import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt from IPython.display import Image from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
1 2 3 4 5 6 7
#写入代码 # 一般先取出X和y后再切割,有些情况会使用到未切割的,这时候X和y就可以用,x是清洗好的数据,y是我们要预测的存活数据'Survived' data = pd.read_csv('clear_data.csv') train = pd.read_csv('train.csv') X = data y = train['Survived']
#写入代码 # 默认参数逻辑回归模型 lr = LogisticRegression() lr.fit(X_train, y_train)
/root/.pyenv/versions/3.11.1/lib/python3.11/site-packages/sklearn/linear_model/_logistic.py:465: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
#写入代码 from sklearn.metrics import confusion_matrix
1 2 3 4 5
#写入代码 # 训练模型 lr = LogisticRegression(C=100) lr.fit(X_train, y_train)
/root/.pyenv/versions/3.11.1/lib/python3.11/site-packages/sklearn/linear_model/_logistic.py:465: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
1 2 3
#写入代码 # 模型预测结果 pred = lr.predict(X_train)
1 2 3 4
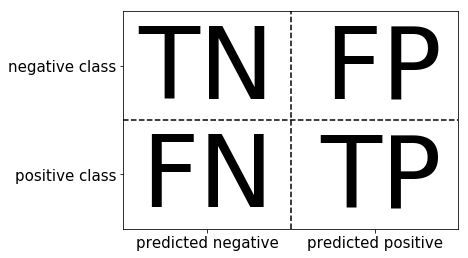
#写入代码 # 混淆矩阵 confusion_matrix(y_train, pred)
array([[355, 57],
[ 82, 174]])
1 2 3
from sklearn.metrics import classification_report # 精确率、召回率以及f1-score print(classification_report(y_train, pred))
/tmp/ipykernel_1400/2627332835.py:5: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2])
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
…
Age_66.0
Age_70.0
Age_70.5
Age_71.0
Age_74.0
Age_80.0
Embarked_0
Embarked_C
Embarked_Q
Embarked_S
0
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
…
False
False
False
False
False
False
False
False
False
True
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th…
female
38.0
1
0
PC 17599
71.2833
…
False
False
False
False
False
False
False
True
False
False
2
3
1
3
Heikkinen, Miss. Laina
female
26.0
0
0
STON/O2. 3101282
7.9250
…
False
False
False
False
False
False
False
False
False
True
3
4
1
1
Futrelle, Mrs. Jacques Heath (Lily May Peel)
female
35.0
1
0
113803
53.1000
…
False
False
False
False
False
False
False
False
False
True
4
5
0
3
Allen, Mr. William Henry
male
35.0
0
0
373450
8.0500
…
False
False
False
False
False
False
False
False
False
True
5 rows × 109 columns
1 2 3 4 5 6 7 8 9 10 11 12
#将类别文本转换为one-hot编码
#方法一: OneHotEncoder for feat in ["Age", "Embarked"]: x = pd.get_dummies(df["Age"] // 6) # x = pd.get_dummies(pd.cut(df['Age'],5)) x = pd.get_dummies(df[feat], prefix=feat) df = pd.concat([df, x], axis=1) #df[feat] = pd.get_dummies(df[feat], prefix=feat) df.head() df.to_csv('temp.csv')
#写入代码 from sklearn.model_selection import train_test_split # 一般先取出X和y后再切割,有些情况会使用到未切割的,这时候X和y就可以用,x是清洗好的数据,y是我们要预测的存活数据'Survived' X = data y = train['Survived'] # 对数据集进行切割 X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier
1 2 3 4 5 6
#写入代码 # 默认参数逻辑回归模型 lr = LogisticRegression() lr.fit(X_train, y_train)
/root/.pyenv/versions/3.11.1/lib/python3.11/site-packages/sklearn/linear_model/_logistic.py:465: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
1 2 3 4 5 6
#写入代码 # 查看训练集和测试集score值 print("Training set score: {:.2f}".format(lr.score(X_train, y_train))) print("Testing set score: {:.2f}".format(lr.score(X_test, y_test)))
Training set score: 0.80
Testing set score: 0.79
1 2 3 4 5 6 7
#写入代码 # 调整参数后的逻辑回归模型 lr2 = LogisticRegression(C=100) lr2.fit(X_train, y_train) print("Training set score: {:.2f}".format(lr2.score(X_train, y_train))) print("Testing set score: {:.2f}".format(lr2.score(X_test, y_test)))
Training set score: 0.79
Testing set score: 0.78
/root/.pyenv/versions/3.11.1/lib/python3.11/site-packages/sklearn/linear_model/_logistic.py:465: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
1 2 3 4 5
# 默认参数的随机森林分类模型 rfc = RandomForestClassifier() rfc.fit(X_train, y_train) print("Training set score: {:.2f}".format(rfc.score(X_train, y_train))) print("Testing set score: {:.2f}".format(rfc.score(X_test, y_test)))
/root/.pyenv/versions/3.11.1/lib/python3.11/site-packages/seaborn/axisgrid.py:854: FutureWarning:
`shade` is now deprecated in favor of `fill`; setting `fill=True`.
This will become an error in seaborn v0.14.0; please update your code.
func(*plot_args, **plot_kwargs)
/root/.pyenv/versions/3.11.1/lib/python3.11/site-packages/seaborn/axisgrid.py:854: FutureWarning:
`shade` is now deprecated in favor of `fill`; setting `fill=True`.
This will become an error in seaborn v0.14.0; please update your code.
func(*plot_args, **plot_kwargs)
<seaborn.axisgrid.FacetGrid at 0x7f9c6bce1f50>
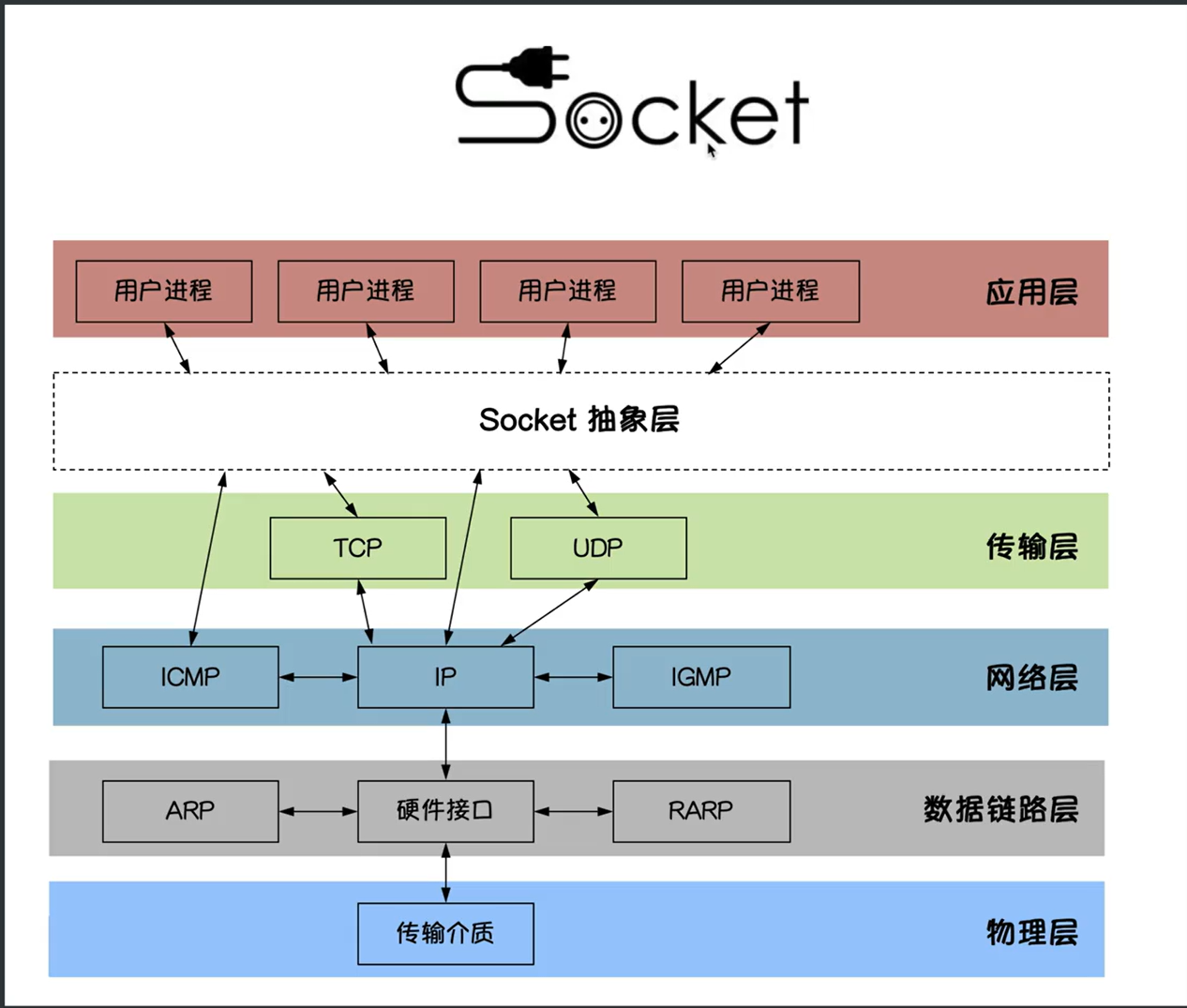
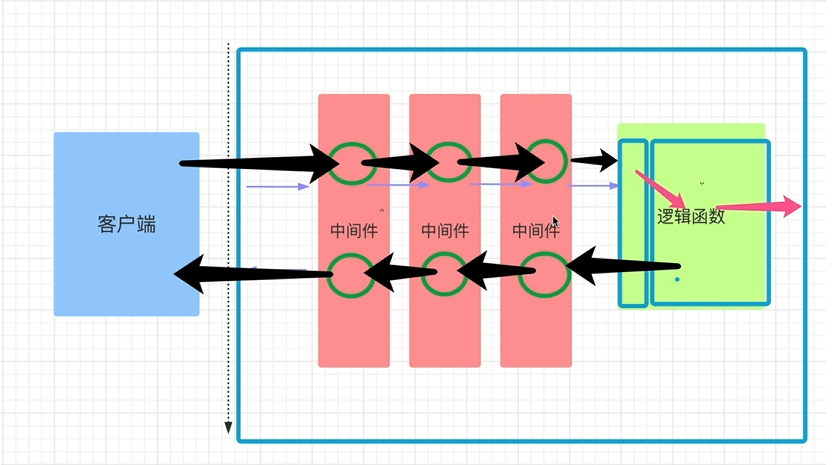
ASGI(Asynchronous Server Gateway Interface
)是一种用于连接 Python Web
服务器和应用程序框架的异步接口标准 ,旨在支持现代 Web
协议(如 WebSocket、HTTP/2)和异步编程模型
Pydantic负责
Pydantic 负责 FastAPI 的数据验证、序列化和自动文档生成
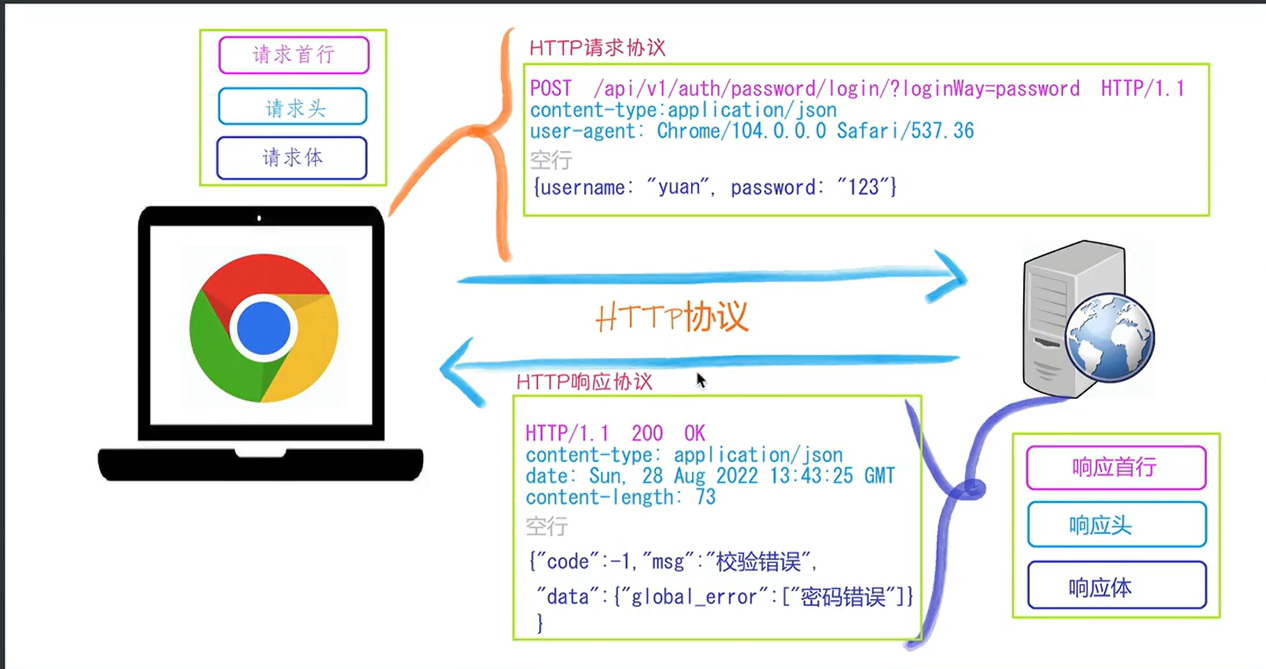
http协议
一、简介
HTTP协议 是Hyper Text Transfer
Protocol(超文本传输协议)的缩写,是用于万维网(WWW: World Wide
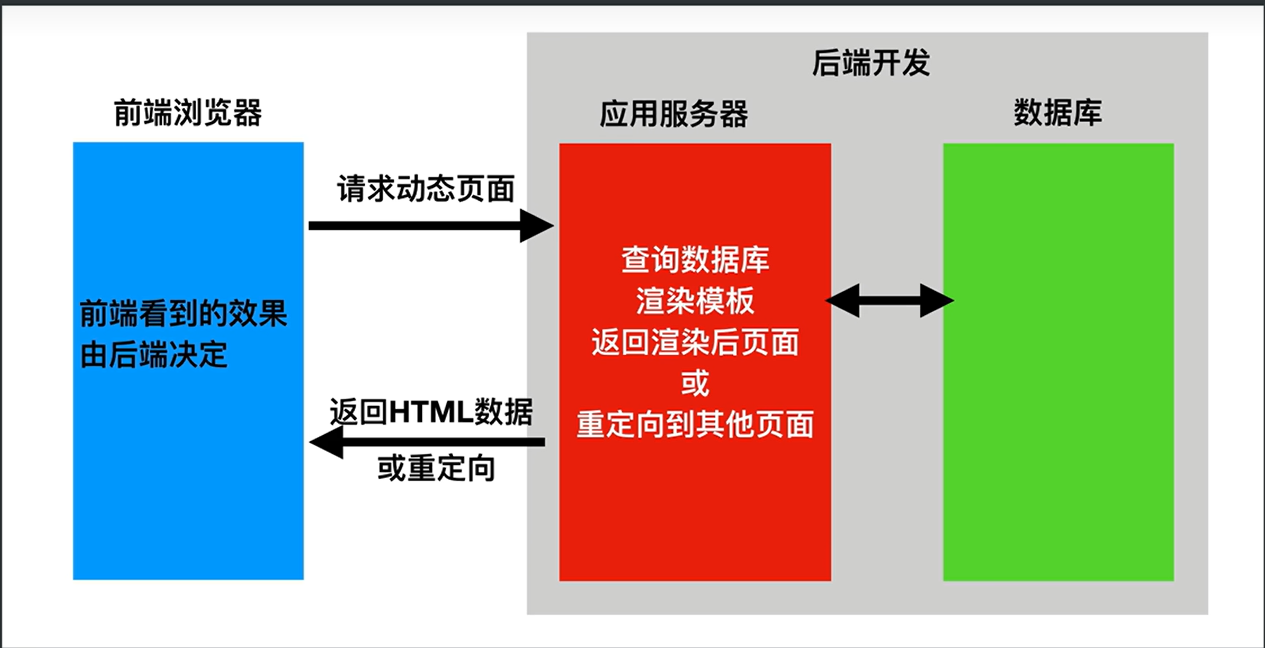
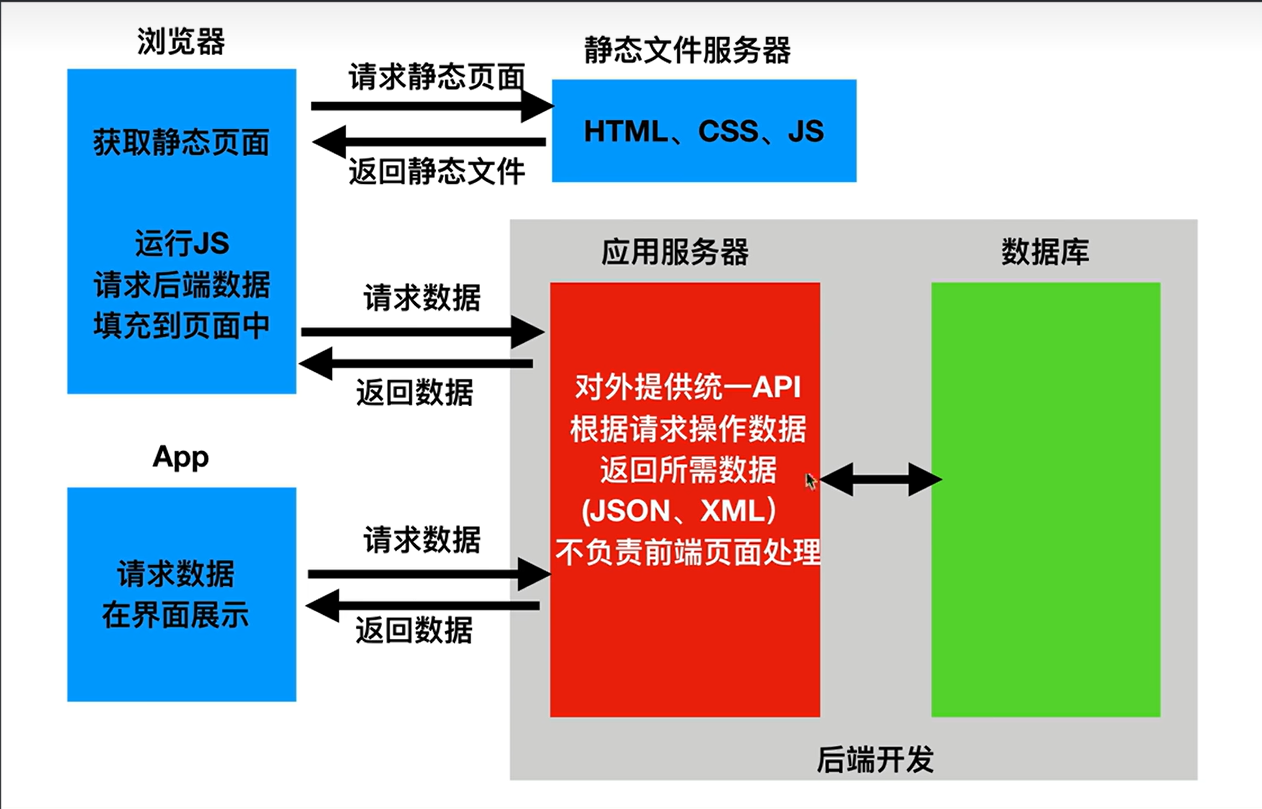
Web)服务器与本地浏览器之间传输超文本的传送协议。HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。


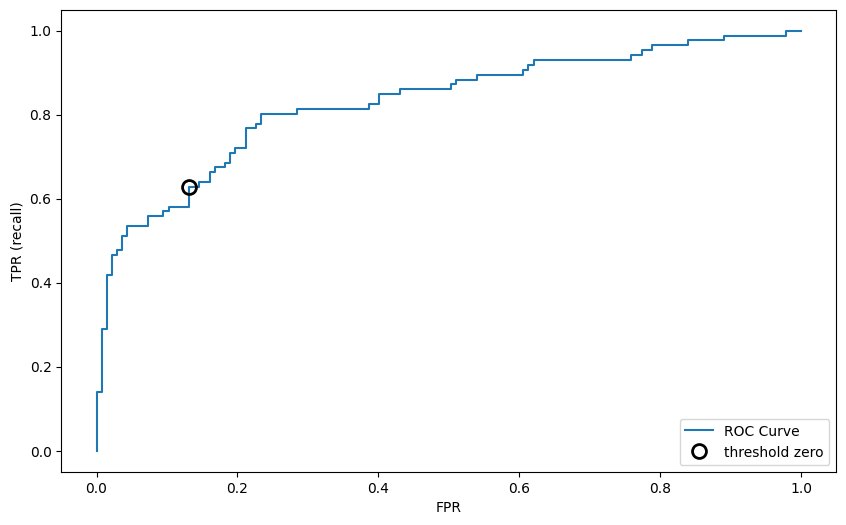
/第二章:第四节数据可视化-课程_10_0.png)
/第二章:第四节数据可视化-课程_14_1.png)
/第二章:第四节数据可视化-课程_19_0.png)
/第二章:第四节数据可视化-课程_20_0.png)
/第二章:第四节数据可视化-课程_23_1.png)
/第二章:第四节数据可视化-课程_27_2.png)
/第二章:第四节数据可视化-课程_29_1.png)