前言 代码仓库zxj-2023/learn_fastapi
FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架,使用 Python 并基于标准的 Python 类型提示。
关键特性:
快速 :可与 NodeJS 和 Go 并肩的极高性能(归功于 Starlette 和 Pydantic)。最快的 Python web 框架之一 。高效编码 :提高功能开发速度约 200% 至 300%。*更少 bug :减少约 40% 的人为(开发者)导致错误。*智能 :极佳的编辑器支持。处处皆可自动补全,减少调试时间。简单 :设计的易于使用和学习,阅读文档的时间更短。简短 :使代码重复最小化。通过不同的参数声明实现丰富功能。bug 更少。健壮 :生产可用级别的代码。还有自动生成的交互式文档。标准化 :基于(并完全兼容)API 的相关开放标准:OpenAPI (以前被称为 Swagger) 和 JSON Schema 。
两个核心组件:Starlette 和 Pydantic Starlette 负责web部分
Starlette 是 FastAPI 的底层 ASGI(异步服务器网关接口)框架,为 FastAPI 提供了异步编程能力和高性能的网络通信支持。
ASGI(Asynchronous Server Gateway Interface )是一种用于连接 Python Web 服务器和应用程序框架的异步接口标准 ,旨在支持现代 Web 协议(如 WebSocket、HTTP/2)和异步编程模型
Pydantic负责
Pydantic 负责 FastAPI 的数据验证、序列化和自动文档生成
http协议 一、简介 HTTP协议 是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW: World Wide Web)服务器与本地浏览器之间传输超文本的传送协议。HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
二、http协议特性 (1)基于 TCP/IP 协议
http 协议是基于 TCP/IP 协议 之上的应用层协议。
(2)基于请求 - 响应模式
HTTP 协议规定,请求从客户端发出,最后服务器端响应应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应 。
(3)无状态保存
HTTP 是一种不保存状态,即无状态(stateless)协议。HTTP 协议自身不对请求和响应之间的通信状态进行保存。也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理。
使用 HTTP 协议,每当有新的请求发送时,就会有对应的新响应产生。协议本身并不保留之前一切的请求或响应报文的信息 。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把 HTTP 协议设计成如此简单的。
(4)短连接
HTTP 1.0 默认使用的是短连接。浏览器和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。
HTTP 1.1 起,默认使用长连接。要使用长连接,客户端和服务器的 HTTP 首部的 Connection 都要设置为 keep - alive,才能支持长连接。
HTTP 长连接,指的是复用 TCP 连接。多个 HTTP 请求可以复用同一个 TCP 连接,这就节省了 TCP 连接建立和断开的消耗。
三、http请求协议与响应协议
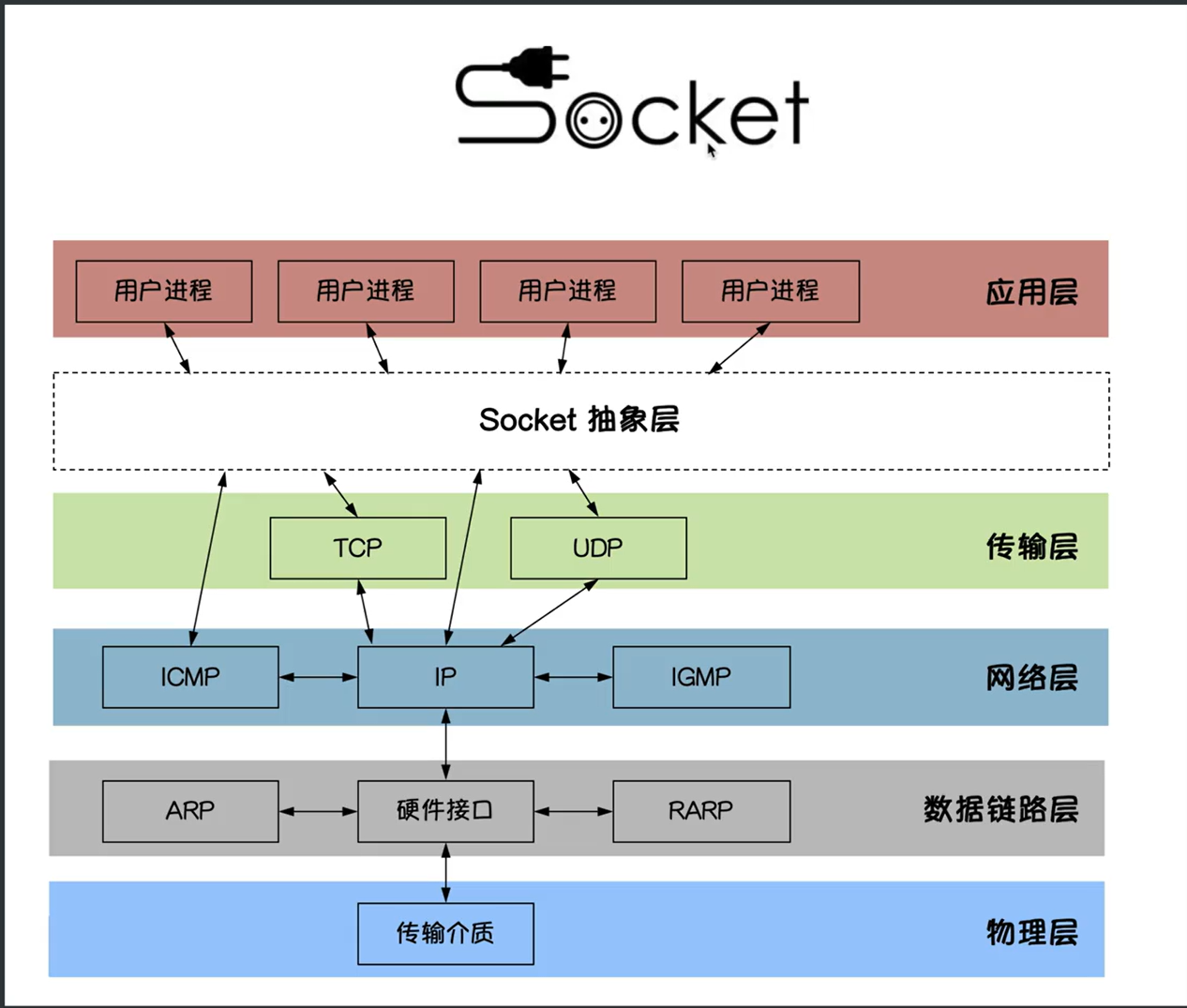
Socket(套接字)是计算机网络中用于实现进程间双向通信的端点抽象,它为应用层进程通过网络协议交换数据提供了统一的接口。具体来说,Socket 是应用层与 TCP/IP 协议族通信的中间软件抽象层,本质上是一组封装了复杂网络协议的接口,简化了开发者对底层通信细节的操作。
从功能上看,Socket 可以看作是网络通信的“电话插座”:两个设备(如客户端与服务器)通过 Socket 建立连接后,即可像电话通话一样进行数据交换,而端口号则类似于插座上的插孔,用于标识具体的通信进程,且不能被其他进程占用。此外,Socket 包含网络通信必需的五种核心信息,例如使用的协议(TCP/UDP)、本地与远程地址、端口等,构成了网络通信的基本操作单元。
总结而言,Socket 既是通信端点的逻辑概念,也是实现网络应用层交互的关键工具,其设计目标是屏蔽底层协议的复杂性,提供统一的编程接口。
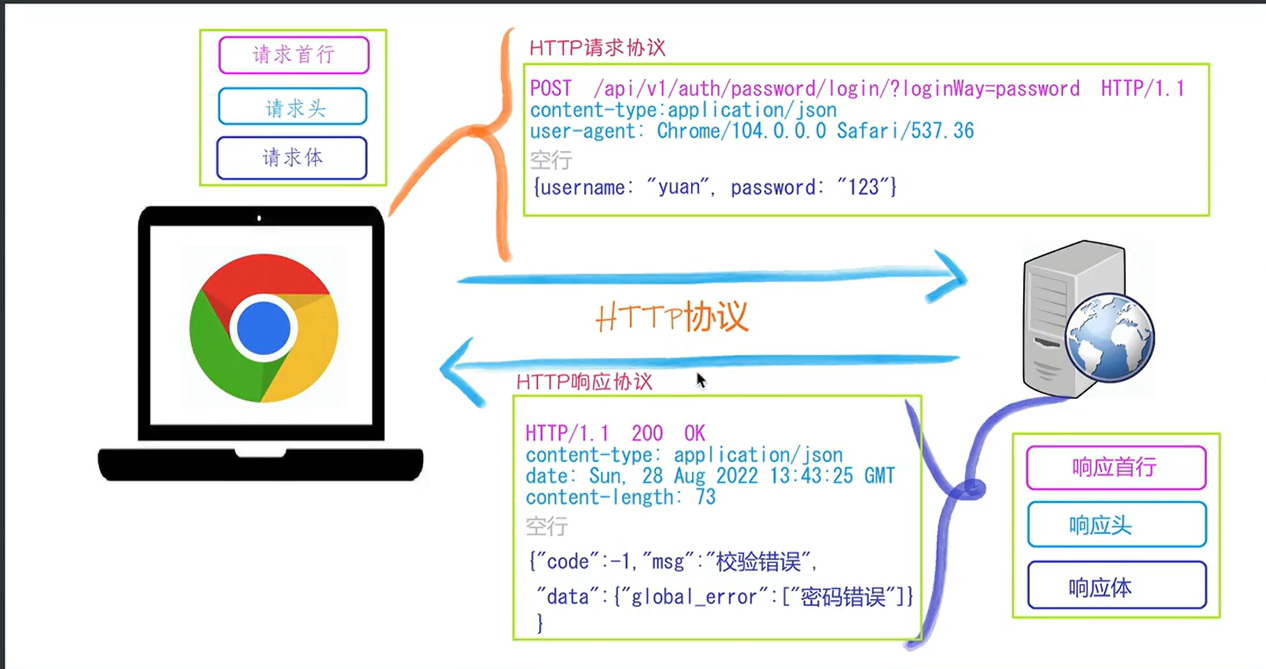
GET :请求参数通过 URL 的查询字符串(Query String)传递,数据暴露在地址栏中,例如:https://example.com ?name=value
POST :请求参数存储在请求体(Body)中传输,相对更安全,且支持传输非字符串数据(如文件、二进制等)
一个完整的URL包括:协议、ip、端口、路径、参数
例如:https://www.baidu.com/s?wd=yuan 其中https是协议,www.baidu.com 是IP,端口默认80,/s是路径,参数是wd=yuan
请求方式:get与post请求
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456。POST方法是把提交的数据放在HTTP包的请求体中。
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制
响应状态码:状态码的职责是当客户端向服务器端发送请求时,返回的请求结果。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了问题。状态码如200 OK,以3位数字和原因组成。
测试http协议格式:请求与响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import socketsock=socket.socket() sock.bind(("127.0.0.1" ,8080 )) sock.listen(5 ) while True : ''' conn 表示新建立的套接字对象,用于在服务器和客户端之间进行数据传输。 addr 是一个元组,它包含了连接进来的客户端的 IP 地址和端口号。 ''' conn, addr = sock.accept() data=conn.recv(1024 ) print ("客户端发送的请求信息:\n" ,data) conn.send(b"HTTP/1.1 200 ok\r\nserver:zxj\r\n\r\nhello world" ) conn.close()
测试post请求:urlencoded格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import socketclient = socket.socket(socket.AF_INET, socket.SOCK_STREAM) client.connect(("127.0.0.1" , 8080 )) path = "/" headers = { "Host" : "127.0.0.1" , "Content-Type" : "application/x-www-form-urlencoded" , "Content-Length" : len ("username=admin&password=123456" ) } body = "username=admin&password=123456" request = f"POST {path} HTTP/1.1\r\n" for k, v in headers.items(): request += f"{k} : {v} \r\n" request += "\r\n" request += body client.send(request.encode('utf-8' )) response = client.recv(4096 ) print (response.decode('utf-8' ))client.close()
测试post请求:json格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import requestsimport jsonurl = "http://127.0.0.1:8080" data = { "username" : "admin" , "password" : "123456" } response = requests.post( url, json=data ) print ("状态码:" , response.status_code)print ("响应内容:" , response.text) ''' 客户端发送的请求信息: b'POST / HTTP/1.1\r\nHost: 127.0.0.1:8080\r\nUser-Agent: python-requests/2.32.2\r\nAccept-Encoding: gzip, deflate\r\nAccept: */*\r\nConnection: keep-alive\r\nContent-Length: 43\r\nContent-Type: application/json\r\n\r\n{"username": "admin", "password": "123456"}' '''
通过 json=data 参数,requests 会自动将字典转换为 JSON 字符串,并设置请求头 Content-Type: application/json,无需手动调用 json.dumps() 或配置 headers
SSL 验证是指通过 SSL 证书验证网站身份并确保通信安全的过程。其核心目标是确认服务器的真实性、防止身份伪造,并建立加密连接以保护数据传输的安全性
HTTPS(HyperText Transfer Protocol Secure)是以安全为目标的 HTTP 通道,通过在 HTTP 基础上加入加密和身份认证机制,确保数据传输的隐私性、完整性和服务器身份的真实性
https=http+ssl
通过 Content-Type,服务器可识别请求体(Body)的格式(如 JSON、表单数据),客户端可解析响应数据的类型(如 HTML、图片)
例如:conn.send(b”HTTP/1.1 200 ok\r\nserver:zxj\r\ncontent-type:text/html \r\n\r\n
hello world<\h1>”)
再例如:‘HTTP/1.1 200 ok\r\nserver:zxj\r\ncontent-type:application/json \r\n\r\n{“user_id”:zxj}’
api接口 在开发web应用中,有两种应用模式:
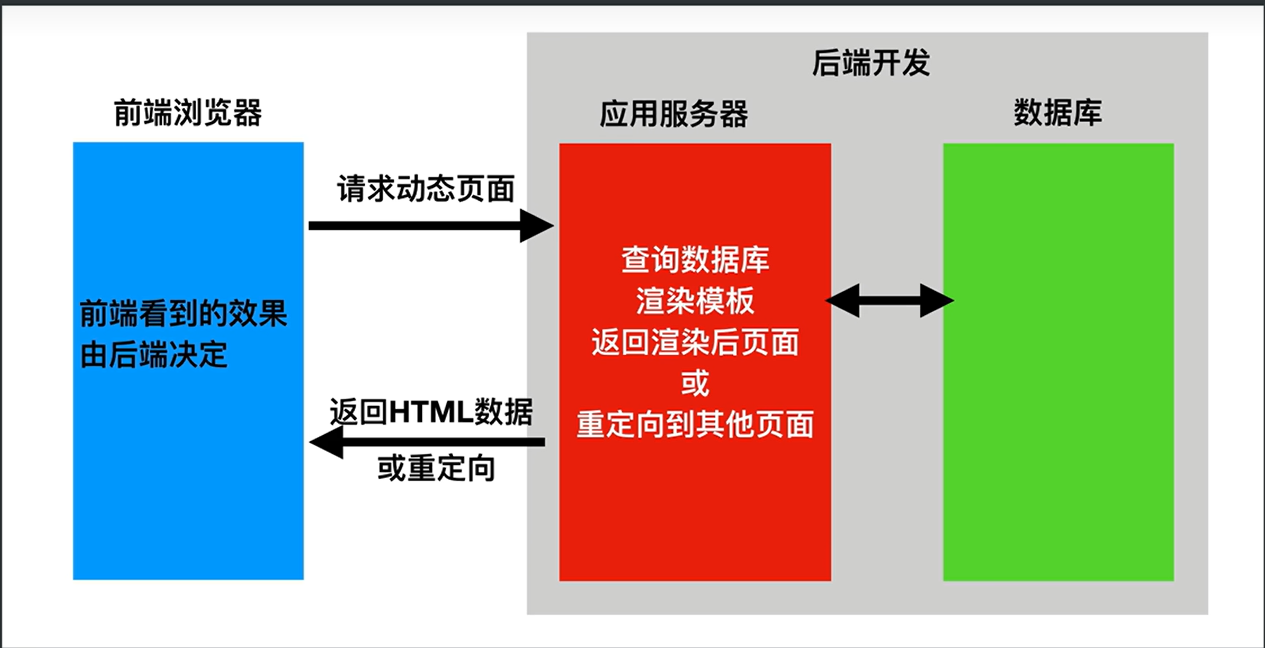
1.前后端不分离:客户端看到的内容和所有页面效果都是有服务端提供出来的
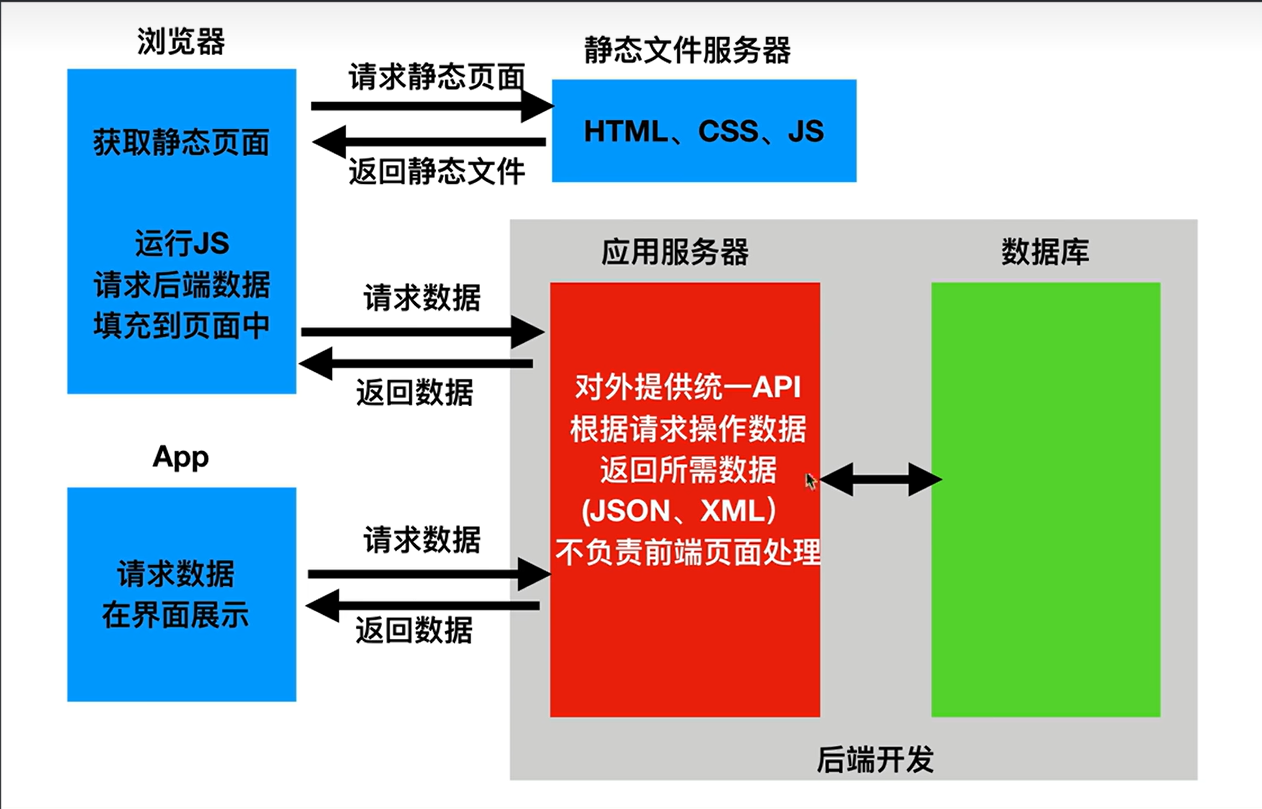
2.前后端分离:把前端的页面效果(html,css,js分离到另一个服务端,python服务端只需要返回数据即可)
前端形成一个独立的网站,服务端构成一个独立的网站
应用程序编程接口(Application Programming Interface,API接口) ,就是应用程序对外提供了一个操作数据的入口,这个入口可以是一个函数或类方法,也可以是一个url地址或者一个网络地址。当客户端调用这个入口,应用程序则会执行对应代码操作,给客户端完成相对应的功能。
当然,api接口在工作中是比较常见的开发内容,有时候,我们会调用其他人编写的api接口,有时候,我们也需要提供api接口给其他人操作。由此就会带来一个问题,api接口往往都是一个函数、类方法、或者url或其他网络地址,不断是哪一种,当api接口编写过程中,我们都要考虑一个问题就是这个接口应该怎么编写?接口怎么写的更加容易维护和清晰,这就需要大家在调用或者编写api接口的时候要有一个明确的编写规范!!!
为了在团队内部形成共识,防止个人习惯差异引起的混乱,我们都需要找到一种大家都觉得很好的接口实现规范,而且这种规范能够让后端写的接口,用途一目了然,减少客户端和服务端双方之间的合作成本。
目前市面上大部分公司开发人员使用的接口实现规范主要有:restful、RPC。
REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移。它首次出现在2000年Roy Fielding的博士论文中。
RESTful是一种专门为Web开发而定义API接口的设计风格,尤其适用于前后端分离的应用模式中。
关键:面向资源开发
这种风格的理念认为后端开发任务就是提供数据的,对外提供的是数据资源的访问接口,所以在定义接口时,客户端访问的URL路径就表示这种要操作的数据资源。
而对于数据资源分别使用POST、DELETE、GET、UPDATE等请求动作来表达对数据的增删查改 。
请求方法
请求地址
后端操作
POST
/student/
增加学生
GET
/student/
获取所有学生
GET
/student/1
获取id为1的学生
PUT
/student/1
修改id为1的学生
DELETE
/student/1
删除id为1的学生
restful规范是一种通用的规范,不限制语言和开发框架的使用。事实上,我们可以使用任何一门语言,任何一个框架都可以实现符合restful规范的API接口。
fastapi快速开始 简单案例 安装:pip install fastapi
还需要一个ASGI服务器,生产环境使用Uvicorn:pip install uvicorn
ASGI(Asynchronous Server Gateway Interface )是一种异步服务器网关接口 ,为 Python Web 应用提供了标准接口,使其能够处理现代网络协议(如 WebSocket、HTTP/2 等)的异步请求。与传统的 WSGI 不同,ASGI 支持异步编程模型,允许单个请求处理多个事件(如长连接、双向通信),从而提升高并发场景下的性能
Uvicorn 是一个基于 ASGI 的高性能异步 Web 服务器,专为 Python 异步框架设计。
web应用程序=web框架+自己写的业务逻辑代码
1 2 3 4 5 6 7 8 9 10 11 12 from fastapi import FastAPIapp= FastAPI() @app.get("/" async def home (): return {"user_id" :1001 } @app.get("/shop" async def shop (): return {"shop_id" :1002 }
启动:uvicorn "04 fastapi_begin:app" --reload
也可以:
1 2 3 import uvicornif __name__ == "__main__" : uvicorn.run(app="04 fastapi_begin:app" ,port=8080 ,reload=True )
接口文档
修饰器(Decorator)是 Python 中一种动态修改函数或类行为的高级功能,本质上是一个函数或类,它接受目标函数或类作为参数,并返回包装后的新函数或类对象 ,从而在不修改原始代码 的前提下为对象添加额外功能
路径操作 路径操作修饰器 1 2 3 4 5 6 7 8 @app.get() @app.post() @app.put() @app.patch() @app.delete() @app.options() @app.head() @app.trace()
路径操作修饰器参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ''' tags为接口添加标签,用于在自动生成的文档 summary为接口添加描述 description为接口添加详细描述 response_description为接口返回值描述 deprecated为过时的接口 ''' @app.post("/post" , tags=["这是post方法" ], summary="这是post方法的描述" , description="这是post方法的详细描述" , response_description="这是post方法的返回值描述" , deprecated=True , )def test ():
include_router 文件路径如下
main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from fastapi import FastAPIimport uvicornfrom apps.app01.shop import shopfrom apps.app02.user import userapp= FastAPI() app.include_router(shop, prefix="/shop" , tags=["购物中心接口" ], responses={200 : {"description" : "成功" }} ) app.include_router(user, prefix="/user" , tags=["用户接口" ], responses={200 : {"description" : "成功" }} ) if __name__ == "__main__" : uvicorn.run("main:app" , port=8080 , reload=True )
shop.py
1 2 3 4 5 6 7 8 9 10 11 from fastapi import APIRoutershop=APIRouter() @shop.get("/food" def shop_food (): return {"food" :"shop food" } @shop.get("/drink" def shop_drink (): return {"drink" :"shop drink" }
user.py
1 2 3 4 5 6 7 8 9 10 11 from fastapi import APIRouteruser=APIRouter() @user.post("/login" def user_login (): return {"user" :"user login" } @user.post("/register" def user_register (): return {"user" :"user register" }
include_router 是 FastAPI 框架中用于整合路由的核心方法,其作用是将通过 APIRouter 定义的路由模块添加到主应用程序实例中,使这些路由在应用中生效。
请求与响应 4.1 路径参数 (1)基本用法 以使用与 Python 格式化字符串相同的语法来声明路径”参数”或”变量”:
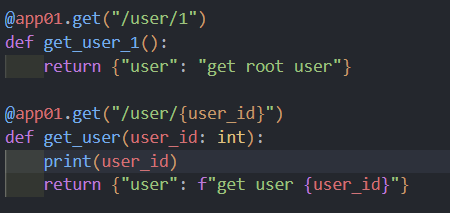
1 2 3 4 @app.get("/user/{user_id}" def get_user (user_id ): print (user_id, type (user_id)) return {"user_id" : user_id}
路径参数 user_id 的值将作为参数 user_id 传递给你的函数。
(2)有类型的路径参数 你可以使用标准的 Python 类型标注为函数中的路径参数声明类型。
1 2 3 4 @app.get("/user/{user_id}" def get_user (user_id: int ): print (user_id, type (user_id)) return {"user_id" : user_id}
在这个例子中,user_id 被声明为 int 类型。
这将为你的函数提供编辑器支持,包括错误检查、代码补全等等。
(3)注意顺序 在创建路径操作时,你会发现有些情况下路径是固定的。
比如 /users/me,我们假设它用来获取关于当前用户的数据。
然后,你还可以使用路径 /user/{username} 来通过用户名获取关于特定用户的数据。
由于路径操作是按顺序依次运行 的,你需要确保路径 /user/me 声明在路径 /user/{username} 之前。
如下
路由(Routing)是指在网络中选择数据传输路径 的过程,其核心目标是将数据从源点高效、可靠地传输到目的地
cURL 是一个开源的命令行工具和跨平台的库(libcurl),用于基于 URL 语法在网络协议下进行数据传输。它支持多种协议(如 HTTP、HTTPS、FTP、SMTP 等),能够实现文件上传、下载以及与 Web 服务器的交互,常被开发者用于 API 测试、数据传输等场景
4.2 查询参数(请求参数) 路径函数中声明不属于路径参数的其他函数参数 时,它们将被自动解释为查询字符串参数 ,就是 url?之后用 & 分割的 key-value 键值对。
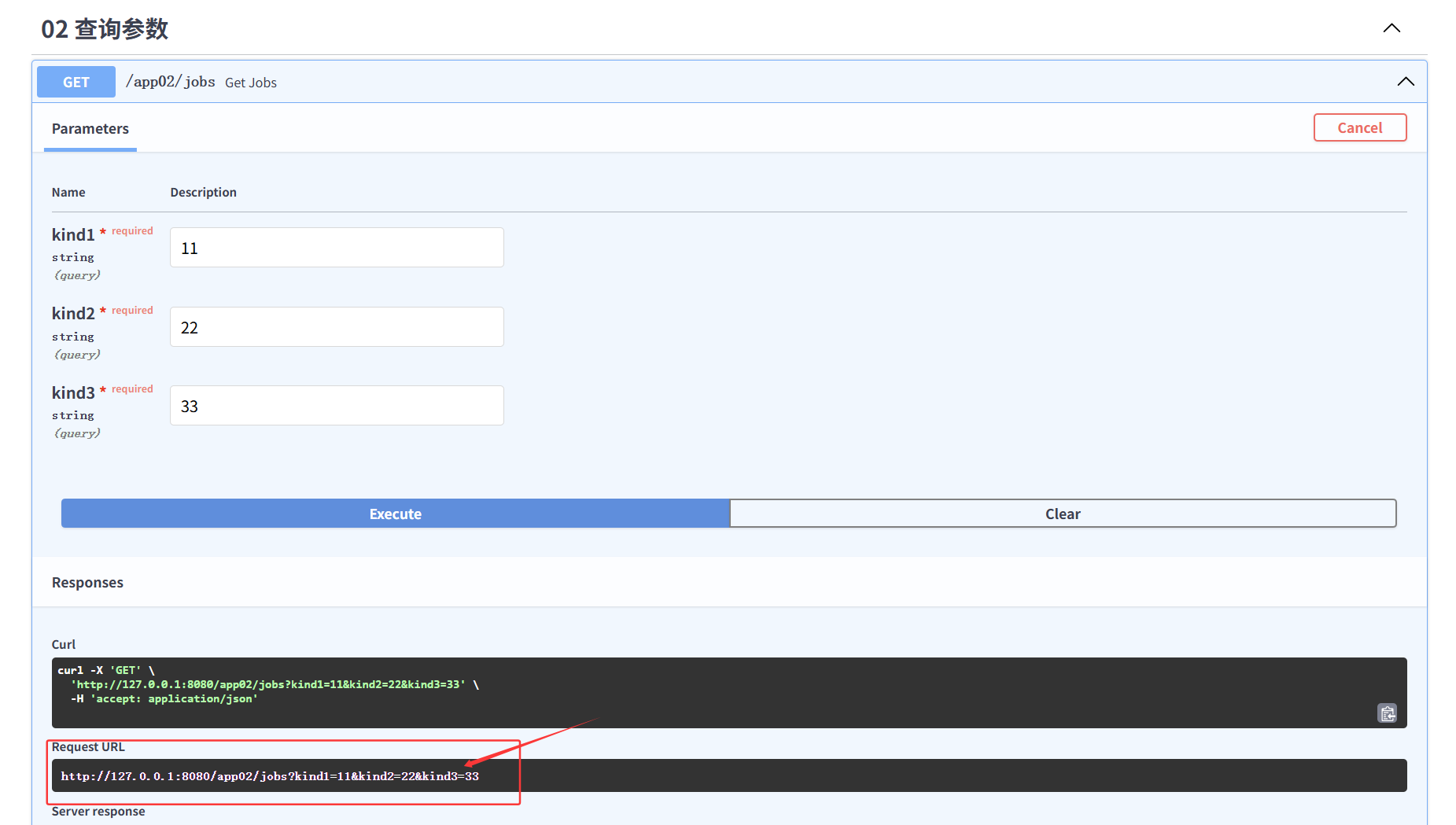
1 2 3 4 5 6 7 8 @app02.get("/jobs" async def get_jobs (kind1: str , kind2: str , kind3: str ): return { "kind1" : kind1, "kind2" : kind2, "kind3" : kind3 }
增加路径参数:kind1为路径参数
增加默认参数值
1 2 3 4 5 6 7 8 @app02.get("/jobs/{kind1}" async def get_jobs (kind1: str , kind2: str ="None" , kind3: str ="None" ): return { "kind1" : kind1, "kind2" : kind2, "kind3" : kind3 }
Request URL:
http://127.0.0.1:8080/app02/jobs/11?kind2=22&kind3=33
自python3.5开始,PEP484为python引入了类型注解(type hints),typing的主要作用有:
1.类型检查,防止运行时出现参数、返回值类型不符。
2.作为开发文档附加说明,方便使用者调用时传入和返回参数类型。
3.模块加入不会影响程序的运行不会报正式的错误,pycharm支持typing检查错误时会出现黄色警告。
type hints主要是要指示函数的输入和输出的数据类型,数据类型在typing包中,基本类型有str list dict等等,
Type Hints 是 Python 3.5 引入的功能,通过类型注解增强代码的可读性和可维护性。它允许开发者为变量、函数参数、返回值等指定预期的数据类型,从而帮助静态类型检查工具(如 mypy)捕获潜在错误,并提升 IDE 的智能提示能力。例如:
1 2 def greet (name: str ) -> str : return f"Hello, {name} "
此处 name: str 表示参数需为字符串类型,-> str 表示返回值类型为字符串 。
Union是当有多种可能的数据类型时使用,比如函数有可能根据不同情况有时返回str或返回list,那么就可以写成Union[list, str]
从 Python 3.10 起,Union[X, Y] 可简写为 X | Y。例如 int | str 等价于 Union[int, str] 。
再例如:kind2:str|None=None
Optional是Union的一个简化,当数据类型中有可能是None时,比如有可能是str也有可能是None,则Optional[str],相当于Union[str, None]
4.3 请求体数据 当你需要将数据从客户端(例如浏览器)发送给 API 时,你将其作为「请求体」发送。请求体是客户端发送给 API 的数据。响应体是 API 发送给客户端的数据。
FastAPI 基于 Pydantic ,Pydantic 主要用来做类型强制检查(校验数据)。不符合类型要求就会抛出异常。
对于 API 服务,支持类型检查非常有用,会让服务更加健壮,也会加快开发速度,因为开发者再也不用自己写一行一行的做类型检查。
安装上手 pip install pydantic
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from fastapi import APIRouterfrom pydantic import BaseModel,Field,field_validatorfrom datetime import datefrom typing import Union ,Optional app03 = APIRouter() class Address (BaseModel ): province: str city: str class User (BaseModel ): name:str age: int =Field(default=0 ,gt=0 ,lt=100 ) birth:Union [date,None ] = None friends:list [int ]=[] description:Optional [str ]=None addr:Address|None = None ''' field_validator 的第一个参数必须是 cls,因为它是类方法 (classmethod),用于在验证字段时访问模型类的上下文。 ''' @field_validator("name" def name_must_alpha (cls,value ): ''' value.isalpha() 会检查字符串是否只由字母组成,如果是则返回 True,否则返回 False。 如果返回 False,assert 触发,会抛出 AssertionError,并显示错误信息 "name must be alpha"。 ''' assert value.isalpha(), "name must be alpha" return value class Data (BaseModel ): data:list [User] @app03.post("/user" async def user (user:User ): print (user,type (user)) return user @app03.post("/data" async def data (data:Data ): print (data,type (data)) return data
BaseModel专门用于数据验证、数据转换和序列化。在定义数据结构时继承自 BaseModel,可以:
自动校验数据类型 :根据类中字段的类型注解,自动校验输入数据是否符合预期类型。数据转换 :可以自动将输入数据(例如 JSON 字符串)转换成相应的 Python 数据类型。序列化输出 :支持将模型实例转换成 JSON、字典等格式,便于响应输出。
在 Pydantic 中,Field 用于为模型字段提供额外的信息,比如设置默认值、描述信息、约束条件(例如长度、范围等)或别名。这可以帮助自动生成 OpenAPI 文档、增强验证或对字段进行更细粒度的控制。
field_validator 是 Pydantic v2 中用于替代旧版 @validator 的新装饰器,专门用于为模型字段添加自定义验证逻辑。它通过更清晰的命名和更灵活的模式(如 mode="before" 或 mode="after")提升代码可读性和验证逻辑的控制能力
field_validator和model_validator区别
field_validator单个字段 进行验证,适用于需要校验特定字段的规则(如长度、格式、类型约束)。例如验证用户名长度
model_validator整个模型实例 ,适用于需要跨字段验证或全局逻辑的场景。例如检查两次密码是否一致
在 OAuth2 规范的一种使用方式(密码流)中,需要将用户名、密码作为表单字段发送,而不是 JSON。
FastAPI 可以使用 Form 组件 来接收表单数据,需要先使用 pip install python-multipart 命令进行安装。
1 2 3 4 5 6 7 @app04.post("/register" async def data (username:str =Form(str =Form( ): print (f"username: {username} , password: {password} " ) return { "username" : username, "password" : password }
发送post请求:form表单数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 url = "http://127.0.0.1:8080/app04/register" data = { "username" : "test_user" , "password" : "secure_password_123" } response = requests.post( url, data=data )
通过 requests.post() 的 data 参数传递表单数据,该参数接受字典或字符串格式的数据。requests 会自动将其编码为 application/x-www-form-urlencoded 格式
4.5 文件上传 导入必要库
1 2 3 from fastapi import File,UploadFileimport osapp05 = APIRouter()
通过字节上传
1 2 3 4 5 6 7 @app05.post("/file" async def file (file: bytes = File(... ) ): return { "filename" : "file" , "size" : len (file) }
多文件上传
1 2 3 4 5 6 7 8 9 @app05.post("/files" async def files (files: list [bytes ] = File(... ) ): for file in files: print (len (file)) return { "filename" : "files" , "size" : len (files) }
UploadFile上传,绝对路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @app05.post("/uploadfile" async def upload_file (file: UploadFile= File(... ) ): base_dir = os.path.dirname(os.path.abspath(__file__)) print (base_dir) img_dir = os.path.join(base_dir, "../imgs" ) print (img_dir) path = os.path.join(img_dir, file.filename) print (path) with open (path, "wb" ) as f: print ("文件名:" , file.filename) for chunk in file.file: f.write(chunk) return { "filename" : file.filename }
UploadFile是 FastAPI 提供的一个类,用于处理文件上传。与直接将文件内容读取为字节流(例如 bytes相比,UploadFile有以下优点:
内存优化 :它采用了文件对象的方式处理上传文件,不必将整个文件内容一次性加载到内存中,适合处理大文件。异步支持 :支持异步操作,可以用异步方式读取文件内容,提高性能。文件元数据 :提供文件名、内容类型等元数据信息,通过属性 filename、content_type 获取。文件接口 :通过 file 属性获取一个类文件对象,可以像操作普通文件一样读取或保存上传的文件。
4.6 Request对象 有些情况下我们希望能直接访问 Request 对象。例如我们在路径操作函数中想获取客户端的 IP 地址,需要在函数中声明 Request 类型的参数,FastAPI 就会自动传递 Request 对象给这个参数,我们就可以获取到 Request 对象及其属性信息,例如 header、url、cookie、session 等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @app06.post("/items" async def items (request: Request ): print ("url:" , request.url) print ("客户端ip:" , request.client.host) print ("请求头:" , request.headers) print ("客户端宿主" ,request.headers.get("user-agent" )) print ("cookie:" , request.cookies) return { "url" : request.url, "client_ip" : request.client.host, "headers" : request.headers, "user_agent" : request.headers.get("user-agent" ), "cookies" : request.cookies }
4.7请求静态文件 在 Web 开发中,需要请求很多静态资源文件(不是由服务器生成的文件),如 css/js 和图片文件等。
main.py
1 2 from fastapi.staticfiles import StaticFilesapp.mount("/static" , StaticFiles(directory="statics" ))
静态网站
完全由静态文件(HTML、CSS、JavaScript)组成,内容固定不变,所有页面在开发时已预生成,无需动态计算或数据库支持
动态网站
内容根据用户请求实时生成,通常依赖数据库和服务器端编程(如PHP、Python、Node.js),能提供个性化和交互功能
StaticFiles是 FastAPI(实际来自 Starlette)提供的一个类,用于挂载和服务静态文件目录。
mount()方法用于将一个完整的应用或静态文件目录挂载到主 FastAPI 应用的某个路径下。这样,访问指定路径时,请求会被转发到挂载的应用或目录。
4.8 响应模型相关参数 response_model response_model是 FastAPI 路由装饰器(如 @app.post、@app.get 等)中的一个参数,用于指定接口响应的数据模型。它的作用是:
自动校验和序列化 :FastAPI 会根据你指定的 Pydantic 模型自动校验、过滤和格式化返回的数据。自动生成文档 :接口文档会自动显示响应的数据结构。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class UserIn (BaseModel ): username: str password: str email: EmailStr full_name: str |None = None class UserOut (BaseModel ): username: str email: EmailStr full_name: str |None = None @app07.post("/user02" ,response_model=UserOut async def create_user (user: UserIn ): return user
案例:
注册功能
输入账号、密码、昵称、邮箱,注册成功后返回个人信息
response_model_exclude_unset=True 通过上面的例子,我们学到了如何用 response_model 控制响应体结构,但是,如果它们实际上没有存储,则可能要从结果中忽略它们。例如,如果 model 在 NoSQL 数据库中具有很多可选属性,但是不想发送很长的 JSON 响应,其中包含默认值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Item (BaseModel ): name:str description: str |None = None price: float tax:float =10.5 tags: list [str ]|None = None items={ "item01" :Item(name="item01" ,price=10.5 ), "item02" :Item(name="item02" ,description="item02" ,price=20.5 ,tax=20.5 ,tags=["tag1" ,"tag2" ]), "item03" :Item(name="item03" ,description="item03" ,price=30.5 ,tax=30.5 ,tags=["tag1" ,"tag2" ]), } @app07.get("/items/{item_id}" ,response_model=Item,response_model_exclude_unset=True async def read_item (item_id: str ): return items[item_id]
设置后返回为:
1 2 3 4 5 item01 { "name" : "item01" , "price" : 10.5 }
当你设置 response_model_exclude_unset=True 时,返回的响应数据只包含被显式设置过的字段 ,没有被赋值的(即使用默认值且未传递的)字段不会出现在响应中。
其他参数 response_model_exclude_defaults 作用:排除所有值为默认值的字段。
response_model_exclude_none 作用:排除所有值为 None 的字段。
response_model_include 作用:只返回指定字段
response_model_exclude 作用:排除指定字段,不在响应中返回。
jinja2模板 要了解 jinja2,那么需要先理解模板的概念。模板在 Python 的 web 开发中广泛使用,它能够有效的将业务逻辑和页面逻辑分开,使代码可读性增强、并且更加容易理解和维护。
模板简单来说就是一个其中包涵占位变量表示动态的部分的文件,模板文件在经过动态赋值后,返回给用户。
jinja2 是 Flask 作者开发的一个模板系统,起初是仿 django 模板的一个模板引擎,为 Flask 提供模板支持,由于其灵活,快速和安全等优点被广泛使用。
在 jinja2 中,存在三种语法:
变量取值 {{ }}
控制结构 {% %}
应用于前后端不分离,模板html+数据库,返回动态网站
5.1 变量 main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from fastapi.templating import Jinja2Templatestemplates=Jinja2Templates(directory="templates" ) @app.get("/index" def index (request: Request ): name="World" books=["Python" , "Java" , "C++" ] user={"name" :"Tom" , "age" :18 } return templates.TemplateResponse( "index.html" , { "request" : request, "name" : name, "books" : books, "user" : user } )
index.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <!DOCTYPE html> <html lang="en" > <head> <meta charset="UTF-8" > <meta name="viewport" content="width=device-width, initial-scale=1.0" > <title>Document</title> </head> <body> <h1>Hello, {{ name }}!</h1> <p>Your favorite books are:</p> <ul> {% for book in books %} <li>{{ book }}</li> {% endfor %} </ul> <p>姓名:{{ user.name }}</p> <p>年龄:{{ user.age }}</p> </body> </html>
5.2 过滤器 变量可以通过“过滤器”进行修改,过滤器可以理解为是 jinja2 里面的内置函数和字符串处理函数。常用的过滤器有:
过滤器名称
说明
capitalize
把值的首字母转换成大写,其他字母转换为小写
lower
把值转换成小写形式
title
把值中每个单词的首字母都转换成大写
trim
把值的首尾空格去掉
striptags
渲染之前把值中所有的 HTML 标签都删掉
join
拼接多个值为字符串
round
默认对数字进行四舍五入,也可以用参数进行控制
safe
渲染时值不转义
那么如何使用这些过滤器呢?只需要在变量后面使用管道 (|) 分割,多个过滤器可以链式调用,前一个过滤器的输出会作为后一个过滤器的输入。
例如:<h1>Hello, {{ name|upper }}!</h1> <li>{{ book|title }}</li>
5.3 控制结构 jinja2中的if语句类似与Python的if语句,它也具有单分支,多分支等多种结构,不同的是,条件语句不需要使用冒号结尾,而结束控制语句,需要使用endif关键字
1 2 3 4 5 6 7 8 9 10 11 12 <p>影视区</p> { % if age >= 18 %} <ul> <li>成人影片</li> <li>成人游戏</li> </ul> { % else %} <ul> <li>儿童影片</li> <li>儿童游戏</li> </ul> { % endif %}
jinja2中的for循环用于迭代Python的数据类型,包括列表、元组和字典。在jinja2中不存在while循环。
1 2 3 { % for book in books %} <li>{ { book|title } } </li> { % endfor %}
ORM操作 在大型的 Web 开发中,我们肯定会用到数据库操作,那么 FastAPI 也支持数据库的开发,你可以用 PostgreSQL、MySQL、SQLite、Oracle 等。本文用 SQLite 为例。我们看下在 FastAPI 是如何操作设计数据库的。
FastAPI 是一个很优秀的框架,但是缺少一个合适的 ORM,官方代码里面使用的是 SQLAlchemy,Tortoise ORM 是受 Django 启发的易于使用的异步 ORM(对象关系映射器)。
Tortoise ORM 目前支持以下数据库:
PostgreSQL >= 9.4(使用 asyncpg)
SQLite(使用 aiosqlite)
MySQL/MariaDB(使用 aiomysql 或使用 asyncmy)
安装:pip install tortoise-orm
6.1 创建模型 1. 一对一关系(One-to-One)
定义 :一张表中的一条记录仅关联另一张表中的一条记录。示例 :用户表(User)与身份证信息表(IDCard),一个用户仅对应一张身份证信息。
2. 一对多关系(One-to-Many)
定义 :一张表中的一条记录关联另一张表中的多条记录。示例 :班级表(Class)与学生表(Student),一个班级包含多个学生,但每个学生只能属于一个班级。
3. 多对多关系(Many-to-Many)
定义 :两张表中的记录可以互相关联多条记录,通常通过中间表实现。示例 :学生表(Student)与课程表(Course),一个学生可选修多门课程,一门课程也可被多个学生选修。
4. 自引用关系(Self-Referencing)
定义 :表内的记录通过字段关联自身,形成层级或树状结构。示例 :员工表(Employee),每个员工可能有直属上级(另一个员工)。
5. 继承关系(Inheritance)
定义 :基于面向对象的继承概念,子表继承父表的字段和约束。示例 :用户表(User)作为基表,管理员表(Admin)和普通用户表(RegularUser)继承其字段(如用户名、密码)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from tortoise.models import Modelfrom tortoise import fields''' Model 是所有数据模型的基类,通过继承 Model 可定义数据库表的结构。每个 Model 子类对应一张数据库表,其类属性定义了表的字段(列)及其约束。 fields 提供了多种字段类型,用于定义数据库表的列及其约束。 ''' class Student (Model ): id = fields.IntField(pk=True ) name = fields.CharField(max_length=50 ,description="姓名" ) pwd = fields.CharField(max_length=50 ,description="密码" ) sno = fields.IntField(description="学号" ) Class_id = fields.ForeignKeyField( "models.Class" , related_name="students" , on_delete=fields.CASCADE, description="班级" ) Course_id = fields.ManyToManyField( "models.Course" , related_name="students" , description="课程" ) class Course (Model ): id = fields.IntField(pk=True ) name = fields.CharField(max_length=50 ,description="课程名称" ) teacher = fields.CharField(max_length=50 ,description="授课老师" ) teacher_id = fields.ForeignKeyField( "models.Teacher" , related_name="courses" , on_delete=fields.CASCADE, description="老师" ) class Class (Model ): id = fields.IntField(pk=True ) name= fields.CharField(max_length=50 ,description="班级名称" ) class Teacher (Model ): id =fields.IntField(pk=True ) name = fields.CharField(max_length=50 ,description="老师姓名" ) pwd = fields.CharField(max_length=50 ,description="密码" ) sno = fields.IntField(description="工号" )
ORM(Object Relational Mapping,对象关系映射)是一种程序设计技术,主要用于实现面向对象编程语言 与关系型数据库 之间的数据转换。其核心思想是通过对象模型与数据库表结构的映射,将数据库操作转化为面向对象的操作,从而简化开发流程并提升代码的可维护性
Tortoise ORM 是一款专为 Python 异步环境设计的轻量级对象关系映射(ORM)框架,其设计灵感来源于 Django ORM,但专注于异步编程场景,适用于 FastAPI、Sanic 等基于 asyncio 的现代 Web 框架。
关系型数据库与非关系型数据库
关系型数据库 id、name、email 等列,每行对应一个用户记录。这种结构化设计支持严格的模式约束(Schema)17。
典型代表 :MySQL、Oracle、PostgreSQL。
非关系型数据库(NoSQL)
6.2 aerich迁移工具 docker 安装 mysql :
拉取 MySQL 镜像:docker pull mysql
运行 MySQL 容器:
1 docker run --name fastapi -e MYSQL_ROOT_PASSWORD=root -p 3306:3306 -d mysql
-p表示端口映射
启动这个 MySQL 容器:docker start fastapi
进入 MySQL 容器:docker exec -it fastapi bash
这条命令的作用是:
docker exec:在已运行的 Docker 容器中执行命令。-it:-i 表示交互式操作,-t 分配一个伪终端(让你像在终端一样操作)。fastapi:这是你要进入的容器名称(你的 MySQL 容器名)。bash:在容器内启动 bash shell。
这条命令会让你进入名为 fastapi 的容器,并获得一个 bash 命令行界面,就像登录到一台 Linux 服务器一样,可以在里面执行各种命令(比如登录 MySQL、查看日志等)。
登录 MySQL:mysql -u root -p
从主机直接连接:mysql -h 127.0.0.1 -P 3306 -u root -p
配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 TORTOISE_ORM = { "connections": { "default": { "engine":'tortoise.backends.mysql',#选择数据库引擎,mysql "credentials": { "host": "localhost",#数据库地址 "port": 3306,#数据库端口 "user": "root",#数据库用户名 "password": "root",#数据库密码 "database": "fastapi_db",#数据库名称 'charset': "utf8mb4",#数据库编码 'echo': True,#是否打印sql语句 'minsize': 1,#连接池最小连接数 'maxsize': 5#连接池最大连接数 } } }, "apps": { "models": { #db.models是我们自己定义的模型类,models在db文件夹下 "models": ["db.models","aerich.models"], "default_connection": "default" } }, 'use_tz': False,#是否使用时区 'timezone': 'Asia/Shanghai',#时区 "generate_schemas": True, "add_exception_handlers": True }
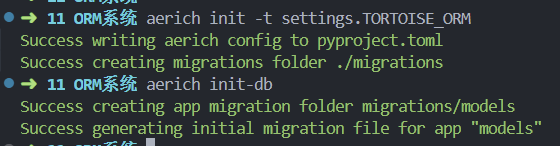
1.初始化配置,只需要使用一次 aerich 是一种 ORM 迁移工具,需要结合 tortoise 异步 orm 框架使用。安装 aerich
pip install aerich
aerich init -t settings.TORTOISE_ORM # TORTOISE_ORM 配置的位置
初始化完会在当前目录生成一个文件:pyproject.toml 和一个文件夹:migrations
pyproject.toml:保存配置文件路径,低版本可能是 aerich.ini
migrations:存放迁移文件
2.初始化数据库,一般情况下只用一次 aerich init-db
3.更新模型并进行迁移 修改model类,重新生成迁移文件
aerich migrate
4.重新执行迁移,写入数据库 aerich upgrade
5.回到上一个版本 aerich downgrade
6.查看历史迁移记录 aerich history
register_tortoise 是 Tortoise ORM 提供的一个工具函数,用于在 FastAPI 等异步框架中快速集成和管理 Tortoise ORM 的生命周期(如启动时初始化数据库连接,关闭时释放资源)。其核心作用是简化 Tortoise ORM 的配置和自动化管理,开发者只需一行代码即可完成复杂的初始化流程
6.3 ORM查询操作 api.stud
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 from fastapi import APIRouterfrom db.models import *student_api=APIRouter() @student_api.get("" async def get_students (): """ #查询所有学生信息 students= await Student.all()#获取所有学生信息 for student in students: print(student.id,student.name) #过滤查询filter students= await Student.filter(name__contains="张").all() for student in students: print(student.id,student.name) #get学生信息 stu = await Student.get(id=1) print(stu.id,stu.name) #模糊查询 #最大值 stu =await Student.filter(sno__gt=1000).all() #最小值 #stu = await Student.filter(sno__lt=1000).all() #范围查询 #stu = await Student.filter(sno__range=(1000,2000)).all() #values查询 stu = await Student.all().values("sno","name") """ return { "操作" :"获取所有学生信息" } @student_api.post("" async def create_student (): return { "操作" :"创建学生信息" } @student_api.get("/{student_id}" async def get_student (student_id:int ): return { "操作" :f"获取学生信息,ID:{student_id} " } @student_api.put("/{student_id}" async def update_student (student_id:int ): return { "操作" :f"更新学生信息,ID:{student_id} " }
在 FastAPI 和 Tortoise ORM 中,async 和 await 用于异步编程 ,主要原因如下:
异步 I/O 操作 async/await 可以在等待数据库响应时,不阻塞主线程,提高应用的并发性能。FastAPI 支持异步路由 async def)的路由函数,这样可以充分利用 Python 的异步特性,提升 Web 服务的吞吐量。Tortoise ORM 的方法是异步的 .all()、.create() 等)本身就是异步方法,必须用 await 调用,并且所在函数必须用 async def 声明。
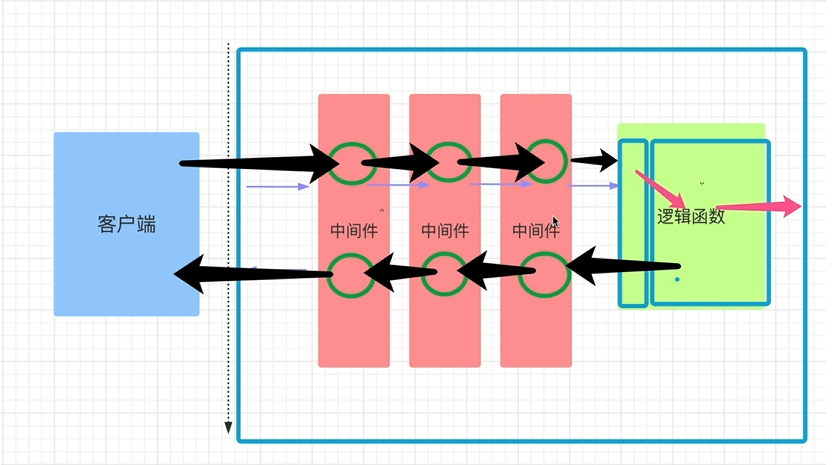
中间件 FastAPI 的「中间件(middleware)」就是 在请求进入路由函数之前、响应离开路由函数之后 插入的 通用处理逻辑 ;
什么时候需要中间件 真实场景举例 —— 统一鉴权 + 日志
需求
实战 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from fastapi import FastAPI, Request import uvicorn app = FastAPI() @app.middleware("http") # 注册一个全局中间件 async def mid1(request: Request, call_next): print("mid1 request") response = await call_next(request) #先让请求继续往后走 print("mid1 respones") return response @app.middleware("http") async def mid2(request: Request, call_next): print("mid2 request") response = await call_next(request) print("mid2 respones") return response @app.get("/") # 任意路由 def home(): print("home") return {"msg": "ok"} if __name__ == "__main__": uvicorn.run(app, host="127.0.0.1", port=8000)
注意中间件添加的顺序
FastAPI/Starlette 把后添加的中间件包在最外层 (洋葱最外层)
所以 mid2 在外层 ,请求先打印
1 2 3 4 5 mid2 request mid1 request home mid1 response mid2 response
cors组件 CORS(Cross-Origin Resource Sharing,跨源资源共享)浏览器为了安全,默认禁止网页去“别的域名/端口/协议”拿数据;CORS 是一套 HTTP 机制,让服务器告诉浏览器“我允许谁来拿、拿什么、怎么拿”。
同源与跨域 同源(Same-Origin)
浏览器把下面三个部分合称 “源” (origin):
协议(http: / https:)
域名(example.com / sub.example.com 算不同)
端口(:80 / :8080)
只有当 协议 + 域名 + 端口 都完全一致时,才叫同源 。
跨域(Cross-Origin)
只要 协议、域名、端口 中的任意一个不同,就是跨域 。
正常来说,服务器为了保护数据,会拒绝跨域的响应,但是通过cors可以允许跨域,因此,CORS 不是“绕过”安全限制,而是服务器主动声明的“安全白名单”。
1 2 3 4 5 6 7 8 9 # 为 FastAPI 应用添加 CORS(跨源资源共享)中间件 # 允许浏览器跨域访问本服务,开发阶段常用;生产环境请收窄范围 app.add_middleware( CORSMiddleware, allow_origins=["*"], # 允许所有来源(生产建议改成具体域名列表,如 ["https://foo.com"]) allow_credentials=False, # 是否允许携带 Cookie/Authorization;True 时 origins 不能为 "*" allow_methods=["GET"], # 允许的 HTTP 方法;["*"] 表示全部 allow_headers=["*"], # 允许的自定义请求头;["*"] 表示全部 )
知识点 端口查询 查看所有端口占用情况:netstat -ano
查询特定端口是否被占用:netstat -ano | findstr 8080
使用 taskkill 命令强制结束进程:taskkill /PID 进程ID /F
通过 PID 查找进程:tasklist | findstr PID
获取绝对路径 获取当前文件的绝对路径:base_dir = os.path.dirname(os.path.abspath(__file__))
拼接路径:img_dir = os.path.join(base_dir, "../imgs")
mysql部分指令 查看数据库列表 :SHOW DATABASES;
选择数据库 :USE 数据库名;
删除数据库 :DROP DATABASE 数据库名;
创建数据库 :CREATE DATABASE 数据库名;
登录 MySQL :mysql -u root -p
退出 :exit
docker部分指令 linux安装docker :sudo apt-get update && sudo apt-get install docker.io
查看 Docker 版本信息 :docker version
查看镜像 :docker images
查看所有的容器 :docker ps -a
systemctl 是 systemd 系统和服务管理器的核心工具,用于管理系统和服务的状态及配置。
mysql-client 是 MySQL 数据库的命令行客户端工具。它允许你通过命令行连接和操作 MySQL 数据库服务器,比如执行 SQL 查询、管理数据库和用户等。
常用命令格式如下:mysql -h 主机地址 -P 端口号 -u 用户名 -p
你可以在终端输入以下命令来检查是否已安装 mysql-client:mysql --version
可以使用以下命令安装:sudo apt-get update sudo apt-get install mysql-client
sudo apt-get update 这个命令的作用是更新本地软件包列表 。
停止并删除容器 :docker stop fastapi docker rm fastapi
参考资料 fastapi一个项目FastAPI进阶_哔哩哔哩_bilibili
教程fastapi框架快速学习_哔哩哔哩_bilibili
fastapi相关知识的补充Python 异步编程 - 搞明白 async, await (继续解释 yield)_哔哩哔哩_bilibili
 /第二章:第四节数据可视化-课程_10_0.png)
/第二章:第四节数据可视化-课程_10_0.png)/第二章:第四节数据可视化-课程_14_1.png)
/第二章:第四节数据可视化-课程_19_0.png)
/第二章:第四节数据可视化-课程_20_0.png)
/第二章:第四节数据可视化-课程_29_1.png)