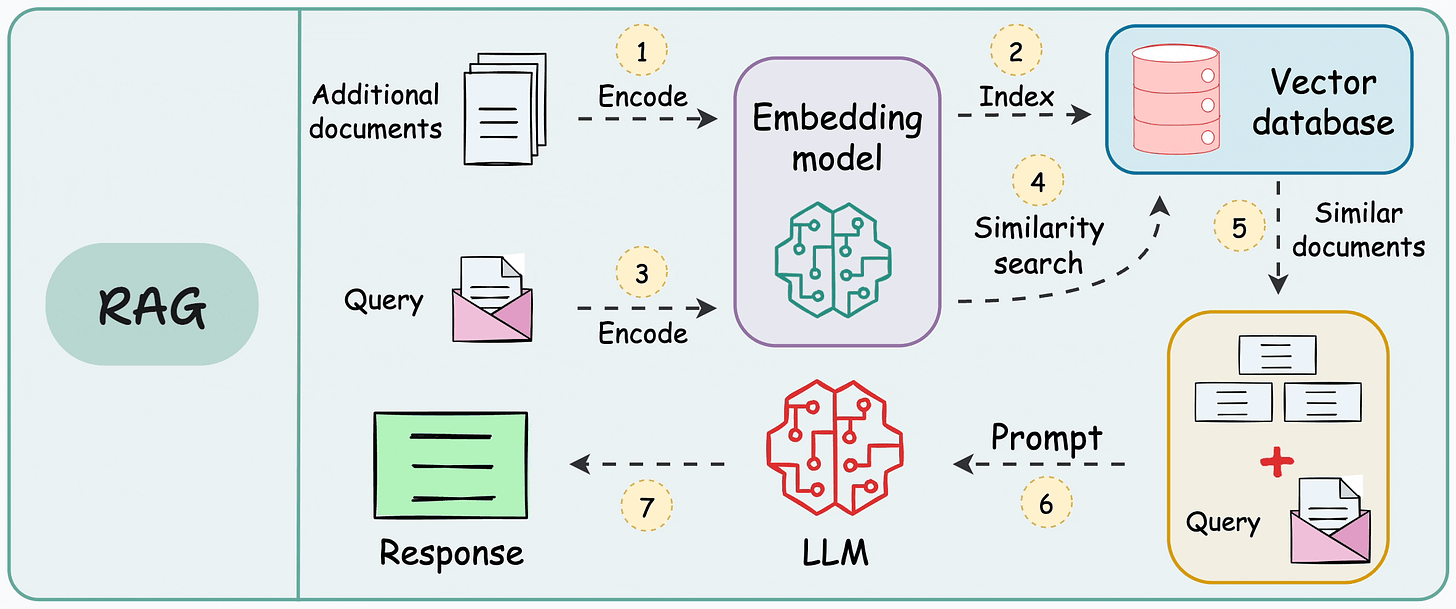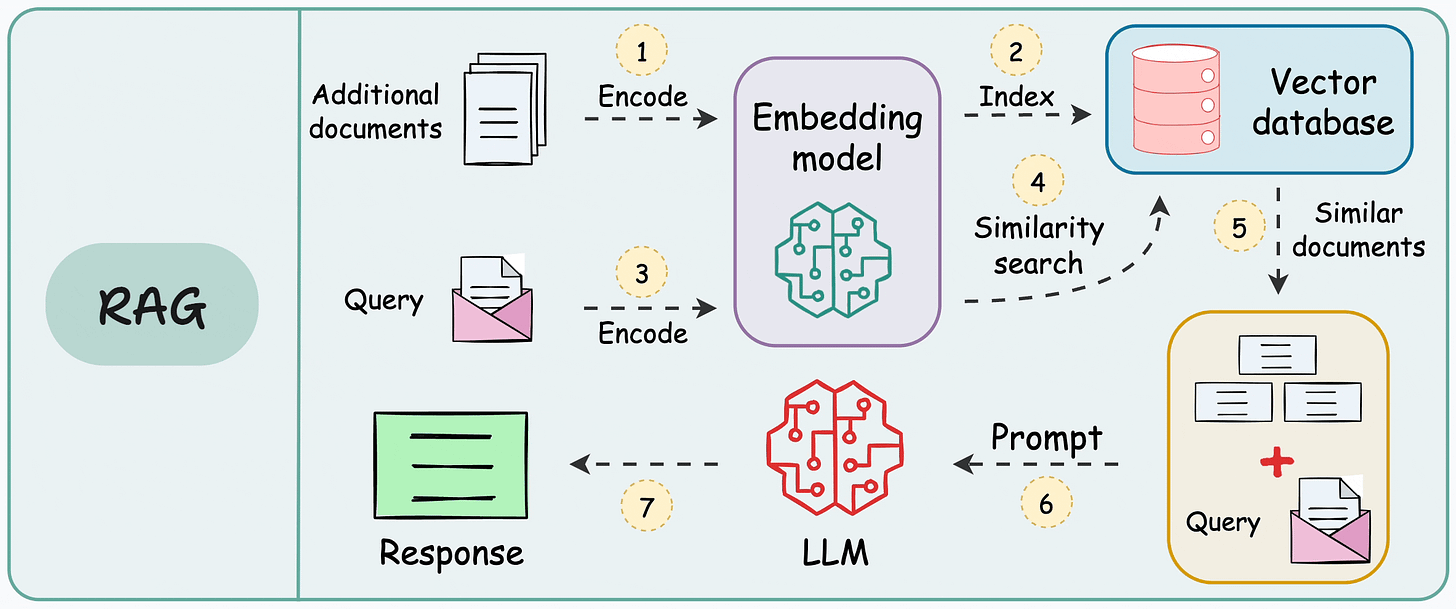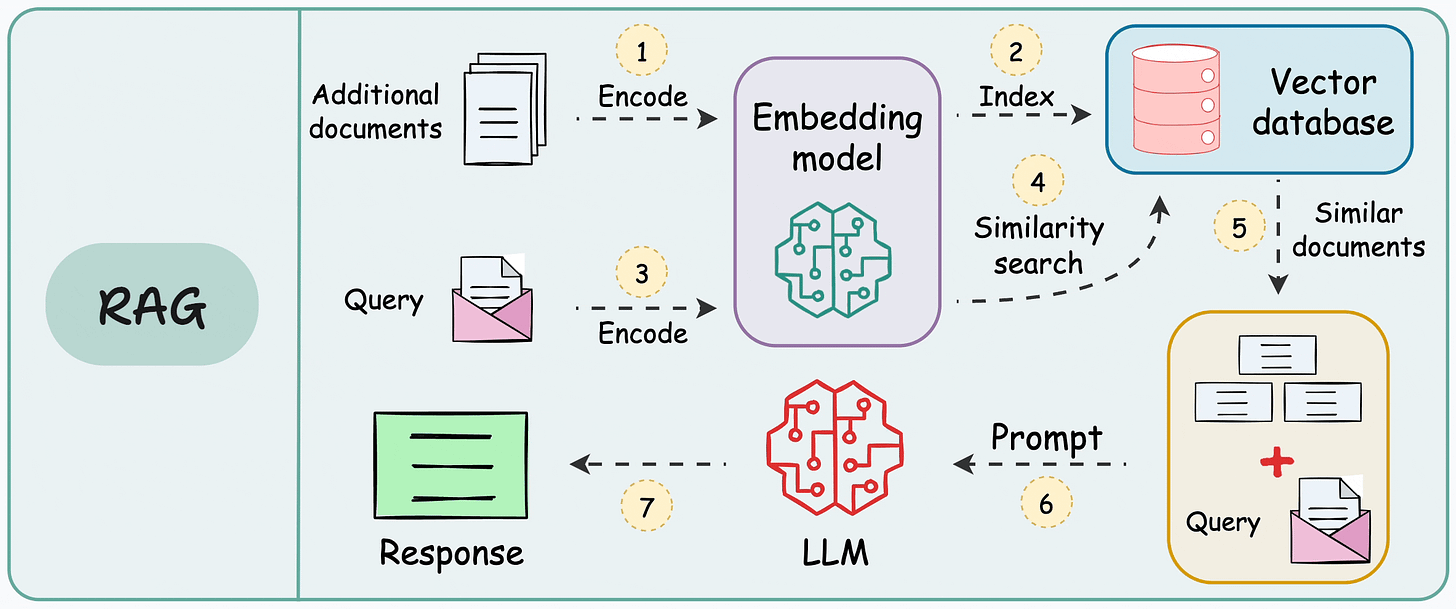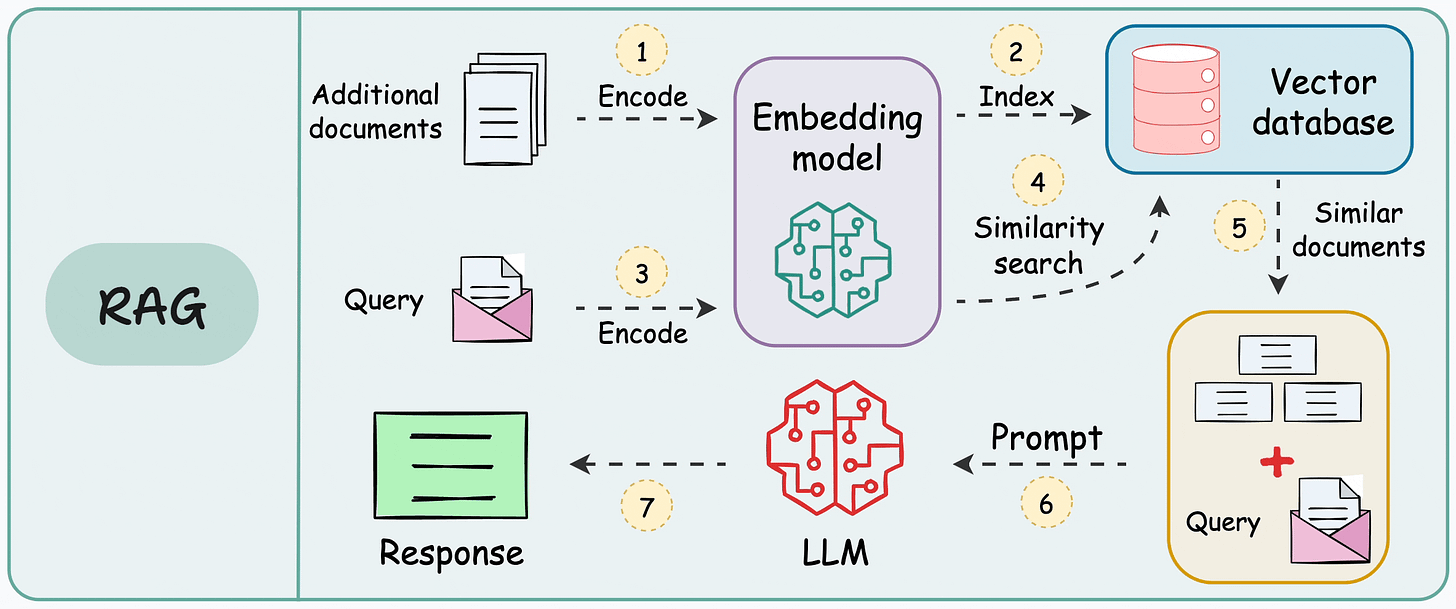
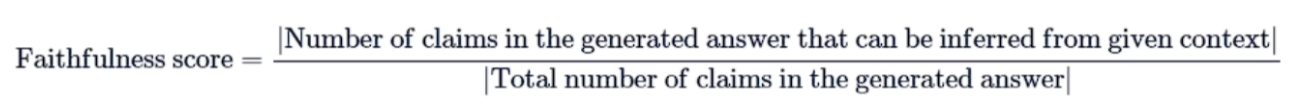template = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
from datasets import Dataset #构建问题与标准答案(黄金数据集) questions = ["What is faithfulness ?", "How many pages are included in the WikiEval dataset, and which years do they cover information from?", "Why is evaluating Retrieval Augmented Generation (RAG) systems challenging?", ] ground_truths = ["Faithfulness refers to the idea that the answer should be grounded in the given context.", " To construct the dataset, we first selected 50 Wikipedia pages covering events that have happened since the start of 2022.", "Evaluating RAG architectures is, however, challenging because there are several dimensions to consider: the ability of the retrieval system to identify relevant and focused context passages, the ability of the LLM to exploit such passages in a faithful way, or the quality of the generation itself."] answers = [] contexts = []
# 生成答案 for query in questions: answers.append(rag_chain.invoke(query)) contexts.append([docs.page_content for docs in base_retriever.get_relevant_documents(query)])
from ragas.llms import LangchainLLMWrapper evaluator_llm = LangchainLLMWrapper(llm)
调用
1 2 3 4
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectness from ragas import evaluate result = evaluate(dataset=evaluation_dataset,metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],llm=evaluator_llm) result
image-20250713164037571
查看结果
1 2 3 4 5
import pandas as pd pd.set_option("display.max_colwidth", None)
[Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}, page_content='Hi this is Jim \nHi this is Joe'), Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}, page_content='Hi this is Lance'), Document(metadata={'Header 1': 'Foo', 'Header 2': 'Baz'}, page_content='Hi this is Molly')]
''' 将文本划分成单句,可以按照标点符号划分 ''' single_sentences_list = re.split(r'(?<=[。!?])', essay) # 移除可能存在的空字符串 single_sentences_list = [s.strip() for s in single_sentences_list if s.strip()]
''' 我们需要为单个句子拼接更多的句子,但是 `list` 添加比较困难。因此将其转换为字典列(`List[dict]`) { 'sentence' : XXX , 'index' : 0} ''' sentences = [{'sentence': x, 'index' : i} for i, x inenumerate(single_sentences_list)]
#利用滑动窗口分段 defcombine_sentences(sentences, buffer_size=1): combined_sentences = [ ' '.join(sentences[j]['sentence'] for j inrange(max(i - buffer_size, 0), min(i + buffer_size + 1, len(sentences)))) for i inrange(len(sentences)) ] # 更新原始字典列表,添加组合后的句子 for i, combined_sentence inenumerate(combined_sentences): sentences[i]['combined_sentence'] = combined_sentence
#根据阈值划分 breakpoint_percentile_threshold = 95 breakpoint_distance_threshold = np.percentile(distances, breakpoint_percentile_threshold) print("距离的第95个百分位阈值是:", breakpoint_distance_threshold) # 找到所有距离大于阈值的点的索引,这些索引就是我们的切分点 indices_above_thresh = [i for i, x inenumerate(distances) if x > breakpoint_distance_threshold]
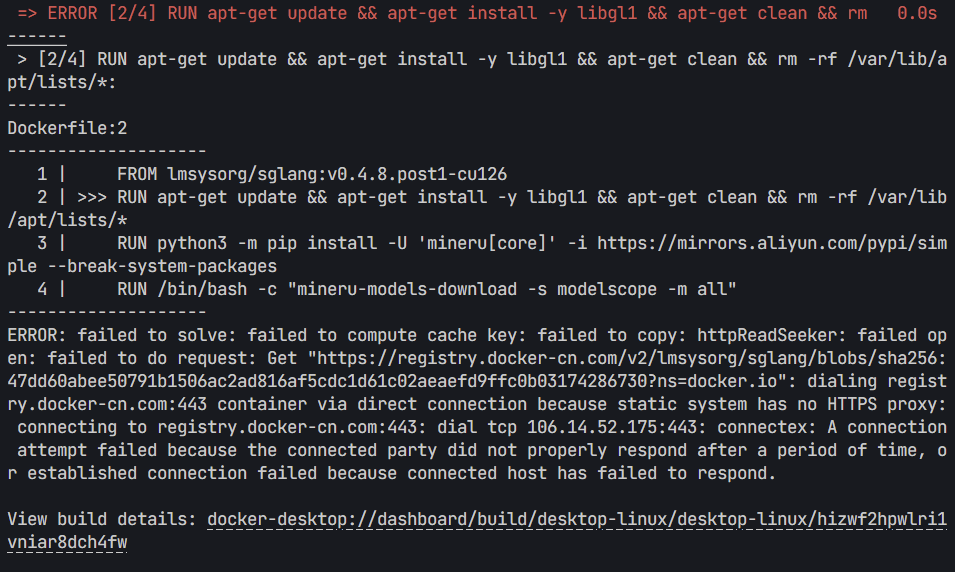
lmsysorg/sglang:v0.4.8.post1-cu126: failed to resolve source metadata for docker.io/lmsysorg/sglang:v0.4.8.post1-cu126: unexpected status from HEAD request to https://yaj2teeh.mirror.aliyuncs.com/v2/lmsysorg/sglang/manifests/v0.4.8.post1-cu126?ns=docker.io: 403 Forbidden
deffindMinCoins(coins, amount): coins.sort(reverse=True) # 降序排序 res = [] for i inrange(len(coins)): while amount >= coins[i]: res.append(coins[i]) amount -= coins[i] return res
defprim(graph, start=0): V = len(graph) # 顶点数量 selected = [False] * V # 标记顶点是否已加入生成树 key = [sys.maxsize] * V # 记录各顶点到生成树的最小权重 parent = [-1] * V # 记录最小生成树的父节点
key[start] = 0# 起始顶点的权值设为0
for _ inrange(V): # 找到当前未选顶点中 key 最小的顶点 u min_key = sys.maxsize u = -1 for v inrange(V): ifnot selected[v] and key[v] < min_key: min_key = key[v] u = v if u == -1: break# 无连通顶点,生成树结束 selected[u] = True# 将 u 加入生成树
# 更新 u 的所有邻接顶点的 key 值 for v inrange(V): if graph[u][v] > 0andnot selected[v] and graph[u][v] < key[v]: key[v] = graph[u][v] parent[v] = u # 记录 v 的父节点为 u
def unbounded_knapsack_2d(weights, values, capacity): n = len(weights) dp = [[0] * (capacity + 1) for _ in range(n + 1)]
for i in range(1, n + 1): for j in range(1, capacity + 1): if weights[i-1] <= j: dp[i][j] = max( dp[i-1][j], dp[i][j - weights[i-1]] + values[i-1] ) else: dp[i][j] = dp[i-1][j] return dp[n][capacity]
def optimal_bst(p, q, n): # 初始化 dp 和 w 数组(大小为 (n+2) x (n+2),避免越界) dp = [[0] * (n+2) for _ in range(n+2)] w = [[0] * (n+2) for _ in range(n+2)] root = [[0] * (n+2) for _ in range(n+2)]
# 初始化虚拟键的权重 for i in range(n+1): w[i][i] = q[i] # 填表顺序:链长从 1 到 n for l in range(1, n+1): # l 为关键字数量 for i in range(n - l + 1): j = i + l w[i][j] = w[i][j-1] + p[j] + q[j] dp[i][j] = float('inf') # 枚举根节点 r(i < r ≤ j) for r in range(i+1, j+1): cost = dp[i][r-1] + dp[r][j] if cost < dp[i][j]: dp[i][j] = cost root[i][j] = r return dp[0][n], root
''' https://leetcode.cn/problems/n-queens/ ''' n=4 ans=[] path=[] onpath=[False]*n#记录哪一列有皇后 diag1=[False]*(2*n-1)#记录主对角线是否有皇后 diag2=[False]*(2*n-1)#记录副对角线是否有皇后 def dfs(row,path:list): if row==n: #print(path) chess=[] # 生成棋盘 for i in range(n): chess.append("."*path[i]+"Q"+"."*(n-path[i]-1)) ans.append(chess) return for col in range(n): if isvalid(row,col): path.append(col)#放置皇后 onpath[col]=diag1[row+col]=diag2[row-col+n-1]=True dfs(row+1,path)#递归下一行 path.pop()#回溯,取消放置 onpath[col]=diag1[row+col]=diag2[row-col+n-1]=False def isvalid(row,col): if onpath[col] or diag1[row+col] or diag2[row-col+n-1]: return False return True dfs(0,path) print(ans)