MinPts $(最小样本数) :
控制簇的最小密度阈值。
通常取 $ d+1 ( d $
为特征维度),避免在高维空间中误判噪声。
层次聚类与AGNES
层次聚类是一种通过构建树状结构(Dendrogram) 将数据划分为不同层次的聚类方法。其核心思想是:凝聚型(Agglomerative) :从每个样本作为一个独立簇开始,逐步合并最相似的簇,直到达到预设的簇数或形成一个唯一簇。分裂型(Divisive) :与凝聚型相反,从整个数据集作为一个簇开始,逐步分裂为更小的簇。
本节重点介绍AGNES(Agglomerative
Nesting) ,一种经典的自底向上的层次聚类算法。
1. AGNES 算法流程
初始化 :每个样本作为一个独立簇。迭代合并 :
终止条件 :
达到预设的簇数 $ k $;
所有簇之间的距离大于阈值。
2. 簇间距离的定义 AGNES
的关键在于如何定义簇间距离 ,常见的三种方法如下:
(1)最小距离(Single Linkage) d min (C i C j x ∈ C i z ∈ C j x , z )含义 :两个簇之间最近的两个样本的距离。
(2)最大距离(Complete Linkage) d max (C i C j x ∈ C i z ∈ C j x , z )含义 :两个簇之间最远的两个样本的距离。
(3)平均距离(Average Linkage) $$
d_{\text{avg}}(C_i, C_j) = \frac{1}{|C_i| |C_j|} \sum_{\boldsymbol{x}
\in C_i} \sum_{\boldsymbol{z} \in C_j} \text{dist}(\boldsymbol{x},
\boldsymbol{z})
$$ - 含义 :两个簇所有样本对距离的平均值。
层次聚类法的算法流程如下所示:
image-20250607125338029
作业
1
假设任务是将下面8个点聚类成3个簇:A1(2,10), A2(2,5), A3(8,4),
B1(5,8), B2(7,5), B3(6,4), C1(1,2),
C3(4,9),距离函数是欧式距离。假设初始选择A1,B1,C1分别作为每个聚类的中心,用Kmeans算法给出计算过程。
image-20250607125506436
image-20250607125606040
2
Kmeans初始类簇中心如何选取?K值如何确定?请简要阐述。
一、初始类簇中心的选取 (如何选好的起始点?)
传统K-means随机选择初始中心点,容易导致结果不稳定(多次运行结果不同)或陷入局部最优(效果差)。改进方法主要有:
K-means++ (最常用且推荐):
核心思想: 让初始中心点彼此尽量远离。步骤:
随机选择第一个 中心点。
计算每个数据点到当前已选中心点 的最短距离(即离最近中心的距离)。
以与这个最短距离平方成正比 的概率,随机选择下一个中心点(距离越大的点,被选中的概率越大)。
重复步骤2和3,直到选出K个中心点。
优点:
显著提高聚类质量和稳定性,计算开销增加不大。 多次运行+选取最优:
独立运行K-means算法多次(每次随机初始化)。
每次运行完成后,计算所有数据点与其所属簇中心的距离平方和(SSE, Sum
of Squared Errors)。
选择SSE最小的那次运行结果作为最终结果。
优点: 简单,增加找到更好解的机会。缺点: 计算开销随运行次数增加。 基于样本密度/距离:
选择数据空间中样本密度高的区域点作为中心。
或选择相互之间距离较远的点作为中心(类似K-means++的思想,但实现方式可能不同)。
二、K值(簇数量)的确定 (如何知道分几类?)
K值通常需要预先指定,但没有绝对正确的答案。常用方法基于评估不同K值下聚类结果的“质量”,寻找拐点或最优值:
肘部法则:
核心思想:
随着K增大,簇内样本聚合更紧密,簇内平方和误差(SSE)会下降,但下降幅度会逐渐变缓。找到SSE下降速率发生显著变化的“肘点”。做法: 计算不同K值(如K=1, 2, 3, …,
max)对应的SSE。绘制K值 - SSE曲线图。观察曲线,寻找SSE下降幅度突然变得平缓的那个K值(形如手臂的“肘关节”)。优点: 直观。缺点:
“肘点”有时不明显或不存在,需要主观判断。 轮廓系数:
核心思想:
综合衡量一个样本与其自身簇的紧密度(a)和与其他簇的分离度(b)。计算: 对于每个样本i:
a(i) = i
到同簇内所有其他点的平均距离(簇内不相似度)。b(i) = i
到所有其他簇 中点的平均距离的最小值(最近邻簇的不相似度)。样本i的轮廓系数:s(i) = (b(i) - a(i)) / max(a(i), b(i))。值在[-1,
1]之间。
整体评估:
计算所有样本轮廓系数的平均值,作为该K值下聚类的整体轮廓系数。选择K:
尝试不同K值,选择平均轮廓系数最大 对应的K值。轮廓系数越接近1,表示聚类效果越好(簇内紧凑,簇间分离)。优点: 量化评估,结果在[-1, 1]之间有界。缺点: 计算量较大,尤其对于大数据集。
参考资料
《机器学习》–
第九章 聚类-腾讯云开发者社区-腾讯云
降维与度量学习
KNN
k近邻算法简称kNN(k-Nearest
Neighbor) ,是一种经典的监督学习方法,是数据挖掘十大算法之一。其工作机制十分简单:给定某个测试样本,kNN基于某种距离度量 在训练集中找出与其距离最近的k个带有真实标记的训练样本,然后基于这k个邻居的真实标记来进行预测,类似于集成学习中的基学习器结合策略:分类任务采用投票法,回归任务则采用平均法。
image-20250607150256290
核心思想
1NN 分类器通过将测试样本 $ $ 分配到其最近邻样本 $ $
的类别来完成预测。其错误概率取决于两个关键因素: - $ $
的真实类别 :$ P(c | ) $,即给定 $ $ 属于类别 $ c $
的概率。$ $ 的类别 :$ P(c | ) $,即 $ $ 属于类别 $ c $
的概率。
错误概率公式
若测试样本 $ $ 的最近邻为 $ ,则 1N N 分 类 器 出 错 的 概 率 为 : $
P() = 1 - P() = 1 - _{c } P(c | ) P(c | ) $$ 其中: - $ $
是所有可能的类别集合。: $ 属于类别 $ c $
的条件概率。: $ 属于类别 $ c $
的条件概率。
通过证明可以发现一个令人震惊的结论:最近邻分类器的错误率不超过贝叶斯最优分类器错误率的两倍 。
对于距离度量,不同的度量方法得到的k个近邻不尽相同,从而对最终的投票结果产生了影响 ,因此选择一个合适的距离度量方法也十分重要。
在上一篇聚类算法中,在度量样本相似性时介绍了常用的几种距离计算方法,包括闵可夫斯基距离,曼哈顿距离,VDM 等。在实际应用中,kNN的距离度量函数一般根据样本的特性来选择合适的距离度量,同时应对数据进行去量纲/归一化处理来消除大量纲属性的强权政治影响 。
低维嵌入
使用knn的前提是样本空间的密度要一定大,但是这个条件在现实中很难满足,因此引出降维操作
kNN的重要假设: 任意测试样本 附近任意小的
距离范围内总能找到一个训练样本,即训练样本的采样密度足够大,或称为
“密采样”( dense sample)
。然而,这个假设在现实任务中通常很难满足
样本的特征数 也称为维数 (dimensionality),当维数非常大时,也就是通常所说的“维数灾难 ”(curse
of
dimensionality),具体表现在:在高维情形下,数据样本变得十分稀疏 ,因为此时要满足训练样本为“密采样 ”的总体样本数目是一个触不可及的天文数字。训练样本的稀疏使得其代表总体分布的能力大大减弱,从而消减了学习器的泛化能力 ;同时当维数很高时,计算距离也变得十分复杂 ,甚至连计算内积都不再容易
缓解维数灾难的一个重要途径就是降维(dimension
reduction),即通过某种数学变换将原始高维空间转变到一个低维的子空间 。在这个子空间中,样本的密度将大幅提高,同时距离计算也变得容易。这
时也许会有疑问,降维之后不是会丢失原始数据的一部分信息吗?
实际上,在很多实际问题中,虽然训练数据是高维的,但是与学习任务相关也许仅仅是其中的一个低维子空间,也称为一个低维嵌入 ,例如:数据属性中存在噪声属性、相似属性或冗余属性等,对高维数据进行降维能在一定程度上达到提炼低维优质属性或降噪的效果 。
MDS算法 MDS(Multidimensional
Scaling,多维尺度分析)是一种经典的降维技术 ,其核心目标是将高维数据映射到低维空间(如二维或三维),同时尽可能保留原始数据中样本点之间的距离关系 。以下是其核心原理与应用要点:
1. 核心思想
输入 :一个样本点之间的距离矩阵 $ D
$(如欧氏距离、余弦距离等)。输出 :低维空间中样本点的坐标矩阵 $ Z
$,使得低维空间中的距离与原始距离尽可能一致 。关键假设 :高维数据的内在结构可通过样本间的距离关系描述,降维后需最小化这种关系的失真。
2. 算法步骤
MDS 的核心是通过矩阵分解 从距离矩阵推导低维坐标: 1.
构建距离矩阵 $ D $ :
双中心化(Double Centering) :
特征值分解 :
构造低维坐标 :Z = Λ 1/2 V ⊤
3. 关键特性
保留距离关系 :MDS
直接优化低维空间中的距离与原始距离的一致性,适用于需精确保留样本相似性的场景(如生物信息学中的基因关系分析)。非线性适应性 :与 PCA 不同,MDS
不要求数据线性分布,更适合处理非线性结构(如环形、流形数据)。灵活性 :支持任意距离度量(如自定义的相似性指标),而
PCA 仅适用于欧氏距离 。
线性降维方法 线性降维通过线性变换 将高维数据 $ ^{d m} $
投影到低维空间 $ ^{d’ m} ( d’ d ),保 留 数 据 的 主 要 信 息 。其 数 学 表 达 为 : $
= ^ $$
变换矩阵 $ ^{d d’} $ :
目标 :选择 $ $ 使得低维表示 $ $
最大化保留原始数据的信息(如方差、距离等)。
MDS :保留高维空间中样本点之间的距离关系 为目标。降维后的低维空间需尽可能保持原始样本两两之间的距离(如欧氏距离、自定义相似性距离)。
示例 :在基因数据分析中,MDS可确保基因表达相似的样本在低维空间中仍紧密分布。 其他线性方法(如PCA、LDA) :
PCA :最大化数据在低维空间的方差,强调保留全局结构而非具体距离。LDA :在监督学习中最大化类间分离度,忽略类内距离。
主成分分析
不同于MDS采用距离保持的方法,主成分分析(Principal Component Analysis
,PCA)是一种经典的无监督降维算法
,其核心目标是通过线性变换将高维数据映射到低维空间,同时保留数据的最大方差信息
(即信息损失最小)
直接通过一个线性变换 ,将原始空间中的样本投影 到新的低维空间中。
简单来理解这一过程便是:PCA采用一组新的基(向量)来表示样本点,其中每一个基向量都是原始空间基向量的线性组合,通过使用尽可能少的新基向量来表出样本,从而达到降维的目的。
image-20250607155733314
假设使用d’个新基向量来表示原来样本,实质上是将样本投影到一个由d’个基向量确定的一个超平面 上(即舍弃了一些维度 ),要用一个超平面对空间中所有高维样本进行恰当的表达,最理想的情形是:若这些样本点都能在超平面上表出且这些表出在超平面上都能够很好地分散开来 。但是一般使用较原空间低一些维度的超平面来做到这两点十分不容易,因此我们退一步海阔天空,要求这个超平面应具有如下两个性质:
最近重构性 :样本点到超平面的距离足够近,即尽可能在超平面附近;
最大可分性 :样本点在超平面上的投影尽可能地分散开来,即投影后的坐标具有区分性。
这里十分神奇的是:最近重构性与最大可分性虽然从不同的出发点来定义优化问题中的目标函数,但最终这两种特性得到了完全相同的优化问题 :
image-20250607165159235
协方差矩阵与优化求解 若数据已中心化 (均值为零),则 $ ^$
是样本协方差矩阵 的 $ m $
倍。此时,PCA的优化问题转化为: $$
\begin{aligned}
& \underset{\mathbf{W}}{\text{maximize}}
& & \text{tr}\left( \mathbf{W}^\top \mathbf{X} \mathbf{X}^\top
\mathbf{W} \right) \\
& \text{subject to}
& & \mathbf{W}^\top \mathbf{W} = \mathbf{I}
\end{aligned}
$$ 通过拉格朗日乘数法,该问题的解为 $ ^$ 的前 $ d’ $
个最大特征值对应的特征向量
PCA的数学推导
优化目标 :maxW W ⊤ X X ⊤ W ) s.t. W ⊤ W = I
其中,$ ^{d m} $ 是中心化后的数据矩阵(均值为零)。
拉格朗日乘数法 :,构 造 拉 格 朗 日 函 数 : $
(, ) = ( ^ ^ ) - ( (^ - ) ) $$
对 $ \mathbf{W} $ 求导并令导数为零,得到:
$$ ^ = $$
即 $ \mathbf{X} \mathbf{X}^\top $ 的特征向量 $ \mathbf{w}_i $ 满足:
$$ ^_i = _i _i $$
PCA特征向量选择
1. 核心问题
在PCA中,我们希望找到一个 $ d’ d $ 的变换矩阵 $
$,其列向量是协方差矩阵 $ ^$ 的特征向量,且满足正交约束 $ ^ =
$。关键问题是:如何从 $ d $ 个特征向量中选择 $ d’ $
个最优的?
2. 数学推导
特征值分解 :X X ⊤ W = W Λ
优化目标转化 :。利 用 特 征 值 分 解 ,可 得 : $
^ ^ = ^( ) = 因 此 ,优 化 目 标 变 为 :{} () = {i=1}^{d’} _i $$ 即选择 $ d’ $ 个最大的特征值 $ _i $
对应的特征向量组成 $ $。
3. 特征向量选择策略
按特征值排序 :正交性保证 :
PCA算法的整个流程如下图所示:
image-20250607170020467
核化线性降维 待学习
流形学习
流形学习(manifold
learning) 是一种借助拓扑流形概念的降维方法,流形是指在局部与欧式空间同胚的空间 ,即在局部与欧式空间具有相同的性质,能用欧氏距离计算样本之间的距离。这样即使高维空间的分布十分复杂,但是在局部上依然满足欧式空间的性质,基于流形学习的降维正是这种
“邻域保持” 的思想。其中
等度量映射(Isomap)试图在降维前后保持邻域内样本之间的距离,而局部线性嵌入(LLE)则是保持邻域内样本之间的线性关系
。
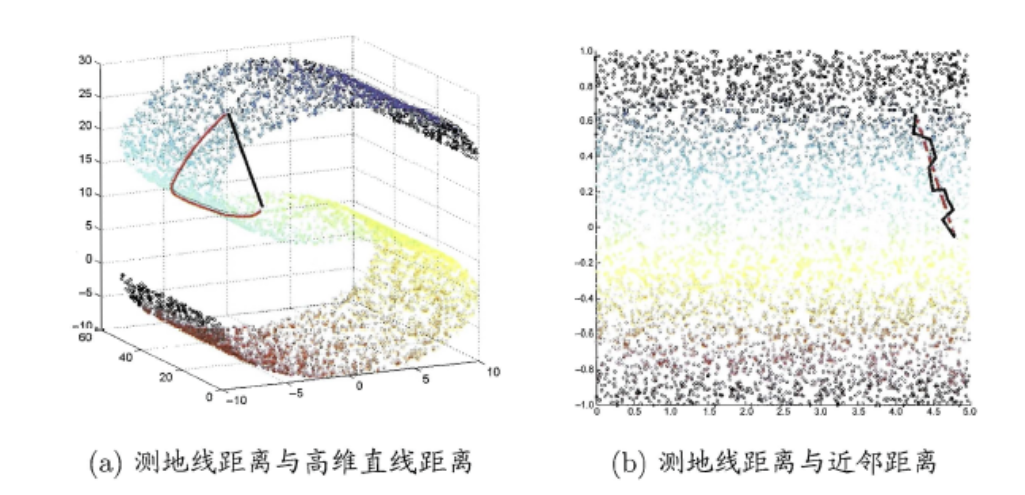
等度量映射Isomap
等度量映射的基本出发点是:高维空间中的直线距离具有误导性,因为有时高维空间中的直线距离在低维空间中是不可达的。因此利用流形在局部上与欧式空间同胚的性质,可以使用近邻距离来逼近测地线距离 ,即对于一个样本点,它与近邻内的样本点之间是可达的,且距离使用欧式距离计算,这样整个样本空间就形成了一张近邻图,高维空间中两个样本之间的距离就转为最短路径问题。可采用著名的Dijkstra算法 或Floyd算法 计算最短距离,得到高维空间中任意两点之间的距离后便可以使用
MDS 算法来其计算低维空间中的坐标。
image-20250607171119645
Isomap算法流程如下图:
image-20250607171258284
对于近邻图的构建,常用的有两种方法:一种是指定近邻点个数 ,像kNN一样选取k个最近的邻居;另一种是指定邻域半径 ,距离小于该阈值的被认为是它的近邻点。但两种方法均会出现下面的问题:
若邻域范围指定过大,则会造成“短路问题” ,即本身距离很远却成了近邻,将距离近的那些样本扼杀在摇篮。
若邻域范围指定过小,则会造成“断路问题” ,即有些样本点无法可达了,整个世界村被划分为互不可达的小部落。
局部线性嵌入
待学习
度量学习
1. 核心思想
度量学习(Metric
Learning)的核心目标是学习一个合理的距离度量 ,使得相似样本距离更近,不相似样本距离更远。传统欧式距离(Euclidean
Distance)虽然简单,但其固定权重无法反映不同特征的实际重要性。因此,我们引入加权欧式距离 ,通过可调节的参数(权重)优化距离计算。
2. 欧式距离与加权欧式距离
标准欧式距离 :$$
\text{dist}_{\text{ed}}^2(\boldsymbol{x}_i, \boldsymbol{x}_j) =
\|\boldsymbol{x}_i - \boldsymbol{x}_j\|_2^2 = \sum_{k=1}^d
(\boldsymbol{x}_{i,k} - \boldsymbol{x}_{j,k})^2
$$
每个特征维度对距离的贡献相同,未考虑特征的重要性差异。
加权欧式距离 :distwed 2 (x i x j x i x j ⊤ W (x i x j
其中,$ = () $ 是对角权重矩阵,$ w_k $ 表示第 $ k $ 个特征的权重。$$
\text{dist}_{\text{wed}}^2(\boldsymbol{x}_i, \boldsymbol{x}_j) =
\sum_{k=1}^d w_k (\boldsymbol{x}_{i,k} - \boldsymbol{x}_{j,k})^2
$$
3. 权重的作用
特征重要性调节 :
高权重 $ w_k $:强调第 $ k $
维特征对距离的影响(如图像的颜色通道比位置更重要)。
低权重 $ w_k $:弱化噪声或冗余特征的影响。
几何意义 :
4. 度量学习的目标
通过学习最优权重 $ ,使 以 下 目 标 成 立 : − * * 相 似 样 本 * *:加 权 距 离 小 (
_{}^2(_i, j) )。 − * * 不 相 似 样 本 * *:加 权 距 离 大 (
{}^2(_i, _j) $)。
典型优化问题形式: minw (x i x j S distwed 2 (x i x j λ ∥w ∥2 2
其中,$ S $ 是相似样本对集合,$ $ 是正则化项防止过拟合。
总结来说,
降维是将原高维空间嵌入到一个合适的低维子空间中,接着在低维空间中进行学习任务 度量学习则是试图去学习出一个 *距离度量*
来等效降维的效果
LMNN(Large
Margin Nearest Neighbors)详解 1. 核心思想
LMNN
是一种监督度量学习方法 ,其目标是通过学习一个线性变换矩阵
$
$,使同类样本在变换后的空间中更紧密 ,不同类样本被推开 ,从而提升KNN等基于距离的算法性能。其核心是引入最大边距(Large
Margin) 的概念,类似于SVM的分类边界。
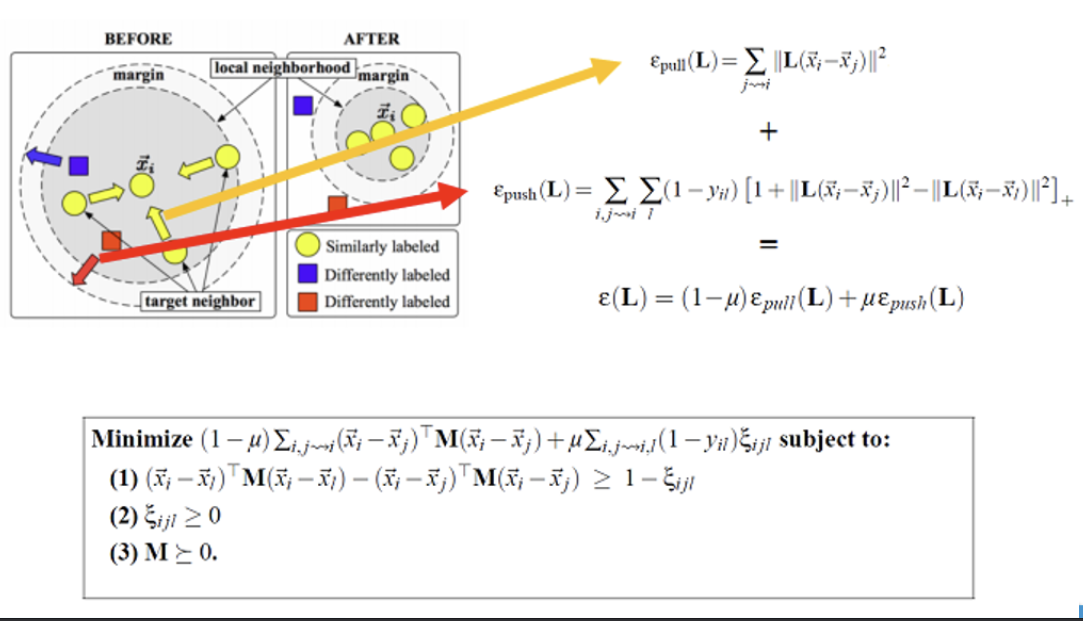
2. 损失函数
LMNN 的优化目标由两部分组成: - Pull
Loss(拉力损失) :$$
\varepsilon_{\text{pull}}(\mathbf{L}) = \sum_{j \sim i}
\|\mathbf{L}(\bar{\boldsymbol{x}}_i - \bar{\boldsymbol{x}}_j)\|^2
$$ 其中,$ j i $ 表示与样本 $ i $ 同类的最近邻样本。
Push Loss(推力损失) :{ijl} ,公 式 为 : $
{}() = {i,j,l} (1 - y {il}) + $$ 其中,$ y {il} = 1
$ 表示样本 $ i $ 和 $ l $ 属于同一类,否则为0;$ []_+ $
表示取正值部分。
总损失函数 :ε (L ) = (1 − μ )ε pull (L ) + μ ε push (L )
3. 优化问题
LMNN 的目标是最小化总损失函数,同时满足以下约束: $$
\begin{aligned}
& \min_{\mathbf{M}, \boldsymbol{\xi}} \quad (1 - \mu) \sum_{i,j \sim
i} (\bar{\boldsymbol{x}}_i - \bar{\boldsymbol{x}}_j)^\top \mathbf{M}
(\bar{\boldsymbol{x}}_i - \bar{\boldsymbol{x}}_j) + \mu \sum_{i,j \sim
i,l} (1 - y_{il}) \xi_{ijl} \\
& \text{s.t.} \quad (\bar{\boldsymbol{x}}_i -
\bar{\boldsymbol{x}}_l)^\top \mathbf{M} (\bar{\boldsymbol{x}}_i -
\bar{\boldsymbol{x}}_l) - (\bar{\boldsymbol{x}}_i -
\bar{\boldsymbol{x}}_j)^\top \mathbf{M} (\bar{\boldsymbol{x}}_i -
\bar{\boldsymbol{x}}_j) \geq 1 - \xi_{ijl}, \\
& \quad \quad \quad \xi_{ijl} \geq 0, \quad \mathbf{M} \succeq 0.
\end{aligned}
$$ -
约束(1) :确保不同类样本对的距离比同类样本对大至少 $ 1
- {ijl} $。约束(2) :松弛变量 $ {ijl} $
允许部分样本对违反约束。约束(3) :$ $
必须是半正定矩阵,保证距离的非负性和三角不等式。
作业
1
数据降维有哪些常用的方法?阐述主成分分析(PCA)算法的计算流程,并讨论PCA
降维之后的维度如何确定?
(1)常用数据降维方法
主成分分析(PCA) :通过线性变换保留最大方差方向,适用于去噪和压缩数据
。线性判别分析(LDA) :在监督学习中最大化类间分离度,适用于分类任务
。
(2)主成分分析(PCA)的计算流程
数据标准化 :对原始数据去均值、方差归一化,消除量纲影响
。计算协方差矩阵 :$$
\mathbf{\Sigma} = \frac{1}{m} \mathbf{X} \mathbf{X}^\top
$$ 其中 $ $ 是中心化后的数据矩阵 。特征值分解 :对协方差矩阵进行特征值分解,得到特征值
$ _i $ 和单位正交特征向量 $ _i $ 。选择主成分 :按特征值大小排序,选择前 $ d’ $
个最大特征值对应的特征向量构成变换矩阵 $ = [_1, 2, , {d’}]
$。降维投影 :计算低维表示 $ = ^ $,其中 $ ^{d’ m} $
。
(3)PCA降维后维度的确定
累积方差贡献率 :选择前 $ d’ $
个主成分,使累计方差占比达到阈值(如95%)。肘部法则(Elbow
Method) :绘制特征值随维度变化的曲线,选择“拐点”作为 $ d’
$。
2
度量学习的目标是什么?LMNN算法中三元组损失是什么?如何计算?
(1)度量学习的目标
度量学习旨在学习一个合理的距离度量,使得: -
相似样本 :距离尽可能小(如同类样本)。不相似样本 :距离尽可能大(如异类样本)。
(2)LMNN中的三元组损失
LMNN(Large Margin Nearest
Neighbor)是一种监督度量学习方法,其核心思想是通过优化距离度量来提升KNN的分类性能。虽然LMNN本身主要使用对比损失(Contrastive
Loss),但三元组损失(Triplet
Loss)是深度度量学习中常见的损失函数,其计算方式如下:三元组损失的定义
三元组损失基于锚点(Anchor)、正例(Positive)和负例(Negative)三个样本,目标是使锚点与正例的距离小于锚点与负例的距离,公式为:
ℒ = ∑i , j , l z i z j 2 −∥z i z l 2 + m )
- $ _i $:锚点样本的嵌入表示。
LMNN的损失函数
LMNN 的损失函数包含两部分: 1. 拉力损失(Pull
Loss) :最小化同类样本对的距离:$$
\varepsilon_{\text{pull}} = \sum_{i,j \sim i}
\|\mathbf{L}(\bar{\boldsymbol{x}}_i - \bar{\boldsymbol{x}}_j)\|^2
$$ 2. 推力损失(Push
Loss) :最大化异类样本对的距离:$$
\varepsilon_{\text{push}} = \sum_{i,j \sim i,l} (1 - y_{il}) \left[1
+ \|\mathbf{L}(\bar{\boldsymbol{x}}_i - \bar{\boldsymbol{x}}_j)\|^2 -
\|\mathbf{L}(\bar{\boldsymbol{x}}_i -
\bar{\boldsymbol{x}}_l)\|^2\right]_+
$$ 其中 $ $ 是线性变换矩阵,$ y_{il} $ 表示样本对是否同类,$
[]_+ $ 表示取正值部分 。
优化目标
LMNN 的总损失为拉力和推力损失的加权和: ε (L ) = (1 − μ )ε pull + μ ε push
image-20250607175825520
半监督学习
监督学习解决现实问题有哪些难点?
1.标记数据获取成本高:在许多领域如医疗,获取标记数据是昂贵且耗时的。
2.未标记数据大量存在且易得:相对而言,未标记数据大量存在且容易获取。
3.提升模型的泛化能力:通过利用未标记数据,可以增强模型的泛化能力。
举例:在医疗领域,获取医生标记的诊断数据非常昂贵,但有大量未标记的病人记录。
半监督学习可以帮助利用这些未标记数据,提高疾病预测模型的准确性。
少量的标记数据 和大量的未标记数据 来训练模型,主要目标是提升模型在未标记数据上的表现。
基于生成模型的方法
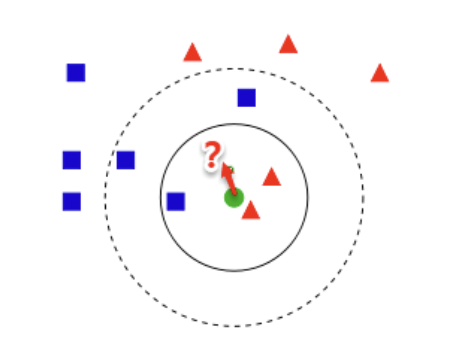
假设所有数据(无论是否有标记)都是由一个潜在的模型 “生成”的。那么无标记的数据可以帮助更准确的估计潜在模型的参数。
比如右图中可以看到数据可以由两个高斯分布近似,则无监督的数据可以被用来更好得做高斯分布的参数估计
image-20250607183201926
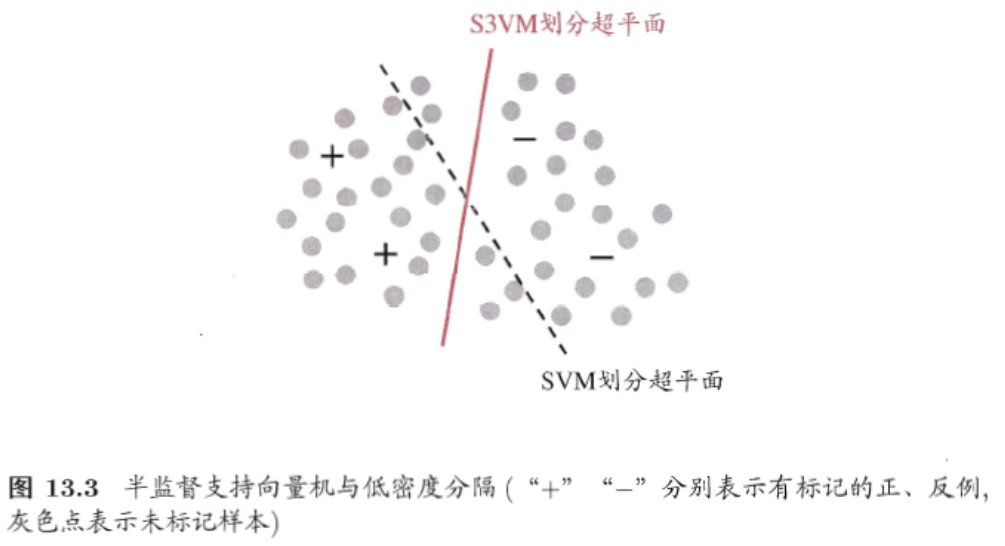
半监督SVM 监督学习中的SVM试图找到一个划分超平面,使得两侧支持向量之间的间隔最大,即
最大划分间隔 思想。对于半监督SVM (Semi-Supervised
Support Vector Machine, S3VM)
则考虑超平面在能将两类标记样本分隔的同时,穿过数据低密度的区域 。
image-20250607183349866
TSVM(Transductive
Support Vector Machine)
1. 核心思想
TSVM 是一种半监督学习方法 ,通过结合有标记数据 $ D_l
$ 和未标记数据 $ D_u
$,利用伪标签(Pseudo-labels)和迭代优化策略,最大化分类超平面的间隔。其损失函数需同时考虑:
- 有标记样本 :最小化分类错误(Hinge Loss)。未标记样本 :通过伪标签引入约束,逐步调整超平面。
2. 损失函数推导
TSVM 的目标是找到一个超平面 $ ^ + b = 0 $,使得: 1.
有标记样本 的分类误差最小。未标记样本 的伪标签与超平面预测结果一致。
标准SVM的损失函数 为: $$
\min_{\boldsymbol{w}, b, \xi} \quad \frac{1}{2} \|\boldsymbol{w}\|^2 + C
\sum_{i=1}^l \xi_i
$$ 其中,$ _i $ 是松弛变量,表示样本 $ (_i, y_i) $
的分类误差。
TSVM的扩展 :j ( j = l+1, , l+u $),并赋予其较小的惩罚系数
$ C_u $(初始阶段 $ C_u C_l ): $
{, b, } ||^2 + C_l _{i=1}^l i + C_u {j=l+1}^{l+u} _j $$
其中: - $ C_l $:有标记样本的惩罚系数。
3. 迭代优化流程
初始化 :
用有标记数据 $ D_l $ 训练初始 SVM,得到 $ _0, b_0 $。
对未标记数据 $ D_u $ 预测伪标签 $ _j = (_0^_j + b_0) $。
伪标签调整 :
若存在冲突(如 $ _i _j < 0 $ 且 $ _i + _j > 2
$),翻转其中一个伪标签(如 $ _i -_i $)。
重新求解优化问题,更新 $ , b $。
参数调整 :
逐步增大 $ C_u $(如 $ C_u {2C_u, C_l}
$),增强未标记样本的影响。
4. 关键数学细节
Hinge Loss :,损 失 为 : $ _i =
(0, 1 - y_i (^_i + b)) $$ 未标记样本的伪标签 $ _j $
同样代入此公式,但惩罚系数为 $ C_u $。
正则化项 :
伪标签翻转条件 :ŷ i ŷ j ξ i ξ j ξ i ξ j
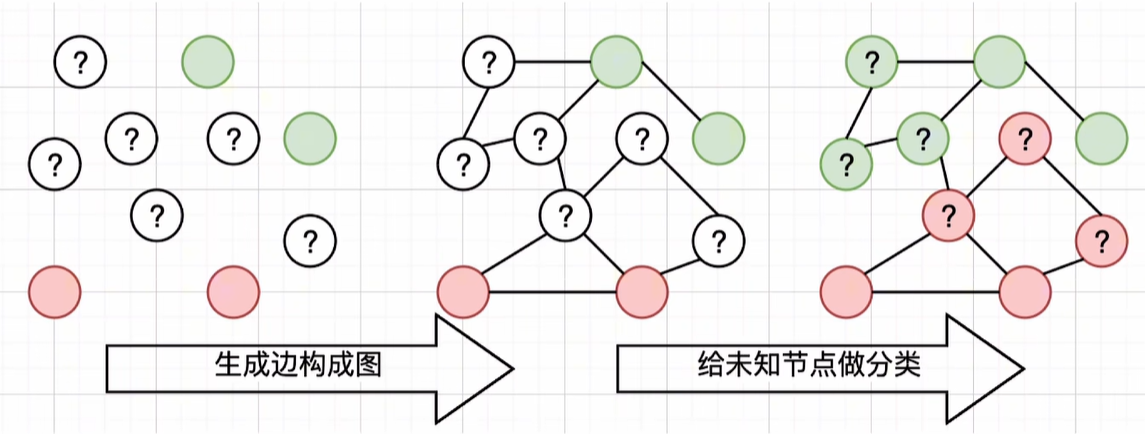
图半监督学习 给定一个数据集,我们可将其映射为一个图,数据集中每个样本对应于图结点,若两个样本之间的相似度很高(或相关性很强),则对应的结点之间存在一条边,边的“强度”(strength)
正比于样本之间的相似度(或相关性)。
可将有标记样本所对应的结点想象为染过色,标记样本所对应的结点尚未染色。半监督学习就对应于“颜色”在图上扩散或传播的过程。由于个图对应了一个矩阵,我们就能基于矩阵运算来进行半监督学习算法的推导与分析。
image-20250607184534217
图半监督学习中的能量函数推导详解
1. 图结构与亲和矩阵
给定有标记数据集 $ D_l = {(1, y_1), (2, y_2), , (l, y_l)}
$ 和未标记数据集 $ D_u = { {l+1}, {l+2}, , {l+u}}
$,构建图 $ G = (V, E) : − * * 结 点 集 * *:
V = {1, , l, {l+1}, , {l+u}} $,包含所有样本。边集 :通过亲和矩阵 $ $ 表示,元素定义为: $$
(\mathbf{W})_{ij} =
\begin{cases}
\exp\left(-\frac{\|\boldsymbol{x}_i -
\boldsymbol{x}_j\|^2}{2\sigma^2}\right), & i \neq j \\
0, & \text{otherwise}
\end{cases}
$$ 其中,$ $ 是高斯核的带宽参数,控制邻接关系的敏感性。
2. 能量函数的定义与推导
假设分类模型的输出标记为 $ f(_i) $(取值为类别标签,如 $
$),定义能量函数 $ E(f) $ 为: $$
E(f) = \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^m (\mathbf{W})_{ij}
(f(\boldsymbol{x}_i) - f(\boldsymbol{x}_j))^2
$$ 其中 $ m = l + u $ 是总样本数。
3. 能量函数的展开与简化
展开平方项 $$
E(f) = \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^m (\mathbf{W})_{ij} \left[
f^2(\boldsymbol{x}_i) - 2 f(\boldsymbol{x}_i) f(\boldsymbol{x}_j) +
f^2(\boldsymbol{x}_j) \right]
$$ 利用对称性简化 由于 $ $ 是对称矩阵((W )i j W )j i ),可交换求和顺序:
$$
\sum_{i=1}^m \sum_{j=1}^m (\mathbf{W})_{ij} f^2(\boldsymbol{x}_j) =
\sum_{j=1}^m \sum_{i=1}^m (\mathbf{W})_{ji} f^2(\boldsymbol{x}_j) =
\sum_{i=1}^m \sum_{j=1}^m (\mathbf{W})_{ij} f^2(\boldsymbol{x}_i)
$$ 因此,能量函数变为 $$
E(f) = \frac{1}{2} \left( 2 \sum_{i=1}^m \sum_{j=1}^m (\mathbf{W})_{ij}
f^2(\boldsymbol{x}_i) - 2 \sum_{i=1}^m \sum_{j=1}^m (\mathbf{W})_{ij}
f(\boldsymbol{x}_i) f(\boldsymbol{x}_j) \right)
$$ 引入度矩阵 定义度矩阵 $ $
为对角矩阵,其对角线元素为: $$
d_i = \sum_{j=1}^m (\mathbf{W})_{ij}
$$ 最终能量函数可表示为: $$
E(f) = \sum_{i=1}^m d_i f^2(\boldsymbol{x}_i) - \sum_{i=1}^m
\sum_{j=1}^m (\mathbf{W})_{ij} f(\boldsymbol{x}_i) f(\boldsymbol{x}_j) =
\boldsymbol{f}^\top (\mathbf{D} - \mathbf{W}) \boldsymbol{f}
$$ 其中,$ = [f(_1), f(_2), , f(_m)]^$。
图半监督学习方法推导详解
1. 分块矩阵表示
将亲和矩阵 $ $ 和度矩阵 $ $ 按有标记数据(前 $ l $
行列)和未标记数据(后 $ u $ 行列)分块: $$
\mathbf{W} =
\begin{bmatrix}
\mathbf{W}_{ll} & \mathbf{W}_{lu} \\
\mathbf{W}_{ul} & \mathbf{W}_{uu}
\end{bmatrix}, \quad
\mathbf{D} =
\begin{bmatrix}
\mathbf{D}_{ll} & \mathbf{0}_{lu} \\
\mathbf{0}_{ul} & \mathbf{D}_{uu}
\end{bmatrix}
$$ 其中: - $ {ll} $:有标记数据间的亲和度。 {lu} $:有标记与未标记数据间的亲和度。{uu} $:未标记数据间的亲和度。 {ll}, _{uu} $:对应子图的度矩阵。
2. 能量函数的分块展开
能量函数 $ E(f) = ^( - ) $ 可展开为
展开后得到: E (f ) = f l ⊤ (D l l W l l f l f u ⊤ W u l f l f u ⊤ (D u u W u u f u
**3. 对未标记数据 $ _u $ 求偏微分**
目标是最小化 $ E(f) $,对 $ _u $ 求偏导并令其为零: $$
\frac{\partial E(f)}{\partial \boldsymbol{f}_u} = -2 \mathbf{W}_{ul}
\boldsymbol{f}_l + 2 (\mathbf{D}_{uu} - \mathbf{W}_{uu})
\boldsymbol{f}_u = 0
$$ 解得: f u D u u W u u −1 W u l f l
协同训练
协同训练(Co-training)是一种经典的半监督学习方法 ,由Blum和Mitchell于1998年首次提出,主要用于处理多视图数据 (Multi-view
Data)。其核心思想是通过多个分类器的协作,利用少量标记数据和大量未标记数据提升模型性能。以下是详细解析:
1. 核心思想与假设
(1)多视图数据
定义 :每个样本可被划分为多个充分冗余且条件独立 的视图(View)。
充分冗余 :每个视图本身包含足够信息,可独立完成学习任务。条件独立性 :在给定类别标签的条件下,不同视图的特征相互独立。
(2)协作机制
双分类器设计 :使用两个分类器 $ h_1 $ 和 $ h_2
$,分别基于视图 $ V_1 $ 和 $ V_2 $ 进行训练。伪标签生成 :分类器 $ h_1 $
对未标记数据的高置信度预测结果会被 $ h_2 $
使用,反之亦然,形成迭代优化。目标 :通过分类器间的互补性,逐步扩展标记数据集,提升模型泛化能力。
2. 算法流程
初始化阶段 :
使用少量标记数据 $ D_l $,分别训练分类器 $ h_1 $(基于视图 $ V_1
$)和 $ h_2 $(基于视图 $ V_2 $)。
伪标签生成 :
对未标记数据 $ D_u , h_1 $
预测视图 $ V_1 $ 的伪标签,$ h_2 $ 预测视图 $ V_2 $ 的伪标签。
选择置信度高于阈值的样本加入训练集(如 $ h_1 $ 的预测结果用于更新 $
h_2 $ 的训练数据,反之亦然)。
迭代优化 :
重复伪标签生成和模型训练,直到未标记数据耗尽或模型收敛。
3. 核心优势
减少对标注数据的依赖 :仅需少量标记数据即可训练高性能模型,尤其适合标注成本高的场景(如医疗影像分析)。提升模型鲁棒性 :分类器间的协作可纠正彼此的错误,降低单一模型过拟合风险。多视图互补性 :不同视图的信息融合能捕捉更全面的特征(如图像的RGB通道与纹理特征)。
作业
1
什么是半监督学习?请简要描述其基本思想。半监督学习相比于监督学习和无监督学习有什么优势和应用场景?
(1)定义与基本思想
半监督学习(Semi-Supervised
Learning)是结合监督学习 (利用标记数据)和无监督学习 (利用未标记数据)的机器学习方法,其核心思想是通过少量标记数据与大量未标记数据的联合训练,提升模型的泛化能力和鲁棒性。监督学习 :依赖大量人工标注数据(如分类、回归)。无监督学习 :仅利用数据分布规律(如聚类、降维)。半监督学习 :在标记数据稀缺时,通过未标记数据挖掘潜在结构,降低标注成本
。
(2)优势
减少标注依赖 :仅需少量标记数据即可训练高性能模型,适用于标注成本高的场景(如医疗影像分析)。提升模型性能 :利用未标记数据增强数据多样性,缓解过拟合风险。平衡效率与精度 :在资源有限时,兼顾监督学习的准确性与无监督学习的高效性
。
(3)应用场景
医学诊断 :利用少量标注的病理图像和大量未标注数据训练疾病预测模型。推荐系统 :结合用户行为(有标记)与商品属性(未标记)优化排序模型。自然语言处理 :通过预训练模型(如GPT)的“预训练+微调”框架,减少人工标注需求
。
2
协同训练算法的作用是什么?请简述算法主要流程和所需条件。
(1)作用与核心思想
协同训练是一种典型的半监督学习方法,适用于多视图数据 (Multi-view
Data)。其核心思想是通过多个分类器的协作,利用未标记数据扩展训练集,最终提升模型性能。
多视图条件 :
充分冗余 :每个视图本身包含足够信息,可独立完成任务。条件独立性 :在给定类别标签的条件下,不同视图的特征相互独立
。
(2)算法流程
初始化阶段 :
使用少量标记数据 $ D_l $,分别训练两个分类器 $ h_1 $(基于视图 $ V_1
$)和 $ h_2 $(基于视图 $ V_2 $)。
伪标签生成 :
对未标记数据 $ D_u , h_1 $ 预测 $
V_2 $ 的伪标签,$ h_2 $ 预测 $ V_1 $ 的伪标签。
选择置信度高于阈值的样本加入训练集(如 $ h_1 $ 的预测结果用于更新 $
h_2 $ 的训练数据,反之亦然)。
迭代优化 :
重复伪标签生成和模型训练,直到未标记数据耗尽或模型收敛 。
(3)所需条件
多视图划分 :数据需满足“充分冗余”和“条件独立性”(如图像的RGB通道与纹理特征)。分类器多样性 :选择差异较大的分类器(如SVM +
决策树),增强互补性。伪标签可靠性 :初始模型需有一定性能,避免错误伪标签污染训练集
。








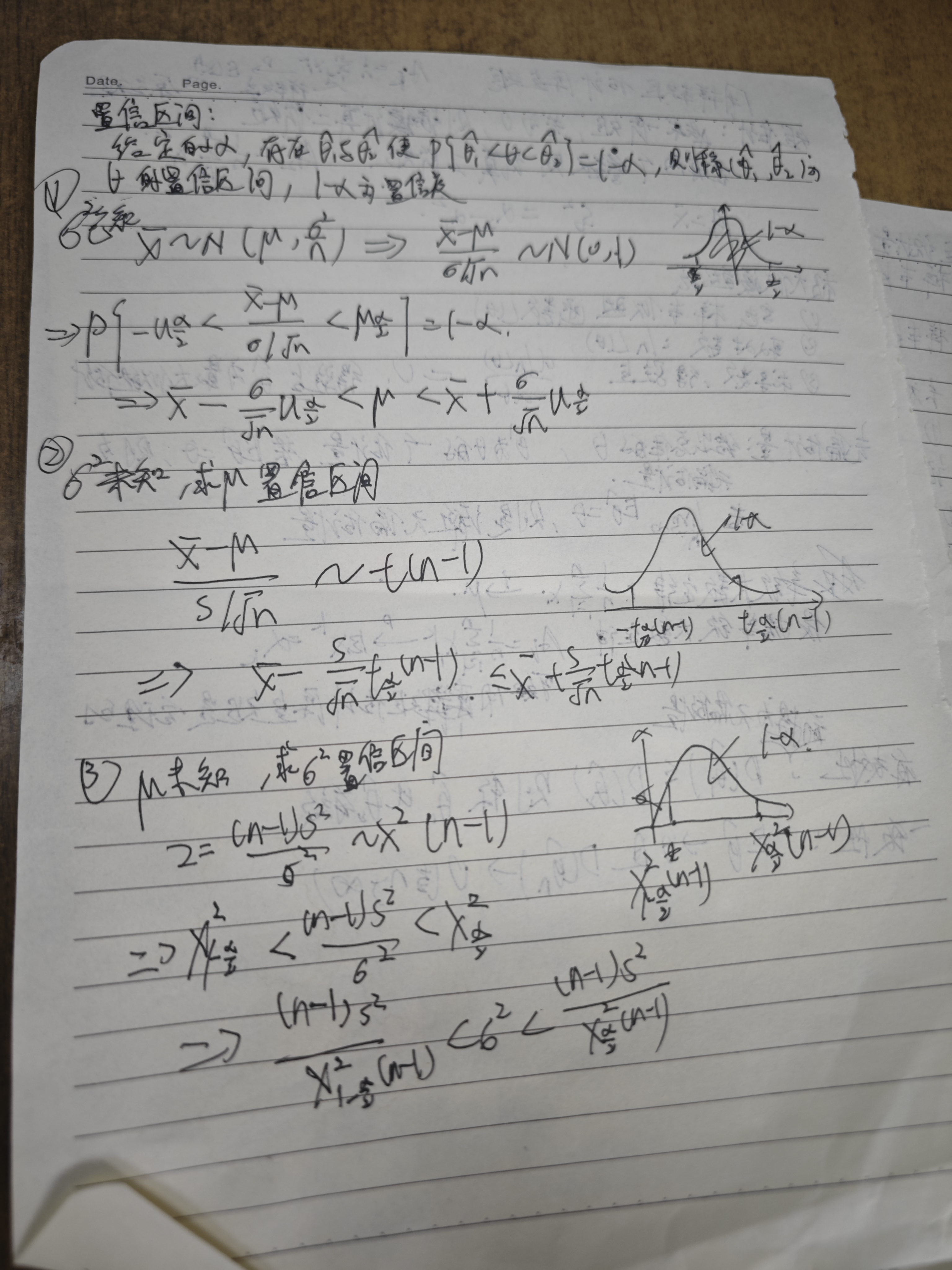






















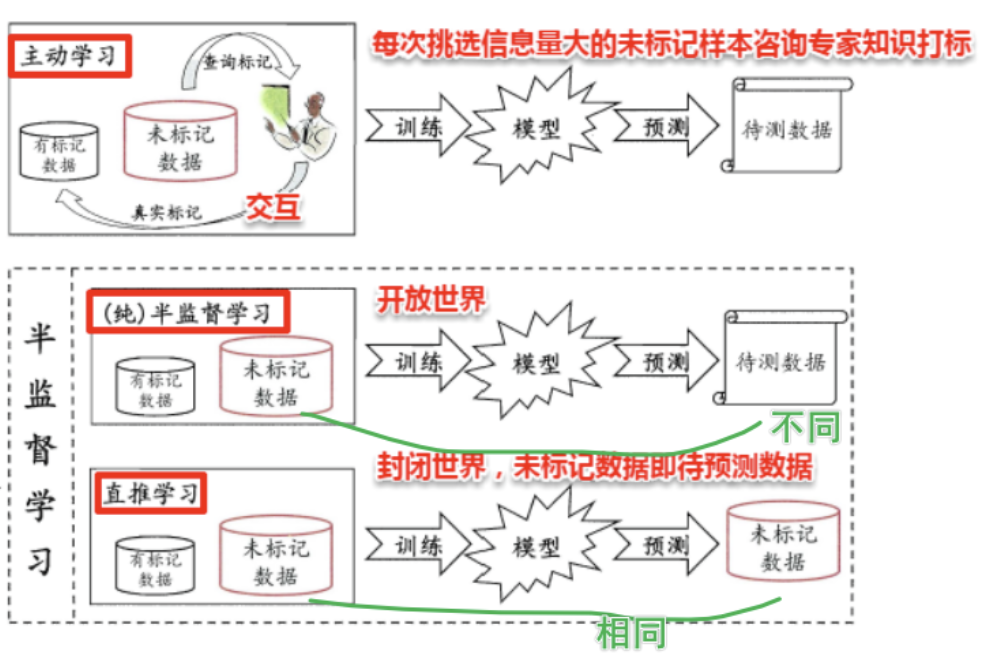 半监督学习结合了有监督学习和无监督学习,半监督学习使用少量的标记数据和大量的未标记数据来训练模型,主要目标是提升模型在未标记数据上的表现。
半监督学习结合了有监督学习和无监督学习,半监督学习使用少量的标记数据和大量的未标记数据来训练模型,主要目标是提升模型在未标记数据上的表现。