# 原错误代码 for content in response.content: # ❌ response没有content属性
# 修复后代码 message = response.choices[0].message # ✅ 正确的访问路径 if message.content: final_text.append(message.content) if message.tool_calls: for tool_call in message.tool_calls: # 处理工具调用
工具调用结果处理修复
问题:错误处理MCP工具调用返回的结果结构
修复:
1 2 3 4 5 6 7 8 9 10 11
# 原错误代码 "content": result.content # ❌ 可能包含复杂对象
# 修复后代码 tool_result_content = "" if result.content: for item in result.content: ifhasattr(item, 'type') and item.type == 'text': tool_result_content += item.text else: tool_result_content += str(item)
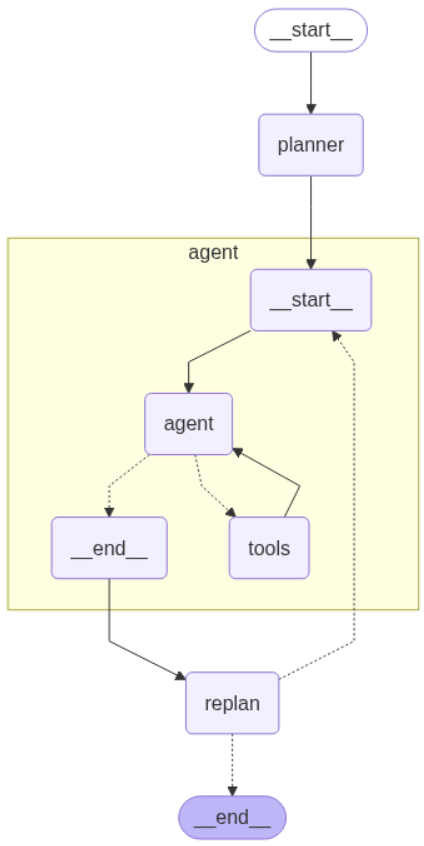
def should_end(state: PlanExecute): """判断是否结束执行流程""" if "response" in state and state["response"]: # 如果存在响应内容,结束流程 return END else: # 否则继续执行代理步骤 return "agent"
# short-term短期记忆 实例化PostgresSaver对象 并初始化checkpointer # long-term长期记忆 实例化PostgresStore对象 并初始化store async with ( AsyncPostgresSaver.from_conn_string(db_uri) as checkpointer, AsyncPostgresStore.from_conn_string(db_uri) as store
): await store.setup() await checkpointer.setup()
更换apt镜像源
1 2 3 4 5 6 7 8
cat > /etc/apt/sources.list <<'EOF' deb http://mirrors.aliyun.com/debian/ bookworm main contrib non-free deb http://mirrors.aliyun.com/debian/ bookworm-updates main contrib non-free deb http://mirrors.aliyun.com/debian/ bookworm-backports main contrib non-free deb http://mirrors.aliyun.com/debian-security bookworm-security main contrib non-free EOF
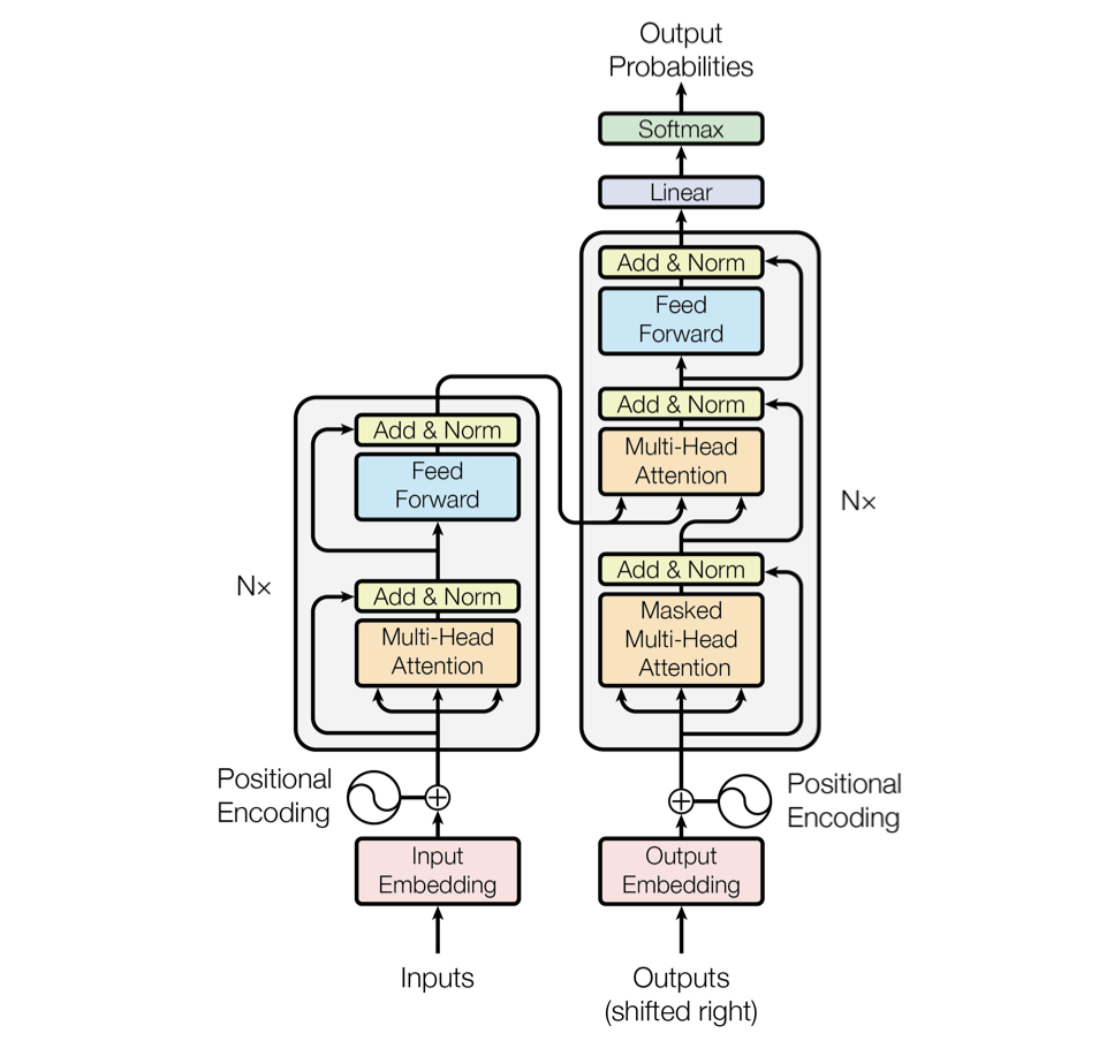
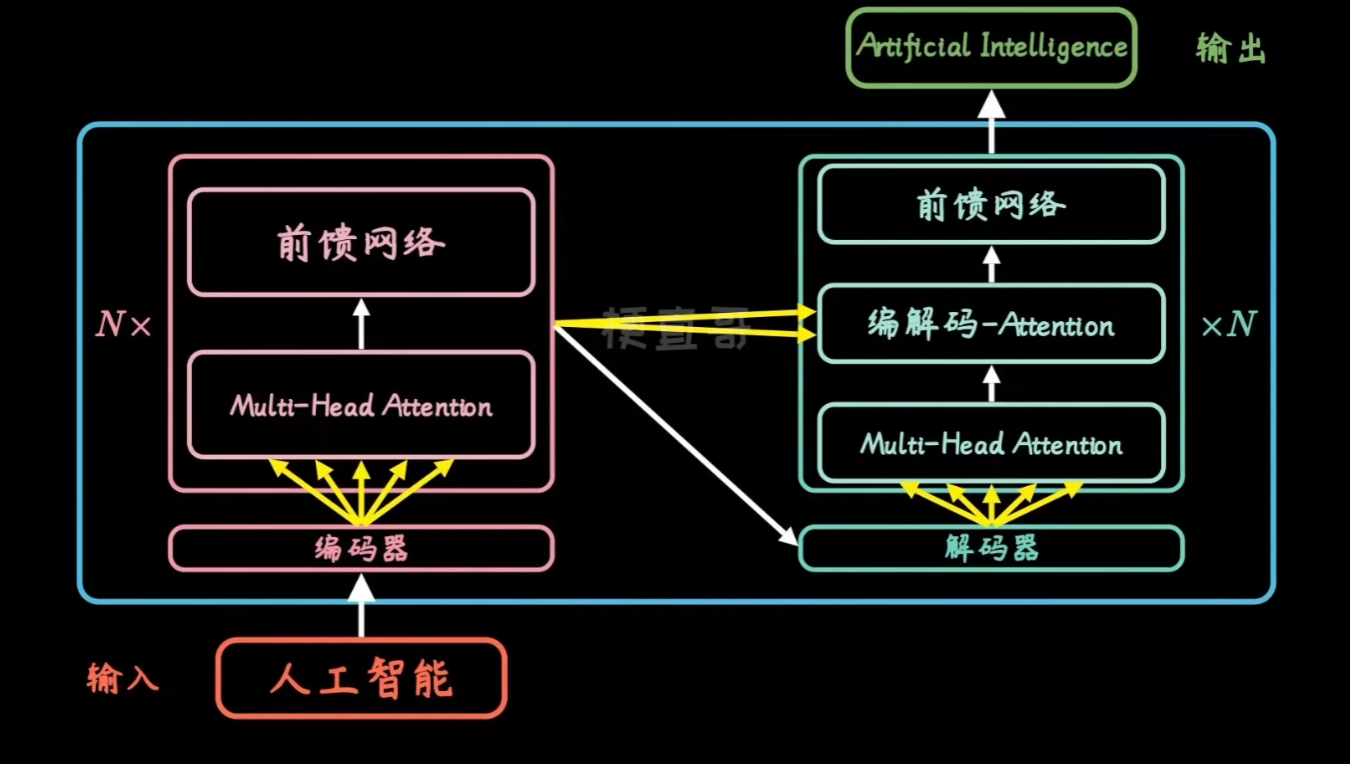
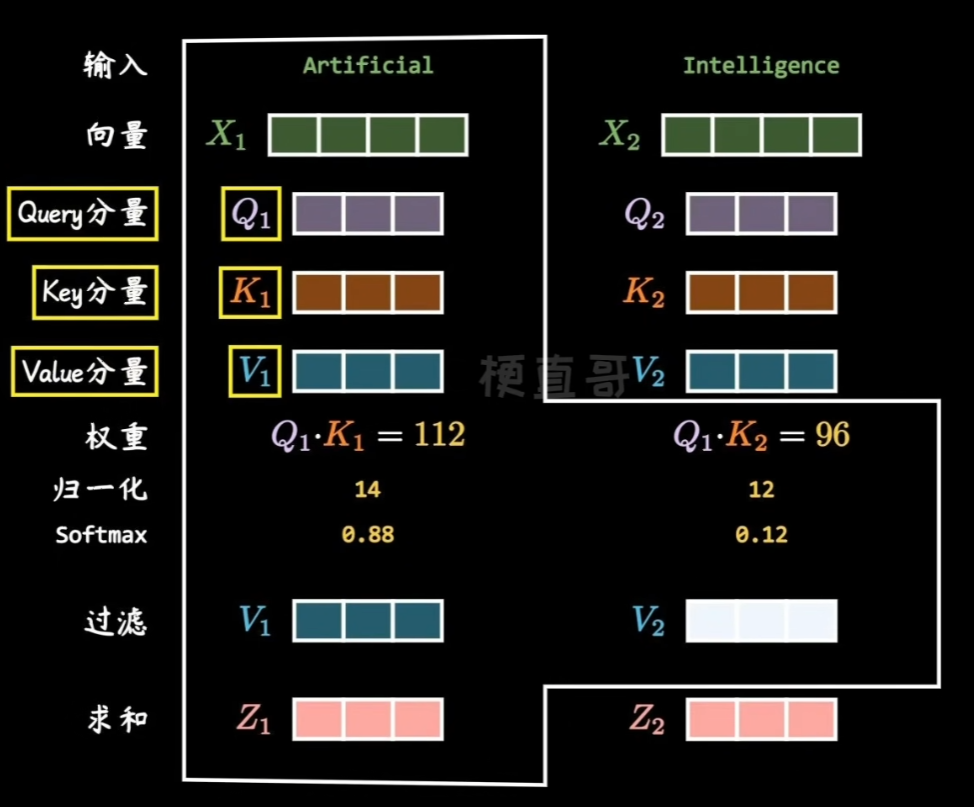
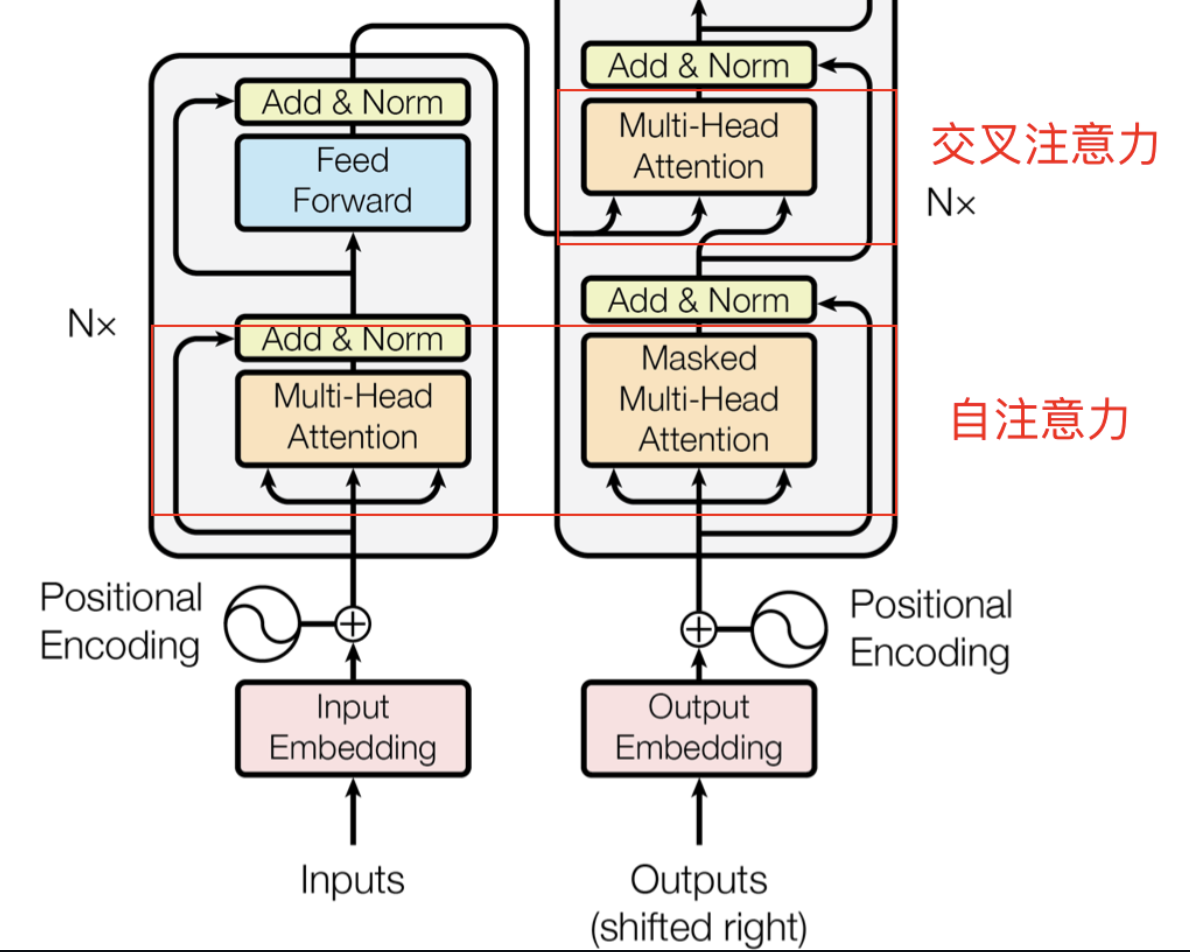
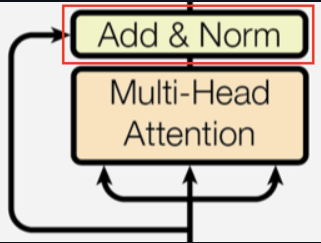
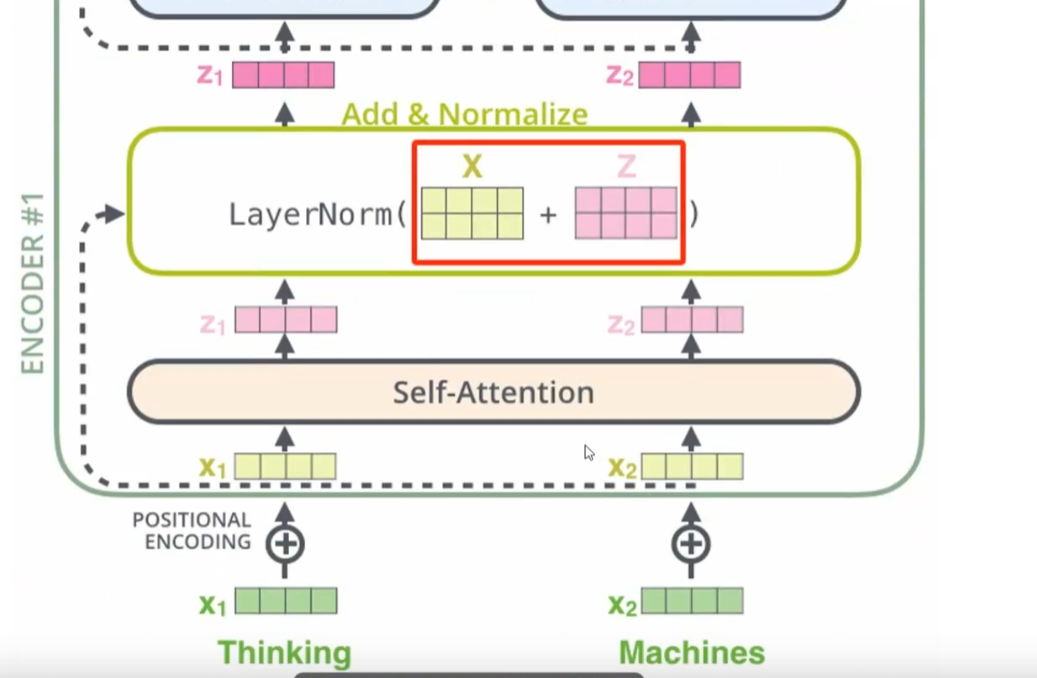
以机器翻译中的中译英任务为例:对于中文句子“中国的首都是北京”,假设模型已经生成了部分译文“The
capital of China is”,此时需要预测下一个单词。
在这一阶段,解码器中的交叉注意力机制会使用当前已生成的译文“The
capital of China
is”的编码表示作为查询,并将编码器对输入句子“中国的首都是北京”编码表示作为键和值,通过计算查询与键之间的匹配程度,生成相应的注意力权重,以此从值中提取上下文信息,基于这些信息生成下一个可能的单词(token),比如:“Beijing”。
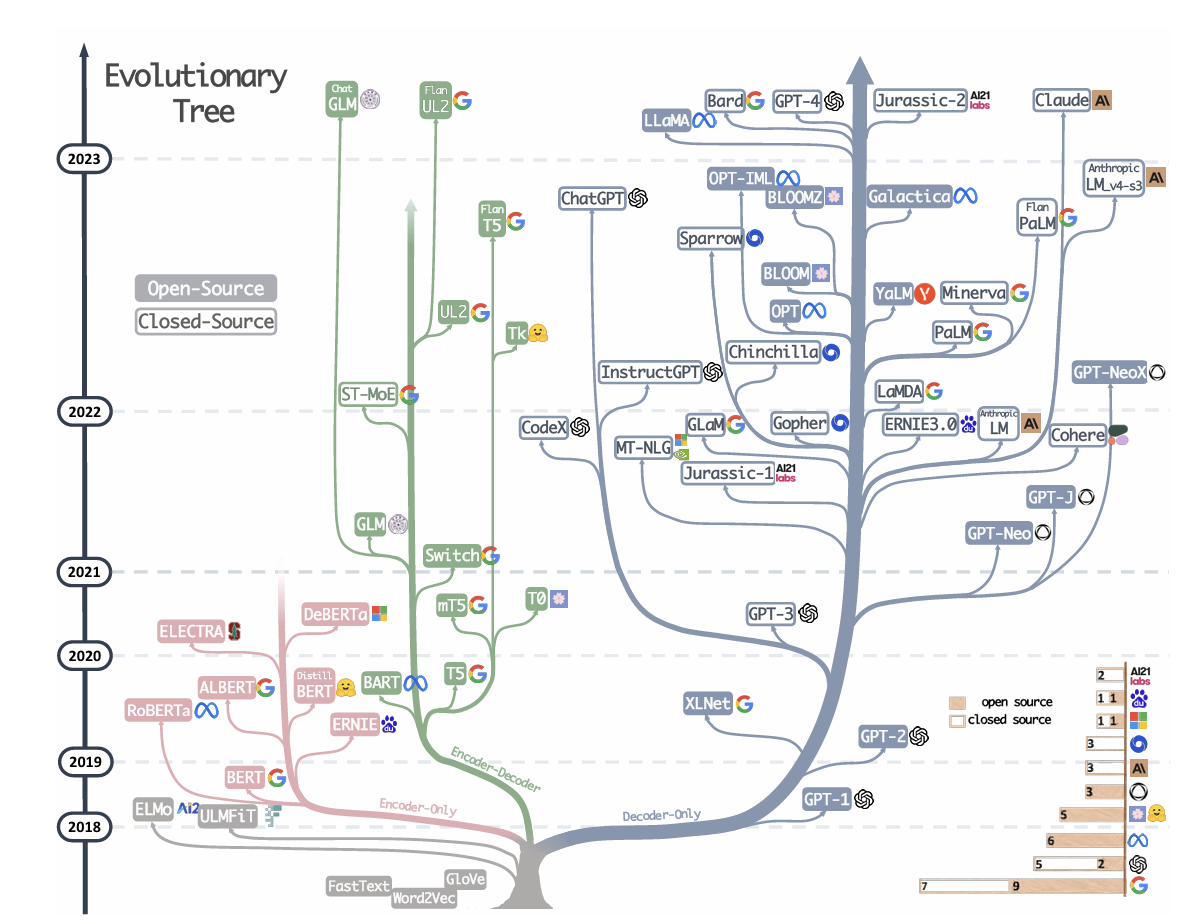
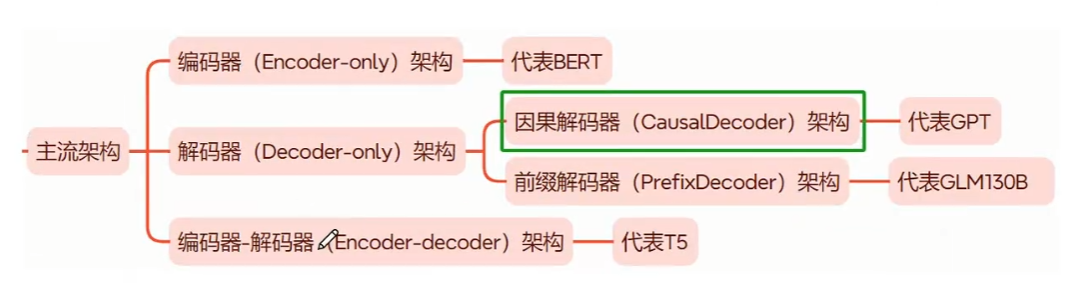
针对 Encoder、Decoder 的特点,引入 ELMo
的预训练思路,开始出现不同的、对 Transformer
进行优化的思路。例如,Google 仅选择了 Encoder
层,通过将 Encoder
层进行堆叠,再提出不同的预训练任务-掩码语言模型(Masked Language
Model,MLM),打造了一统自然语言理解(Natural Language
Understanding,NLU)任务的代表模型——BERT。
BERT,全名为 Bidirectional Encoder Representations from
Transformers,是由 Google 团队在
2018年发布的预训练语言模型。该模型发布于论文《BERT: Pre-training of Deep
Bidirectional Transformers for Language Understanding》,实现了包括
GLUE、MultiNLI 等七个自然语言处理评测任务的最优性能(State Of The
Art,SOTA),堪称里程碑式的成果。
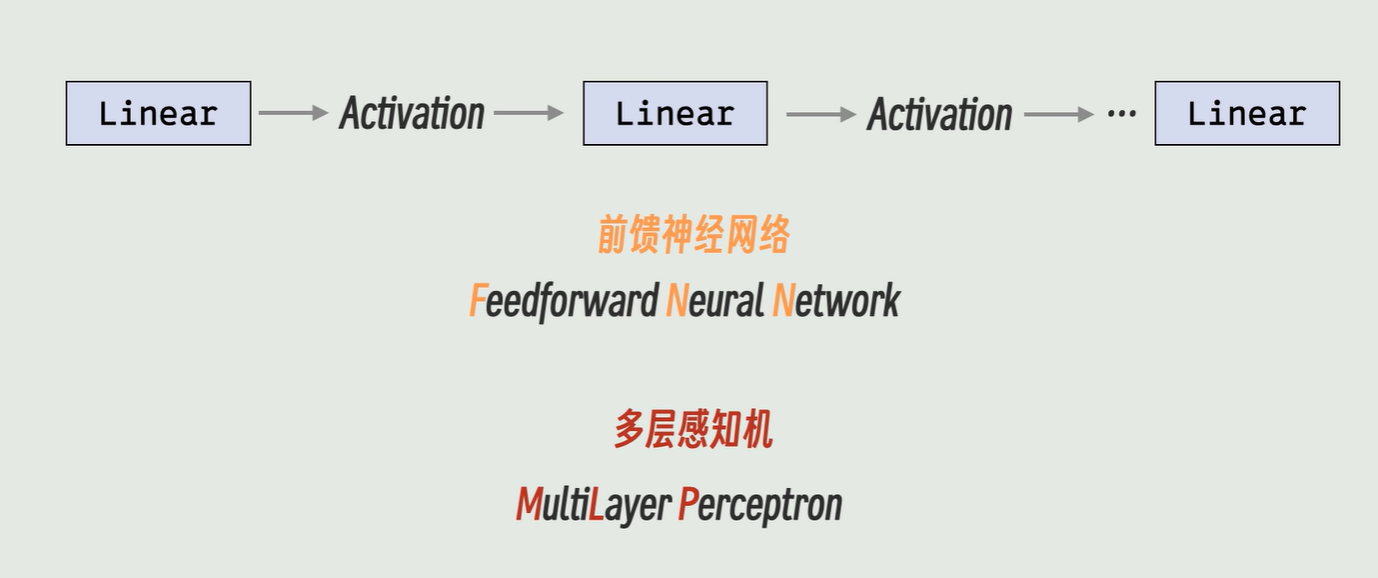
T5(Text-To-Text Transfer Transformer)是由 Google
提出的一种预训练语言模型,通过将所有 NLP
任务统一表示为文本到文本的转换问题,大大简化了模型设计和任务处理。T5
基于 Transformer
架构,包含编码器和解码器两个部分,使用自注意力机制和多头注意力捕捉全局依赖关系,利用相对位置编码处理长序列中的位置信息,并在每层中包含前馈神经网络进一步处理特征。
作用:让 AI 助手(如 Claude、Cline
等)在对话过程中,动态调用外部工具(Tool)完成复杂任务(读写文件、查询数据库、调用
API 等)。
组成:
MCP Host(宿主,如 Cline、Claude Desktop)
MCP Server(提供 Tool 的后台服务)
Tool(具体功能单元,如 read_file,
exec_command 等)
核心概念速记
MCP Server
一个独立进程,提供 1-N 个 Tool。
可以用任何语言编写,只要暴露标准 MCP 接口。
Tool
最小执行单元,必须包含:
name(唯一)
description(让 LLM 理解何时调用)
input schema(参数结构,JSON Schema)
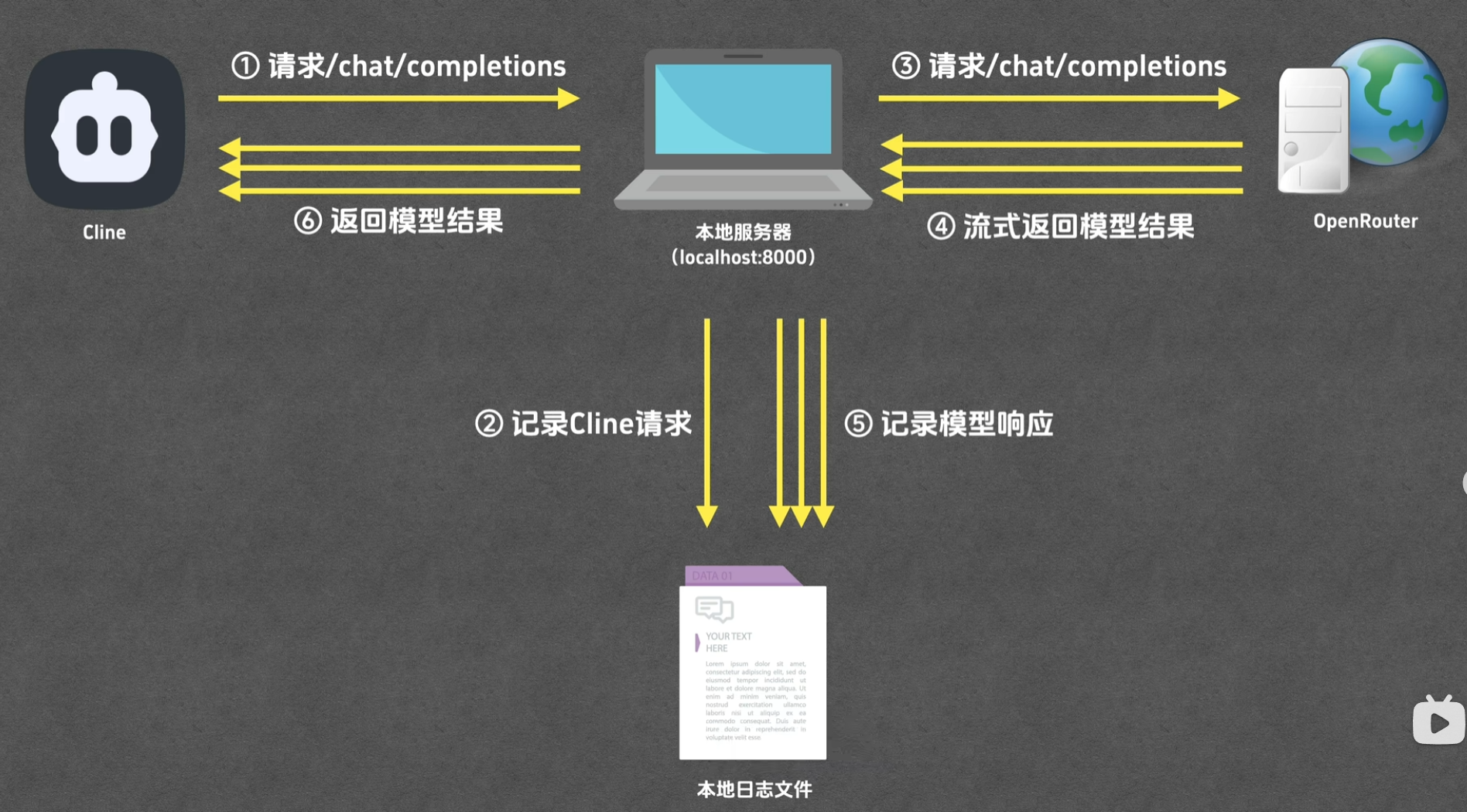
交互流程(重点)
在启动mcp server时,server将tool信息传送给host
用户在 Host 输入自然语言需求。
Host 将需求 + 可用 Tool 列表发给 LLM。
LLM 判断调用哪个 Tool,并填充参数。
Host 通过 MCP 协议向对应 Server 发送请求。
Server 执行 Tool 并返回结果。
Host 将结果合并上下文,继续对话。
mcp和fuction calling的区别
维度
Function Calling(FC)
MCP(Model Context Protocol)
本质
能力 ——
某个大模型原生就带的一种「调用函数」功能
协议 —— 定义 AI
与外部世界如何长期、标准、可复用地交互
工作方式
模型在一次推理里主动决定要调用哪个函数,并吐出结构化参数
通过「客户端-服务器」架构,由 MCP Server
被动等待模型或 Agent 的请求
是否标准化
否。OpenAI、Anthropic、百度等各家接口格式不同
是。统一 JSON-RPC 2.0 协议,跨模型通用
上下文管理
单次调用,无状态;复杂多轮任务需自己维护
协议层面支持会话、状态、长链路任务
复用/共享
函数代码往往紧耦合在项目里,换模型就得重写
一次写成 MCP Server,可被任何支持 MCP 的模型/IDE/Agent 直接插用
一句话总结: Function Calling
是「某个模型自带的快捷指令」,MCP
是「让任何模型都能统一插拔工具的工业标准」。 二者并非互斥——MCP
的实现里仍然可以用 Function Calling
去触发具体函数,但它把「怎么描述工具、怎么发现工具、怎么保持会话」这些事都标准化了,从而解决了
FC 带来的碎片化、难维护、难共享的问题 。