ragangything
RAG-Anything
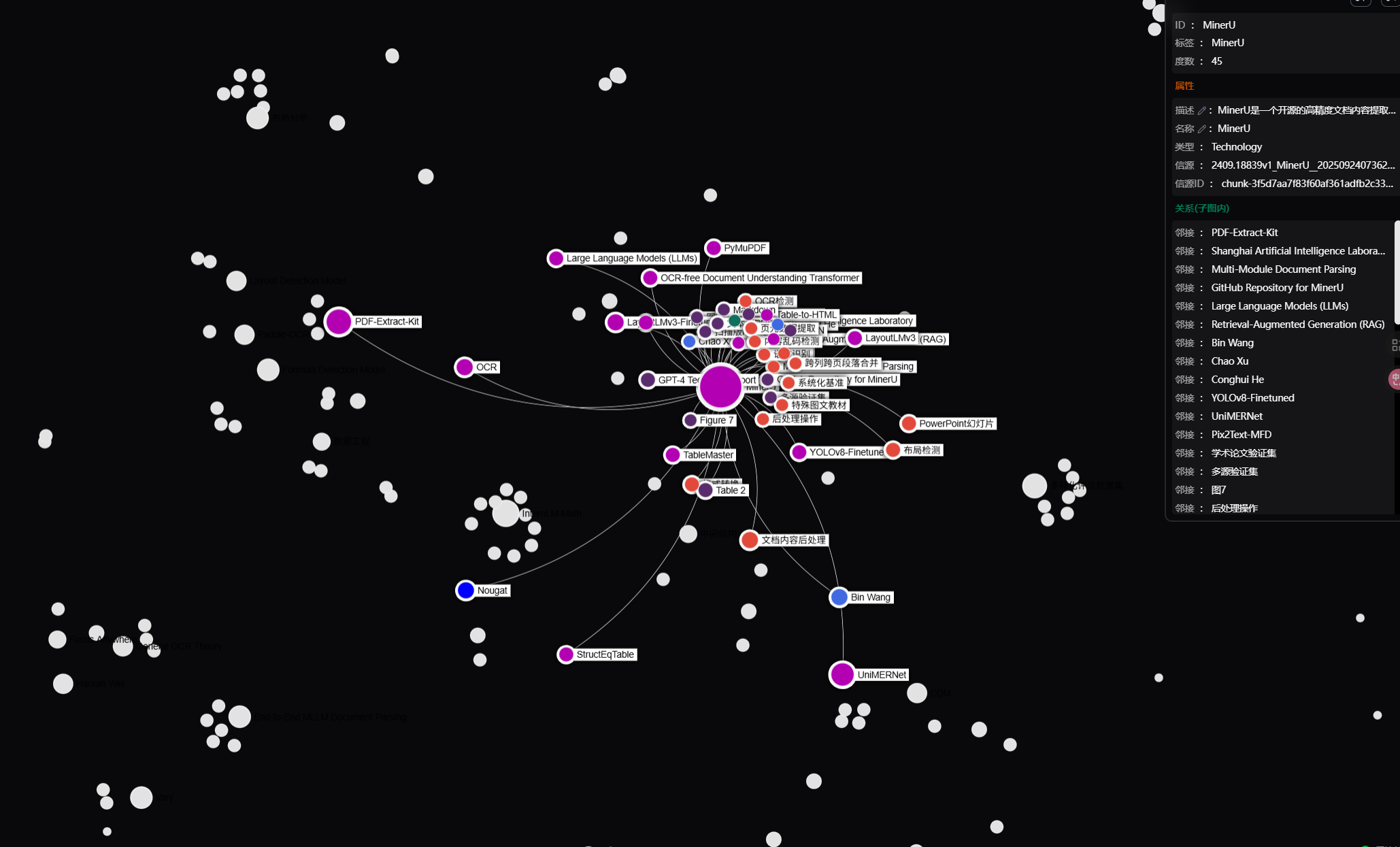
RAG-Anything是一个综合性多模态文档处理RAG系统。该系统能够无缝处理和查询包含文本、图像、表格、公式等多模态内容的复杂文档,提供完整的检索增强(RAG)生成解决方案。
解析方式
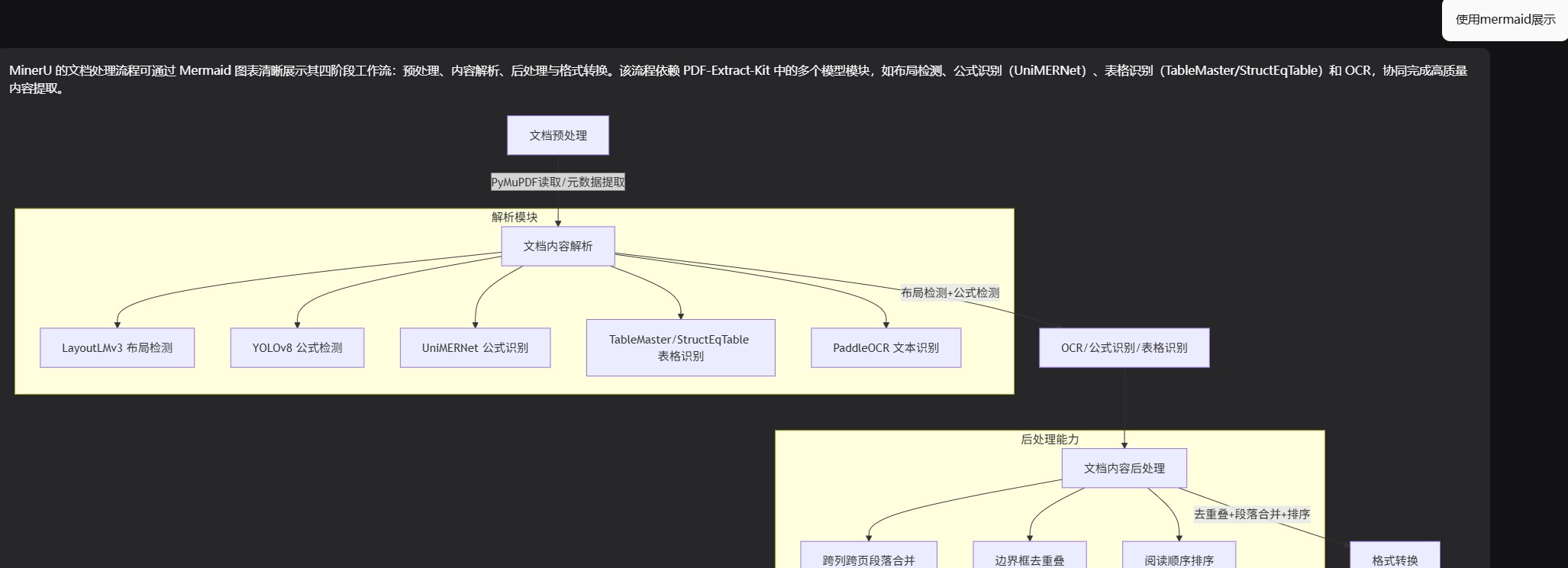
process_document_complete执行流程
- 初始化依赖: await self._ensure_lightrag_initialized() ,保证 LightRAG 已就绪。
- 读取配置默认:对 output_dir / parse_method / display_stats 应用默认值。
- 记录开始日志: Starting complete document processing: {file_path} 。
- 第一步(解析):调用 parse_document(…) ,返回
- content_list : 解析出的内容列表(混合文本块与多模态项的统一结构)。
- content_based_doc_id : 基于内容生成的文档ID(用于未显式提供 doc_id 时)。
- 文档ID确定:若未传入 doc_id ,用 content_based_doc_id 作为本次处理的文档标识。
- 第二步(拆分): text_content, multimodal_items = separate_content(content_list) ,将纯文本与多模态项分离。
- 第二步半(上下文源设置):若存在多模态项且类实现了 set_content_source_for_context ,调用它以建立“内容源 → 上下文”映射,用于后续多模态处理更好地提取上下文。
- 第三步(插入文本):如果 text_content 非空:
- 取 file_name = os.path.basename(file_path) ,作为 file_paths 元信息传入。
- 调用 insert_text_content(…) 将文本写入 LightRAG 索引,支持 split_by_character 与 split_by_character_only 控制切分方式,并统一使用同一个 ids=doc_id 以保证该文档的索引一致性。
- 第四步(处理多模态):
- 若 multimodal_items 非空:调用 await self._process_multimodal_content(multimodal_items, file_path, doc_id) 用专用处理器写入图片、表格、公式等相关产物并建立索引/缓存。
- 若为空:调用 _mark_multimodal_processing_complete(doc_id) 标记该文档的多模态处理阶段已完成(即使没有多模态项也要显式完成,以便状态一致)。
- 记录完成日志: Document {file_path} processing complete! 。
存储方式
检索方式
功能区别
- aquery :纯文本查询入口,直接把你的问题和检索参数封装到 QueryParam 并调用 LightRAG。若已配置视觉模型函数( vision_model_func ),默认会自动启用图像增强;可通过传入 vlm_enhanced=False 强制走纯文本。
- aquery_with_multimodal :主动把你提供的多模态素材(图片、表格、公式等)先“描述压缩”为文本(用已注册的处理器生成说明),把这些说明拼接到查询中,然后再执行 aquery 做检索与问答;内置结果缓存(按素材和参数归一化生成 key)。
- aquery_vlm_enhanced :在检索生成的原始提示( only_need_prompt=True )里扫描图片路径,保持原路径并插入标记,将图片转为 base64,与文本一并发给视觉模型生成最终答案;不把图转成文字摘要,而是让 VLM直接“看图”。需要你已提供 vision_model_func ,否则会报错。
aquery_vlm_enhanced执行流程
- 检查 VLM 可用:若 vision_model_func 未配置,抛出 ValueError 。
- 确保 LightRAG 就绪:调用 self._ensure_lightrag_initialized() ,保证你之前已处理并建好索引/图谱。
- 清理图片缓存:删除上一次查询残留的 self._current_images_base64 。
- 只取检索提示:构造 QueryParam(mode=mode, only_need_prompt=True, **kwargs) ,调用 self.lightrag.aquery(…) 拿到“原始提示”(包含检索到的上下文与可能的图片路径),此时不向 LLM发起最终回答。
- 解析图片路径:调用 self._process_image_paths_for_vlm(raw_prompt) ,用正则匹配诸如 Image Path: …(.jpg|.png|…) 的行,对路径做 validate_image_file 验证并转 base64,往提示里插入供 VLM使用的标记;返回增强后的提示与图片计数。
- 无图兜底:若 images_found == 0 ,直接退回普通查询( QueryParam(mode=mode, **kwargs) )走文本 LLM(即不做看图增强)。
- 构建 VLM消息: self._build_vlm_messages_with_images(enhanced_prompt, query) 将“增强提示+图片(base64)”打包成 VLM需要的消息格式。
- 调用视觉模型: self._call_vlm_with_multimodal_content(messages) ,由你的 vision_model_func 实际生成最终答案并返回。
为什么要转base64
心原因
- 远端不可读本地路径:检索提示里只有 Image Path: C:... 或 ./xxx.png ,VLM(常在云端或独立进程)无法直接访问你的本地文件系统,必须把图像的字节随请求一起发送。
- 标准化传输格式:多数 VLM 接口以 JSON/HTTP 交互,原生不支持二进制;Base64 是通用的文本编码,易于嵌入到消息体或 data:image/png;base64,… 这样的数据 URI。
- 跨平台与健壮性:避免 Windows/中文路径、权限、相对路径等差异导致文件读取失败;编码后与工作目录无关,传到哪都能被解码。
- 兼容主流 API 形态:OpenAI、LM Studio、部分本地/私有 VLM 都支持用 Base64 提供图像数据;RAGAnything 将其统一为 vision_model_func 可消费的消息格式。
- 可缓存与复用:编码后可做哈希/去重与一次请求内复用( _current_images_base64 ),同时避免在日志或提示里暴露真实文件路径结构。
参考资料
python-dotenv
什么是 dotenv?
dotenv 是一个用于从 .env
文件中加载环境变量到程序中的工具。它广泛用于各种编程语言(如
Python、Node.js、Ruby 等),目的是把敏感信息(比如 API
密钥、数据库密码)和配置从代码中分离出来,避免硬编码,提高安全性与灵活性。
基本使用
1 | #安装 |
1 | #.env |
1 | from dotenv import load_dotenv |
在.gitignore增加
1 | # Environment variables |
| 写法 | 含义 |
|---|---|
.env |
只忽略名为 .env
的文件(精确匹配) |
*.env |
忽略所有以 .env
结尾的文件(通配符匹配) |
python内存管理-GIL
GIL是什么
GIL(Global Interpreter Lock,全局解释器锁) 是 CPython 解释器(Python 的官方实现)中的一个互斥锁(mutex),它确保同一时刻只有一个线程执行 Python 字节码。
🔒 互斥锁的定义:
互斥锁是一种同步原语,用于防止多个线程同时访问共享资源。
GIL 正是这样一把锁:
- 共享资源 = CPython 解释器的内部状态(如对象引用计数、内存管理器)
- 保护方式 = 任何线程要执行 Python 代码,必须先获取 GIL
为什么要设计GIL
GIL 的核心原因:CPython 的内存管理模型
🔑 关键点:
CPython 使用“引用计数(Reference Counting)”作为主要的内存管理机制,而引用计数的增减操作必须是原子的。
🔑 核心逻辑链:
Python(CPython)使用引用计数(Reference Counting)管理内存 ↓ 引用计数的增减必须是原子操作(否则会出错) ↓ 为了保证原子性,CPython 引入了 GIL(全局互斥锁) ↓ GIL 确保同一时刻只有一个线程能修改引用计数
什么是引用计数(Reference Counting)
在 CPython 中,每个 Python 对象(如
list, str, 自定义类实例)都有一个字段叫
ob_refcnt,记录“有多少变量/容器引用了它”。
1 | a = [1, 2, 3] # ob_refcnt = 1 |
当 ob_refcnt 降到 0
时,对象立即被销毁(内存回收)。
如果没有GIL
假设两个线程同时执行 b = a:
| 线程 A | 线程 B | 实际 ob_refcnt |
|---|---|---|
读取 ob_refcnt = 1 |
读取 ob_refcnt = 1 |
1 |
计算 1 + 1 = 2 |
计算 1 + 1 = 2 |
— |
写回 ob_refcnt = 2 |
写回 ob_refcnt = 2 |
2(但正确值应为 3!) |
👉 结果:引用计数错误 → 对象可能被提前释放(程序崩溃)或内存泄漏。
💥 这就是竞态条件(Race Condition):多个线程/进程并发访问共享资源时,最终结果依赖于它们的执行顺序或 timing(时序),导致程序行为不可预测、错误或崩溃。
为什么 Java/Go 不需要GIL?
| 语言 | 内存管理 | 是否需要全局锁 |
|---|---|---|
| Python (CPython) | 引用计数(运行时增减) | ✅ 需要(GIL) |
| Java / Go / C# | 垃圾回收(GC) | ❌ 不需要 |
| Rust | 编译期所有权检查 | ❌ 不需要 |
- GC 语言:对象分配/回收由专用 GC 线程处理,用户线程不直接操作引用计数
- Rust:内存安全在编译期保证,运行时无引用计数开销
什么是GC
GC(Garbage Collection,垃圾回收) 是现代编程语言中自动管理内存的核心机制。其核心思想为, 自动找出“不再使用的对象”,并回收其内存,无需程序员手动释放。
🆚 对比:手动管理 vs 自动管理
| 方式 | 代表语言 | 特点 |
|---|---|---|
| 手动管理 | C, C++ | 程序员用malloc/free或new/delete管理内存 →
容易出错(内存泄漏、野指针) |
| 自动管理 | Java, Go, C#, Python | 语言运行时自动回收内存 → 安全,但有性能开销 |
GC是如何工作的
主流 GC(如 Java、Go)使用 “可达性分析”(Reachability Analysis)判断对象是否存活:
🌳 核心概念:根对象(Roots)
- 全局变量
- 当前函数的局部变量
- CPU 寄存器中的引用
📌 判断规则:
从根对象出发,能通过引用链到达的对象 = 存活对象 无法到达的对象 = 垃圾(可回收)
python的程序并行
由于 CPython 的 GIL(全局解释器锁)存在:
- 多线程无法在多核 CPU 上并行执行 Python 字节码(尤其是 CPU 密集型任务);
- 但多进程可以绕过 GIL,每个进程拥有独立的解释器和内存空间,因此能真正并行,充分利用多核 CPU。
| 类型 | 是否受 GIL 限制 | 能否利用多核 | 适用场景 |
|---|---|---|---|
| 多线程(Threading) | ✅ 受限(CPU 任务串行) | ❌ CPU 任务不能✅ I/O 任务可以(因释放 GIL) | 网络请求、文件读写、数据库查询等 I/O 密集型 |
| 多进程(Multiprocessing) | ❌ 不受限 | ✅ 能(真并行) | 图像处理、模型推理、加密计算等 CPU 密集型 |
📌 注意:“并行”(parallelism)≠ “并发”(concurrency)
- 多线程在 Python 中实现的是 并发(交替执行),不是 并行(同时执行)(对 CPU 任务而言)。
参考资料
python异步编程-asyncio
asyncio是什么
asyncio 是 Python
标准库中的一个模块,用于编写异步(asynchronous)程序。它提供了一套完整的工具,让你可以用
async/await 语法编写并发代码,特别适合处理
I/O
密集型任务(比如网络请求、文件读写、数据库查询等),而不会阻塞整个程序。
概念学习
并发
并发(Concurrency)是一种“效果”——多个任务在一段时间内交替或同时推进。 它可以通过多种方式实现,常见的有:
- 多线程(Multithreading)
- 异步编程(Asynchronous programming,如 asyncio)
- 多进程(Multiprocessing)(严格说更偏向“并行”,但也支持并发)
进程(Process)、线程(Thread) 和 协程(Coroutine)
| 概念 | 定义 |
|---|---|
| 进程(Process) | 操作系统进行资源分配和调度的基本单位。它是程序的一次执行实例,拥有独立的虚拟地址空间、文件描述符表、环境变量、信号处理表等内核资源。 |
| 线程(Thread) | 进程内的执行流(execution context),是 CPU 调度的基本单位。同一进程内的多个线程共享该进程的地址空间和大部分资源(如堆、全局变量、打开的文件),但各自拥有独立的栈、寄存器状态和线程局部存储(TLS)。 |
| 协程(Coroutine) | 一种用户态的轻量级并发原语,属于协作式多任务(cooperative
multitasking)模型。协程的切换由程序显式控制(如通过
await 或
yield),不依赖操作系统调度,上下文切换在用户空间完成,无内核介入。 |
线程”在 CPU 核心上运行。 进程是资源容器,线程是执行单位。
内存与资源共享模型
| 模型 | 地址空间 | 堆(Heap) | 栈(Stack) | 同步机制 |
|---|---|---|---|---|
| 进程 | 独立 | 独立 | 独立 | 需 IPC(如管道、消息队列、共享内存 + 信号量) |
| 线程 | 共享(同进程内) | 共享 | 独立(每个线程一个栈) | 需互斥锁(Mutex)、条件变量等防止数据竞争 |
| 协程 | 共享(同一线程内) | 共享 | 逻辑独立(由运行时管理协程栈或使用生成器状态) | 通常无需锁(因单线程串行执行),但需注意异步回调中的状态一致性 |
在 Python 中的实现
| 模型 | 标准库模块 | 关键 API |
|---|---|---|
| 进程 | multiprocessing |
Process, Pool, Queue,
Pipe, Manager |
| 线程 | threading |
Thread, Lock, Condition,
Semaphore |
| 协程 | asyncio + async/await |
async def, await,
asyncio.run(), create_task(),
gather() |
进程 是资源隔离与并行计算的基石;
线程 是操作系统级并发的传统手段,但在 Python 中受 GIL 限制;
协程 是高并发 I/O 的现代解决方案,以极低开销实现大规模并发,已成为 Python 异步编程的事实标准。
1 | 操作系统 |
当你运行一个 Python 脚本(如
python app.py),操作系统会:
- 创建一个新进程(Process)
- 加载 Python 解释器(CPython)
- 在该进程中启动主线程(Main Thread)
- 执行你的代码
📌 所以:一个正在运行的 Python 程序 = 1 个进程 + 至少 1 个线程(主线程)
但注意:
- 程序可以创建更多进程(通过
multiprocessing) - 程序可以创建更多线程(通过
threading) - 所以“一个程序”最终可能对应 多个进程、多个线程
Python 异步编程的核心机制
async def定义协程函数 → 返回 协程对象(Coroutine Object)await用于挂起当前协程,等待另一个协程或异步操作完成- 事件循环(Event Loop)(由
asyncio提供)负责:- 调度协程
- 管理 I/O 多路复用(如
epoll/kqueue) - 在 I/O 就绪时恢复对应协程
实战学习
sync_demo.py
1 | from time import sleep, perf_counter |
以上展示一份同步的代码,sleep用来模拟阻塞
1 | Fetching the URL |
async_demo.py
异步编程的三步核心流程:
1. 定义协程函数 → 2. 包装协程为任务 → 3. 建立事件循环
1 | from time import sleep, perf_counter |
以上则是改为了异步的代码
1 | Fetching the url |
协程函数
协程函数(Coroutine Function)是 Python 中使用
async def
语法定义的函数,它是异步编程的核心构建单元。调用协程函数不会立即执行其内部代码,而是返回一个
协程对象(Coroutine Object),该对象必须由事件循环(如
asyncio)驱动或通过 await
在另一个协程中调用,才能真正执行。
1 | import asyncio |
1 | <coroutine object coroutine_func at 0x000001958D88A4B0> |
由输出可见,coroutine object,返回的是一个协程对象
await关键字
await 是 Python
异步编程中的核心关键字,它的作用是:
暂停当前协程的执行,等待一个“可等待对象”(awaitable)完成,并获取其结果,同时将控制权交还给事件循环,使其能运行其他任务。
✅ 三大功能:
- 挂起(Suspend):当前协程在此处暂停,不阻塞线程。
- 等待(Wait):等待一个异步操作(如网络请求、文件读写、定时器)完成。
- 恢复(Resume):当被等待的对象完成后,协程从此处恢复执行,并拿到结果。
⚠️ 关键:
await不会阻塞整个线程,而是让事件循环去执行其他就绪的协程。
事件循环(Event Loop)与任务(Task)
事件循环(Event Loop)
是异步编程的核心引擎,尤其在 Python 的
asyncio 模型中,它是驱动协程执行、管理异步
I/O、调度任务的中枢系统。
事件循环是一个程序结构,用于监听和分发事件或消息,实现非阻塞 I/O 和协作式多任务调度。
在 Python asyncio 中,事件循环:
- 维护一个待执行协程队列
- 管理定时器(如
asyncio.sleep) - 使用操作系统提供的 I/O 多路复用机制(如 Linux 的
epoll、macOS 的kqueue、Windows 的IOCP)来高效监听大量文件描述符(如 socket) - 在 I/O 就绪时,恢复对应的协程
那事件循环如何知道哪些协程可以执行,哪些协程需要暂停呢
在 Python 异步编程(特别是
asyncio)中,任务(Task)
是是对协程(Coroutine)的封装,用于被事件循环调度和并发执行。
Task是asyncio中表示“未来会完成的异步操作”的对象,它是Future的子类,用于包装协程并自动调度其执行。
核心作用:
- 将协程注册到事件循环中,使其能够并发运行(而非顺序等待)
- 提供状态管理(如是否完成、是否取消、结果或异常)
- 支持取消操作(
task.cancel()) - 允许多次
await(协程对象只能await一次,但Task可以)
1 | import asyncio |
1 | 开始 A |
💡 Task 是实现并发的关键:它让多个协程“同时启动”,而不是“一个接一个等”。
asyncio.gather
asyncio.gather用于并发运行多个 awaitable 对象(如协程、Task、Future),并按顺序返回它们的结果列表。
默认:任意一个任务出错,其他任务会被取消(除非
return_exceptions=True)
1 | async def main(): |
1 | Fetching the url |
asyncio.as_completed
asyncio.as_completed返回一个异步迭代器(async iterator),按任务完成的先后顺序,逐个产出已完成的 awaitable 对象(通常是 Task 或 Future)。
1 | results = asyncio.as_completed([ |
特点:先完成的任务先被处理,无需等待所有任务结束
asyncio.to_thread
await asyncio.to_thread(func, \*args)在默认线程池中运行同步函数
func(*args),并返回结果。 它是
loop.run_in_executor(None, func, *args)
的高层封装。
1 | import asyncio |
aiohttp和aiofiles
aiohttp:异步 HTTP 客户端与服务器框架
1 | import aiohttp |
aiofiles
是一个为标准文件操作提供异步接口的库,允许你在
async/await
代码中安全地读写文件,而不会阻塞事件循环。
1 | import aiofiles |
参考资料
python设计模式
为什么要有设计模式
1 | class DatabaseConnection: |
这是数据库连接类的范例,其存在以下问题
- 数据库连接信息(主机、端口、用户名、密码)直接写在代码中,缺乏配置管理,难以在不同环境间切换,如果要更改数据库的信息,就要更改项目中每一处的连接数据库的参数,难以维护
- 每次都需要手动传入相同类型的参数,增加出错的风险
工厂模式(Factory Pattern)
工厂模式 是一种创建型设计模式,它提供了一种创建对象的接口,但让子类决定实例化哪一个类。换句话说:把对象的创建过程封装起来,调用者不需要关心具体创建的是哪个类,只需要知道“我要一个某种类型的东西”。
1 | def connection_factory(db_type): |
将数据库的配置信息提取到config.py
1 | #factory_pattern.py |
1 | #config.py |
为什么要这么做
- 所有配置信息都在一个地方,便于统一管理和维护
- 易于修改 :配置变更不需要修改业务逻辑代码
工厂模式的核心就是工厂函数
工厂函数是一个返回对象的函数(而不是类),它封装了对象的创建逻辑,根据输入参数决定返回哪种具体对象。
建造者模式(Builder Pattern)
当你需要创建一个有很多属性、配置步骤繁多的对象时(比如一辆汽车、一个 HTTP 请求、一个数据库连接配置),直接用构造函数会非常混乱。 建造者模式通过“分步构建 + 最终组装”的方式,让创建过程清晰、灵活、可读性强。
1 | class DatabaseConnectionBuilder: |
单例模式(Singleton Pattern)
单例模式确保一个类只有一个实例,并提供一个全局访问点来获取该实例。
换句话说: 无论你调用多少次“创建对象”,返回的始终是同一个对象。
1 | class DatabaseConnection: |
参考资料
Python项目结构和打包
Python项目结构和打包
pip install 的本质
从 PyPI(默认)或其他源(如私有仓库、本地文件)查找指定名称的包,下载对应的.whl文件
whl文件
.whl是 Wheel 的缩写,是 Python 的一种标准打包格式(PEP 427 定义)。- 它本质上是一个 ZIP 格式的压缩包,扩展名改为
.whl。
安装 .whl 文件
1 | pip install package_name.whl |
hachling
hatchling 是 Python
生态中一个现代的、轻量级的构建后端(build
backend),主要用于将 Python 项目打包成可分发的格式(如
.whl 或源码包)。它是 Hatch项目的一部分,由 PyPA(Python
Packaging Authority)推荐使用。
在pyproject.toml添加
1 | [build-system] |
当你运行:
1 | pip install . |
如果项目配置了 hatchling 作为构建后端,pip
或 build 工具就会调用 hatchling
来完成打包和安装。
例如以下项目结构
1 | my_project/ |
想让项目的其他文件使用自己编写的包,在pyproject.toml增加
1 | # 👇 新增:显式声明包位置 |
在项目根目录(my_project/)执行:
1 | uv pip install -e . |
✅ 这会把
src/my_utils/注册为一个可导入的包。
src layout
src layout(也称为 src 布局 或
src 目录结构)是 Python
项目中一种推荐的源代码组织方式,其核心思想是:将你的
Python 包(package)放在一个名为 src/
的子目录下,而不是直接放在项目根目录中。
❌ 传统布局(不推荐)
1 | my_project/ |
✅ src 布局(推荐)
1 | my_project/ |
uv build和uv pip install .什么区别
一、uv build
✅ 作用:构建分发包(不安装)
- 调用项目的构建后端(如
hatchling、setuptools等)。 - 生成标准的分发文件:
- 一个 Wheel 文件(
.whl) - 一个 源码分发包(sdist,
.tar.gz)
- 一个 Wheel 文件(
- 输出到项目根目录下的
dist/文件夹。 - 不会将包安装到当前 Python 环境中。
🔧 示例:
1 | uv build |
输出: 1
2dist/my_package-0.1.0-py3-none-any.whl
dist/my_package-0.1.0.tar.gz
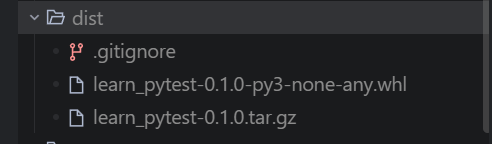
二、uv pip install .
✅ 作用:安装当前项目到当前环境
- 首先(隐式)构建项目(类似
uv build的过程)。 - 然后将构建结果安装到当前激活的 Python 环境(如虚拟环境或系统环境)。
- 安装后,你可以在 Python 中
import该包。 - 默认是 “非可编辑安装”(即代码改动不会自动生效,除非重新安装)。
🔧 示例:
1 | uv pip install . |
效果: - 包被安装到 site-packages/ - 可在 Python 中
import my_package
Editable install(可编辑安装)
Editable install(可编辑安装) 是 Python 包管理中的一种安装模式,它让你在安装一个包的同时,保留对源代码的直接引用。
1 | uv pip install -e . |
- 核心机制:
- 不复制代码到
site-packages/。 - 而是在
site-packages/中创建一个.pth文件 或my_package.egg-link,指向你本地项目中的src/(或包目录)。 - Python 解释器在导入时,会顺着这个链接去读你本地的源码。
- 不复制代码到
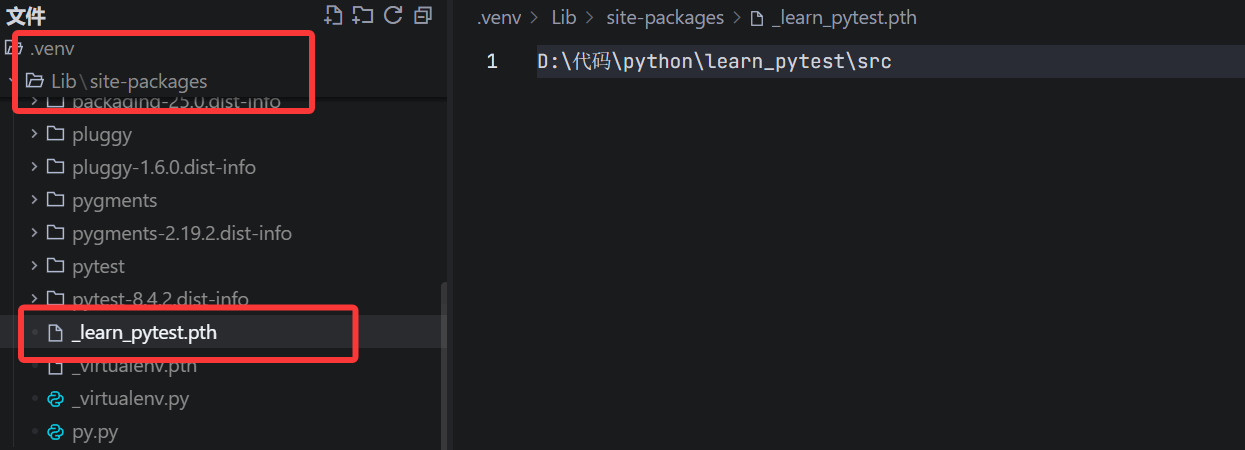
python是从哪里查找模块的
Python 查找模块(module)的机制由 模块搜索路径(module search
path) 决定,这个路径是一个字符串列表,存储在
sys.path 中。当你执行 import some_module
时,Python
会按顺序在这个列表中的每个目录里查找对应的模块文件。
可以通过以下代码查看当前 Python 的模块搜索路径:
1 | import sys |
sys.path 通常包含以下几类路径(顺序很重要):
- 脚本所在目录(或当前工作目录)
- 如果你运行
python /path/to/script.py,那么/path/to/会被加到sys.path[0]。 - 如果你运行
python进入交互模式,或运行python -c "...",则当前工作目录(os.getcwd()) 会被放在首位。 - ⚠️ 这是很多“意外导入”问题的根源(比如项目根目录下有同名包)。
- 环境变量
PYTHONPATH中的目录
- 类似系统的
PATH,你可以通过设置PYTHONPATH添加自定义搜索路径。 - 示例(Linux/macOS):
1
2export PYTHONPATH="/my/custom/modules:$PYTHONPATH"
python my_script.py - Windows(PowerShell):
1
$env:PYTHONPATH = "C:\my\custom\modules;" + $env:PYTHONPATH
- 标准库目录
- Python 自带的模块(如
os,sys,json)所在位置。 - 通常位于 Python 安装目录下的
lib/子目录中。
- 第三方包安装目录(site-packages)
- 通过
pip install、uv pip install等安装的包,会被放到site-packages目录。 - 路径可通过以下命令查看:
1
2
3import site
print(site.getsitepackages()) # 全局环境
print(site.getusersitepackages()) # 用户级安装
.pth文件中指定的路径
- 某些包(尤其是 editable install)会在
site-packages/中放置.pth文件,动态添加路径到sys.path。
参考资料
pytest
生成项目结构
1 | ─src |
生成calculator.py类用于后续学习pytest,以上树状结构使用tree /f生成
__init__.py 文件的作用
__init__.py
文件的主要作用是告诉Python解释器这个目录是一个Python包(package)。当Python看到一个包含
__init__.py
文件的目录时,就会将其识别为一个可导入的包。
1 | """ |
相对导入 : from .calculator import Calculator
- .calculator 表示从当前包内的 calculator.py 模块导入 Calculator 类
- 点号 . 表示相对导入,指向当前包
__all__ 列表 :
__all__ = ['Calculator']
- 定义了当使用 from pytest_demo import * 时会导入哪些对象
- 这是一个显式的公共API声明
pytest 的自动发现规则
pytest 会自动查找以下内容:
- 文件名:
test_*.py或*_test.py - 函数名:
test_*() - 类名:
Test*(类中方法也需以test_开头)
测试文件
1 | └─tests |
1 | from pytest_demo.calculator import Calculator |
运行 uv run pytest
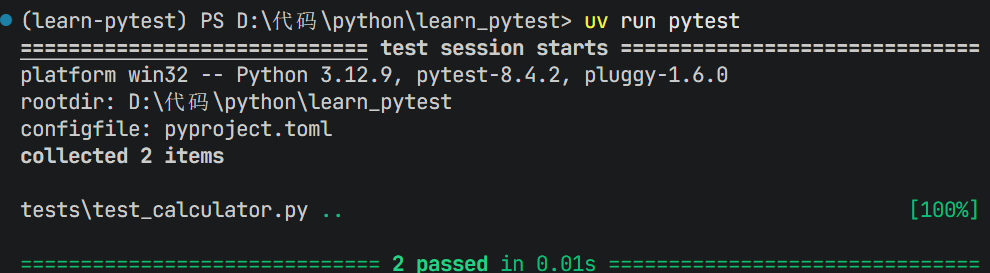
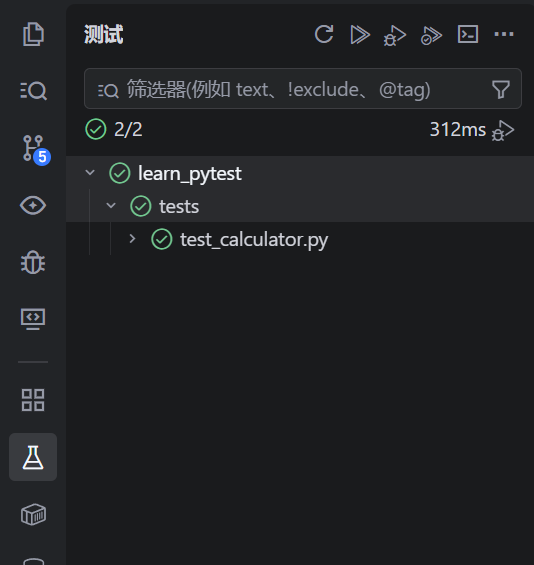
vscode支持pytest的可视化页面
ctrl+shift+p搜索

使用pytest.raises验证异常
1 | import pytest |
当你测试的函数应该在特定条件下抛出异常(比如传入非法参数、除零错误等),你可以用
pytest.raises 来验证:
“这段代码是否如预期那样,抛出了我们想要的异常?”
如果:
- ✅ 抛出了指定类型的异常 → 测试通过
- ❌ 没有抛出异常 → 测试失败
- ❌ 抛出了其他类型的异常 → 测试失败
@pytest.fixture提供测试参数
@pytest.fixture 是 pytest
中最核心、最强大的功能之一,它的作用是:
为测试函数提供可复用的、隔离的“测试依赖”(如对象、数据、资源、环境等),并管理它们的生命周期。
1 | #工厂函数 |
在 pytest 中,当测试函数(或另一个 fixture)的参数名与某个 fixture 的名称相同时,pytest 会自动调用该 fixture,并将其返回值传入测试函数。
这是 pytest 依赖注入机制的核心,也是 fixture 能“自动生效”的原因。
工厂函数(Factory Function) 是一种返回对象(通常是类的实例或其他函数)的函数,它的名字来源于“工厂模式”——就像工厂生产产品一样,这个函数“生产”对象。
scope 参数
1 | @pytest.fixture(scope="session") # 整个测试会话只启动一次 |
好处:避免创建多个实例
支持的作用域:
function(默认):每个测试函数class:每个测试类module:每个.py文件session:整个测试运行
自动管理资源生命周期
1 | pytest.fixture |
pydantic
@field_validator()
field_validator 是 Pydantic v2 的字段级校验与转换装饰器,用来在模型创建或赋值时,对指定字段做规则检查和/或值变换。例如
1 | @field_validator("name") |
这个验证器的作用是确保 name 字段不能为空,这个
_validate_name 验证器会在 Pydantic
模型实例化(创建对象)时自动调用
lightrag
算法流程
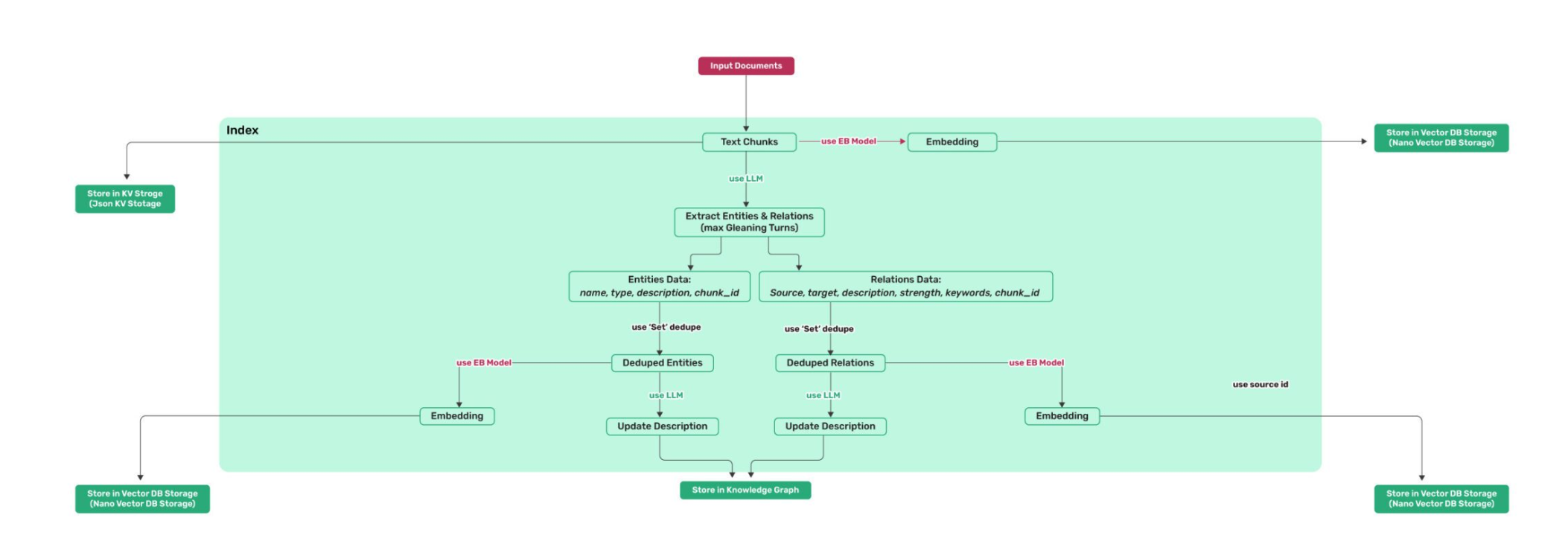
对文本进行分块后,分别存储在kvstorage与 VectorDB Storage
然后调用大模型进行实体与关系抽取(Extract Entities & Relations)
然后进行实体与关系的存储(Entities Data / Relations Data),去重后(Deduplication),再次调用embedding模型存储于VectorDB Storage
再次调用大模型,对关系与实体的描述进行精炼或合并(Update Description),并存储到Knowledge Graph
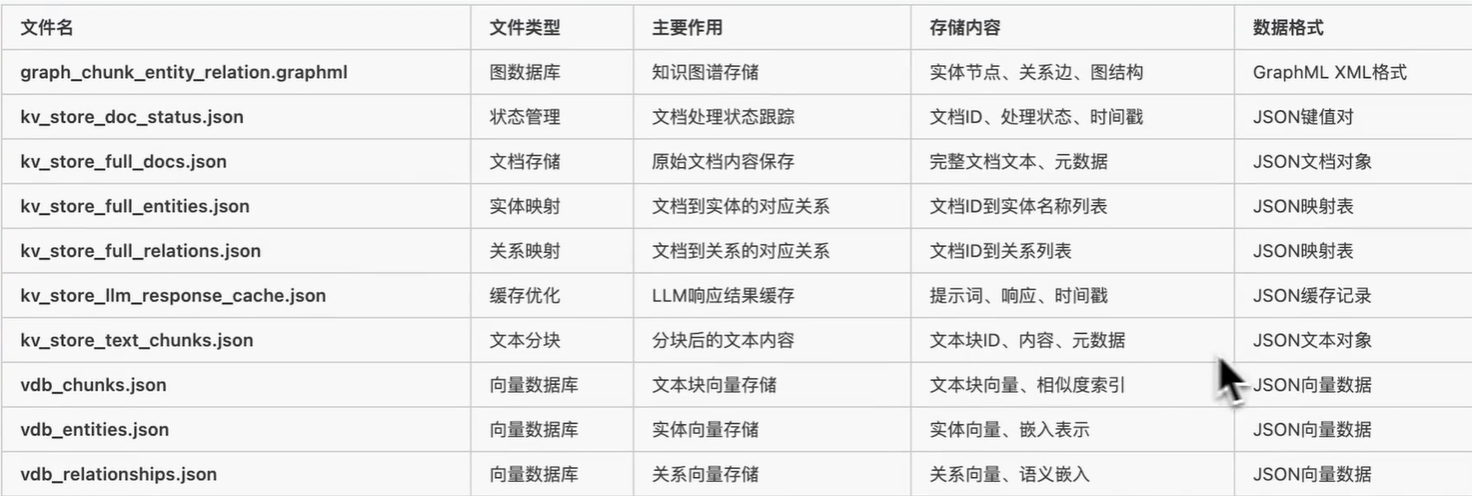
LightRAG 使用 4 种类型的存储用于不同目的:
- KV_STORAGE:llm 响应缓存、文本块、文档信息
- VECTOR_STORAGE:实体向量、关系向量、块向量
- GRAPH_STORAGE:实体关系图
- DOC_STATUS_STORAGE:文档索引状态
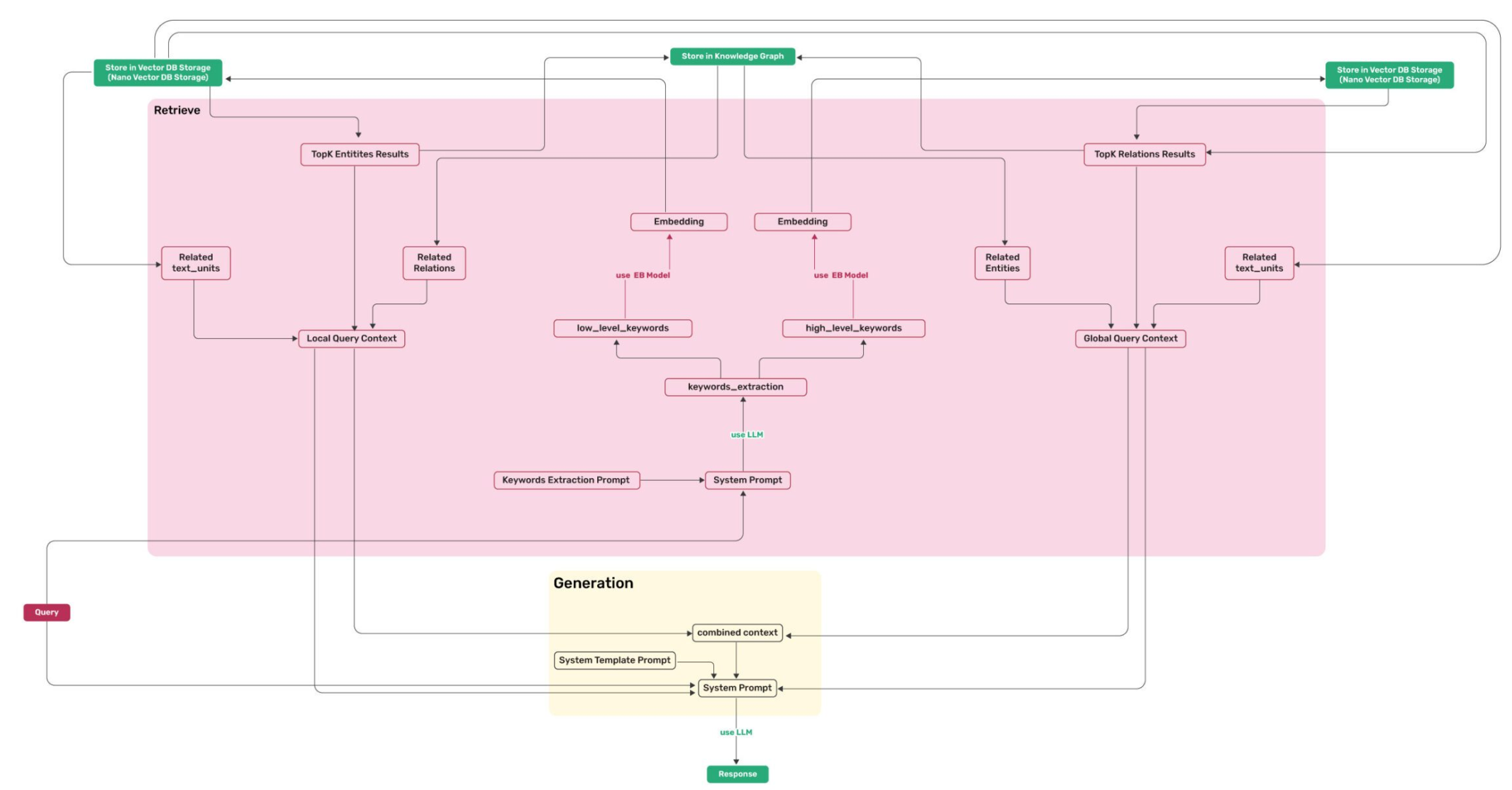
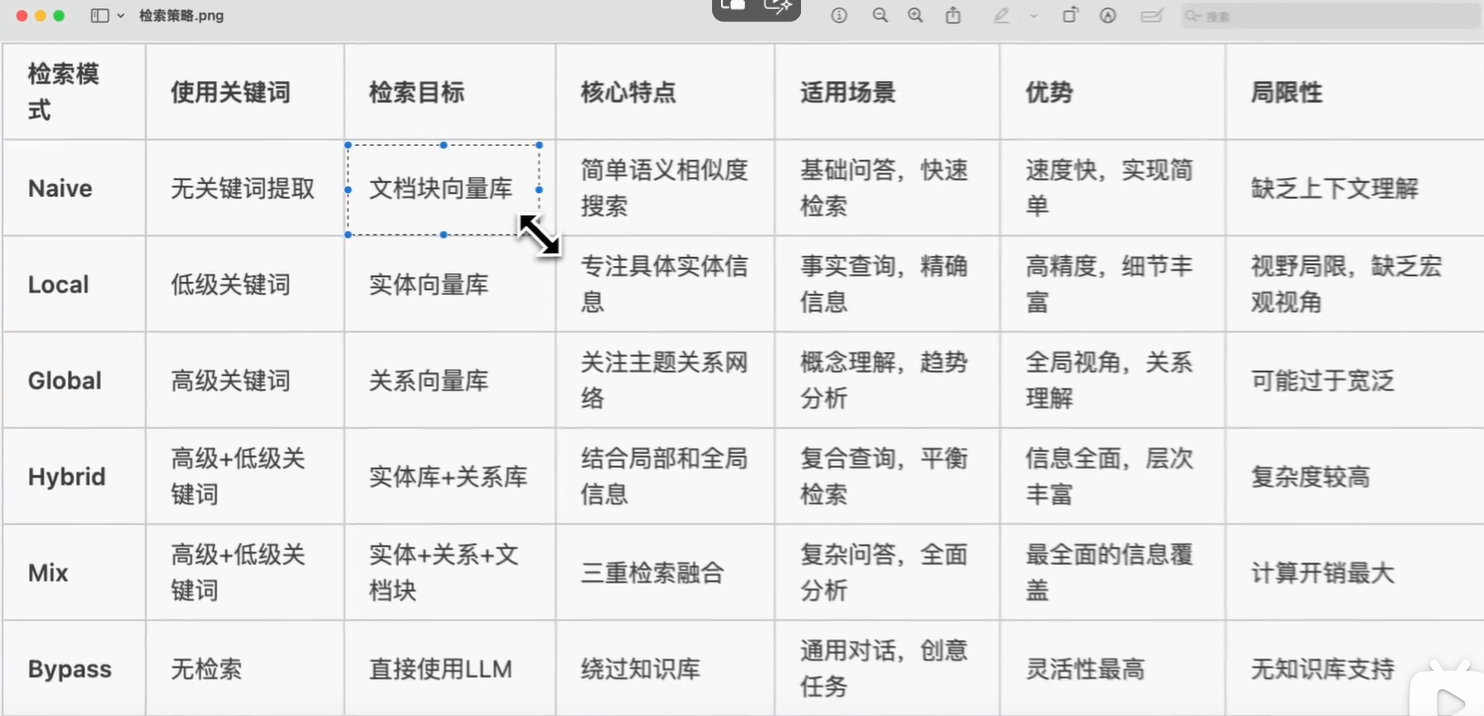
值得注意的是,local检索模式仅使用low_level_keywords,而global检索模式仅支持high_level_keywords,从算法流程图可以看出来,前者更侧重于检索实体,后者则侧重于关系
高关键词(High-level Keywords)用于捕获查询的核心意图和主题概念;低关键词(Low-level Keywords)用于识别具体的实体和细节信息
text_units的作用是:
- 每条实体/关系记录在 KV 里都挂着
chunk_ids列表。 - 把 Top-K 结果里的
chunk_ids做 合并 + 去重,得到原始文本块序号。 - 用序号去 Nano VectorDB 里把对应 text_units(原始句子/段落) 拉回,作为 上下文原始语料。
安装
安装LightRAG服务器
LightRAG服务器旨在提供Web UI和API支持。Web UI便于文档索引、知识图谱探索和简单的RAG查询界面。LightRAG服务器还提供兼容Ollama的接口,旨在将LightRAG模拟为Ollama聊天模型。这使得AI聊天机器人(如Open WebUI)可以轻松访问LightRAG。
1 | pip install "lightrag-hku[api]" |
在此获取LightRAG docker镜像历史版本: LightRAG Docker Images
安装 LightRAG Core
1 | pip install lightrag-hku |
LightRAG 服务器和 WebUI
LightRAG/lightrag/api/README-zh.md at main · HKUDS/LightRAG
LightRAG 服务器旨在提供 Web 界面和 API 支持。Web 界面便于文档索引、知识图谱探索和简单的 RAG 查询界面。
使用环境变量来配置 LightRAG 服务器。
1 | LLM_BINDING=openai |
启动
1 | lightrag-server |
这是因为每次启动时,LightRAG Server会将.env文件中的环境变量加载至系统环境变量,且系统环境变量的设置具有更高优先级。
启动时可以通过命令行参数覆盖.env文件中的配置。常用的命令行参数包括:
--host:服务器监听地址(默认:0.0.0.0)--port:服务器监听端口(默认:9621)--working-dir:数据库持久化目录(默认:./rag_storage)--input-dir:上传文件存放目录(默认:./inputs)--workspace: 工作空间名称,用于逻辑上隔离多个LightRAG实例之间的数据(默认:空)
启动多个LightRAG实例
所有实例共享一套相同的.env配置文件,然后通过命令行参数来为每个实例指定不同的服务器监听端口和工作空间。你可以在同一个工作目录中通过不同的命令行参数启动多个LightRAG实例。例如:
1 | # 启动实例1 |
运行
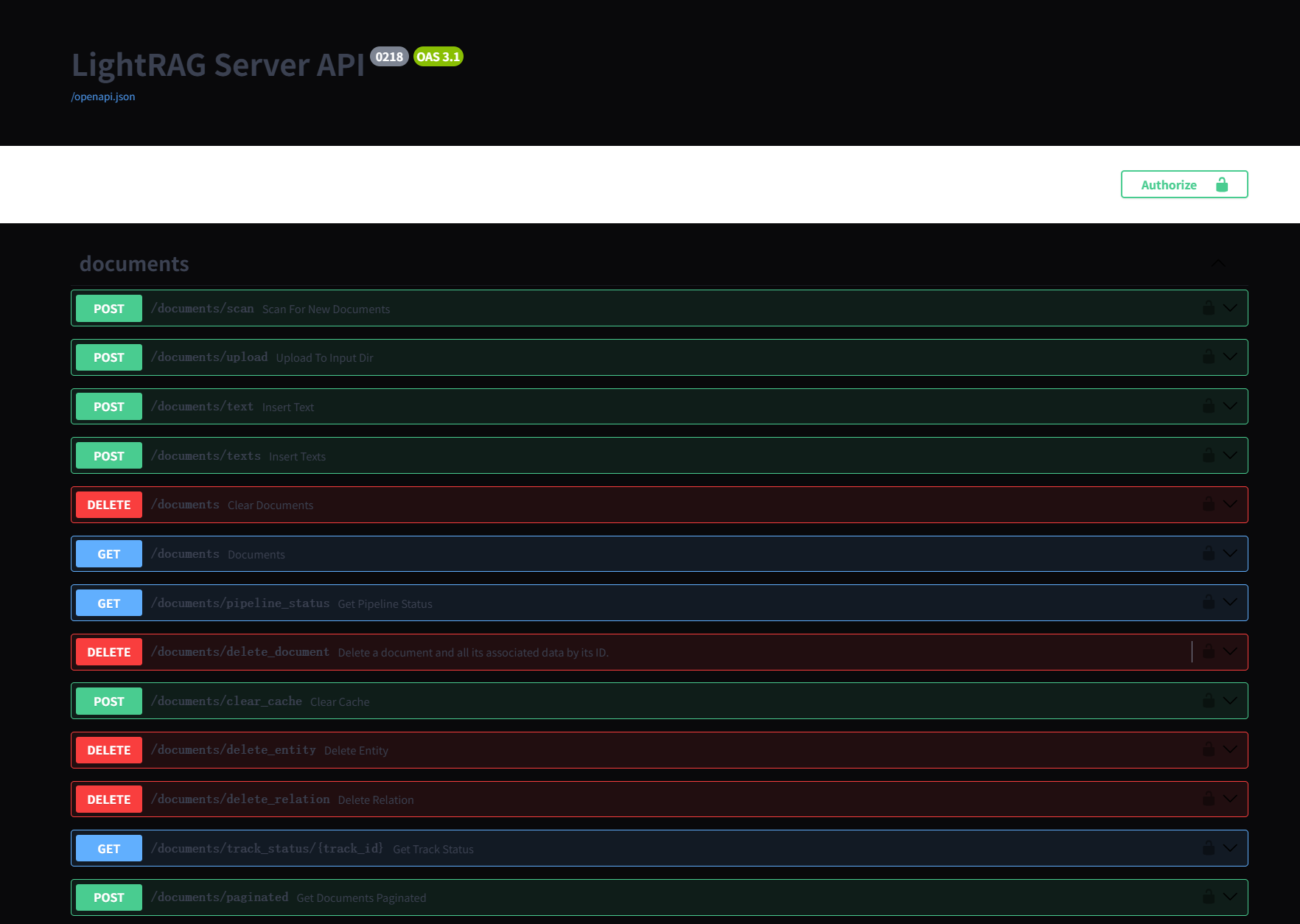
LightRAG的数据隔离
需要通过配置工作空间来实现数据隔离,否则不同实例的数据将会出现冲突并被破坏。
LightRAG 使用 4 种类型的存储用于不同目的:
- KV_STORAGE:llm 响应缓存、文本块、文档信息
- VECTOR_STORAGE:实体向量、关系向量、块向量
- GRAPH_STORAGE:实体关系图
- DOC_STATUS_STORAGE:文档索引状态
每种存储类型都有多种存储实现方式。LightRAG Server默认的存储实现为内存数据库,数据通过文件持久化保存到WORKING_DIR目录。LightRAG还支持PostgreSQL、MongoDB、FAISS、Milvus、Qdrant、Neo4j、Memgraph和Redis等存储实现方式。
您可以通过环境变量选择存储实现。例如,在首次启动 API 服务器之前,您可以将以下环境变量设置为特定的存储实现名称:
1 | LIGHTRAG_KV_STORAGE=PGKVStorage |
文档和块处理逻辑说明
LightRAG
中的文档处理流程有些复杂,分为两个主要阶段:提取阶段(实体和关系提取)和合并阶段(实体和关系合并)。有两个关键参数控制流程并发性:并行处理的最大文件数(MAX_PARALLEL_INSERT)和最大并发
LLM 请求数(MAX_ASYNC)。工作流程描述如下:
MAX_ASYNC限制系统中并发 LLM 请求的总数,包括查询、提取和合并的请求。LLM 请求具有不同的优先级:查询操作优先级最高,其次是合并,然后是提取。MAX_PARALLEL_INSERT控制提取阶段并行处理的文件数量。MAX_PARALLEL_INSERT建议设置为2~10之间,通常设置为MAX_ASYNC/3,设置太大会导致合并阶段不同文档之间实体和关系重名的机会增大,降低合并阶段的效率。- 在单个文件中,来自不同文本块的实体和关系提取是并发处理的,并发度由
MAX_ASYNC设置。只有在处理完MAX_ASYNC个文本块后,系统才会继续处理同一文件中的下一批文本块。 - 当一个文件完成实体和关系提后,将进入实体和关系合并阶段。这一阶段也会并发处理多个实体和关系,其并发度同样是由
MAX_ASYNC控制。 - 合并阶段的 LLM 请求的优先级别高于提取阶段,目的是让进入合并阶段的文件尽快完成处理,并让处理结果尽快更新到向量数据库中。
- 为防止竞争条件,合并阶段会避免并发处理同一个实体或关系,当多个文件中都涉及同一个实体或关系需要合并的时候他们会串行执行。
- 每个文件在流程中被视为一个原子处理单元。只有当其所有文本块都完成提取和合并后,文件才会被标记为成功处理。如果在处理过程中发生任何错误,整个文件将被标记为失败,并且必须重新处理。
- 当由于错误而重新处理文件时,由于 LLM 缓存,先前处理的文本块可以快速跳过。尽管 LLM 缓存在合并阶段也会被利用,但合并顺序的不一致可能会限制其在此阶段的有效性。
- 如果在提取过程中发生错误,系统不会保留任何中间结果。如果在合并过程中发生错误,已合并的实体和关系可能会被保留;当重新处理同一文件时,重新提取的实体和关系将与现有实体和关系合并,而不会影响查询结果。
- 在合并阶段结束时,所有实体和关系数据都会在向量数据库中更新。如果此时发生错误,某些更新可能会被保留。但是,下一次处理尝试将覆盖先前结果,确保成功重新处理的文件不会影响未来查询结果的完整性。
大家好,我想请教一下如何更好的使用这个项目,我现在处理的好慢,昨天从晚上十点跑到今天早上7点,只处理好33份文件[苦涩]我看日志,一份47页的pdf花了一个小时(mineru处理了十分钟)。 我自己总结下是有以下几个 1.我应该使用milvus和neo4j存储,而不是图方便存本地 2.设置一下并发,而不是每次只处理一个文件 3.不对图片进行处理了(感觉对我当前的场景没有必要) 针对第一点,我想问一下,存储到数据库是影响检索速率还是存储(我个人感觉是不是只影响检索啊)
Embedding模型应该本地部署,这样速度才比较快。一个文本块的Embedding速度在本地是毫秒级别的。调用云端API通常是秒级别的。 没有必要都用RagAnything来处理,先试一下用LightRAG来处理看一把速度如何。日后LightRAG会进程RagAnything,到时候可以灵活地指定每个文件的处理方式。 LightRAG的处理速度组要受到LLM的影响,与使用什么存储关系不是十分大。 LLM每秒能够输出的Tokens数量和支持的最大并发数决定了文档处理的速度。 例如一个LLM在8个并发的时候能够达到 400Tokens/秒 的峰值,预计处理速度达到15~20秒处理一个文本块。文本块的处理速度与识别出来的实体数量和实体关系需要合并的数量是有关的,因此不同文档是有所不同的。 可以用以上经验值来评估一下自己的系统处理速度是否合理。
实现代码
1 | class LightRAGStorage: |
参考资料
通过实际案例拆解Light RAG,构建可视化知识图谱,解析Graph RAG的运行原理和关键概念(一)_哔哩哔哩_bilibili
AI知识图谱 GraphRAG 是怎么回事?_哔哩哔哩_bilibili
LightRAG/README-zh.md 在主 ·香港科技大学/LightRAG — LightRAG/README-zh.md at main · HKUDS/LightRAG