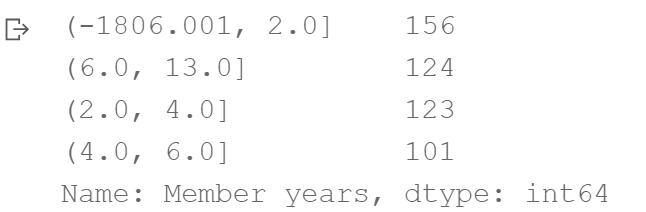import pandas as pd # sklearn是一个用于机器学习的Python库,提供了各种分类、回归、聚类算法, # 包括支持向量机、随机森林、梯度提升等。它还包含了用于数据预处理、特征提取和模型选择的工具。 from sklearn.preprocessing import StandardScaler data = pd.read_csv('user_review.csv')
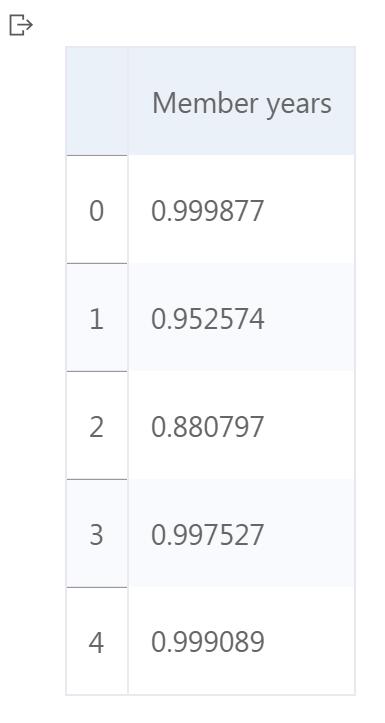
User country User continent Member years Traveler type
75 USA North America -1806 Solo
143 USA North America 13 Couples
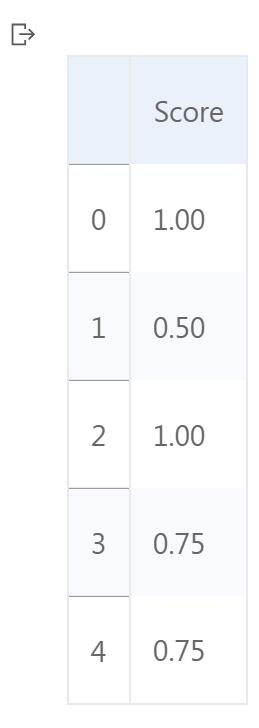
Hotel name Hotel stars Nr. rooms Score
75 Treasure Island- TI Hotel & Casino 4.0 2884 5
143 Caesars Palace 5.0 3348 4
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error print ('the value of R-squared of LR is',r2_score(y_test,lr_y_predict)) print ('the MSE of LR is',mean_squared_error(y_test,lr_y_predict)) print ('the MAE of LR is',mean_absolute_error(y_test,lr_y_predict))
the value of R-squared of LR is 0.7250808093832966
the MSE of LR is 23.56944609104811
the MAE of LR is 3.302381007591344
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error print('the value of R-squared of Ridge is',r2_score(y_test,rd_y_predict )) print('the MSE of Ridge is',mean_squared_error(y_test,rd_y_predict)) print('the MAE of Ridge is',mean_absolute_error(y_test,rd_y_predict))
the value of R-squared of Ridge is 0.7279447933421523
the MSE of Ridge is 23.323910246960786
the MAE of Ridge is 3.2535718613670053
from sklearn.datasets import load_boston import matplotlib.pyplot as plt from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
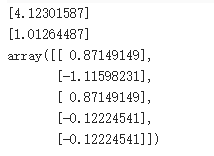
# 模型训练 from sklearn.linear_model import LinearRegression lr = LinearRegression() # 模型训练:我们使用 LogisticRegression(线性回归常用于回归问题,但 Logistic Regression 更适合于二分类问题) lr = LogisticRegression(max_iter=10000) # 设置最大迭代次数为10000以确保收敛
# 训练模型 lr.fit(X_train, y_train)
# 模型预测:对测试集进行预测 lr_y_predict = lr.predict(X_test)
# 模型评估 print('The accuracy score of LR is', accuracy_score(y_test, lr_y_predict)) # 准确率 print('The f1 score of LR is', f1_score(y_test, lr_y_predict)) # F1 分数 print('The auc of LR is', roc_auc_score(y_test, lr_y_predict)) # AUC(曲线下面积)
The accuracy score of LR is 0.9117647058823529
The f1 score of LR is 0.8695652173913043
The auc of LR is 0.89002079002079
f:\project python\.conda\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function load_boston is deprecated; `load_boston` is deprecated in 1.0 and will be removed in 1.2.
The Boston housing prices dataset has an ethical problem. You can refer to
the documentation of this function for further details.
The scikit-learn maintainers therefore strongly discourage the use of this
dataset unless the purpose of the code is to study and educate about
ethical issues in data science and machine learning.
In this special case, you can fetch the dataset from the original
source::
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
Alternative datasets include the California housing dataset (i.e.
:func:`~sklearn.datasets.fetch_california_housing`) and the Ames housing
dataset. You can load the datasets as follows::
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
for the California housing dataset and::
from sklearn.datasets import fetch_openml
housing = fetch_openml(name="house_prices", as_frame=True)
for the Ames housing dataset.
warnings.warn(msg, category=FutureWarning)