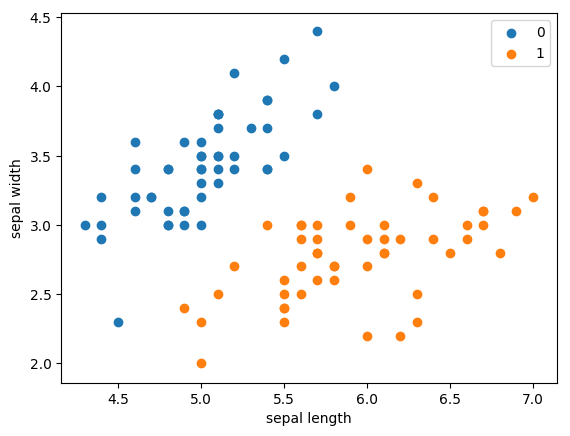
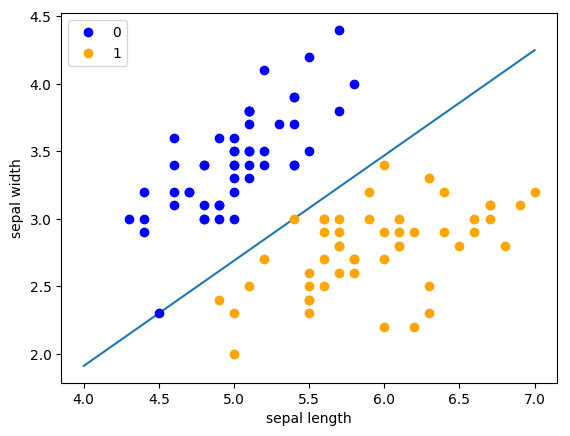
机器学习——支持向量机
正文
下面我将为你详细解释KKT(Karush-Kuhn-Tucker)条件。KKT条件是优化理论中用于求解带约束非线性规划问题的一组必要条件,广泛应用于支持向量机(SVM)等机器学习算法中。我会使用内联数学公式(如 )来展示相关表达式。
1. 优化问题的一般形式
我们考虑一个带有约束的优化问题,数学形式如下:
- 目标:
- 不等式约束:,其中
- 等式约束:,其中
这里:
- 是目标函数,通常是我们希望最小化的函数。
- 表示 个不等式约束。
- 表示 个等式约束。
KKT条件的目标是找到满足这些约束的局部最优解 。
2. 拉格朗日函数
为了引入KKT条件,我们首先定义拉格朗日函数:
其中:
- 是与不等式约束 对应的拉格朗日乘子。
- 是与等式约束 对应的拉格朗日乘子。
拉格朗日函数将目标函数和约束条件结合在一起,通过引入乘子 和 来平衡约束对优化的影响。
3. KKT条件的组成部分
KKT条件由以下四个部分组成,只有当某些正则性条件(如Slater条件)满足时,局部最优解 才会同时满足这些条件。以下是具体的KKT条件:
3.1 梯度条件(Stationarity)
拉格朗日函数对 的梯度必须为零,即:
这意味着在最优解处,目标函数的梯度可以通过约束函数梯度的线性组合来表示。
3.2 原始可行性(Primal Feasibility)
解 必须满足原始问题的所有约束:
- 不等式约束:,其中
- 等式约束:,其中
这确保了解仍在问题的可行域内。
3.3 对偶可行性(Dual Feasibility)
对于不等式约束对应的拉格朗日乘子,必须满足:
这表明不等式约束的乘子非负,反映了约束对优化方向的影响。
3.4 互补松弛条件(Complementary Slackness)
对于每个不等式约束,乘子与约束函数的乘积必须为零:
这意味着:
- 如果某个约束不“紧”(即 ),则对应的乘子 。
- 如果 ,则该约束必须是“紧”的(即 )。
4. KKT条件的意义
- 梯度条件:表明最优解处目标函数的改变方向被约束完全平衡。
- 原始可行性:确保解满足所有约束条件。
- 对偶可行性:限制拉格朗日乘子的符号,保证优化方向的合理性。
- 互补松弛条件:揭示哪些约束在最优解处起作用(紧约束),哪些不起作用。
5. KKT条件在SVM中的应用示例
KKT条件在支持向量机(SVM)中尤为重要。SVM的原始优化问题为:
- 目标:
- 约束:,其中
将其改写为标准形式的不等式约束:。
拉格朗日函数为:
应用KKT条件:
- 梯度条件:
- 对 :
- 对 :
- 原始可行性:
- 对偶可行性:
- 互补松弛条件:
这些条件帮助我们识别支持向量( 的点)并求解最优的 和 。
6. 总结
KKT条件是求解带约束优化问题的核心工具,它通过梯度条件、原始可行性、对偶可行性和互补松弛条件,确保了解既是最优的,又满足所有约束。在机器学习中,KKT条件为SVM等算法提供了理论支持,是理解和实现这些模型的关键。
作业
关于支持向量机,推导目标函数的原始问题转换为对偶问题的过程和条件。(使用拉格朗日乘子法)

下面我们将推导支持向量机(SVM)中目标函数从原始问题转换为对偶问题的过程和条件,使用拉格朗日乘子法。我们将一步步展开,确保推导清晰且完整。
1. 原始问题
支持向量机(SVM)的目标是找到一个超平面,能够最大化到最近数据点的间隔。对于线性可分的情况,原始优化问题可以定义为:
目标函数:
约束条件:
其中:
- 是超平面的法向量;
- 是超平面的截距;
- 是训练样本, 是对应的类别标签;
- 表示法向量的平方范数,目标是最小化它以最大化间隔;
- 约束条件确保所有样本点被正确分类,并且到超平面的归一化距离至少为 1。
2. 引入拉格朗日乘子法
由于这是一个带不等式约束的优化问题,我们使用拉格朗日乘子法将其转换为无约束形式。引入拉格朗日乘子 ,其中 ,构造拉格朗日函数:
- 第一项 是原始目标函数;
- 第二项 将约束条件引入,由于是 不等式,乘子 。
我们的目标是通过拉格朗日函数,将原始问题转换为对偶问题。
3. 转换为对偶问题
对偶问题的核心思想是:先对 和 求拉格朗日函数的极小值,然后对 求极大值。即:
3.1 对 和 求偏导
为了找到 关于 和 的极小值,分别求偏导并令其为零:
对 求偏导:
解得:
对 求偏导:
解得:
这两个结果是后续推导的关键。
3.2 代入拉格朗日函数
将 代入拉格朗日函数,并利用 简化:
计算第一项:
计算第二项中的内积部分:
所以:
考虑 项:
代入后,拉格朗日函数变为:
化简:
3.3 对偶优化问题
于是,对偶问题是:
- 约束条件:
为了与标准优化形式一致,常将其写为最小化问题:
- 约束条件不变:
4. 转换的条件
原始问题与对偶问题之间的关系由强对偶性保证。在SVM中:
- 目标函数 是凸函数(二次函数);
- 约束条件 是线性不等式;
- 对于线性可分数据,Slater条件满足(存在可行解使约束严格成立)。
因此,强对偶性成立,原始问题的最优解可以通过对偶问题求解得到。
此外:
- 最优的 通过对偶问题求解;
- ;
- 对于支持向量( 的样本),,可据此解出 。
5. 总结
原始问题:
受约束:
对偶问题:
受约束:,
转换条件:
通过拉格朗日乘子法,基于凸优化和强对偶性完成转换。对偶形式不仅便于求解,还为引入核函数奠定了基础。
以上就是SVM目标函数从原始问题到对偶问题的推导过程和条件。
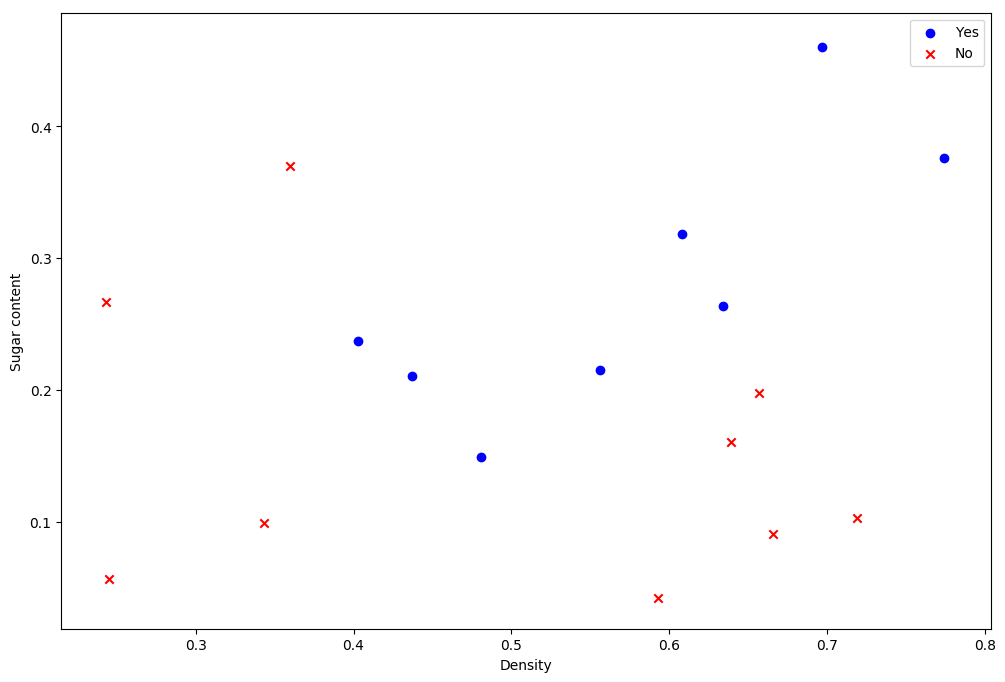
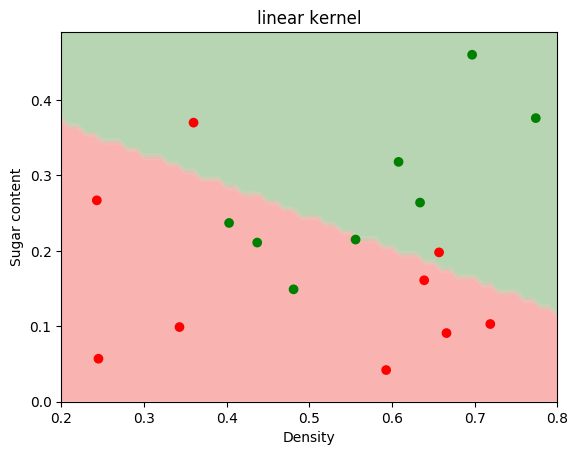
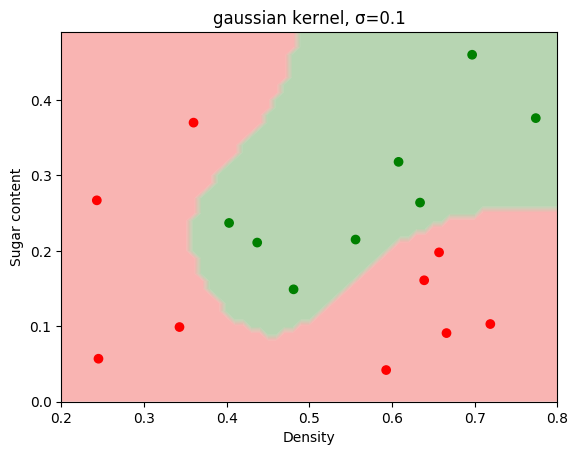
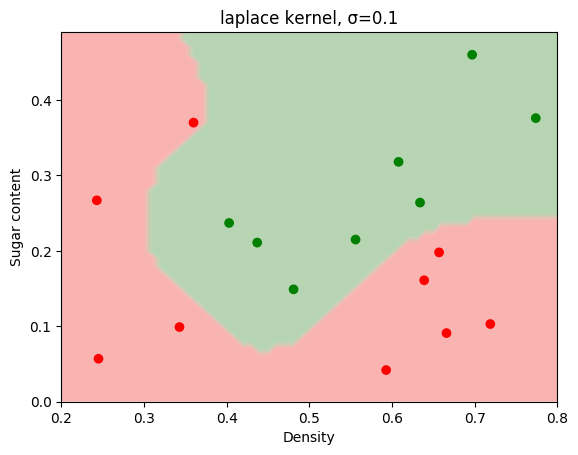
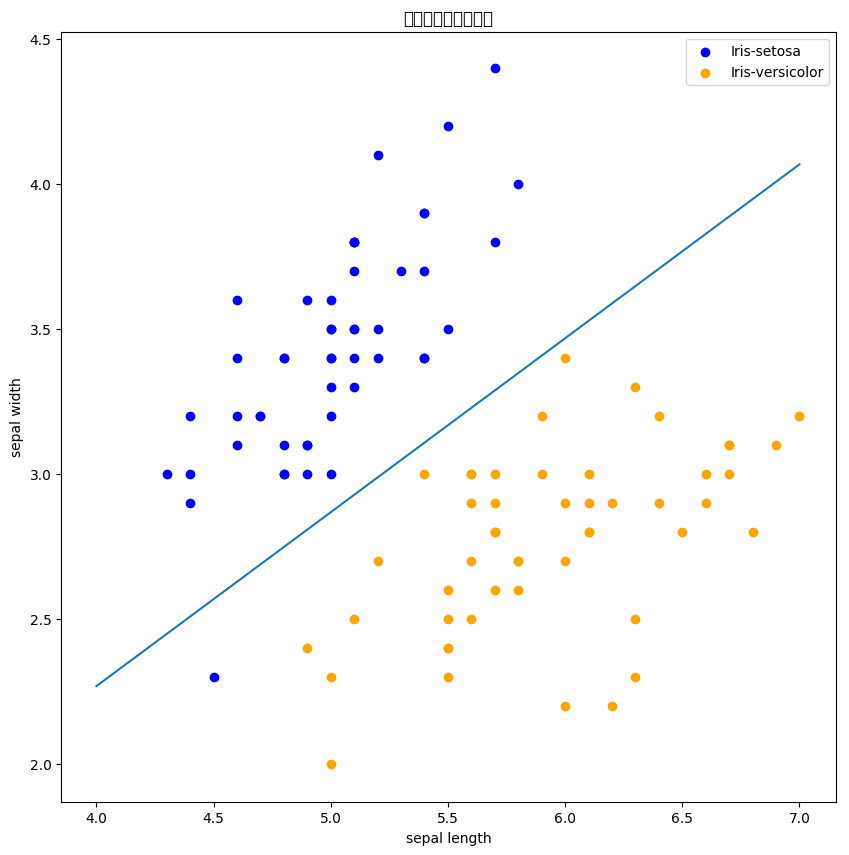
2.已知训练数据集中正例点x1=(2,3),x2=(3,3),x3=(3,2),负例点x4=(1,2), x5=(2,1),x6=(3,1),训练线性SVM分类器。求最大间隔分类超平面和分类决策函数,并画出分类超平面、间隔边界以及支持向量。